Scanpy(3)单细胞数据分析常规流程
单细胞数据分析常规流程
面对高效快速的要求上,使用R分析数据越来越困难,转战Python分析,我们通过scanpy官网去学习如何分析单细胞下游常规分析。
数据3k PBMC来自健康的志愿者,可从10x Genomics免费获得。在linux系统上,可以取消注释并运行以下操作来下载和解压缩数据。最后一行创建一个用于保存已处理数据的目录write,后面直接使用保存的数据,能快速加载数据。
下载数据:
$mkdir data
$cd data
$wget http://cf.10xgenomics.com/samples/cell-exp/1.1.0/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz -O ../data/pbmc3k_filtered_gene_bc_matrices.tar.gz
$tar -xzf pbmc3k_filtered_gene_bc_matrices.tar.gz
# 获得数据
1. 数据加载
import numpy as np
import pandas as pd
import scanpy as scsc.settings.verbosity = 3 # verbosity: errors (0), warnings (1), info (2), hints (3)
sc.logging.print_header()
sc.settings.set_figure_params(dpi=80, facecolor='white')# 声明h5ad用于存储分析结果
results_file = 'data/write/pbmc3k.h5ad'adata = sc.read_10x_mtx('data/filtered_gene_bc_matrices/hg19/', # `.mtx`文件所在的目录var_names='gene_symbols', # 用 gene 作为varcache=True) # 开启缓存读写"""
注意cache=Trure
... writing an h5ad cache file to speedup reading next time
下次读取就不会从count matrix读, 会直接从cache目录下的h5ad文件读(更快)
"""
在函数 sc.read_10x_mtx 中,参数 var_names 用于指定在加载数据时使用哪个变量来作为基因的名称。在这里,如果你将 var_names='gene_ids',它将使用基因的唯一标识符作为变量名,而如果你将 var_names='gene_symbols',它将使用基因的符号名称作为变量名。
这两者之间的区别在于:
-
gene_ids:使用基因的唯一标识符作为变量名。这通常是一种更确切和唯一的标识,不同基因之间不存在重复。使用基因的唯一标识符作为变量名可以确保在分析中每个基因都有唯一的标识符,并且不会出现混淆或重复。
-
gene_symbols:使用基因的符号名称作为变量名。基因的符号名称通常更容易理解和记忆,因为它们通常是基于基因的功能或特征而命名的。然而,基因的符号名称不一定是唯一的,可能存在多个基因具有相同的符号名称,这可能会导致一些混淆或不一致。
因此,你可以根据具体的需求和分析的目的来选择使用哪种类型的变量名。如果需要确保每个基因都具有唯一的标识符,并且不会出现混淆或重复,那么可以使用 gene_ids。如果更关注基因的功能或特征,并且不太担心可能存在的重复符号名称,那么可以使用 gene_symbols。
注意,如果在函数sc.read_10x_mtx中指定参数var_names='gene_ids'时,下一个操作将是不必要的:
# 消除重复的列
adata.var_names_make_unique()print(adata)AnnData object with n_obs × n_vars = 2700 × 32738var: 'gene_ids'
adata包含2700个细胞、32738个基因的对象
2. top基因箱型图
下图计算每一个基因在所有细胞中的平均表达量,并绘制了平均表达量前30的基因箱型图。
sc.pl.highest_expr_genes(adata, n_top=30)

计算每一个基因在所有细胞中的平均表达量。所有细胞中平均分数最高n_top的基因被绘制为箱形图。
3. 质量控制
然后进行基本的过滤(质量控制),使用两个工具:
sc.pp.filter_cells进行细胞的过滤,该函数保留至少有min_genes个基因(某个基因表达非0可判断存在该基因)的细胞,或者保留至多有max_genes个基因的细胞;sc.pp.filter_genes进行基因的过滤,该函数用于保留在至少min_cells个细胞中出现的基因,或者保留在至多max_cells个细胞中出现的基因;
# 基因表达低于200的细胞将要删除
sc.pp.filter_cells(adata, min_genes=200)
# 至少 3 个细胞中检测到表达的基因才会被保留下来
sc.pp.filter_genes(adata, min_cells=3)print(adata)AnnData object with n_obs × n_vars = 2700 × 13714obs: 'n_genes'var: 'gene_ids', 'n_cells'
# 稀疏矩阵通常用于表示高维数据,例如基因表达数据,其中大多数值都是零
print(adata.X)
# 结果如下:
(0, 29) 1.0
(0, 73) 1.0
(0, 80) 2.0
(0, 148) 1.0
(0, 163) 1.0
(0, 184) 1.0print(adata.var)
# 结果如下:gene_ids n_cells
AL627309.1 ENSG00000237683 9
AP006222.2 ENSG00000228463 3
RP11-206L10.2 ENSG00000228327 5
RP11-206L10.9 ENSG00000237491 3
LINC00115 ENSG00000225880 18
稀疏矩阵中,每个元素由三个值组成:(i, j, value)。其中,i 表示行索引,j 表示列索引,而 value 表示在索引为 (i, j) 的位置上的值。在这个例子中,adata.X 返回的稀疏矩阵包含了多个非零元素。每一行代表一个样本或数据点,每一列代表一个特征或基因。
adata.var 是一个 DataFrame,它包含两列:gene_ids 和 n_cells。
gene_ids列包含基因的标识符或 ID,每行对应于一个基因。n_cells列包含每个基因在数据集中出现的细胞数目,即在多少个细胞中检测到了该基因。
通过查看 adata.var,你可以获得关于数据集中基因的一些信息,比如它们的标识符以及它们在样本中的表达情况。
3.1 质控选做
下一步是过滤线粒体核糖体基因(质量控制的选做步骤):这是一个很难把握的工作,需要结合自己项目的情况来做。不过通常有以下策略:
- 粗暴去除所有线粒体核糖体基因,直接去除包含”MT-”开头的基因。
- 选择阈值去除高表达量的细胞,阈值很大程度上取决于对自己项目的了解程度,因为不同器官组织提取的单细胞,线粒体基因平均水平不一样。
使用pp.calculate_qc_metrics,我们可以高效计算很多度量指标:
# 将 adata.var_names 列中以 "MT-" 开头的元素赋值为 True,并将其保存在 adata.var Dataframe 的 mt 列中。
adata.var['mt'] = adata.var_names.str.startswith('MT-')
adata.var['mt']
"""
AL627309.1 False...
SRSF10-1 False
Name: mt, Length: 13714, dtype: bool
"""# 计算指标相关文章:
Scanpy(3)单细胞数据分析常规流程
单细胞数据分析常规流程 面对高效快速的要求上,使用R分析数据越来越困难,转战Python分析,我们通过scanpy官网去学习如何分析单细胞下游常规分析。 数据3k PBMC来自健康的志愿者,可从10x Genomics免费获得。在linux系统上,可以取消注释并运行以下操作来下载和解压缩数据。…...

