“深入探讨Java中的对象拷贝:浅拷贝与深拷贝的差异与应用“
前言:在Java编程中,深拷贝(Deep Copy)与浅拷贝(Shallow Copy)是两个非常重要的概念。它们涉及到对象在内存中的复制方式,对于理解对象的引用、内存管理以及数据安全都至关重要。
✨✨✨这里是秋刀鱼不做梦的BLOG
✨✨✨想要了解更多内容可以访问我的主页秋刀鱼不做梦-CSDN博客

先让我们看一下本文的大致内容:
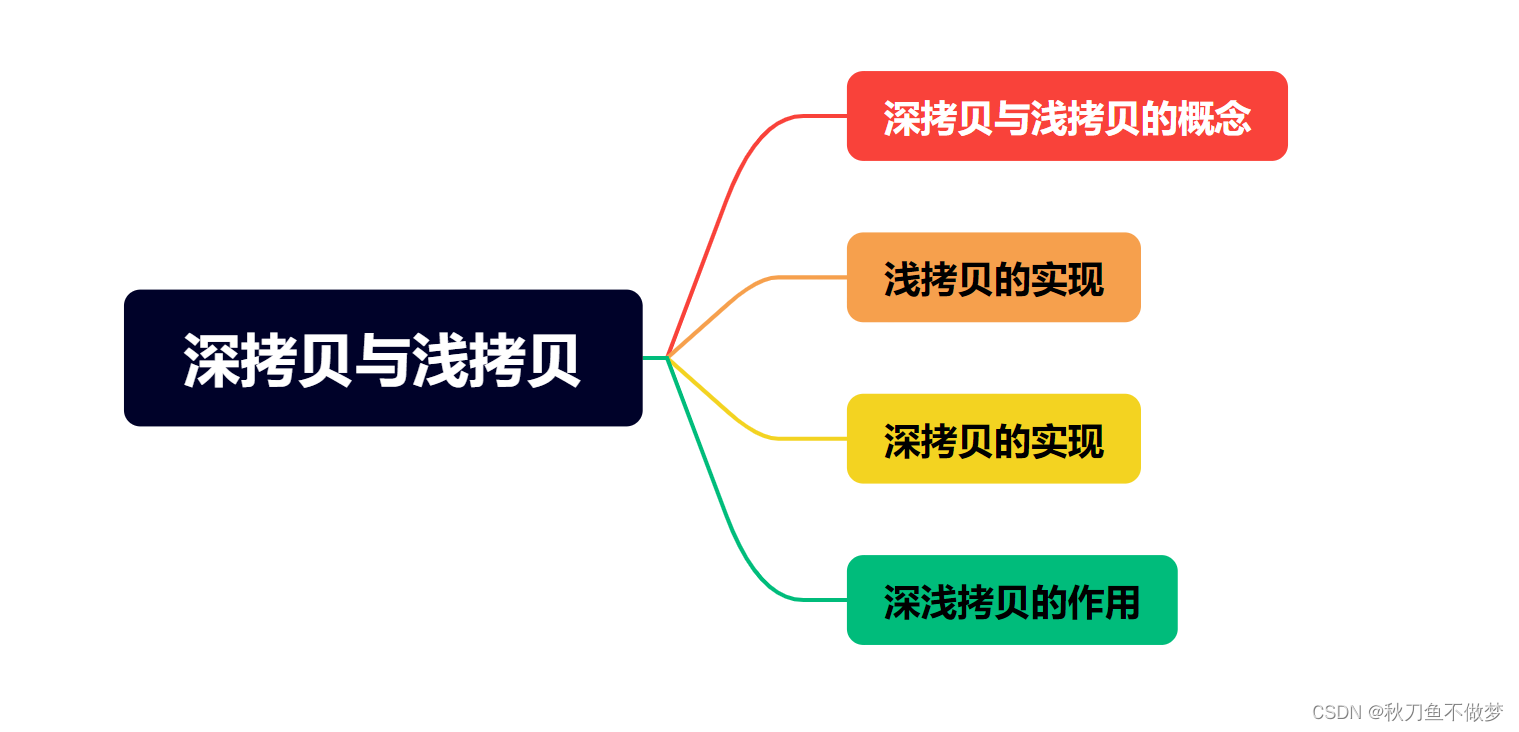
目录
1.深拷贝与浅拷贝的概念
(1)浅拷贝
(2)深拷贝
2.浅拷贝的实现
3.深拷贝的实现
4.深浅拷贝的作用
浅拷贝的作用:
深拷贝的作用:
1.深拷贝与浅拷贝的概念
——在了解Java中是如何实现对象的深浅拷贝之前,我们需要先了解一下什么是深拷贝、浅拷贝:

(1)浅拷贝
在浅拷贝中,只复制对象本身,而不复制对象引用的内容。这意味着,如果对象中包含了引用类型的成员变量,那么这些成员变量的引用将会被复制,但是它们仍然指向相同的内存地址。因此,对于引用类型成员变量的修改会影响到原始对象和拷贝对象。
(2)深拷贝
与浅拷贝不同,深拷贝会递归地复制对象及其所有引用的对象,直到所有对象都被复制到一个新的内存地址上。这样,原始对象和拷贝对象完全独立,彼此的修改不会相互影响。
嗯嗯嗯......感觉看了和没看没什么区别,还是不太能理解到底什么是Java中的深浅拷贝,那么我们使用一个生活中的案例来解释一下:
浅拷贝的情景:
——如果你选择了浅拷贝,那么你会简单地把整个礼物篮进行复制,然后送给你的朋友。在这种情况下,你的朋友会得到一个看起来一模一样的礼物篮。然而,当你的朋友拆开礼物篮,他们发现里面的食品和饰品并没有改变,他们是和你的礼物篮里的相同的食品和饰品。
深拷贝的情景:
——相比之下,如果你选择了深拷贝,那么你会仔细地把礼物篮里的每一样东西都复制一份,然后把这些复制品装进一个新的礼物篮里,送给你的朋友。在这种情况下,你的朋友得到的是一个全新的礼物篮,里面的食品和饰品和你的礼物篮里的完全一样。但是,现在他们拥有的是独立于你的礼物篮的新的食品和饰品。
不知道上面的生活案例有没有使你更好的理解Java中的深浅拷贝,如果还是没有,那么直接往下看即可!
大致的了解了什么是Java中的深浅拷贝之后,那么我们又该如何使用代码去实现它们呢?
2.浅拷贝的实现
在Java中,实现浅拷贝通常使用clone()方法。该方法会创建一个新对象,并将原始对象的所有字段值复制到新对象中。但是需要注意的是,对于引用类型的成员变量,仍然是浅拷贝,即复制的是引用而不是对象本身。
下面是在Java中实现浅拷贝的详细步骤:
1.实现Cloneable接口:
class MyClass implements Cloneable {// 类的定义
}
2.重写clone()方法并调用super.clone():
class MyClass implements Cloneable {// 类的定义@Overridepublic Object clone() throws CloneNotSupportedException {return super.clone();}
}
3.在使用时捕获CloneNotSupportedException异常:
try {MyClass copy = (MyClass) original.clone();
} catch (CloneNotSupportedException e) {e.printStackTrace();
}
4.强制转换:由于clone()方法返回的是Object类型,因此在使用时需要进行类型转换。
try {MyClass copy = (MyClass) original.clone();
} catch (CloneNotSupportedException e) {e.printStackTrace();
}
这就是实现Java中浅拷贝的四步实现流程,相信你仔细的读完上边的代码之后,对Java中浅拷贝的实现流程已经有了初步的理解了,现在让我们使用一个完整的案例,来实现一下Java中的浅拷贝:
class Person implements Cloneable {private String name;private Address address;public Person(String name, Address address) {this.name = name;this.address = address;}// Getter and setter 方法@Overrideprotected Object clone() throws CloneNotSupportedException {return super.clone();}
}class Address {private String city;public Address(String city) {this.city = city;}// Getter and setter 方法
}public class ShallowCopyExample {public static void main(String[] args) {Address address = new Address("New York");Person person1 = new Person("Alice", address);try {Person person2 = (Person) person1.clone();// 输出: trueSystem.out.println(person1.getAddress() == person2.getAddress()); } catch (CloneNotSupportedException e) {e.printStackTrace();}}
}
以上代码演示了一个浅拷贝的例子。让我来解释一下它的执行过程和输出:
首先,我们定义了两个类:
Person和Address。Person类有一个name属性和一个address属性,而Address类只有一个city属性。在
ShallowCopyExample类的main方法中,我们创建了一个Address对象,表示Alice的地址是"New York"。然后,我们创建了一个Person对象person1,传入了名字"Alice"和上面创建的Address对象。接着,我们调用
person1.clone()方法进行浅拷贝。由于Person类实现了Cloneable接口并重写了clone()方法,因此它支持克隆操作。在clone()方法内部,我们调用了super.clone()来复制Person对象本身,但是对于address属性,只是复制了其引用,而没有对Address对象进行深度复制。输出语句
System.out.println(person1.getAddress() == person2.getAddress());比较了person1和person2的address属性是否是同一个对象。由于浅拷贝只是复制了引用,所以person1和person2的address属性指向的是同一个Address对象,因此输出结果为true。
这样我们就大致的了解了在Java中如何去实现对象的浅拷贝了。
3.深拷贝的实现
在Java中实现深拷贝相对于浅拷贝来说更为复杂,因为需要确保对象及其引用的所有对象都被复制到新的内存地址上。
下面是在Java中实现深拷贝的详细流程:
1.实现Cloneable接口:同样,为了使用clone()方法,需要确保类实现了Cloneable接口。
class MyClass implements Cloneable {// 类的定义
}
2.重写clone()方法:在重写的clone()方法中,除了调用super.clone()来复制对象本身之外,还需要递归地复制所有引用的对象。
