深度学习Week16——数据增强
文章目录
深度学习Week16——数据增强
一、前言
二、我的环境
三、前期工作
1、配置环境
2、导入数据
2.1 加载数据
2.2 配置数据集
2.3 数据可视化
四、数据增强
五、增强方式
1、将其嵌入model中
2、在Dataset数据集中进行数据增强
六、训练模型
七、自定义增强函数
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
本篇内容分为两个部分,前面部分是学习K同学给的算法知识点以及复现,后半部分是自己的拓展与未解决的问题
本期学习了数据增强函数并自己实现一个增强函数,使用的数据集仍然是猫狗数据集。
二、我的环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.0
- 编译器:Pycharm2023.2.3
深度学习环境:TensorFlow
显卡及显存:RTX 3060 8G
三、前期工作
1、配置环境
import matplotlib.pyplot as plt
import numpy as np
#隐藏警告
import warnings
warnings.filterwarnings('ignore')from tensorflow.keras import layers
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")# 打印显卡信息,确认GPU可用
print(gpus)
输出:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
这一步与pytorch第一步类似,我们在写神经网络程序前无论是选择pytorch还是tensorflow都应该配置好gpu环境(如果有gpu的话)
2、 导入数据
导入所有猫狗图片数据,依次分别为训练集图片(train_images)、训练集标签(train_labels)、测试集图片(test_images)、测试集标签(test_labels),数据集来源于K同学啊
2.1 加载数据
data_dir = "/home/mw/input/dogcat3675/365-7-data"
img_height = 224
img_width = 224
batch_size = 32train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.3,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
使用
image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
tf.keras.preprocessing.image_dataset_from_directory()会将文件夹中的数据加载到tf.data.Dataset中,且加载的同时会打乱数据。
- class_names
- validation_split: 0和1之间的可选浮点数,可保留一部分数据用于验证。
- subset: training或validation之一。仅在设置validation_split时使用。
- seed: 用于shuffle和转换的可选随机种子。
- batch_size: 数据批次的大小。默认值:32
- image_size: 从磁盘读取数据后将其重新调整大小。默认:(256,256)。由于管道处理的图像批次必须具有相同的大小,因此该参数必须提供。
输出:
Found 3400 files belonging to 2 classes.
Using 2380 files for training.
由于原始的数据集里不包含测试集,所以我们需要自己创建一个
val_batches = tf.data.experimental.cardinality(val_ds)
test_ds = val_ds.take(val_batches // 5)
val_ds = val_ds.skip(val_batches // 5)print('Number of validation batches: %d' % tf.data.experimental.cardinality(val_ds))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_ds))
Number of validation batches: 60
Number of test batches: 15
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
[‘cat’, ‘dog’]
2.2 配置数据集
AUTOTUNE = tf.data.AUTOTUNEdef preprocess_image(image,label):return (image/255.0,label)# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
2.3 数据可视化
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(5, 8, i + 1) plt.imshow(images[i])plt.title(class_names[labels[i]])plt.axis("off")

