【因果推断python】24_倾向得分2
目录
倾向加权
倾向得分估计
倾向加权

好的,我们得到了倾向得分。怎么办?就像我说过的,我们需要做的就是以此为条件。例如,我们可以运行一个线性回归,它仅以倾向得分为条件,而不是所有的 X。现在,让我们看一下只使用倾向得分而不使用其他任何东西的技术。这个想法是用倾向得分写出均值的条件差
我们可以进一步简化这一点,但让我们这样看一下,因为它让我们对倾向得分的作用有了一些很好的直觉。第一项是估计 Y1。它应用于所有接受干预的对象,并按接受干预的逆概率对它们的权重进行缩放。这样做的目的是使那些接受干预的可能性非常低的人权重增加。想想看,这是有道理的,对吧?如果某人接受干预的可能性很低,那么该人看起来就像未经干预的人。然而,同一个人受到了干预。这一定很有趣。我们有一个看起来像未经干预的被干预对象,因此我们将给予该实体较高的权重。这样做的目的是创建一个与原始全样本相同大小的群体,但每个人都受到干预。出于同样的原因,另一个术语着眼于未经干预的人,并赋予那些看起来像经过干预的人很高的权重。这个估计器被称为干预加权的逆概率(IPTW),因为它通过接受除它所接受的干预之外的某种其他影响的概率来缩放每个单元的权重。
在下面在图片中,就展示了这种加权的作用。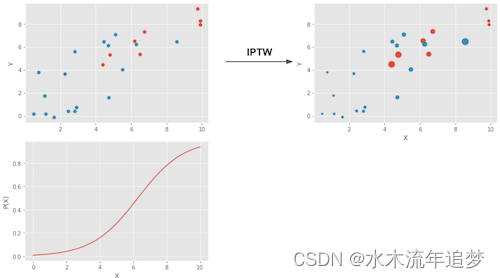
左上图显示了原始数据。蓝点是未干预的,红点是干预过的。底部图显示了倾向得分 P(x)。注意它是如何在 0 和 1 之间的,并且随着 X 的增加而增长。最后,右上图是加权后的数据。注意更靠左的红色(处理过的)(倾向得分较低)的权重更高。同样,右侧的蓝色图也具有更高的权重。现在我们有了直觉,我们可以将上面的术语简化为如果我们对 X 进行积分,它就会成为我们的倾向得分加权估计量。
请注意,此估计器要求 P(x) 和 1−P(x) 大于零。换句话说,这意味着每个人都需要至少有一些机会接受干预和不接受干预。说明这一点的另一种方式是干预和未干预样本的分布需要重叠。这是因果推理的正值假设(positivity assumption)。它也具有直觉意义。如果干预和未干预的样本不重叠,这意味着它们非常不同,我将无法将一组的效果外推到另一组。这种推断并非不可能(回归做到了),但它非常危险。这就像在实验中测试一种新药,只有男性接受治疗,然后假设女性对它的反应同样好。
倾向得分估计
在一个理想的世界中,我们会有真实的倾向得分P(X)。 然而,在实践中,分配干预的机制是未知的,我们需要用对它的估计来替换真实的倾向得分 。 这样做的一种常见方法是使用逻辑回归,但也可以使用其他机器学习方法,如梯度提升(尽管它需要一些额外的步骤来避免过度拟合)。
在这里,我将坚持逻辑回归。 这意味着我必须将数据集中的分类特征转换为假人。
categ = ["ethnicity", "gender", "school_urbanicity"]
cont = ["school_mindset", "school_achievement", "school_ethnic_minority", "school_poverty", "school_size"]data_with_categ = pd.concat([data.drop(columns=categ), # dataset without the categorical featurespd.get_dummies(data[categ], columns=categ, drop_first=False)# categorical features converted to dummies
], axis=1)print(data_with_categ.shape)(10391, 32)现在让我们使用逻辑回归(logistic regression)来估计倾向得分。
from sklearn.linear_model import LogisticRegressionT = 'intervention'
Y = 'achievement_score'
X = data_with_categ.columns.drop(['schoolid', T, Y])ps_model = LogisticRegression(C=1e6).fit(data_with_categ[X], data_with_categ[T])data_ps = data.assign(propensity_score=ps_model.predict_proba(data_with_categ[X])[:, 1])data_ps[["intervention", "achievement_score", "propensity_score"]].head()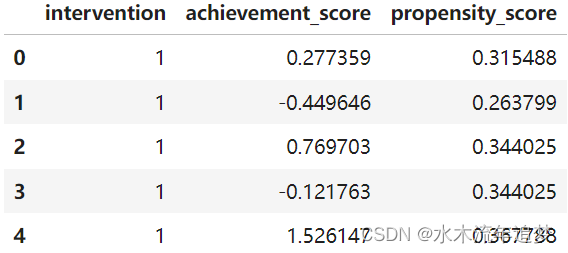
首先,我们可以确保倾向得分权重确实重建了每个人都得到干预的人群。 通过产生权重1/P(X),它创建了每个人都被对待的群体,并通过提供权重1/(1−P(X)),它创建了群体,其中 每个人都没有得到干预。
