Ascend训练软件栈了解
一.分布式大模型训练的完整流程及注意事项
1. 迁移分析
- 模型选取与约束说明 : 确保模型能在GPU或CPU上运行并获取性能基线,了解不支持场景,如DP模式、APEX库、bmtrain框架等。
- 支持度分析 : 使用msFmkTransplt工具分析模型算子、三方库、亲和API和动态shape在昇腾平台上的支持情况。
- 算子开发与适配 : 如存在不支持算子,可使用等价算子替换或联系华为工程师开发适配。
2. 迁移适配
- 模型脚本迁移 : 推荐使用自动迁移,导入torch_npu库实现CUDA接口到NPU接口的替换。
- 模型训练适配 :
- 环境变量配置 : 配置CANN相关环境变量、LD_LIBRARY_PATH、HCCL_WHITELIST_DISABLE等。
- 启动脚本配置 :
- 单卡训练 : 直接运行训练脚本。
- 多卡分布式训练 :
- 单机多卡 : 将单卡脚本修改为多卡脚本,并使用shell脚本、mp.spawn、Python、torchrun或torch_npu_run等方式拉起训练。
- 多机多卡 : 准备多机环境,配置device IP、防火墙、交换机等,修改模型脚本,并使用shell脚本、torchrun或torch_npu_run等方式拉起训练。
- 关键特性适配 :
- 精度敏感特征值检测 : 开启NPU_ASD_ENABLE环境变量,配置NPU_ASD_UPPER_THRESH和NPU_ASD_SIGMA_THRESH,并进行故障处理。
- 混合精度适配(可选) : 使用PyTorch AMP模块,根据场景选择典型、梯度累加、多模型、损失函数和优化器、DDP场景等适配方法。
3. 精度调试
- 精度分析与调优 : 分析训练过程中的Loss、perplexity、梯度范数等指标,评估迁移前后精度差异,并使用精度问题分析工具排查问题。
- 数据集清洗 : 剔除非目标语言、低质量样本、重复数据等,并进行去重。
- 超参配置调优 : 调整Batch Size、学习率、梯度裁剪阈值、Loss scale等超参数。
- 混合精度配置选择 : 根据任务需求和硬件资源选择FP16或BF16,并进行Loss scale调整。
- 训练状态监控和恢复 : 使用TensorBoard或hook机制监控PPL、GNorm、内存占用等指标,并进行异常状态急救和恢复。
4. 性能调优
- 性能数据采集与评测 : 使用Ascend PyTorch Profiler、性能比对工具、集群分析工具和Ascend Insight等工具采集和分析性能数据。
- 模型性能优化实施 : 根据性能瓶颈模块的类型,从并行策略、IO优化、NPU亲和适配优化、内存优化、融合算子、融合优化器等方面进行优化。
注意事项 :
- 并行策略选择 : 根据模型大小、内存需求、算力资源等因素选择合适的并行策略,并进行线性度和micro batch size测试分析。
- IO优化 : 优化数据加载方式,如使用pin_memory、persistent_workers、预取数据、Infinite DataLoader、缓存数据等。
- NPU亲和适配优化 : 消除多余的stream同步、优化CPU侧代码、替换融合算子、使用融合优化器等。
- 内存优化 : 调整内存参数、使用多流复用、减小HCCL通信缓存、开启通信并行、使能FFTS、关闭Python GC等。
- 通信优化 : 配置HCCL_INTRA_ROCE_ENABLE、HCCL_RDMA_TC、HCCL_RDMA_SL、HCCL_BUFFSIZE等环境变量。
二.并行策略通用建议
- 并行策略的调试与设计需要对具体模型进行详细分析,没有一个通用的万能法则可以适用于所有情况。然而,借鉴以往的调优经验,我们可以总结出一些相对通用的建议。
- 在面临显存不足、模型过大无法完全加载以及需要进行切分的情况下,优先考虑使用TP (Tensor Parallelism)进行切分,并确保切分的数量小于等于机器内的计算卡数。例如,在一台服务器上有8张计算卡,那么TP的最大设置不应超过8。这样可以充分利用计算资源,减少显存占用。
- 如果在TP切分达到最大显存容量仍然不足的情况下,可以考虑在机器之间使用PP(Pipeline Parallelism)进行切分。理论上,PP的数量应该越小越好 ,以尽可能减少空闲计算资源的浪费。
- 在机器资源富裕的情况下,可以开启DP(Data Parallelism)并行,将计算任务分配给多个机器进行并行处理,从而提高处理效率。然而,在机器资源有限的情况下,如果开启TP+PP切分后显存仍然不足,可以考虑使用ZeRO1和重计算技术 。ZeRO1可以将模型优化器状态划分到更多的设备上,并通过集合通信进行同步。
- 同时,重计算技术可以通过选择性重计算来提高显存的使用率,从而提高模型训练效率。
- 此外,即使在模型能够成功运行的情况下,也可以尝试主动地使用降低内存占用的手段,例如ZeRO1和重计算等,然后增大Batch Size 。这样有时也会取得令人意外的效果。
- 综上所述,通过技术能力和合理选择并行策略,可以在资源有限的情况下优化模型训练效率,并充分利用计算资源。然而,对于具体的模型和环境,仍需要进行详细分析和实验,以找到最佳的并行策略和优化方法。
三.Mindspeed框架的演化过程及未来潜在的方向
1. 模型并行 (Tensor Parallel) :
- 问题 : 单个设备内存无法容纳大型模型。
- 解决方案 : 将模型参数在设备间进行切分,每个设备只负责部分模型计算。
- 演化 :
- 参数矩阵横切 : 将参数矩阵按行切分,需要额外进行输入输出矩阵的切分和拼接。
- 参数矩阵纵切 : 将参数矩阵按列切分,简化了输入输出矩阵的处理,但需要更多的设备进行通信。
2. 流水线并行 (Pipeline Parallel) :
- 问题 : 模型并行中,设备间存在依赖关系,计算资源利用率低。
- 解决方案 : 将模型按层划分为多个阶段,不同阶段在不同设备上并行计算。
- 演化 :
- 虚拟流水线并行 : 将计算进一步细分,通过增加通信量来降低空泡比率,进一步提升性能。
3. 序列并行 (Sequence Parallel) :
- 问题 : 长序列训练内存占用高,无法扩展。
- 解决方案 : 将序列维度切分,不同设备只处理序列的一部分。
- 演化 :
- Ulysses : 需要head_size被tp_size*cp_size整除。
- Ring Attention : 并行维度不受head_size限制,但性能可能低于Ulysses。
- 混合序列并行 : 结合Ulysses和Ring Attention的优势,实现更灵活的序列并行方案。
4. 激活函数重计算 :
- 问题 : 激活函数输出占用大量内存,但计算量小。
- 解决方案 : 在反向计算之前,丢弃激活函数输出,反向时再重新计算。
- 演化 :
- 选择性重计算 : 只对部分激活函数输出进行重计算,减少内存占用和计算量。
- 完全重计算 : 对所有激活函数输出进行重计算,进一步降低内存占用。
5. 数据并行 (Data Parallel) :
- 问题 : 数据集过大,训练时间过长。
- 解决方案 : 将数据集切分为多个batch,每个设备只处理部分数据。
- 演化 :
- Megatron 分布式优化器 : 将优化器状态拆分到所有设备,减少内存占用。
6. 通信优化 :
- 问题 : 计算和通信任务串行执行,效率低。
- 解决方案 :
- 异步DDP : 将计算和通信任务拆分,并行执行,提高效率。
- 权重更新通信隐藏 : 将权重更新和通信任务并行执行,提高效率。
- 计算通信并行 (CoC) : 将计算和通信任务分别拆分,并行执行,提高效率。
- Ascend MC2 : 将matmul计算和通信操作融合,提高效率。
7. 其他优化 :
- 混合精度训练 : 使用BF16和FP16混合精度训练,减少内存占用。
- 参数副本复用 : 等价去除冗余的FP32参数副本,减少内存占用。
- Alibi 位置编码 : 提高模型外推能力。
- Flash Attention 适配 : 优化IO访存,提高长序列训练效率。
- Efficient-MOE : 减少MoE训练中不必要的通信开销。
- 内存碎片优化 : 减少内存碎片,避免内存不足。
- RMSNorm/ Rotary Postion Embedding/ Swiglu 融合优化 : 提升计算效率,减少内存占用。
8. 自适应选择重计算 (Adaptive Recomputing) :
- 问题 : 现有重计算策略固定,无法最大化利用显存资源。
- 解决方案 : 根据当前内存使用情况,自动选择最优的重计算策略,最大化利用显存资源。
- 演化 :
- 重计算策略搜索 : 搜索并选择最优的重计算策略,例如层切分方式、重计算层数等。
- SwapManager 功能 : 及时将tensor换到CPU,避免内存不足导致训练中断。
- 内存管理 : 适配PTA的NPUPluggableAllocator接口,拦截OOM,让SwapManager功能可以介入。
9. 异步DDP (Overlap Grad Reduce) :
- 问题 : 数据并行场景下,梯度更新和反向计算串行执行,效率低。
- 解决方案 : 将梯度更新和反向计算任务拆分,并行执行,提高效率。
10. 权重更新通信隐藏 (Overlap Param Gather) :
- 问题 : 数据并行场景下,权重更新和下一轮前向计算串行执行,效率低。
- 解决方案 : 将权重更新和下一轮前向计算任务拆分,并行执行,提高效率。
11. PP自动并行 (Auto Pipeline Parallel) :
- 问题 : PP-Stage 0的显存占用过高,限制模型规模。
- 解决方案 : 自动寻找最优的层分布和重计算模块,均匀分配每个卡上的显存,降低峰值内存,并最小化端到端训练时间。
12. 混合长序列并行 (Hybrid CP Algorithm) :
- 问题 : Ulysses和Ring Attention方案存在各自的局限性。
- 解决方案 : 结合Ulysses和Ring Attention的优势,实现更灵活的序列并行方案,克服各自的缺陷。
