使用亮数据代理IP爬取PubMed文章链接和邮箱地址
- 💂 个人网站:【 摸鱼游戏】【神级代码资源网站】【工具大全】
- 🤟 一站式轻松构建小程序、Web网站、移动应用:👉注册地址
- 🤟 基于Web端打造的:👉轻量化工具创作平台
- 💅 想寻找共同学习交流,摸鱼划水的小伙伴,请点击【全栈技术交流群】
目录
- 背景
- 爬取文章链接
- 使用代理 IP 进行爬取
- 爬取邮箱地址
- 完整代码
- 总结
背景
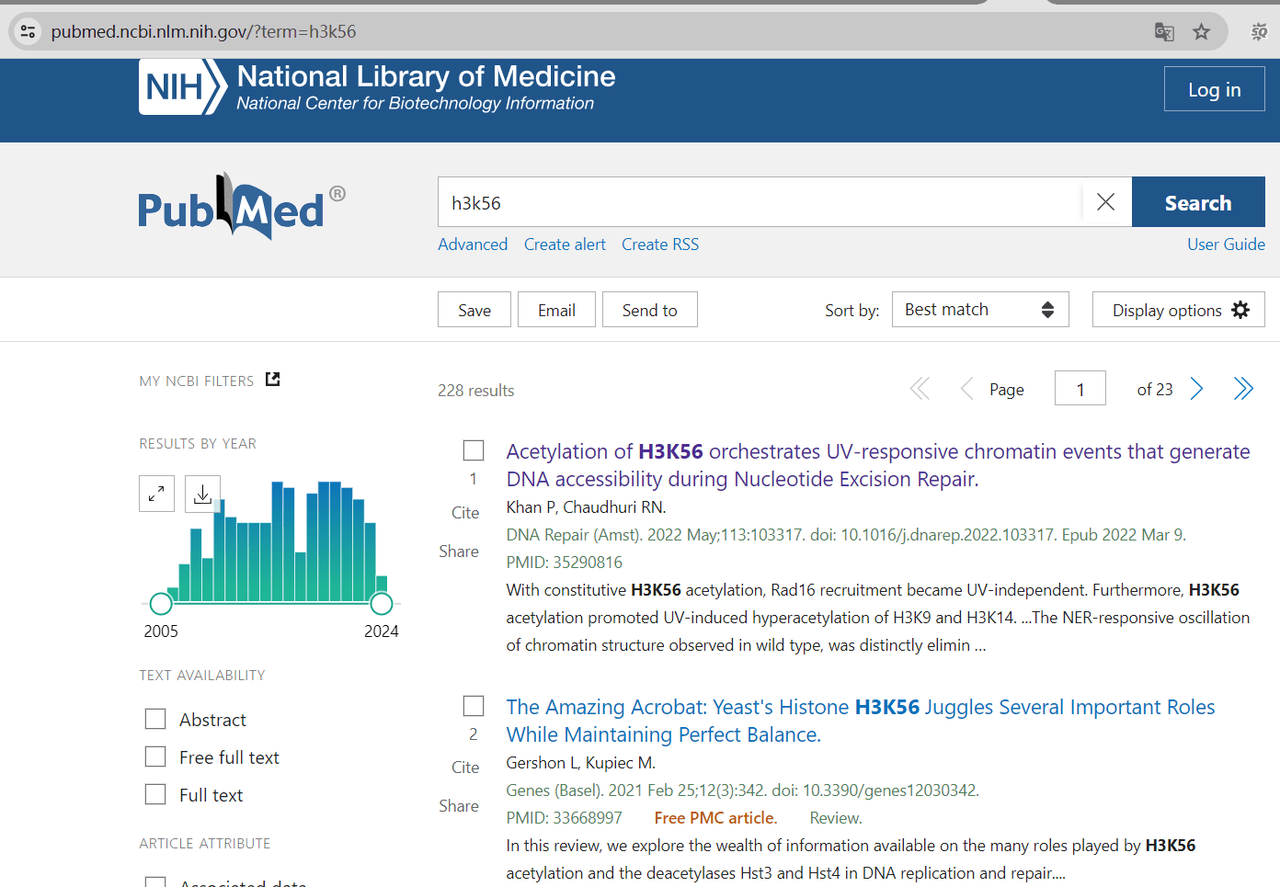
最近有同事询问我是否能够帮忙从 PubMed 网站上批量爬取一些邮箱地址,因为其中可能包含我们的潜在客户。我开始尝试了一下,首先选择了一个关键词 h3k56 进行搜索,得到了 228 个结果(文章)。
爬取文章链接
我们首先需要获取这些文章的链接。在 PubMed 网站上,每个页面只显示十篇文章,并且链接是按照一定规律排列的。
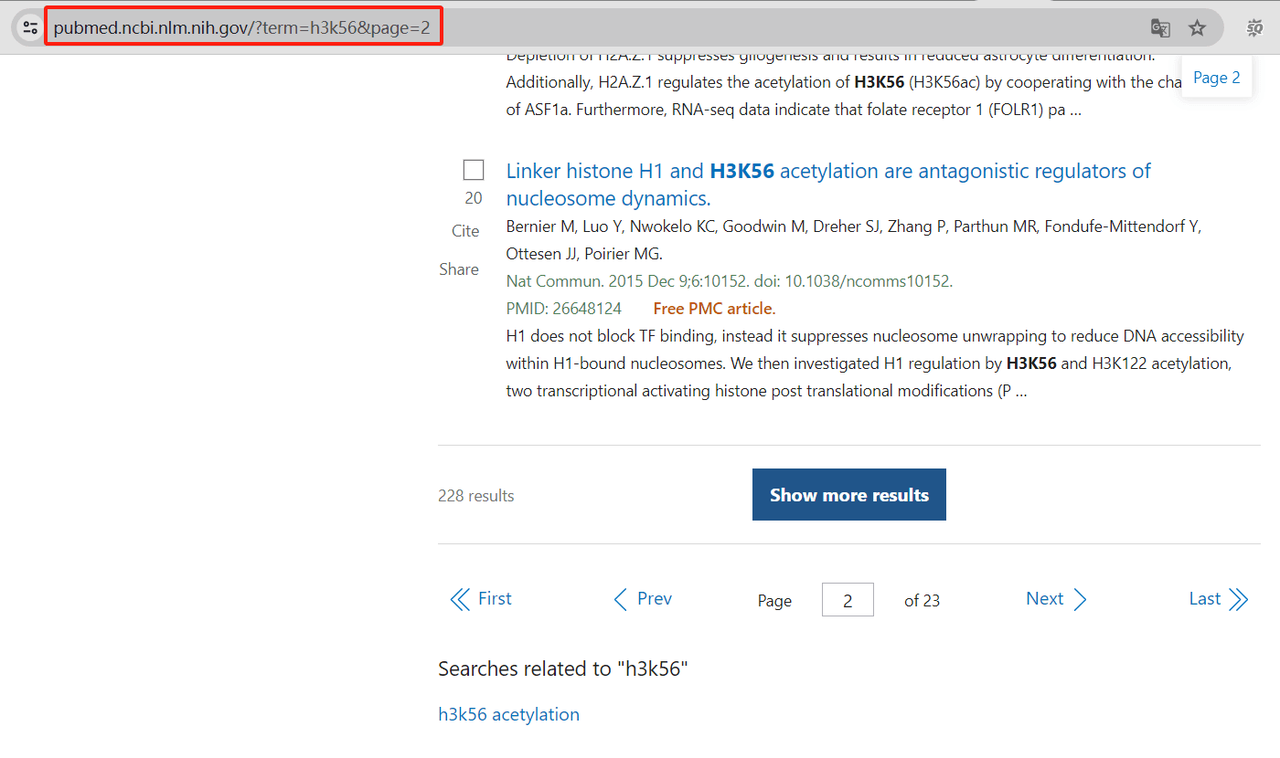
我们可以将搜索关键词 ‘h3k56’ 的 PubMed 搜索基础 URL 列出来:
base_url = "https://pubmed.ncbi.nlm.nih.gov/?term=h3k56&page="
接下来,我们可以使用 requests 库发送 HTTP 请求,获取网页内容。我们先获取每个页面的文章链接,然后将这些链接存储在一个列表中。以下是具体步骤:
首先,我们导入了 requests 和 BeautifulSoup 库,它们用于发送 HTTP 请求和解析 HTML 页面。
import requests
from bs4 import BeautifulSoup
然后,我们定义了基础的 PubMed 搜索 URL base_url,用于搜索关键词 'h3k56',以及总共的页面数 total_pages 和用于存储文章链接的列表 article_links。
base_url = "https://pubmed.ncbi.nlm.nih.gov/?term=h3k56&page=" # PubMed搜索基础URL,搜索关键词'h3k56'
total_pages = 23 # 总共的页面数
article_links = [] # 存储文章链接的列表
接下来,我们使用一个循环来遍历每一页的链接,并发送 HTTP 请求以获取页面内容。
for page_num in range(1, total_pages + 1):url = base_url + str(page_num) # 构建当前页面的完整URLresponse = requests.get(url) # 发起GET请求获取页面内容
在每次请求成功后,我们使用 BeautifulSoup 解析页面内容,查找具有 'docsum-title' 类的 <a> 标签,并提取其中的 href 属性,拼接成完整的文章链接,并将其添加到 article_links 列表中。
