爬虫(二)解析数据
文章目录
- 1. Xpath
- 2. jsonpath
- 3. BeautifulSoup
- 4. 正则表达式
- 4.1 特殊符号
- 4.2 特殊字符
- 4.3 限定符
- 4.3 常用函数
- 4.4 匹配策略
- 4.5 常用正则
爬虫将数据爬取到后,并不是全部的数据都能用,我们只需要截取里面的一些数据来用,这也就是解析爬取到的信息,在解析方面,我们常用的手段有三个,Xpath,jsonpath以及BeautifulSoup,接下来我将对其分别进行介绍。
1. Xpath
Chrome有Xpath的插件,可以在应用商店里面下载一个,而Python中使用Xpath解析的话需要安装 lxml 库。
lxml 库的方法很多,这么只讲一些涉及到爬虫解析的方法,即主要使用的是 lxml 中的 etree 。Xpath的主要使用语句如下:
| 语句 | 含义 |
|---|---|
// | 查找所有子孙结点,忽略层级 |
/ | 只查找子结点 |
@ | 选取属性 |
.. | 选取当前节点的父节点 |
* | 通配符 |
[] | 选取子元素,如 [1] 表示选取第一个元素 |
div[@id] | 查找有 id 属性的 div 标签 |
div[@id="name"] | 查找 id="name" 属性的 div 标签 |
div[contains(@id, "name")] | 查找 id 中包含 name 的 div 标签 |
div[starts-with(@id, "name")] | 查找 id 中以 name 开头的 div 标签 |
div[@id="name" and @class="name1"] | 逻辑与查询 |
div[@id="name"] | div[@class="name1"] | 逻辑或操作,逻辑或不能写成 div[@id="name" | @class="name1"] |
我们查询的HTML 代码如下所示:
<!DOCTYPE html>
<html lang="en" ><head><meta charset="UTF-8"/><title></title></head>
<body><div class="wrapper"><a href="www.biancheng.net/product/" id="site">website product</a><ul id="sitename"><li><a href="http://www.biancheng.net/" title="编程帮" id="1">编程</a></li><li><a href="http://world.sina.com/" title="编程帮" id="2">微博</a></li><li><a href="http://www.baidu.com" title="百度">百度贴吧</a></li><li><a href="http://www.taobao.com" title="淘宝">天猫淘宝</a></li><li><a href="http://www.jd.com/" title="京东">京东购物</a></li><li><a href="http://c.bianchneg.net/" title="C语言中文网">编程</a></li><li><a href="http://www.360.com" title="360科技">安全卫士</a></li><li><a href="http://www.bytesjump.com/" title="字节">视频娱乐</a></li><li><a href="http://bzhan.com/" title="b站">年轻娱乐</a></li><li><a href="http://hao123.com/" title="浏览器Chrome">搜索引擎</a></li></ul></div>
</body>
</html>
下面是我们的代码查询示例:
from lxml import etreetree = etree.parse('test.html')# 找到ul下所有的a标签的文本内容
find1 = tree.xpath('//ul//a/text()')
print('find1 = {}'.format(find1))# 找到ul下所有的a标签中title="编程帮"的标签内容
find2 = tree.xpath('//a[@title="编程帮"]/text()')
print('find2 = {}'.format(find2))# 找到ul下所有的a标签中title="编程帮"且id="1"的标签内容
find3 = tree.xpath('//a[@id="1" and @title="编程帮"]/text()')
print('find3 = {}'.format(find3))# 找到ul下所有的a标签中title="淘宝"或id="1"的标签内容
find4 = tree.xpath('//a[@id="1"]/text() | //a[@title="淘宝"]/text()')
print('find4 = {}'.format(find4))# 找到ul下所有的a标签中title包含"C"的标签内容
find5 = tree.xpath('//a[contains(@title, "C")]/text()')
print('find5 = {}'.format(find5))# 找到ul下所有的a标签的以"C"开头的title的标签内容
find6 = tree.xpath('//a[starts-with(@title, "C")]/text()')
print('find6 = {}'.format(find6))# 找到ul下所有的a标签中title="淘宝"或id="1"的标签的爷爷结点的id
find7 = tree.xpath('//a[starts-with(@title, "C")]/../../@id')
print('find7 = {}'.format(find7))
输出如下:
find1 = [‘编程’, ‘微博’, ‘百度贴吧’, ‘天猫淘宝’, ‘京东购物’, ‘编程’, ‘安全卫士’, ‘视频娱乐’, ‘年轻娱乐’, ‘搜索引擎’]
find2 = [‘编程’, ‘微博’]
find3 = [‘编程’]
find4 = [‘编程’, ‘天猫淘宝’]
find5 = [‘编程’, ‘搜索引擎’]
find6 = [‘编程’]
find7 = [‘sitename’]