【Stable Diffusion】(基础篇二)—— Stable Diffusion图形界面介绍和基本使用流程
本系列笔记主要参考B站nenly同学的视频教程,传送门:B站第一套系统的AI绘画课!零基础学会Stable Diffusion,这绝对是你看过的最容易上手的AI绘画教程 | SD WebUI 保姆级攻略_哔哩哔哩_bilibili 在上一篇博客中,我们成功…...
OpenCv之简单的人脸识别项目(动态处理页面)
人脸识别 准备九、动态处理页面1.导入所需的包2.设置窗口2.1定义窗口外观和大小2.2设置窗口背景2.2.1设置背景图片2.2.2创建label控件 3.定义视频处理脚本4.定义相机抓取脚本5.定义关闭窗口的函数6.按钮设计6.1视频处理按钮6.2相机抓取按钮6.3返回按钮 7.定义关键函数8.动态处理…...
【Linux】进程间通信
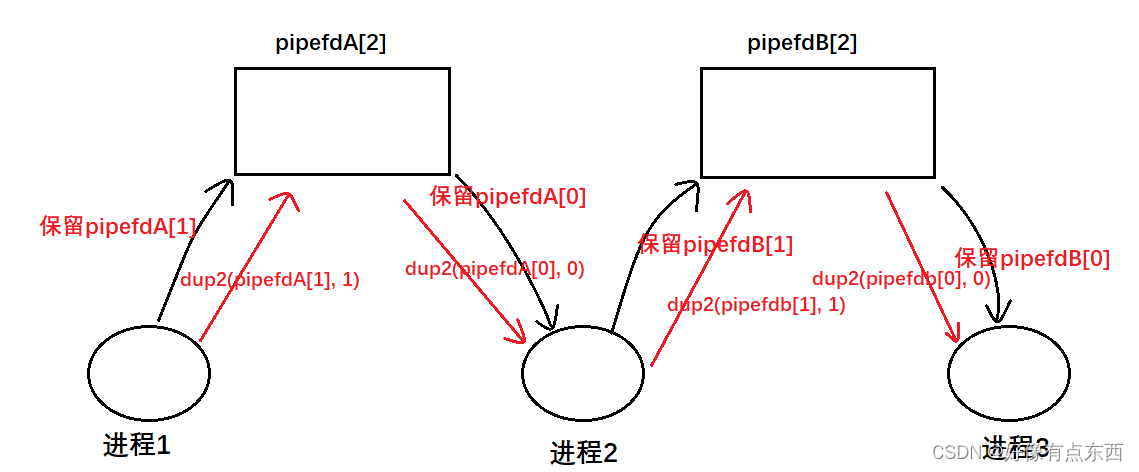
目录 一、进程间通信概念 二、进程间通信的发展 三、进程间通信的分类 四、管道 4.1 什么是管道 4.2 匿名管道 4.2 基于匿名管道设计进程池 4.3 命名管道 4.4 用命名管道实现server&client通信 五、system V共享内存 5.1 system V共享内存的引入 5.2 共享内存的…...

UI与前端:揭秘两者的微妙差异
UI与前端:揭秘两者的微妙差异 在数字化时代的浪潮中,UI设计和前端开发已成为塑造用户体验的两大核心力量。然而,这两者之间究竟有何区别?本文将深入剖析UI设计与前端开发的四个方面、五个方面、六个方面和七个方面的差异…...
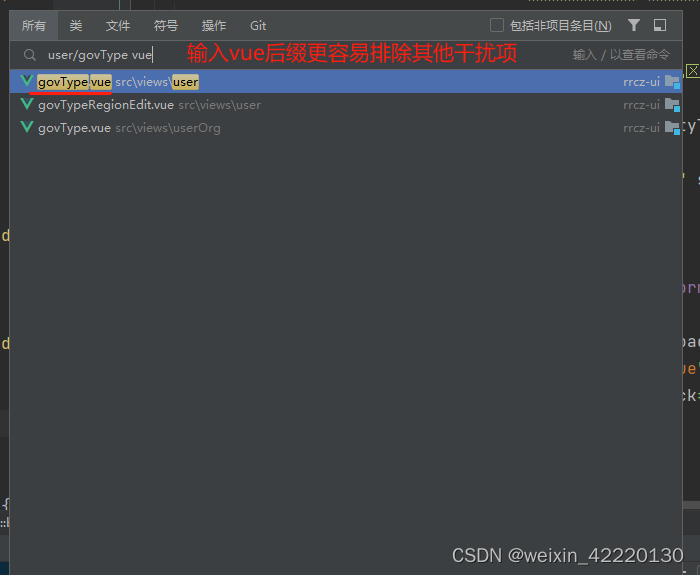
idea如何根据路径快速在项目中快速打卡该页面
在idea项目中使用快捷键shift根据路径快速找到该文件并打卡 双击shift(连续按两下shift) -粘贴文件路径-鼠标左键点击选中跳转的路径 自动进入该路径页面 例如:我的实例路径为src/views/user/govType.vue 输入src/views/user/govType或加vue后缀src/views/user/go…...

