Docker搭建ELKF日志分析系统
Docker搭建ELKF日志分析系统
文章目录
- Docker搭建ELKF日志分析系统
- 资源列表
- 基础环境
- 一、系统环境准备
- 1.1、创建所需的映射目录
- 1.2、修改系统参数
- 1.3、单击创建elk-kgc网络桥接
- 二、基于Dockerfile构建Elasticsearch镜像
- 2.1、创建Elasticsearch工作目录
- 2.2、上传资源到指定工作路径
- 2.3、编写Dockerfile文件
- 2.4、构建Elasticsearch镜像
- 三、基于Dockerfile构建Kibana镜像
- 3.1、创建Kibana工作目录
- 3.2、上传资源到指定工作目录
- 3.3、编写Dockerfile文件
- 3.4、构建Kibana镜像
- 四、基于Dockerfile构建Logstash镜像
- 4.1、创建Logstash工作目录
- 4.2、编写Dockerfile文件
- 4.3、创建CMD运行的脚本文件
- 4.4、上传资源到指定工作目录
- 4.5、构建Logstash镜像
- 4.6、logstash配置文件详解
- 4.6.1、关于filter部分
- 4.6.2、关于output部分
- 五、基于Dockerfile构建Filebeat镜像
- 5.1、创建Filebeat工作目录
- 5.2、编写Dockerfile文件
- 5.3、创建CMD运行的脚本文件
- 5.4、上传资源到指定工作目录
- 5.5、构建Filebeat镜像
- 5.6、Filebeat.yml文件详解
- 六、启动Nginx容器作为日志输入源
- 七、启动Filebeat+ELK日志收集环境
- 7.1、启动Elasticsearch
- 7.2、启动Kibana
- 7.3、启动Logstash
- 7.4、启动Filebeat
- 八、Kibana Web管理
- 8.1、访问Kibana
- 九、Kibana图示分析
资源列表
| 操作系统 | 配置 | 主机名 | IP | 所需软件 |
|---|---|---|---|---|
| CentOS 7.9 | 4C8G | docker | 192.168.93.165 | Docker-ce 26.1.2 |
基础环境
- 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
- 关闭内核安全机制
setenforce 0
sed -i "s/^SELINUX=.*/SELINUX=disabled/g" /etc/selinux/config
- 修改主机名
hostnamectl set-hostname docker
一、系统环境准备
- 基于Docker环境部署ELKF日志分析系统,实现日志分析功能
1.1、创建所需的映射目录
# 根据实际情况做修改
[root@docker ~]# mkdir -p /var/log/elasticsearch
[root@docker ~]# chmod -R 777 /var/log/elasticsearch/
1.2、修改系统参数
# 定义了一个进程可以拥有的最大内存映射区域数
[root@docker ~]# echo "vm.max_map_count=655360" >> /etc/sysctl.conf
[root@docker ~]# sysctl -p
vm.max_map_count = 655360# 配置用户和系统级的资源限制。修改的内容立即生效(严谨)
[root@docker ~]# cat >> /etc/security/limits.conf << EOF
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 63335
* soft memlock unlimited
* hard memlock unlimited
EOF
1.3、单击创建elk-kgc网络桥接
[root@docker ~]# docker network create elk-kgc
b8b1b7e36412169d689c39b39b5624c79f8fe0698a3c7b95dc1c78852285644e
[root@docker ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
e8a2cadd9616 bridge bridge local
b8b1b7e36412 elk-kgc bridge local
3566b89c775b host host local
a5914394299b none null local
二、基于Dockerfile构建Elasticsearch镜像
- 执行步骤如下:
2.1、创建Elasticsearch工作目录
[root@docker ~]# mkdir -p /root/elk/elasticsearch
[root@docker ~]# cd /root/elk/elasticsearch/
2.2、上传资源到指定工作路径
- 上传Elasticsearch的源码包和Elasticsearch配置文件到/root/elk/elasticsearch目录下,所需文件如下
[root@docker elasticsearch]# ll
total 27872
-rw-r--r-- 1 root root 28535876 Jun 6 22:45 elasticsearch-6.1.0.tar.gz
-rw-r--r-- 1 root root 3017 Jun 6 22:44 elasticsearch.yml# 配置文件内容yml如下
[root@docker elasticsearch]# cat elasticsearch.yml | grep -v "#"
cluster.name: kgc-elk
node.name: node-1
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
2.3、编写Dockerfile文件
[root@docker elasticsearch]# cat Dockerfile
FROM centos:7
MAINTAINER wzh@kgc.com
RUN yum -y install java-1.8.0-openjdk vim telnet lsof
ADD elasticsearch-6.1.0.tar.gz /usr/local/
RUN cd /usr/local/elasticsearch-6.1.0/config
RUN mkdir -p /data/behavior/log-node1
RUN mkdir /var/log/elasticsearch
COPY elasticsearch.yml /usr/local/elasticsearch-6.1.0/config/
RUN useradd es && chown -R es:es /usr/local/elasticsearch-6.1.0/
RUN chmod +x /usr/local/elasticsearch-6.1.0/bin/*
RUN chown -R es:es /var/log/elasticsearch/
RUN chown -R es:es /data/behavior/log-node1/
RUN sed -i "s/-Xms1g/-Xms2g/g" /usr/local/elasticsearch-6.1.0/config/jvm.options
RUN sed -i "s/-Xmx1g/-Xmx2g/g" /usr/local/elasticsearch-6.1.0/config/jvm.options
EXPOSE 9200
EXPOSE 9300
CMD su es /usr/local/elasticsearch-6.1.0/bin/elasticsearch
2.4、构建Elasticsearch镜像
[root@docker elasticsearch]# docker build -t elasticsearch .