接下来我们讲讲最开始安装的Xpath的插件有什么作用。在这里我们以百度首页为例,按下 Ctrl+Shift+x ,并按下F12唤出开发者工具,页面如下。
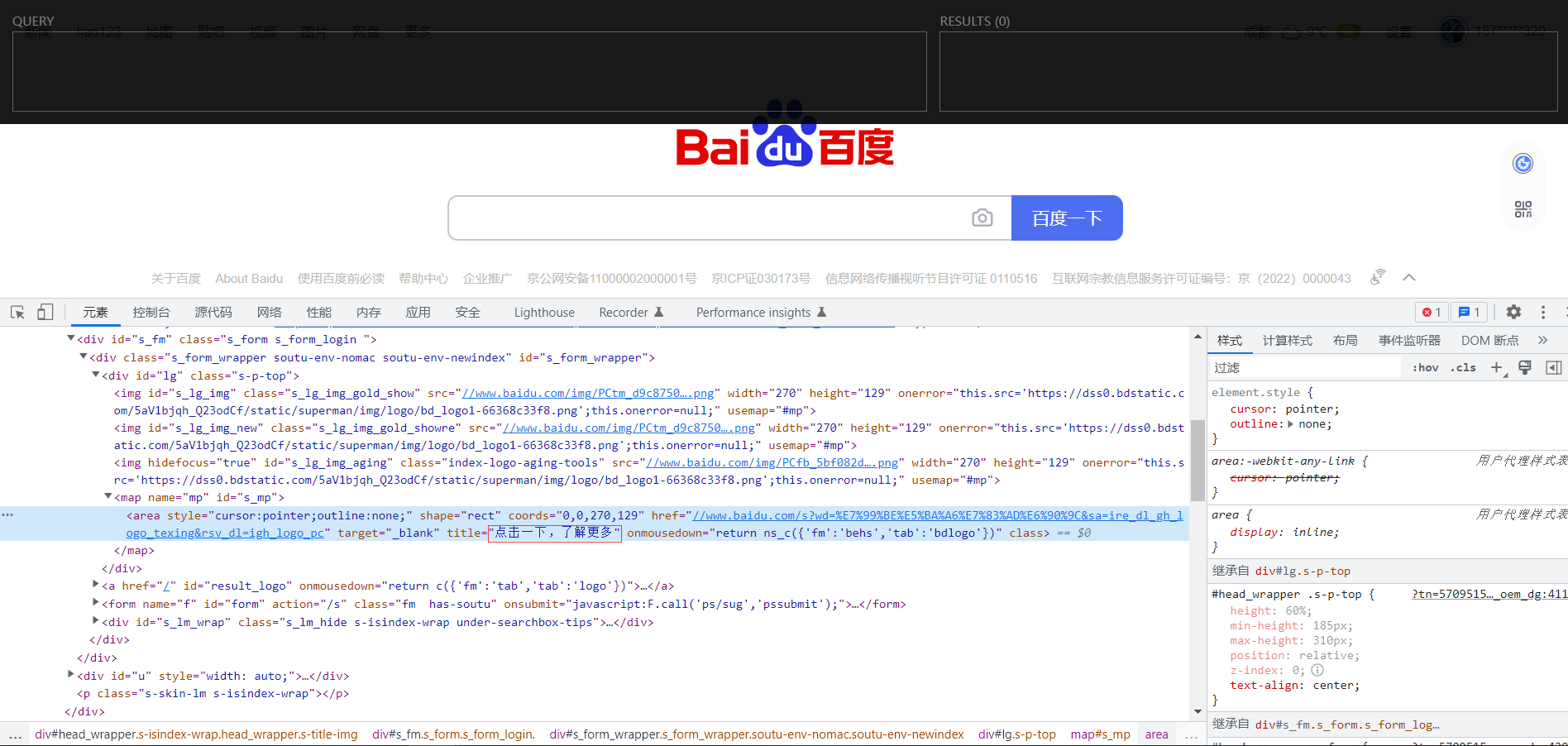
上面的黑框就是插件所起的效果,比如说我们获取上图的 点击一下,了解更多 字样,那我们就可以在黑框中输入我们的Xpath查询语句,黑框右边就会出现语句查询得到的结果,非常实用。
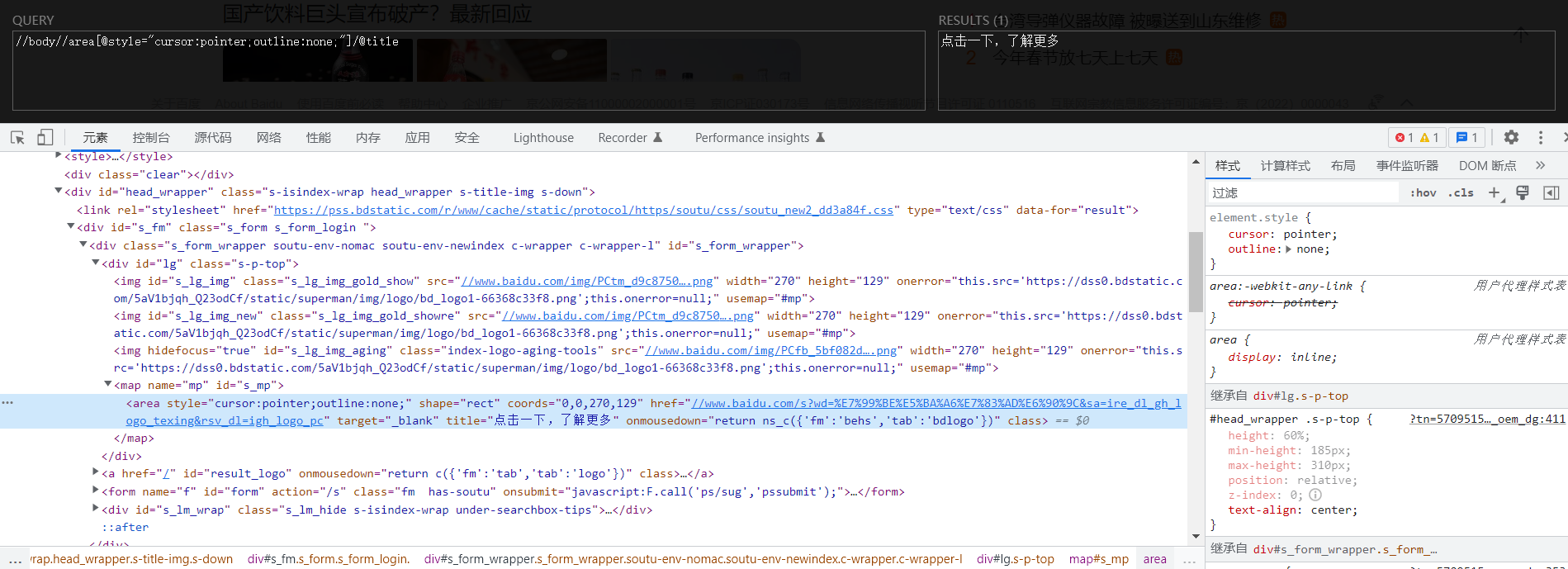
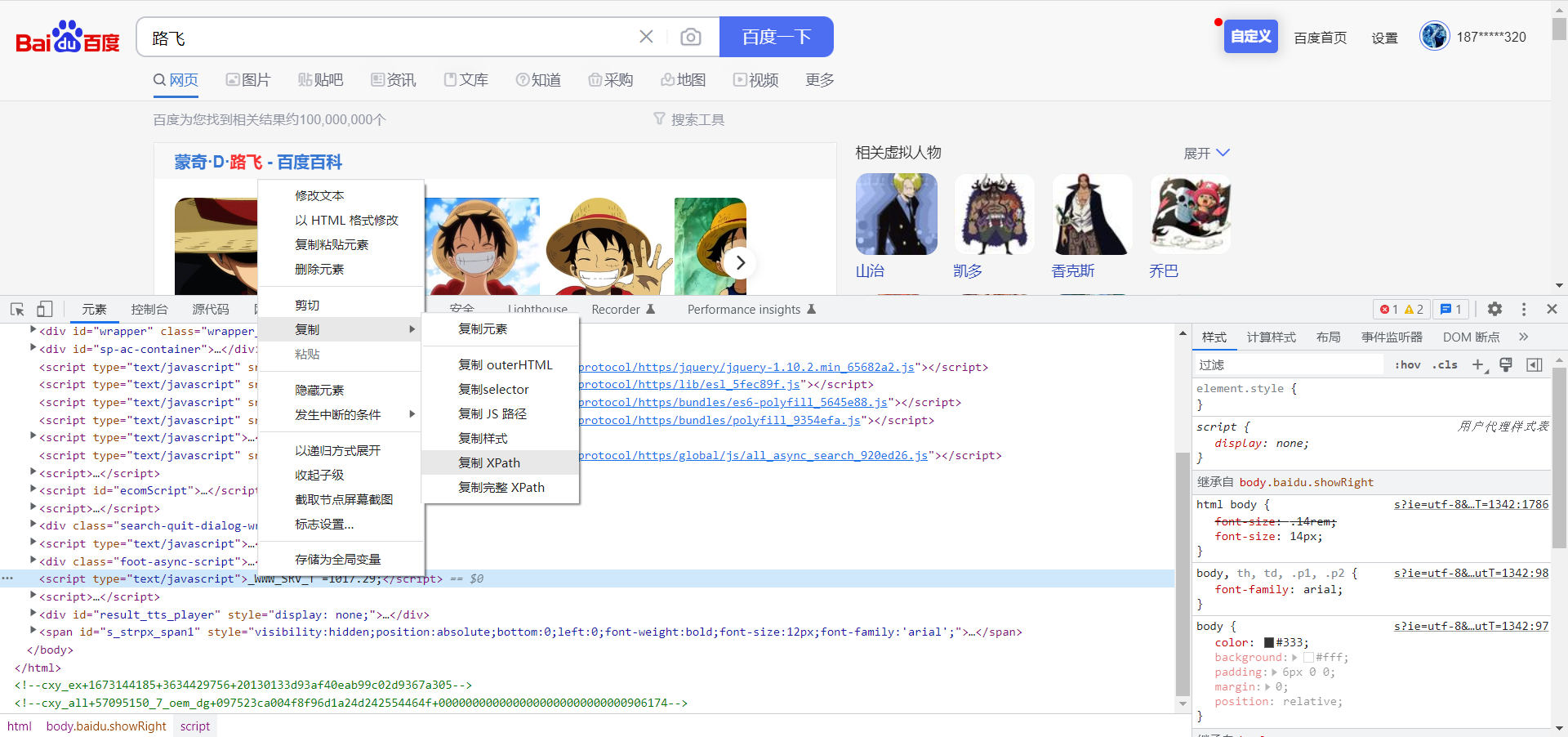
当然,如果你不想这样看得眼花缭乱的去写Xpath也行,只需要在F12开发者模式下右击你想要查询的元素,选择复制Xpath即可,如下图所示,实际上,我们一般选择的是这种方法,虽然有的时候复制的并不是最简的Xpath语法,但是这确实有效。
2. jsonpath
jsonpath使用前必须安装jsonpath的包,jsonpath 是参照xpath表达式来解析xml文档的方式,jsonpath的入门可以参考这篇文章,在这里,我将主要的点进行一下说明。
学会了Xpath的语法,那么jsonpath的语法其实可以对照着进行学习。
| Xpath | jsonpath | 说明 |
|---|---|---|
| / | $ | 表示根元素 |
| . | @ | 当前元素 |
| / | . or [] | 子元素 |
| … | 父元素 | |
| // | … | 递归下降,JSONPath是从E4X借鉴的。 |
| * | * | 通配符,表示所有的元素 |
| @ | 属性访问字符 | |
| [] | [] | 子元素操作符 |
| | | [,] | 逻辑或。jsonpath允许name或者 [start:end:step] 的数组分片索引 |
| [] | ?() | 应用过滤表示式 |
为了更加直观一点,我把文章的例子搞过来,大家可以对照着看。
测试数据如下:
{ "store": {"book": [ { "category": "reference","author": "Nigel Rees","title": "Sayings of the Century","price": 8.95},{ "category": "fiction","author": "Evelyn Waugh","title": "Sword of Honour","price": 12.99},{ "category": "fiction","author": "Herman Melville","title": "Moby Dick","isbn": "0-553-21311-3","price": 8.99},{ "category": "fiction","author": "J. R. R. Tolkien","title": "The Lord of the Rings","isbn": "0-395-19395-8","price": 22.99}],"bicycle": {"color": "red","price": 19.95}}
}
| XPath | JSONPath | 结果 |
|---|---|---|
| /store/book/author | $.store.book[*].author | 书点所有书的作者 |
| //author | $..author | 所有的作者 |
| /store/* | $.store.* | store的所有元素。所有的bookst和bicycle |
| /store//price | $.store..price | store里面所有东西的price |
| //book[3] | $..book[2] | 第三个书 |
| //book[last()] | $..book[(@.length-1)] | 最后一本书 |
| //book[position() < 3] | $..book[0,1] $..book[:2] | 前面的两本书。 |
| //book[isbn] | $..book[?(@.isbn)] | 过滤出所有的包含isbn的书。 |
| //book[price<10] | $..book[?(@.price<10)] | 过滤出价格低于10的书。 |
| //* | $..* | 所有元素。 |
3. BeautifulSoup
BeautifulSoup 库也是解析爬虫的一大利器,BeautifulSoup 库的解析速度比 Xpath 相对来说更慢一些,但是使用方法简单了不少。这里将BeautifulSoup 常用的方法例举如下:
| 方法 | 含义 |
|---|---|
soup.a | 找到第一个 a 标签 |
soup.a.name | 找到第一个 a 标签,并输出标签名 |
soup.a.attrs | 找到第一个 a 标签,并将标签属性以字典列出 |
soup.a.get_text() | 找到第一个 a 标签,并输出其内容 |
soup.find('a', class_='name1') | 找到第一个 class='name1' 的 a 标签 |
soup.find_all('a') | 找到全部的 a 标签,并以列表形式返回 |
soup.find_all(['a', 'span']) | 找到全部的 a 标签和 span 标签 |
soup.find_all('a', limit=2) | 找到前两个 a 标签 |
soup.select('a') | 找到全部的 a 标签,并以列表返回 |
soup.select('.a1') | 找到全部的 class='a1' 的标签 |
soup.select('#a1') | 找到全部的 id=a1 的标签 |
soup.select('a[class]') | 找到全部的拥有 class 属性的 a 标签 |
soup.select('a[class='name1']') | 找到全部的 class='name1' 的 a 标签 |
soup.select('a', 'span') | 找到全部的 a 标签和 span 标签 |
soup.select('div li') | 找到 div 后代中的所有 li 标签 |
soup.select('div > li') | 找到 div 子代(即下面第一层级)中的所有 li 标签 |
我们仍以第一节中 Xpath 的HTML代码为例进行查询。
from bs4 import BeautifulSoup# 使用lxml解析器