class MyClass implements Cloneable {private AnotherClass anotherObject;public MyClass(AnotherClass anotherObject) {this.anotherObject = anotherObject;}// Getter and setter 方法@Overridepublic Object clone() throws CloneNotSupportedException {MyClass clonedObject = (MyClass) super.clone();// 对引用类型的成员变量进行深度复制clonedObject.anotherObject = (AnotherClass) anotherObject.clone();return clonedObject;}
}
3.在引用类型的类中同样实现深拷贝:如果类中有成员变量是引用类型,那么需要在该引用类型的类中同样实现深拷贝。
class AnotherClass implements Cloneable {// 类的定义@Overridepublic Object clone() throws CloneNotSupportedException {return super.clone();}
}
4.调用clone()方法:现在可以调用clone()方法来获取深拷贝的对象。
public class DeepCopyExample {public static void main(String[] args) {AnotherClass anotherObject = new AnotherClass();MyClass original = new MyClass(anotherObject);MyClass deepCopy = null;try {deepCopy = (MyClass) original.clone();} catch (CloneNotSupportedException e) {e.printStackTrace();}}
}
这就是实现Java中深拷贝的四步实现流程,当然,现在让我们使用一个完整的案例,来实现一下Java中的深拷贝:
class Person implements Cloneable {private String name;private Address address;public Person(String name, Address address) {this.name = name;this.address = address;}// Getter and setter 方法@Overrideprotected Object clone() throws CloneNotSupportedException {Person clonedPerson = (Person) super.clone();clonedPerson.address = (Address) this.address.clone();return clonedPerson;}
}class Address implements Cloneable {private String city;public Address(String city) {this.city = city;}// Getter and setter 方法@Overrideprotected Object clone() throws CloneNotSupportedException {return super.clone();}
}public class DeepCopyExample {public static void main(String[] args) {Address address = new Address("New York");Person person1 = new Person("Alice", address);try {Person person2 = (Person) person1.clone();// 输出: falseSystem.out.println(person1.getAddress() == person2.getAddress()); } catch (CloneNotSupportedException e) {e.printStackTrace();}}
}
让我解释一下代码的主要部分:
Person类和Address类都实现了Cloneable接口,这是为了表明它们可以被克隆。在
Person类中,有一个私有字段address,类型为Address。Person类的构造函数用于初始化这个字段。
Person类的clone()方法首先调用了super.clone(),这会复制Person对象本身。然后,它对address字段进行了深拷贝,即创建了一个新的Address对象,并将其赋值给clonedPerson的address字段。
Address类中的clone()方法也是调用了super.clone(),实现了浅拷贝,因为Address类只有一个字段,且该字段为不可变类型。在
main()方法中,首先创建了一个Address对象和一个Person对象。然后,通过调用clone()方法,创建了一个新的Person对象person2,其中包含了新的Address对象。最后,通过比较
person1和person2的地址字段,可以看到它们不相同,这表明在克隆过程中进行了深拷贝。
这样我们就大致的了解了在Java中如何去实现对象的深拷贝了。
4.深浅拷贝的作用
了解完了Java中的深浅拷贝之后,那么其有什么用呢?
浅拷贝的作用:
节省内存空间:浅拷贝只复制对象本身,不会复制对象引用的内容,因此在某些情况下可以节省内存空间。
提高对象创建速度:由于浅拷贝只复制对象本身,因此复制过程相对较快。
适用于不包含引用类型成员变量的对象:如果对象中的成员变量都是基本数据类型或者不需要被复制的对象,那么浅拷贝是一个简单有效的复制方式。
深拷贝的作用:
确保对象的独立性:深拷贝会递归地复制对象及其引用的所有对象,从而确保复制后的对象与原始对象完全独立,对复制对象的修改不会影响原始对象。
数据安全性:在多线程环境下,深拷贝可以确保对象的数据安全性,因为每个线程都可以操作独立的对象,而不会相互影响。
避免对象共享的副作用:在某些情况下,对象的共享可能会导致意外的副作用,深拷贝可以避免这种情况的发生,保证数据的一致性和可靠性。
适用于包含引用类型成员变量的对象:如果对象中包含了引用类型的成员变量,并且需要复制所有引用的对象,那么深拷贝是更合适的选择。
总的来说,浅拷贝适用于简单对象的复制,可以提高性能和节省内存空间,而深拷贝则适用于需要确保对象独立性和数据安全性的情况,尤其是当对象包含引用类型成员变量时。
以上就是本篇文章的全部内容了~~~
相关文章:
“深入探讨Java中的对象拷贝:浅拷贝与深拷贝的差异与应用“
前言:在Java编程中,深拷贝(Deep Copy)与浅拷贝(Shallow Copy)是两个非常重要的概念。它们涉及到对象在内存中的复制方式,对于理解对象的引用、内存管理以及数据安全都至关重要。 ✨✨✨这里是秋…...