探索成功者的特质——俞敏洪的观点启示
在人生的舞台上,我们常常对成功者充满好奇与敬仰,试图探寻他们成功的奥秘。俞敏洪指出,成功者都具备七个特质,而这些特质与家庭背景和大学的好坏并无直接关系。让我们深入剖析这七个特质,或许能从中获得对我们自身成长…...

MCU的环形FIFO
fifo.h #ifndef __FIFO_H #define __FIFO_H#include "main.h"#define RINGBUFF_LEN (500) //定义最大接收字节数 500typedef struct {uint16_t Head; // 头指针 指向可读起始地址 每读一个,数字1uint16_t Tail; // 尾指针 指…...
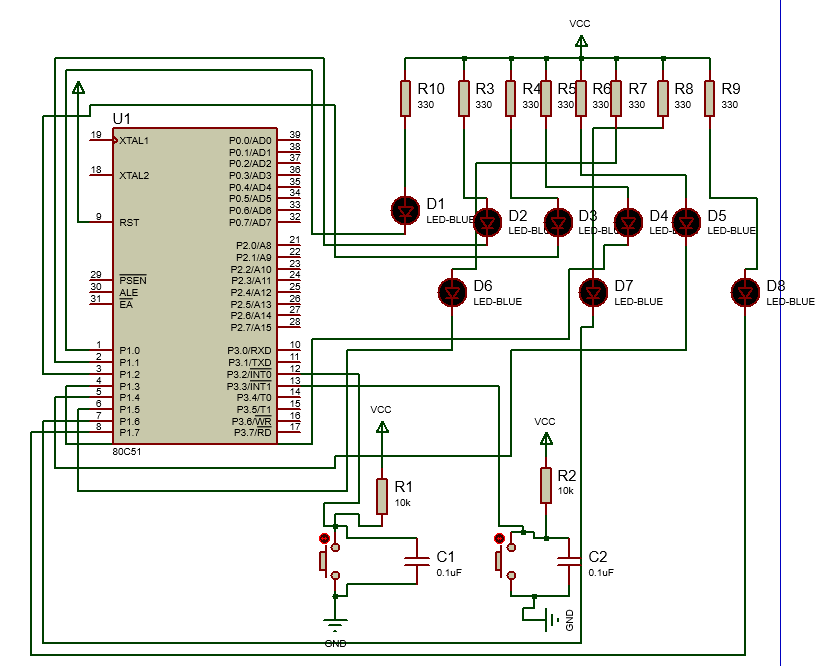
使用proteus仿真51单片机的流水灯实现
proteus介绍: proteus是一个十分便捷的用于电路仿真的软件,可以用于实现电路的设计、仿真、调试等。并且可以在对应的代码编辑区域,使用代码实现电路功能的仿真。 汇编语言介绍: 百度百科介绍如下: 汇编语言是培养…...

【漏洞复现】Apache OFBiz 路径遍历导致RCE漏洞(CVE-2024-36104)
0x01 产品简介 Apache OFBiz是一个电子商务平台,用于构建大中型企业级、跨平台、跨数据库、跨应用服务器的多层、分布式电子商务类应用系统。是美国阿帕奇(Apache)基金会的一套企业资源计划(ERP)系统。该系统提供了一整套基于Java的Web应用程序组件和工具。 0x02 …...

数据库表中创建字段查询出来却为NULL?
起因: 今天新创建了一张表,其中一个字段命名为"word_num"带下划线,我在前端页面怎么也查询不出来word_num的值,后来在后端接口处打印了一下数据库查询出来的数据,发现这个字段一直为NULL,然后我就想到是不是…...

缓存方法返回值
1. 业务需求 前端用户查询数据时,数据查询缓慢耗费时间; 基于缓存中间件实现缓存方法返回值:实现流程用户第一次查询时在数据库查询,并将查询的返回值存储在缓存中间件中,在缓存有效期内前端用户再次查询时,从缓存中间件缓存获取 2. 基于Redis实现 参考1 2.1 简单实现 引入…...
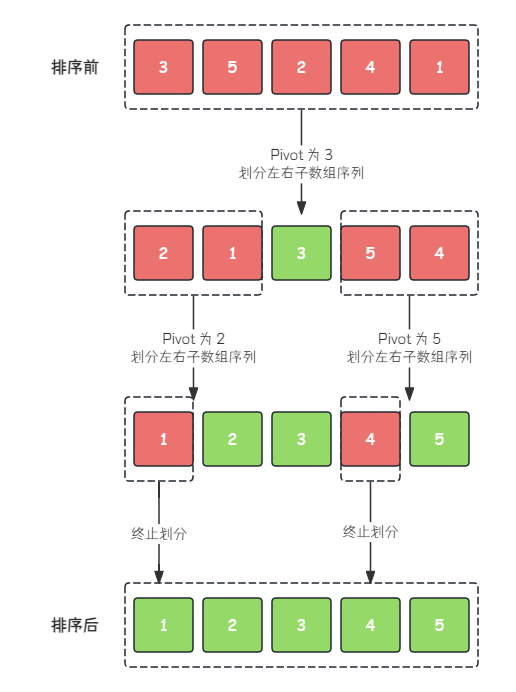
【十大排序算法】快速排序
在乱序的世界中,快速排序如同一位智慧的园丁, 以轻盈的手法,将无序的花朵们重新安排, 在每一次比较中,沐浴着理性的阳光, 终使它们在有序的花园里,开出绚烂的芬芳。 文章目录 一、快速排序二、…...