soup = BeautifulSoup(open("test.html", encoding='utf-8'), "lxml")find1 = soup.a
print('find1 = {}'.format(find1.get_text()))
print('find1.name = {}'.format(find1.name))
print('find1.attrs = {}'.format(find1.attrs))# 找到id=site 的标签
find2 = soup.select('#site')
print('find2 = {}'.format(find2))# 找到前两个 a 标签和 li 标签
find3 = soup.find_all(['a', 'li'], limit=2)
print('find3 = {}'.format(find3))# 找到class=th 的 a 标签
find4 = soup.select('a[class="th"]')
print('find4 = {}'.format(find4))
4. 正则表达式
最后我们来讲一讲正则表达式。爬虫解析数据中最出名的当属正则表达式了,但是正则表达式并不是仅仅在爬虫中才有使用,很多的搜索功能或者筛选功能都支持正则表达式。聊到Python正则表达式的支持,首先肯定会想到re库,这是一个Python处理文本的标准库,下面我就来详细讲讲re库的使用。
4.1 特殊符号
正则表达式中存在这一些特殊符号,这些符号的使用能够带来不同的匹配作用,介绍如下:
| 模式 | 描述 |
|---|---|
| . | 匹配除换行符 \n 之外的任何 单字符。要匹配 . ,请使用 \. 。 |
| * | 匹配前面的 子表达式 零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的 子表达式 一次或多次。要匹配 + 字符,请使用 \+。 |
| ? | 匹配前面的 子表达式 零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| ^ | 匹配输入字符串的开始位置,在方括号表达式中使用时,表示不接受该字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| $ | 匹配字符串的结尾位置。如果设置了Multiline 属性,则 $ 也匹配 \n 或 \r。要匹配 $ 字符本身,请使用 \$。 |
| \ | 转义字符。将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。 |
| | | 关系符号“或”。指明两项之间的一个选择。要匹配 |,请使用 \|。 |
4.2 特殊字符
正则表达式中还存在一些以转义字符开头的特殊字符,这些符号也能表示一些匹配的规则。
| 模式 | 描述 |
|---|---|
| \d | 匹配数字:[0-9] |
| \D | 匹配非数字 |
| \s | 匹配任何空白字符 |
| \S | 匹配非空白字符 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \A | 仅匹配字符串开头,同^ |
| \Z | 仅匹配字符串结尾,同$ |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’ |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’ |
4.3 限定符
限定符用来指定正则表达式的一个给定 子字符串 必须要出现多少次才能满足匹配。
| 字符 | 描述 |
|---|---|
| ( ) | 标记一个 子表达式 的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| [ ] | 标记一个 中括号表达式 的开始和结束位置。表示字符集合。要匹配这些字符,请使用 \[ 和 \]。 |
| { } | 标记 限定符表达式 的开始和结束位置。要匹配这些字符,请使用 \{ 和 \}。 |
| {n} | n 是一个非负整数。它前面的 字符 或 子字符串 匹配确定的 n 次。 |
| {n,} | n 是一个非负整数。它前面的 字符 或 子字符串 至少匹配n 次。 |
| {,m} | m 为非负整数,它前面的 字符 或 子字符串 最多匹配 m 次。 |
| {n,m} | n 和 m 均为非负整数,其中n <= m。它前面的 字符 或 子字符串 最少匹配 n 次且最多匹配 m 次。 |
4.3 常用函数
接下来介绍 re 库中的常用函数。
-
match
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None,只匹配一个。
函数的使用如下:re.match(pattern, string, flags=0)其中
pattern是要匹配的正则表达式,string是要匹配的字符串,flags是正则表达式匹配的模式。 -
search
re.search扫描整个字符串并返回第一个成功的匹配。
函数的使用如下:re.search(pattern, string, flags=0)其中
pattern是要匹配的正则表达式,string是要匹配的字符串,flags是正则表达式匹配的模式。示例如下:import res = 'Red里面香克斯帅爆了好吧' pattern = r'香克斯.' print('re.search结果:{}'.format(re.search(pattern, s).group())) print('re.match结果:{}'.format(re.match(pattern, s)))输出结果为
re.search结果:香克斯帅
re.match结果:None -
sub
re.sub为re模块的替换函数。
函数的使用如下:re.sub(pattern, repl, string, count=0, flags=0)其中
pattern是要匹配的正则表达式,repl是要替换成什么字符串,string原始字符串,count表示模式匹配后替换的最大次数,默认 0 表示替换所有的匹配,flags是正则表达式匹配的模式。 -
compile
re.compile函数用于编译正则表达式,生成一个正则表达式(Pattern)对象,供match()和search()这两个函数使用。
函数的使用如下:re.compile(pattern[, flags])其中
