AIGC笔记--Stable Diffusion源码剖析之UNetModel
1--前言
以论文《High-Resolution Image Synthesis with Latent Diffusion Models》 开源的项目为例,剖析Stable Diffusion经典组成部分,巩固学习加深印象。
2--UNetModel
一个可以debug的小demo:SD_UNet
以文生图为例,剖析UNetModel核心组成模块。
2-1--Forward总揽
提供的文生图Demo中,实际传入的参数只有x、timesteps和context三个,其中:
x 表示随机初始化的噪声Tensor(shape: [B*2, 4, 64, 64],*2表示使用Classifier-Free Diffusion Guidance)。
timesteps 表示去噪过程中每一轮传入的timestep(shape: [B*2])。
context表示经过CLIP编码后对应的文本Prompt(shape: [B*2, 77, 768])。
def forward(self, x, timesteps=None, context=None, y=None,**kwargs):"""Apply the model to an input batch.:param x: an [N x C x ...] Tensor of inputs.:param timesteps: a 1-D batch of timesteps.:param context: conditioning plugged in via crossattn:param y: an [N] Tensor of labels, if class-conditional.:return: an [N x C x ...] Tensor of outputs."""assert (y is not None) == (self.num_classes is not None), "must specify y if and only if the model is class-conditional"hs = []t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False) # Create sinusoidal timestep embeddings.emb = self.time_embed(t_emb) # MLPif self.num_classes is not None:assert y.shape == (x.shape[0],)emb = emb + self.label_emb(y)h = x.type(self.dtype)for module in self.input_blocks:h = module(h, emb, context)hs.append(h)h = self.middle_block(h, emb, context)for module in self.output_blocks:h = th.cat([h, hs.pop()], dim=1)h = module(h, emb, context)h = h.type(x.dtype)if self.predict_codebook_ids:return self.id_predictor(h)else:return self.out(h)2-2--timestep embedding生成
使用函数 timestep_embedding() 和 self.time_embed() 对传入的timestep进行位置编码,生成sinusoidal timestep embeddings。
其中 timestep_embedding() 函数定义如下,而self.time_embed()是一个MLP函数。
def timestep_embedding(timesteps, dim, max_period=10000, repeat_only=False):"""Create sinusoidal timestep embeddings.:param timesteps: a 1-D Tensor of N indices, one per batch element.These may be fractional.:param dim: the dimension of the output.:param max_period: controls the minimum frequency of the embeddings.:return: an [N x dim] Tensor of positional embeddings."""if not repeat_only:half = dim // 2freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(device=timesteps.device)args = timesteps[:, None].float() * freqs[None]embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)if dim % 2:embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)else:embedding = repeat(timesteps, 'b -> b d', d=dim)return embeddingself.time_embed = nn.Sequential(linear(model_channels, time_embed_dim),nn.SiLU(),linear(time_embed_dim, time_embed_dim),
)2-3--self.input_blocks下采样
在 Forward() 中,使用 self.input_blocks 将输入噪声进行分辨率下采样,经过下采样具体维度变化为:[B*2, 4, 64, 64] > [B*2, 1280, 8, 8];
下采样模块共有12个 module,其组成如下:
ModuleList((0): TimestepEmbedSequential((0): Conv2d(4, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(1-2): 2 x TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 320, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=320, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 320, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Identity())(1): SpatialTransformer((norm): GroupNorm(32, 320, eps=1e-06, affine=True)(proj_in): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((attn1): CrossAttention((to_q): Linear(in_features=320, out_features=320, bias=False)(to_k): Linear(in_features=320, out_features=320, bias=False)(to_v): Linear(in_features=320, out_features=320, bias=False)(to_out): Sequential((0): Linear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(ff): FeedForward((net): Sequential((0): GEGLU((proj): Linear(in_features=320, out_features=2560, bias=True))(1): Dropout(p=0.0, inplace=False)(2): Linear(in_features=1280, out_features=320, bias=True)))(attn2): CrossAttention((to_q): Linear(in_features=320, out_features=320, bias=False)(to_k): Linear(in_features=768, out_features=320, bias=False)(to_v): Linear(in_features=768, out_features=320, bias=False)(to_out): Sequential((0): Linear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm1): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((320,), eps=1e-05, elementwise_affine=True)))(proj_out): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))))(3): TimestepEmbedSequential((0): Downsample((op): Conv2d(320, 320, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))))(4): TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 320, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(320, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=640, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 640, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Conv2d(320, 640, kernel_size=(1, 1), stride=(1, 1)))(1): SpatialTransformer((norm): GroupNorm(32, 640, eps=1e-06, affine=True)(proj_in): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((attn1): CrossAttention((to_q): Linear(in_features=640, out_features=640, bias=False)(to_k): Linear(in_features=640, out_features=640, bias=False)(to_v): Linear(in_features=640, out_features=640, bias=False)(to_out): Sequential((0): Linear(in_features=640, out_features=640, bias=True)(1): Dropout(p=0.0, inplace=False)))(ff): FeedForward((net): Sequential((0): GEGLU((proj): Linear(in_features=640, out_features=5120, bias=True))(1): Dropout(p=0.0, inplace=False)(2): Linear(in_features=2560, out_features=640, bias=True)))(attn2): CrossAttention((to_q): Linear(in_features=640, out_features=640, bias=False)(to_k): Linear(in_features=768, out_features=640, bias=False)(to_v): Linear(in_features=768, out_features=640, bias=False)(to_out): Sequential((0): Linear(in_features=640, out_features=640, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm1): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((640,), eps=1e-05, elementwise_affine=True)))(proj_out): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))))(5): TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 640, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=640, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 640, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(640, 640, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Identity())(1): SpatialTransformer((norm): GroupNorm(32, 640, eps=1e-06, affine=True)(proj_in): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((attn1): CrossAttention((to_q): Linear(in_features=640, out_features=640, bias=False)(to_k): Linear(in_features=640, out_features=640, bias=False)(to_v): Linear(in_features=640, out_features=640, bias=False)(to_out): Sequential((0): Linear(in_features=640, out_features=640, bias=True)(1): Dropout(p=0.0, inplace=False)))(ff): FeedForward((net): Sequential((0): GEGLU((proj): Linear(in_features=640, out_features=5120, bias=True))(1): Dropout(p=0.0, inplace=False)(2): Linear(in_features=2560, out_features=640, bias=True)))(attn2): CrossAttention((to_q): Linear(in_features=640, out_features=640, bias=False)(to_k): Linear(in_features=768, out_features=640, bias=False)(to_v): Linear(in_features=768, out_features=640, bias=False)(to_out): Sequential((0): Linear(in_features=640, out_features=640, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm1): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((640,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((640,), eps=1e-05, elementwise_affine=True)))(proj_out): Conv2d(640, 640, kernel_size=(1, 1), stride=(1, 1))))(6): TimestepEmbedSequential((0): Downsample((op): Conv2d(640, 640, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))))(7): TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 640, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(640, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=1280, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 1280, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Conv2d(640, 1280, kernel_size=(1, 1), stride=(1, 1)))(1): SpatialTransformer((norm): GroupNorm(32, 1280, eps=1e-06, affine=True)(proj_in): Conv2d(1280, 1280, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((attn1): CrossAttention((to_q): Linear(in_features=1280, out_features=1280, bias=False)(to_k): Linear(in_features=1280, out_features=1280, bias=False)(to_v): Linear(in_features=1280, out_features=1280, bias=False)(to_out): Sequential((0): Linear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(ff): FeedForward((net): Sequential((0): GEGLU((proj): Linear(in_features=1280, out_features=10240, bias=True))(1): Dropout(p=0.0, inplace=False)(2): Linear(in_features=5120, out_features=1280, bias=True)))(attn2): CrossAttention((to_q): Linear(in_features=1280, out_features=1280, bias=False)(to_k): Linear(in_features=768, out_features=1280, bias=False)(to_v): Linear(in_features=768, out_features=1280, bias=False)(to_out): Sequential((0): Linear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)))(proj_out): Conv2d(1280, 