深度学习部署笔记(九): CUDA RunTime API-2.1内存管理
1. 前言
- 主要理解pinned memory、global memory、shared memory即可
2. 主机内存
- 主机内存很多名字: CPU内存,pinned内存,host memory,这些都是储存在内存条上的
- Pageable Memory(可分页内存) + Page lock Memory(页锁定内存) 共同组成内存
- 你可以理解为Page lock memory是vip房间,锁定给你一个人用。而Pageable memory是普通房间,在酒店房间不够的时候,选择性的把你的房间腾出来给其他人交换用,这就可以容纳更多人了。造成房间很多的假象,代价是性能降低
3. 页锁定内存 (pinned memory/Page lock Memory)
- pinned memory具有锁定性,是稳定不会被交换的
- pageable memory没有锁定特性,对于第三方设备(比如GPU),去访问时,因为无法感知内存是否被交换,可能得不到正确的数据(每次去房间找,说不准你的房间被人交换了)
- pageable memory的性能比pinned memory差,很可能降低你程序的优先级然后把内存交换给别人用
- pageable memory策略能使用内存假象,实际8GB但是可以使用15GB,提高程序运行数量(不是速度)
- pinned memory太多,会导致操作系统整体性能降低(程序运行数量减少),8GB就只能用8GB。注意不是你的应用程序性能降低,这一点一般都是废话,不用当回事
- GPU可以直接访问pinned memory而不能访问pageable memory(因为第二条)
4. 内存总结:
- GPU可以直接访问pinned memory,称之为(DMA Direct Memory Access)
- 对于GPU访问而言,距离计算单元越近,效率越高,所以PinnedMemory<GlobalMemory<SharedMemory
- 代码中,由new、malloc分配的,是pageable memory,由cudaMallocHost分配的是PinnedMemory,由cudaMalloc分配的是GlobalMemory
- 尽量多用PinnedMemory储存host数据,或者显式处理Host到Device时,用PinnedMemory做缓存,都是提高性能的关键
5. 案例代码
// CUDA运行时头文件
#include <cuda_runtime.h>#include <stdio.h>
#include <string.h>#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){if(code != cudaSuccess){ const char* err_name = cudaGetErrorName(code); const char* err_message = cudaGetErrorString(code); printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message); return false;}return true;
}int main(){int device_id = 0;checkRuntime(cudaSetDevice(device_id));// 分配global memoryfloat *memory_device = nullptr;checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float))); // pointer to device// 分配pageable memoryfloat* memory_host = new float[100];memory_host[2] = 520.25;checkRuntime(cudaMemcpy(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice)); // 返回的地址是开辟的device地址,存放在memory_device// 分配pinned memory page locked memoryfloat* memory_page_locked = nullptr;checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float))); // 返回的地址是被开辟的pin memory的地址,存放在memory_page_lockedcheckRuntime(cudaMemcpy(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost)); // printf("%f\n", memory_page_locked[2]);checkRuntime(cudaFreeHost(memory_page_locked));delete [] memory_host;checkRuntime(cudaFree(memory_device)); return 0;
}
6. 案例代码分段解析
int device_id = 0;
cudaSetDevice(device_id); // 如果不写device_id = 0
是由于set device函数是“第一个执行的需要context的函数”,所以他会执行cuDevicePrimaryCtxRetain。
如果不指定设备ID,则默认使用设备ID为0的设备。在调用其他CUDA API函数之前,通常需要先调用cudaSetDevice来设置当前线程要使用的GPU设备。
float *memory_device = nullptr;
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float))); // pointer to device
分配global memory需要使用cudaMalloc() 这里使用cudaMalloc()函数在GPU上分配一块100个float类型元素的内存,返回一个指向设备内存的指针memory_device。
// 分配pageable memory
float* memory_host = new float[100];
memory_host[2] = 520.25;
checkRuntime(cudaMemcpy(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice)); // 返回的地址是开辟的device地址,存放在memory_device
分配pageable memory(主机上的内存), 使用new运算符在主机上分配一块100个float类型元素的内存,返回一个指向主机内存的指针memory_host。使用new运算符在主机上分配一块100个float类型元素的内存,返回一个指向主机内存的指针memory_host。
// 分配pinned memory page locked memory
float* memory_page_locked = nullptr;
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float))); // 返回的地址是被开辟的pin memory的地址,存放在memory_page_locked
checkRuntime(cudaMemcpy(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost));
分配pinned memory page locked memory使用cudaMallocHost()函数在主机上分配一块100个float类型元素的锁页内存(pinned memory),返回一个指向锁页内存的指针memory_page_locked。
将memory_device中的数据复制到memory_page_locked中,使用cudaMemcpy()函数,该函数将memory_device的数据从设备复制到主机的锁页内存。
printf("%f\n", memory_page_locked[2]);
checkRuntime(cudaFreeHost(memory_page_locked));
delete [] memory_host;
checkRuntime(cudaFree(memory_device));
输出memory_page_locked[2]的值,即设备内存的第三个元素的值(数组下标从0开始)。
使用cudaFreeHost()函数释放锁页内存。
使用delete[]运算符释放主机内存。
使用cudaFree()函数释放设备内存。
相关文章:
: CUDA RunTime API-2.1内存管理)
深度学习部署笔记(九): CUDA RunTime API-2.1内存管理
1. 前言 主要理解pinned memory、global memory、shared memory即可 2. 主机内存 主机内存很多名字: CPU内存,pinned内存,host memory,这些都是储存在内存条上的Pageable Memory(可分页内存) Page lock Memory(页锁定内存) 共同组成内存你…...