四 、数据增强
使用下面两个函数来进行数据增强:
tf.keras.layers.experimental.preprocessing.RandomFlip:水平和垂直随机翻转每个图像。tf.keras.layers.experimental.preprocessing.RandomRotation:随机旋转每个图像
data_augmentation = tf.keras.Sequential([tf.keras.layers.experimental.preprocessing.RandomFlip("horizontal_and_vertical"),tf.keras.layers.experimental.preprocessing.RandomRotation(0.3),
])
第一个层表示进行随机的水平和垂直翻转,而第二个层表示按照0.3的弧度值进行随机旋转。
# Add the image to a batch.
image = tf.expand_dims(images[i], 0)plt.figure(figsize=(8, 8))
for i in range(9):augmented_image = data_augmentation(image)ax = plt.subplot(3, 3, i + 1)plt.imshow(augmented_image[0])plt.axis("off")
五、增强方式
1. 将其嵌入model中
model = tf.keras.Sequential([data_augmentation,layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(32, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(64, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(len(class_names))
])
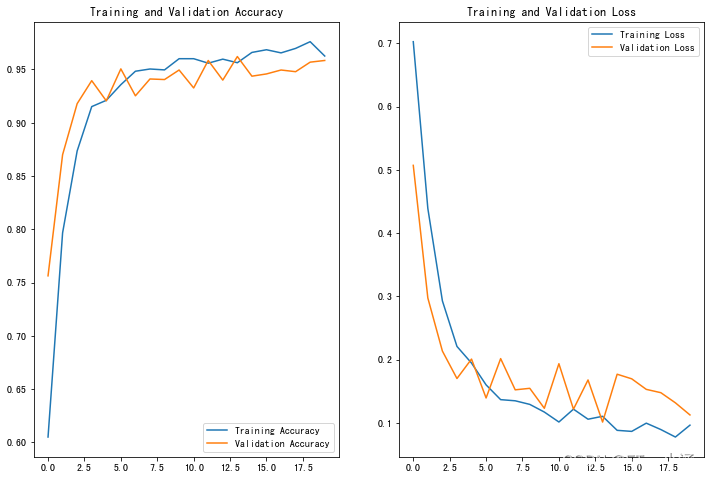
Epoch 1/20
43/43 [==============================] - 18s 103ms/step - loss: 1.2824 - accuracy: 0.5495 - val_loss: 0.4272 - val_accuracy: 0.8941
Epoch 2/20
43/43 [==============================] - 3s 55ms/step - loss: 0.3326 - accuracy: 0.8815 - val_loss: 0.1882 - val_accuracy: 0.9309
Epoch 3/20
43/43 [==============================] - 3s 54ms/step - loss: 0.1614 - accuracy: 0.9488 - val_loss: 0.1493 - val_accuracy: 0.9412
Epoch 4/20
43/43 [==============================] - 2s 54ms/step - loss: 0.1215 - accuracy: 0.9557 - val_loss: 0.0950 - val_accuracy: 0.9721
Epoch 5/20
43/43 [==============================] - 3s 54ms/step - loss: 0.0906 - accuracy: 0.9666 - val_loss: 0.0791 - val_accuracy: 0.9691
Epoch 6/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0614 - accuracy: 0.9768 - val_loss: 0.1131 - val_accuracy: 0.9559
Epoch 7/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0603 - accuracy: 0.9807 - val_loss: 0.0692 - val_accuracy: 0.9794
Epoch 8/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0577 - accuracy: 0.9793 - val_loss: 0.0609 - val_accuracy: 0.9779
Epoch 9/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0511 - accuracy: 0.9825 - val_loss: 0.0546 - val_accuracy: 0.9779
Epoch 10/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0462 - accuracy: 0.9871 - val_loss: 0.0628 - val_accuracy: 0.9765
Epoch 11/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0327 - accuracy: 0.9895 - val_loss: 0.0790 - val_accuracy: 0.9721
Epoch 12/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0242 - accuracy: 0.9938 - val_loss: 0.0580 - val_accuracy: 0.9794
Epoch 13/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0354 - accuracy: 0.9907 - val_loss: 0.0797 - val_accuracy: 0.9735
Epoch 14/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0276 - accuracy: 0.9900 - val_loss: 0.0810 - val_accuracy: 0.9691
Epoch 15/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0243 - accuracy: 0.9931 - val_loss: 0.1063 - val_accuracy: 0.9676
Epoch 16/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0253 - accuracy: 0.9914 - val_loss: 0.1142 - val_accuracy: 0.9721
Epoch 17/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0205 - accuracy: 0.9937 - val_loss: 0.0726 - val_accuracy: 0.9706
Epoch 18/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0154 - accuracy: 0.9948 - val_loss: 0.0741 - val_accuracy: 0.9765
Epoch 19/20
43/43 [==============================] - 3s 56ms/step - loss: 0.0155 - accuracy: 0.9966 - val_loss: 0.0870 - val_accuracy: 0.9721
Epoch 20/20
43/43 [==============================] - 3s 55ms/step - loss: 0.0259 - accuracy: 0.9907 - val_loss: 0.1194 - val_accuracy: 0.9721
这样做的好处是:
数据增强这块的工作可以得到GPU的加速(如果你使用了GPU训练的话)
注意:只有在模型训练时(Model.fit)才会进行增强,在模型评估(Model.evaluate)以及预测(Model.predict)时并不会进行增强操作。
2. 在Dataset数据集中进行数据增强
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNEdef prepare(ds):ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y), num_parallel_calls=AUTOTUNE)return ds
model = tf.keras.Sequential([layers.Conv2D(16, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(32, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Conv2D(64, 3, padding='same', activation='relu'),layers.MaxPooling2D(),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(len(class_names))
])
Epoch 1/20