pattern是要匹配的正则表达式,flags可选,是正则表达式匹配的模式。示例如下。import res = 'Red里面香克斯帅爆了好吧' pattern = re.compile(r'香克斯.') m = pattern.search(s) print('匹配结果:{}'.format(m.group())) print('替换结果:{}'.format(re.sub('香克斯', '路飞', s)))输出结果如下:
匹配结果:香克斯帅
替换结果:Red里面路飞帅爆了好吧 -
findall
re.findall在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
函数的使用如下:findall(string[, pos[, endpos]])其中
string是字符串,pos是可选参数,表示匹配开始的位置,endpos是可选参数,表示匹配结束的位置。 -
split
re.splitsplit 方法按照能够匹配的子串将字符串分割后返回列表。
函数的使用如下:re.split(pattern, string[, maxsplit=0, flags=0])其中
pattern是匹配的正则表达式,string是要匹配的字符串,maxsplit分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数,flags是匹配模式。示例如下:import res = 'Red里面香克斯帅爆了好吧,香克斯牛皮' pattern = re.compile(r'香克斯.') m = pattern.findall(s) print('匹配结果:{}'.format(m)) print('切分结果:{}'.format(re.split('香克斯.', s)))
最后,对于 search() 以及 match() 函数匹配后返回的 Match 对象,都有以下的方法可以使用:
| 方法 | 描述 |
|---|---|
group([group1, …]) | 获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0) |
start([group]) | 获取分组匹配的子串在整个字符串中的起始位置 |
end([group]) | 获取分组匹配的子串在整个字符串中的结束位置 |
span([group]) | 方法返回 (start(group), end(group)) |
4.4 匹配策略
正则表达式中常用的匹配策略有四种,可以在各函数的flag中进行模式指定。
-
IGNORECASE
可以使用re.IGNORECASE或re.I标志。进行忽略大小写的匹配。示例如下:import res = 'Red里面香克斯帅爆了好吧,香克斯牛皮' pattern1 = re.compile(r'r') pattern2 = re.compile(r'r', re.I) print('默认情况:{}'.format(pattern1.findall(s))) print('改变后为:{}'.format(pattern2.findall(s)))输出结果为
默认情况:[]
改变后为:[‘R’] -
ASCII
可以使用re.ASCII或re.A标志。让\w,\W,\b,\B,\d,\D,\s和\S只匹配ASCII,而不是Unicode。示例如下:import res = 'Red里面香克斯帅爆了好吧\n香克斯牛皮' pattern1 = re.compile(r'\w+') pattern2 = re.compile(r'\w+', re.A) print('默认情况:{}'.format(pattern1.findall(s))) print('改变后为:{}'.format(pattern2.findall(s)))输出结果为
默认情况:[‘Red里面香克斯帅爆了好吧’, ‘香克斯牛皮’]
改变后为:[‘Red’] -
DOTALL
可以使用re.DOTALL或re.S标志。DOT表示.,ALL表示所有,连起来就是.匹配所有,包括换行符\n。默认模式下.是不能匹配行符\n的。示例如下:import res = 'Red里面香克斯帅爆了好吧\n香克斯牛皮' pattern1 = re.compile(r'香克斯.*') pattern2 = re.compile(r'香克斯.*', re.S) print('默认情况:{}'.format(pattern1.findall(s))) print('改变后为:{}'.format(pattern2.findall(s)))输出结果为
默认情况:[‘香克斯帅爆了好吧’, ‘香克斯牛皮’]
改变后为:[‘香克斯帅爆了好吧\n香克斯牛皮’] -
MULTILINE
可以使用re.MULTILINE或re.M标志。多行模式,当某字符串中有换行符\n,默认模式下是不支持换行符特性的,影响 ^ 和 $。示例如下:import res = '香克斯Red里面帅爆了好吧\n香克斯牛皮' pattern1 = re.compile(r'^香克斯') pattern2 = re.compile(r'^香克斯', re.M) print('默认情况:{}'.format(pattern1.findall(s))) print('改变后为:{}'.format(pattern2.findall(s)))输出结果为
默认情况:[‘香克斯’]
改变后为:[‘香克斯’, ‘香克斯’] -
VERBOSE
可以使用re.VERBOSE或re.X标志。详细模式,可以在正则表达式中加注解,会忽略正则表达式中的空格和#后面的注释。示例如下:import res = '香克斯Red里面帅爆了好吧香克斯牛皮' pattern1 = re.compile(r'^香克斯 #四皇之一') pattern2 = re.compile(r'^香克斯 #四皇之一', re.X) print('默认情况:{}'.format(pattern1.findall(s))) print('改变后为:{}'.format(pattern2.findall(s)))输出结果为
默认情况:[]
改变后为:[‘香克斯’]
4.5 常用正则
| 正则表达式 | 解释 |
|---|---|
[\u4e00-\u9fa5]+ | 匹配汉字 |
这里我给一个就行,其他的有什么功能都可以去查。
相关文章:
爬虫(二)解析数据
文章目录1. Xpath2. jsonpath3. BeautifulSoup4. 正则表达式4.1 特殊符号4.2 特殊字符4.3 限定符4.3 常用函数4.4 匹配策略4.5 常用正则爬虫将数据爬取到后,并不是全部的数据都能用,我们只需要截取里面的一些数据来用,这也就是解析爬取到的信…...

