数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析
数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析
作者:AOAIYI
作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:数据分析 |
|---|
| 数据分析:某电商优惠卷数据分析 |
| 数据分析:旅游景点销售门票和消费情况分析 |
| 数据分析:消费者数据分析 |
| 数据分析:餐厅订单数据分析 |
| 数据分析:基于随机森林(RFC)对酒店预订分析预测 |
文章目录
- 数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析
- 一、前言
- 二、数据准备
- 三、数据预处理
- 四、建立模型
- 五、模型验证
- 总结
一、前言
k-近邻算法是分类数据最简单最有效的算法,k-近邻算法是基于实例的学习,使用算法时我们必须有接近实际数据的训练样本数据。k-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外,由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。k-近邻算法的另一个缺陷是它无法给出任何数据的基础结构信息,因此我们也无法知晓平均实例样本和典型实例样本具有什么特征。
二、数据准备
1.数据准备

2.导入数据
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
data = pd.read_csv("../input/Diabetes/pima-indians-diabetes.csv")
data.head()
data.shape

三、数据预处理
1.将每一列的标签重新命名
data.columns = ["Pregnancies","Glucose","BloodPressure","SkinThickness","Insulin","BMI","DiabetesPedigreeFunction","Age","Outcome"]
data.head()
2.查看有没有空值数据
data.isnull().any()

3.观察样本中阳性和阴性的个数
data.groupby("Outcome").size()

4.分离特征和标签
X=data.iloc[:,0:8]
Y=data.iloc[:,8]
X=np.array(X)
Y=np.array(Y)
print("X:",X)
print('\n')
print("Y",Y)

5.划分训练集和测试集
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier,RadiusNeighborsClassifier
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2)
四、建立模型
models = []
models.append(("KNN",KNeighborsClassifier(n_neighbors=2)))
models.append(("KNN with weights",KNeighborsClassifier(n_neighbors=2,weights="distance")))
models.append(("Radius Neighbors",RadiusNeighborsClassifier(n_neighbors=2,radius=500.0)))
models

分别训练三个模型,计算平均评分
results = []
for name,model in models:model.fit(X_train,Y_train)results.append((name,model.score(X_test,Y_test)))
for i in range(len(results)):print("name:{},score:{}".format(results[i][0],results[i][1]))

利用交叉验证准确对比算法的精确性
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
results = []
for name,model in models:Kfold = KFold(n_splits=10)cv_result = cross_val_score(model,X_train,Y_train,cv=Kfold)results.append((name,cv_result))for i in range(len(results)):print("name:{};cross_val_score:{}".format(results[i][0],results[i][1].mean()))

通过以上结果显示,普通KNN算法的性能更优一些,接下来用普通KNN进行训练
五、模型验证
knn =KNeighborsClassifier(n_neighbors=2)
knn.fit(X_train,Y_train)

train_score = knn.score(X_train,Y_train)
test_score = knn.score(X_test,Y_test)
print("train_score:{};test score:{}".format(train_score,test_score))