75/75 [==============================] - 11s 133ms/step - loss: 0.8828 - accuracy: 0.7113 - val_loss: 0.1488 - val_accuracy: 0.9447
Epoch 2/20
75/75 [==============================] - 2s 33ms/step - loss: 0.1796 - accuracy: 0.9317 - val_loss: 0.0969 - val_accuracy: 0.9658
Epoch 3/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0999 - accuracy: 0.9655 - val_loss: 0.0362 - val_accuracy: 0.9879
Epoch 4/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0566 - accuracy: 0.9810 - val_loss: 0.0448 - val_accuracy: 0.9853
Epoch 5/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0426 - accuracy: 0.9807 - val_loss: 0.0142 - val_accuracy: 0.9937
Epoch 6/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0149 - accuracy: 0.9944 - val_loss: 0.0052 - val_accuracy: 0.9989
Epoch 7/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0068 - accuracy: 0.9974 - val_loss: 7.9693e-04 - val_accuracy: 1.0000
Epoch 8/20
75/75 [==============================] - 2s 33ms/step - loss: 0.0015 - accuracy: 1.0000 - val_loss: 4.8532e-04 - val_accuracy: 1.0000
Epoch 9/20
75/75 [==============================] - 2s 33ms/step - loss: 4.5804e-04 - accuracy: 1.0000 - val_loss: 1.9160e-04 - val_accuracy: 1.0000
Epoch 10/20
75/75 [==============================] - 2s 33ms/step - loss: 1.7624e-04 - accuracy: 1.0000 - val_loss: 1.1390e-04 - val_accuracy: 1.0000
Epoch 11/20
75/75 [==============================] - 2s 33ms/step - loss: 1.1646e-04 - accuracy: 1.0000 - val_loss: 8.7005e-05 - val_accuracy: 1.0000
Epoch 12/20
75/75 [==============================] - 2s 33ms/step - loss: 9.0645e-05 - accuracy: 1.0000 - val_loss: 7.1111e-05 - val_accuracy: 1.0000
Epoch 13/20
75/75 [==============================] - 2s 33ms/step - loss: 7.4695e-05 - accuracy: 1.0000 - val_loss: 5.9888e-05 - val_accuracy: 1.0000
Epoch 14/20
75/75 [==============================] - 2s 33ms/step - loss: 6.3227e-05 - accuracy: 1.0000 - val_loss: 5.1448e-05 - val_accuracy: 1.0000
Epoch 15/20
75/75 [==============================] - 2s 33ms/step - loss: 5.4484e-05 - accuracy: 1.0000 - val_loss: 4.4721e-05 - val_accuracy: 1.0000
Epoch 16/20
75/75 [==============================] - 2s 33ms/step - loss: 4.7525e-05 - accuracy: 1.0000 - val_loss: 3.9201e-05 - val_accuracy: 1.0000
Epoch 17/20
75/75 [==============================] - 2s 33ms/step - loss: 4.1816e-05 - accuracy: 1.0000 - val_loss: 3.4528e-05 - val_accuracy: 1.0000
Epoch 18/20
75/75 [==============================] - 2s 33ms/step - loss: 3.7006e-05 - accuracy: 1.0000 - val_loss: 3.0541e-05 - val_accuracy: 1.0000
Epoch 19/20
75/75 [==============================] - 2s 33ms/step - loss: 3.2878e-05 - accuracy: 1.0000 - val_loss: 2.7116e-05 - val_accuracy: 1.0000
Epoch 20/20
75/75 [==============================] - 2s 33ms/step - loss: 2.9274e-05 - accuracy: 1.0000 - val_loss: 2.4160e-05 - val_accuracy: 1.0000
六、训练模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])epochs=20
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
使用方法一:
15/15 [==============================] - 1s 58ms/step - loss: 0.0984 - accuracy: 0.9646
Accuracy 0.9645833373069763
使用方法二:
15/15 [==============================] - 1s 58ms/step - loss: 2.7453e-05 - accuracy: 1.0000
Accuracy 1.0
七、自定义增强函数
import random
def aug_img(image):seed = random.randint(0, 10000) # 随机种子# 随机亮度image = tf.image.stateless_random_brightness(image, max_delta=0.2, seed=[seed, 0])# 随机对比度image = tf.image.stateless_random_contrast(image, lower=0.8, upper=1.2, seed=[seed, 1])# 随机饱和度image = tf.image.stateless_random_saturation(image, lower=0.8, upper=1.2, seed=[seed, 2])# 随机色调image = tf.image.stateless_random_hue(image, max_delta=0.2, seed=[seed, 3])# 随机翻转水平和垂直image = tf.image.stateless_random_flip_left_right(image, seed=[seed, 4])image = tf.image.stateless_random_flip_up_down(image, seed=[seed, 5])# 随机旋转image = tf.image.rot90(image, k=random.randint(0, 3)) # 旋转0, 90, 180, 270度return image
image = tf.expand_dims(images[3]*255, 0)
print("Min and max pixel values:", image.numpy().min(), image.numpy().max())
Min and max pixel values: 2.4591687 241.47968
plt.figure(figsize=(8, 8))
for i in range(9):augmented_image = aug_img(image)ax = plt.subplot(3, 3, i + 1)plt.imshow(augmented_image[0].numpy().astype("uint8"))plt.axis("off")

