TensorBoard在pytorch训练过程中如何使用,及数据读取问题解决方法
TensorBoard
- 模块导入
- 日志记录文件的创建
- 训练中如何写入数据
- 如何提取保存的数据调用TensorBoard面板
- 可能会遇到的问题
模块导入
首先从torch中导入tensorboard的SummaryWriter日志记录模块
from torch.utils.tensorboard import SummaryWriter
然后导入要用到的os库,当然你们也要导入自己模型训练需要用到的库
import os
日志记录文件的创建
import oslog_dir = 'runs/EfficientNet_B3_experiment2'# 检查目录是否存在
if os.path.exists(log_dir):# 如果目录存在,获取目录下的所有文件和子目录列表files = os.listdir(log_dir)# 遍历目录下的文件和子目录for file in files:# 拼接文件的完整路径file_path = os.path.join(log_dir, file)# 判断是否为文件if os.path.isfile(file_path):# 如果是文件,删除该文件os.remove(file_path)elif os.path.isdir(file_path):# 如果是目录,递归地删除目录及其下的所有文件和子目录for root, dirs, files in os.walk(file_path, topdown=False):for name in files:os.remove(os.path.join(root, name))for name in dirs:os.rmdir(os.path.join(root, name))os.rmdir(file_path)# 创建新的SummaryWriter
writer = SummaryWriter(log_dir)
这个代码会自动创建并更新日志文件目录,请谨慎使用,记得改
log_dir = 'runs/EfficientNet_B3_experiment2'路径名字小心把之前保存好的数据删除了
之后模型训练的数据将会写入到log_dir这个路径文件中,在由TensorBoard张量板调用显示数据
训练中如何写入数据
for epoch in range(num_epochs):model.train()running_loss = 0.0correct = 0total = 0start_time = time.time()for images, labels in train_loader:images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 记录学习率current_lr = optimizer.param_groups[0]['lr']writer.add_scalar('Learning Rate', current_lr, epoch)# 记录梯度范数total_norm = 0for p in model.parameters():param_norm = p.grad.data.norm(2)total_norm += param_norm.item() ** 2total_norm = total_norm ** 0.5writer.add_scalar('Gradient Norm', total_norm, epoch)running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()train_loss = running_loss / len(train_loader)train_accuracy = 100 * correct / total# 记录训练损失和准确率writer.add_scalar('Training Loss', train_loss, epoch)writer.add_scalar('Training Accuracy', train_accuracy, epoch)# 记录模型参数的直方图for name, param in model.named_parameters():writer.add_histogram(name, param, epoch)# 记录网络结构(通常只需要记录一次)if epoch == 0:writer.add_graph(model, images.to(device))# 记录输入图片img_grid = torchvision.utils.make_grid(images)writer.add_image('train_images', img_grid, epoch)# 使用matplotlib记录渲染的图片fig, ax = plt.subplots()ax.plot(np.arange(len(labels)), labels.cpu().numpy(), 'b', label='True')ax.plot(np.arange(len(predicted)), predicted.cpu().numpy(), 'r', label='Predicted')ax.legend()writer.add_figure('predictions vs. actuals', fig, epoch)# 验证模型model.eval()val_loss = 0.0correct = 0total = 0all_preds = []all_labels = []with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)loss = criterion(outputs, labels)val_loss += loss.item()_, predicted = torch.max(outputs.data, 1)all_preds.extend(predicted.cpu().numpy())all_labels.extend(labels.cpu().numpy())total += labels.size(0)correct += (predicted == labels).sum().item()val_loss /= len(test_loader)val_accuracy = 100 * correct / totalif val_accuracy > best_val_accuracy:# 当新的最佳验证准确率出现时,保存模型状态字典best_val_accuracy = val_accuracybest_model_state_dict = model.state_dict()# 记录验证损失和准确率writer.add_scalar('Validation Loss', val_loss, epoch)writer.add_scalar('Validation Accuracy', val_accuracy, epoch)# 记录多条曲线writer.add_scalars('Loss', {'train': train_loss, 'val': val_loss}, epoch)writer.add_scalars('Accuracy', {'train': train_accuracy, 'val': val_accuracy}, epoch)# 打印每个epoch的训练和验证结果print(f'Epoch [{epoch+1}/{num_epochs}], 'f'Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.2f}%, 'f'Validation Loss: {val_loss:.4f}, Validation Accuracy: {val_accuracy:.2f}%, 'f'Time: {time.time() - start_time:.2f}s')
以上代码分别记录了