if response.status_code == 200: # 如果响应码为200,表示请求成功soup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup解析页面内容for a in soup.find_all('a', class_='docsum-title', href=True): # 查找具有'docsum-title'类的<a>标签article_links.append("https://pubmed.ncbi.nlm.nih.gov" + a['href']) # 将找到的文章链接添加到列表中
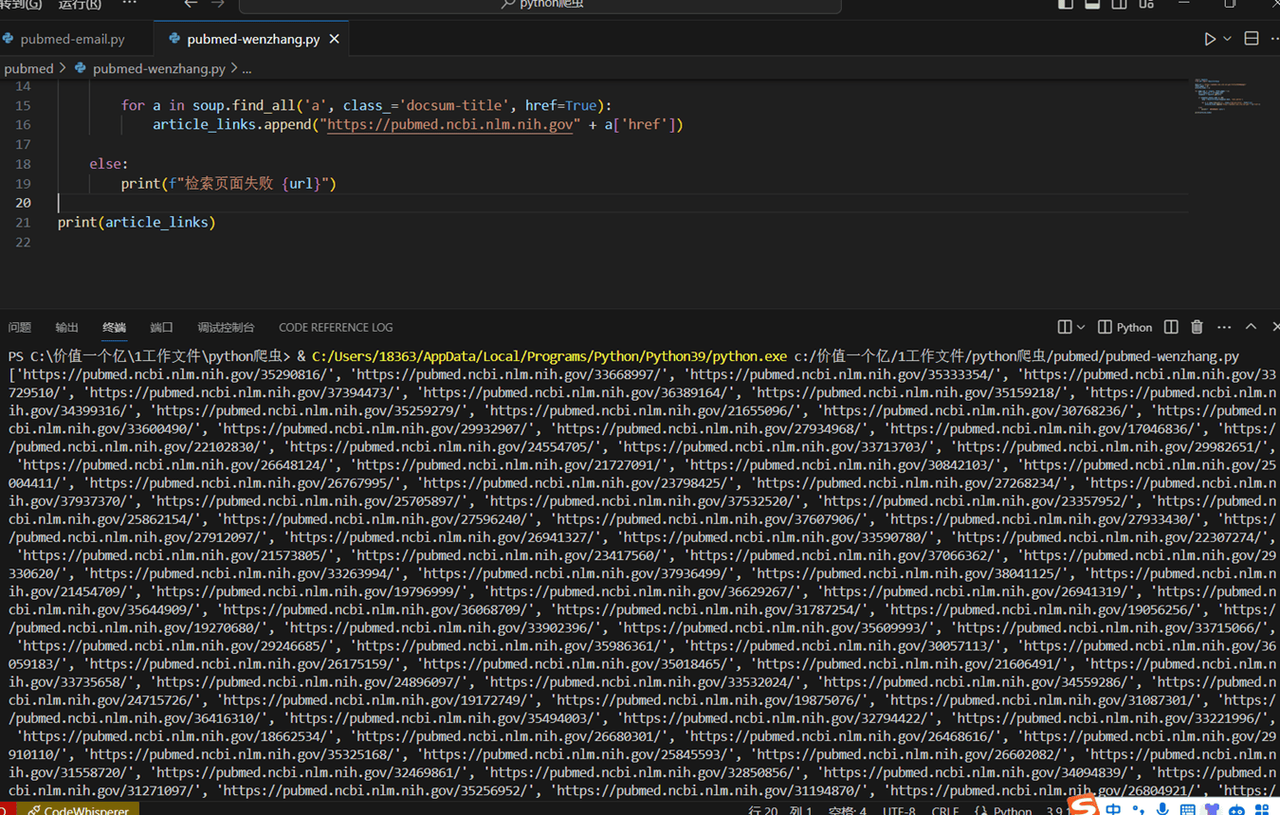
最后,我们打印出所有爬取到的文章链接列表。
print(article_links) # 打印所有文章链接列表
运行程序,大概等待了半分钟,完整输出了 228 篇文章的链接。
这样,我们就完成了获取 PubMed 文章链接的过程。接下来,我们将介绍如何使用代理 IP 进行爬取,并爬取文章中的邮箱地址。
好的,现在我们来继续介绍如何使用代理 IP 进行爬取,并爬取文章中的邮箱地址。
使用代理 IP 进行爬取
考虑到一些网站对频繁访问或大量请求会有限制,可能采取封禁IP或者设立验证码等措施。使用IP代理服务可以使爬虫在请求目标网站时轮换IP,从而规避了被网站封禁的风险。这里我采用的是亮数据IP代理服务。
首先,我们需要导入 requests 库,并定义一个代理 IP 的地址。假设代理 IP 的地址是 http://127.0.0.1:8000。
import requestsproxy = "http://127.0.0.1:8000"
接着,我们修改发送请求的方式,使用 requests.get 方法的 proxies 参数来设置代理 IP。
response = requests.get(url, proxies={"http": proxy, "https": proxy})
这样,我们就可以通过代理 IP 发送请求了。接下来我们获取文章中的邮箱地址。
爬取邮箱地址
为了使用Selenium库获取文章中的邮箱地址,我们首先需要导入相关的库。Selenium是一个自动化测试工具,可以模拟用户在浏览器中的操作,比如点击、输入、提交表单等。
from selenium import webdriver
import re
import time
然后,我们需要设置Chrome浏览器的选项,以及要爬取的文章链接列表和存储提取到的邮箱地址的列表。
# 设置ChromeOptions以指定Chrome二进制文件位置和其他选项
chrome_options = webdriver.ChromeOptions()
chrome_options.binary_location = "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe" # 请根据你的Chrome安装路径进行修改# 加载ChromeDriver并应用Chrome选项
driver = webdriver.Chrome(options=chrome_options)# 要爬取的文章链接列表