13. 计算通信并行 CoC (Communication Over Computation) :
- 问题 : 计算和通信任务串行执行,效率低。
- 解决方案 : 将计算和通信任务分别拆分,并行执行,提高效率。
- 演化 :
- Python脚本侧实现 : 通过脚本实现子tensor之间的计算和通信并行。
- 融合算子实现 : 基于MTE远端内存访问能力,以融合大Kernel方式实现计算和通信任务的拆分和并行。
14. Ascend MC2 :
- 问题 : TP和SP场景下,matmul计算和通信操作存在强依赖关系,效率低。
- 解决方案 : 将matmul计算和集合通信操作融合,通过流水的方式减少等待和闲置时间,提高利用率。
15. 内存碎片优化 :
- 问题 : 频繁地申请和释放内存空间容易引发内存碎片问题。
- 解决方案 : 将不同生命周期的tensor放入不同的内存池分别管理,减少内存碎片。
16. 参数副本复用 :
- 问题 : 混合精度训练中BF16计算参数和FP32参数副本同时存在,占用冗余内存。
- 解决方案 : 通过数值变换的方式等价去除冗余的FP32参数副本,减少内存占用。
17. Ring Attention长序列并行 :
- 问题 : 序列维度扩展受限,训练内存开销大。
- 解决方案 : 支持Ring Attention长序列并行方案,通过分块计算和环状通信结构,实现序列维度无限拓展。
18. RMSNorm/ Rotary Postion Embedding/ Swiglu 融合优化 :
- 问题 : 常用算子没有融合优化,执行效率低。
- 解决方案 : 将常用算子融合成一个算子,减少数据传输和临时存储,提升计算效率。
19. Token重排性能优化 :
- 问题 : DeepSpeed MoE的token重排方案计算复杂度高,存在优化空间。
- 解决方案 : 使用等价的pytorch API: index_select来实现token重排,降低计算时间复杂度。
20. Ulysses长序列并行 :
- 问题 : 序列维度扩展受限,训练内存开销大。
- 解决方案 : 支持Ulysses长序列并行方案,通过all-to-all通信操作,实现序列维度无限拓展。
概括为以下几个阶段:
1. 从单机到分布式 :
- 早期 : 单机训练是主流,但随着模型规模的不断扩大,单机内存和计算能力逐渐成为瓶颈。
- 演化 : 引入模型并行和流水线并行,将模型切分到多个设备上进行训练,突破了单机资源的限制。
2. 从静态到动态 :
- 早期 : 模型并行和流水线并行需要预先设置,缺乏灵活性。
- 演化 : 引入自适应选择重计算和PP自动并行,根据当前内存使用情况自动选择最优的重计算策略和层分布,提高了训练效率和灵活性。
3. 从串行到并行 :
- 早期 : 计算和通信任务串行执行,效率低。
- 演化 : 引入异步DDP、权重更新通信隐藏、计算通信并行 CoC 和 Ascend MC2 等技术,将计算和通信任务并行执行,提高了训练效率。
4. 从粗粒度到细粒度 :
- 早期 : 序列并行方案较为简单,存在局限性。
- 演化 : 引入混合长序列并行、Ring Attention长序列并行和Ulysses长序列并行等方案,实现了更灵活的序列维度扩展。
5. 从基础到融合 :
- 早期 : 常用算子没有融合优化,执行效率低。
- 演化 : 引入RMSNorm/ Rotary Postion Embedding/ Swiglu 融合优化等技术,将常用算子融合成一个算子,提高了计算效率。
6. 从单一到综合 :
- 早期 : 模型训练优化主要集中在单一方面。
- 演化 : 引入内存碎片优化、参数副本复用等技术,从多个方面综合提升训练效率。
未来展望 :
- 更灵活的并行方案 : 随着模型规模的不断增长,需要更灵活的并行方案来适应不同的训练场景。
- 更高效的通信技术 : 通信效率是影响分布式训练性能的关键因素,需要开发更高效的通信技术来降低通信开销。
- 更智能的自动优化 : 自动化是未来模型训练的趋势,需要开发更智能的自动优化技术来简化训练过程。
展望Mindspeed框架的未来发展:
1. 资源利用最大化 :
- 内存碎片优化 : 进一步优化内存管理策略,减少内存碎片,提高内存利用率。
- 显存扩展技术 : 探索显存扩展技术,例如虚拟内存、分布式缓存等,突破单设备显存限制。
- 计算资源调度 : 开发更智能的计算资源调度算法,根据模型特点和训练任务,动态调整资源分配,提高资源利用率。
2. 训练效率最大化 :
- 更高效的并行算法 : 探索更高效的并行算法,例如基于图计算、张量网络等,进一步提高并行效率。
- 更高效的通信协议 : 开发更高效的通信协议,例如低延迟通信、多路径通信等,降低通信开销。
- 更智能的自动优化 : 开发更智能的自动优化技术,例如基于强化学习、机器学习等,自动选择最优的并行策略和参数配置。
3. 模型训练自动化 :
- 自动化模型并行 : 自动识别模型结构和特征,自动选择最优的模型并行策略。
- 自动化流水线并行 : 自动划分模型层,自动选择最优的流水线并行策略。
- 自动化序列并行 : 自动选择最优的序列并行方案,例如Ulysses、Ring Attention、混合长序列并行等。
- 自动化重计算 : 自动识别重计算热点,自动选择最优的重计算策略。
4. 模型训练智能化 :
- 模型压缩 : 开发更高效的模型压缩技术,例如量化、剪枝、蒸馏等,降低模型规模,提高训练效率。
- 模型搜索 : 开发更高效的模型搜索算法,例如强化学习、进化算法等,自动搜索最优的模型结构。
- 模型评估 : 开发更智能的模型评估方法,例如基于数据分布、任务特征等,更准确地评估模型性能。
5. 训练框架开放化 :
- 开放接口 : 提供更开放的接口,方便用户定制化和扩展训练框架。
- 开源代码 : 开源训练框架的代码,促进社区协作和知识共享。
- 生态建设 : 构建更完善的训练框架生态系统,例如提供模型库、数据集、工具等,方便用户进行模型训练和应用开发。
潜在的发展方向:
1. 跨平台支持 :
- 支持更多硬件平台 : 目前Mindspeed框架主要针对昇腾平台进行优化,未来可以考虑支持更多硬件平台,例如GPU、FPGA等,扩大用户群体。
- 云原生架构 : 将Mindspeed框架与云平台结合,提供更便捷、高效的云上大模型训练服务。
2. 生态系统建设 :
- 模型库 : 建立一个开放的大模型模型库,方便用户共享和复用模型。
- 数据集 : 建立一个开放的大模型数据集平台,方便用户获取和共享数据。
- 工具 : 开发更多便捷的工具,例如可视化工具、调试工具等,方便用户进行模型训练和应用开发。
- 社区 : 建立一个活跃的社区,方便用户交流经验、解决问题、分享成果。
3. 可解释性和可信赖性 :
- 模型可解释性 : 开发更有效的模型可解释性技术,例如特征可视化、注意力可视化等,帮助用户理解模型的行为和决策过程。
- 模型可信赖性 : 开发更有效的模型可信赖性技术,例如鲁棒性分析、公平性分析等,确保模型的可靠性和安全性。
4. 应用场景拓展 :
- 推理加速 : 开发更高效的推理加速技术,例如模型量化、模型剪枝等,降低模型推理的延迟和功耗。
- 多模态训练 : 支持多模态数据的大模型训练,例如文本、图像、音频等,构建更全面、更智能的AI模型。
- 边缘计算 : 将Mindspeed框架应用于边缘计算场景,实现更本地化、更实时的大模型推理服务。
5. 安全性和隐私保护 :
- 模型安全 : 开发更有效的模型安全技术,例如对抗攻击防御、后门攻击防御等,确保模型的安全性。
- 数据隐私 : 开发更有效的数据隐私保护技术,例如联邦学习、差分隐私等,保护用户数据隐私。
几个方向前进:
- 技术创新与突破 :
- 新型并行架构 : 探索新型并行架构,例如分布式内存、异构计算等,进一步提高并行效率。
- 量子计算 : 将Mindspeed框架与量子计算结合,探索量子计算在大模型训练中的应用。
- 脑机接口 : 将Mindspeed框架与脑机接口结合,实现更自然、更高效的交互方式。
- 元宇宙 : 将Mindspeed框架应用于元宇宙场景,构建更加逼真、沉浸式的虚拟世界,实现更丰富的交互体验。
- 跨学科融合 :
- 认知科学 : 将Mindspeed框架与认知科学结合,探索人脑的工作原理,构建更智能的AI模型。
- 心理学 : 将Mindspeed框架与心理学结合,探索人类的情感、意识等,构建更具情感、更具同理心的AI模型。
- 哲学 : 将Mindspeed框架与哲学结合,探索人工智能的本质和未来,构建更具伦理、更具道德的AI模型。
- 可持续发展 :
- 绿色计算 : 开发更节能的模型训练技术,例如模型压缩、模型剪枝等,降低模型训练的能耗。
- 可扩展性 : 开发更具可扩展性的模型训练框架,例如支持动态模型大小、支持动态并行策略等,适应不同规模的训练任务。
- 社会责任 :
- 公平性 : 开发更公平的AI模型,避免算法歧视和偏见。
- 透明性 : 提高AI模型的透明性,让用户了解模型的行为和决策过程。
- 可解释性 : 开发更可解释的AI模型,让用户理解模型的行为和决策过程。
- 人机协作 :
- 协同工作 : 开发更有效的人机协作工具,例如智能助手、智能机器人等,帮助人类完成更复杂的任务。
- 自主学习 : 开发更自主学习的AI模型,例如强化学习、迁移学习等,让AI模型能够自主学习、自我改进。
- 构建智能生态 :
- 多模态融合 : 支持多模态数据的大模型训练,例如文本、图像、音频、视频等,构建更全面、更智能的AI模型,实现更自然的人机交互。
- 知识图谱 : 将Mindspeed框架与知识图谱结合,构建更加丰富、更加精准的知识图谱,实现更深入的语义理解。
- 机器学习平台 : 构建开放的机器学习平台,提供更便捷、更高效的模型训练、评估和应用开发工具,推动人工智能技术的普及和应用。
四.Ascend开源工具介绍
1. ACLLite
功能介绍:对 CANN 提供的 ACL 接口进行高阶封装 ,简化用户调用流程,提供易用的公共接口,主要针对边缘场景设计。
要解决的痛点:传统 ACL 接口使用复杂,开发效率低。
创新点:提供高阶封装和简易接口,降低开发门槛。
2. ADS-Accelerator