【C++、C++11】可变参数模板、lambda表达式、包装器
文章目录📖 前言1. 可变参数模板1.1 万能模板:1.2 完美转发:1.3 可变参数模板的使用:1.4 emplace_back:2. lambda表达式2.1 lambda表达式的定义:2.2 lambda表达式的用法:2.2 - 1 捕捉列表的用法…...

外贸主机测评
一、俄罗斯vps 服务商: JUSTG: Home - Sun Network Company Limited LOCVPS: LOCVPS 全球云 - 十年老牌 为跨境外贸/远程办公/网站建设提供澎湃动力 JUSTHOST: justhost.ru RUVDS: Gcorelabs: 二、主机测评指标: 1、速度、延迟、丢包、路由测试…...

Meta CTO:Quest 2生命周期或比预期更久
前不久,Meta未来4年路线图遭曝光,泄露了该公司正在筹备中的一些AR/VR原型。除此之外,还有消息称Quest Pro或因销量不佳,而不再迭代。毫无疑问,Meta的一举一动持续受到行业关注,而面对最近的爆料,…...

Vector - CAPL - 文件处理函数
在当前平台化的趋势下,就算是协议层测试依然需要适配各种各样的项目,也需要处理各类型的文件,那我们如何对文件进行读取、写入、修改等类型的操作呢?今天我们就会介绍此类型的函数,主要适用于text、bin文件的处理。 打开文件 Open...