以上结果显示表明,训练样本的拟合情况不佳,模型的准确性欠佳
通过画学习率曲线来观察这一结论.
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import learning_curveimport matplotlib.pyplot as plt
%matplotlib inline
knn = KNeighborsClassifier(n_neighbors=2)
cv= ShuffleSplit(n_splits=10,test_size=0.2,random_state=0)
plt.figure(figsize=(10,6),dpi=200)
plot_learning_curve(knn,"Learning Curve for KNN Diabetes",X,Y,ylim=(0.0,1.01),cv=cv)
plt.show()
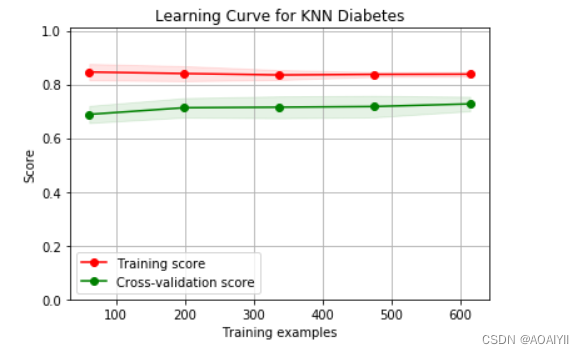
学习曲线分析
从图中可以看出来,训练样本的评分较低,且测试样本与训练样本距离较大,这是典型的欠拟合现象,KNN算法没有更好的措施解决欠拟合的问题,可以尝试用其他的分类器。
总结
k-近邻算法是分类数据最简单最有效的算法,k-近邻算法是基于实例的学习,使用算法时我们必须有接近实际数据的训练样本数据。k-近邻算法必须保存全部数据集,如果训练数据集的很大,必须使用大量的存储空间。此外,由于必须对数据集中的每个数据计算距离值,实际使用时可能非常耗时。k-近邻算法的另一个缺陷是它无法给出任何数据的基础结构信息,因此我们也无法知晓平均实例样本和典型实例样本具有什么特征。
相关文章:
数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析
数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析 作者:AOAIYI 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞&#x…...
Kettle体系结构及源码解析
介绍 ETL是数据抽取(Extract)、转换(Transform)、装载(Load)的过程。Kettle是一款国外开源的ETL工具,有两种脚本文件transformation和job,transformation完成针对数据的基础转换&…...
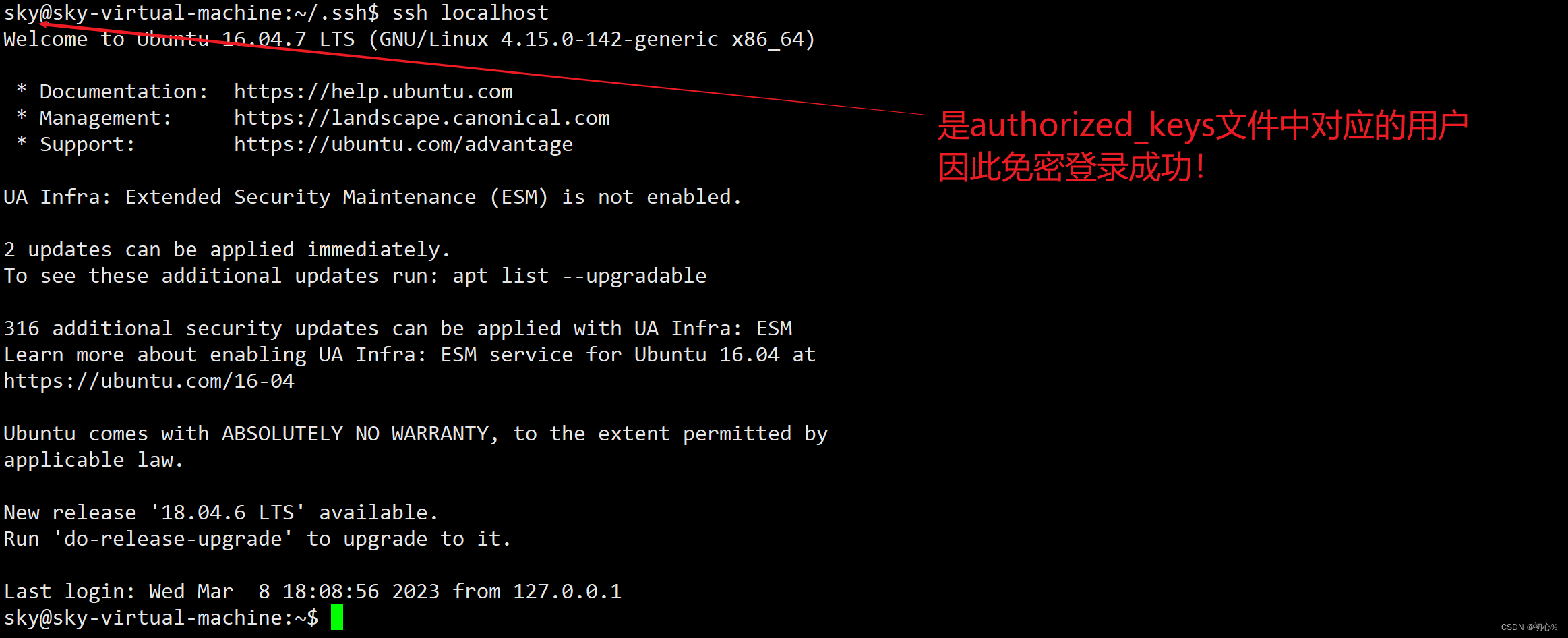
大数据 | (二)SSH连接报错Permission denied
大数据 | (三)centos7图形界面无法执行yum命令:centos7图形界面无法执行yum命令 哈喽!各位CSDN的朋友们大家好! 今天在执行Hadoop伪分布式安装时,遇到了一个问题,在此跟大家分享, …...

前端——6.文本格式化标签和<div>和<span>标签
这篇文章,我们来讲一下HTML中的文本格式化标签 目录 1.文本格式化标签 1.1介绍 1.2代码演示 1.3小拓展 2.div和span标签 2.1介绍 2.2代码演示 2.3解释 3.小结 1.文本格式化标签 在网页中,有时需要为文字设置粗体、斜体和下划线等效果…...

