【Go语言精进之路】构建高效Go程序:掌握变量、常量声明法则与iota在枚举中的奥秘


文章目录
- 引言
- 一、变量
- 1.1 基础知识
- 1.2 包级变量的声明形式深入解析
- 📌 声明并同时显式初始化
- 📌 声明但延迟初始化
- 📌 声明聚类与就近原则
- 1.3 局部变量的声明形式深入探讨
- 📌 延迟初始化的局部变量声明
- 📌 显式初始化的局部变量与短变量声明
- 📌 分支控制中的短变量声明
- 二、常量
- 2.1 Go语言常量溯源:从C语言到Go
- 📌 C语言中的常量
- 📌 Go语言中的常量进化
- 2.2 有类型常量带来的烦恼
- 📌 类型转换的显式性
- 📌 限制通用性
- 📌 类型错误的频繁出现
- 2.3 无类型常量消除烦恼,简化代码
- 📌 动态类型推导
- 📌 增强通用性和代码复用
- 📌 减少类型错误
- 三、使用 iota 实现枚举常量
- 3.1 基础用法:自动递增
- 3.2 高级用法:表达式、继承、显式赋值、空标识符与重置
- 四、总结
引言
Go 语言作为现代编程领域的重要成员,对变量和常量的处理体现了静态类型语言的精髓。本文深入剖析了 Go 语言中变量的基础知识、包级与局部变量的声明形式,以及常量的设计哲学与实践中的考量,旨在为开发者揭示 Go 在数据存储与类型管理方面的独特机制与优化策略。

一、变量
1.1 基础知识
变量是编程语言的基本构成元素,它们担当存储信息与实现数据操作的重任。Go语言中,变量声明是一项核心机制,深刻反映了语言本身的设计原则:追求简洁性、确保运行效率及强化代码的安全性。恰当的变量声明策略,对于提升程序代码的可读性、维护便捷性以及执行效能具有不可或缺的作用。

在Go语言体系中,变量是存储数据的基本单元,其核心功能在于保存程序运行过程中的信息。每个变量都被赋予了特定的数据类型,这些类型涵盖了诸如整数(int)、浮点数(float)、字符串(string) 等多种基本类型以及其他复合类型。数据类型定义了变量能够存储值的范围和类型,确保了数据的准确性和一致性。
Go 作为一种静态类型语言,在程序编译阶段就要求明确指定每个变量的类型。这意味着:
- 类型固定性:一旦为变量指定了一个类型,如
int或string,该变量就只能存储该类型的数据,无法在程序运行过程中改变其类型。 - 编译时检查:编译器会在编译阶段检查所有变量的使用是否符合其声明的类型,这样可以提前发现类型不匹配的错误,避免运行时出现意外行为。
- 性能优势:由于类型在编译时已确定,编译器可以进行更多的优化,提升程序的执行效率。
例如,声明一个整型变量counter并赋值为10,其类型int在编译时就需要被明确指定,并且后续尝试给counter赋值为字符串将导致编译错误:
var counter int = 10
// counter = "This will not compile" // 错误:类型不匹配
这种静态类型的特性,促使开发者在编码初期就必须仔细考虑数据的表示,促进了代码的严谨性和可维护性。
在Go中,变量除了按数据类型划分外,还可以根据其声明的位置和作用域分为两大类:包级变量和局部变量。
1.2 包级变量的声明形式深入解析
包级变量是定义在包作用域内的变量,它们具有全局可见性,对包内的所有函数开放访问权限。这类变量通常用于存储那些在包的多个组件间共享的状态或配置信息。
📌 声明并同时显式初始化
当你希望变量在声明时即赋予一个具体的初始值,可以采用这种方式。这不仅明确了变量的用途,有时还能帮助减少因未初始化变量而引发的错误。
package mainvar version string = "1.0.0" // 包级变量声明并显式初始化为版本号
📌 声明但延迟初始化
在某些场景下,你可能知道某个变量将被使用,但其确切的初始化值在声明时刻还未知或不适合立即设定。此时,你可以先声明变量而不进行初始化。Go会自动为这些变量赋予其类型的零值(如int的零值为0,bool为false等)。
var debugMode bool // 声明一个布尔型包级变量,初始化为false(零值)
📌 声明聚类与就近原则
Go允许在一个var声明中声明多个变量,这称为声明聚类,可以使得代码更为紧凑。此外,Go遵循就近原则,如果在更小的作用域内重新声明了同名变量,那么原始的包级变量在该作用域内将被遮蔽。
var (connectionTimeout time.Duration = 5 * time.Second // 初始化连接超时时间maxAttempts int = 3 // 最大尝试次数// ...其他变量声明
)func handleRequest() {var maxAttempts int = 10 // 函数内重新声明maxAttempts,遮蔽包级变量// 此处的maxAttempts指的是局部变量10
}
在上面的例子中,handleRequest函数内部重新声明了一个名为maxAttempts的局部变量,这表明在该函数内部,maxAttempts引用的是局部变量10,而非包级变量3,展示了就近原则的应用。
1.3 局部变量的声明形式深入探讨
局部变量作为函数或代码块内部的存储单元,其生命期严格限定于声明它们的上下文内,这有助于保持代码的模块化和清晰度。接下来,我们将详细探讨局部变量的几种声明形式及其在实际编程中的应用策略。
📌 延迟初始化的局部变量声明
在某些情况下,你可能需要 先声明变量,稍后再根据逻辑流程决定其初始化值。这时,采用传统的var声明形式是合适的。
func calculateSum(numbers []int) int {var sum int // 声明局部变量sum但不立即初始化for _, number := range numbers {sum += number // 在循环中累加求和}return sum
}
📌 显式初始化的局部变量与短变量声明
Go推崇简洁性,特别是在类型可以从初始值直接推断的情况下,推荐使用短变量声明(:=)来声明并初始化局部变量。这种方式不仅减少了代码量,也增强了代码的可读性。
func greetUser(name string) {greeting := "Hello, " + name + "!" // 简洁声明并初始化fmt.Println(greeting)
}
📌 分支控制中的短变量声明
在条件语句或循环体中,利用短变量声明可以有效地管理临时变量,避免不必要的变量作用域扩散,使得代码更加紧凑且易于理解。
func processData(inputData map[string]int) {if value, exists := inputData["key"]; exists {// 使用value,已知存在} else {// 在else块内部声明新的value,避免污染外部作用域value := getDefaultData()// 处理defaultValue}
}func getDefaultData() int {return 0
}
总结而言,Go语言在局部变量声明上提供了丰富的机制,旨在提升代码的简洁性和执行效率。无论是通过传统的var声明进行延迟初始化,还是利用类型推断的短变量声明来简化代码,亦或是巧妙地在分支结构中应用短变量声明以增强代码逻辑的清晰度,都是为了帮助开发者编写出更加高效、易读、易维护的Go程序。
二、常量
2.1 Go语言常量溯源:从C语言到Go
在探索Go语言常量的设计理念之前,回顾一下C语言中的常量概念是十分有益的,因为C语言对许多现代编程语言的常量和变量处理方式有着深远的影响。