三、基于Dockerfile构建Kibana镜像
- 执行步骤如下:
3.1、创建Kibana工作目录
[root@docker ~]# mkdir -p /root/elk/kibana
3.2、上传资源到指定工作目录
- 上传kibana的源码包到/root/elk/kibana目录下
[root@docker ~]# ll /root/elk/kibana/
total 64404
-rw-r--r-- 1 root root 65947685 Jun 6 23:09 kibana-6.1.0-linux-x86_64.tar.gz
3.3、编写Dockerfile文件
[root@docker ~]# cd /root/elk/kibana/
[root@docker kibana]# cat Dockerfile
FROM centos:7
MAINTAINER wzh@kgc.com
RUN yum -y install java-1.8.0-openjdk vim telnet lsof
ADD kibana-6.1.0-linux-x86_64.tar.gz /usr/local/
RUN cd /usr/local/kibana-6.1.0-linux-x86_64
RUN sed -i "s/#server.name: \"your-hostname\"/server.name: "kibana-hostname"/g" /usr/local/kibana-6.1.0-linux-x86_64/config/kibana.yml
RUN sed -i "s/#server.port: 5601/server.port: \"5601\"/g" /usr/local/kibana-6.1.0-linux-x86_64/config/kibana.yml
RUN sed -i "s/#server.host: \"localhost\"/server.host: \"0.0.0.0\"/g" /usr/local/kibana-6.1.0-linux-x86_64/config/kibana.yml
RUN sed -ri '/elasticsearch.url/ s/^#|"//g' /usr/local/kibana-6.1.0-linux-x86_64/config/kibana.yml
RUN sed -i "s/localhost:9200/elasticsearch:9200/g" /usr/local/kibana-6.1.0-linux-x86_64/config/kibana.yml
EXPOSE 5601
CMD ["/usr/local/kibana-6.1.0-linux-x86_64/bin/kibana"]
3.4、构建Kibana镜像
[root@docker kibana]# docker build -t kibana .
四、基于Dockerfile构建Logstash镜像
- 执行步骤如下
4.1、创建Logstash工作目录
[root@docker ~]# mkdir -p /root/elk/logstash
4.2、编写Dockerfile文件
[root@docker ~]# cd /root/elk/logstash/
[root@docker logstash]# cat Dockerfile
FROM centos:7
MAINTAINER wzh@kgc.com
RUN yum -y install java-1.8.0-openjdk vim telnet lsof
ADD logstash-6.1.0.tar.gz /usr/local/
RUN cd /usr/local/logstash-6.1.0/
ADD run.sh /run.sh
RUN chmod 755 /*.sh
EXPOSE 5044
CMD ["/run.sh"]
4.3、创建CMD运行的脚本文件
[root@docker logstash]# cat run.sh
#!/bin/bash
/usr/local/logstash-6.1.0/bin/logstash -f /opt/logstash/conf/nginx-log.conf
4.4、上传资源到指定工作目录
- 上传logstash的源码包到/root/elk/logstash目录下,所需文件如下
[root@docker logstash]# ll
total 107152
-rw-r--r-- 1 root root 230 Jun 7 00:41 Dockerfile
-rw-r--r-- 1 root root 109714065 Jun 7 00:40 logstash-6.1.0.tar.gz
-rw-r--r-- 1 root root 88 Jun 7 00:42 run.sh
4.5、构建Logstash镜像
[root@docker logstash]# docker build -t logstash .