然后我们使用了第二种增强方法,以下为他的结果:
15/15 [==============================] - 1s 57ms/step - loss: 0.1294 - accuracy: 0.9604
Accuracy 0.9604166746139526
相关文章:
深度学习Week16——数据增强
文章目录 深度学习Week16——数据增强 一、前言 二、我的环境 三、前期工作 1、配置环境 2、导入数据 2.1 加载数据 2.2 配置数据集 2.3 数据可视化 四、数据增强 五、增强方式 1、将其嵌入model中 2、在Dataset数据集中进行数据增强 六、训练模型 七、自定义增强函数 一、前言…...

python-自幂数判断
[题目描述]: 自幂数是指,一个N 位数,满足各位数字N 次方之和是本身。例如,153153 是 33 位数,其每位数的 33 次方之和,135333153135333153,因此 153153 是自幂数;16341634 是 44 位数…...
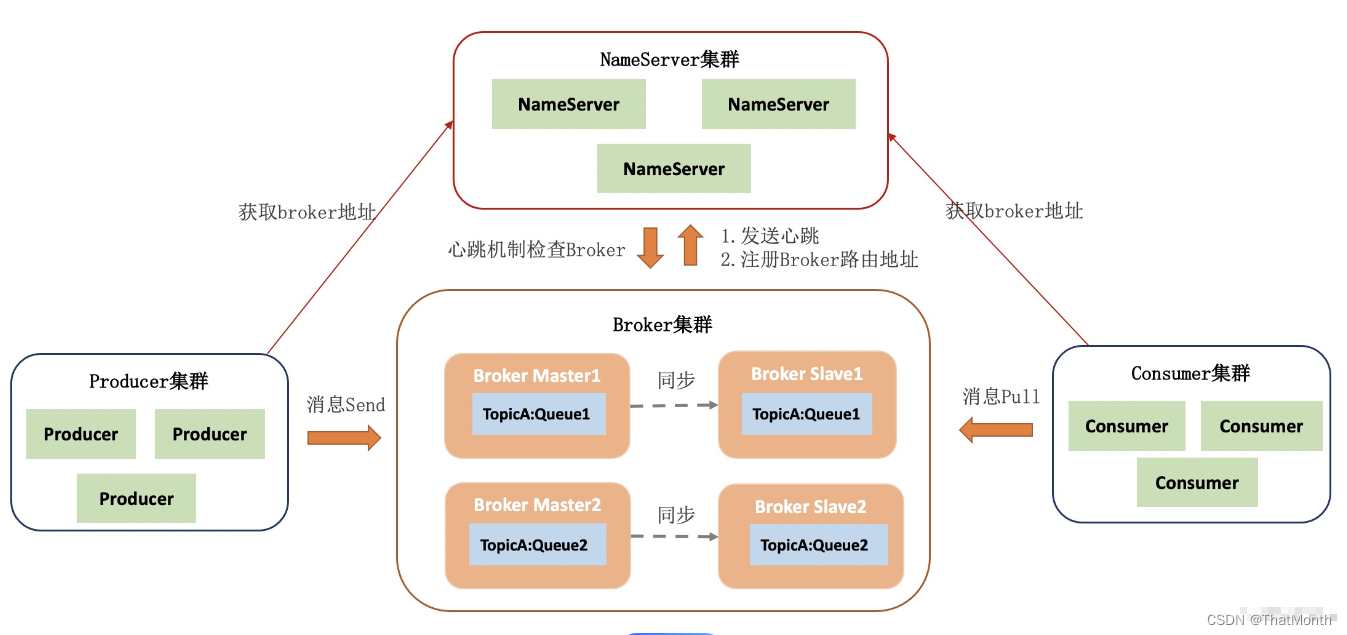
RocketMQ教程(三):RocketMQ的核心组件
四个核心组件 RocketMQ 的架构采用了典型的分布式系统设计理念,以确保高性能、高可用和可扩展性。RocketMQ 主要由四个核心组件构成:NameServer、Broker、Producer 和 Consumer。下面是对这些组件以及它们在 RocketMQ 中的角色和功能的概述: 1. NameServer 角色和功能:Name…...