article_links = ['https://pubmed.ncbi.nlm.nih.gov/35290816/', 'https://pubmed.ncbi.nlm.nih.gov/33668997/', ...] # 这里省略了大部分链接# 存储提取到的邮箱地址
email_addresses = []
然后我们可以使用Selenium模拟浏览器打开每个文章链接,并从页面中提取邮箱地址。
# 遍历文章链接列表
for link in article_links:driver.get(link)time.sleep(2) # 等待页面加载# 使用正则表达式查找页面中的邮箱地址email_matches = re.findall(r'[\w\.-]+@[\w\.-]+\.[a-zA-Z]+', driver.page_source)# 如果找到邮箱地址则添加到列表中if email_matches:for email in email_matches:email_addresses.append(email)
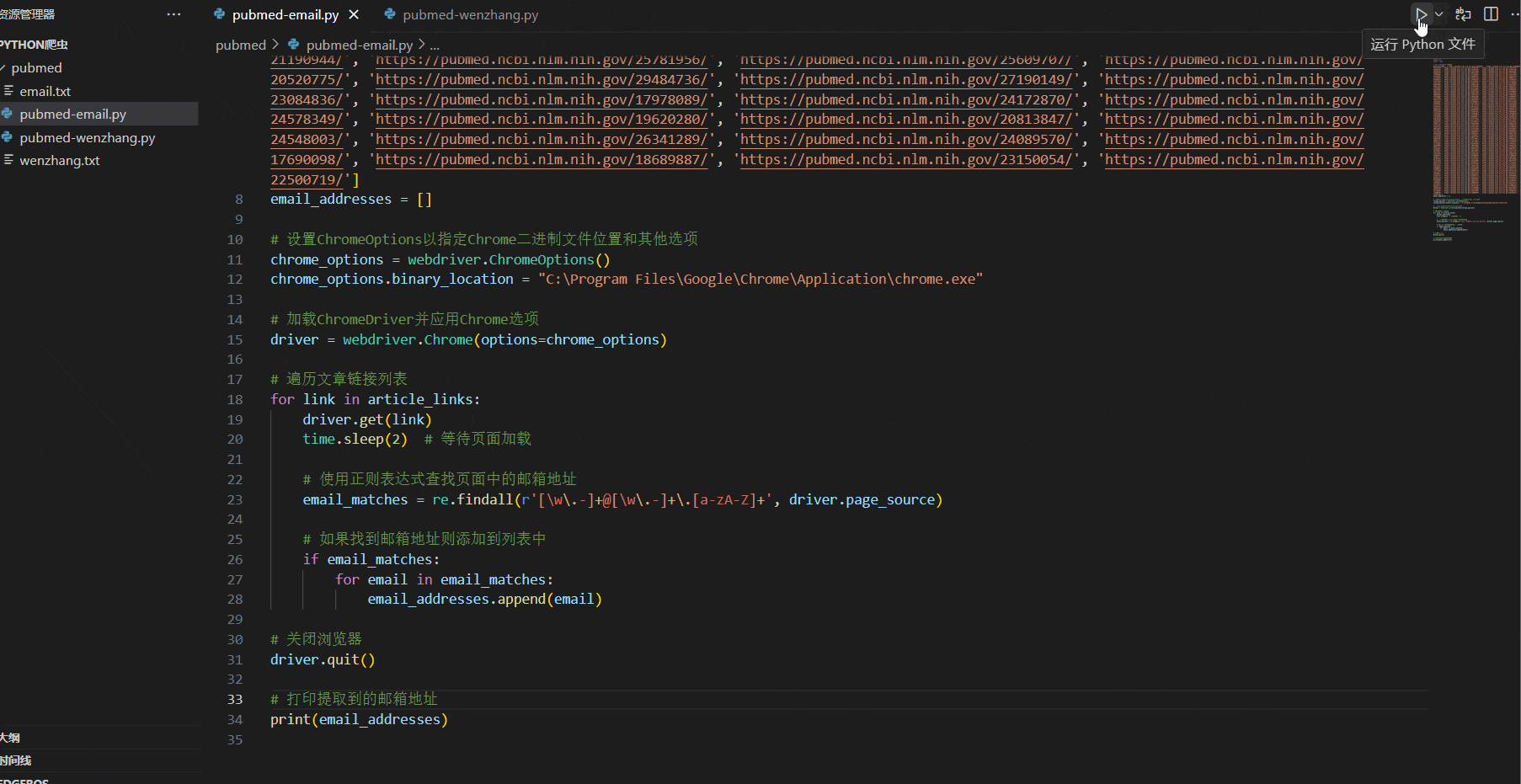
最后,关闭浏览器并打印提取到的邮箱地址。
# 关闭浏览器
driver.quit()# 打印提取到的邮箱地址
print(email_addresses)
这样,我们就可以使用Selenium库在每个文章链接中提取到邮箱地址了。
运行效果如下,selenium 会自动打开浏览器,访问这两百多个页面
待页面访问完成即可输出邮箱地址
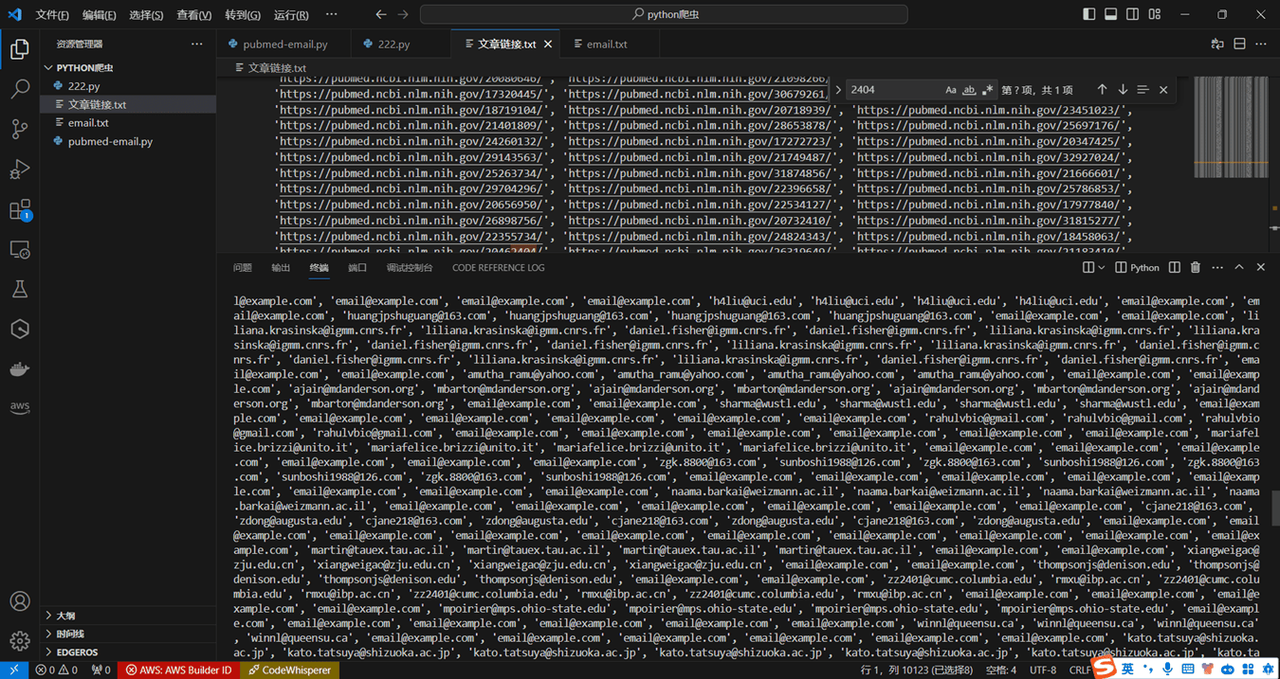
到这里我们就大功告成了。
完整代码
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import re
import time# 定义代理IP地址
proxy = {'http': 'http://your_proxy_ip:your_proxy_port','https': 'https://your_proxy_ip:your_proxy_port'
}# 设置请求头
headers = {'User-Agent': 'Your User Agent'
}# 设置ChromeOptions以指定Chrome二进制文件位置和其他选项
chrome_options = webdriver.ChromeOptions()
chrome_options.binary_location = "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe" # 请根据你的Chrome安装路径进行修改
chrome_options.add_argument('--proxy-server=http://your_proxy_ip:your_proxy_port') # 添加代理IP地址# 加载ChromeDriver并应用Chrome选项
driver = webdriver.Chrome(options=chrome_options)# PubMed搜索基础URL,搜索关键词'h3k56'
