深入解析Java HashMap的putVal方法
Java中的HashMap是我们在开发中经常使用的集合之一,它提供了基于哈希表的数据存储方式,使得对数据的插入、删除和查找操作都具有较高的效率。在本文中,我们将深入解析HashMap中的putVal方法,揭示其内部工作原理。通过对代码的逐行分析,我们不仅能够更好地理解HashMap的设计和实现,还能提高我们在实际开发中对HashMap的使用水平。
一、方法概述
putVal方法是HashMap中的核心方法之一,主要用于向HashMap中插入键值对。它的签名如下:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)
参数说明:
hash:键的哈希值。key:键。value:值。onlyIfAbsent:是否仅在键不存在时才插入。evict:是否在插入后进行驱逐操作。
该方法的返回值是插入前与键关联的旧值,如果没有旧值则返回null。
二、代码详细分析
下面我们将对putVal方法的每一部分进行详细的分析。
1. 初始化table
HashMap.Node<K, V>[] tab;
HashMap.Node<K, V> p;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;
在这段代码中,首先定义了局部变量tab、p、n和i。接着检查table是否为空或长度为0。如果是,则通过resize()方法进行初始化。这一步确保了HashMap的底层数组table已经被初始化且具有一定的容量。
2. 计算索引并插入新节点
if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);
这里通过 (n - 1) & hash 计算出键值对应该插入的索引位置,并检查该位置是否为空。如果为空,直接在该位置创建一个新的节点。值得注意的是,为什么使用 (n - 1) & hash 而不是 n & hash。因为 (n - 1) 能确保结果在 0 到 n-1 之间,正好是数组的有效索引范围。
3. 处理哈希冲突
else {HashMap.Node<K, V> e;K k;if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof HashMap.TreeNode)e = ((HashMap.TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);break;}if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) {V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}
}
这部分代码处理哈希冲突的情况。哈希冲突发生时,同一个索引位置可能会有多个节点。为了处理这些节点,HashMap使用了链表和红黑树两种数据结构。
- 覆盖旧值:首先检查当前节点的哈希值和键是否与待插入的键值对相同。如果相同,直接进行覆盖。
- 红黑树节点:如果当前节点是红黑树节点,通过
putTreeVal方法处理。 - 链表节点:如果是链表节点,通过遍历链表找到适当的位置插入新节点。如果链表长度超过阈值(默认是8),会将链表转换为红黑树。
4. 维护结构修改计数和大小
++modCount;
if (++size > threshold)resize();
afterNodeInsertion(evict);
return null;
最后,更新modCount,表示HashMap的结构发生了变化。然后检查当前大小是否超过阈值,如果超过则进行扩容。扩容通过resize方法完成。最后调用afterNodeInsertion方法执行插入后的操作,返回null表示插入成功且没有旧值被覆盖。
三、关键细节与实现原理
1. 哈希函数
在HashMap中,哈希函数的质量直接影响哈希表的性能。HashMap通过对键的哈希码进行二次扰动来减少哈希冲突,提高哈希分布的均匀性。
2. 链表与红黑树
HashMap最初使用链表来处理哈希冲突,但链表在极端情况下会退化为线性查找,性能较差。为了解决这个问题,Java 8引入了红黑树,当链表长度超过阈值时(默认是8),会将链表转换为红黑树,以提高查找效率。
3. 扩容机制
HashMap的扩容机制通过resize方法实现。每次扩容都会将容量扩大为原来的两倍,并重新计算所有元素的索引位置。扩容是一个代价较高的操作,因此HashMap会尽量延迟扩容,直到元素数量超过阈值。
四、优化与最佳实践
1. 初始容量设置
为了减少扩容次数,可以在创建HashMap时设置一个合理的初始容量。这样在插入大量元素时,可以减少扩容操作,提高性能。
2. 合理选择负载因子
HashMap的负载因子(默认是0.75)决定了扩容的阈值。负载因子越大,空间利用率越高,但哈希冲突的概率也越大。根据具体情况,可以选择合适的负载因子,以平衡空间利用率和性能。
3. 避免使用可变对象作为键
如果使用可变对象作为键,在对象状态变化后,哈希值可能会改变,导致无法正确查找到对应的值。因此,尽量使用不可变对象(如String、Integer等)作为键。
五、总结
通过对HashMap中putVal方法的深入分析,我们了解了HashMap处理插入操作的详细过程,包括初始化、哈希冲突处理、扩容机制等。理解这些内部细节,不仅有助于我们更好地使用HashMap,还能在需要时对其进行优化,提升程序的性能。
在实际开发中,选择合适的数据结构和算法是至关重要的。HashMap作为Java中常用的集合类,其高效的实现和灵活的使用方式,使得它在众多应用场景中得到了广泛的应用。希望通过本文的分析,能够帮助读者更深入地理解HashMap的内部机制,提高编程技巧和代码质量。
相关文章:

深入解析Java HashMap的putVal方法
Java中的HashMap是我们在开发中经常使用的集合之一,它提供了基于哈希表的数据存储方式,使得对数据的插入、删除和查找操作都具有较高的效率。在本文中,我们将深入解析HashMap中的putVal方法,揭示其内部工作原理。通过对代码的逐行…...
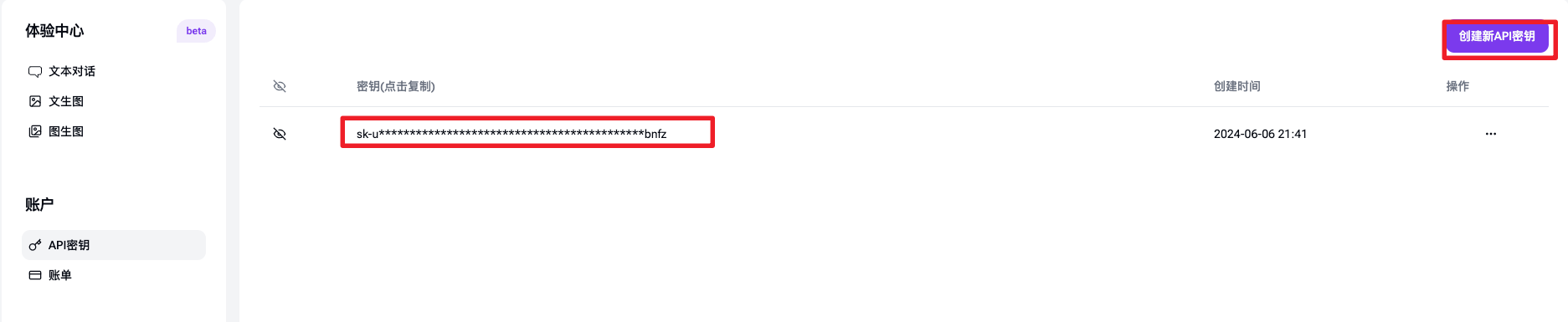
使用智谱 GLM-4-9B 和 SiliconCloud 云服务快速构建一个编码类智能体应用
本篇文章我将介绍使用智谱 AI 最新开源的 GLM-4-9B 模型和 GenAI 云服务 SiliconCloud 快速构建一个 RAG 应用,首先我会详细介绍下 GLM-4-9B 模型的能力情况和开源限制,以及 SiliconCloud 的使用介绍,最后构建一个编码类智能体应用作为测试。…...
关于vue2 antd 碰到的问题总结下
1.关于vue2 antd 视图更新问题 1.一种强制更新 Vue2是通过用Object…defineProperty来设置数据的getter和setter实现对数据和以及视图改变的监听的。对于数组和对象这种引用类型来说,getter和setter无法检测到它们内部的变化。用这种 this.$set(this.form, "…...

常见的api:Runtime Object
一.Runtiem的成员方法 1.getRuntime() 当前系统的运行环境 2.exit 停止虚拟机 3.avaliableProcessors 获取Cpu线程的参数 4.maxMemory JVM能从系统中获取总内存大小(单位byte) 5.totalMemory JVM已经从系统中获取总内大小(单位byte) 6.freeMemory JVM剩余内存大小(…...

Linux守护进程揭秘-无声无息运行在后台
在Linux系统中,有一些特殊的进程悄无声息地运行在后台,如同坚实的基石支撑着整个系统的运转。它们就是众所周知的守护进程(Daemon)。本文将为你揭开守护进程的神秘面纱,探讨它们的本质特征、创建过程,以及如何重定向它们的输入输出…...
模型基础笔记0.1.096)
python-Bert(谷歌非官方产品)模型基础笔记0.1.096
python-bert模型基础笔记0.1.015 TODOLIST官网中的微调样例代码Bert模型的微调限制Bert的适合的场景Bert多语言和中文模型Bert模型两大类官方建议模型Bert模型中名字的含义Bert模型包含的文件Bert系列模型参数介绍微调与迁移学习区别Bert微调的方式Pre-training和Fine-tuning区…...