46.SQLserver中按照多条件分组:查询每个地方的各种水果的种植数量,新增时,一个地方同时有几种水果,只插入一条记录,同时多种水果之间使用|隔开
1.SQLserver中按照多条件分组 ,分组条件包括(一个字段使用|进行分割,如:apple|orange,查询时,apple和orange分别对应一条数据) 例如:SQL如下: SELECT FROM ( SELECT CDFBM 地方编码…...
C盘满了怎么办,Windows11的C盘没有磁盘清理选项怎么办,一次搞定
问题: 太久没清电脑了,满的跟垃圾堆一样。。。C盘红色看上去很不妙。 一. C盘满了怎么办: 1. 删除临时文件 找到 C:\Windows\Temp,进入Temp资料夹,选中所有文件夹和文件,按下ShiftDelete键,彻…...

「动态规划」当小偷改行去当按摩师,会发生什么?
一个有名的按摩师会收到源源不断的预约请求,每个预约都可以选择接或不接。在每次预约服务之间要有休息时间,因此她不能接受相邻的预约。给定一个预约请求序列,替按摩师找到最优的预约集合(总预约时间最长),…...

Python | 排队取奶茶
队列的基本概念(队头、队尾)和特点(先入先出) 在 Python 语言中,标准库中的queue模块提供了多种队列的实现,比如普通队列和优先级队列,因此你可以使用queue.Queue类来创建队列,不过…...
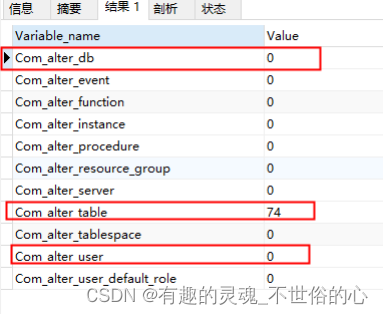
mysql当前状态分析(show status)
文章目录 查看当前线程数据查询连接情况查询缓存相关查询锁相关查询增删改查执行次数查询DDL创建相关 SHOW STATUS 是一个在 MySQL 中用来查看服务器运行状态的命令。它可以帮助你了解服务器的当前性能,包括连接数、表锁定、缓冲区使用情况等信息。 查看当前线程数据…...
——使用机器学习进行金三角大米分布图)
Google Earth Engine(GEE)——使用机器学习进行金三角大米分布图
第 1 步:转到https://code.earthengine.google.com/打开代码编辑器 第 2 步:使用以下代码从 Google Earth Engine Asset 导入数据 // 导入影像集合 var composites = ee.ImageCollection("projects/servir-mekong/yearlyComposites"); // 导入训练数据 var data …...

MyBatis一级和二级缓存介绍
MyBatis是一个持久层框架,它提供了一级缓存和二级缓存来提高数据库操作的性能。下面是一级缓存和二级缓存的区别理解、画图和知识点总结: 一级缓存: 一级缓存是MyBatis默认开启的缓存层,它是SqlSession级别的缓存,也…...