功能介绍:基于昇腾 NPU 平台开发的算子和模型加速库,提供高性能算子和模型加速接口,支持 PyTorch 框架。
要解决的痛点:昇腾 NPU 训练效率低,模型部署复杂。
创新点:提供高性能算子和模型加速接口,简化模型部署流程。
3. Apex Patch
功能介绍:以代码 patch 的形式发布,让用户可以在华为昇腾 AI 处理器上使用 Apex 的自动混合精度训练功能,提升训练效率。
要解决的痛点:昇腾 NPU 训练效率低,模型精度不稳定。
创新点:提供自动混合精度训练功能,提升训练效率并保持模型精度。
4. Ascend Inference Tools (ait)
功能介绍:昇腾推理工具链 ,提供模型推理迁移全流程、大模型推理迁移全流程等工具,帮助用户快速进行模型推理开发。
要解决的痛点:模型推理迁移流程复杂,开发效率低。
创新点:提供一体化推理开发工具,简化模型推理迁移流程。
5. DeepSpeed NPU
功能介绍:昇腾 NPU 适配 DeepSpeed 插件,让用户可以在昇腾 910 芯片上使用 DeepSpeed,并基于 DeepSpeed 进行开发。
要解决的痛点:DeepSpeed 不支持昇腾 NPU。
创新点:提供昇腾 NPU 适配的 DeepSpeed 插件,让用户可以使用 DeepSpeed 进行训练和推理。
6. Megatron-NPU
功能介绍:基于 Megatron-LM 原始仓开发的适配仓,已适配数据并行、模型并行、流水并行、序列并行等特性,支持大模型训练。
要解决的痛点:Megatron-LM 不支持昇腾 NPU。
创新点:提供昇腾 NPU 适配的 Megatron-LM,让用户可以使用 Megatron-LM 进行大模型训练。
7. MindSpeed
功能介绍:针对华为昇腾设备的大模型加速库,支持昇腾专有算法,确保开箱可用。
要解决的痛点:大模型训练需要大量显存资源,对计算卡提出挑战。
创新点:提供大模型加速库,提升大模型训练效率。
8. MindX SDK Reference Apps
功能介绍:基于 MindX SDK 开发的参考样例,涵盖图像识别、目标检测、语义分割、文本生成等多种应用场景。
要解决的痛点:MindX SDK 使用复杂,缺乏参考样例。
创新点:提供丰富的参考样例,帮助开发者快速入门和使用 MindX SDK。
9. ModelLink
功能介绍:为华为昇腾芯片上的大语言模型提供端到端的解决方案 ,包含模型、算法以及下游任务。
要解决的痛点:大语言模型训练和推理流程复杂,缺乏一体化解决方案。
创新点:提供端到端解决方案,简化大语言模型训练和推理流程。
10. Ascend ModelZoo
功能介绍:昇腾旗下的开源 AI 模型平台,涵盖计算机视觉、自然语言处理、语音、推荐、多模态、大语言模型等多个方向的 AI 模型及其基于昇腾机器实操案例。
要解决的痛点:缺乏高质量的昇腾 AI 模型资源。
创新点:提供丰富的昇腾 AI 模型资源,并附带详细的使用指导。
11. msadvisor
功能介绍:昇腾性能调优 专家系统工具,可以帮助开发者识别算子/模型性能瓶颈,并输出合理的性能调优方案。
要解决的痛点:算子/模型性能调优依赖开发者经验,缺乏统一的调优规范和结果输出。
创新点:提供基于专家系统知识的性能调优工具,简化性能调优流程。
12. mxRec
功能介绍:面向互联网市场搜索推荐 广告的应用使能 SDK 产品,提供大规模搜推广场景的搜索推荐广告框架。
要解决的痛点:搜索推荐广告模型训练效率低,缺乏大规模稀疏表支持。
创新点:提供大规模搜推广场景的搜索推荐广告框架,并支持大规模稀疏表。
13. OpPlugin
功能介绍:Ascend Extension for PyTorch 算子插件 ,为使用 PyTorch 框架的开发者提供便捷的 NPU
算子库调用能力。
要解决的痛点:PyTorch 框架缺乏对昇腾 NPU 的支持。
创新点:提供 PyTorch 框架的 NPU 算子插件,让用户可以使用 PyTorch 进行昇腾 NPU 训练和推理。
14. Ascend CANN Parser
功能介绍:将第三方框架的算法表示转换成 Ascend IR ,方便开发者充分利用昇腾 AI 处理器的运算能力。
要解决的痛点:第三方框架算法与昇腾 AI 处理器不兼容。
创新点:提供算法转换工具,实现第三方框架算法与昇腾 AI 处理器的兼容。
15. playground
功能介绍:Ascend open source playground,提供昇腾 AI 开发的学习资源和工具。
要解决的痛点:缺乏昇腾 AI 开发的学习资源和工具。
创新点:提供昇腾 AI 开发的学习资源和工具,帮助开发者快速入门。
16. TorchAir
功能介绍:基于 PyTorch 框架和 torch_npu 插件,支持用户在昇腾 NPU 上使用图模式进行训练和推理 。
要解决的痛点:PyTorch 框架缺乏对昇腾 NPU 图模式的 support。
创新点:提供 PyTorch 框架的昇腾 NPU 图模式支持,提升训练和推理效率。
17. Hugging Face
功能介绍:Hugging Face 核心套件 transformers、accelerate、peft、trl 已原生支持 Ascend NPU。
要解决的痛点:Hugging Face 套件缺乏对昇腾 NPU 的 support。
创新点:提供 Hugging Face 套件的昇腾 NPU 支持,让用户可以使用 Hugging Face 套件进行昇腾 NPU 训练和推理。
18. Torchvision Adapter
功能介绍:昇腾适配 Torchvision 框架,提供基于 cv2 和昇腾 NPU 的图像处理加速后端,加速图像处理。
要解决的痛点:Torchvision 框架缺乏对昇腾 NPU 的 support。
创新点:提供 Torchvision 框架的昇腾 NPU 支持,提升图像处理效率。
19. workload_analysis
功能介绍:mindstudio 负载建模众智合作仓库,提供昇腾 AI 工作负载分析工具和资源。
要解决的痛点:缺乏昇腾 AI 工作负载分析工具和资源。
创新点:提供昇腾 AI 工作负载分析工具和资源,帮助开发者优化昇腾 AI 工作负载。
继续
20. Ascend Extension for PyTorch (torch_npu)
功能介绍:昇腾扩展库,让 PyTorch 框架 可以使用昇腾 NPU 进行训练和推理,提供高性能 AI 计算能力。
要解决的痛点:PyTorch 框架原生不支持昇腾 NPU。
创新点:提供 PyTorch 框架的昇腾 NPU 支持,实现 PyTorch 模型在昇腾 NPU 上的高效训练和推理。
21. Ascend Samples
功能介绍:昇腾样例仓,提供媒体数据处理、算子开发与调用、推理应用开发与部署等场景的丰富代码样例,帮助开发者快速入门和使用 CANN。
要解决的痛点:CANN 使用复杂,缺乏参考样例。
创新点:提供丰富的代码样例,帮助开发者快速学习和掌握 CANN。
22. TensorFlow Adapter For Ascend (TF Adapter)
功能介绍:昇腾扩展库,让 TensorFlow 框架可以使用昇腾 NPU 进行训练和推理,提供高性能 AI 计算能力。
要解决的痛点:TensorFlow 框架原生不支持昇腾 NPU。
创新点:提供 TensorFlow 框架的昇腾 NPU 支持,实现 TensorFlow 模型在昇腾 NPU 上的高效训练和推理。
23. Ascend Extension for TensorPipe
功能介绍:开源仓 Tensorpipe 基于 Ascend pytorch/torch_npu 的适配,提供高性能的分布式训练通信库 。
要解决的痛点:Tensorpipe 缺乏对昇腾 NPU 的 support。
创新点:提供 Tensorpipe 的昇腾 NPU 支持,提升分布式训练效率。
24. msquickcmp
功能介绍:一键式全流程精度比对工具 ,适用于 TensorFlow 和 ONNX 模型,输入原始模型和对应的离线 om 模型,输出精度比对结果。
要解决的痛点:模型精度比对流程复杂,缺乏自动化工具。
创新点:提供一键式全流程精度比对工具,简化模型精度比对流程。
25. precision_tool
功能介绍:精度问题分析工具 ,提供精度比对常用功能,主要适配 TensorFlow 训练场景,同时提供 Dump
数据/图信息的交互式查询和操作入口。
要解决的痛点:缺乏模型精度问题分析工具。
创新点:提供模型精度问题分析工具,帮助开发者定位和解决精度问题。
26. auto-optimizer
功能介绍:提供基于 ONNX 的改图、自动优化 及端到端推理流程,帮助开发者提升模型推理效率。
要解决的痛点:模型推理效率低,缺乏自动化优化工具。
创新点:提供模型自动优化工具,简化模型推理优化流程。
27. saved_model2om
功能介绍:TensorFlow 1.15 saved_model 模型转 om 模型工具,输入 TensorFlow 存储的 saved_model
模型,转换为 pb 模型,再转换为 om 模型。
要解决的痛点:缺乏 TensorFlow saved_model 模型到 om 模型的转换工具。
创新点:提供 TensorFlow saved_model 模型到 om 模型的转换工具,简化模型迁移流程。
28. mindxedge_whitebox
功能介绍:MindXEdge 白牌化安装工具,支持 Atlas500 智能小站进行白牌化的首次安装,安装后设备将变为白牌化的设备。
要解决的痛点:缺乏 MindXEdge 白牌化安装工具。
创新点:提供 MindXEdge 白牌化安装工具,简化 MindXEdge 白牌化流程。
继续
29. Hugging Face Transformers
功能介绍:Hugging Face 的自然语言处理模型库,提供预训练模型和工具,支持多语言和多种任务,包括文本分类、命名实体识别、机器翻译等。
要解决的痛点:自然语言处理任务开发复杂,缺乏高质量预训练模型和工具。
创新点:提供丰富的预训练模型和工具,简化自然语言处理任务开发。