weight_t = 1/data_ps.query("intervention==1")["propensity_score"]
weight_nt = 1/(1-data_ps.query("intervention==0")["propensity_score"])
print("Original Sample Size", data.shape[0])
print("Treated Population Sample Size", sum(weight_t))
print("Untreated Population Sample Size", sum(weight_nt))Original Sample Size 10391 Treated Population Sample Size 10388.604824722199 Untreated Population Sample Size 10391.4305248224
我们还可以使用倾向得分来找到混淆的证据。 如果人群中的一个细分群体的倾向得分高于另一个群体,这意味着不是随机的东西导致了干预。 如果同样的事情也导致了结果,我们就会感到困惑。 在我们的案例中,我们可以看到自称更有野心的学生也更有可能参加成长心态研讨会。
sns.boxplot(x="success_expect", y="propensity_score", data=data_ps)
plt.title("Confounding Evidence");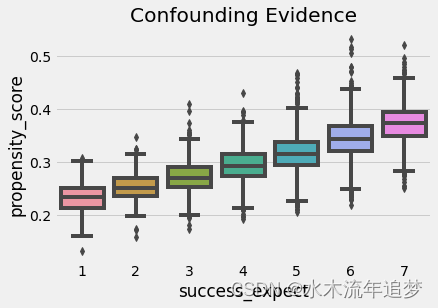
我们还必须检查干预和未干预人群之间是否存在重叠。 为此,我们可以看到倾向得分在未干预者和被干预者上的经验分布。 查看下图,我们可以看到没有人的倾向得分为零,即使在倾向得分较低的区域,我们也可以找到接受干预和未接受干预的个体。 这就是我们所说的经过良好平衡的干预和未干预人群。
sns.distplot(data_ps.query("intervention==0")["propensity_score"], kde=False, label="Non Treated")
sns.distplot(data_ps.query("intervention==1")["propensity_score"], kde=False, label="Treated")
plt.title("Positivity Check")
plt.legend();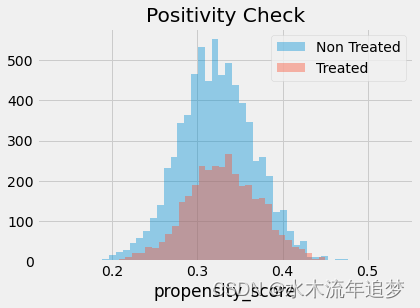
最后,我们可以使用倾向得分加权估计器来估计平均干预效果(ATE)。
weight = ((data_ps["intervention"]-data_ps["propensity_score"]) /(data_ps["propensity_score"]*(1-data_ps["propensity_score"])))y1 = sum(data_ps.query("intervention==1")["achievement_score"]*weight_t) / len(data)
y0 = sum(data_ps.query("intervention==0")["achievement_score"]*weight_nt) / len(data)ate = np.mean(weight * data_ps["achievement_score"])print("Y1:", y1)
print("Y0:", y0)
print("ATE", np.mean(weight * data_ps["achievement_score"]))Y1: 0.2595774244866067 Y0: -0.12892090981713242 ATE 0.38849833430373715
倾向得分加权表示,就成就而言,我们应该期望接受干预的个体比未经干预的同伴高 0.38 个标准差。 我们还可以看到,如果没有人得到干预,我们应该期望成绩的总体水平比现在低 0.12 个标准差。 同样的道理,如果我们为每个人提供研讨会,我们应该期望一般成就水平高出 0.25 个标准差。 将此与我们通过简单比较干预和未干预得到的 0.47 ATE 估计值进行对比。 这证明我们的偏差确实是正向的,并且控制 X 让我们对成长心态的影响有了更适度的估计。
相关文章:
【因果推断python】24_倾向得分2
目录 倾向加权 倾向得分估计 倾向加权 好的,我们得到了倾向得分。怎么办?就像我说过的,我们需要做的就是以此为条件。例如,我们可以运行一个线性回归,它仅以倾向得分为条件,而不是所有的 X。现在ÿ…...
)
部件库(Widget Factory)
部件库(Widget Factory) 部件库,也被称为Widget Factory,是一个强大的工具,用于创建、存储和管理可重用的软件组件。在本文中,我们将深入探讨部件库的概念、重要性、以及如何在现代软件开发中使用它。 什么是部件库? 部件库是一个集合,其中包含了各种预先构建的软件…...