PowerDesigner遍历导出所有表结构到Excel
PowerDesigner遍历导出所有表到Excel 1.打开需要导出表结构到Excel的pdm文件 2.点击Tools|Execute Commands|Edit/Run Script菜单或按下快捷键Ctrl Shift X打开脚本窗口,输入示例VBScript脚本,修改其中的Excel模板路径及工作薄页签,点Run…...
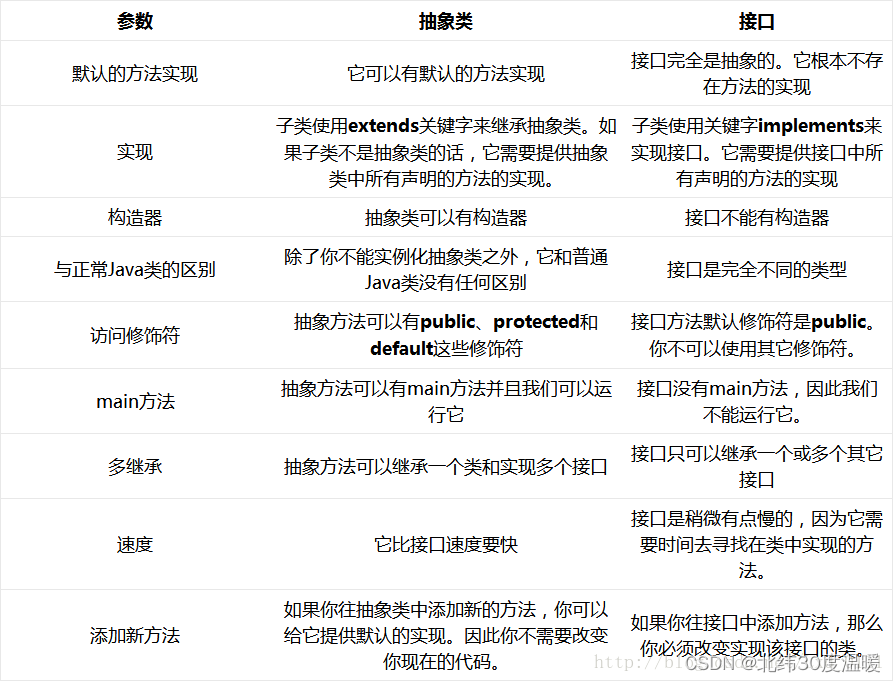
JavaSE——抽象类和接口
目录 一 .抽象类 1.抽象类概念 2.抽象类语法 3.抽象类特性 4.抽象类的作用 二. 接口 1.接口的概念 2.语法规则 3.接口的使用 4.接口特性 5.实现多个接口 6.接口间的继承 三.抽象类和接口的区别 一 .抽象类 1.抽象类概念 在面向对象的概念中,所有的对…...
生成式人工智能 - stable diffusion web-ui安装教程
一、Stable Diffusion WEB UI 屌丝劲发作了,所以本地调试了Stable Diffusion之后,就去看了一下Stable Diffusion WEB UI,网络上各种打包套件什么的好像很火。国内的也就这个层次了,老外搞创新,国内跟着屁股后面搞搞应用层,就叫大神了。 不扯闲篇了,我们这里从git源码直接…...
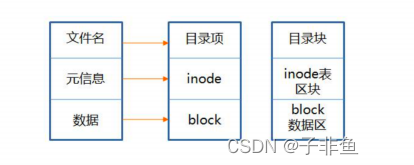
11-Linux文件系统与日志分析
11.1深入理解Linux文件系统 在处理Liunx系统出现故障时,故障的症状是最易发现。数学LInux系统中常见的日志文件,可以帮助管理员快速定位故障点,并及时解决各种系统问题。 11.1.1 inode与block详解 文件系统通常会将这两部分内容分别存放在…...
mac M1下安装PySide2
在M1下装不了PySide2, 是因为PySide2没有arm架构的包 1 先在M1上装qt5 安装qt主要是为了能用里面的Desinger, uic, rcc brew install qt5 我装完的路径在/opt/homebrew/opt/qt5 其中Designer就是用来设计界面的 rcc用resource compiler, 编绎rc资源文件的, 生成对应的py文件…...

超详解——识别None——小白篇
目录 1. 内建类型的布尔值 2. 对象身份的比较 3. 对象类型比较 4. 类型工厂函数 5. Python不支持的类型 总结: 1. 内建类型的布尔值 在Python中,布尔值的计算遵循如下规则: None、False、空序列(如空列表 [],空…...

C++的MQTT开发:使用Paho的C++接口实现消息发布、订阅、连接RabbitMQ
C Paho实现MQTT消息发布功能 要使用paho的cpp接口实现发布MQTT消息的功能,需要进行以下步骤: 安装paho库:首先从paho官方网站下载并安装paho的C库。可以从https://www.eclipse.org/paho/clients/cpp/ 下载适合操作系统的版本。 创建MQTT客户…...