Linux的命令补全脚本
一 linux命令补全脚本 Linux的命令补全脚本是一个强大且高效的工具,它能够极大地提高用户在命令行界面的工作效率。这种脚本通过自动完成部分输入的命令或参数,帮助用户减少敲击键盘的次数并降低出错率。接下来将深入探讨其工作原理、安装方式以及如何自…...

前端 JS 经典:打印对象的 bug
1. 问题 相信这个 console 打印语句的 bug,其实小伙伴们是遇到过的,就是你有一个对象,通过 console,打印一次,然后经过一些处理,再通过 console 打印,发现两次打印的结果是一样的,第…...

大型语言模型简介
大型语言模型简介 大型语言模型 (LLM) 是一种深度学习算法,可以使用非常大的数据集识别、总结、翻译、预测和生成内容。 文章目录 大型语言模型简介什么是大型语言模型?为什么大型语言模型很重要?什么是大型语言模型示例?大型语…...

javaWeb4 Maven
Maven-管理和构建java项目的工具 基于POM的概念 1.依赖管理:管理项目依赖的jar包 ,避免版本冲突 2.统一项目结构:比如统一eclipse IDEA等开发工具 3.项目构建:标准跨平台的自动化项目构建方式。有标准构建流程,能快速…...

eclipse连接后端mysql数据库并且查询
教学视频:https://www.bilibili.com/video/BV1mK4y157kE/?spm_id_from333.337.search-card.all.click&vd_source26e80390f500a7ceea611e29c7bcea38本人eclipse和up主不同的地方如下,右键项目名称->build path->configure build path->Libr…...
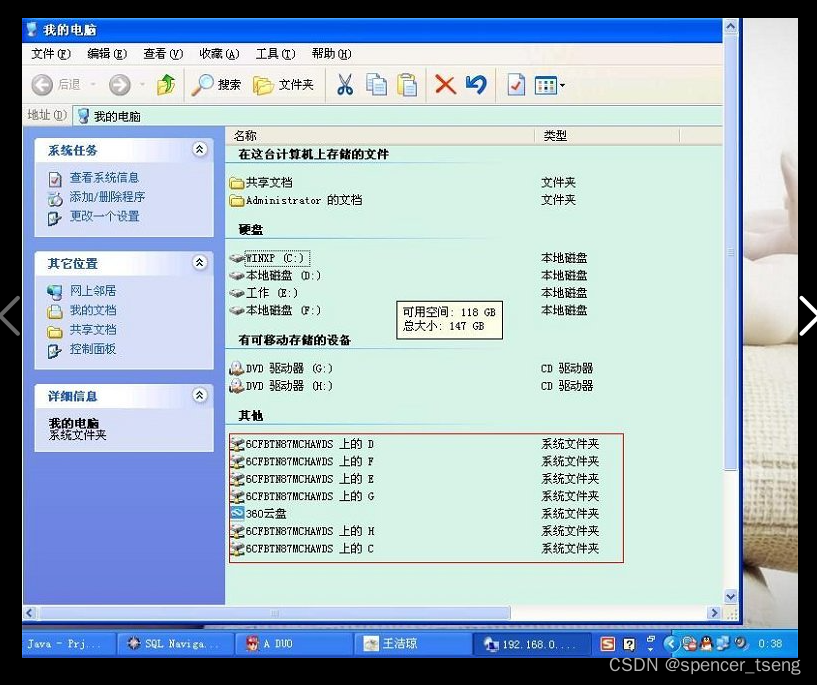
Windows mstsc
