详解 Flink 的常见部署方式
一、常见部署模式分类
1. 按是否依赖外部资源调度
1.1 Standalone 模式
独立模式 (Standalone) 是独立运行的,不依赖任何外部的资源管理平台,只需要运行所有 Flink 组件服务
1.2 Yarn 模式
Yarn 模式是指客户端把 Flink 应用提交给 Yarn 的 ResourceManager, Yarn 的 ResourceManager 会在 Yarn 的 NodeManager 上创建容器。在这些容器上,Flink 会部署 JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源
2. 按集群的生命周期和执行位置
2.1 会话模式
- 会话模式 (Session Mode) 是指先启动一个集群,保持一个会话并且确定所有的资源,然后向集群提交作业,所有提交的作业会竞争集群中的资源,从而会出现资源不足作业执行失败的情况
- 会话模式比较适合于单个规模小、执行时间短的大量作业
2.2 单作业模式
- 单作业模式 (Per-Job Mode) 是指为每一个提交的作业启动一个集群,由客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。
- 单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式
- 单作业模式一般需要借助一些资源管理框架来启动集群,比如 YARN、Kubernetes
2.3 应用模式
- 应用模式 (Application Mode) 是指为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了。这一模式下没有客户端的存在
- 应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交作业的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应用程序的,并且即使应用包含了多个作业,也只创建一个集群
二、常见部署模式组合
- Standalone + 会话模式
- Standalone + 应用模式
- Yarn + 会话模式
- Yarn + 单作业模式
- Yarn + 应用模式
三、独立模式安装
1. 单节点安装
-
flink 下载地址:https://flink.apache.org/downloads/
-
下载 flink 安装包:
flink-1.10.1-bin-scala_2.12.tgz -
将安装包上传到虚拟机节点并解压缩
tar -zxvf flink-1.10.1-bin-scala_2.12.tgz -C /opt/module cd /opt/module mv flink-1.10.1 flink -
进入 flink 安装目录,执行启动命令,并查看进程
cd /opt/module/flink bin/start-cluster.shjps -
访问 http://hadoop102:8081 进入 flink 集群和任务监控管理 Web 页面
-
关闭 flink:
bin/stop-cluster.sh
2. 集群安装
2.1 集群规划
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | JobManager | TaskManager | TaskManager |
2.2 步骤
-
下载 flink 安装包:
flink-1.10.1-bin-scala_2.12.tgz -
将安装包上传到 hadoop102 并解压缩
tar -zxvf flink-1.10.1-bin-scala_2.12.tgz -C /opt/module cd /opt/module mv flink-1.10.1 flink -
进入 flink 安装目录下的 conf 目录,修改配置文件
flink-conf.yamlcd /opt/module/flink/conf vim flink-conf.yaml#修改 jobmanager 内部通信主机名 jobmanager.rpc.address: hadoop102 jobmanager.rpc.port: 6123 -
修改 conf 目录下的 slaves 文件,配置 taskmanager 节点
vim slaves #1.13版本为 workers 文件 #添加内容 hadoop103 hadoop104 -
flink-conf.yaml文件中常用配置项:#对 JobManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整 jobmanager.memory.process.size: 1600#对 TaskManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整 taskmanager.memory.process.size: 1600#对每个 TaskManager 能够分配的 TaskSlot 数量进行配置,默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源 taskmanager.numberOfTaskSlots: 1#Flink 任务执行的默认并行度,优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量 parallelism.default: 1 -
分发 flink 安装目录到 hadoop103 和 hadoop104
-
在 hadoop102 上启动 flink 集群
cd /opt/module/flink bin/start-cluster.shjps -
访问
http://hadoop102:8081查看 flink 监控页面
3. 提交任务
3.1 会话模式提交
-
启动 Flink 集群服务
-
在 hadoop102 中启动 netcat 网络端口
nc -lk 7777 -
Web 页面提交
- 将编码好的 Flink maven 工程打成 jar 包
- 访问
http://hadoop102:8081进入 flink 监控页面,选择左侧的Submit New Job选项菜单 - 点击
+Add New按钮,然后选择 jar 包进行上传 - 点击页面上上传好的 jar 包项,配置填写主程序类全类名、启动参数项、并行度等;点击
submit提交任务 - 在页面左侧的
overview和jobs等菜单选项下查看任务运行情况 - 一个 job 所占据的 TaskSlots 数等于该 job 中最大的并行度
-
命令行提交
#提交任务:bin/flink run -m [jobmanager主机和端口] -c [主程序类全类名] -p [并行度] [jar包的绝对路径] [--param1 value1 --param2 value2 ...] cd flink bin/flink run -m hadoop102:8081 -c com.app.wc.StreamWordCount2 -p 3 /project/FlinkTutorial/target/FlinkTutorial-1.0-SNAPSHOT.jar --host localhost --port 7777#查看job:-a 可以查看已经取消的job bin/flink list [-a]#取消job bin/flink cancel [jobId]
3.2 应用模式提交
-
不能使用
start-cluster.sh命令启动集群 -
将编码好的 Flink maven 工程打成 jar 包,并将 jar 包上传到 flink 安装目录下的 lib 目录
-
启动 JobManager
cd /opt/module/flink bin/standalone-job.sh start --job-classname com.app.wc.StreamWordCount2 -
启动 TaskManager
cd /opt/module/flink bin/taskmanager.sh start -
访问
http://hadoop102:8081查看 flink 监控页面的作业执行 -
关闭