如何提取保存的数据调用TensorBoard面板
在终端输入以下代码
tensorboard --logdir='修改为自己的log_dir路径'
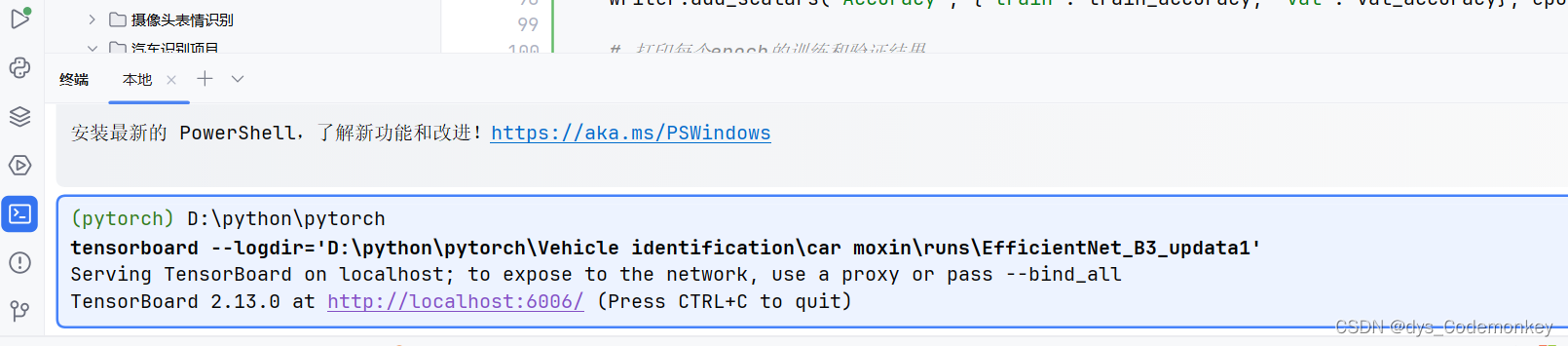
然后点击 http://localhost:6006/就可以成功加载面板了
可能会遇到的问题
如果数据读取失败那么请检查数据路径是否正确
注意数据文件中不能有任何中文
相关文章:
TensorBoard在pytorch训练过程中如何使用,及数据读取问题解决方法
TensorBoard 模块导入日志记录文件的创建训练中如何写入数据如何提取保存的数据调用TensorBoard面板可能会遇到的问题 模块导入 首先从torch中导入tensorboard的SummaryWriter日志记录模块 from torch.utils.tensorboard import SummaryWriter然后导入要用到的os库࿰…...