linux系统ubuntu中在命令行中打开图形界面的文件夹
在命令行中打开当前路径,以文件管理器的形式打开: 命令 # 打开文件管理器 当前的路径 nautilus .nautilus 是一个与 GNOME 桌面环境集成的文件管理器的命令行启动程序。在 Linux 系统中,特别是使用 GNOME 作为桌面环境时,用户经…...
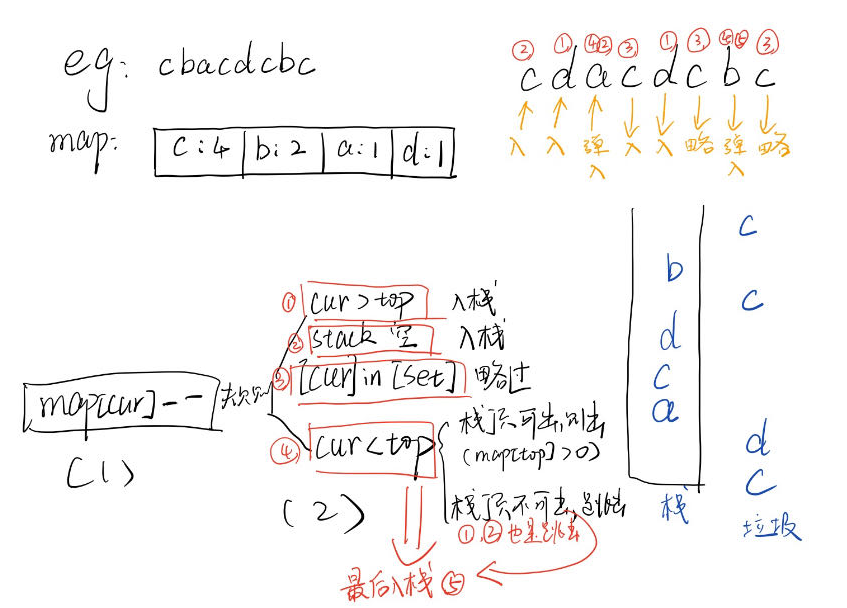
【C++11数据结构与算法】C++ 栈
C 栈(stack) 文章目录 C 栈(stack)栈的基本介绍栈的算法运用单调栈实战题LC例题:[321. 