📌 C语言中的常量
在C语言中,常量分为以下几类:
- 字面常量:直接写在代码中的固定值,如
5,"Hello, World!",true等,它们没有名字,直接用于表达式。 - 符号常量:通过
#define预处理器指令定义,给一个固定值赋予一个名字,如#define PI 3.14159。符号常量在编译前会被替换为对应的值,因此不占用运行时内存,也没有类型信息。
C语言的常量系统相对简单,但也存在一些局限性:
- 类型不安全:符号常量(
#define)本质上是一种文本替换,编译器不做类型检查,可能导致类型错误。 - 缺乏类型灵活性:字面常量有固定的类型,而符号常量完全无类型,这限制了它们的使用场景。
- 表达式能力有限:C语言的常量表达式在编译时计算的能力有限,不支持复杂的计算或类型推导。
📌 Go语言中的常量进化
Go 语言设计者在设计常量系统时,既借鉴了C语言的优点,也针对其局限性进行了改进:
-
类型安全与灵活性:Go中的常量通过
const关键字声明,不仅支持基本类型,还可以是用户自定义类型。与C语言不同,Go的常量是有类型的,这保证了类型安全,同时允许在编译时进行类型推导和转换。 -
强大的编译时计算能力:Go支持在常量声明中使用几乎所有的算术和逻辑运算符,甚至支持位操作,使得编译时计算能力大大增强。这意味着可以在编译阶段完成更多工作,减少运行时负担。
-
iota与枚举:Go引入了
iota这个特殊的常量生成器,极大地简化了枚举类型的定义。iota在每个const声明块中自动递增,为创建有序的常量集合提供了一种简洁的方式。 -
无类型常量与类型推导:Go允许定义无类型常量,这些常量在使用时会根据上下文自动推断类型。这种机制既保留了灵活性,又保持了类型安全,减少了因类型转换带来的代码复杂度。
通过这些设计,Go语言的常量系统在继承C语言简单直接特性的基础上,进一步提升了类型安全、表达能力和编译时计算的灵活性,更好地满足了现代软件开发的需求。
2.2 有类型常量带来的烦恼
在编程语言的领域里,有类型常量(Typed Constants)扮演着双重角色:一方面,它们为程序设计引入了清晰的明确性,确保了数据的安全性;另一方面,在诸如 Go 或某些特定用途的 C++ 等类型系统严格的语言中,它们也带来了一系列潜在的挑战与烦恼。以下是几个关键方面的深入探讨。
📌 类型转换的显式性
有类型常量的一个核心烦恼在于跨类型操作时的显式类型转换需求。这意味着,当有类型常量参与不同数据类型间的运算或赋值时,程序员必须手动执行类型转换,以确保类型兼容性。这样做虽确保了类型安全,却可能增加代码的复杂度,尤其是在涉及多步骤计算或复杂表达式时。
package mainimport "fmt"func main() {const intConstant int = 42const floatConstant float64 = 3.14// 显示转换intConstant为float64以进行加法操作sum := floatConstant + float64(intConstant)fmt.Println(sum) // 输出: 45.14
}
此例中,即使目的很明确——将intConstant与floatConstant相加,也必须通过float64(intConstant)显式转换类型,增加了实现的繁琐度。
📌 限制通用性
有类型常量的另一个局限在于其固定性。一旦定义了常量的类型,该类型便不可更改,这在一定程度上限制了常量在多上下文中的复用性。特别是在需要适应多种类型处理逻辑的场景,这可能导致需要定义多个相同值但类型不同的常量。
package mainimport ("fmt"
)func processIntValue(i int) {fmt.Println("Processing an integer:", i)
}func processFloatValue(f float64) {fmt.Println("Processing a float:", f)
}func main() {const myConst int = 10// 为了适应不同函数的参数类型,需要进行类型转换processFloatValue(float64(myConst)) // 需要转换
}
尽管myConst的值对于processIntValue和processFloatValue都适用,但其定义为int类型,迫使我们在调用processFloatValue时进行类型转换,体现了类型固定性对通用性的影响。
📌 类型错误的频繁出现
在大型项目开发中,由于有类型常量的严格类型约束,开发者在不恰当使用时容易遇到编译时类型不匹配的错误,尤其当常量被广泛应用时,此类错误的排查可能变得相当耗时且繁琐。
package mainimport ("fmt"
)const strConstant string = "GoLang"func expectsInt(i int) {fmt.Println("Received int:", i)
}func main() {// 这里尝试赋值会导致编译错误,因为类型不匹配// expectsInt(strConstant)
}
尝试将strConstant(一个字符串类型常量)传递给期望整型参数的expectsInt函数,编译器会立即指出类型不匹配的错误,虽然这保障了类型安全,但也意味着在编写和维护时必须时刻警惕类型的一致性。
综上所述,有类型常量的这些“烦恼”实际上是类型安全机制的双刃剑,它们确保了程序的健壮性,但同时也对开发者提出了更高的要求,即在享受类型安全带来的好处的同时,也要妥善处理由此产生的额外复杂性。
2.3 无类型常量消除烦恼,简化代码
相较于有类型常量可能带来的种种挑战,无类型常量(Untyped Constants) 在Go语言中提供了一种更为灵活和简洁的解决方案,有效消除了上述烦恼,让代码编写和维护变得更加顺畅。
📌 动态类型推导
无类型常量最大的特点在于其能够在赋值或参与表达式时根据上下文自动推导类型,从而免去了显式类型转换的需要。这不仅减少了代码量,也提升了代码的可读性和维护性。
package mainimport "fmt"func main() {const untypedConst = 42 // 无类型常量// 自动推导为int类型intVar := untypedConstfmt.Println("As int:", intVar)// 自动推导为float64类型floatVar := untypedConst + 3.14fmt.Println("As float64:", floatVar)
}
在这个例子中,untypedConst作为无类型常量,既可以直接赋值给int类型的变量,也能参与浮点数运算自动转化为float64类型,大大简化了代码并提高了灵活性。
📌 增强通用性和代码复用
无类型常量的另一大优势在于其泛用性。由于没有固定类型,它们可以在多种类型上下文中复用,无需为每个上下文单独定义类型化的常量,这对于需要跨类型共享相同基础值的场景尤为有用。
package mainimport "fmt"func processAnyTypeValue[T any](v T) {fmt.Printf("Processing value of type %T: %v\n", v)
}func main() {const universalConst = 10 // 无类型常量// 直接用于不同类型的函数调用,无需转换processAnyTypeValue(universalConst)processAnyTypeValue(float64(universalConst)) // 显示转换示例,实际并不需要,仅展示灵活性
}
通过泛型函数processAnyTypeValue的演示,可以看到无类型常量universalConst能够轻松应用于各种类型参数,显著增强了代码的通用性和复用性。
📌 减少类型错误
由于无类型常量在使用时由编译器根据上下文自动推导类型,这在很大程度上减少了由于类型不匹配导致的编译错误。开发者不再需要担心因忘记类型转换而引发的错误,提高了开发效率和代码的稳定性。
通过以上分析与示例,可以看出,无类型常量通过其动态类型推导的特性,有效解决了有类型常量带来的类型转换显式性、通用性限制以及类型错误频繁出现等问题,从而简化了代码,提升了编程体验。在 Go 语言中明智地利用无类型常量,能够让我们编写出更加清晰、灵活和高效的代码。
三、使用 iota 实现枚举常量
在 Go 语言中,iota是一个非常特殊的常量生成器,它在常量定义中自动递增,为开发者提供了一种极其优雅的方式来定义枚举类型的常量序列。通过iota,我们可以避免手动指定每个常量的值,从而简化代码,减少错误,提高可读性。下面是iota在实现枚举常量中的应用细节和示例。