base_url = "https://pubmed.ncbi.nlm.nih.gov/?term=h3k56&page="# 总共的页面数
total_pages = 23# 存储文章链接的列表
article_links = []# 遍历页面获取文章链接
for page_num in range(1, total_pages + 1):url = base_url + str(page_num) # 构建当前页面的完整URLtry:# 发起GET请求获取页面内容response = requests.get(url, headers=headers, proxies=proxy)if response.status_code == 200: # 如果响应码为200,表示请求成功soup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup解析页面内容for a in soup.find_all('a', class_='docsum-title', href=True): # 查找具有'docsum-title'类的<a>标签article_links.append("https://pubmed.ncbi.nlm.nih.gov" + a['href']) # 将找到的文章链接添加到列表中else:print(f"检索页面失败 {url}") # 请求失败时输出错误信息except Exception as e:print(f"请求异常: {e}")# 打印所有文章链接列表
print(article_links)# 存储提取到的邮箱地址
email_addresses = []# 遍历文章链接列表并提取邮箱地址
for link in article_links:try:driver.get(link)time.sleep(2) # 等待页面加载# 使用正则表达式查找页面中的邮箱地址email_matches = re.findall(r'[\w\.-]+@[\w\.-]+\.[a-zA-Z]+', driver.page_source)# 如果找到邮箱地址则添加到列表中if email_matches:for email in email_matches:email_addresses.append(email)except Exception as e:print(f"提取邮箱地址异常: {e}")# 关闭浏览器
driver.quit()# 打印提取到的邮箱地址
print(email_addresses)总结
以上是一个简单的爬虫示例,展示了如何使用亮数据的IP代理服务来爬取网页链接以及邮箱地址。通过亮数据的IP代理服务,我们可以轻松地突破网站的封锁,实现数据的高效获取。希望通过以上示例能够帮助大家更好地理解IP代理服务的重要性和使用方法。
如果您对IP代理服务感兴趣,可以通过亮数据官网了解更多信息。
相关文章:
使用亮数据代理IP爬取PubMed文章链接和邮箱地址
💂 个人网站:【 摸鱼游戏】【神级代码资源网站】【工具大全】🤟 一站式轻松构建小程序、Web网站、移动应用:👉注册地址🤟 基于Web端打造的:👉轻量化工具创作平台💅 想寻找共同学习交…...