cd /opt/module/flink bin/standalone-job.sh stop bin/taskmanager.sh stop
4. 高可用集群安装
4.1 集群规划
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | JobManager | JobManager / TaskManager | TaskManager |
4.2 步骤
-
在 hadoop102 上进入 flink 目录下的 conf 目录,修改
flink-conf.yaml文件cd /opt/module/flink/conf vim flink-conf.yaml#添加内容 high-availability: zookeeper high-availability.storageDir: hdfs://hadoop102:9820/flink/standalone/ha high-availability.zookeeper.quorum: hadoop102:2181,hadoop103:2181,hadoop104:2181 high-availability.zookeeper.path.root: /flink-standalone high-availability.cluster-id: /cluster_atguigu -
修改 masters 文件
vim masters #添加 hadoop102:8081 hadoop103:8081 -
分发配置到其他节点
-
启动
#保证hadoop环境变量配置生效 #启动 hadoop 集群和 Zookeeper 集群 #启动 flink 集群 cd /opt/module/flink bin/start-cluster.sh -
访问:
http://hadoop102:8081和http://hadoop103:8081
四、Yarn 模式安装
1. 安装步骤
-
下载安装包:
- flink 1.8 版本之前可以直接下载基于 hadoop 版本编译的安装包
- flink 1.8 及之后的版本除了下载基本的安装包之外,还需要下载 Hadoop 相关版本的组件,如
flink-shaded-hadoop-2-uber-2.7.5-10.0.jar,并将该组件上传至 Flink 的 lib 目录下 - flink 1.11 版本之后,不再提供
flink-shaded-hadoop-*的 jar 包,而是通过配置环境变量完成与 Yarn 集群的对接
-
将安装包上传到虚拟机并解压缩
tar -zxvf flink-1.10.1-bin-scala_2.12.tgz -C /opt/module cd /opt/module mv flink-1.10.1 flink -
进入 conf 目录,修改
flink-conf.yaml文件cd /opt/module/flink/conf vim flink-conf.yaml#修改 jobmanager.memory.process.size: 1600m taskmanager.memory.process.size: 1728m taskmanager.numberOfTaskSlots: 8 parallelism.default: 1 -
确保正确安装 Hadoop 集群和配置 Hadoop 环境变量
sudo vim /etc/profile.d/my_env.shexport HADOOP_HOME=/opt/module/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_CLASSPATH=`hadoop classpath`
2. 提交任务
2.1 会话模式提交
-
启动 Hadoop 集群
-
执行脚本命令向 Yarn 集群申请资源,开启一个 Yarn 会话,启动 Flink 集群
cd /opt/module/flink bin/yarn-session.sh -nm test#-n 参数:指定 TaskManager 数量 #-s 参数:指定 slot 数量 #-d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session 也可以后台运行。 #-jm(--jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。 #-nm(--name):配置在 YARN UI 界面上显示的任务名。 #-qu(--queue):指定 YARN 队列名。 #-tm(--taskManager):配置每个 TaskManager 所使用内存 -
提交作业
-
Web UI 提交,同独立模式
-
命令行提交:
#1.将打包好的任务运行 JAR 包上传至集群 #2.执行命令 cd /opt/module/flink bin/flink run -c com.app.wc.StreamWordCount2 FlinkTutorial-1.0-SNAPSHOT.jar
-
-
访问 yarn Web UI 界面或 flink Web UI 界面查看作业执行情况
2.2 单作业模式提交
-
启动 Hadoop 集群
-
直接向 Yarn 提交一个单独的作业,从而启动一个 Flink 集群
cd /opt/module/flink #命令一: bin/flink run -d -t yarn-per-job -c com.app.wc.StreamWordCount2 FlinkTutorial-1.0-SNAPSHOT.jar#命令二: bin/flink run -m yarn-cluster -c com.app.wc.StreamWordCount2 FlinkTutorial-1.0-SNAPSHOT.jar -
访问 yarn Web UI 界面或 flink Web UI 界面查看作业执行情况
-
取消作业:
cd /opt/module/flink bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
2.3 应用模式提交
-
启动 Hadoop 集群
-
执行命令提交作业
#上传 jar 包到集群 cd /opt/module/flink bin/flink run-application -t yarn-application -c com.app.wc.StreamWordCount2 FlinkTutorial-1.0-SNAPSHOT.jar#上传 jar 包到 hdfs bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" hdfs://myhdfs/jars/my-application.jar -
查看或取消作业
/opt/module/flink bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
3. 高可用配置
YARN 的高可用是只启动一个 Jobmanager, 当这个 Jobmanager 挂了之后, YARN 会再次启动一个, 本质是利用的 YARN 的重试次数来实现的高可用
-
在
yarn-site.xml中配置<property><name>yarn.resourcemanager.am.max-attempts</name><value>4</value><description>The maximum number of application master execution attempts.</description> </property> -
分发配置到其他节点
-
在
flink-conf.yaml中配置yarn.application-attempts: 3 #要小于 yarn 的重试次数 high-availability: zookeeper high-availability.storageDir: hdfs://hadoop102:9820/flink/yarn/ha high-availability.zookeeper.quorum: hadoop102:2181,hadoop103:2181,hadoop104:2181 high-availability.zookeeper.path.root: /flink-yarn -
启动 yarn-session,杀死 JobManager, 查看复活情况
相关文章:

详解 Flink 的常见部署方式
一、常见部署模式分类 1. 按是否依赖外部资源调度 1.1 Standalone 模式 独立模式 (Standalone) 是独立运行的,不依赖任何外部的资源管理平台,只需要运行所有 Flink 组件服务 1.2 Yarn 模式 Yarn 模式是指客户端把 Flink 应用提交给 Yarn 的 ResourceMa…...

【UE5.1 角色练习】11-坐骑——Part1(控制大象移动)
前言 在上一篇(【UE5.1 角色练习】10-物体抬升、抛出技能 - part2)基础上创建一个新的大象坐骑角色,并实现控制该角色行走的功能。 效果 步骤 1. 在商城中下载“African Animal Pack”资产和“ANIMAL VARIETY PACK”资产导入工程中 2. 复…...

数据结构严蔚敏版精简版-线性表以及c语言代码实现
线性表、栈、队列、串和数组都属于线性结构。线性结构的基本特点是除第一个元素无直接前驱,最后一个元素无直接后继之外,其他每个数据元素都有一个前驱和后继。 1 线性表的定义和特点 如此类由n(n大于等于0)个数据特性相同的元素…...

【react】react项目支持鼠标拖拽的边框改变元素宽度的组件
目录 安装使用方法示例Props 属性方法示例代码调整兄弟div的宽度 re-resizable github地址 安装 $ npm install --save re-resizable这将安装re-resizable库并将其保存为项目的依赖项。 使用方法 re-resizable 提供了一个 <Resizable> 组件,它可以包裹任何…...
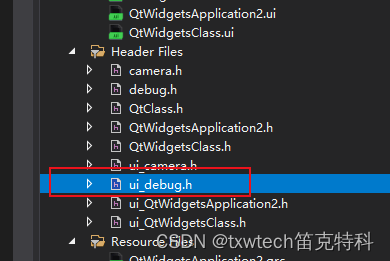
QT 创建文件 Ui 不允许使用不完整类型,可以尝试添加一下任何头文件
#include "debug.h" #include "qmessagebox.h" #pragma execution_character_set("utf-8") //QT 创建文件 Ui 不允许使用不完整类型,尝试添加一下任何头文件,或者添加ui_xx.h头文件 debug::debug(QWidget *parent) : QDialog(p…...