3.1 基础用法:自动递增
package mainimport "fmt"// 利用const关键字定义枚举常量,并利用iota实现自动递增
const (// 首个常量未直接指定值,iota默认从0开始Sunday = iotaMonday // 自动递增到1Tuesday // 自动递增到2Wednesday // 自动递增到3Thursday // 自动递增到4Friday // 自动递增到5Saturday // 自动递增到6
)func main() {fmt.Println("Sunday:", Sunday) // 输出: Sunday: 0fmt.Println("Monday:", Monday) // 输出: Monday: 1fmt.Println("Saturday:", Saturday) // 输出: Saturday: 6
}
这段代码展示了如何使用iota来定义枚举类型的常量。下面是对代码的简要说明和其输出结果的解释:
-
定义枚举: 通过
const关键字定义了一组表示星期的枚举常量。每个常量都隐式地被赋予了一个递增的整数值,起始于0,这是iota的默认行为。 -
iota的使用:
Sunday = iota表示Sunday的值为0,因为这是iota第一次出现的地方,默认从0开始。- 随后,对于
Monday到Saturday,每遇到一个新的常量声明行,iota的值就自动递增1。因此,Monday是1,Tuesday是2,依此类推,直到Saturday为6。
-
代码执行结果:
fmt.Println("Sunday:", Sunday)输出Sunday: 0fmt.Println("Monday:", Monday)输出Monday: 1fmt.Println("Saturday:", Saturday)输出Saturday: 6
这段代码简洁明了地展示了如何利用iota来避免为每个枚举值手动赋值,提高了代码的简洁性和维护性。这种枚举方式在Go语言中非常常见,尤其适用于那些需要定义一系列相关常量的场景。
3.2 高级用法:表达式、继承、显式赋值、空标识符与重置
package mainimport "fmt"const (Red = iota // iota初始为0,所以Red的值为0 Green // iota递增到1,所以Green的值为1 Blue // iota递增到2,所以Blue的值为2Yellow = iota * 10 // iota此时为3,所以Yellow的值为3 * 10 = 30Purple // iota此递增到4,由于没有显式赋值,所以继承上方的iota * 10规则,Purple的值为4 * 10 = 40Black = iota // 显式赋值为iota,此时iota值为5,所以Black为5_ // 空标识符,表示忽略该值 6White = iota + 9 // iota为7,显式iota加9之后变为16_ // 16+1=17Cyan = iota // 重置为iota本身的值 9
)func main() {fmt.Println("Red:", Red) // 输出为0fmt.Println("Green:", Green) // 输出为1fmt.Println("Blue:", Blue) // 输出为2fmt.Println("Yellow:", Yellow) // 输出为30fmt.Println("Purple:", Purple) // 输出为40fmt.Println("Black:", Black) // 输出为5fmt.Println("White:", White) // 输出为16fmt.Println("Cyan:", Cyan) // 输出为9
}
在Go语言的const块中,iota是一个预定义的、只能在const声明中使用的计数器,初始值为0,并在每个const规范组(即没有新的const关键字开始的地方)的每行常量声明中递增。这种特性允许你创建一系列递增或基于特定规则的常量值。
在上述代码中,iota的用法展示了它的基本和高级特性:
-
初始化和递增:
Red = iota:iota初始为0,所以Red的值为0。Green:没有显式赋值,iota递增到1,所以Green的值为1。Blue:同样,iota递增到2,Blue的值为2。