【Vue】普通组件的注册使用-全局注册
文章目录 一、使用步骤二、练习 一、使用步骤 步骤 创建.vue组件(三个组成部分)main.js中进行全局注册 使用方式 当成HTML标签直接使用 <组件名></组件名> 注意 组件名规范 —> 大驼峰命名法, 如 HmHeader 技巧…...
爬虫之反爬思路与解决手段
阅读时间建议:4分钟 本篇概念比较多,嗯。。 0x01 反爬思路与解决手段 1、服务器反爬虫的原因 因为爬虫的访问次数高,浪费资源,公司资源被批量抓走,丧失竞争力,同时也是法律的灰色地带。 2、服务器反什么…...
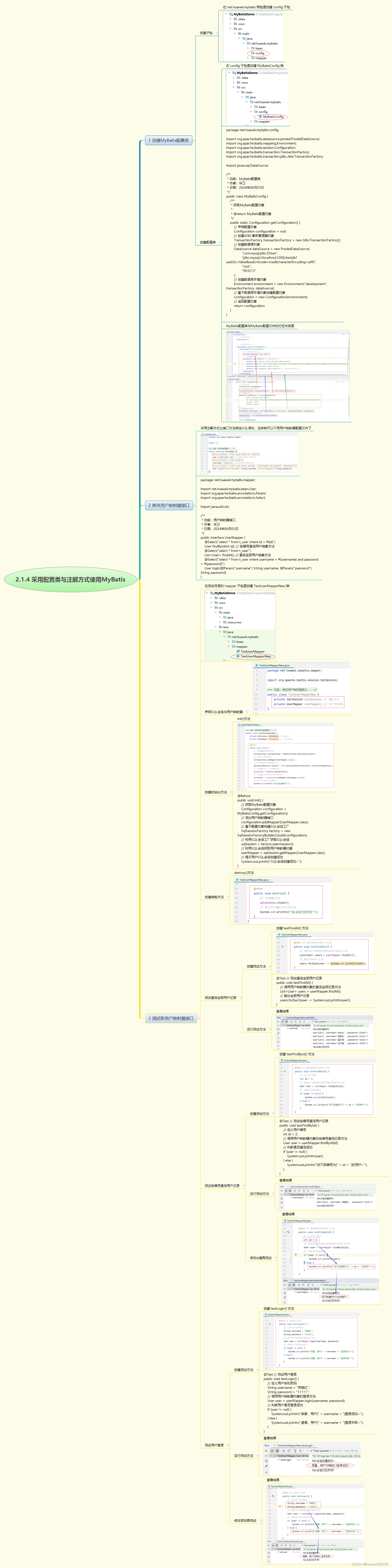
2.1.4 采用配置类与注解方式使用MyBatis
实战概述:采用配置类与注解方式使用MyBatis 创建MyBatis配置类 在net.huawei.mybatis.config包中创建MyBatisConfig类,用于配置MyBatis核心组件,包括数据源、事务工厂和环境设置。 配置数据源和事务 使用PooledDataSource配置MySQL数据库连接…...
微信小程序云开发实现利用云函数将数据库表的数据导出到excel中
实现目标 将所有订单信息导出到excel表格中 思路 1、在页面中bindtap绑定一个导出点击事件daochu() 2、先获取所有订单信息,并将数据添加到List数组中 3、传入以List数组作为参数,调用get_excel云函数 4、get_excel云函数利用node-xlsx第三方库&#…...

python 字符串(str)、列表(list)、元组(tuple)、字典(dict)
学习目标: 1:能够知道如何定义一个字符串; [重点] 使用双引号引起来: 变量名 "xxxx" 2:能够知道切片的语法格式; [重点] [起始: 结束] 3:掌握如何定义一个列表; [重点] 使用[ ]引起来: 变量名 [xx,xx,...] 4:能够说出4个列表相关的方法; [了解] ap…...

【源码】SpringBoot事务注册原理
前言 对于数据库的操作,可能存在脏读、不可重复读、幻读等问题,从而引入了事务的概念。 事务 1.1 事务的定义 事务是指在数据库管理系统中,一系列紧密相关的操作序列,这些操作作为一个单一的工作单元执行。事务的特点是要么全…...

技巧:合并ZIP分卷压缩包
如果ZIP压缩文件文件体积过大,大家可能会选择“分卷压缩”来压缩ZIP文件,那么,如何合并zip分卷压缩包呢?今天我们分享两个ZIP分卷压缩包合并的方法给大家。 方法一: 我们可以将分卷压缩包,通过解压的方式…...
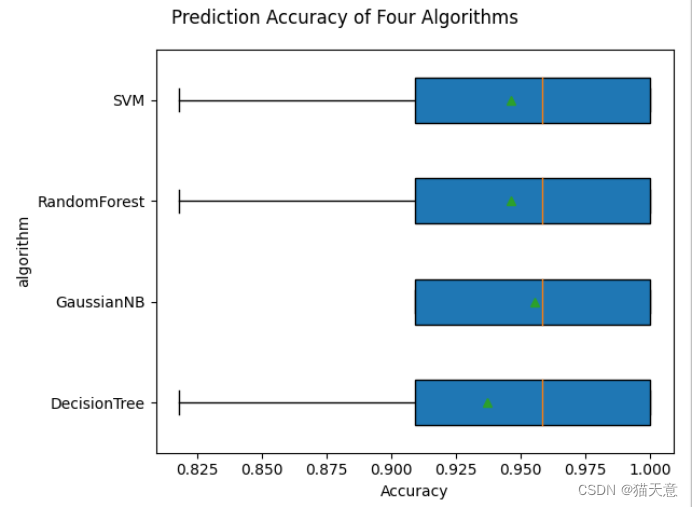
数据挖掘 | 实验三 决策树分类算法
文章目录 一、目的与要求二、实验设备与环境、数据三、实验内容四、实验小结 一、目的与要求 1)熟悉决策树的原理; 2)熟练使用sklearn库中相关决策树分类算法、预测方法; 3)熟悉pydotplus、 GraphViz等库中决策树模型…...