Docker 进入指定容器内部(以Mysql为例)
文章目录 一、启动容器二、查看容器是否启动三、进入容器内部 一、启动容器 这个就不多说了 直接docker run… 二、查看容器是否启动 查看正在运行的容器 docker ps查看所有的容器 docker ps -a结果如下图所示: 三、进入容器内部 通过CONTAINER ID进入到容器…...

计算机网络-数制转换与子网划分
目录 一、了解数制 1、计算机的数制 2、二进制 3、八进制 4、十进制 5、十六进制 二、数制转换 1、二进制转十进制 2、八进制转十进制 3、十六进制转十进制 4、十进制转二进制 5、十进制转八进制 6、十进制转十六进制 三、子网划分 1、IP地址定义 2、IP的两种协…...
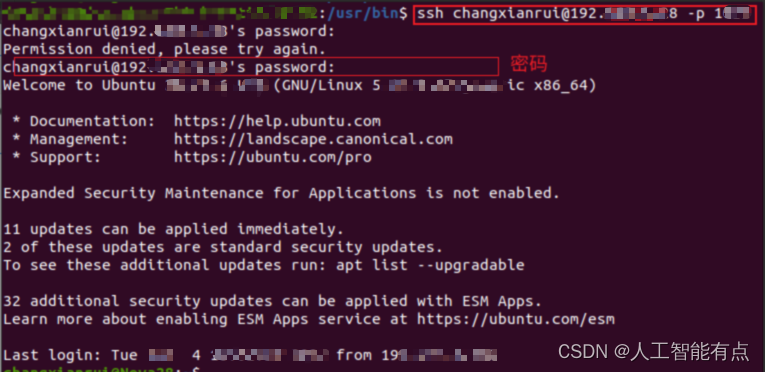
【ssh命令】ssh登录远程服务器
命令格式:ssh 用户名主机IP # 使用非默认端口: -p 端口号 ssh changxianrui192.168.100.100 -p 1022 # 使用默认端口 22 ssh changxianrui192.168.100.100 然后输入密码,就可以登录进去了。...
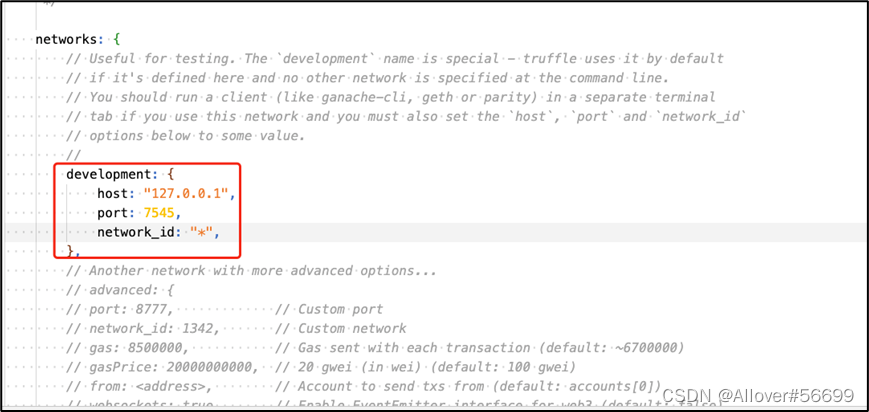
【区块链】truffle测试
配置区块链网络 启动Ganache软件 使用VScode打开项目的wordspace 配置对外访问的RPC接口为7545,配置项目的truffle-config.js实现与新建Workspace的连接。 创建项目 创建一个新的目录 mkdir MetaCoin cd MetaCoin下载metacoin盒子 truffle unbox metacoincontra…...