-
表达式和继承:
Yellow = iota * 10:此时iota为3,所以Yellow的值为3 * 10 = 30。Purple:没有显式赋值,但由于Purple紧跟在Yellow之后,并且Yellow使用了iota * 10的表达式,所以Purple继承了这个表达式并使用当前的iota值(4)进行计算,得到4 * 10 = 40。
-
显式赋值:
Black = iota:这里明确地将Black赋值为当前的iota值,即5(因为Purple之后iota递增了)。
-
空标识符:
_:空标识符用于忽略某个值。在这里,它用于跳过iota的当前值(6),而不将其分配给任何常量。
-
重置和再次递增:
White = iota + 9:此时iota为7(因为_之后递增了),所以White的值为7 + 9 = 16。- 紧接着的
_再次使iota递增到8,但这个值被忽略了。 Cyan = iota:此时iota为9,所以Cyan的值为9。
注意,在 Go 中,const块中的iota是块作用域的,即如果你开始一个新的const块(即新的一组常量声明,前面有const关键字),iota会被重置为0。但在同一个const块中,即使中间插入了其他非常量声明(如变量声明或函数声明),iota的递增也会继续。
此外,iota的使用通常用于创建一组逻辑上相关或按某种模式递增的常量值,使得代码更加清晰和易于维护。然而,过度使用或滥用iota可能会使代码难以阅读和理解,所以应该谨慎使用。
四、总结
Go语言在变量和常量的处理上展现了其卓越的设计和强大的功能:
- 通过静态类型系统,Go 确保了变量声明的严谨性和类型安全,减少了运行时错误。包级变量和局部变量的灵活声明方式,包括显式初始化和类型推断的短变量声明,不仅增强了代码的可读性和可维护性,还提高了执行效率。
- 在常量管理上,Go通过有类型常量和无类型常量的结合,以及引入独特的
iota计数器,为开发者提供了一种简洁而强大的枚举实现方式。iota的高级运用,如表达式结合、值重置和跳过特定值等,进一步丰富了枚举常量的定义方式,使Go 成为编写高质量、高性能软件的理想选择。
📌 变量声明与管理
- Go语言通过静态类型系统强化了变量声明的严谨性,要求在编译阶段明确指定变量类型,从而确保了类型安全和早期错误检测。
- 包级变量具有全局可见性,用于跨函数共享数据,可通过显式初始化或声明后赋零值来定义,支持在同一
var语句中声明多个变量体现声明聚类。 - 局部变量限于函数或代码块内,通过传统
var声明、类型推断的短变量声明(:=)等方式灵活定义,增强了代码简洁性和执行效率,尤其是在分支控制中展现了短变量声明的价值。
📌 常量的演变与优化
- 从C语言常量设计的回顾到Go语言的改进,突出了Go在常量系统上的进步,如类型安全、强大的编译时计算能力、以及通过
iota实现的枚举简化。 - 有类型常量虽然确保了数据的安全性和精确性,但可能伴随显式类型转换的繁琐、通用性受限及类型错误问题。
- 无类型常量通过自动类型推导简化了代码,提高了灵活性和复用性,减轻了类型转换的负担,特别是在多类型上下文中展现了其价值。
📌 iota与枚举常量的高级运用
- iota作为Go中独特的常量计数器,自动递增并在常量声明中提供了一种简洁的枚举实现方式,支持表达式结合、值重置、跳过特定值等高级特性。
- 通过案例分析,展示了如何利用
iota不仅实现基础的递增枚举,还能通过表达式定义复杂的枚举逻辑,如乘法增长、显式赋值重置iota计数等,极大丰富了枚举常量的定义方式和应用场景。
综上所述,Go 语言在变量和常量的处理上,通过静态类型系统、灵活的声明形式、以及
iota在枚举中的创新应用,体现了对代码清晰度、类型安全、执行效率的高度重视,同时也兼顾了开发者的便利性和编程的灵活性。这些特性共同支撑了 Go 语言成为编写高质量、高性能软件的优选工具。
相关文章:
【Go语言精进之路】构建高效Go程序:掌握变量、常量声明法则与iota在枚举中的奥秘
🔥 个人主页:空白诗 文章目录 引言一、变量1.1 基础知识1.2 包级变量的声明形式深入解析📌 声明并同时显式初始化📌 声明但延迟初始化📌 声明聚类与就近原则 1.3 局部变量的声明形式深入探讨📌 延迟初始化的…...