Python:深入探索其生态系统与应用领域
Python:深入探索其生态系统与应用领域 Python,作为一种广泛应用的编程语言,其生态系统之丰富、应用领域之广泛,常常令人叹为观止。那么,Python究竟涉及哪些系统?本文将从四个方面、五个方面、六个方面和七…...
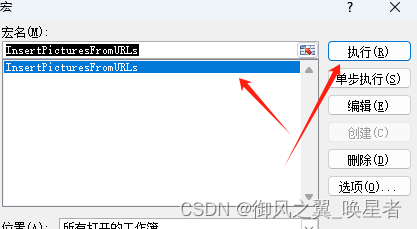
EXCEL从图片链接获取图片
step1: 选中图片地址列 step2:开发工具→Visual Basic 文件→导入 导入我制作的脚本(代码见文章末尾) 点击excel的小图标回到表格界面。 点击【宏】 选中刚才导入的脚本,点执行,等待完成。 代码本体: Sub InsertPict…...
)
Docker迁移默认存储目录(GPT-4o)
Docker在Ubuntu的默认存储目录是/var/lib/docker,要将 Docker 的默认存储目录迁移到指定目录(譬如大存储磁盘),可以通过修改 Docker 守护进程的配置文件来实现。 1.创建新的存储目录: 选择你想要存储 Docker 分层存储…...
植物大战僵尸杂交版2.0.88最新版安装包
游戏简介 游戏中独特的杂交植物更是为游戏增添了不少亮点。这些杂交植物不仅外观独特,而且拥有更强大的能力,能够帮助玩家更好地应对游戏中的挑战。玩家可以通过一定的条件和方式,解锁并培养这些杂交植物,从而不断提升自己的战斗…...
)
MQ基础(RabbitMQ)
通信 同步通信:就相当于打电话,双方交互是实时的。同一时刻,只能与一人交互。 异步通信:就相当于发短信,双方交互不是实时的。不需要立刻回应对方,可以多线程操作,跟不同人同时聊天。 RabbitM…...
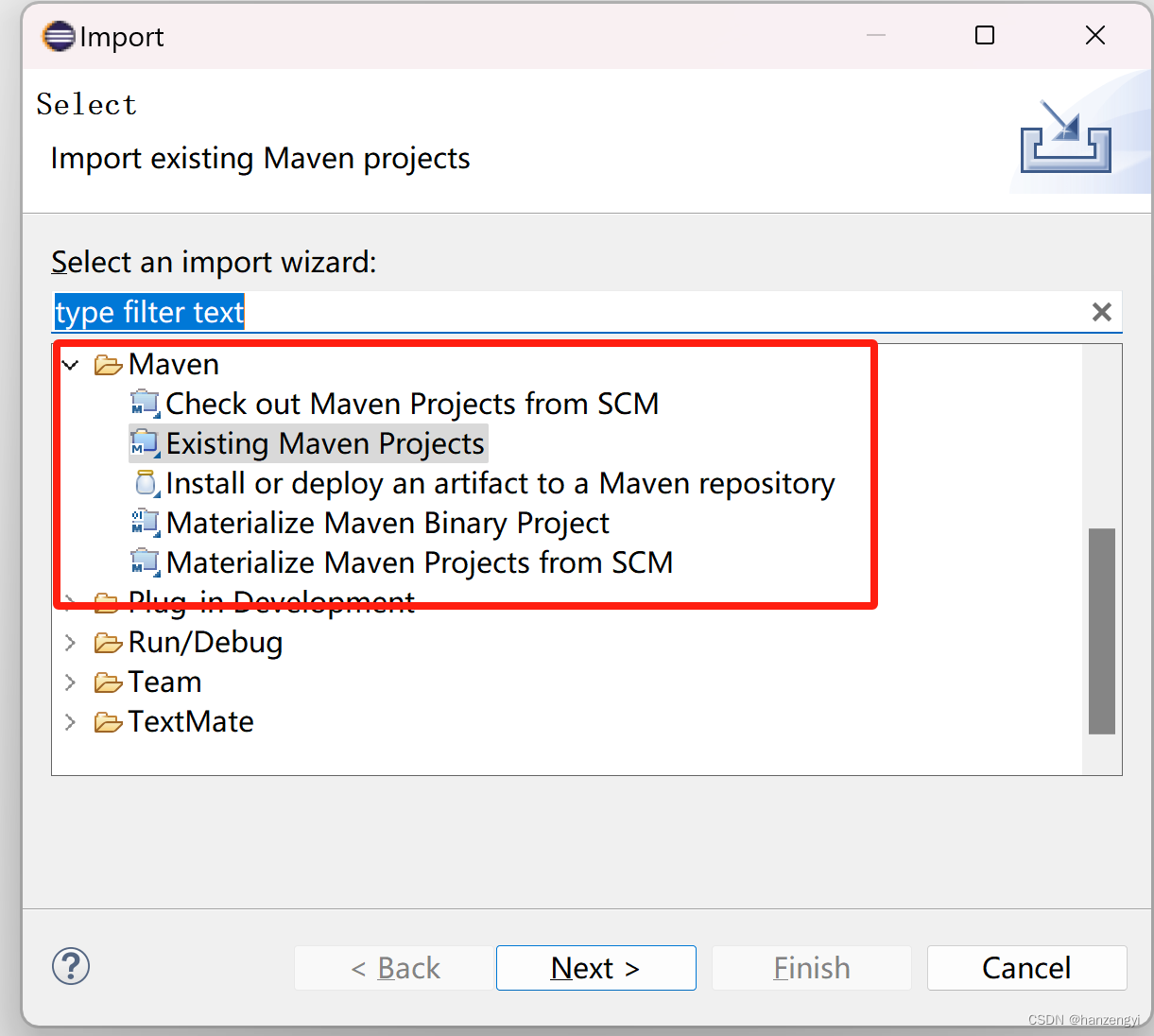
eclipse添加maven插件
打开eclipse菜单 Help/Install New SoftwareWork with下拉菜单选择 2022-03 - https://download.eclipse.org/releases/2022-03‘type filter text’搜索框中输入 maven选择 M2E - Maven Integration for Eclipse一路next安装,重启eclipseImport项目时,就…...