1280, kernel_size=(1, 1), stride=(1, 1))))(8): TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 1280, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=1280, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 1280, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Identity())(1): SpatialTransformer((norm): GroupNorm(32, 1280, eps=1e-06, affine=True)(proj_in): Conv2d(1280, 1280, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((attn1): CrossAttention((to_q): Linear(in_features=1280, out_features=1280, bias=False)(to_k): Linear(in_features=1280, out_features=1280, bias=False)(to_v): Linear(in_features=1280, out_features=1280, bias=False)(to_out): Sequential((0): Linear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(ff): FeedForward((net): Sequential((0): GEGLU((proj): Linear(in_features=1280, out_features=10240, bias=True))(1): Dropout(p=0.0, inplace=False)(2): Linear(in_features=5120, out_features=1280, bias=True)))(attn2): CrossAttention((to_q): Linear(in_features=1280, out_features=1280, bias=False)(to_k): Linear(in_features=768, out_features=1280, bias=False)(to_v): Linear(in_features=768, out_features=1280, bias=False)(to_out): Sequential((0): Linear(in_features=1280, out_features=1280, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm1): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((1280,), eps=1e-05, elementwise_affine=True)))(proj_out): Conv2d(1280, 1280, kernel_size=(1, 1), stride=(1, 1))))(9): TimestepEmbedSequential((0): Downsample((op): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))))(10-11): 2 x TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 1280, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=1280, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 1280, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Identity()))
)12个 module 都使用了 TimestepEmbedSequential 类进行封装,根据不同的网络层,将输入噪声x与timestep embedding和prompt context进行运算。
class TimestepEmbedSequential(nn.Sequential, TimestepBlock):"""A sequential module that passes timestep embeddings to the children thatsupport it as an extra input."""def forward(self, x, emb, context=None):for layer in self:if isinstance(layer, TimestepBlock):x = layer(x, emb)elif isinstance(layer, SpatialTransformer):x = layer(x, context)else:x = layer(x)return x2-3-1--Module0
Module 0 是一个2D卷积层,主要对输入噪声进行特征提取;
# init 初始化
self.input_blocks = nn.ModuleList([TimestepEmbedSequential(conv_nd(dims, in_channels, model_channels, 3, padding=1))]
)# 打印 self.input_blocks[0]
TimestepEmbedSequential((0): Conv2d(4, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)2-3-2--Module1和Module2
Module1和Module2的结构相同,都由一个ResBlock和一个SpatialTransformer组成;
# init 初始化
for _ in range(num_res_blocks):layers = [ResBlock(ch,time_embed_dim,dropout,out_channels=mult * model_channels,dims=dims,use_checkpoint=use_checkpoint,use_scale_shift_norm=use_scale_shift_norm,)]ch = mult * model_channelsif ds in attention_resolutions:if num_head_channels == -1:dim_head = ch // num_headselse:num_heads = ch // num_head_channelsdim_head = num_head_channelsif legacy:#num_heads = 1dim_head = ch // num_heads if use_spatial_transformer else num_head_channelslayers.append(AttentionBlock(ch,use_checkpoint=use_checkpoint,num_heads=num_heads,num_head_channels=dim_head,use_new_attention_order=use_new_attention_order,) if not use_spatial_transformer else SpatialTransformer(ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim))self.input_blocks.append(TimestepEmbedSequential(*layers))self._feature_size += chinput_block_chans.append(ch)# 打印 self.input_blocks[1]
TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 320, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=320, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 320, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Identity())(1): SpatialTransformer((norm): GroupNorm(32, 320, eps=1e-06, affine=True)(proj_in): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((attn1): CrossAttention((to_q): Linear(in_features=320, out_features=320, bias=False)(to_k): Linear(in_features=320, out_features=320, bias=False)(to_v): Linear(in_features=320, out_features=320, bias=False)(to_out): Sequential((0): Linear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(ff): FeedForward((net): Sequential((0): GEGLU((proj): Linear(in_features=320, out_features=2560, bias=True))(1): Dropout(p=0.0, inplace=False)(2): Linear(in_features=1280, out_features=320, bias=True)))(attn2): CrossAttention((to_q): Linear(in_features=320, out_features=320, bias=False)(to_k): Linear(in_features=768, out_features=320, bias=False)(to_v): Linear(in_features=768, out_features=320, bias=False)(to_out): Sequential((0): Linear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm1): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((320,), eps=1e-05, elementwise_affine=True)))(proj_out): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1)))
)# 打印 self.input_blocks[2]
TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 320, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=320, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 320, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(320, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Identity())(1): SpatialTransformer((norm): GroupNorm(32, 320, eps=1e-06, affine=True)(proj_in): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1))(transformer_blocks): ModuleList((0): BasicTransformerBlock((attn1): CrossAttention((to_q): Linear(in_features=320, out_features=320, bias=False)(to_k): Linear(in_features=320, out_features=320, bias=False)(to_v): Linear(in_features=320, out_features=320, bias=False)(to_out): Sequential((0): Linear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(ff): FeedForward((net): Sequential((0): GEGLU((proj): Linear(in_features=320, out_features=2560, bias=True))(1): Dropout(p=0.0, inplace=False)(2): Linear(in_features=1280, out_features=320, bias=True)))(attn2): CrossAttention((to_q): Linear(in_features=320, out_features=320, bias=False)(to_k): Linear(in_features=768, out_features=320, bias=False)(to_v): Linear(in_features=768, out_features=320, bias=False)(to_out): Sequential((0): Linear(in_features=320, out_features=320, bias=True)(1): Dropout(p=0.0, inplace=False)))(norm1): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((320,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((320,), eps=1e-05, elementwise_affine=True)))(proj_out): Conv2d(320, 320, kernel_size=(1, 1), stride=(1, 1)))
)2-3-3--Module3
Module3是一个下采样2D卷积层。
# init 初始化
if level != len(channel_mult) - 1:out_ch = chself.input_blocks.append(TimestepEmbedSequential(ResBlock(ch,time_embed_dim,dropout,out_channels=out_ch,dims=dims,use_checkpoint=use_checkpoint,use_scale_shift_norm=use_scale_shift_norm,down=True,)if resblock_updownelse Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)))# 打印 self.input_blocks[3]
TimestepEmbedSequential((0): Downsample((op): Conv2d(320, 320, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)))
)2-3-4--Module4、Module5、Module7和Module8
与Module1和Module2的结构相同,都由一个ResBlock和一个SpatialTransformer组成,只有特征维度上的区别;
2-3-4--Module6和Module9
与Module3的结构相同,是一个下采样2D卷积层。
2-3--5--Module10和Module11
Module10和Module12的结构相同,只由一个ResBlock组成。
# 打印 self.input_blocks[10]
TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 1280, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=1280, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 1280, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Identity())
)# 打印 self.input_blocks[11]
TimestepEmbedSequential((0): ResBlock((in_layers): Sequential((0): GroupNorm32(32, 1280, eps=1e-05, affine=True)(1): SiLU()(2): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(h_upd): Identity()(x_upd): Identity()(emb_layers): Sequential((0): SiLU()(1): Linear(in_features=1280, out_features=1280, bias=True))(out_layers): Sequential((0): GroupNorm32(32, 1280, eps=1e-05, affine=True)(1): SiLU()(2): Dropout(p=0, inplace=False)(3): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))(skip_connection): Identity())
)相关文章:

AIGC笔记--Stable Diffusion源码剖析之UNetModel
1--前言 以论文《High-Resolution Image Synthesis with Latent Diffusion Models》 开源的项目为例,剖析Stable Diffusion经典组成部分,巩固学习加深印象。 2--UNetModel 一个可以debug的小demo:SD_UNet 以文生图为例&#…...

Linux文件系统与日志分析
目录 inode block 链接 文件修复 实验步骤 针对ext文件系统恢复删除文件 针对xfs文件系统恢复删除文件 日志 日志级别 rsyslogd服务 日志目录 messages日志文件(系统日志) 集中管理日志 - 实验 1.环境配置 1.1 1.2 1.3 1.4 1.5 2.远…...
【SkyWalking】使用PostgreSQL做存储K8s部署
拉取镜像 docker pull apache/skywalking-ui:10.0.1 docker tag apache/skywalking-ui:10.0.1 xxx/xxx/skywalking-ui:10.0.1 docker push xxx/xxx/skywalking-ui:10.0.1docker pull apache/skywalking-oap-server:10.0.1 docker tag apache/skywalking-oap-server:10.0.1 xxx…...

详解大模型微调数据集构建方法(持续更新)
大家好,我是herosunly。985院校硕士毕业,现担任算法t研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算…...

自制植物大战僵尸:HTML5与JavaScript实现的简单游戏
引言 在本文中,我们将一起探索如何使用HTML5和JavaScript来创建一个简单的植物大战僵尸游戏。这不仅是一项有趣的编程挑战,也是学习游戏开发基础的绝佳机会。 什么是植物大战僵尸? 植物大战僵尸是一款流行的策略塔防游戏,玩家需…...
Istio_1.17.8安装
项目背景 按照istio官网的命令一路安装下来,安装好的istio版本为目前的最新版本,1.22.0。而我的k8s集群的版本并不支持istio_1.22的版本,导致ingress-gate网关安装不上,再仔细查看istio的发布文档,如果用istio_1.22版本…...
[数据集][目标检测]室内积水检测数据集VOC+YOLO格式761张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):761 标注数量(xml文件个数):761 标注数量(txt文件个数):761 标注类别…...
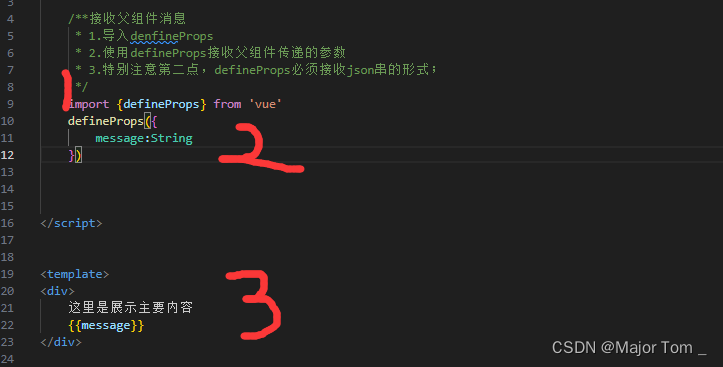
17_Vue高级监听器生命周期Vue组件组件通信
文章目录 1. 数据监听器watch2. Vue生命周期3. Vue组件4. Vue组件通信Appendix 1. 数据监听器watch 首先watch需要单独引 import {watch} from vuewatch函数监听ref响应式数据 watch(监听的内容,监听行为)监听行为默认为(newValue,oldValue) let firstname ref…...
【ROS使用记录】—— ros使用过程中的rosbag录制播放和ros话题信息相关的指令与操作记录
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、rosbag的介绍二、rosbag的在线和离线录制三、rosbag的播放相关的指令四、其他rosbag和ros话题相关的指令总结 前言 rosbag是ROS(机器人操作系统…...

Laravel 富文本内容
Laravel 获取富文本的纯文本内容-CSDN博客 Laravel 富文本内容里面的图片添加前缀URL-CSDN博客 Laravel 富文本图片的style样式删除-CSDN博客. Laravel 获取富文本中的所有图片-CSDN博客 富文本字体font-famly删除 $data preg_replace(/(<[^>])style["\][^"…...

