python词云生成库-wordcloud
内容目录
- 一、模块介绍
- 二、WordCloud常用的方法
- 1. generate(self, text)
- 2. generate_from_frequencies(frequencies)
- 3. fit_words(frequencies)
- 4. generate_from_text(text)
- 三、进阶技巧
- 1. 设置蒙版
- 2. 设置过滤词
WordCloud 是一个用于生成词云的 Python 库,它可以根据提供的文本数据创建出美观的视觉化图像,其中文本的大小和频率成比例。同时也提供了丰富的绘制功能, 可以结合 matplotlib 库进行复杂的操作
关键的方法就是WordCloud方法
一、模块介绍
导入模块
from wordcloud import WordCloud
该类的定义如下:
def __init__(self, font_path=None, width=400, height=200, margin=2,ranks_only=None, prefer_horizontal=.9, mask=None, scale=1,color_func=None, max_words=200, min_font_size=4,stopwords=None, random_state=None, background_color='black',max_font_size=None, font_step=1, mode="RGB",relative_scaling='auto', regexp=None, collocations=True,colormap=None, normalize_plurals=True, contour_width=0,contour_color='black', repeat=False,include_numbers=False, min_word_length=0, collocation_threshold=30):... ...
其中各个参数和属性的说明如下:
font_path: 字符串, 词云中字体格式文件的路径
用于字体的字体路径(OTF或TTF)。默认为Linux机器上的DroidSansMono路径。如果你在其他操作系统上或没有这个字体,你需要调整这个路径。
width: 整数,默认=400, 画布的宽度。
height: 整数,默认=200, 画布的高度。
prefer_horizontal: 浮点数,默认=0.90
尝试水平适应相对于垂直适应的比例。如果 prefer_horizontal < 1,算法会在单词不适应时尝试旋转单词。(目前没有内置方法仅获取垂直单词。)
mask: 数组或None,默认=None
如果不为None,给出在何处绘制单词的二进制掩模。如果mask不为None,将忽略width和height,并使用mask的形状。所有白色(#FF或#FFFFFF)条目将被视为“屏蔽”,而其他条目则可以自由绘制。
contour_width: 浮点数,默认=0
如果mask不为None且contour_width > 0,绘制掩模轮廓。
contour_color: 颜色值,默认="black", 掩模轮廓颜色。
scale: 浮点数,默认=1
计算与绘制之间的缩放。对于大的词云图像,使用scale而不是更大的画布尺寸会显著更快,但可能导致单词的拟合更粗糙。
min_font_size: 整数,默认=4, 使用的最小字体大小。当这个大小没有更多空间时停止。
font_step: 整数,默认=1, 字体的步长。font_step > 1可能会加速计算,但可能给出较差的拟合。
max_words: 数量,默认=200, 最大单词数。
stopwords: 字符串集合或None
将被消除的单词。如果为None,将使用内置的STOPWORDS列表。如果使用generate_from_frequencies,则忽略。
background_color: 颜色值,默认="black", 词云图像的背景颜色。
max_font_size: 整数或None,默认=None
最大单词的最大字体大小。如果为None,则使用图像的高度。
mode: 字符串,默认="RGB"
当mode为"RGBA"且background_color为None时,将生成透明背景。
relative_scaling: 浮点数,默认='auto'
单词相对频率对字体大小的重要性。如果relative_scaling=0,只考虑单词排名。如果relative_scaling=1,频率是两倍的单词将有两倍的大小。如果你想同时考虑单词频率和不仅仅它们的排名,relative_scaling大约0.5通常看起来不错。如果为'auto',则除非repeat为真,否则设置为0.5,此时设置为0。版本更新:: 2.0默认现在是'auto'。
color_func: 可调用,默认=None
有参数word, font_size, position, orientation, font_path, random_state的可调用函数,为每个单词返回一个PIL颜色。覆盖"colormap"。有关指定matplotlib色谱的信息,请参见colormap。要创建单色的词云,使用
color_func=lambda *args, **kwargs: "white"。单色也可以使用RGB代码指定。例如,
color_func=lambda *args, **kwargs: (255,0,0)设置颜色为红色。
regexp: 字符串或None(可选)
在process_text中分割输入文本为标记的正则表达式。如果指定为None,则使用r"\w[\w']+"。如果使用generate_from_frequencies,则忽略。
collocations: 布尔,默认=True
是否包括两个单词的搭配(二元组)。如果使用generate_from_frequencies,则忽略。
colormap: 字符串或matplotlib色谱,默认="viridis"
从每个单词随机抽取颜色的matplotlib色谱。如果指定了"color_func",则忽略。
normalize_plurals: 布尔,默认=True
是否去除单词末尾的's'。如果为True,一个单词以's'结尾和不以's'结尾都出现时,去掉以's'结尾的单词并将它的计数加到没有's'结尾的版本上——除非单词以'ss'结尾。如果使用generate_from_frequencies,则忽略。
repeat: 布尔,默认=False
是否重复单词和短语直到达到max_words或min_font_size。
include_numbers: 布尔,默认=False, 是否将数字作为短语包含进来。
min_word_length: 整数,默认=0, 单词必须有的最少字母数才能被包含。
collocation_threshold: 整数,默认=30
大二元组必须具有高于此参数的Dunning似然性搭配分数才能被计为大二元组。默认值30是任意的。属性
words_: 字符串到浮点数的字典, 关联频率的单词令牌。2.0后words_ 是一个字典
layout_: 元组列表((字符串, 浮点数), 整数, (整数, 整数), 整数, 颜色)
编码拟合的词云。对于每个单词,它编码字符串、规范化频率、字体大小、位置、方向和颜色。频率由最常出现的单词归一化。颜色格式为'rgb(R, G, B)'。
二、WordCloud常用的方法
1. generate(self, text)
接收一个字符串作为输入,计算文本中各单词的频率,并生成相应的词云。这是最基础也是最常用的方法之一。
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 示例文本
text = "This is a simple example showing how to generate a word cloud using the generate method. Generate method uses the input text directly."# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, max_words=100, background_color='white').generate(text)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