4.6、logstash配置文件详解
-
logstash功能非常强大,不仅仅是分析传入的文本,还可以作监控与告警之用。现在介绍logstash的配置文件其使用经验
-
logstash默认的配置文件不需要修改,只需要启动的时候指定一个配置文件即可!比如run.sh脚本中指定/opt/logstash/conf/nginx-log.conf。注意:文件包含了input、filter、output三部分,其中filter不是必须的
[root@docker ~]# mkdir -p /opt/logstash/conf
[root@docker ~]# vim /opt/logstash/conf/nginx-log.conf
input {beats {port => 5044}
}filter {if "www-bdqn-cn-pro-access" in [tags] {grok {match => {"message" => '%{QS:agent} \"%{IPORHOST:http_x_forwarded_for}\" - \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)\" %{NUMBER:response} %{NUMBER:bytes} %{QS:referrer} %{IPORHOST:remote_addr}:%{POSINT:port} %{NUMBER:remote_addr_response} %{BASE16FLOAT:request_time}'}}}urldecode {all_fields => true}date {match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]}useragent {source => "agent"target => "ua"}
}output {if "www-bdqn-cn-pro-access" in [tags] {elasticsearch {hosts => ["elasticsearch:9200"]manage_template => falseindex => "www-bdqn-cn-pro-access-%{+YYYY.MM.dd}"}}
}# 注意:使用nginx-log.conf文件拷贝时,match最长的一行自动换行问题
4.6.1、关于filter部分
- 输入和输出在logstash配置中是很简单的一步,而对数据进行匹配过滤处理显得复杂。匹配当行日志是入门水平需要掌握的,而多行甚至不规则的日志则需要ruby的协助。本例主要展示grok插件