深度网络学习笔记(二)——Transformer架构详解(包括多头自注意力机制)
Transformer架构详解 前言Transformer的整体架构多头注意力机制(Multi-Head Attention)具体步骤1. 步骤12. 步骤23. 步骤34. 步骤4 Self-Attention应用与比较Self-Attention用于图像处理Self-Attention vs. CNNSelf-Attention vs. RNN Transformer架构详…...
Python 快速查找并替换Excel中的数据
Excel中的查找替换是一个非常实用的功能,能够帮助用户快速完成大量数据的整理和处理工作,避免手动逐一修改数据的麻烦,提高工作效率。要使用Python实现这一功能, 我们可以借助Spire.XLS for Python 库,具体操作如下&am…...

KafkaStream Local Store和Global Store区别和用法
前言 使用kafkaStream进行流式计算时,如果需要对数据进行状态处理,那么常用的会遇到kafkaStream的store,而store也有Local Store以及Global Store,当然也可以使用其他方案的来进行状态保存,文本主要理清楚kafkaStream…...

Vex:VS Code向量数据库管理扩展,提升AI开发效率
1. 项目概述:Vex,一个为开发者设计的向量数据库管理利器如果你正在用 VS Code 开发 AI 应用,并且和向量数据库(比如 Milvus 或 ChromaDB)打交道,那你大概率经历过这样的场景:为了插入几条测试向…...

移动通信浪潮如何重塑半导体产业格局:从高通与英特尔市值对比说起
1. 从市场估值看产业浪潮:移动通信如何重塑半导体格局2013年春天,一则消息在半导体和投资圈内引发了不小的震动:无线通信芯片巨头高通(Qualcomm)的市值,悄然与行业传统霸主英特尔(Intel…...

markdownReader:终极Chrome插件,让本地Markdown文件阅读体验提升300%
markdownReader:终极Chrome插件,让本地Markdown文件阅读体验提升300% 【免费下载链接】markdownReader markdownReader is a extention for chrome, used for reading markdown file. 项目地址: https://gitcode.com/gh_mirrors/ma/markdownReader …...

模块化前端框架设计:从原子状态到组合式架构的工程实践
1. 项目概述:一个轻量级、模块化的现代Web应用框架最近在梳理手头的几个前端项目,发现随着功能迭代,代码越来越臃肿,不同项目间的基础工具函数、状态管理逻辑、路由配置总是要重新写一遍,或者复制粘贴,维护…...
✅)
计算机毕业设计:Python智慧医疗数据可视化与疾病预测系统 Flask框架 随机森林 机器学习 疾病数据 智慧医疗 深度学习(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

基于浏览器自动化的高级爬虫框架autoclaw实战指南
1. 项目概述与核心价值最近在折腾自动化脚本时,发现了一个挺有意思的GitHub项目,叫jmoraispk/autoclaw。乍一看名字,可能会联想到“自动爪子”或者“爬虫”,实际上,它也确实是一个专注于自动化网页交互和数据抓取的工具…...

终极ROFL播放器指南:如何免费快速解锁英雄联盟回放文件分析
终极ROFL播放器指南:如何免费快速解锁英雄联盟回放文件分析 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为无法查看英…...

可穿戴ESD监测:从被动防护到主动感知的静电管理革命
1. 项目概述:当静电成为“幽灵”,可穿戴监测如何为航空航天制造“显形” 在航空航天和高可靠性电子制造领域,我们常常与一个看不见的“幽灵”作斗争——静电放电。这个“幽灵”无声无息,却能轻易摧毁价值数十万甚至数百万美元的精…...

django-notifications故障排除:常见问题诊断与解决方案大全
django-notifications故障排除:常见问题诊断与解决方案大全 【免费下载链接】django-notifications GitHub notifications alike app for Django 项目地址: https://gitcode.com/gh_mirrors/dj/django-notifications django-notifications是一个为Django应用…...

告别调参烦恼:用MATLAB Simulink手把手教你实现直流无刷电机的模糊PID控制
直流无刷电机模糊PID控制实战:从Simulink建模到参数自整定 在工业自动化领域,电机控制算法的优劣直接决定了设备性能的上限。传统PID控制器虽然结构简单,但当面对直流无刷电机这类非线性系统时,工程师往往需要花费大量时间反复调整…...