2. generate_from_frequencies(frequencies)
直接接收一个字典,其中键是单词,值是该单词的频率,用来生成词云。这适用于已经计算好词频的情况。
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 示例文本
dic = {'This': 120, 'example': 90, 'showing': 80, 'word': 70, 'cloud': 60, 'Generate': 50, 'method': 40, 'text': 30, 'input': 20, 'directly': 10}
# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, max_words=100, background_color='white').generate_from_frequencies(dic)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

3. fit_words(frequencies)
这个方法接收一个字典,其中键是单词,值是对应的频率,然后根据这些频率生成词云。类似于generate_from_frequencies
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 示例文本
dic = {'This': 120, 'example': 90, 'showing': 80, 'word': 70, 'cloud': 60, 'Generate': 50, 'method': 40, 'text': 30, 'input': 20, 'directly': 10}
# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, max_words=100, background_color='white').fit_words(dic)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

4. generate_from_text(text)
接收一个字符串作为输入,计算文本中各单词的频率,并生成相应的词云。类似于generate。
from wordcloud import WordCloud
import matplotlib.pyplot as plt# 示例文本
text = "This is a simple example showing how to generate a word cloud using the generate method. Generate method uses the input text directly."# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, max_words=100, background_color='white').generate_from_text(text)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

三、进阶技巧
1. 设置蒙版
蒙版设置, 设置蒙版之后, 词云的形状就会显示为设置的蒙版形状
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import numpy as np
from PIL import Imagemask_image = np.array(Image.open('./static/img.png'))# 示例文本
text = "This is a simple example showing how to generate a word cloud using the generate method. Generate method uses the input text directly."# 创建WordCloud对象
wordcloud = WordCloud(width=800, height=800, mask=mask_image, max_words=100, background_color='white')wordcloud.generate_from_text(text)# 显示词云
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