- 以下是某生产环境nginx的access日志格式
log_format main '"$http_user_agent""$http_x_forwarded_for" ''$remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''$upstream_addr $upstream_status $upstream_response_time';
- 下面是对应上述nginx日志格式的grok捕获语法
'%{QS:agent} \"%{IPORHOST:http_x_forwarded_for}\" - \[%{HTTPDATE:timestamp}\]
\"(?:%{WORD:verb} %{NOTSPACE:request}(?:
HTTP/%{NUMBER:http_version})?|-
)\"%{NUMBER:response}%{NUMBER:bytes}%{QS:referrer}%{IP
ORHOST:remote_addr}:%{POSINT:port}
%{NUMBER:remote_addr_response}%{BASE16FLOAT:request_ time}'
在filter段内的第一行是判断语句,如果www-bdqn-cn-pro-access自定义字符在tags内,则使用grok段内的语句对日志进行处理
- geopi:使用GeoIP数据库对client_ip字段的IP地址进行解析,可得出该IP的经纬度、国家与城市等信息,但精确度不高,这主要依赖于GeoIP数据库
- date:默认情况下,Elasticsearch内记录的date字段是Elasticsearch接收到该日志的时间,但在实际应用中需要修改为日志中所记录的时间。这时,需要指定记录时间的字段并指定时间格式。如果匹配成功,则会将日志的时间替换至date字段中
- useragent:主要为webapp提供的解析,可以解析目前常见的一些useragent
4.6.2、关于output部分
- logstash可以在上层配置一个负载调度器实现群集。在实际应用中,logstash服务需要处理多种不同类型的日志或数据。处理后的日志或数据需要存放在不同的Elasticsearch群集或索引中,需要对日志进行分类
output {if "www-bdqn-cn-pro-access" in [tags] {elasticsearch {hosts => ["elasticsearch:9200"]manage_template => falseindex => "www-bdqn-cn-pro-access-%{+YYYY.MM.dd}"}}