【AIGC调研系列】chatTTS与GPT-SoVITS的对比优劣势
ChatTTS和GPT-SoVITS都是在文本转语音(TTS)领域的重要开源项目,但它们各自有不同的优势和劣势。 ChatTTS 优点: 多语言支持:ChatTTS支持中英文,并且能够生成高质量、自然流畅的对话语音[4][10][13]。细粒…...

LLVM Cpu0 新后端10
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章: LLVM 后端实践笔记 代码在这里(还没来得及准备,先用网盘暂存一下): 链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?…...
)
k8s面试题大全,保姆级的攻略哦(二)
目录 三十六、pod的定义中有个command和args参数,这两个参数不会和docker镜像的entrypointc冲突吗? 三十七、标签及标签选择器是什么,如何使用? 三十八、service是如何与pod关联的? 三十九、service的域名解析格式…...
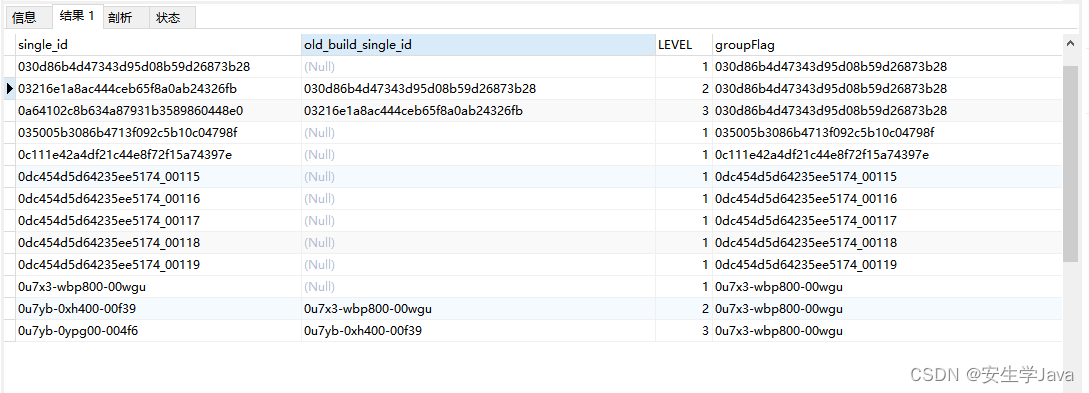
Mysql:通过一张表里的父子级,递归查询并且分组分级
递归函数WITH RECURSIVE语法 WITH RECURSIVE cte_name (column_list) AS (SELECT initial_query_resultUNION [ALL]SELECT recursive_queryFROM cte_nameWHERE condition ) SELECT * FROM cte_name; WITH RECURSIVE 关键字:表示要使用递归查询的方式处理数据。 c…...
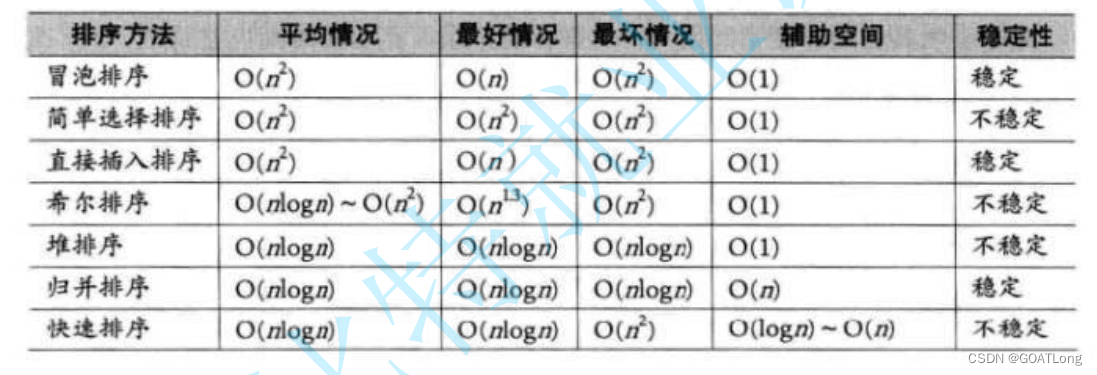
数据结构之排序算法