拼接最大数](https://leetcode.cn/problems/create-maximum-number/)LC例题:[316. 去除重复字母](https://leetcode.cn/problems/remove-duplicate-letters/) 栈的基…...
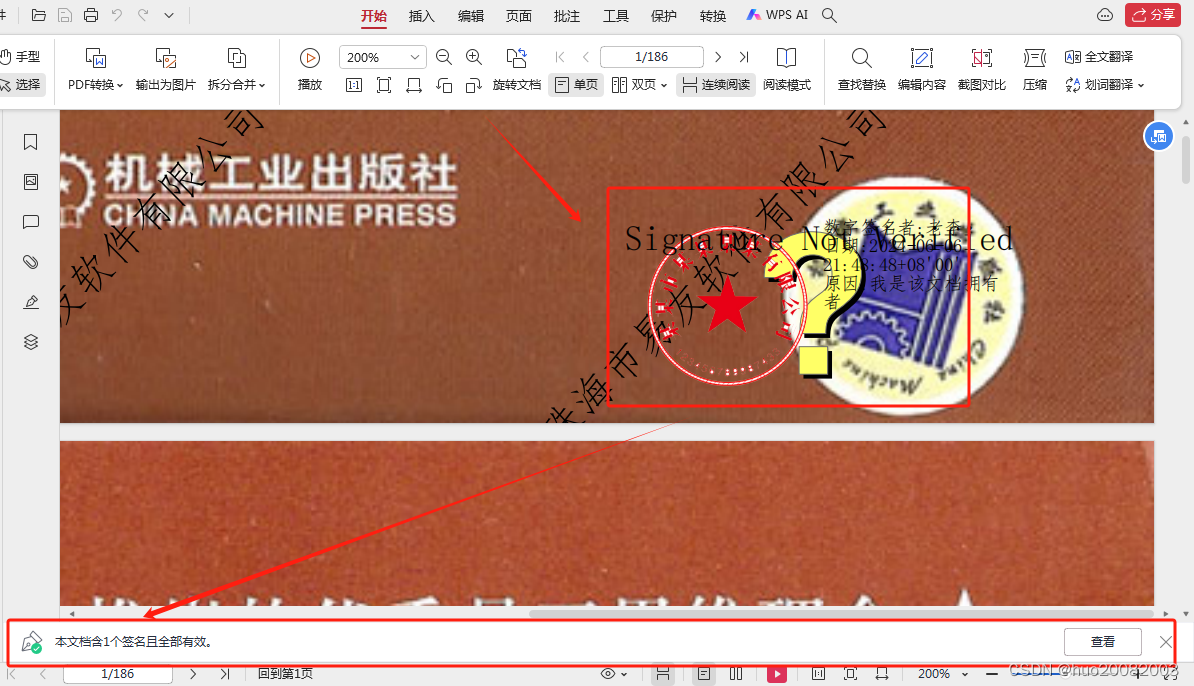
pdf文件如何防篡改内容
PDF文件防篡改内容的方法有多种,以下是一些常见且有效的方法,它们可以帮助确保PDF文件的完整性和真实性: 加密PDF文档: 原理:通过设置密码来保护PDF文档,防止未经授权的访问和修改。注意事项:密…...