}通过在output配置中设定判断语句,将处理后的数据存放到不同的索引中。而这个tags的添加有以下三种途径:
- 在Filebeat读取数据后,向logstash发送前添加到数据中
- logstash处理日志的时候,向tags标签添加自定义内容
- 在logstash接收传入数据时,向tags标签添加自定义内容
从上面的输入配置文件中可以看出,这里来采用的第一种图形,在Filebeat读取数据后,向logstash发送数据前添加www-bdqn-cn-pro-access的tag
这个操作除非在后续处理数据的时候手动将其删除,否则将永久存在该数据中
Elasticsearch字段的各参数意义如下:
- hosts:指定Elasticsearch地址,如有多个节点可用,可以设置为array模式,可实现负载均衡
- manage_template:如果该索引没有合适的模板可用,默认情况下将由默认的模板进行管理
- index:只当存储数据的索引
五、基于Dockerfile构建Filebeat镜像
- 执行步骤如下:
5.1、创建Filebeat工作目录
[root@docker ~]# mkdir -p /root/elk/Filebeat
5.2、编写Dockerfile文件
[root@docker ~]# cd /root/elk/Filebeat/
[root@docker Filebeat]# cat Dockerfile
FROM centos:7
MAINTAINER wzh@kgc.com
ADD filebeat-6.1.0-linux-x86_64.tar.gz /usr/local/
RUN cd /usr/local/filebeat-6.1.0-linux-x86_64
RUN mv /usr/local/filebeat-6.1.0-linux-x86_64/filebeat.yml /root
COPY filebeat.yml /usr/local/filebeat-6.1.0-linux-x86_64/
ADD run.sh /run.sh
RUN chmod 755 /*.sh
CMD ["/run.sh"]
5.3、创建CMD运行的脚本文件
[root@docker Filebeat]# cat run.sh
#!/bin/bash
/usr/local/filebeat-6.1.0-linux-x86_64/filebeat -e -c /usr/local/filebeat-6.1.0-linux-x86_64/filebeat.yml
5.4、上传资源到指定工作目录
- 上传Filebeat的源码包和Filebeat配置文件到/root/elk/filebeat目录下,所需文件如下