tomcat启动闪退解决办法
检查端口冲突: Tomcat默认使用8080端口,如果该端口已被其他应用占用,Tomcat将无法启动。解决办法:更改Tomcat使用的端口号或关闭占用该端口的其他应用。 更改Tomcat端口号:打开Tomcat安装目录下的conf文件夹࿰…...
OpenStack云平台管理
OpenStack云平台管理 文章目录 OpenStack云平台管理资源列表基础环境一、部署Openstack二、创建网络和路由2.1、删除默认的网络2.2、创建网络和路由2.2.1、创建外部网络2.2.2、创建内部网络 2.3、创建路由 三、创建实例3.1、配置实例3.2、配置NAT转换 四、绑定浮动IP地址五、添…...
)
内部类(超详细)
内部类 一:初始内部类 (1)什么是内部类? 类的五大成员:属性、方法、构造方法、代码块、内部类 举例:在A类的内部定义B类,B类就被称为内部类 public class Outer {// 外部类public class Inter {// 内部类} } public class Test {// 外部其他类public static void m…...

Android的SELinux详解
标签: Android的SELinux详解; SELinux;Enforcing; Android的SELinux详解 概述 SELinux(Security-Enhanced Linux)是一个Linux内核模块和用户空间工具的集合,提供强制访问控制(MAC)机制。Android引入SELinux以增强系统的安全性,通过限制进程的权限来减少安全漏洞的…...

R语言中的列表list
基础 在R语言中的最常用的向量有两种: 第一种,原子向量 像字符型向量,数值型向量,逻辑型向量这些,它们共有的一个特点是,向量里面的值是同质的。当你用数值型向量时,里面所有值都是数值型的。…...

10、有条件提前退出关键字Return From Keyword If【robot framework】
在 Robot Framework 中,Return From Keyword If 是一个有用的关键字,它允许你在特定条件下从关键字中返回。这在需要在满足某个条件时提前退出关键字的情况下特别有用。 以下是 Return From Keyword If 的语法和使用示例: 语法 Return From…...
JAVA开发的一套(智造制造领航者云MES系统成品源码)saas云MES制造执行系统源码,全套源码,支持二次开发
JAVA开发的一套(智造制造领航者云MES系统成品源码)saas云MES制造执行系统源码,全套源码,支持二次开发 1990年11月,美国先进制造研究中心AMR(Advanced Manufacturing Research)就提出了MES&#…...