实力加持!RestCloud完成多方国产化适配,携手共建信创生态
近年来,随着数字化建设进入深水区,企事业单位对信息安全重视程度与日俱增,核心技术自主可控已成为时代呼唤,国产化浪潮日益汹涌澎湃。近日,RestCloud在国产化方面取得新进展,完成了全部产品线信创环境的多方…...

Unity 3D GUI教程||OnGUI TextArea 控件||OnGUI ScrollView 控件
OnGUI TextArea 控件 Unity 3D TextArea 控件用于创建一个多行的文本编辑区。用户可以在多行文本编辑区编辑文本内容。 该控件可以对超出控件宽度的文本内容实现换行操作。 TextArea 控件同样会将当前文本编辑区中的文本内容以字符串形式返回。 开发人员可以通过创建 Strin…...
Leetcode.828 统计子串中的唯一字符
题目链接 Leetcode.828 统计子串中的唯一字符 Rating : 2034 题目描述 我们定义了一个函数 countUniqueChars(s)来统计字符串 s中的唯一字符,并返回唯一字符的个数。 例如:s "LEETCODE",则其中 "L", "…...

Hibernate 相关特性
1. Hibernate一般使用hql进行查询,但也有sql执行的方法 Native sql 查询,。需要注意的是,使用Native SQL查询可能会破坏Hibernate的缓存机制,并可能导致性能问题 String sql "SELECT * FROM users WHERE age > :age"; Query …...

【研究生学术英语读写教程翻译 中国科学院大学Unit1-Unit8】
Unit1 Descartes Was Wrong 笛卡尔错了:“他人在,故我在” Unit2 Are we ready for the next volcanic catastrophe?我们准备好应对下一次火山灾难了吗? Unit3 Theorists,experimentalists and the bias in popular physics理论家,实验家和大众物理学的偏见 unit4 Magic Nu…...