[root@docker Filebeat]# ll
total 11660
-rw-r--r-- 1 root root 312 Jun 7 01:11 Dockerfile
-rw-r--r-- 1 root root 11926942 Jun 7 01:09 filebeat-6.1.0-linux-x86_64.tar.gz
-rw-r--r-- 1 root root 186 Jun 7 01:14 filebeat.yml
-rw-r--r-- 1 root root 118 Jun 7 01:12 run.sh
5.5、构建Filebeat镜像
[root@docker Filebeat]# docker build -t filebeat .
5.6、Filebeat.yml文件详解
- Filebeat配置我呢见详解查看Filebeat的配置文件
[root@docker Filebeat]# cat filebeat.yml
filebeat.prospectors:
- input_type: logpaths:- /var/log/nginx/www.bdqn.cn-access.logtags: www-bdqn-cn-pro-access clean_*: trueoutput.logstash:hosts: ["logstash:5044"]# 每个Filebeat可以根据需求的不同拥有一个或多个prospectors。其他配置信息含义如下:
1、input_type:输入的内容,主要为逐行读取的log格式与标准输入stdin
2、paths:指定需要读取的日志的路径,如果路径拥有相同的结构,则可以使用通配符
3、tags:为该路径的日志添加自定义tags
4、clean_:Filebeat在/var/lib/filebeat/registry下有个注册表文件,它记录着Filebeat读取过的文件,还有已经读取的行数等信息。如果日志文件是定时分割,而且数量会随之增加,那么该注册表文件也会慢慢增大。随着注册表的增大,会导致Filebeat检索的性能下降
5、output.logstash:定义内容输出的路径,这里主要输出到Elasticsearch
6、hosts:只当服务地址
六、启动Nginx容器作为日志输入源
- 使用docker run命令启动一个nginx容器
[root@docker ~]# docker run -itd -p 80:80 --network elk-kgc -v /var/log/nginx:/var/log/nginx --name nginx-elk nginx:latest