30. Hugging Face Accelerate
功能介绍:Hugging Face 的分布式训练加速库,支持单机多卡、多机多卡训练,并提供自动混合精度、数据并行等功能。
要解决的痛点:分布式训练效率低,缺乏自动化优化工具。
创新点:提供分布式训练加速库,简化分布式训练流程并提升训练效率。
31. Hugging Face Peft
功能介绍:Hugging Face 的模型微调库,支持模型压缩、知识蒸馏、参数高效等技术,帮助开发者提升模型性能和效率。
要解决的痛点:模型微调流程复杂,缺乏自动化工具。
创新点:提供模型微调库,简化模型微调流程并提升模型性能和效率。
32. Hugging Face TRL
功能介绍:Hugging Face 的强化学习库,提供强化学习模型和工具,支持多种强化学习算法,包括 DQN、PPO、SAC 等。
要解决的痛点:强化学习任务开发复杂,缺乏高质量预训练模型和工具。
创新点:提供强化学习模型和工具,简化强化学习任务开发。
37. MindX SDK Reference Apps
功能介绍:MindX SDK 的参考样例仓库,提供 C++ 和 Python 两种语言的 AI 应用开发样例,涵盖图像识别、视频分析、自然语言处理等领域。
要解决的痛点:MindX SDK 使用复杂,缺乏参考样例。
创新点:提供丰富的 C++ 和 Python AI 应用开发样例,帮助开发者快速学习和掌握 MindX SDK。
38. ModelZoo
功能介绍:昇腾的 AI 模型平台,提供开源的 AI 模型和基于昇腾的实操案例,涵盖计算机视觉、自然语言处理、语音、推荐、多模态、大语言模型等领域。
要解决的痛点:AI 模型开发复杂,缺乏开源模型和案例。
创新点:提供开源的 AI 模型和基于昇腾的实操案例,简化 AI 模型开发流程。
39. ModelZoo-GPL
功能介绍:昇腾的开源 AI 模型平台,提供基于 GPL 许可证的 AI
模型和基于昇腾的实操案例,涵盖计算机视觉、自然语言处理、语音、推荐、多模态、大语言模型等领域。
要解决的痛点:缺乏基于 GPL 许可证的 AI 模型和案例。
创新点:提供基于 GPL 许可证的 AI 模型和基于昇腾的实操案例,满足开源社区的需求。
40. ModelZoo-PyTorch
功能介绍:昇腾的 AI 模型平台,提供基于 PyTorch 框架的开源的 AI
模型和基于昇腾的实操案例,涵盖计算机视觉、自然语言处理、语音、推荐、多模态、大语言模型等领域。
要解决的痛点:缺乏基于 PyTorch 框架的开源的 AI 模型和案例。
创新点:提供基于 PyTorch 框架的开源的 AI 模型和基于昇腾的实操案例,满足 PyTorch 社区的需求。
41. Ascend ModelZoo-TensorFlow
功能介绍:昇腾的 AI 模型平台,提供基于 TensorFlow 框架的开源的 AI
模型和基于昇腾的实操案例,涵盖计算机视觉、自然语言处理、语音、推荐、多模态、大语言模型等领域。
要解决的痛点:缺乏基于 TensorFlow 框架的开源的 AI 模型和案例。
创新点:提供基于 TensorFlow 框架的开源的 AI 模型和基于昇腾的实操案例,满足 TensorFlow 社区的需求。
继续
42. Ascend ModelZoo-TensorFlow2
功能介绍:昇腾的 AI 模型平台,提供基于 TensorFlow 2.x 框架的开源的 AI
模型和基于昇腾的实操案例,涵盖计算机视觉、自然语言处理、语音、推荐、多模态、大语言模型等领域。
要解决的痛点:缺乏基于 TensorFlow 2.x 框架的开源的 AI 模型和案例。
创新点:提供基于 TensorFlow 2.x 框架的开源的 AI 模型和基于昇腾的实操案例,满足 TensorFlow 2.x 社区的需求。
43. msadvisor
功能介绍:昇腾的性能调优专家系统,通过规则集、模糊规则集、案例匹配、神经网络机器学习等方式生成性能调优知识库,帮助开发者识别性能瓶颈并输出合理的性能调优方案。
要解决的痛点:AI 应用性能调优复杂,缺乏自动化工具。
创新点:提供基于专家系统的性能调优工具,简化 AI 应用性能调优流程。
44. mxRec
功能介绍:昇腾的搜索推荐广告应用使能
SDK,提供模型训练基础功能、推荐场景特有功能以及大规模稀疏表特有功能,支持大规模搜推广场景,助力完成搜推广模型的快速高效训练。
要解决的痛点:搜索推荐广告模型训练效率低,缺乏高效训练工具。
创新点:提供高性能的搜索推荐广告模型训练框架,提升搜推广模型训练效率。
45. mxVision
功能介绍:昇腾的视觉分析 SDK,提供图像识别、目标检测、语义分割、人脸识别等 AI 应用开发工具,支持 C++ 和 Python 两种语言。
要解决的痛点:视觉分析任务开发复杂,缺乏高效开发工具。
创新点:提供高性能的视觉分析 SDK,简化视觉分析任务开发。
46. mxIndex
功能介绍:昇腾的检索聚类 SDK,提供文本检索、向量相似度检索、聚类等 AI 应用开发工具,支持 C++ 和 Python 两种语言。
要解决的痛点:检索聚类任务开发复杂,缺乏高效开发工具。
创新点:提供高性能的检索聚类 SDK,简化检索聚类任务开发。
47. mxManufacture
功能介绍:昇腾的制造质检 SDK,提供缺陷检测、分类识别、预测性维护等 AI 应用开发工具,支持 C++ 和 Python 两种语言。
要解决的痛点:制造质检任务开发复杂,缺乏高效开发工具。
创新点:提供高性能的制造质检 SDK,简化制造质检任务开发。
继续
48. Megatron-LM
功能介绍:昇腾基于 Megatron-LM 原始仓开发的适配仓,提供大型 Transformer
模型的训练和推理功能,支持数据并行、模型并行、流水线并行、分布式优化器等多种加速算法。
要解决的痛点:大型 Transformer 模型训练效率低,缺乏高效训练工具。
创新点:提供高性能的大型 Transformer 模型训练框架,提升大型 Transformer 模型训练效率。
49. MindSpeed
功能介绍:昇腾的大模型加速库,提供模型并行、流水线并行、序列并行、重计算、分布式优化器等多种加速算法,并支持昇腾专有算法,确保开箱可用。
要解决的痛点:大模型训练效率低,缺乏高效训练工具。
创新点:提供高性能的大模型加速库,提升大模型训练效率。
50. MindX-Science
功能介绍:昇腾的 AI for Science 高性能开发套件,提供高性能计算、高性能存储、高性能网络等功能,助力科学计算领域的研究和应用。
要解决的痛点:科学计算任务计算效率低,缺乏高性能计算平台。
创新点:提供高性能的 AI for Science 开发套件,提升科学计算任务计算效率。
51. Ascend ModelZoo-ACL
功能介绍:昇腾的 AI 模型平台,提供基于 ACL 接口的开源的 AI
模型和基于昇腾的实操案例,涵盖计算机视觉、自然语言处理、语音、推荐、多模态、大语言模型等领域。
要解决的痛点:缺乏基于 ACL 接口的开源的 AI 模型和案例。
创新点:提供基于 ACL 接口的开源的 AI 模型和基于昇腾的实操案例,满足 ACL 社区的需求。
54. Apex Patch
功能介绍:Apex 的代码 patch,让用户可以在华为昇腾 AI 处理器上使用 Apex 的自动混合精度训练功能,提升 AI
模型的训练效率,同时保持模型的精度和稳定性。
要解决的痛点:Apex 缺乏对昇腾 NPU 的 support。
创新点:提供 Apex 的昇腾 NPU 适配 patch,提升 AI 模型训练效率。
55. Ascend Edge And Robotics
功能介绍:昇腾边缘开发套件社区代码仓库,提供 AI 应用开发样例和外设使用指导,涵盖图像识别、目标检测、视频分析等领域。
要解决的痛点:边缘 AI 应用开发缺乏参考样例和外设使用指导。
创新点:提供边缘 AI 应用开发样例和外设使用指导,简化边缘 AI 应用开发。
56. Ascend-volcano-plugin
功能介绍:基于开源 Volcano 调度器的插件机制,增加昇腾处理器的亲和性调度和虚拟设备调度特性,最大化发挥昇腾处理器计算性能。
要解决的痛点:Volcano 调度器缺乏对昇腾处理器的亲和性调度和虚拟设备调度支持。
创新点:提供昇腾处理器的亲和性调度和虚拟设备调度插件,提升昇腾处理器的计算性能。
57. hccl-controller
功能介绍:用于生成训练作业所有 Pod 的 hccl.json 配置文件的组件,方便 NPU 训练任务更好地协同和调度底层的昇腾处理器。
要解决的痛点:NPU 训练任务缺乏便捷的 hccl.json 配置生成工具。
创新点:提供便捷的 hccl.json 配置生成工具,简化 NPU 训练任务配置。
58. NodeD
功能介绍:节点心跳检测组件,当 NodeD 最近一次上报心跳之后一段时间内未再次上报心跳时,调度组件就会认为 NodeD
所在的节点故障,从而触发故障重调度。
要解决的痛点:集群缺乏节点故障检测和重调度机制。
创新点:提供节点故障检测和重调度机制,提升集群稳定性。
59. NPU-Exporter
功能介绍:用于收集华为 NPU 各种监控信息和指标,并封装成 Prometheus 专用数据格式的服务组件。
要解决的痛点:NPU 监控信息缺乏便捷的收集和展示工具。
创新点:提供 NPU 监控信息收集和展示工具,方便开发者监控 NPU 运行状态。
60. Ascend Docker Runtime
功能介绍:为所有 AI 训练/推理作业提供 Ascend NPU 容器化支持,使用户 AI 作业能够以 Docker 容器的形式平滑运行在昇腾设备之上。
要解决的痛点:AI 作业缺乏便捷的容器化部署方式。
创新点:提供 AI 作业容器化部署工具,简化 AI 作业部署。
62. Opencv ACL 模块安装及使用
功能介绍:Opencv 部分模块 对 AscendCL 的支持,包括 MAT 类及部分矩阵操作函数。
要解决的痛点:Opencv 缺乏对 AscendCL 的支持。
创新点:提供 Opencv ACL 模块,方便开发者使用 Opencv 进行 AI 应用开发。
相关文章:

Ascend训练软件栈了解
一.分布式大模型训练的完整流程及注意事项 1. 迁移分析 模型选取与约束说明 : 确保模型能在GPU或CPU上运行并获取性能基线,了解不支持场景,如DP模式、APEX库、bmtrain框架等。支持度分析 : 使用msFmkTransplt工具分析模型算子、…...
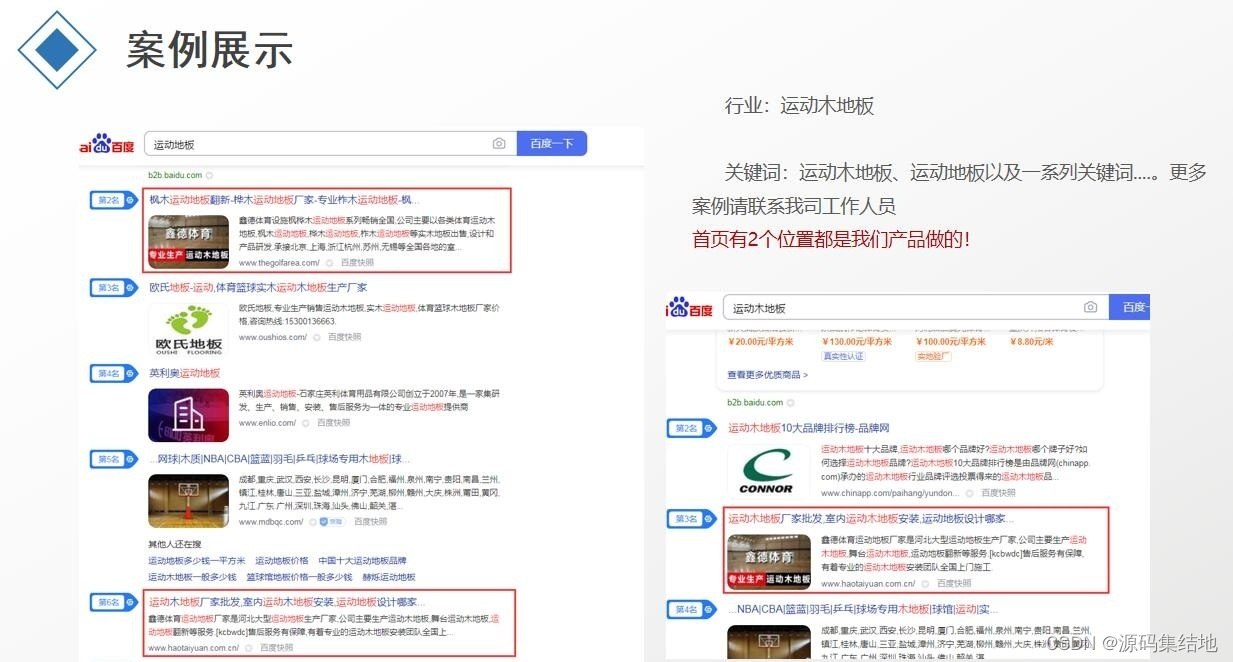
官网万词霸屏推广 轻松实现百度万词霸屏源码系统 带完整的安装代码包以及搭建教程
系统概述 官网万词霸屏推广源码系统是一款基于先进技术研发的综合性 SEO 工具。它的设计理念是通过智能化的算法和策略,帮助用户快速提升网站在百度等搜索引擎中的排名,实现大量关键词的霸屏效果。该系统整合了多种优化技术,包括关键词研究、…...