目录 1. 插入排序 1.1.1 直接插入排序代码实现 1.1.2 直接插入排序的特性总结 1.2.1 希尔排序的实现 1.2.2 希尔排序的特性总结 2. 选择排序 2.1.1 选择排序 2.1.2 选择排序特性 2.2.1 堆排序 2.2.2 堆排序特性 3. 交换排序 3.1.1 冒泡排序 3.1.2 冒泡排序的特性 …...

移动安全赋能化工能源行业智慧转型
随着我国能源化工企业的不断发展,化工厂中经常存在火灾爆炸的危险,特别是生产场所,约有80%以上生产场所区域存在爆炸性物质。而目前我国化工危险场所移动通信设备的普及率高,但是对移动通信设备的安全防护却有所忽视,包…...

今天是放假带娃的一天
端午节放假第一天 早上5点半宝宝就咔咔乱叫了,几乎每天都这个点醒,准时的很,估计他是个勤奋的娃吧,要早起锻炼婴语,哈哈 醒来后做饭、洗锅、洗宝宝的衣服、给他吃D3,喂200ml奶粉、给他洗澡、哄睡࿰…...

linux Ubuntu安装samba服务器与SSH远程登录
目录 1,下载安装包 2,添加服务器 3,修改服务器配置 3.1 备份配置文件 3.2 修改配置 4,开启samba服务器 5,开关电脑与服务器设置 6, SSH远程登录 1,下载samba服务器安装包 sudo apt in…...

纳什均衡:博弈论中的运作方式、示例以及囚徒困境
文章目录 一、说明二、什么是纳什均衡?2.1 基本概念2.2 关键要点 三、理解纳什均衡四、纳什均衡与主导策略五、纳什均衡的例子六、囚徒困境七、如何原理和应用7.1 博弈论中的纳什均衡是什么?7.2 如何找到纳什均衡?7.3 为什么纳什均衡很重要&a…...

Linux之进程信号详解【上】
🌎 Linux信号详解 文章目录: Linux信号详解 信号入门 技术应用角度的信号 信号及信号的产生 信号的概念 信号的处理方式 信号的产生方式 键盘产生信号 系统调用产生信号 软件…...