2. 设置过滤词
对于一些不希望出现的词, 可以通过设置stopword过滤, 实现方法有两种
- 在切词阶段, 将过滤词剔除, 过滤词要求是一个集合{}
- 在生成词云阶段, 使用stopword参数添加过滤词数组, 注意, 此时如果通过generate_from_frequencies方法生成, 此参数则忽略
方式一:
stop_words = {'?', ',', '有', '其', '非常', '的', '为', '所', ':', '和', '”', "'", '\\u3000', '乎', '?', '这', '不', '在', '比', '“', '"', '而', '很', '被', '我', '那'}
datas = [... ...] # 词云数据
cloud_data = []
for data in datas:qdatas = jieba.lcut(data)qdata_filter = [word for word in qdatas if word not in excludes]cloud_data.extend(qdata_filter)wordcloud = WordCloud(font_path='./static/msyh.ttc',background_color='white',colormap='magma',max_font_size=40,random_state=42,max_words=300,# 宽width=1000,# 高height=880,mask = mask_image
).generate(' '.join(cloud_data))
方式二:
stop_words = {'?', ',', '有', '其', '非常', '的', '为', '所', ':', '和', '”', "'", '\\u3000', '乎', '?', '这', '不', '在', '比', '“', '"', '而', '很', '被', '我', '那'}
datas = [... ...] # 词云数据wordcloud = WordCloud(font_path='./static/msyh.ttc',background_color='white',colormap='magma',max_font_size=40,random_state=42,max_words=300,# 宽width=1000,# 高height=880,mask = mask_image,-- 设置过滤词stopwords=stop_words
).generate(datas)
相关文章:
python词云生成库-wordcloud
内容目录 一、模块介绍二、WordCloud常用的方法1. generate(self, text)2. generate_from_frequencies(frequencies)3. fit_words(frequencies)4. generate_from_text(text) 三、进阶技巧1. 设置蒙版2. 设置过滤词 WordCloud 是一个用于生成词云的 Python 库,它可以…...
】)
鸿蒙开发接口数据管理:【@ohos.data.rdb (关系型数据库)】
关系型数据库 关系型数据库(Relational Database,RDB)是一种基于关系模型来管理数据的数据库。关系型数据库基于SQLite组件提供了一套完整的对本地数据库进行管理的机制,对外提供了一系列的增、删、改、查等接口,也可…...

Java返回前端Bigdecimal类型数据时“0E-8“及小数点多余0的问题
目录 问题描述: 解决方法: 重要代码: 问题描述: 项目中oracle数据库需要转换为mysql,Oracle中的表字段定义为number(36,16)类型的工具自动转换为mysql的decimal(36,16)。在Oracle数据库中,number(36,16)类型的字段,使用BigDeci…...

标题:深入探索Linux中的`ausyscall`
标题:深入探索Linux中的ausyscall(注意:ausyscall并非Linux内核标准命令,但我们可以探讨类似的概念) 在Linux系统中,系统调用(syscall)是用户空间程序与内核空间进行交互的一种重要…...