Linux 36.3 + JetPack v6.0@jetson-inference之图像分类
Linux 36.3 JetPack v6.0jetson-inference之图像分类 1. 源由2. imagenet2.1 命令选项2.2 下载模型2.3 操作示例2.3.1 单张照片2.3.2 视频 3. 代码3.1 Python3.2 C 4. 参考资料5. 补充5.1 第一次运行模型本地适应初始化5.2 samba软连接 1. 源由 从应用角度来说,图…...
重庆公司记账代理,打造专业财务管理解决方案的领先企业
重庆公司记账代理,作为专业的财务管理服务提供商,我们的目标是为公司的经营管理和决策提供科学、准确的财务数据支持,我们通过长期的专业经验和对市场的深入理解,为您提供一站式的记账服务和财务咨询。 专业团队 我们拥有一支由经…...

transformers 阅读:Llama 模型
正文 学习一下 transformers 库中,Llama 模型的代码,学习过程中写下这篇笔记,一来加深印象,二来可以多次回顾。 笔者小白,里面错误之处请不吝指出。 层归一化 LlamaRMSNorm transformers 中对于 LlamaRMSNorm 类的…...

python绘制piper三线图
piper三线图 Piper三线图是一种常用于水化学分析的图表,它能够帮助我们理解和比较水样的化学成分。该图表由三个部分组成:两个三角形和一个菱形。两个三角形分别用于显示阳离子和阴离子的相对比例,而菱形部分则综合显示了这些离子比例在水样…...