【Spring Cloud】Eureka详细介绍及底层原理解析
目录 底层原理详解 1. 服务注册与发现 2. 心跳机制 3. 服务剔除与自我保护机制 Eureka Server 核心组件 Eureka Client 核心组件 使用场景 结语 Eureka 是 Netflix 开源的一款服务发现框架,用于构建分布式系统中的服务注册与发现。 它包含两个核心组件&…...
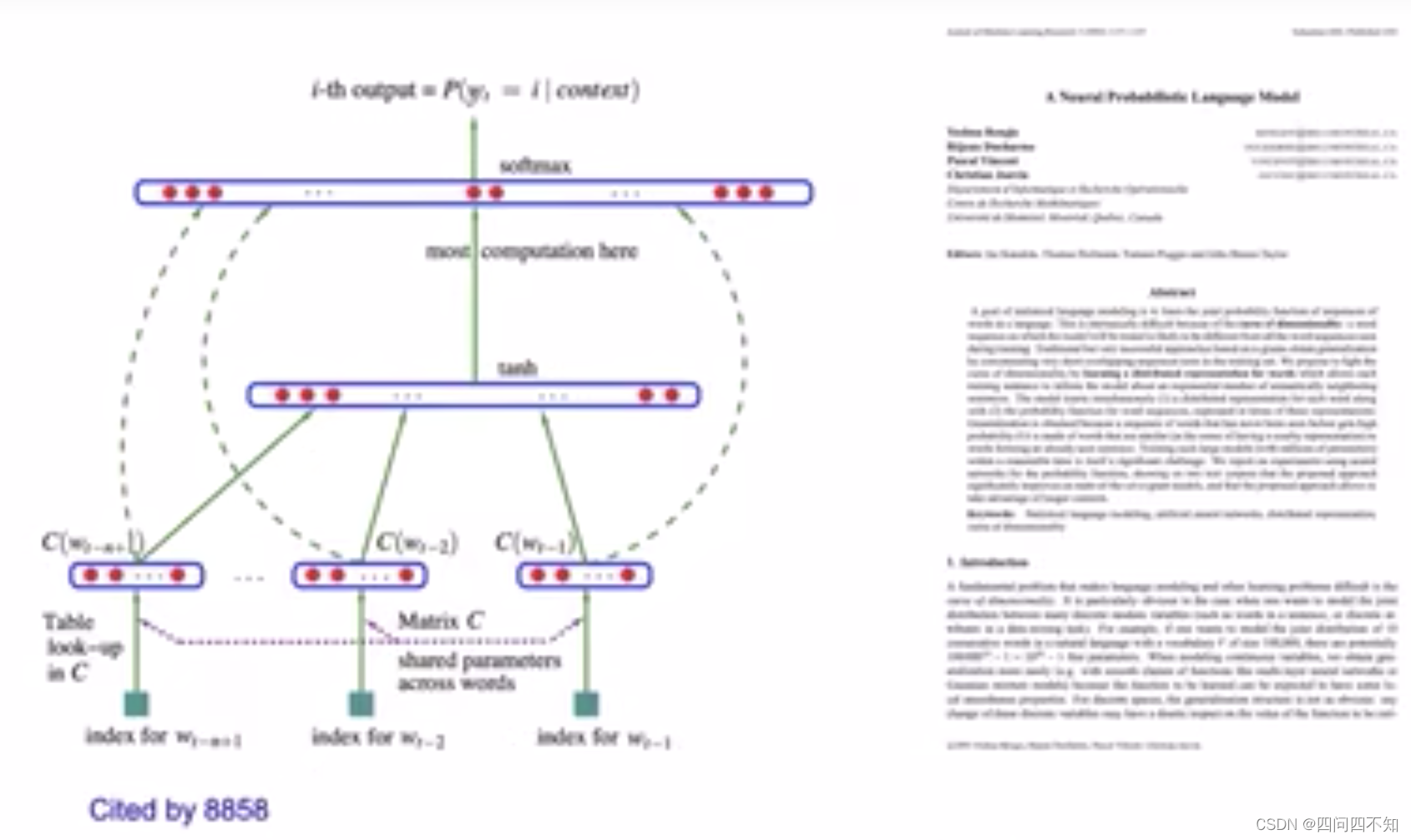
【清华大学】《自然语言处理》(刘知远)课程笔记 ——NLP Basics
自然语言处理基础(Natural Language Processing Basics, NLP Basics) 自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言…...