windows mstsc 局域网远程计算机192.168.0.113为例,远程控制命令mstsc...
百度/迅雷/夸克,网盘免费加速,已破!
哈喽,各位小伙伴们好,我是给大家带来各类黑科技与前沿资讯的小武。 之前给大家安利了百度网盘及迅雷的加速方法,详细方法及获取参考之前文章: 刚刚!度盘、某雷已破!速度50M/s! 本次主要介绍夸…...
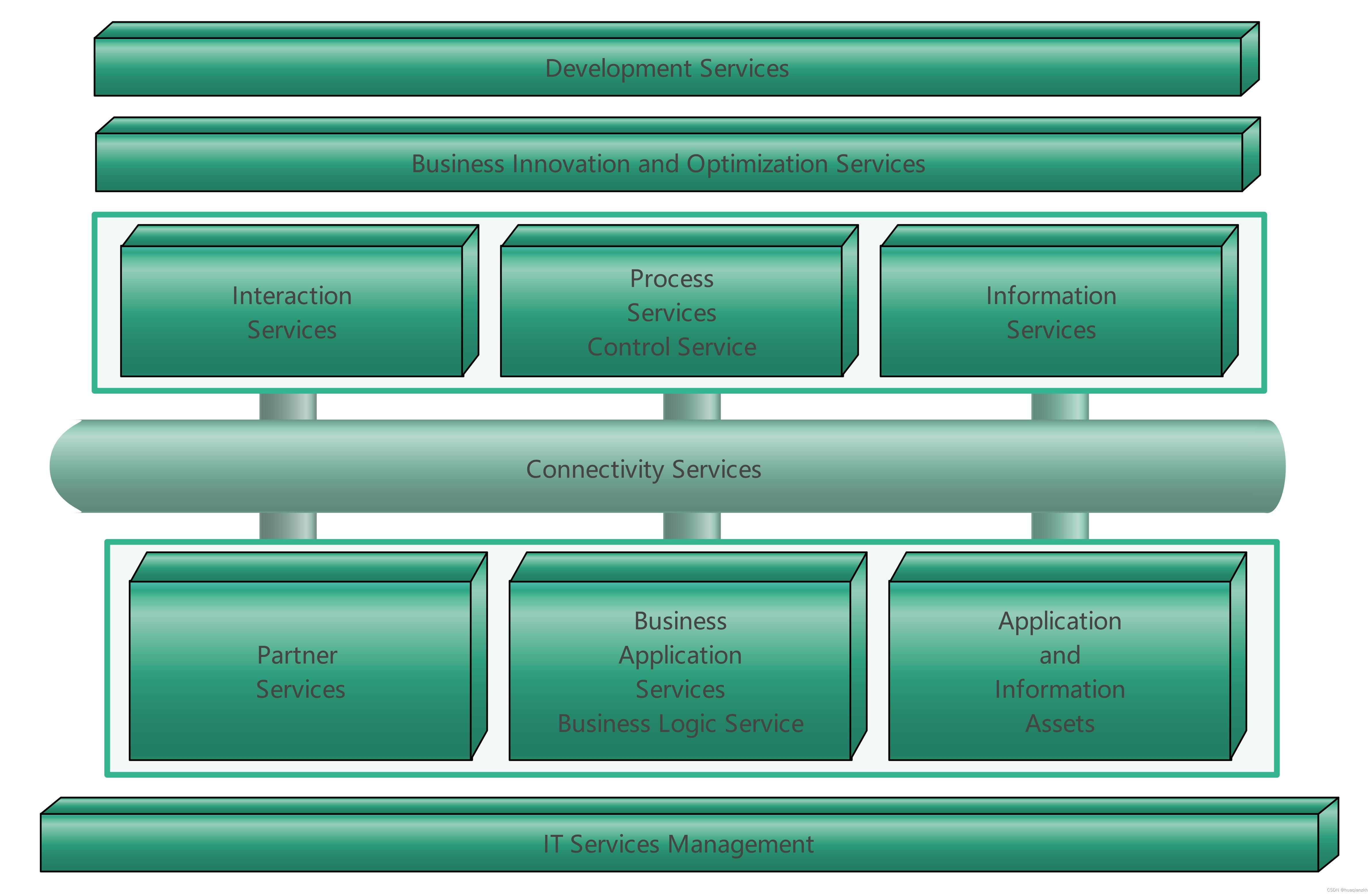
SOA的参考架构
1. 以服务为中心的企业集成架构 IBM的Websphere业务集成参考架构(如图1所示,以下称参考架构)是典型的以服务为中心的企业集成架构。 图1 IBM WebSphere业务集成参考架构 以服务为中心的企业集成采用“关注点分离(Separation of Co…...

前端开发-表单和表格的区别
在前端开发中,表单(Form)和表格(Table)同样具有不同的用途和结构: 前端表单(Form): 数据收集:表单用于收集用户输入的数据,如文本输入、选择选项等。用户交…...

Data Management Controls
Data Browsing and Analysis Data Grid 以标准表格或其他视图格式(例如,带状网格、卡片、瓷砖)显示数据。Vertical Grid 以表格形式显示数据,数据字段显示为行,记录显示为列。Pivot Grid 模拟微软Excel的枢轴表功…...

NextJs 数据篇 - 数据获取 | 缓存 | Server Actions
NextJs 数据篇 - 数据获取 | 缓存 | Server Actions 前言一. 数据获取 fetch1.1 缓存 caching① 服务端组件使用fetch② 路由处理器 GET 请求使用fetch 1.2 重新验证 revalidating① 基于时间的重新验证② 按需重新验证revalidatePathrevalidateTag 1.3 缓存的退出方式 二. Ser…...