Idea+maven+spring-cloud项目搭建系列--11-2 dubbo鉴权日志记录数据统一封装
前言:使用dubbo做为通信组件,如果接口需要鉴权,和日志记录需要怎样处理; 1 鉴权: 1.1 在bootstrap.yml 中定义过滤器: dubbo.provider.filter: 过滤器的名字: 1.2 resources 目录下创建配置文…...
SOLIDWORKS免费培训 SW大型装配体模式课程
在SOLIDWORKS的使用过程中,大家经常会遇到大型装配体的处理问题,微辰三维的培训课程中也包含了一些大型装配体的技术培训,下面整理一些常见问题,供参考:大型装配体模式1.当我们打开一个大的装配体时,可能会…...

xxl-job registry fail
解决方法: 1、检查nacos是否正确,一定要注意格式,一般都是addersses的地址问题,一定的要加/不然找不到,本机就不要使用ip了,用localhost。 xxl: job: admin: addresses: http://localhost:8080/xxl-job-ad…...
【C#进阶】C# 反射
序号系列文章11【C#基础】C# 预处理器指令12【C#基础】C# 文件与IO13【C#进阶】C# 特性文章目录前言1,反射的概念2,使用反射访问特性3,反射的用途4,反射的优缺点比较4.1 优点:4.2 缺点:5,System…...
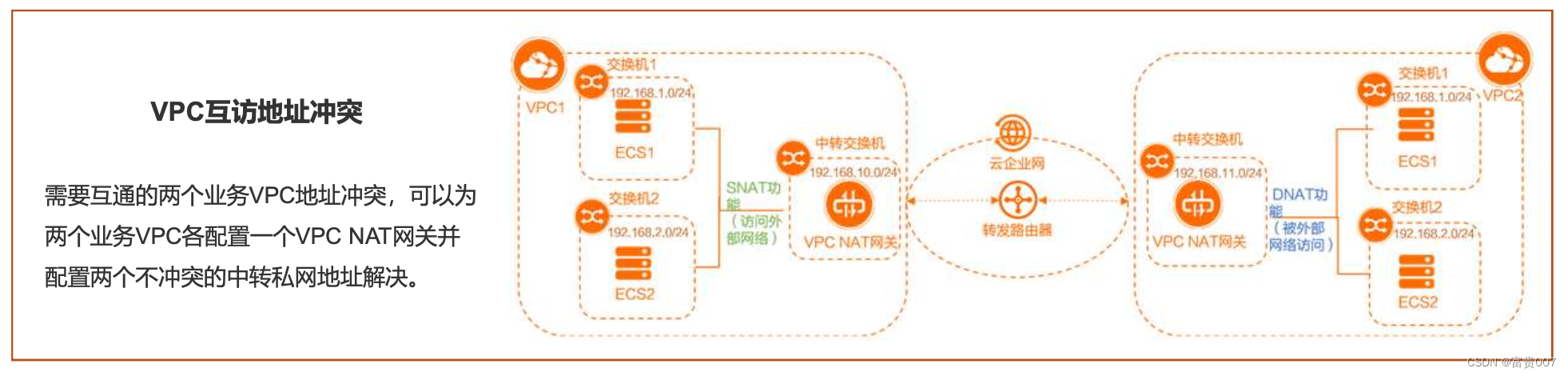
公网NAT网关与VPC NAT网关介绍与实践
NAT网关介绍 NAT网关是一种网络地址转换服务,提供NAT代理(SNAT和DNAT)能力。 公有云NAT分为公网NAT网关和VPC NAT网关。 1)公网NAT网关:提供公网地址转换服务。 2)VPC NAT网关:提供私网地址转换…...
Windows中UWP、WPF和Windows窗体的区别
Windows 中开发应用(或者可以说客户端)有三种方法: UWP(Universal Windows Platform)、WPF(Windows Presentation Foundation)和 Windows 窗体(Win Forms)。这三种方法在…...
Flink从入门到精通系列(一)
1、Flink概述 Apache Flink 是一个框架和分布式处理引擎,用于在, 无边界和有边界数据流上进行有状态的计算 ,Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 Apache Flink 功能强大,支持开发…...