咖啡机器人如何精准控制液位流量
在如今快节奏的生活中,精确控制液位流量的需求愈发迫切,特别是在咖啡机器人等精密设备中。为了满足这一需求,工程师们不断研发出各种先进的技术,以确保液体流量的精准控制。其中,霍尔式流量计和光电式流量计就是两种常…...

Go go-redis应用
go-redis 是 Go 语言的一个流行的 Redis 客户端库,它提供了丰富的功能来与 Redis 数据库进行交互。 1、简单应用 package mainimport ("context""fmt""log""github.com/redis/go-redis/v9" )func main() {ctx : context…...

从混乱到有序:PDM系统如何优化物料编码
在现代制造业中,物料管理是企业运营的核心。物料编码作为物料管理的基础,对于确保物料的准确性、唯一性和高效性至关重要。随着产品种类的不断增加和产品变型的多样化,传统的物料编码管理方式已经不能满足企业的需求。本文将探讨产品数据管理…...

npm发布自己的插件包
要发布自己的插件包到npm,可以按照以下步骤进行操作: 1.创建一个新项目 首先确保你已经安装了Node.js和npm。然后,在你的项目目录中初始化一个新的npm项目:npm init命令会引导你创建一个package.json文件,其中包含你插件包的基本…...

Pygame:新手指南与入门教程
在游戏开发领域,pygame 是一个广受欢迎的 Python 库,它提供了开发二维游戏的丰富工具和方法。这个库让开发者可以较少地关注底层图形处理细节,更多地专注于游戏逻辑和玩法的实现。本文将详细介绍 pygame,包括其安装过程、基本概念、主要功能和一个简单游戏的开发流程。 一…...

动态IP与静态IP的优缺点
在网络连接中,使用动态和静态 IP 地址取决于连接的性质和要求。静态 IP 地址通常更适合企业相关服务,而动态 IP 地址更适合家庭网络。让我们来看看动态 IP 与静态 IP 的优缺点。 1.静态IP的优点: 更好的 DNS 支持:静态 IP 地址在…...

上海市计算机学会竞赛平台2024年1月月赛丙组最大的和
题目描述 给定两个序列 𝑎1,𝑎2,…,𝑎𝑛a1,a2,…,an 与 𝑏1,𝑏2,…,𝑏𝑛b1,b2,…,bn,请从这两个序列中分别各找一个数,要求这两个数的差不超过给…...

C++三大特性之继承,详细介绍
阿尼亚全程陪伴大家学习~ 前言 每个程序员在开发新系统时,都希望能够利用已有的软件资源,以缩短开发周期,提高开发效率。 为了提高软件的可重用性(reusability),C提供了类的继承机制。 1.继承的概念 继承: 指在现有…...

Python推导式详解
引言 推导式(Comprehensions)是Python中一种简洁且强大的语法结构,可以用来生成列表、字典和集合。推导式使得代码更加简洁、易读,同时也更具Pythonic风格。今天我将将详细介绍列表推导式、字典推导式和集合推导式…...