探究JSON和XML:两种常见的数据交换格式之异同
在软件开发和数据交换领域,JSON(JavaScript Object Notation)和XML(eXtensible Markup Language)是两种广泛使用的数据交换格式。它们都具有将数据结构化并在不同系统之间进行传输和解析的能力,但在实际应用…...

SQL查询的优化方案
SQL查询优化是一个重要的数据库管理任务,它可以帮助提升查询性能,减少响应时间和系统资源消耗。以下是一些关键的优化策略及其示例: 1. 使用索引 (Indexing) 优化说明: 索引能够显著加快数据检索速度,特别是对于大表上的查询。为…...

【C语言题解】1、写一个宏来计算结构体中某成员相对于首地址的偏移量;2、写一个宏来交换一个整数二进制的奇偶位
🥰欢迎关注 轻松拿捏C语言系列,来和 小哇 一起进步!✊ 🌈感谢大家的阅读、点赞、收藏和关注 💕希望大家喜欢我本次的讲解💕 目录👑 1、写一个宏,计算结构体中某变量相对于首地址的偏…...
LabVIEW阀性能试验台测控系统
本项目开发的阀性能试验台测控系统是为满足国家和企业相关标准而设计的,主要用于汽车气压制动系统控制装置和调节装置等产品的综合性能测试。系统采用工控机控制,配置电器控制柜,实现运动控制、开关量控制及传感器信号采集,具备数…...

Flutter 中的 LayoutBuilder 小部件:全面指南
Flutter 中的 LayoutBuilder 小部件:全面指南 Flutter 是一个功能丰富的 UI 框架,它允许开发者使用 Dart 语言来构建高性能、美观的跨平台应用。在 Flutter 的布局系统中,LayoutBuilder 是一个强大的组件,它可以根据父容器的约束…...

webman中创建udp服务
webman是workerman的web开发框架 可以很容易的开启udp服务 tcp建议使用gatewayworker webman GatewayWorker插件 创建udp服务: config/process.php中加入: return [// File update detection and automatic reloadmonitor > [ ...........], udp > [handler > p…...

Vue 学习笔记 总结
Vue.js 教程 | 菜鸟教程 (runoob.com) 放一下课上的内容 Vue练习 1、练习要求和实验2的用户注册一样,当用户输入后,能在下方显示用户输入的各项内容(不需要实现【重置】按钮) 2、实验报告中的实验小结部分来谈谈用JS、jQuery和…...
---分布式文件系统)
云计算导论(3)---分布式文件系统
文章目录 1. 概述2. 基本架构3. GFS和HDFS4. 云存储 1. 概述 1. 文件系统是操作系统用来组织磁盘文件的方法和数据结构。 传统的文件系统指各种UNIX平台的文件系统,包括UFS等,它们管理本地的磁盘存储资源,提供文件到存储位置的映射…...

后端进阶-分库分表
文章目录 为什么需要分库为什么需要分表 什么时候需要分库分表只需要分库只需要分表 分库分表解决方案垂直分库水平分库垂直分表水平分表 分库分表常用算法范围算法hash分片查表分片 分库分表模式客户端模式代理模式 今天跟着训练营学习了分库分表,整理了学习笔记。…...
Apple开发者应用商店(AppStore)描述文件及ADHOC描述文件生成
创建AD HOC描述文件 1.选中Profiles,然后点击加号创建 2.创建已注册设备可安装描述文件 3.选择要注册的id 4.选择证书 5.选择设备 6.输入文件名,点击生成 7.生成成功,点击下载...

【Git】修改设置 git 的 username、email
设置全局的本地用户名称和用户邮箱 参考:使用git config --global设置用户名和邮件 git config --global user.name "xxx" git config --global user.email "xxx.com"git config --list git config命令的–global参数,用了这个参数…...