云原生应用风险介绍
本博客地址:https://security.blog.csdn.net/article/details/129303616 一、传统风险 传统风险主要是注入、敏感数据泄露、跨站脚本、配置错误等等,这些传统的安全风险在云原生应用中也是存在的,这里就不具体展开说了。 二、云原生应用架…...
什么是测试用例设计?
前言 想要进行测试自动化的团队都会遇到这个问题:自动化的成功和编码能力有多大的关联?现在更多的招聘信息越来越偏重于对测试人员的编程能力的要求,似乎这个问题的答案是极大的正关联性。 测试人员可以将编码能力用于与测试相关的各种目的…...
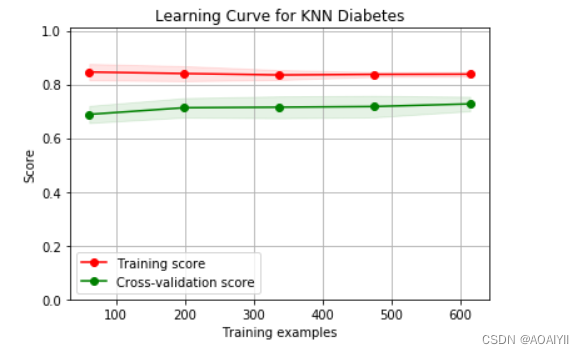
数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析
数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析 作者:AOAIYI 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞&#x…...
Kettle体系结构及源码解析
介绍 ETL是数据抽取(Extract)、转换(Transform)、装载(Load)的过程。Kettle是一款国外开源的ETL工具,有两种脚本文件transformation和job,transformation完成针对数据的基础转换&…...
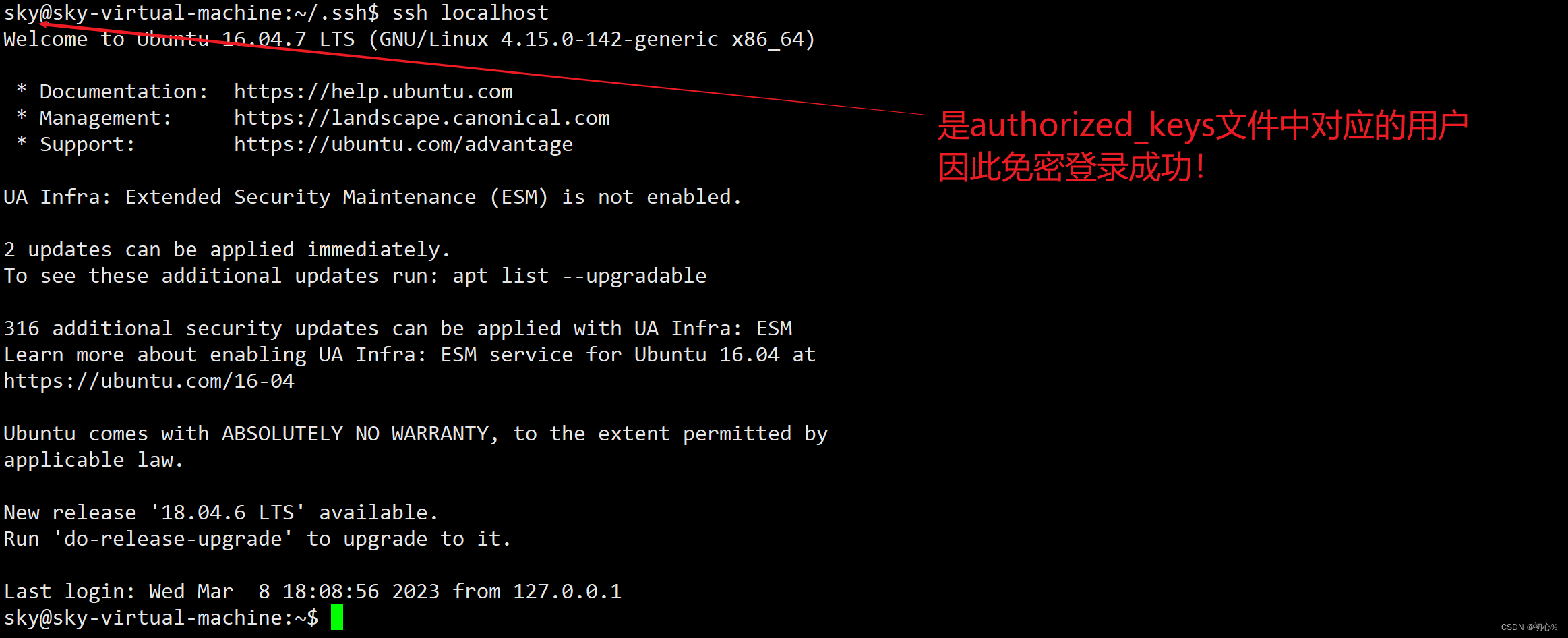
大数据 | (二)SSH连接报错Permission denied
大数据 | (三)centos7图形界面无法执行yum命令:centos7图形界面无法执行yum命令 哈喽!各位CSDN的朋友们大家好! 今天在执行Hadoop伪分布式安装时,遇到了一个问题,在此跟大家分享, …...