python记录之bool
在Python中,bool 是一个内置的数据类型,用于表示逻辑值:True 或 False。虽然这个数据类型看起来很简单,但在编程中它扮演着至关重要的角色,特别是在条件语句、循环以及许多其他逻辑操作中。以下是对Python bool 的深入…...

加密经济浪潮:探索Web3对金融体系的颠覆
随着区块链技术的快速发展,加密经济正在成为全球金融领域的一股新的浪潮。而Web3作为下一代互联网的代表,以其去中心化、可编程的特性,正深刻影响着传统金融体系的格局和运作方式。本文将深入探讨加密经济对金融体系的颠覆,探索We…...
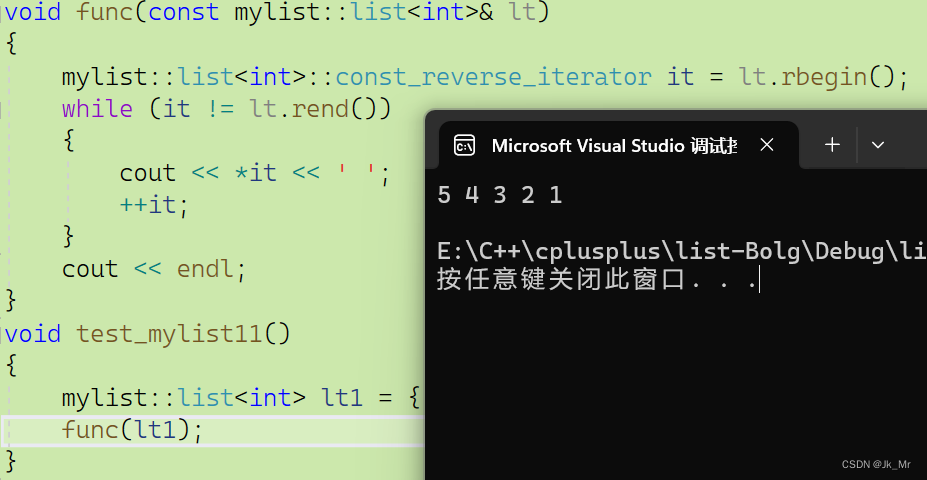
list的简单模拟实现
文章目录 目录 文章目录 前言 一、使用list时的注意事项 1.list不支持std库中的sort排序 2.去重操作 3.splice拼接 二、list的接口实现 1.源码中的节点 2.源码中的构造函数 3.哨兵位头节点 4.尾插和头插 5.迭代器* 5.1 迭代器中的operator和-- 5.2其他迭代器中的接口 5.3迭代器…...