ListView 控件的使用
第一步:找到ListView的控件通过findViewById 找到ListView的控件 ListView listView findViewById(R.id.listView);第二步:创建Bean类 得到set和get的方法解析获取的数据创建Bean类 得到set和get的方法public class Bean {String nanm""; pub…...
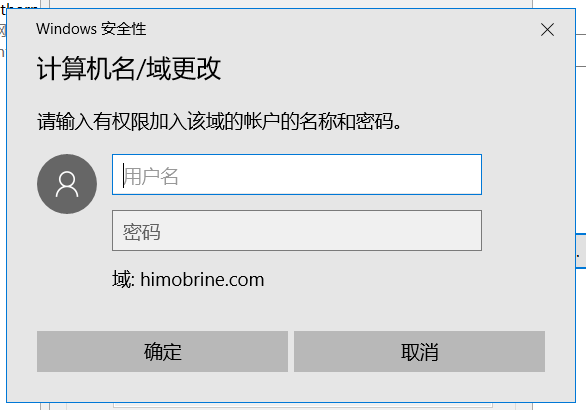
域控制器搭建以及成员加入
需要iso:windows server 2016软件使用:vmwarewindows server 2016系统搭建自己选iso,一直下一步就可以安装完成。(记得要设置密码)(密码要求大小写字母数字符号)等待就能安装完成。安装和配置Ac…...
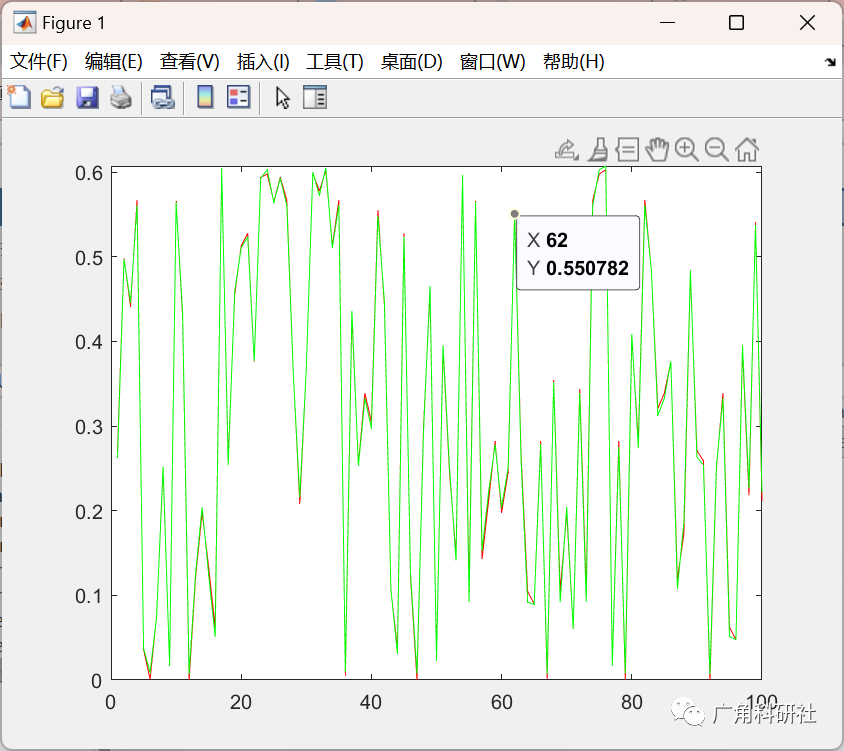
利用 MLP(多层感知器)和 RBF(径向基函数)神经网络解决的近似和分类示例问题(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 1、径向基神经网络 径向基函数网络是由三层构成的前向网络:第一层为输入层,节点个数的能与输入的维数&…...
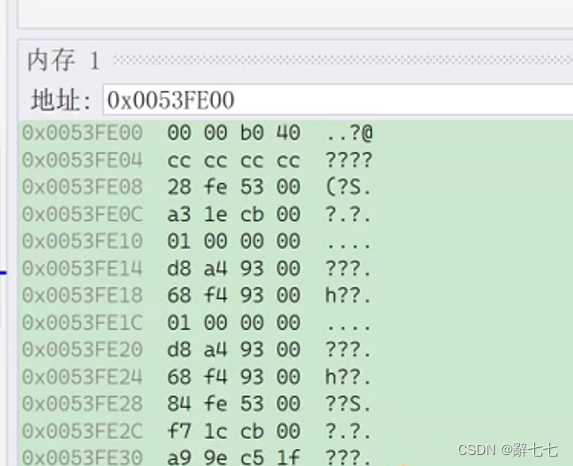
进阶C语言——数据的存储【详解】
文章目录1. 数据类型介绍1.1 类型的基本归类2. 整形在内存中的存储2.1 原码、反码、补码2.2 大小端介绍2.3 练习3. 浮点型在内存中的存储3.1 一个例子3.2 浮点数存储的规则1. 数据类型介绍 前面我们已经学习了基本的内置类型: char //字符数据类型 short //短整型 …...
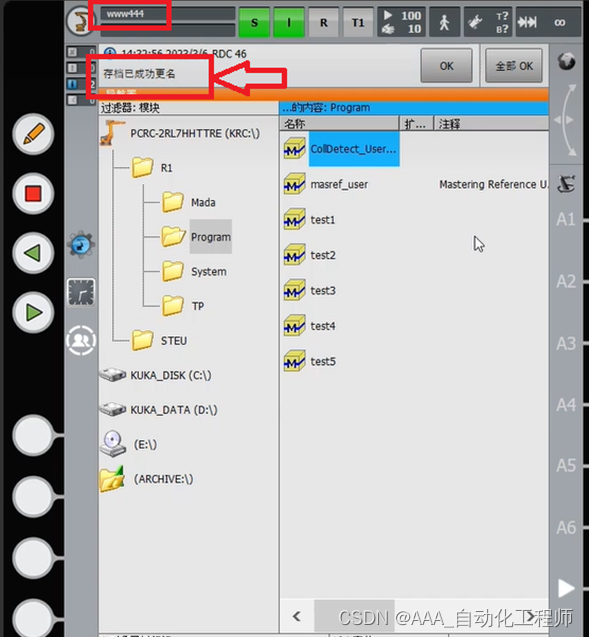
KUKA机器人修改机器人名称和IP地址的具体方法示例
KUKA机器人修改机器人名称和IP地址的具体方法示例 修改机器人名称 如下图所示,首先切换用户组到管理员,输入默认密码:kuka, 如下图所示,点击菜单键—投入运行—机器人数据, 如下图所示,此时可以看到机器人的名称为rrr445, 如下图所示,修改之后,点击左侧的“”…...
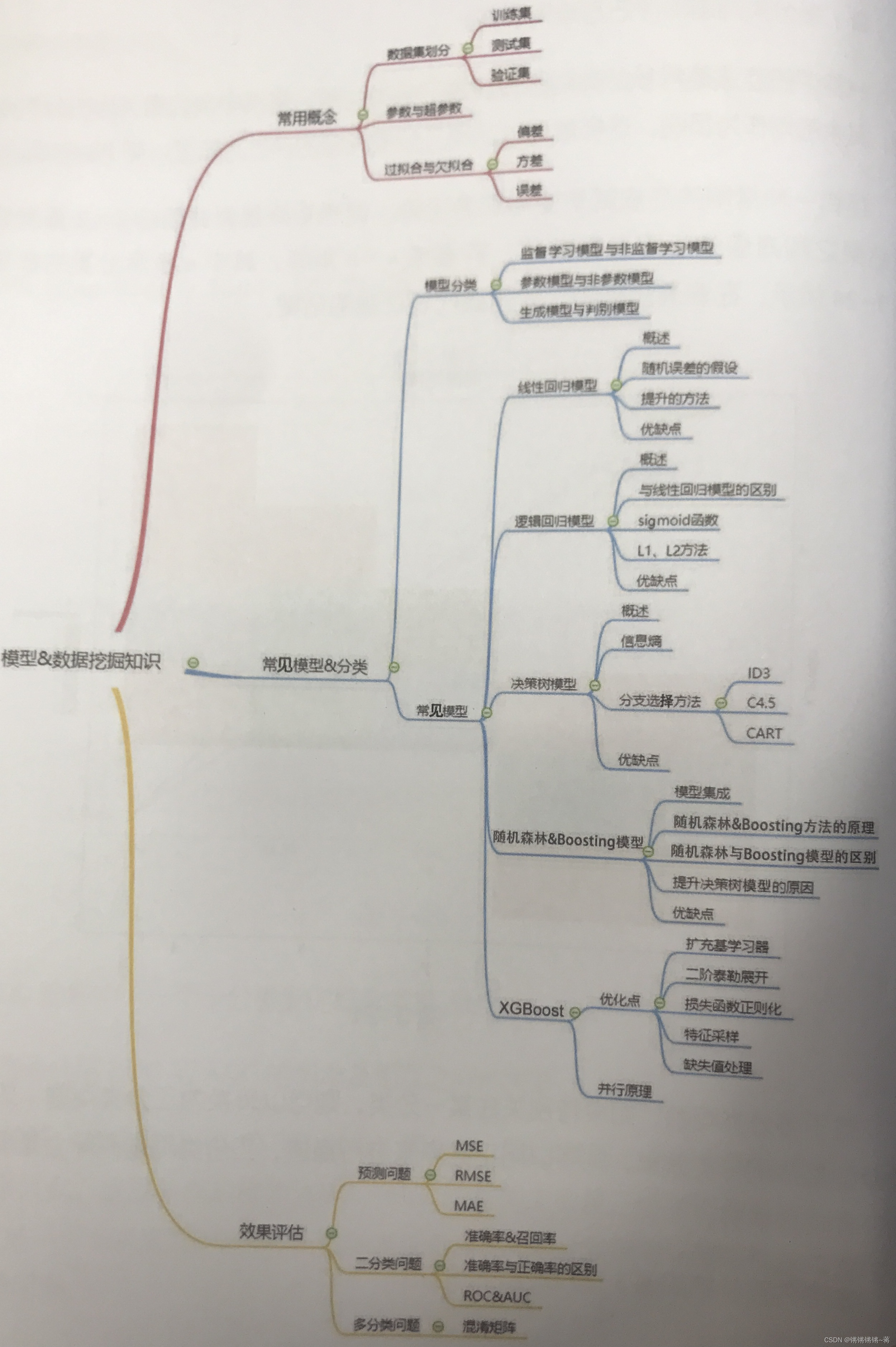
【数据分析师求职面试指南】必备基础知识整理
数据分析师基础知识统计 数据分析知识基础概念随机变量常用特征正态分布与大数定律、中心极限定律假设检验模型、数据挖掘知识常用概念数据集划分欠拟合过拟合模型分类方法常见模型介绍线性回归模型:逻辑回归模型决策树模型随机森林模型Boosting模型XGBoost模型模型…...
的原理与应用》)
《开关电源宝典 降压电路(BUCK)的原理与应用》
嗨,硬件攻城狮或电源工程师同行们,我想写本专门解析BUCK电源电路的书籍,以下是“前言”内容的部分摘录以及当前的目录,当前已经完成22万多字500多页了,即使如此,离真正出版书籍,还有很长的路要走…...