Python机器学习预测区间估计工具库之mapie使用详解
概要 在数据科学和机器学习领域,预测的不确定性估计是一个非常重要的课题。Python的mapie库是一种专注于预测区间估计的工具,旨在提供简单易用的接口来计算和评估预测的不确定性。通过mapie库,用户可以为各种回归和分类模型计算预测区间,从而更好地理解模型预测的可靠性。…...

Linux基础指令磁盘管理002
LVM(Logical Volume Manager)是Linux系统中一种灵活的磁盘管理和存储解决方案,它允许用户在物理卷(Physical Volumes, PV)上创建卷组(Volume Groups, VG),然后在卷组上创建逻辑卷&am…...

Python怎么添加库:深入解析与操作指南
Python怎么添加库:深入解析与操作指南 在Python编程中,库(Library)扮演着至关重要的角色。它们为我们提供了大量的函数、类和模块,使得我们可以更高效地编写代码,实现各种功能。那么,Python如何…...

Python | 虚拟环境的增删改查
mkvirtualenv创建虚拟环境 mkvirtualenv是用于在Pyhon中创建虚拟环境的命令。它通过使用vitualenv库来创建一个隔离的Python环境,以便您可以安装特定版本的Python包,而不会影响全局Python环境。 使用方法: 安装virtualenv:pip install vir…...

【MySQL数据库】:MySQL内外连接
目录 内外连接和多表查询的区别 内连接 外连接 左外连接 右外连接 简单案例 内外连接和多表查询的区别 在 MySQL 中,内连接是多表查询的一种方式,但多表查询包含的范围更广泛。外连接也是多表查询的一种具体形式,而多表查询是一个更…...

C# FTP/SFTP 详解及连接 FTP/SFTP 方式示例汇总
文章目录 1、FTP/SFTP基础知识FTPSFTP 2、FTP连接示例3、SFTP连接示例4、总结 在软件开发中,文件传输是一个常见的需求。尤其是在不同的服务器之间传输文件时,FTP(文件传输协议)和SFTP(安全文件传输协议)成…...

二、【源码】实现映射器的注册和使用
源码地址:https://github.com/mybatis/mybatis-3/ 仓库地址:https://gitcode.net/qq_42665745/mybatis/-/tree/02-auto-registry-proxy 实现映射器的注册和使用 这一节的目的主要是实现自动注册映射器工厂 流程: 1.创建MapperRegistry注册…...
Android Compose 十:常用组件列表 监听
1 去掉超出滑动区域时的拖拽的阴影 即 overScrollMode 代码如下 CompositionLocalProvider(LocalOverscrollConfiguration provides null) {LazyColumn() {items(list, key {list.indexOf(it)}){Row(Modifier.animateItemPlacement(tween(durationMillis 250))) {Text(text…...
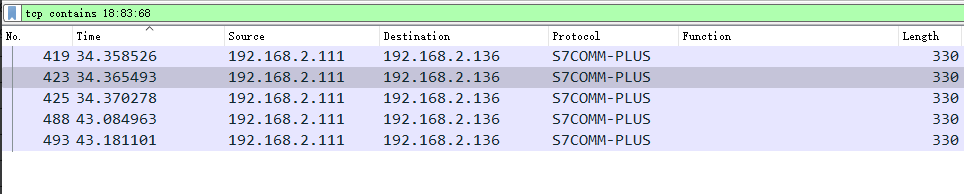
Wireshark 如何查找包含特定数据的数据帧
1、查找包含特定 string 的数据帧 使用如下指令: 双引号中所要查找的字符串 frame contains "xxx" 查找字符串 “heartbeat” 示例: 2、查找包含特定16进制的数据帧 使用如下指令: TCP:在TCP流中查找 tcp contai…...
【深度学习入门篇一】阿里云服务器(不需要配环境直接上手跟学代码)
前言 博主刚刚开始学深度学习,配环境配的心力交瘁,一塌糊涂,不想配环境的刚入门的同伴们可以直接选择阿里云服务器 阿里云天池实验室,在入门阶段跑个小项目完全没有问题,不要自己傻傻的在那配环境配了半天还不匹配&a…...

app,waf笔记
API攻防 知识点: 1、HTTP接口类-测评 2、RPC类接口-测评 3、Web Service类-测评 内容点: SOAP(Simple Object Access Protocol)简单对象访问协议是交换数据的一种协议规范,是一种轻量级的、简单的、基于XML&#…...