Spark Python环境搭建与优化:深入剖析四个方面、五个方面、六个方面及七个关键要点
Spark Python环境搭建与优化:深入剖析四个方面、五个方面、六个方面及七个关键要点 在大数据处理领域,Apache Spark凭借其出色的性能和灵活性备受瞩目。而要在Python中利用Spark的强大功能,首先需要搭建一个稳定且高效的Spark Python环境。本…...
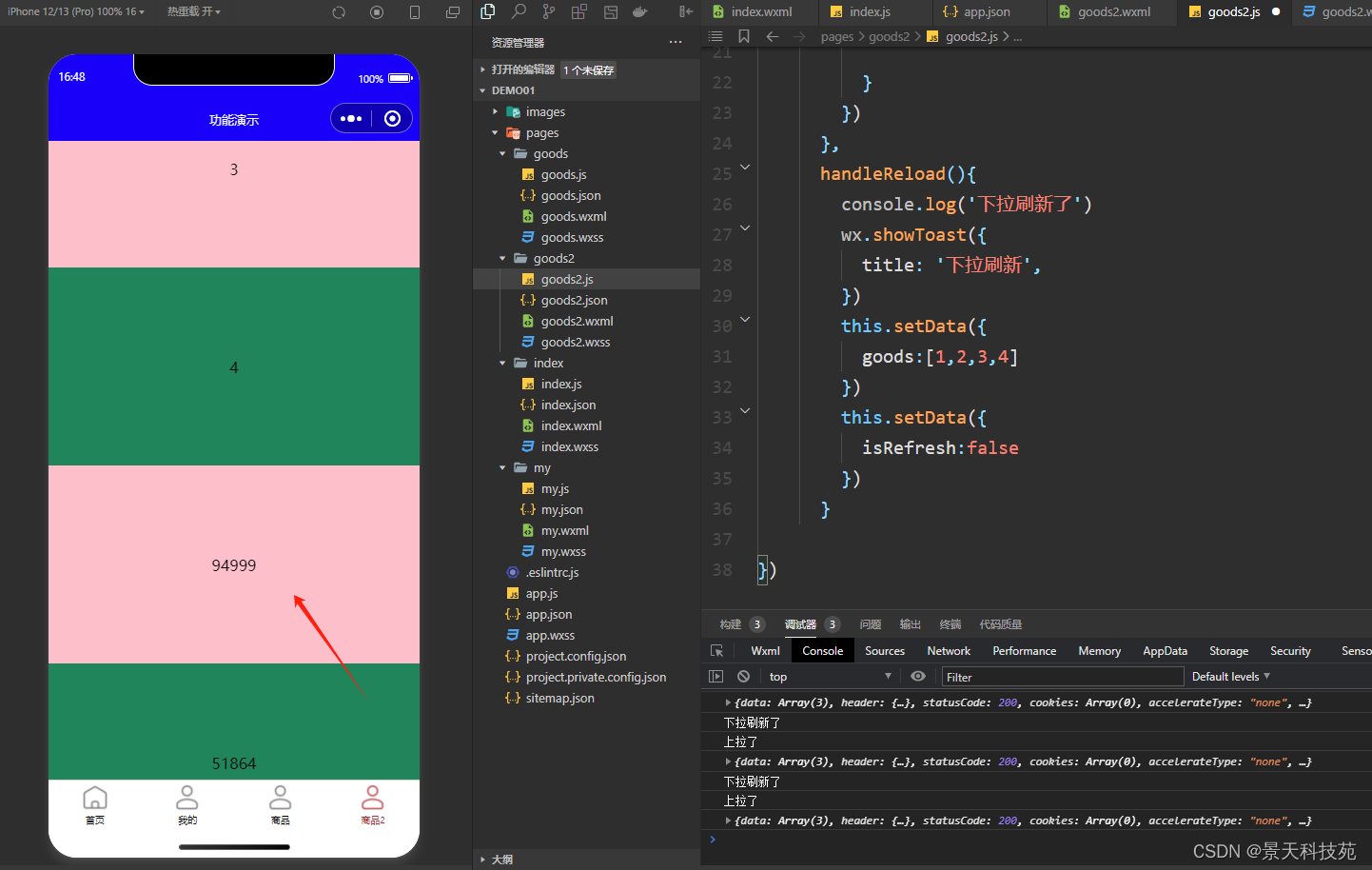
【微信小程序开发】小程序中的上滑加载更多,下拉刷新是如何实现的?
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

从 Android 恢复已删除的备份录
本文介绍了几种在 Android 上恢复丢失和删除的短信的方法。这些方法都不能保证一定成功,但您可能能够恢复一些短信或其中存储的文件。 首先要尝试什么 首先,尝试保留数据。如果你刚刚删除了信息,请立即将手机置于飞行模式,方法是…...

如何使用Python中的random模块生成随机数
在Python中,random模块提供了多种用于生成随机数的函数。以下是一些基本示例: 生成随机整数: 使用random.randint(a, b)函数生成一个介于a和b之间的随机整数(包括a和b)。 python复制代码 import random random_int …...
AI大数据处理与分析实战--体育问卷分析
AI大数据处理与分析实战–体育问卷分析 前言:前一段时间接了一个需求,使用AI进行数据分析与处理,遂整理了一下大致过程和大致简要结果(更详细就不方便放了)。 文章目录 AI大数据处理与分析实战--体育问卷分析一、数据…...

C++第二十五弹---从零开始模拟STL中的list(下)
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】【C详解】 目录 1、函数补充 2、迭代器完善 3、const迭代器 总结 1、函数补充 拷贝构造 思路: 先构造一个头结点,然后将 lt 类中的元…...

STM32/keil把多个c文件编译为静态库lib
把常用的、不经常修改的代码库编译成lib以后,可以加快整个工程的编译速度。 一个常见的应用场景就是,把ST的标准库或HAL库等编译成lib,这样以后再编译整个工程时,就无需再次编译他们了,可以节省编译时间。当然&#x…...