- 本地目录/var/log/nginx必须挂载到Filebeat容器中,让Filebeat可以采集到日目录
- 手动模拟生产环境几条日志文件作为nignx容器所产生的站点日志,同样注意拷贝的时候换行问题
[root@docker nginx]# cat www.bdqn.cn-access.log
"YisouSpider" "106.11.155.156" - [18/Jul/2020:00:00:13 +0800] "GET /applier/position?gwid=17728&qyid=122257 HTTP/1.0" 200 9197 "-" 192.168.10.131:80 2000.032
"-""162.209.213.146" - [18/Jul/2020:00:02:11 +0800] "GET //tag/7764.shtml HTTP/1.0" 200 24922 "-" 192.168.10.131:80 200 0.074
"YisouSpider" "106.11.152.248" - [18/Jul/2020:00:07:44+0800] "GET /news/201712/21424.shtml HTTP/1.0" 200 8821 "-" 192.168.10.131:80 2000.097
"YisouSpider" "106.11.158.233" - [18/Jul/2020:00:07:44+0800] "GET /news/201301/7672.shtml HTTP/1.0" 200 8666 "-" 192.168.10.131:80 2000.111
"YisouSpider" "106.11.159.250" - [18/Jul/2020:00:07:44+0800] "GET /news/info/id/7312.html HTTP/1.0" 200 6617 "-" 192.168.10.131:80 2000.339
"Mozilla/5.0 (compatible;SemrushBot/2~bl;+http://www.semrush.com/bot.html)" "46.229.168.83" - [18/Jul/2020:00:08:57+0800] "GET /tag/1134.shtml HTTP/1.0"2006030"-"192.168.10.131:80 200 0.079
七、启动Filebeat+ELK日志收集环境
- 注意启动顺序和查看启动日志
7.1、启动Elasticsearch