electron调用dll时应用程序闪退
electron调用dll时,直接闪退,且用如下方式监听无任何输出: window-all-closed 或 will-quit 此时需要检查传给dll的参数及参数类型是否正确,特别是使用ffi-napi时调用dll,使用 ref-napi定义类型,经常容易…...
单片机原理及技术(三)—— AT89S51单片机(二)(C51编程)
一、AT89S51单片机的并行I/O端口 1.1 P0口 AT89S51的P0口是一个通用的I/O口,可以用于输入和输出。每个引脚都可以通过软件控制为输入或输出模式。 1.1.1 P0口的工作原理 P0口的工作原理是通过对P0寄存器的读写操作来控制P0口的引脚。 输出模式:当P0口…...

摄影店展示服务预约小程序的作用是什么
摄影店包含婚照、毕业照、写真、儿童照、工作照等多个服务项目,虽然如今人们手机打开便可随时拍照摄影,但在专业程度和场景应用方面,却是需要前往专业门店服务获取。 除了进店,也有外部预约及活动、同行合作等场景,重…...
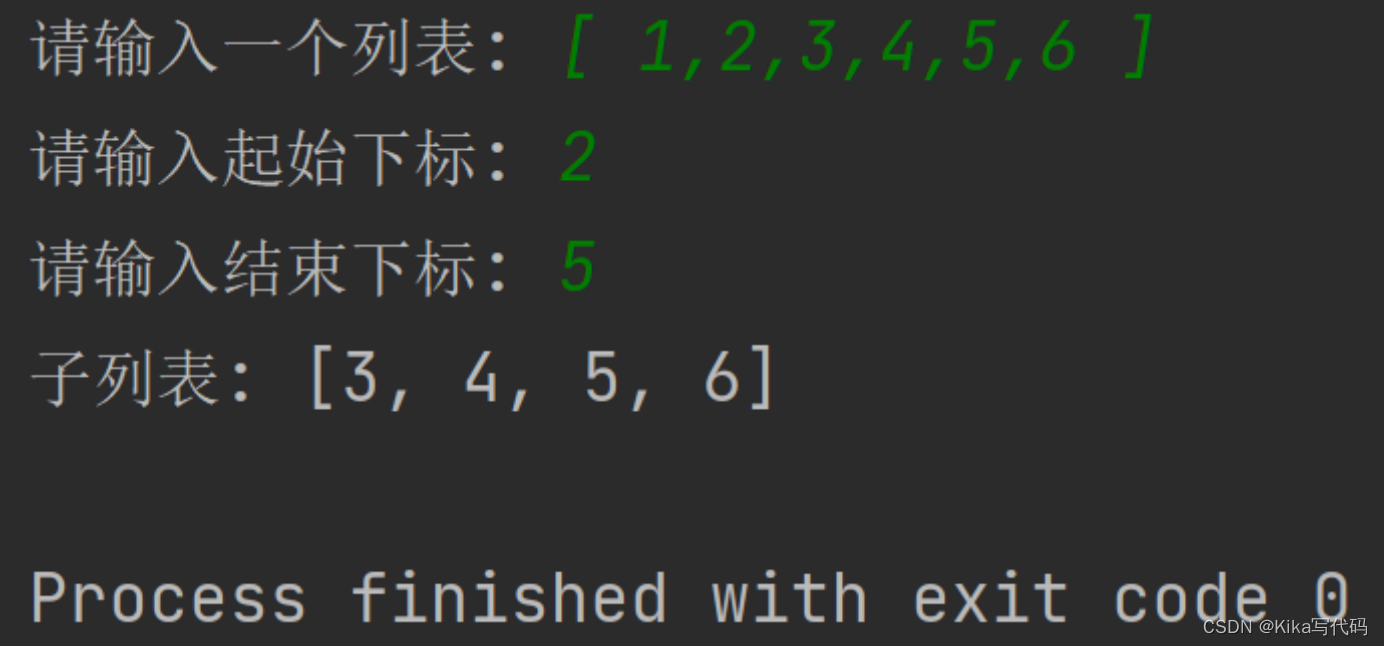
【数据分析基础】实验一 Python运算符、内置函数、序列基本用法
一、实验目的 熟练运用Python运算符。熟练运用Python内置函数。掌握Python的基本输入输出方法。了解lambda表达式作为函数参数的用法。掌握列表、元组、字典、集合的概念和基本用法。了解Python函数式编程模式。 二、实验内容: 1. 在命令模式测试如下命令&#x…...