CorelDRAW2024发布更新啦!设计师们的得力助手
在数字化的今天,视觉设计已经成为我们生活中不可或缺的一部分。从手机界面到广告海报,从网页布局到包装设计,每一个细节都离不开设计师们的专业与创意。然而,面对日益增长的设计需求和不断提升的审美标准,许多设计师开…...
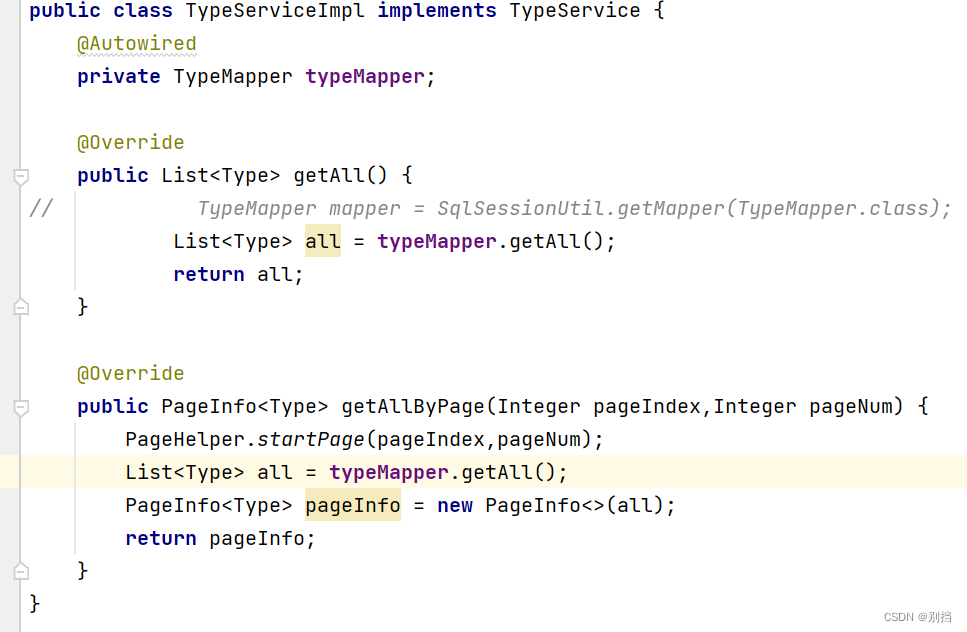
SpringMVC日期格式处理 分页条件查询
实现日期格式处理: springmvc能实现String类型和基本数据类型及包装类的自动格式转换,但是不能识别String和 日期类格式的自动转换。 实现方式: 1是在实体类上加上注解DateTimeFormat,识别String格式为“yyyy-MM-dd” 2使用自定义…...

蓝桥云课第12届强者挑战赛
第一题:字符串加法 其实本质上就是一个高精度问题,可以使用同余定理的推论 (ab)%n((a%n)(b%n))%n; #include <iostream> using namespace std; const int mod1e97; int main() {string a,b;cin>>a>>b;ab;int …...

LabVIEW储油罐监控系统
LabVIEW储油罐监控系统 介绍了基于LabVIEW的储油罐监控系统的设计与实施。系统通过集成传感器技术和虚拟仪器技术,实现对储油罐内液位和温度的实时监控,提高了油罐监管的数字化和智能化水平,有效增强了油库安全管理的能力。 项目背景 随着…...

局域网、城域网、广域网的ip
一、 广域网ip: 全球共享同一个广域网,所以广域网也被称为公网,所以广域网的ip也称为公网ip,全球公网ip必须是都是唯一的,不能冲突。 二、城域网、局域网ip: 可以有无数个局域网、城域网,虽然在…...
【全开源】Java共享茶室棋牌室无人系统支持微信小程序+微信公众号
打造智能化休闲新体验 一、引言:智能化休闲时代的来临 随着科技的飞速发展,智能化、无人化服务逐渐渗透到我们生活的各个领域。在休闲娱乐行业,共享茶室棋牌室无人系统源码的出现,不仅革新了传统的休闲方式,更为消费…...

echarts数据更新没反应解决方案
数据处理逻辑问题: 确保data数组在传入函数时确实发生了变化,并且这些变化对于生成newData1和newData2是有效的。您可以增加一些日志输出来验证处理后的数据是否如预期那样被更新了。 ECharts实例未正确更新: 虽然使用了myChart.setOption…...

RK3588+FPGA+算能BM1684X:高性能AI边缘计算盒子,应用于视频分析、图像视觉等
搭载RK3588(四核 A76四核 A55),CPU主频高达 2.4GHz ,提供1MB L2 Cache 和 3MB L3 ,Cache提供更强的 CPU运算能力,具备6T AI算力,可扩展至38T算力。 产品规格 系统主控CPURK3588,四核…...

Mysql学习(三)——SQL通用语法之DML
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 DML添加数据修改数据删除数据 总结 DML DML用来对数据库中表的数据记录进行增删改操作。 添加数据 -- 给指定字段添加数据 insert into 表名(字段1,字…...

java static 如何理解
在Java中,static关键字是一个重要的概念,它用于定义类的静态成员,包括静态变量(也称作类变量)、静态方法和静态代码块。static关键字的主要作用是创建独立于对象的成员,这些成员属于类本身,而不…...