L45---506.相对名次(java)--排序
1.题目描述 2.知识点 (1)String.join(" ", words) 是 Java 中的一个语法,用于将数组或集合中的元素连接成一个单独的字符串,连接时使用指定的分隔符。这里的 " " 是作为分隔符使用的一个空格字符串。 Strin…...

跨网段路由
跨网段路由通常是指在网络中配置路由,以允许不同子网之间的通信。要设置跨网段的永久路由,取决于你是在操作路由器、交换机这样的网络设备,还是在配置个人计算机(如Windows或Linux系统)。下面是两种常见情况下的简要指…...

HO-3D 数据集
// 由于非刚体的追踪比较困难,所以看看刚体数据集 HOnnotate: A method for 3D Annotation of Hand and Object Poses // cvpr20https://arxiv.org/abs/1907.01481 https://github.com/shreyashampali/ho3d https://paperswithcode.com/paper/ho-3d-a-mult…...

VR大空间项目屡获行业大奖,AI数字人公司赋能文旅智慧升级
在经历了早期的概念普及和单点试验后,AI数字人、VR、MR等技术正在文旅行业完成从“尝鲜”到“刚需”的蜕变。不再仅仅是博物馆或景区里的一块互动屏幕,而是一套能够重塑服务流程、活化文化IP、创造全新消费场景的完整解决方案。从边疆秘境到城市地标&…...

基于OpenClaw的MacOS自动化AI助手:架构、配置与实战
1. 项目概述:一个为MacOS设计的自动化AI助手 最近在折腾桌面自动化,特别是想把一些高频、重复的跨应用操作给整合起来。比如,我经常需要在Telegram或WhatsApp上接收消息,然后根据内容去浏览器查资料、整理到笔记软件,或…...

航拍UAV电力电缆巡检检测数据集_数据集第10027期
航拍UAV电力电缆巡检检测数据集_数据集第10027期 项目简介 面向无人机电力巡检场景的开源目标检测数据集,聚焦电力电缆识别任务,可用于电力线检测、植被与电力线安全距离监测等场景,助力电力巡检智能化。 数据集核心信息 数据规模:…...

WP Pinch:通过MCP协议为WordPress站点集成AI助手管理能力
1. 项目概述:当你的WordPress站点“长出”AI的爪子 如果你和我一样,每天大部分时间都泡在Slack、Telegram或者WhatsApp里,和团队沟通、处理信息,那么你肯定也烦透了那种“这个内容不错,等我回到电脑前再发到网站上”的…...

个人开发者如何利用 Taotoken 管理多个项目的 AI 调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 个人开发者如何利用 Taotoken 管理多个项目的 AI 调用成本 对于独立开发者或自由职业者而言,同时维护多个小型项目是常…...

3分钟解锁百度网盘极速下载:BaiduPCS-Web高效解决方案全攻略
3分钟解锁百度网盘极速下载:BaiduPCS-Web高效解决方案全攻略 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 还在为百度网盘的龟速下载而烦恼吗?今天我要为你介绍一个能够彻底改变下载体验的神器——…...

GENIVI DLT Viewer:从编译到实战连接的完整指南
1. 环境准备:搭建DLT Viewer开发环境 第一次接触GENIVI DLT Viewer时,我花了两天时间才把环境搭好。现在回想起来,其实只要抓住几个关键点就能少走弯路。DLT Viewer是汽车电子和嵌入式领域常用的日志分析工具,主要用于查看设备端…...

不加机器也能提速10倍?低成本优化系统性能,才是高手真正的实力
不加机器也能提速10倍?低成本优化系统性能,才是高手真正的实力 很多公司一遇到系统卡顿。 第一反应特别统一: 加机器。CPU 不够? 加。 QPS 扛不住? 扩容。 数据库慢? 上集群。 结果最后: 服务器越来越多。 成本越来越高。 系统还是越来越慢。 最离谱的是: 有…...

终极指南:如何使用OpenCore Legacy Patcher让旧款Mac焕发新生
终极指南:如何使用OpenCore Legacy Patcher让旧款Mac焕发新生 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为你的老款Mac无法升级最新macO…...

Windows和Office激活难题终结者:KMS智能激活脚本全攻略
Windows和Office激活难题终结者:KMS智能激活脚本全攻略 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows系统那恼人的激活提醒而烦恼?是否因为Office突然…...