前端——6.文本格式化标签和<div>和<span>标签
这篇文章,我们来讲一下HTML中的文本格式化标签 目录 1.文本格式化标签 1.1介绍 1.2代码演示 1.3小拓展 2.div和span标签 2.1介绍 2.2代码演示 2.3解释 3.小结 1.文本格式化标签 在网页中,有时需要为文字设置粗体、斜体和下划线等效果…...

浅谈Xpath注入漏洞
目录 知识简介 攻击简介 基础语法 语法演示 漏洞简介 漏洞原理 漏洞复现 Xpath盲注 知识简介 攻击简介 XPath注入攻击是指利用XPath 解析器的松散输入和容错特性,能够在 URL、表单或其它信息上附带恶意的XPath 查询代码,以获得权限信息的访问权…...

Oracle LogMiner分析归档日志
目录:Oracle LogMiner分析归档日志一、准备测试环境1、开启数据库归档日志2、打开数据库最小附加日志3、设置当前session时间日期格式二、创建测试数据1、创建数据2、数据落盘三、日志发掘测试挖掘在上次归档的Redo Log File1.确定最近归档的Redo Log File2.指定要分…...
趣味三角——第15章——傅里叶定理
第15章 傅里叶定理(Fourier’s Theorem) Fourier, not being noble, could not enter the artillery, although he was a second Newton. (傅立叶出生并不高贵,因此按当时的惯例进不了炮兵部队,虽然他是第二个牛顿。) —Franois Jean Dominique Arag…...