深入解析Java HashMap的putVal方法
Java中的HashMap是我们在开发中经常使用的集合之一,它提供了基于哈希表的数据存储方式,使得对数据的插入、删除和查找操作都具有较高的效率。在本文中,我们将深入解析HashMap中的putVal方法,揭示其内部工作原理。通过对代码的逐行…...
使用智谱 GLM-4-9B 和 SiliconCloud 云服务快速构建一个编码类智能体应用
本篇文章我将介绍使用智谱 AI 最新开源的 GLM-4-9B 模型和 GenAI 云服务 SiliconCloud 快速构建一个 RAG 应用,首先我会详细介绍下 GLM-4-9B 模型的能力情况和开源限制,以及 SiliconCloud 的使用介绍,最后构建一个编码类智能体应用作为测试。…...
关于vue2 antd 碰到的问题总结下
1.关于vue2 antd 视图更新问题 1.一种强制更新 Vue2是通过用Object…defineProperty来设置数据的getter和setter实现对数据和以及视图改变的监听的。对于数组和对象这种引用类型来说,getter和setter无法检测到它们内部的变化。用这种 this.$set(this.form, "…...

常见的api:Runtime Object
一.Runtiem的成员方法 1.getRuntime() 当前系统的运行环境 2.exit 停止虚拟机 3.avaliableProcessors 获取Cpu线程的参数 4.maxMemory JVM能从系统中获取总内存大小(单位byte) 5.totalMemory JVM已经从系统中获取总内大小(单位byte) 6.freeMemory JVM剩余内存大小(…...

Linux守护进程揭秘-无声无息运行在后台
在Linux系统中,有一些特殊的进程悄无声息地运行在后台,如同坚实的基石支撑着整个系统的运转。它们就是众所周知的守护进程(Daemon)。本文将为你揭开守护进程的神秘面纱,探讨它们的本质特征、创建过程,以及如何重定向它们的输入输出…...
模型基础笔记0.1.096)
python-Bert(谷歌非官方产品)模型基础笔记0.1.096
python-bert模型基础笔记0.1.015 TODOLIST官网中的微调样例代码Bert模型的微调限制Bert的适合的场景Bert多语言和中文模型Bert模型两大类官方建议模型Bert模型中名字的含义Bert模型包含的文件Bert系列模型参数介绍微调与迁移学习区别Bert微调的方式Pre-training和Fine-tuning区…...

Linux的命令补全脚本
一 linux命令补全脚本 Linux的命令补全脚本是一个强大且高效的工具,它能够极大地提高用户在命令行界面的工作效率。这种脚本通过自动完成部分输入的命令或参数,帮助用户减少敲击键盘的次数并降低出错率。接下来将深入探讨其工作原理、安装方式以及如何自…...

前端 JS 经典:打印对象的 bug
1. 问题 相信这个 console 打印语句的 bug,其实小伙伴们是遇到过的,就是你有一个对象,通过 console,打印一次,然后经过一些处理,再通过 console 打印,发现两次打印的结果是一样的,第…...