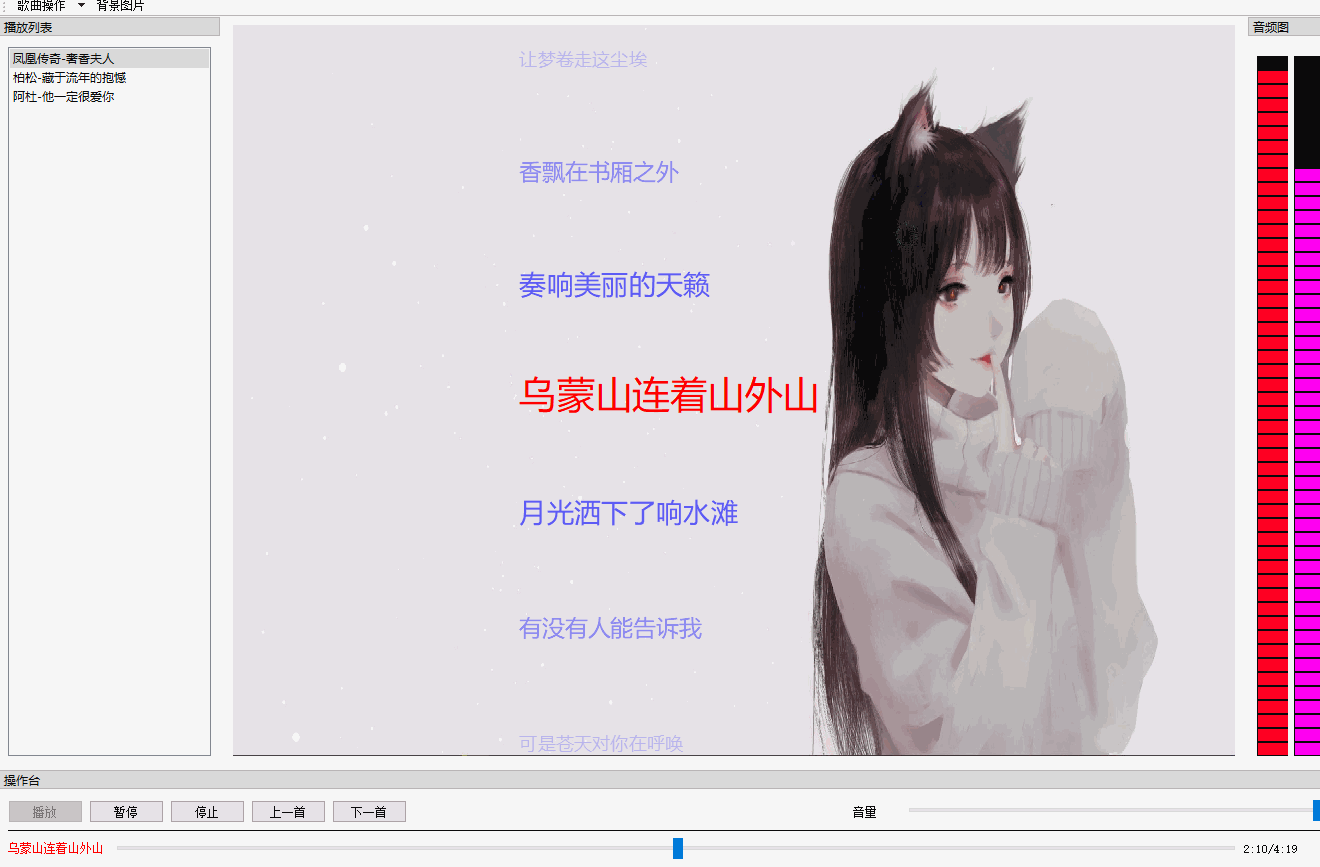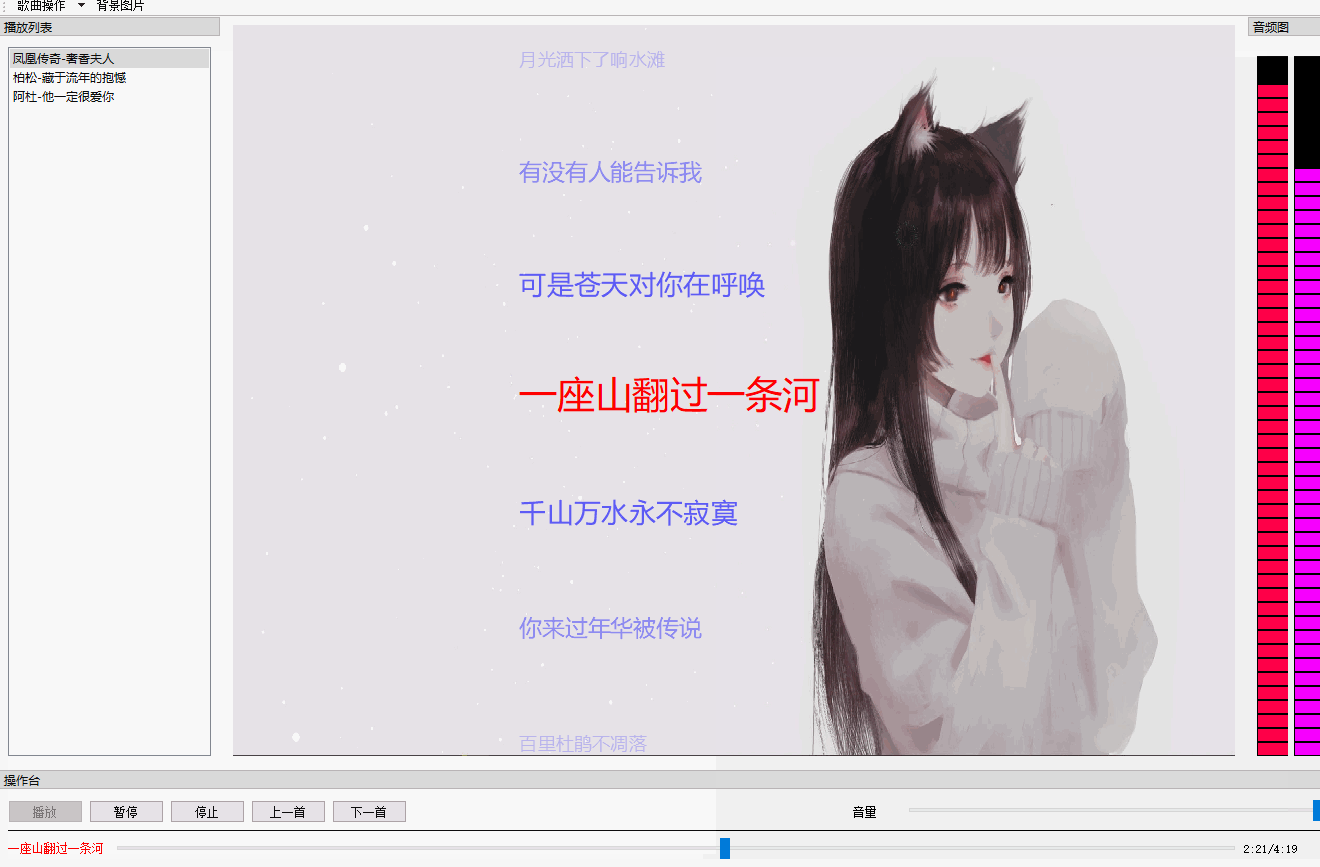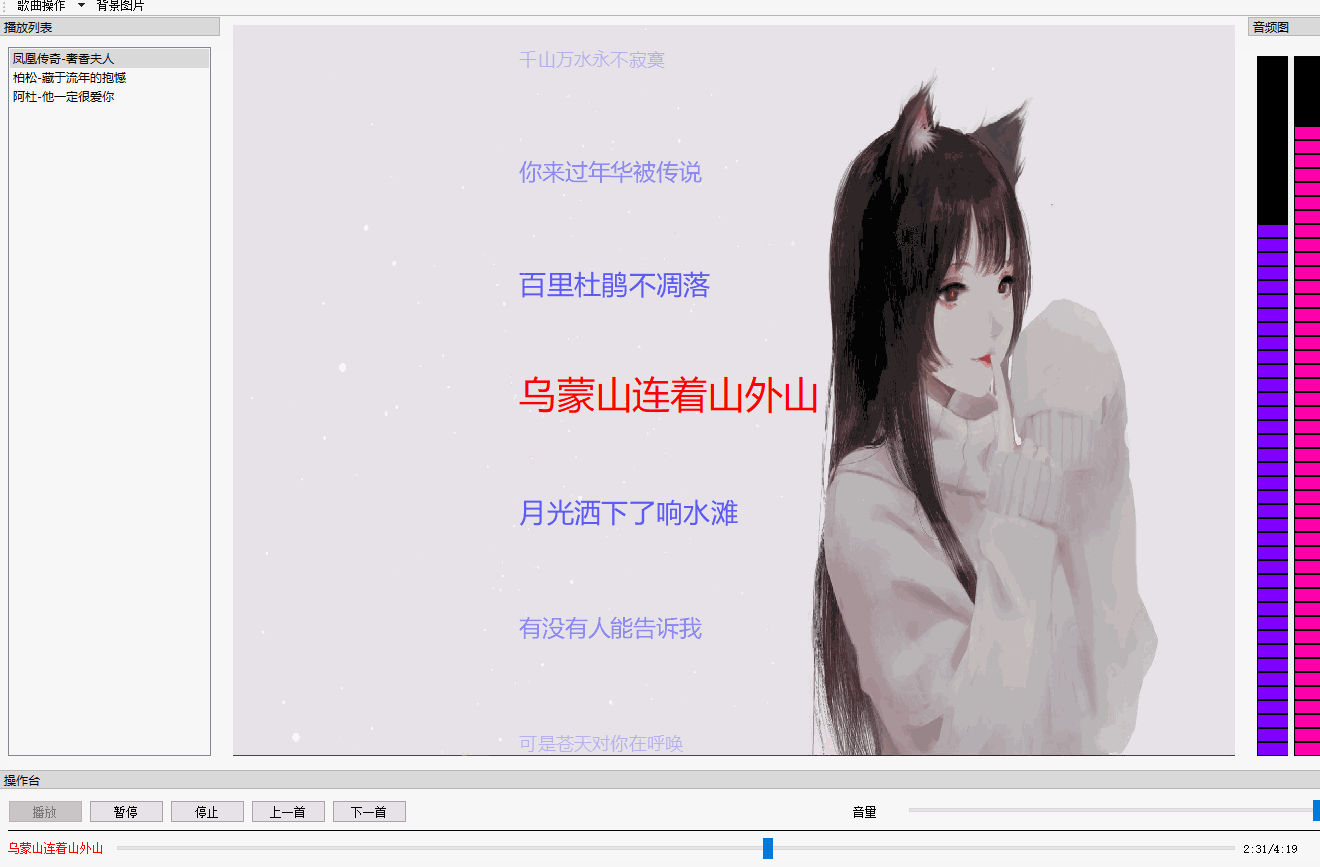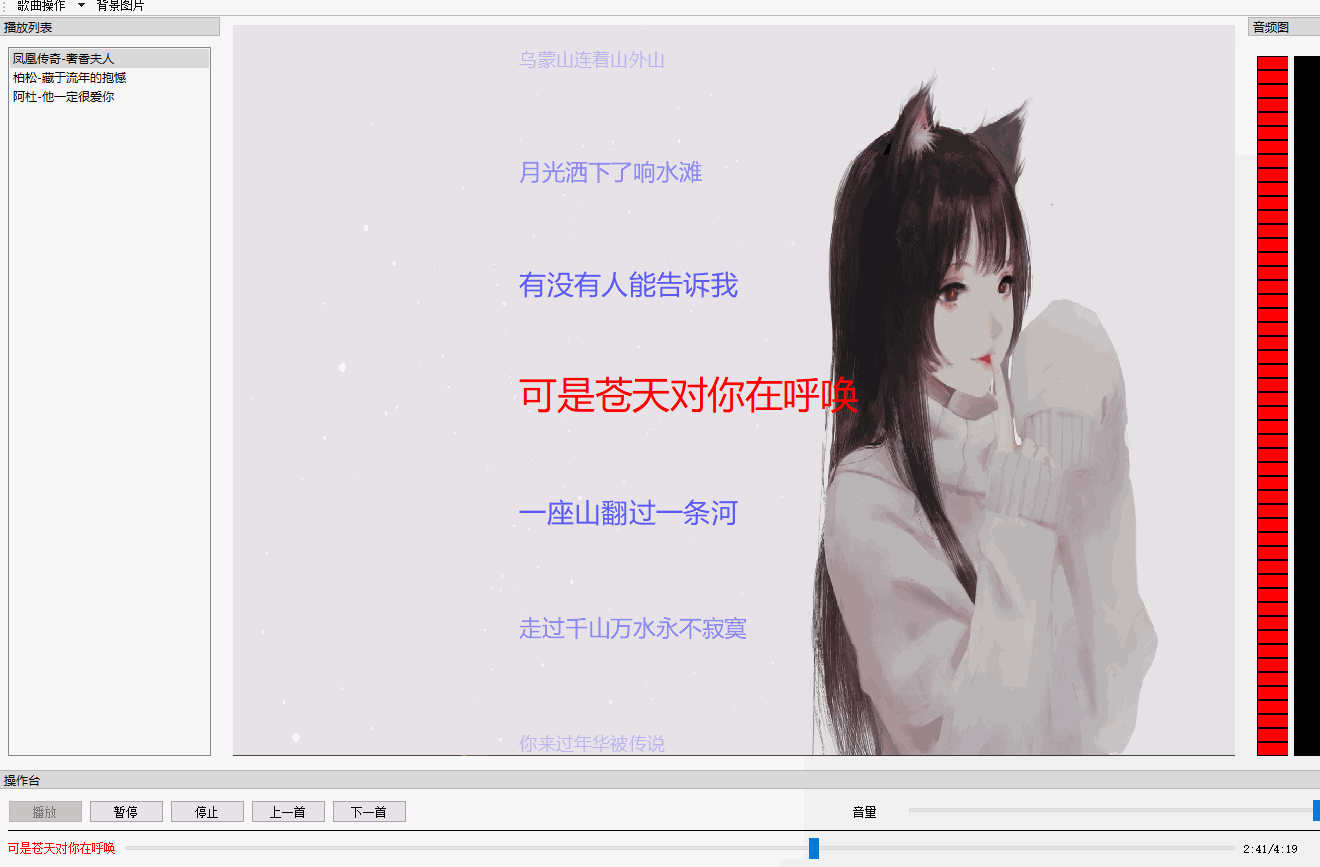
QT 音乐播放器【二】 歌词同步+滚动+特效
文章目录 效果图概述代码解析歌词歌词同步歌词特效 总结 效果图 概述 先整体说明一下这个效果的实现,你所看到的歌词都是QGraphicsObject,在QGraphicsView上绘制(paint)出来的。也就是说每一句歌词都是一个图元(item)。 为什么用QGraphicsView框架&…...
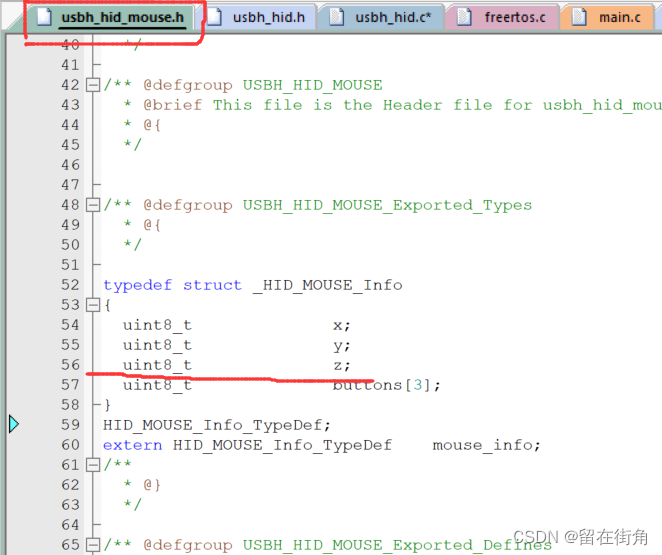
关于怎么用Cubemx生成的USBHID设备实现读取一体的鼠标键盘设备(改进版)
主要最近做了一个要用STM32实现读取鼠标键盘一体的那种USB设备,STM32的界面上要和电脑一样的能通过这个USB接口实现鼠标移动,键盘的按键。然后我就很自然的去参考了正点原子的例程,可是找了一圈,发现正点原子好像用的库函数&#…...
Soildworks学习笔记(二)
放样凸台基体: 自动生成连接两个物体两个面的基体: 2.旋转切除: 3.剪切实体: 4.转换实体引用: 将实体的轮廓线转换至当前草图使其成为当前草图的图元,主要用于在同一平面或另一个坐标中制作草图实体或其尺寸的副本。 …...