专业游戏界面增强:HunterPie如何提升Monster Hunter: World的狩猎体验
专业游戏界面增强:HunterPie如何提升Monster Hunter: World的狩猎体验 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/…...

专业解决方案:Windows 11 LTSC系统一键安装微软商店完整指南
专业解决方案:Windows 11 LTSC系统一键安装微软商店完整指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows 11 LTSC系统以其卓越…...

Janus-Pro-7B代码实例:Python调用app.py实现图文双向交互
Janus-Pro-7B代码实例:Python调用app.py实现图文双向交互 1. 项目概述 Janus-Pro-7B是一个强大的统一多模态AI模型,能够同时处理图像理解和文本生成图像任务。这个模型特别适合需要图文双向交互的应用场景,比如智能图片分析、创意内容生成、…...

intv_ai_mk11惊艳输出展示:中文一句话介绍、机器学习解释等基准测试
intv_ai_mk11惊艳输出展示:中文一句话介绍、机器学习解释等基准测试 1. 模型效果惊艳展示 intv_ai_mk11作为一款基于Llama架构的中等规模文本生成模型,在实际使用中展现出令人印象深刻的能力。让我们通过几个典型场景,直观感受它的生成效果…...

WebDataset压缩算法对比:GZIP、BZIP2与LZMA的性能分析
WebDataset压缩算法对比:GZIP、BZIP2与LZMA的性能分析 【免费下载链接】webdataset A high-performance Python-based I/O system for large (and small) deep learning problems, with strong support for PyTorch. 项目地址: https://gitcode.com/gh_mirrors/we…...

LFM2.5-1.2B-Thinking-GGUF惊艳效果:32K上下文下长文档关键信息抽取准确率实测
LFM2.5-1.2B-Thinking-GGUF惊艳效果:32K上下文下长文档关键信息抽取准确率实测 1. 模型效果实测背景 LFM2.5-1.2B-Thinking-GGUF作为Liquid AI推出的轻量级文本生成模型,在低资源环境下展现出令人惊喜的性能表现。本次测试聚焦于模型在32K超长上下文环…...

霜儿-汉服-造相Z-Turbo科研辅助:使用LaTeX撰写包含AI生成图像的学术论文
霜儿-汉服-造相Z-Turbo科研辅助:使用LaTeX撰写包含AI生成图像的学术论文 最近在帮一位研究传统服饰的朋友整理论文,遇到了一个挺有意思的问题。他们需要大量汉服的结构示意图和纹样分析图,但手绘耗时,找现成资料又很难完全匹配研…...

Apache NetBeans社区生态解析:如何参与贡献与获取支持
Apache NetBeans社区生态解析:如何参与贡献与获取支持 【免费下载链接】netbeans Apache NetBeans 项目地址: https://gitcode.com/gh_mirrors/ne/netbeans Apache NetBeans作为一个功能强大的开源IDE(集成开发环境),拥有一…...

Nunchaku FLUX.1-dev部署教程:Linux系统下CUDA驱动与PyTorch匹配指南
Nunchaku FLUX.1-dev部署教程:Linux系统下CUDA驱动与PyTorch匹配指南 想用最新的Nunchaku FLUX.1-dev模型生成惊艳的AI图片,结果卡在了环境配置上?别担心,这篇教程就是为你准备的。很多朋友在部署时遇到的最大障碍,往…...

Nature Microbiology|质粒驱动的抗菌素耐药性进化:插入序列介导的基因失活新机制
背景 抗菌素耐药性(AMR)是全球公共卫生面临的严峻挑战。细菌进化出耐药性的主要途径包括基因突变和通过水平基因转移(Horizontal Gene Transfer, HGT)获得外源耐药基因。在后者中,接合质粒扮演了核心角色,它…...