【Redis】构建强韧的远程Redis连接与端口保障机制完美指南
【Redis】构建强韧的远程Redis连接与端口保障机制完美指南 大家好 我是寸铁👊 总结了【Redis】构建强韧的远程Redis连接与端口保障机制完美指南✨ 喜欢的小伙伴可以点点关注 💝 前言 在当今的软件开发领域中,远程访问和操作数据存储是极为常见…...
Flowable项目启动报错#java.time.LocalDateTime cannot be cast to java.lang.String
Flowable 项目启动后报错 flow项目第一次启动创建表成功,但是第二次启动时报错信息如下: 1、Error creating bean with name ‘appRepositoryServiceBean’ defined in class 2、Error creating bean with name ‘flowableAppEngine’: FactoryBean t…...

《数字电路》
问答题4*5 在数字电路中,三极管经常工作在哪两种开关状态? 在数字电路中,三极管经常工作在饱和导通状态和截止状态。 时序电路根据输出信号分为哪两类? 时序电路根据输出信号分为莫尔型和米里型两类。 写出三种以上常用的二-十…...

STM32F103 点亮LED闪烁与仿真
STM32F103 点亮LED闪烁与仿真 今天给大家分享一下STM32 流水灯简单的仿真吧,我感觉这个提供有用的,但是自己也是第一次使用,主要是感觉曲线很高级。在PWM中查看脉宽很有用。 code: led.c #include "led.h" #include "delay…...

阿里云服务器发送邮件失败 Could not connect to SMTP host: smtp.xxx.com, port: 465;
最近做了一个发送邮件的功能, 在本地调试完成后,部署到阿里云服务器就一直报错, Could not connect to SMTP host: smtp.qiye.aliyun.com, port: 465; 网上也搜索了很多的资料,最后花了好几个小时才解决, 报错日志如下…...

Socket编程权威指南(二)完美掌握TCP流式协议及Socket编程的recv()和send()
在上一篇文章中,我们学习了Socket编程的基础知识,包括创建Socket、绑定地址、监听连接、接收连接等操作。然而,真正的套接字编程远不止于此。本文将重点介绍TCP 流式协议,什么是粘包问题?如何解决粘包问题 ?…...

当C++的static遇上了继承
比如我们想要统计下当前类被实例化了多少次,我们通常会这么写 class A { public:A() { Count_; }~A() { Count_--; }int GetCount() { return Count_; }private:static int Count_; };class B { public:B() { Count_; }~B() { Count_--; }int GetCount() { return …...

Three.js中的Raycasting技术:实现3D场景交互事件的Raycaster详解
前言 在Web开发中,Three.js是一个极为强大的库,它让开发者能够轻松地在浏览器中创建和展示3D图形。随着3D技术在网页设计、游戏开发、数据可视化等领域的广泛应用,用户与3D场景的交互变得日益重要。而要实现这种交互,一个核心的技…...
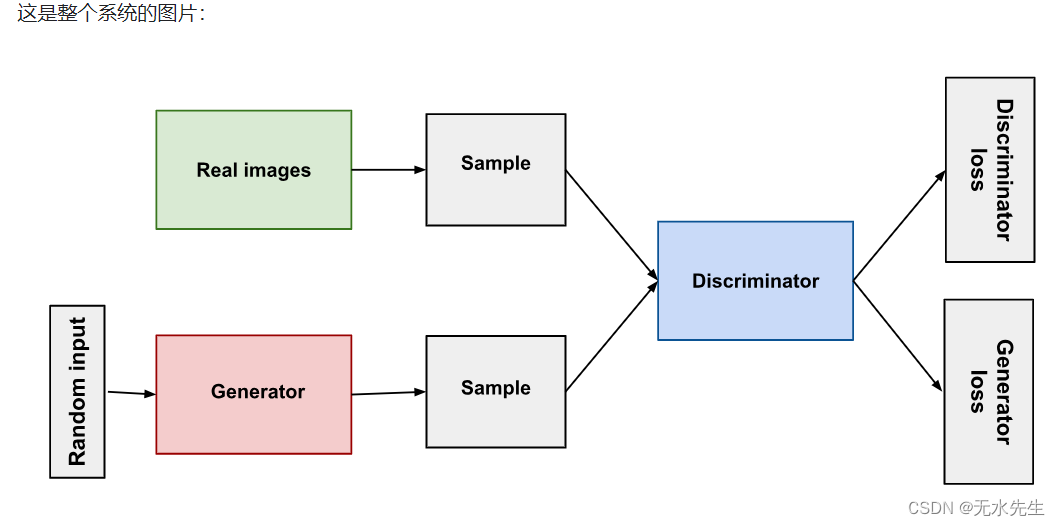
5 分钟内构建一个简单的基于 Python 的 GAN
文章目录 一、说明二、代码三、训练四、后记 一、说明 生成对抗网络(GAN)因其能力而在学术界引起轩然大波。机器能够创作出新颖、富有灵感的作品,这让每个人都感到敬畏和恐惧。因此,人们开始好奇,如何构建一个这样的网…...