Linux配置uwsgi环境
Linux配置uwsgi环境 1.进入虚拟环境 source /envs/django_-shop-system/bin/activate2.安装uwsgi pip install uwsgi3.基于uwsgi运行项目 – 基于配置文件 在项目目录下创建配置文件 #socket 0.0.0.0:8005 http 0.0.0.0:8005 # http120.55.47.111:8005 chdir/opt/www/djang…...

苹果将在培训应用中采用AI生成主播,解决传统培训规模化与个性化难题
苹果培训应用引入AI生成主播据9to5mac报道,Aaron Perris在X平台披露,苹果公司将很快在其内部培训应用“Apple Sales Coach”中采用AI生成主播,用于制作销售培训视频。该应用由苹果此前的“SEED”应用更新而来,旨在向全球苹果销售合…...

【大白话说Java面试题 第49题】【JVM篇】第9题:什么是双亲委派机制?介绍一下运作过程。?
📌 PDF:大白话说Java面试题 — 02-JVM篇 第9题:什么是双亲委派机制?介绍一下运作过程。 📚 回答: 核心概念: 双亲委派机制 是 JVM 中类加载器的工作模式,用于保证类加载的安全性和…...

OAI 5G核心网搭建后,如何用Docker命令进行日常运维和故障排查?
OAI 5G核心网Docker运维实战:从日志分析到故障排查 当OAI 5G核心网完成基础部署后,真正的挑战才刚刚开始。面对由多个容器组成的复杂系统,如何快速定位AMF拒绝注册的原因?SMF的PDU会话建立失败该如何排查?本文将分享一…...

基于AI与贝叶斯学习的开源LinkedIn自动化销售探索代理部署指南
1. 项目概述:一个能自己找客户的AI销售代理如果你在B2B销售、市场拓展或者创业,你一定对LinkedIn又爱又恨。爱的是,它几乎是全球最精准的B2B客户数据库;恨的是,手动寻找、筛选、联系潜在客户,是一个极其耗时…...

从DP-V0到DP-V2:一文讲透Profibus-DP三大版本的核心差异与工业现场选型建议
从DP-V0到DP-V2:Profibus-DP三大版本的核心差异与工业现场选型指南 在工业自动化领域,实时通信协议的选型往往直接决定生产线的响应速度、诊断能力和系统扩展性。作为制造业自动化系统中应用最广泛的现场总线之一,Profibus-DP历经三次重大版本…...

React 18 + Vite + Tailwind CSS 构建现代化SaaS落地页实战
1. 项目概述与设计思路最近在做一个保险科技(InsurTech)相关的概念项目,需要为这个名为“Insura”的SaaS平台打造一个现代化的落地页(Landing Page)。这个页面的核心目标很明确:向潜在客户(主要…...

叫不动下属、又不能裁?中层必看!不撕破脸、不内耗,3招拿捏摆烂员工
很多中层都有这样的困境:上面领导催进度,下面员工躺平摆烂,叫不动、推不动;想辞退,却因编制、合同等原因动不了,要么硬刚撕破脸,要么忍气吞声自己扛,内耗严重还没成效。 其实&#…...

百度首页网页图片更多当AI开始写测试用例,手工测试工程师的护城河在哪里?
一、 第一道护城河:从“用例执行者”到“策略设计者”AI可以基于需求文档和历史数据,瞬间生成海量测试用例。但它无法回答一个根本性的问题:我们究竟应该测试什么?测试策略的设计,是在有限的时间和资源下,对…...

CircuitMaker免费PCB设计工具:从开源协议到实战避坑指南
1. 从“Freemium”到“全免费”:CircuitMaker的定位之变与我的选择时间过得真快,距离Altium首次推出免费的CircuitMaker工具,仿佛就在昨天。我记得当时业界一片哗然,大家都在讨论这家以高端、专业的Altium Designer闻名的公司&…...
函数绘制三维曲面图)
用surf( )函数绘制三维曲面图
在“用plot3( )函数绘制三维曲线图”中,实现了三维曲线的绘制,得到了一个类似面包圈形状的旋转曲面,很喜欢这个造型,就想到是不是可以直接绘制出曲面,而不只是用曲线方式绘制出看起来像曲面的图形。一看参考书…...