腾讯开源人像照片生成视频模型V-Express
网址 https://github.com/tencent-ailab/V-Express 下面是github里的翻译: 在人像视频生成领域,使用单张图像生成人像视频变得越来越普遍。一种常见的方法是利用生成模型来增强受控发电的适配器。 但是,控制信号的强度可能会有所不同&…...
)
pytorch使用DataParallel并行化保存和加载模型(单卡、多卡各种情况讲解)
话不多说,直接进入正题。 !!!不过要注意一点,本文保存模型采用的都是只保存模型参数的情况,而不是保存整个模型的情况。一定要看清楚再用啊! 1 单卡训练,单卡加载 #保存模型 torc…...
PS初级|写在纸上的字怎么抠成透明背景?
前言 上一次咱们讲了很多很多很多的抠图教程,这次继续。。。最近有小伙伴问我:如果是写在纸上的字,要怎么把它抠成透明背景。 这个其实很简单,直接来说就是选择通道来抠。但有一点要注意的是,写在纸上的字࿰…...

C盘空间管理完全指南:从清理到预防,根治飘红
你的C盘是否在不知不觉中已经飘红?在清理文件的路上,你是否曾因误删系统文件而追悔莫及? C盘告急的普遍困境 每当Windows系统运行缓慢,或安装新软件时弹出磁盘空间不足的提示,用户的第一反应往往是查看C盘使用情况。…...

LLM长文本处理实战:模块化分割策略与向量化预处理指南
1. 项目概述:一个为LLM打造的文本处理中心如果你和我一样,经常和大型语言模型打交道,无论是用它来总结文档、分析代码,还是处理客服对话,那你肯定遇到过这个痛点:喂给模型的文本太长了怎么办?模…...

Crush性能优化指南:如何利用半懒惰流处理大数据集
Crush性能优化指南:如何利用半懒惰流处理大数据集 【免费下载链接】crush Crush is a command line shell that is also a powerful modern programming language. 项目地址: https://gitcode.com/gh_mirrors/cr/crush Crush是一个革命性的命令行shell和现代…...

原生TypeScript待办清单:纯前端架构、观察者模式与拖拽排序实践
1. 项目概述:一个由AI辅助构思的现代化待办清单最近在整理个人项目时,我重新审视了一个之前用TypeScript写的待办清单应用。这个项目的初衷很简单:我需要一个极简、快速、完全由我掌控的待办工具,它不需要登录,数据就存…...

边缘计算中的机器学习能效优化与混合架构实践
1. 边缘计算中的机器学习能效革命在智能手表、健康监测设备等穿戴式设备中,实时运行机器学习模型一直是个棘手的问题。传统方案要么耗电太快导致续航崩溃,要么精度太低失去实用价值。我们团队最近实验的一组数据很能说明问题:在常见的运动识别…...

用Python和MATLAB复现DMD算法:从COVID-19死亡数据预测到动态模态分解实战
用Python和MATLAB复现DMD算法:从COVID-19死亡数据预测到动态模态分解实战 动态模态分解(Dynamic Mode Decomposition, DMD)作为一种数据驱动的建模方法,近年来在复杂系统分析、流体力学和流行病预测等领域展现出强大潜力。本文将带…...

从RIPv2到RIPng:IPv6时代路由协议的演进与实战部署
1. 从RIPv2到RIPng:为什么IPv6需要新的路由协议? 第一次在实验室配置RIPv2时,我盯着那些IPv4地址看了整整三天。直到某天客户突然要求支持IPv6,才发现这个诞生于1988年的老协议已经跟不上时代——就像用传呼机收发4K视频ÿ…...
核心算法,搞定面试高频考点)
C++数据结构进阶|排序:吃透O(n log n)核心算法,搞定面试高频考点
文章目录 前言 一、希尔排序(Shell Sort)—— 插入排序的进阶优化版 二、快速排序(Quick Sort)—— C面试手写高频,实际开发首选 三、归并排序(Merge Sort)—— 稳定排序的核心选择 四、堆排…...

BBDown终极指南:5分钟掌握B站视频本地化完整解决方案
BBDown终极指南:5分钟掌握B站视频本地化完整解决方案 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown 在数字内容爆炸的时代,你是否曾为无法离线观看B站优质视频…...

全网没人敢说,关于中小企业AI营销一体机到底是卖硬件还是卖落地闭环的屎盆子,我先扣为敬。
[实话] 干这行十年,我拍着桌子定过一条死规矩。三个不做:不做只卖盒子不管结果的,不做签完合同就消失的,不做让你自己研究三个月才能用的。[实话] 现在的“AI营销一体机”,90%都是在收智商税。我见过太多老板ÿ…...