代码随想录 | Day17 | 二叉树:二叉树的最大深度最小深度
代码随想录 | Day17 | 二叉树:二叉树的最大深度&&最小深度 主要学习内容: 利用前序后序层序求解二叉树深度问题 其中穿插回溯法 104.二叉树的最大深度 104. 二叉树的最大深度 - 力扣(LeetCode) 递归遍历 后序遍历 …...

【Linux】Socket编程基础
文章目录 字节序字节序转化函数 套接字socket通用结构体通信类型名空间套接字函数socket():创建套接字bind()函数:绑定服务器套接字与其地址、端口listen()函数:侦听客户连接connect():连接服务器套接字accept()函数:服…...
关于stm32的软件复位
使用软件复位的目的: 软件复位并不会擦除存储器中的数据,它只是将处理器恢复到复位状态,即中断使能位被清除,系统寄存器被重置,但RAM和Flash存储器中的数据保持不变。 STM32软件复位(基于库文件V3.5) ,对…...

AI智能体驱动微软广告自动化:MCP协议实战与降本增效策略
1. 项目概述:当AI智能体遇上被低估的搜索广告金矿如果你在谷歌广告上已经跑通了盈利模型,每个月稳定投入预算并获取回报,那么恭喜你,你已经超越了大多数广告主。但接下来我要问一个可能让你心跳加速的问题:你是否知道&…...

大模型+Agent+Skills+MCP,到底啥关系?
一句话总览:大模型是大脑,Agent是带目标的执行者,Skills是可复用技能包,MCP是连接外部世界的标准接口。它们不是竞争,而是分层协作、越绑越紧的关系。一、四个概念,人话版解释概念人话核心能力大模型&#…...

CANN/ops-nn CELU激活函数
aclnnCelu&aclnnInplaceCelu 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 📄 查看源码 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DTAt…...

AI 术语通俗词典:自动微分
自动微分是机器学习、深度学习、数值计算和人工智能中非常常见的一个术语。它用来描述:让计算机根据程序中的计算过程,自动、准确地计算导数或梯度的方法。 换句话说,自动微分是在回答:当一个模型由许多层计算组成时,怎…...

GE 静态执行器特性分析
GE 静态执行器(Known Shape Executor)特性分析 【免费下载链接】ge GE(Graph Engine)是面向昇腾的图编译器和执行器,提供了计算图优化、多流并行、内存复用和模型下沉等技术手段,加速模型执行效率ÿ…...

ESP32 Wi-Fi数据记录器:从嗅探原理到物联网监控实践
1. 项目概述:一个基于ESP32的Wi-Fi数据记录器如果你手头有一些ESP32开发板,并且对无线网络、数据采集或者物联网设备监控感兴趣,那么这个名为“esp-wifi-logger”的开源项目绝对值得你花时间研究。简单来说,它就是一个运行在ESP32…...
)
抖音矩阵云混剪系统 源码短视频矩阵营销系统V2.3.0(免授权版)
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 抖音矩阵云混剪系统 源码短视频矩阵营销系统V2.3.0(免授权版)多平台多账号一站式管理,一键发布作品。智能标题,关键词优化,排名…...

数据驱动的可解释AI:从特征归因到样本影响分析的实践指南
1. 项目概述:当数据挖掘遇见可解释AI在深度学习的浪潮席卷了几乎所有领域之后,我们获得了一个又一个性能惊人的“黑箱”模型。作为一名长期在数据科学一线工作的从业者,我见证了模型精度从90%提升到99.9%的激动,也亲历了当业务方或…...

Java开发者集成OpenAI API实战:chatgpt-java库深度解析与应用指南
1. 项目概述与核心价值最近在折腾一些需要集成AI对话能力的Java后端项目,发现市面上虽然有不少封装好的SDK,但要么功能不全,要么文档写得云里雾里,要么就是更新维护跟不上OpenAI API的迭代速度。直到我遇到了hongspell/chatgpt-ja…...

TensorFlow-Course:Colab云端开发终极指南
TensorFlow-Course:Colab云端开发终极指南 【免费下载链接】TensorFlow-Course :satellite: Simple and ready-to-use tutorials for TensorFlow 项目地址: https://gitcode.com/gh_mirrors/te/TensorFlow-Course TensorFlow-Course是一个专为初学者设计的T…...