浅谈Xpath注入漏洞
目录 知识简介 攻击简介 基础语法 语法演示 漏洞简介 漏洞原理 漏洞复现 Xpath盲注 知识简介 攻击简介 XPath注入攻击是指利用XPath 解析器的松散输入和容错特性,能够在 URL、表单或其它信息上附带恶意的XPath 查询代码,以获得权限信息的访问权…...

Oracle LogMiner分析归档日志
目录:Oracle LogMiner分析归档日志一、准备测试环境1、开启数据库归档日志2、打开数据库最小附加日志3、设置当前session时间日期格式二、创建测试数据1、创建数据2、数据落盘三、日志发掘测试挖掘在上次归档的Redo Log File1.确定最近归档的Redo Log File2.指定要分…...
趣味三角——第15章——傅里叶定理
第15章 傅里叶定理(Fourier’s Theorem) Fourier, not being noble, could not enter the artillery, although he was a second Newton. (傅立叶出生并不高贵,因此按当时的惯例进不了炮兵部队,虽然他是第二个牛顿。) —Franois Jean Dominique Arag…...

市场营销的核心是什么?
之所以写下「市场营销的核心是什么?」这篇文章,是因为这几天刚读完了《经理人参阅:市场营销》这本书。作为一个有着近十年工作经验的市场营销从业人员,看完这本书也产生了很多新的想法,也想记录一下,遂成此…...

c/cpp - 多线程/进程 多进程
c/cpp - 多线程/进程 多进程多进程创建多进程进程等待多进程 宏观上 两个进程完全并发的 父子进程具有互相独立的进程空间 父进程结束,不影响子进程的执行 创建多进程 #include <sys/types.h> #include <unistd.h> #include <stdio.h>int main()…...

MySQL必知必会 | 存储过程、游标、触发器
使用存储过程 存储过程 简单来说就是为了以后的使用而保存的一条或多条MySQL语句的集合。 我觉得就是封装了一组sql语句 为什么需要存储过程(简单来说就是,简单、安全、高性能 通过把处理封装在容易使用的单元中,简化复杂操作所有开发人员…...

优化Facebook广告ROI的数据驱动方法:从投放到运营
“投放广告并不是最终的目的,关键在于如何最大程度地利用数据驱动的方法来提高广告投放的回报率(ROI)”Facebook广告是现代数字营销中最为常见和重要的广告形式之一。但是,要让Facebook广告真正发挥作用,需要通过数据驱…...

动态规划入门经典问题讲解
最近开始接触动态规划问题,以下浅谈(或回顾)一下这些问题的求解过程。解题思路对于动态规划问题,由于最终问题的求解需要以同类子问题作为基础,故需要定义一个dp数组(一维或二维)来记录问题求解…...

快速入门深度学习1(用时1h)
速通《动手学深度学习》1写在最前面0.内容与结构1.深度学习简介1.1 问题引入1.2 思路:逆向思考1.3 跳过1.4 特点1.5 小结2.预备知识(MXNet版本,学错了。。。。)2.1 获取和运行本书的代码2.2 数据操作2.2.1 略过2.2.2 小结2.3 自动…...
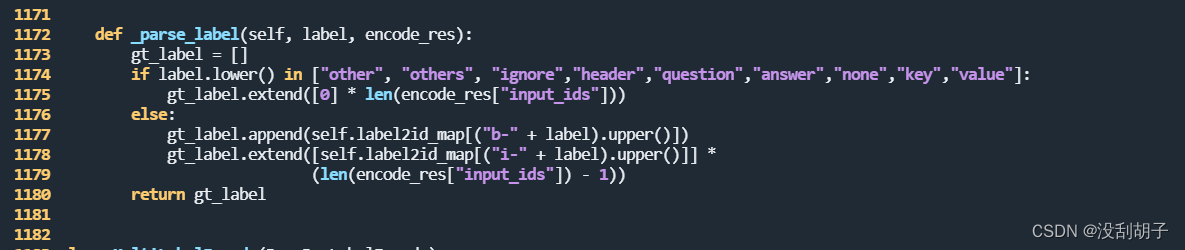
PaddleOCR关键信息抽取(KIE)的训练(SER训练和RE训练)错误汇总
1.SER训练报错: SystemError: (Fatal) Blocking queue is killed because the data reader raises an exception 1.1.问题描述 在执行训练任务的时候报错 单卡训练 python3 tools/train.py -c train_data/my_data/ser_vi_layoutxlm_xfund_zh.yml错误信息如下: T…...