知识库系统:从认识到搭建
在这个信息过载的时代,企业越来越需要一个集中的知识库系统来促进员工协作和解决问题。本文跟着LookLook同学一起来探讨搭建高效知识库系统的所有注意事项和知识库系统的最佳推荐。 | 什么是知识库系统 知识库系统是一种软件或工具,旨在填补组织内的知识…...

JVM双亲委派模型
在之前的JVM类加载器篇中说过,各个类加载器都有自己加载的范围,比如引导类加载器只加载Java核心库中的class如String,那如果用户自己建一个包名和类名与String相同的类,会不会被引导类加载器加载。可以通过如下代码测试࿰…...

Python语言与算法:深度探索与实战应用
Python语言与算法:深度探索与实战应用 在数字化浪潮汹涌的时代,Python语言以其简洁、易读和强大的功能库成为了编程界的翘楚。而算法,作为计算机科学的核心,是解决问题、优化性能的关键。本文将围绕Python语言与算法的结合&#…...

Python实现连连看7
3.3 根据地图显示图片 在获取了图片地图之后,就可以根据该图片地图显示图片了。显示图片的功能在自定义函数drawMap()中实现。 3.3.1 清除画布中的内容 在画布上显示图片之前,需要将画布中图1的启动界面内容清除,代码如下所示。 canvas.delete(all) 其中,delete()方法…...

C#中的as和is
在 C# 中,as 和 is 是用于类型转换和类型检查的操作符。 as 操作符: as 操作符用于尝试将一个对象转换为指定的引用类型或可空类型,如果转换失败,将返回 null。语法:expression as type示例: object obj &…...

示波器眼图怎么看
目录 什么是眼图? 怎么看? 眼图的电压幅度(Y轴) 眼睛幅度和高度 信噪比 抖动 上升时间和下降时间 眼宽 什么是眼图? 眼图(Eye Diagram)是一种用于分析高速数字信号传输质量的重要工具。通…...
Visual Studio Code编辑STM32CubeMX已生成的文件
在这里插入图片描述...