智能硬件产品中常用的参数存储和管理方案
一、有哪些参数需要管理? 在智能硬件产品中,一般有三类数据需要存储并管理: 1. 系统设置数据 系统设置数据是指产品自身正常工作所依赖的一些参数。 这类数据的特点:只能在生产过程中修改,出厂后用户无权限修改。 比如:产品SN、产品密钥/token/license、传感器校准值…...

SwiftUI中Mask修饰符的理解与使用
Mask是一种用于控制图形元素可见性的图形技术,使用给定视图的alpha通道掩码该视图。在SwiftUI中,它类似于创建一个只显示视图的特定部分的模板。 Mask修饰符的定义: func mask<Mask>(alignment: Alignment .center,ViewBuilder _ ma…...
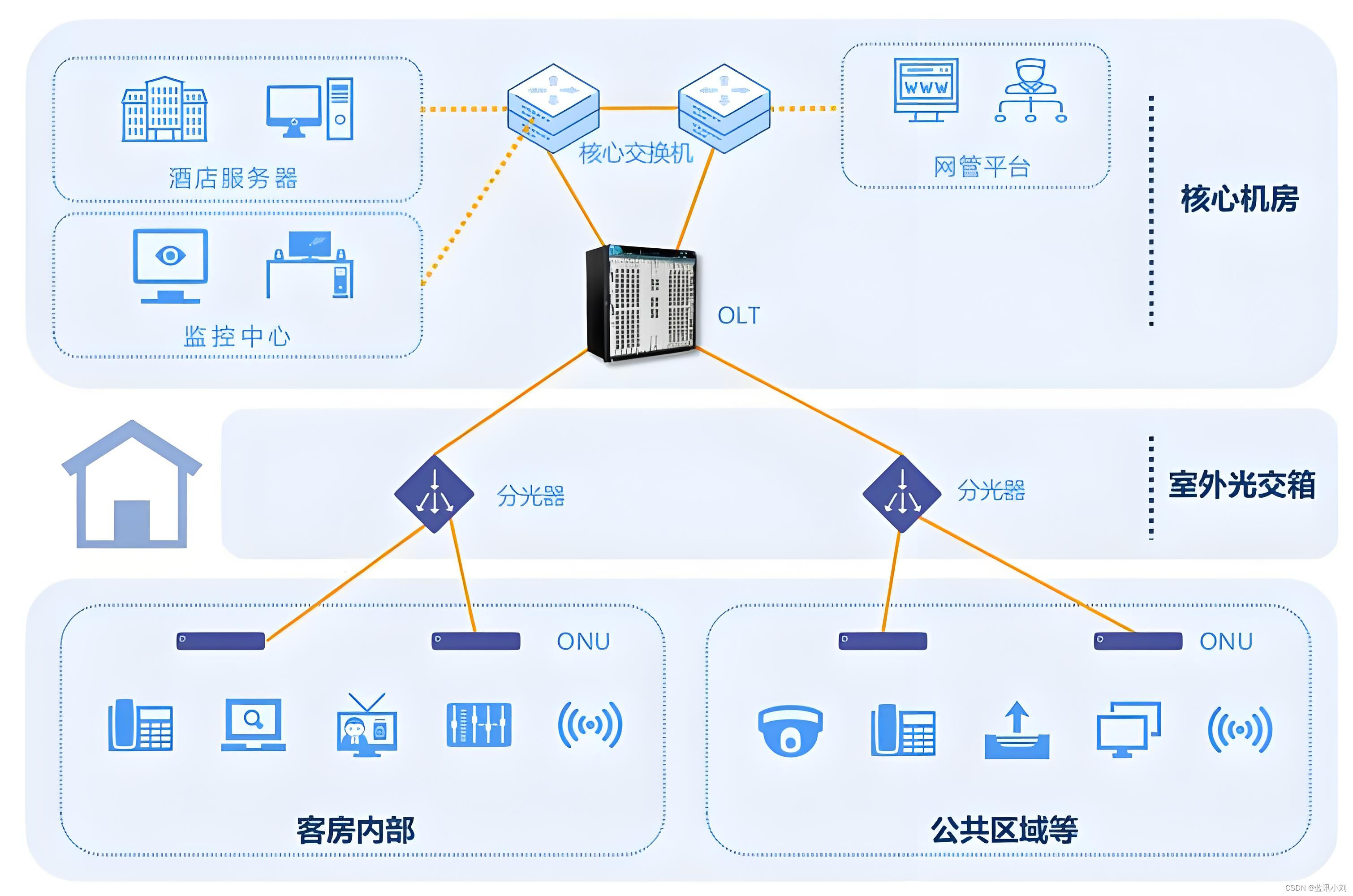
全光网络与传统网络架构的对比分析
随着信息技术的飞速发展,网络已经成为我们日常生活中不可或缺的一部分。在这个信息爆炸的时代,全光网络和传统网络架构作为两种主流的网络技术,各有其特点和适用范围。本文将对这两种网络架构进行详细的对比分析,帮助读者更好地了…...
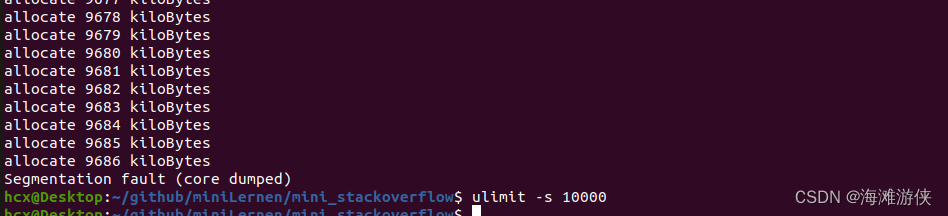
stack overflow复现
当你在内存的栈中,存放了太多元素,就有可能在造成 stack overflow这个问题。 今天看看如何复现这个问题。 下图,是我写的程序,不断的创造1KB的栈,来看看执行了多少次,无限循环。 最后结果是7929kB时, 发…...