大型语言模型简介
大型语言模型简介 大型语言模型 (LLM) 是一种深度学习算法,可以使用非常大的数据集识别、总结、翻译、预测和生成内容。 文章目录 大型语言模型简介什么是大型语言模型?为什么大型语言模型很重要?什么是大型语言模型示例?大型语…...

javaWeb4 Maven
Maven-管理和构建java项目的工具 基于POM的概念 1.依赖管理:管理项目依赖的jar包 ,避免版本冲突 2.统一项目结构:比如统一eclipse IDEA等开发工具 3.项目构建:标准跨平台的自动化项目构建方式。有标准构建流程,能快速…...

eclipse连接后端mysql数据库并且查询
教学视频:https://www.bilibili.com/video/BV1mK4y157kE/?spm_id_from333.337.search-card.all.click&vd_source26e80390f500a7ceea611e29c7bcea38本人eclipse和up主不同的地方如下,右键项目名称->build path->configure build path->Libr…...
Windows mstsc
windows mstsc 局域网远程计算机192.168.0.113为例,远程控制命令mstsc...
百度/迅雷/夸克,网盘免费加速,已破!
哈喽,各位小伙伴们好,我是给大家带来各类黑科技与前沿资讯的小武。 之前给大家安利了百度网盘及迅雷的加速方法,详细方法及获取参考之前文章: 刚刚!度盘、某雷已破!速度50M/s! 本次主要介绍夸…...
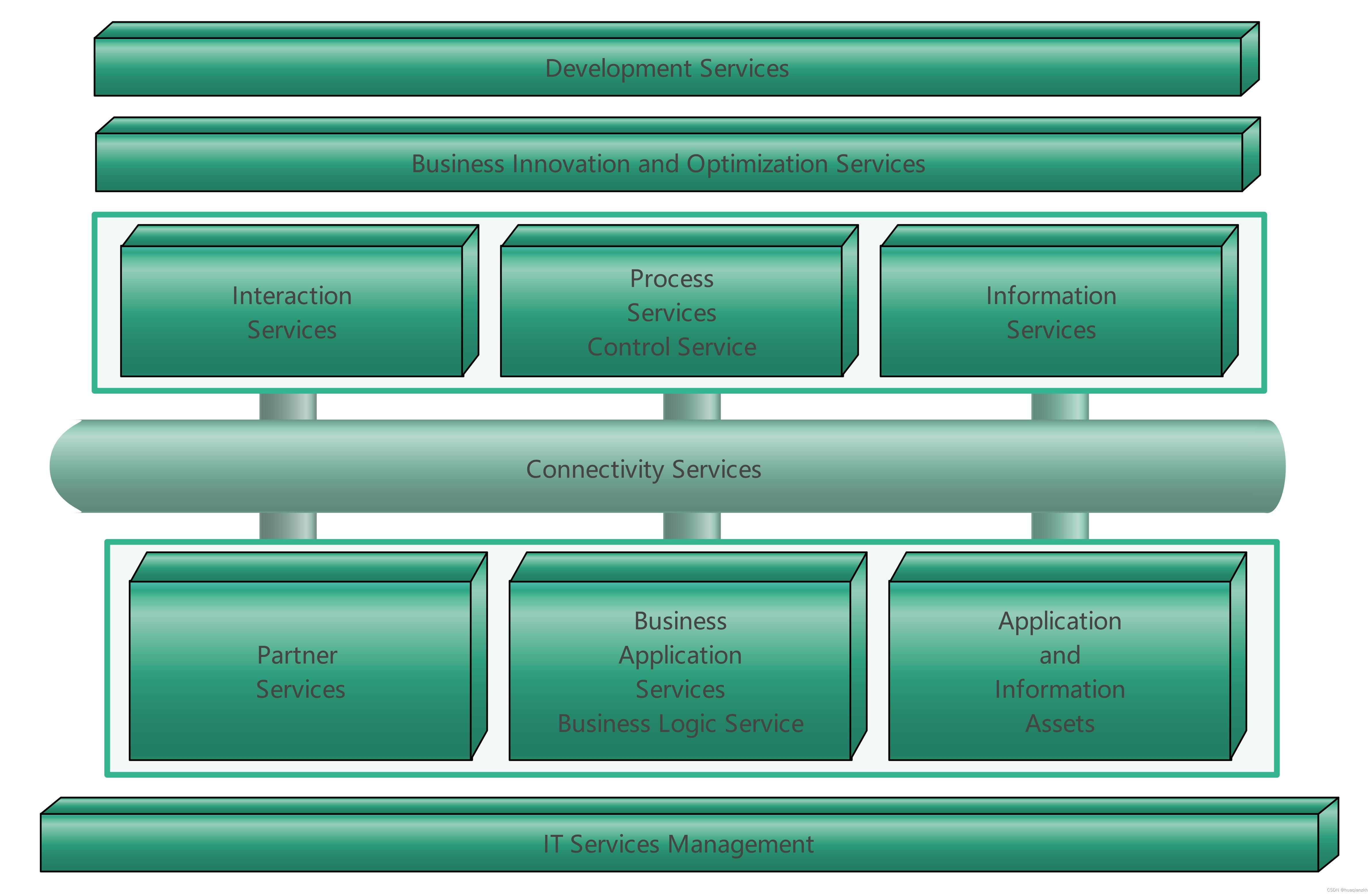
SOA的参考架构
1. 以服务为中心的企业集成架构 IBM的Websphere业务集成参考架构(如图1所示,以下称参考架构)是典型的以服务为中心的企业集成架构。 图1 IBM WebSphere业务集成参考架构 以服务为中心的企业集成采用“关注点分离(Separation of Co…...