算法金 | 不愧是腾讯,问基础巨细节 。。。
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 最近,有读者参加了腾讯算法岗位的面试,面试着重考察了基础知识,并且提问非常详细。 特别是关于Ada…...
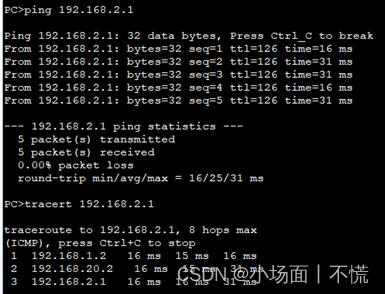
实验9 浮动静态路由配置
--名称-- 一、 原理描述二、 实验目的三、 实验内容四、 实验配置五、 实验步骤 一、 原理描述 浮动静态路由也是一种特殊的静态路由,主要考虑链路冗余。浮动静态路由通过配置一条比主路由优先级低的静态路由,用于保证在主路由失效的情况下,…...
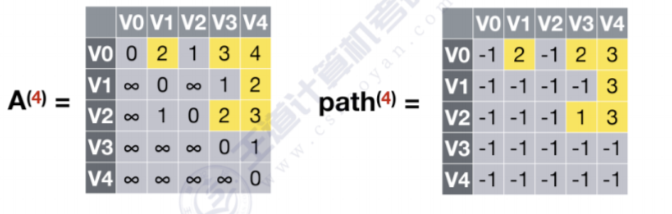
多源最短路径算法–Floyd算法
多源最短路径算法–Floyd算法 Floyd算法是为了求出每一对顶点之间的最短路径 它使用了动态规划的思想,将问题的求解分为了多个阶段 先来个例子,这是个有向图 Floyd算法的运行需要两个矩阵 最短路径矩阵 从当前这个状态看各顶点间的最短路径长度 例…...
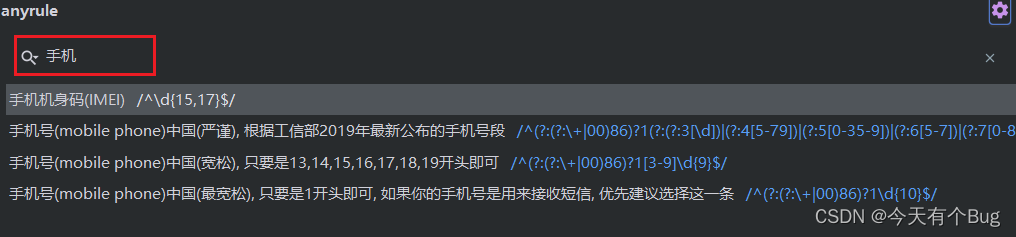
使用Redis缓存实现短信登录逻辑,手机验证码缓存,用户信息缓存
引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency> 加配置 spring:redis:host: 127.0.0.1 #redis地址port: 6379 #端口password: 123456 #密码…...

探索未来制造,BFT Robotics引领潮流
“买机器人,上BFT” 在这个快速变化的时代,创新和效率是企业发展的关键。BFT Robotics,作为您值得信赖的合作伙伴,专注于为您提供一站式的机器人采购和自动化解决方案。 产品系列: 协作机器人:安全、灵活、…...
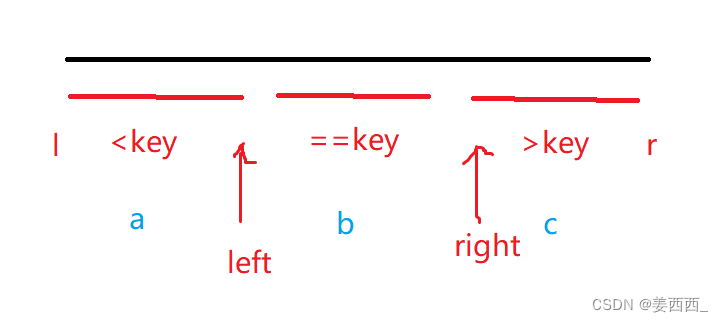
数组中的第K个最大元素 ---- 分治-快排
题目链接 题目: 分析: 这道题很明显是一个top-K问题, 我们很容易想到用堆排序来解决, 堆排序的时间复杂度是O(N*logN), 不符合题意, 所以我们可以用另一种方法:快速选择算法, 他的时间复杂度为O(N)快速选择算法, 其实是基于快排, 进行修改而成, 我们还是使用将"将数组分…...