从myplaces.shp到专题地图:手把手教你用QGIS C++ API实现点要素分级渲染
从myplaces.shp到专题地图:QGIS C API实现点要素分级渲染实战指南 当我们需要在桌面GIS应用中直观展示气象站降雨量、城市人口密度或商业网点销售额等连续型空间数据时,分级色彩渲染是最有效的可视化手段之一。本文将深入探讨如何利用QGIS强大的C API&am…...

终极跨平台漫画阅读方案:nhentai-cross全平台使用指南
终极跨平台漫画阅读方案:nhentai-cross全平台使用指南 【免费下载链接】nhentai-cross A nhentai client 项目地址: https://gitcode.com/gh_mirrors/nh/nhentai-cross 你是否厌倦了在不同设备间切换漫画阅读应用?nhentai-cross正是为你量身定制…...

基于LLM的长文本摘要工具SumGPT:从原理到本地化部署实战
1. 项目概述:一个为长文本摘要而生的智能工具最近在折腾一些文档处理的工作流,发现一个挺普遍但很烦人的痛点:面对动辄几十页的PDF报告、冗长的会议纪要或是海量的研究论文,想要快速抓住核心要点,简直像大海捞针。手动…...

基于大语言模型的本地语义搜索工具LLocalSearch部署与应用指南
1. 项目概述:一个能“读懂”你电脑的本地搜索工具 如果你和我一样,电脑里塞满了各种文档、邮件、聊天记录和代码片段,那么“找东西”这件事,绝对能排进日常最耗时的任务前三。传统的文件搜索,比如Windows自带的搜索或者…...

从零构建团队技能仓库:结构化知识管理与VuePress实践
1. 项目概述:一个技能仓库的诞生与价值 最近在整理团队内部的技术资产时,我一直在思考一个问题:如何让那些散落在个人笔记、项目代码片段、会议纪要里的“隐性知识”和“最佳实践”沉淀下来,变成团队可复用、可传承的“显性资产”…...

可穿戴电子模块化连接方案:5mm微型按扣实现电路板与织物的可插拔连接
1. 项目概述与核心思路在折腾可穿戴电子项目时,最让人头疼的问题之一,就是如何让电路板与衣物既可靠连接,又能方便地拆下来。传统的做法要么是用导电胶带粘(不牢靠、易氧化),要么是直接把线焊死在板子上然后…...

从零构建Go Web框架:解析the0极简框架的设计原理与实现
1. 项目概述:一个极简主义Web框架的诞生在Web开发的世界里,我们常常面临一个选择:是拥抱功能齐全但略显臃肿的“巨无霸”框架,还是追求极致轻量与灵活的自定义方案?对于许多追求性能、热爱掌控感,或是需要构…...

基于Claude API构建可编程AI智能体:从对话到自动化生产单元
1. 项目概述:从Claude中“招聘”一个AI伙伴最近在GitHub上看到一个挺有意思的项目,叫“hire-from-claude”。初看这个标题,你可能会有点摸不着头脑:Claude不是Anthropic公司开发的那个AI助手吗?怎么还能从它那里“招聘…...

EL电致发光线与3D打印技术打造可穿戴发光骨架服
1. 项目概述:当发光骨架“活”过来每年万圣节,看着满大街的“幽灵”和“僵尸”,我总想搞点不一样的。直到去年,我决定不再满足于商店里千篇一律的服装,而是想自己动手,做一件真正能“发光”的、有科技感的骨…...

开源AI应用开发平台TaskingAI:从RAG智能体到工作流编排实战
1. 项目概述:一个开源的AI应用开发平台最近在折腾AI应用开发的朋友,估计都绕不开一个核心痛点:想法很丰满,落地很骨感。你想做个智能客服、一个文档分析助手,或者一个个性化的内容生成工具,从模型调用、流程…...