前端开发-表单和表格的区别
在前端开发中,表单(Form)和表格(Table)同样具有不同的用途和结构: 前端表单(Form): 数据收集:表单用于收集用户输入的数据,如文本输入、选择选项等。用户交…...

Data Management Controls
Data Browsing and Analysis Data Grid 以标准表格或其他视图格式(例如,带状网格、卡片、瓷砖)显示数据。Vertical Grid 以表格形式显示数据,数据字段显示为行,记录显示为列。Pivot Grid 模拟微软Excel的枢轴表功…...

用电脑自动玩小红书,OpenClaw+ADB让效率翻倍!附详细教程“
本文介绍了如何使用OpenClaw(运行在MacOS上)结合ADB工具实现Android手机的自动化操作。内容涵盖Android手机配置(开启开发者选项和USB调试)、MacOS环境准备(安装ADB工具和配置ADBKeyboard支持中文输入)&…...

企业微信代开发应用:CallBackUrl验证失败排查与CorpID加密升级实战
1. 企业微信代开发应用验证失败的典型场景 最近不少服务商朋友反馈,代开发应用在验证CallBackUrl时频繁失败。这个问题其实源于企业微信在2022年6月底进行的一次安全升级。当时官方发布公告称,为了提升账户安全性,所有新建的代开发应用都需要…...

AI智能体技能库架构设计与实现:从标准化到工程化实践
1. 项目概述:从零构建一个AI智能体技能库最近在GitHub上看到一个挺有意思的项目,叫leon2k2k2k/agent-skills。光看名字,你可能觉得这又是一个关于AI智能体(Agent)的普通代码仓库。但作为一个在AI应用开发领域摸爬滚打了…...

Task GCP终极指南:如何在谷歌云平台上实现高效任务调度与自动化构建 [特殊字符]
Task GCP终极指南:如何在谷歌云平台上实现高效任务调度与自动化构建 🚀 【免费下载链接】task A fast, cross-platform build tool inspired by Make, designed for modern workflows. 项目地址: https://gitcode.com/gh_mirrors/ta/task 在现代化…...

React Native Actions Sheet源码解析:深入理解其架构与实现原理
React Native Actions Sheet源码解析:深入理解其架构与实现原理 【免费下载链接】react-native-actions-sheet A Cross Platform(Android, iOS & Web) ActionSheet with a flexible api, native performance for react native. Create anything you want inside…...

最小扩张三角剖分:算法优化与计算几何实践
1. 最小扩张三角剖分问题概述在计算几何领域,最小扩张三角剖分(Minimum Dilation Triangulation, MDT)是一个经典的优化问题。给定平面上的n个点集P,MDT的目标是找到一个三角剖分T,使得对于P中的任意两点s和tÿ…...

在株洲如何根据个人需求选择合适的床垫?
如何根据个人需求选择合适的床垫?在快节奏的现代生活中,一张舒适的床垫对于保证良好的睡眠质量至关重要。然而,面对市场上琳琅满目的床垫产品,如何根据个人需求选择一款合适的床垫呢?本文将从多个维度出发,…...

Cursor Pro免费升级完整指南:3分钟突破使用限制的实用教程
Cursor Pro免费升级完整指南:3分钟突破使用限制的实用教程 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

观察Taotoken在多模型同时高并发调用下的服务表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型同时高并发调用下的服务表现 在构建依赖大模型能力的应用时,一个常见的工程挑战是如何应对突发的…...

DeFi预测市场套利机器人:延迟套利与结构性对冲策略详解
1. 项目概述:在2.7秒的缝隙中寻找确定性如果你在DeFi世界里寻找一种“低风险、高确定性”的套利机会,那么Polymarket这类预测市场可能是一个被低估的宝藏。这个项目,genoshide/polymarket-arbitrage-trading-bot,本质上是一个高度…...