R语言基础(一):注释、变量
R语言用于统计分析和绘制图表等操作。不同于Java等其它语言,R用于统计,而不是做一个网站或者软件,所以R的一些开发习惯和其它语言不同。如果你是一个编程小白,那么可以放心大胆的学。如果你是一个有编程基础的人,那么需…...

Java 集合进阶(二)
文章目录一、Set1. 概述2. 哈希值3. 元素唯一性4. 哈希表5. 遍历学生对象6. LinkedHashSet7. TreeSet7.1 自然排序7.2 比较器排序8. 不重复的随机数二、泛型1. 概述2. 泛型类3. 泛型方法4. 泛型接口5. 类型通配符6. 可变参数7. 可变参数的使用一、Set 1. 概述 Set 集合特点&am…...

小孩用什么样的台灯比较好?2023眼科医生青睐的儿童台灯推荐
小孩子属于眼睛比较脆弱的人群,所以选购护眼台灯时,选光线温和的比较好,而且调光、显色效果、色温、防蓝光等方面也要出色,否则容易导致孩子近视。 1、调光。台灯首先是照度高,国AA级+大功率发光࿰…...

别再IO模拟SPI了!STM32F103驱动AD9833信号发生器,库函数SPI配置避坑全记录
STM32硬件SPI驱动AD9833信号发生器的深度避坑指南 在嵌入式开发中,SPI通信是最常用的外设接口之一。许多开发者习惯使用GPIO模拟SPI时序,认为这样更灵活可控。但当我们面对AD9833这类对时序要求严格的芯片时,IO模拟的弊端就会暴露无遗——信号…...

Loop:Mac窗口管理的终极免费解决方案,告别杂乱桌面
Loop:Mac窗口管理的终极免费解决方案,告别杂乱桌面 【免费下载链接】Loop Window management made elegant. 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 你是否曾为Mac上杂乱的窗口而烦恼?当多个应用同时打开时ÿ…...

终极指南:轻松突破Cursor Pro限制,实现永久免费使用
终极指南:轻松突破Cursor Pro限制,实现永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

n8n与Claude集成指南:构建AI代码生成与自动化执行工作流
1. 项目概述与核心价值最近在折腾自动化工作流时,我偶然发现了一个名为n8n-claude-code-guide的开源项目。这个项目乍一看名字,你可能以为它只是一个简单的代码指南,但深入探究后,你会发现它实际上是一个将两个强大的工具——n8n和…...

从虚拟到物理:电子系统原型设计的工程化策略与实战解析
1. 原型设计全景:从概念到实物的工程化思维 在电子系统设计领域,尤其是面对航空航天、汽车电子、通信设备这类高复杂、高可靠性要求的项目时,“原型”这个词的分量远超一个简单的模型。它不是一个可有可无的步骤,而是连接创意与产…...

AnyFlip下载器:3分钟将在线翻页电子书变为永久PDF收藏
AnyFlip下载器:3分钟将在线翻页电子书变为永久PDF收藏 【免费下载链接】anyflip-downloader Download anyflip books as PDF 项目地址: https://gitcode.com/gh_mirrors/an/anyflip-downloader 你是否曾在AnyFlip网站上发现一本精彩的电子书,想要…...

Pinecone示例库实战指南:从向量数据库原理到RAG应用开发
1. 项目概述:Pinecone示例库的深度探索 如果你正在寻找一个能让你快速上手向量数据库和现代AI应用开发的“实战训练营”,那么Pinecone官方的 pinecone-io/examples 仓库绝对是一个不容错过的宝藏。这个仓库远不止是一个简单的代码合集,它更…...

基于React+TypeScript+Tailwind的ChatGPT应用UI模板开发指南
1. 项目概述:一个为ChatGPT应用量身定制的UI模板如果你正在开发一个基于ChatGPT或类似大语言模型的Web应用,无论是客服机器人、智能写作助手,还是企业内部的知识问答工具,那么你大概率会遇到一个绕不开的难题:如何快速…...

Quality Guardian MCP:为AI编程助手设计的实时代码质量聚合与基线管理工具
1. 项目概述:为AI编程助手打造的代码质量守门员如果你和我一样,日常重度依赖 Claude Code、Cursor 这类 AI 编程助手来写代码,那你肯定也遇到过这个头疼的问题:AI 助手确实能快速生成代码,但它对项目里已有的“技术债”…...

微博数据接口解决方案:Python爬虫工程实践与反爬策略
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫longlannet/weibo。乍一看,这像是一个与微博相关的代码仓库,但它的价值远不止于一个简单的爬虫或客户端。作为一个在数据工程和自动化领域摸爬滚打多年的从业者,我深知在当今…...