信息收集之搜索引擎
Google Hacking 也可以用百度,不过谷歌的搜索引擎更强大 site 功能:搜索指定域名的网页内容,可以用来搜索子域名、跟此域名相关的内容 示例: site:zhihu.com 搜索跟zhihu.com相关的网页“web安全” site:zhihu.com 搜索zhihu…...
布局类组件)
Flutter(四)布局类组件
目录布局类组件简介布局原理与约束线性布局(Row和Column)弹性布局流式布局(Wrap、Flow)层叠布局(Stack、Positioned)对齐与相对定位(Align)Align和Stack对比Center组件LayoutBuilder…...

【黑马】Java基础从入门到起飞目录合集
视频链接: Java入门到起飞(上部):BV17F411T7AoJava入门到起飞(下部):BV1yW4y1Y7Ms 学习时间: 2023/02/01 —— 2023/03/09断断续续的学习,历时大概37天,完结撒…...

PMP考前冲刺3.10 | 2023新征程,一举拿证
题目1-2:1.在最近的一次耗时四周的迭代中,赫克托尔所在的敏捷团队刚完成了10 个用户故事点的开发、测试和发布,那么团队的速度是?A. 10B. 4C. 5D.402.产品负责人奥佩,倾向于在短周期内看到工作产品的新版本,…...

JavaScript Math常用方法
math是JavaScript的一个内置对象,它提供了一些数学属性和方法,可以对数字进行计算(用于Number类型)。 math和其他全局对象不同,它不是一个构造器,math的所有方法和属性都是静态的,直接使用并传入…...

【C++】模板进阶
文章目录一、非类型模板参数1、非类型模板参数2、C11 中的 array 类二、模板的特化1、模板特化的概念2、函数模板特化3、类模板特化3.1 全特化3.2 偏特化三、模板的分离编译四、模板总结一、非类型模板参数 1、非类型模板参数 模板参数分为类型形参与非类型形参,类…...

保姆级教程:用Intel官方工具搞定Realsense D435深度不准和黑点问题
深度视觉优化实战:Intel RealSense D435深度校准全流程解析 刚拆封的RealSense D435摄像头在深度模式下出现零星黑点?深度图某些区域数值明显失真?这些问题往往不是硬件缺陷,而是出厂校准参数与实际使用环境不匹配导致的。作为计算…...

taotoken的token plan套餐让长期使用的成本预测变得简单
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的 Token Plan 套餐让长期使用的成本预测变得简单 对于将大模型 API 深度集成到业务流程中的团队而言,成本管…...

IC场景XR全息通信_CSDN
6G IC场景XR/全息通信技术深度分析 摘要: 6G时代的沉浸式通信(Immersive Communication, IC)是实现"存在感"传输的核心场景,其中XR与全息通信技术对网络提出了Tbps级速率和亚毫秒级延迟的极限需求。本文从技术需求量化、…...

基于SEID模型与ode45数值解的艾滋病传播动力学建模与区域防控策略评估
1. 当数学模型遇上艾滋病防控 我第一次接触传染病建模是在研究生时期,当时导师扔给我一叠艾滋病流行病学数据,说:"试试用微分方程描述这个传播过程"。那会儿对着密密麻麻的病例报告,我完全没想到数学公式真能模拟现实中…...

中小项目如何通过按token计费模式灵活启动AI功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小项目如何通过按token计费模式灵活启动AI功能 对于预算有限的中小项目团队而言,在探索产品方向、验证市场需求的早期…...

NomNom终极指南:3个技巧让你轻松掌控《无人深空》存档
NomNom终极指南:3个技巧让你轻松掌控《无人深空》存档 【免费下载链接】NomNom NomNom is the most complete savegame editor for NMS but also shows additional information around the data youre about to change. You can also easily look up each item indi…...

嵌入式Linux SPI屏驱动踩坑实录:fbtft模块加载失败与dmesg排错指南
嵌入式Linux SPI屏驱动深度排错指南:从dmesg到硬件配置的全链路解析 当你在树莓派或全志H3开发板上折腾那块SPI接口的TFT屏幕时,是否经历过这样的绝望时刻?设备树配置看起来完美无缺,insmod命令执行后却只收获一片漆黑的屏幕和满屏…...

终极Windows安卓应用安装指南:告别模拟器,拥抱轻量级体验
终极Windows安卓应用安装指南:告别模拟器,拥抱轻量级体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了笨重的安卓模拟器&#x…...

APK安装器终极指南:在Windows上轻松安装安卓应用的5个简单步骤
APK安装器终极指南:在Windows上轻松安装安卓应用的5个简单步骤 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上直接运行安卓应用&a…...

终极指南:在Windows上使用BiliBili-UWP第三方客户端获得流畅的B站观影体验
终极指南:在Windows上使用BiliBili-UWP第三方客户端获得流畅的B站观影体验 【免费下载链接】BiliBili-UWP BiliBili的UWP客户端,当然,是第三方的了 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBili-UWP 你是否厌倦了网页版B站的…...