PX4倾转垂起固定翼混控配置与硬件适配实战
1. PX4倾转垂起固定翼的核心概念解析 第一次接触倾转垂起固定翼的朋友可能会被这个名词吓到,其实它的原理并不复杂。简单来说,这是一种既能像多旋翼一样垂直起降,又能像固定翼飞机一样高效巡航的混合飞行器。我经手过的项目中,这种…...

GraphQL在后端开发中的应用与优势
在现代后端开发领域,GraphQL作为一种新兴的API查询语言,正迅速改变着开发者构建和交互数据的方式。与传统的RESTful API相比,GraphQL提供了一种更灵活、高效的数据获取机制,使前端能够精准地请求所需数据,避免了过度获…...

淘宝淘金币自动脚本:每天15分钟解放双手的终极指南
淘宝淘金币自动脚本:每天15分钟解放双手的终极指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 淘宝淘金…...

Onyx:基于Next.js 14的全栈MVP模板,集成Supabase与现代化工具链
1. 项目概述:Onyx,一个开箱即用的全栈Next.js 14 MVP模板如果你正在寻找一个能让你在几天内,而不是几周内,就启动一个现代化、功能齐全的Web应用原型的起点,那么Onyx很可能就是你需要的那个“瑞士军刀”。这不是一个简…...

基于VLLM与VoxCPM2的高并发TTS服务器部署与调优指南
1. 项目概述:uttera-tts-vllm,一个为高并发而生的TTS服务器如果你正在寻找一个能扛住高并发请求、支持实时语音克隆、并且完全自托管的文本转语音解决方案,那么uttera-tts-vllm绝对值得你花时间研究一下。这个项目本质上是一个基于 FastAPI 构…...

基于Git与Markdown的文档即代码协作平台CORP实践指南
1. 项目概述:一个面向未来的开源协作平台 最近在开源社区里,一个名为“CORP”的项目引起了我的注意。这个项目全称是“CORP-md/CORP”,从名字上看,它似乎是一个与Markdown文档和协作相关的工具。作为一个长期在开源项目和团队协作…...

高性能事件存储引擎Chronicle:原理、部署与生产实践指南
1. 项目概述与核心价值最近在折腾日志和事件数据的管理,发现一个挺有意思的开源项目,叫tensakulabs/chronicle。这名字起得挺贴切,“编年史”,一听就知道是跟记录、存储历史事件相关的。简单来说,Chronicle 是一个高性…...

Docker镜像标准化机器人开发环境:OpenClaw项目协作实践
1. 项目概述:一个面向协作开发的OpenClaw项目镜像最近在开源社区里,一个名为laolin5564/openclaw-collab-dev的Docker镜像引起了我的注意。这个镜像的名字本身就很有意思,它明确指向了“OpenClaw”和“协作开发”这两个核心概念。对于从事机器…...

Shell脚本工程化:great.sh框架解决运维脚本可维护性难题
1. 项目概述:一个被低估的Shell脚本构建框架如果你和我一样,常年混迹在运维、DevOps或者后端开发领域,那么对Shell脚本的感情一定是复杂的。一方面,它是我们最趁手的“瑞士军刀”,从服务器初始化、日志分析到自动化部署…...

泰拉瑞亚地图编辑器TEdit:5步打造专业级游戏世界的终极指南
泰拉瑞亚地图编辑器TEdit:5步打造专业级游戏世界的终极指南 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets y…...