【读脑仪game】
读脑仪(Brain-Computer Interface,BCI)游戏是一种利用脑电信号来控制游戏的新型交互方式。这类游戏通常需要专业的硬件设备来读取用户的脑电信号,并将这些信号转化为游戏中的控制信号。编写这样的游戏代码涉及到多个方面ÿ…...

基于STM32的毕业设计示例
**基于STM32的毕业设计示例** 一、引言 在当前的电子工程领域,STM32微控制器因其高性能、低功耗和丰富的外设接口而备受青睐。本次毕业设计旨在展示基于STM32微控制器的系统设计与实现能力,通过构建一个具有实际应用价值的系统,体现对嵌入式…...

春秋云境CVE-2018-12613
1.阅读靶场介绍index.php中存在一处文件包含逻辑可以理解为对url做处理能想到的就是../../../../../flag2.启动靶场如上图所示看到这个界面我想到的就是select flag from flag出来但是本博主没有找到哟期待各位大神的评论3.poc这里博主是通过这个处理过的url夺旗的如下所示url在…...

面向对象AI启示下的软件设计新范式
当物理世界成为对象网络,我们的软件架构该如何进化? 核心理念:软件作为“对象生态”的模拟器 从面向对象AI的启示中,我们得到的核心洞见是:优秀的软件应该像智能体理解物理世界一样,理解自己的问题域。这意味着软件不再仅仅是数据处理管道,而是一个动态的、对象化的生态…...

Baichuan-7B代码生成能力:编程助手的最佳选择 - 7B参数大模型的终极指南
Baichuan-7B代码生成能力:编程助手的最佳选择 - 7B参数大模型的终极指南 【免费下载链接】Baichuan-7B A large-scale 7B pretraining language model developed by BaiChuan-Inc. 项目地址: https://gitcode.com/gh_mirrors/ba/Baichuan-7B Baichuan-7B是由…...

Webpacker终极集成指南:如何与React、Vue、TypeScript完美协作
Webpacker终极集成指南:如何与React、Vue、TypeScript完美协作 【免费下载链接】webpacker Use Webpack to manage app-like JavaScript modules in Rails 项目地址: https://gitcode.com/gh_mirrors/we/webpacker Webpacker是Rails生态系统中一个革命性的工…...

Vue甘特图实战:从零构建高效项目管理视图
1. 为什么选择VueECharts实现甘特图 在项目管理工具中,甘特图是最直观的任务排期展示方式。传统方案往往需要引入复杂的第三方库,而VueECharts的组合却能以最小成本实现专业效果。我去年负责一个电商大促项目时,就用这个方案替代了原本采购的…...

告别重复造轮子:用快马一键生成qoderwork官网开发骨架,效率倍增
作为一个经常需要搭建官网的前端开发者,我深刻理解那种面对空白项目时的无力感。每次新建项目,光是搭建基础框架、配置路由、设计布局就要花掉大半天时间。最近尝试用InsCode(快马)平台生成qoderwork官网的骨架代码,效率提升简直惊人。 为什么…...

突破传统切片限制:Excel驱动的GCode设计革命
突破传统切片限制:Excel驱动的GCode设计革命 【免费下载链接】FullControl-GCode-Designer Software for designing GCODE for 3D printing 项目地址: https://gitcode.com/gh_mirrors/fu/FullControl-GCode-Designer 在3D打印领域,GCode设计和参…...

提升Adobe Illustrator开发效率的自动化脚本工具集
提升Adobe Illustrator开发效率的自动化脚本工具集 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在设计开发流程中,重复性操作、多文件管理和格式标准化往往消耗大量时…...

Aimmy:重新定义游戏公平性,AI技术为视障玩家打造的智能瞄准革命
Aimmy:重新定义游戏公平性,AI技术为视障玩家打造的智能瞄准革命 【免费下载链接】Aimmy Universal Second Eye for Gamers with Impairments (Universal AI Aim Aligner (AI Aimbot) - ONNX/YOLOv8 - C#) 项目地址: https://gitcode.com/gh_mirrors/ai…...

2026网站制作公司到底哪家好?国内主流PC网站建设服务公司排名
2026年1月,最新修订的《网络安全法》正式施行,叠加《网络数据安全管理条例》《个人信息保护法》细则落地,数据合规已成为网站建设的前置准入门槛。据中国互联网协会数据显示,2025年国内中大型企业官网合规整改率仅41.7%࿰…...