mybatis使用笔记
文章目录 打印sql日志mybatis-config.xml方式application.yml里面配置配置类配置方式 其他扫描方式官网文档 mybatis用了那么久,实际一直不明白,做个笔记吧。 打印sql日志 实测,mybatis-config.xml方式好用(记得注掉yml里的相关配置) mybat…...

学习笔记——路由网络基础——路由概述
一、路由概述 1、路由定义与作用 路由(routing)是指导报文转发路径信息,通过路由可以确认转发IP报文的路径。 路由:是指路由器从一个接口上收到数据包,根据数据包的目的地址进行定向并转发到另一个接口的过程。 路由(routing)的定义是指分…...

太秀了,我把自己蒸馏成了 Skill!已开源
最近 GitHub 上掀起了一股「AI 蒸馏」热潮,这里的蒸馏可不是酿酒,而是把身边的人封装成 AI 技能包——同事.skill、老板.skill、搭档.skill 等各类蒸馏项目层出不穷,大家都在把身边人的工作经验、说话风格、做事逻辑,做成可直接使…...

imFile下载管理器:从入门到精通的免费全能下载解决方案
imFile下载管理器:从入门到精通的免费全能下载解决方案 【免费下载链接】imfile-desktop A full-featured download manager. 项目地址: https://gitcode.com/gh_mirrors/im/imfile-desktop imFile是一款功能全面的免费下载管理器,支持HTTP、FTP、…...

数字音频抖动抑制技术与DSS™同步方案解析
1. 数字音频系统中的抖动现象解析抖动(Jitter)是数字音频领域最令人头痛的问题之一,它就像一位不守时的乐队指挥——当每个音符的演奏时机出现微秒级的偏差时,整首乐曲就会失去原有的韵律和质感。在技术层面,抖动被定义…...

文献处理效率暴跌?NotebookLM Agent的3层语义理解架构,让PDF秒变可推理知识图谱!
更多请点击: https://intelliparadigm.com 第一章:文献处理效率暴跌?NotebookLM Agent的3层语义理解架构,让PDF秒变可推理知识图谱! 传统PDF阅读工具仅支持关键词检索与线性浏览,面对百页学术论文或跨领域…...

GENIVI DLT Viewer:从编译到实战连接的完整指南
1. 环境准备:搭建DLT Viewer开发环境 第一次接触GENIVI DLT Viewer时,我花了两天时间才把环境搭好。现在回想起来,其实只要抓住几个关键点就能少走弯路。DLT Viewer是汽车电子和嵌入式领域常用的日志分析工具,主要用于查看设备端…...

Ruby纳米机器人框架:构建高内聚低耦合的自动化任务管道
1. 项目概述:当Ruby遇上纳米机器人最近在GitHub上闲逛,发现了一个名为icebaker/ruby-nano-bots的项目。这个标题本身就充满了想象力——Ruby,一门以优雅和生产力著称的动态语言;Nano-Bots,一个源自科幻、代表微观自动化…...

AutoDock-Vina终极指南:快速掌握分子对接的完整教程
AutoDock-Vina终极指南:快速掌握分子对接的完整教程 【免费下载链接】AutoDock-Vina AutoDock Vina 项目地址: https://gitcode.com/gh_mirrors/au/AutoDock-Vina AutoDock-Vina是一款开源的分子对接工具,专门用于模拟小分子(配体&…...

别再只调包了!用PyTorch从零手搓一个Unet,搞懂语义分割的每个细节
从零构建Unet:深入解析语义分割的代码实现与设计哲学 在计算机视觉领域,语义分割一直是极具挑战性的任务之一。不同于简单的图像分类,语义分割需要模型对图像中的每一个像素进行分类,这要求模型既要理解全局上下文信息,…...

基于矩阵分解与独立向量分析的深度神经网络后门攻击检测方法
1. 项目概述:当深度神经网络遭遇“潜伏者”在深度神经网络(DNN)如卷积神经网络(CNN)、Transformer模型等成为计算机视觉、自然语言处理乃至语音识别领域基石的今天,我们享受着其带来的高精度与自动化红利。…...

基于MCP的AI智能体:用自然语言轻松管理TikTok广告投放
1. 项目概述:用AI智能体玩转TikTok广告投放 如果你正在做跨境电商、品牌出海,或者任何面向年轻消费者的生意,TikTok广告绝对是你绕不开的战场。但真正上手后,你会发现事情没那么简单:TikTok的广告后台(Ads…...