stm32中如何实现EXTI线 0 ~ 15与对应IO口的配置呢?
STM32的EXTI控制器支持19 个外部中断/ 事件请求。每个中断设有状态位,每个中断/ 事件都有独立的触发和屏蔽设置。 STM32的19个外部中断对应着19路中断线,分别是EXTI_Line0-EXTI_Line18: 线0~15:对应外部 IO口的输入中断。 线16&…...
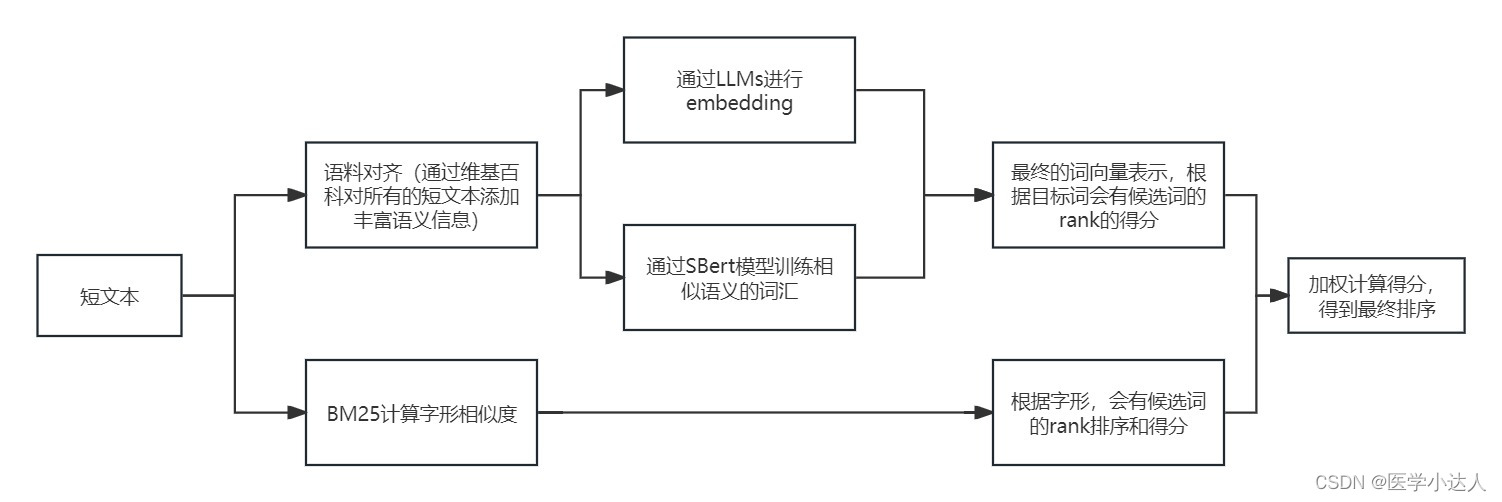
Python 短文本匹配,短文本语义相似度,基于大模型的短文本匹配,基于LLMs的短文本语义相似度识别,短文本语义扩充和匹配
1.任务描述 之前在做疾病相似度匹配的时候,堪称史诗级难题,虽然最后加上规则以及一些nlp模型,取得了差强人意的效果,但是短文本的语义相似度匹配一直属于比较难以攻克的难题 2.思路 随着近年大模型的飞速发展,就之前…...

提升接口性能方式汇总
1,sql 2,缓存,尤其面向用户,如app数据。可用redis咖啡,二级缓存。 充分利用redis,redis数据类型很多,平时场景中结合实际情况,找一下对应的redis实现方案 比如Zset可以排序&#…...

C++中的常见语法糖汇总
C中的语法糖是指使代码更简洁、可读性更高的语言特性和简化的语法。以下是一些常见的C语法糖: 1. 自动类型推导(auto) 使用 auto 关键字可以让编译器自动推导变量的类型,简化变量的声明。 auto x 10; // 编译器推导 x…...

TensorFlow Playground神经网络演示工具使用方法详解
在现代机器学习领域,神经网络无疑是一个重要的研究方向。然而,对于许多初学者来说,神经网络的概念和实际操作可能显得相当复杂。幸运的是,TensorFlow Playground 提供了一个交互式的在线工具,使得我们可以直观地理解和实验神经网络的基本原理。在这篇博客中,我们将详细介…...

从零到一:51单片机数字电子时钟的DIY全流程解析
1. 项目背景与准备 数字电子时钟是单片机入门最经典的练手项目之一。我第一次接触51单片机时,也是从做一个电子时钟开始的。这个项目涵盖了定时器中断、数码管显示、按键扫描、蜂鸣器驱动等核心知识点,而且最终能看到实物运行,成就感直接拉满…...
)
从零开始理解反步控制:用李雅普诺夫函数一步步‘后退’设计控制器(附Simulink仿真模型)
非线性控制实战:用反步法构建稳定系统的可视化指南 在控制理论中,非线性系统总是以其复杂的动态特性让工程师们又爱又恨。传统的线性控制方法往往难以应对这种复杂性,而反步控制(Backstepping Control)作为一种系统化的…...

储能电站EMS系统实战指南:从硬件选型到软件配置的完整避坑手册
储能电站EMS系统实战指南:从硬件选型到软件配置的完整避坑手册 在新能源行业快速发展的今天,储能电站作为电力系统中的关键调节单元,其能量管理系统(EMS)的稳定性和智能化水平直接决定了电站的经济效益和运行安全。然而…...

minikeyvalue架构解密:为什么它比SeaweedFS更简单高效?
minikeyvalue架构解密:为什么它比SeaweedFS更简单高效? 【免费下载链接】minikeyvalue A distributed key value store in under 1000 lines. Used in production at comma.ai 项目地址: https://gitcode.com/gh_mirrors/mi/minikeyvalue minikey…...

Apache Spark 第 11 章:Delta Lake 与 Lakehouse
第十一章深入拆解 Delta Lake 与 Lakehouse 架构,这是现代数据工程的核心组件。从传统数据湖的痛点出发,逐层剖析 Delta Lake 的实现原理。 第一张:为什么需要 Delta Lake。三大痛点和 Delta Lake 的解法一目了然。接下来看最核心的实现机制—…...

Scrcpy:重新定义安卓设备跨平台交互体验
Scrcpy:重新定义安卓设备跨平台交互体验 【免费下载链接】scrcpy Display and control your Android device 项目地址: https://gitcode.com/gh_mirrors/sc/scrcpy 一、跨设备交互的现实困境:发现问题本质 在数字化办公与移动开发的日常场景中&a…...

别等电脑挂了后悔,教你现在就查看Bitlocker密钥
网管小贾 / sysadm.cc陈主任晃了晃脑袋,皱着眉冲着刘晓白说道:“简历我看过了,就算请我吃饭,恐怕也很难办啊!” 刘晓白则一呲牙:“我说老舅,要进你们公司,还不是您一句话的事儿嘛&am…...

DAMO-YOLO在工地安全监管中的应用:防护装备检测系统
DAMO-YOLO在工地安全监管中的应用:防护装备检测系统 1. 工地安全监管的现实挑战 建筑工地从来都不是一个安静的场所。钢筋切割的刺耳声、塔吊运转的轰鸣、混凝土泵车的震动,这些声音背后是数百名工人同时作业的复杂场景。就在这样的环境中,…...

告别手动点鼠标!用Python脚本批量跑Simulink仿真,效率提升10倍
告别手动点鼠标!用Python脚本批量跑Simulink仿真,效率提升10倍 在工程仿真领域,Simulink无疑是建模与分析的利器。但当面对参数扫描、蒙特卡洛分析或设计迭代等需要大量重复仿真的场景时,手动操作不仅效率低下,还容易…...

500+精选RSS源如何解决信息获取难题:Awesome RSS Feeds全解析
500精选RSS源如何解决信息获取难题:Awesome RSS Feeds全解析 【免费下载链接】awesome-rss-feeds Awesome RSS feeds - A curated list of RSS feeds (and OPML files) used in Recommended Feeds and local news sections of Plenary - an RSS reader, article dow…...