市场营销的核心是什么?
之所以写下「市场营销的核心是什么?」这篇文章,是因为这几天刚读完了《经理人参阅:市场营销》这本书。作为一个有着近十年工作经验的市场营销从业人员,看完这本书也产生了很多新的想法,也想记录一下,遂成此…...

c/cpp - 多线程/进程 多进程
c/cpp - 多线程/进程 多进程多进程创建多进程进程等待多进程 宏观上 两个进程完全并发的 父子进程具有互相独立的进程空间 父进程结束,不影响子进程的执行 创建多进程 #include <sys/types.h> #include <unistd.h> #include <stdio.h>int main()…...

MySQL必知必会 | 存储过程、游标、触发器
使用存储过程 存储过程 简单来说就是为了以后的使用而保存的一条或多条MySQL语句的集合。 我觉得就是封装了一组sql语句 为什么需要存储过程(简单来说就是,简单、安全、高性能 通过把处理封装在容易使用的单元中,简化复杂操作所有开发人员…...

数字永生:将意识上传云端的技术与伦理极限
——一个软件测试从业者的技术解构与风险分析各位同行,当你看到“数字永生”这四个字时,脑海里浮现的是什么?是马斯克口中2045年即将实现的意识上传,还是《黑镜》里那些被困在虚拟牢笼中的数字灵魂?作为一个每天与需求…...

别再乱装驱动了!Ubuntu 20.04显卡驱动‘掉了’的终极排查与修复思路
Ubuntu 20.04显卡驱动失效的系统化诊断与修复指南 当你正专注于一个重要项目时,突然发现Ubuntu的NVIDIA显卡驱动"神秘消失"——这种体验对Linux用户来说简直像一场噩梦。nvidia-smi命令返回"驱动未加载",外接显示器黑屏,…...

CPT Markets:国际监管框架下的稳健运营
在评估金融服务平台时,监管合规、技术能力、客户服务等维度构成了重要的观察方向。CPT Markets作为业内较为活跃的服务机构,其在这些方面的实践具有一定的参考价值。本文将围绕评测视角,对其综合表现进行系统性的呈现,希望为读者提…...

SkillSync MCP:为AI技能市场构建自动化安全门禁系统
1. 项目概述:为AI技能市场装上“安全门” 如果你和我一样,是Claude Code、Cursor这类AI编程助手的深度用户,那你一定对“技能”(Skills)这个概念不陌生。简单来说,技能就是一些预定义的提示词模板或工具脚…...

终极百度网盘加速解决方案:BaiduPCS-Web完整使用指南
终极百度网盘加速解决方案:BaiduPCS-Web完整使用指南 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 还在为百度网盘那令人抓狂的下载速度而烦恼吗?当下载进度条像蜗牛一样缓慢移动时,你是…...

Flutter + 开源鸿蒙实战 | 极简记账本 Day1:项目初始化 + 底部导航框架搭建
🔥 Flutter 开源鸿蒙实战 | 极简记账本 Day1:项目初始化 底部导航框架搭建欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 系列项目:极简记账本(6 天完结)环境:Flutt…...

避坑指南:用Qt为STM32项目写上位机时,我遇到的5个串口和界面难题
避坑指南:用Qt为STM32项目写上位机时,我遇到的5个串口和界面难题 第一次用Qt给STM32开发上位机时,我以为串口通信不过是简单的数据收发,界面设计拖拖控件就能搞定。直到项目进度被各种诡异bug拖慢两周后,才意识到自己踩…...

从FPGA工程师的视角看AMBA总线:手把手教你用Verilog实现一个简易APB外设
从FPGA工程师的视角看AMBA总线:手把手教你用Verilog实现一个简易APB外设 在FPGA和数字IC设计领域,AMBA总线协议就像城市中的交通网络,负责协调各个功能模块之间的数据流动。而APB(Advanced Peripheral Bus)作为AMBA家族…...

OpenClaw 接入微信 / 企业微信完整教程
本文介绍如何通过 OpenClaw 框架,将个人微信和企业微信接入 AI Agent,实现「AI 自动回复」的功能。适用于树莓派、Mac/Windows 电脑、NAS 或云服务器等各类设备。 一、环境准备 1.1 安装 OpenClaw OpenClaw 是核心运行环境,负责加载插件、管…...

如何用GHelper解决华硕笔记本性能管理难题:轻量级开源工具的完整指南
如何用GHelper解决华硕笔记本性能管理难题:轻量级开源工具的完整指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivoboo…...