[root@docker ~]# docker run -itd -p 9200:9200 -p 9300:9300 --network elk-kgc -v /var/log/elasticsearch:/var/log/elasticsearch --name elasticsearch elasticsearch
7.2、启动Kibana
[root@docker ~]# docker run -itd -p 5601:5601 --network elk-kgc --name kibana kibana:latest
7.3、启动Logstash
[root@docker ~]# docker run -itd -p 5044:5044 --network elk-kgc -v /opt/logstash/conf:/opt/logstash/conf --name logstash logstash:latest
7.4、启动Filebeat
[root@docker ~]# docker run -itd --network elk-kgc -v /var/log/nginx:/var/log/nginx --name filebeat filebeat:latest
八、Kibana Web管理
- 因为kibana的数据需要从Elasticsearch中读取,所以需要Elasticsearch中有数据才能创建索引,创建不同的索引区分不同的数据集
8.1、访问Kibana
-
浏览器输入http://192.168.93.165:5601访问kibana控制台。在Management中找到Indexpatterns,单击进去可以看到类似以下图片中的界面,填写www-bdqn-cn-pro-access-*
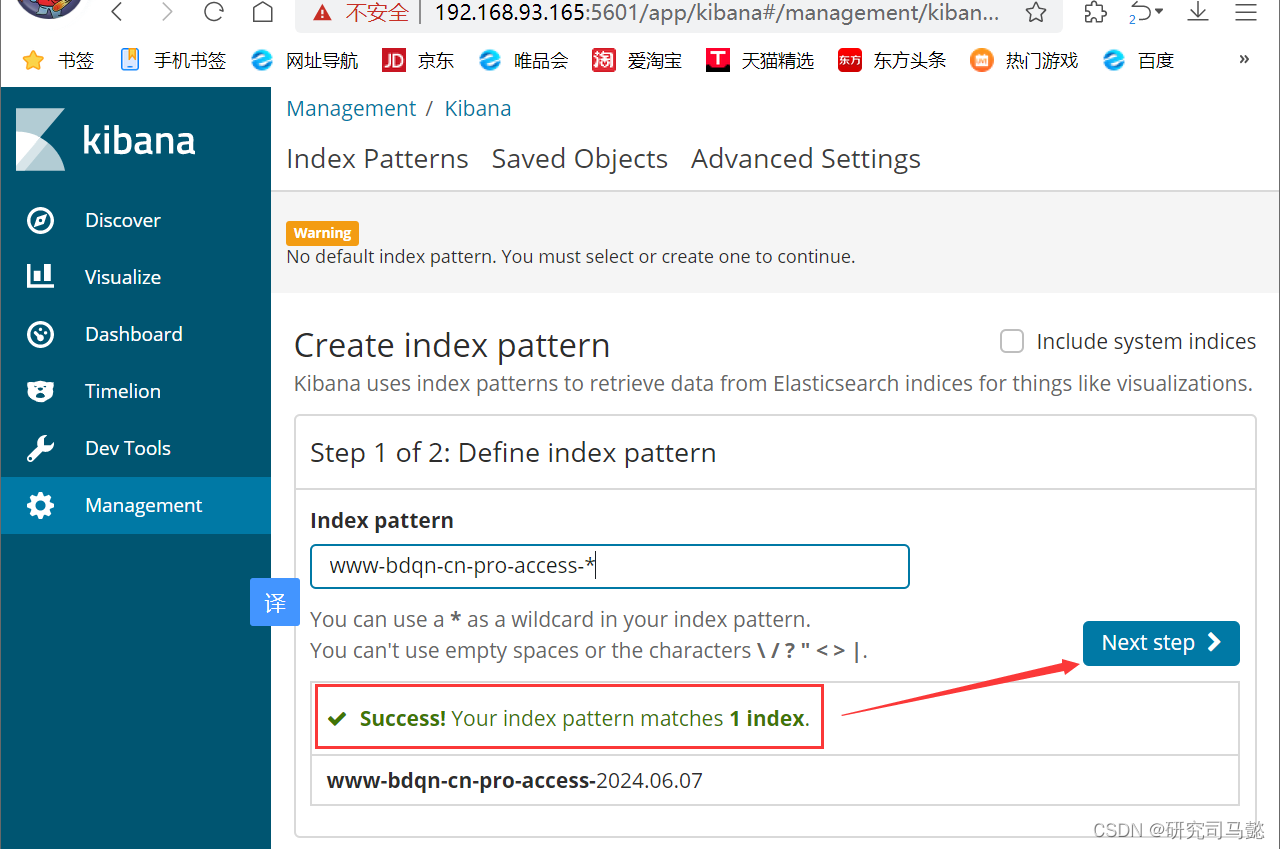
-
在TimeFilterfieldname选项框中选中@timestemp这个选项。在kibana中,默认通过时间来排序。如果将日志存放入Elasticsearch的时候没有指定@timestamp字段内容,则Elasticsearch会分配接收到的日志时的时间作为该日志@timestamp的值
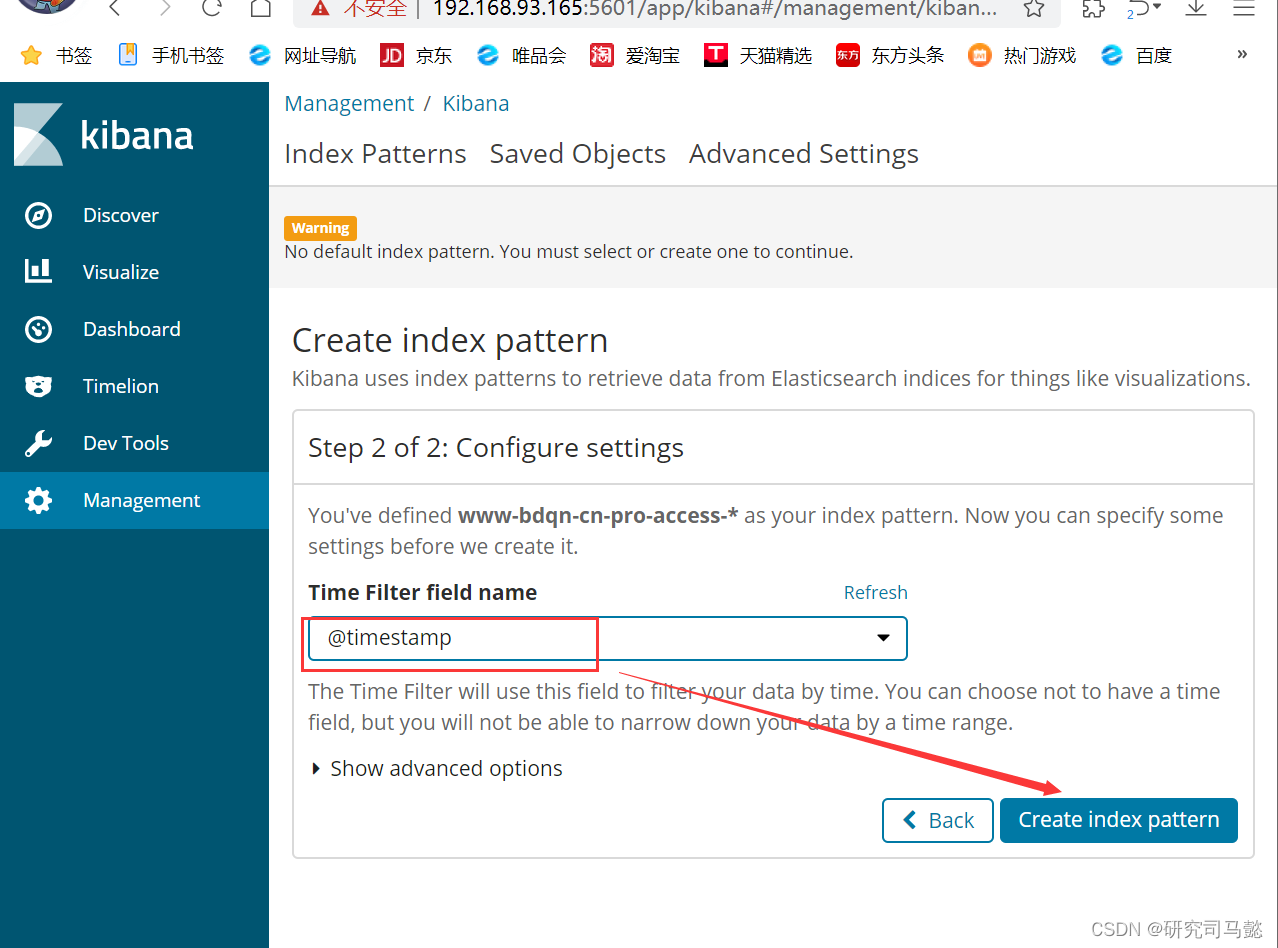
-
单击**“Createindexpattern”**按钮,创建www-bdqn-cn-pro-access索引后界面效果如下
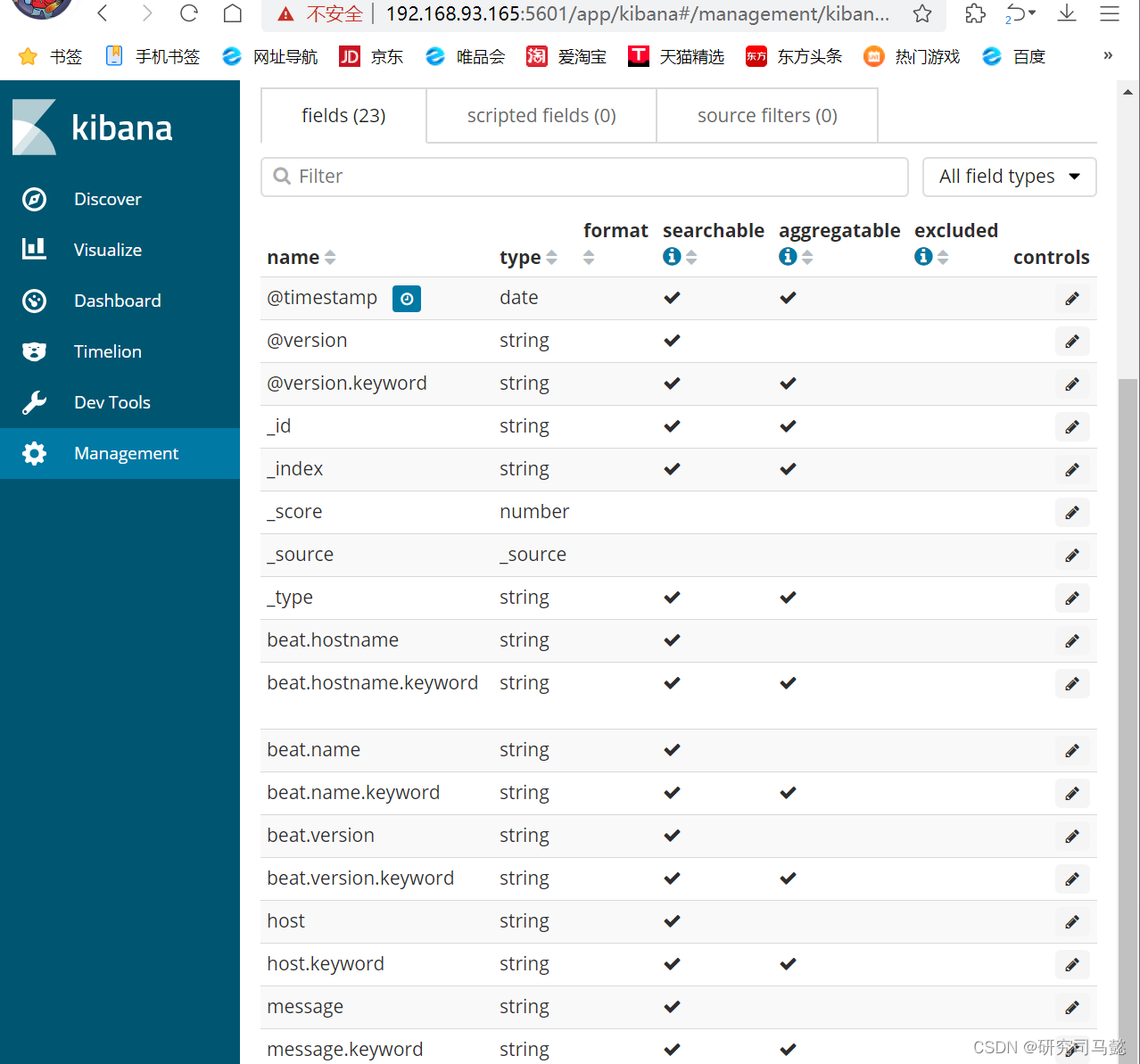
-
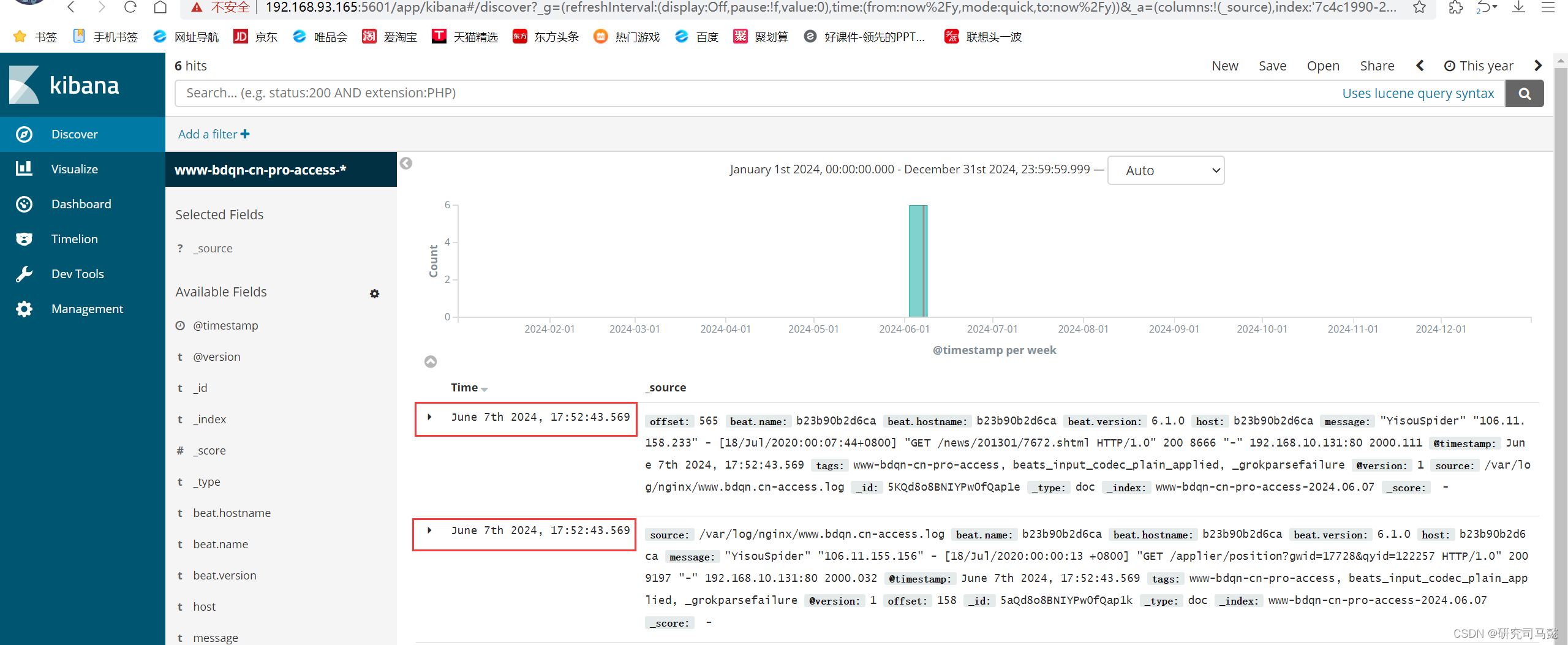
单击“Discover”标签,可能会看不到数据。需要将时间轴选中为“Thisyear”才可以看到的内容
九、Kibana图示分析
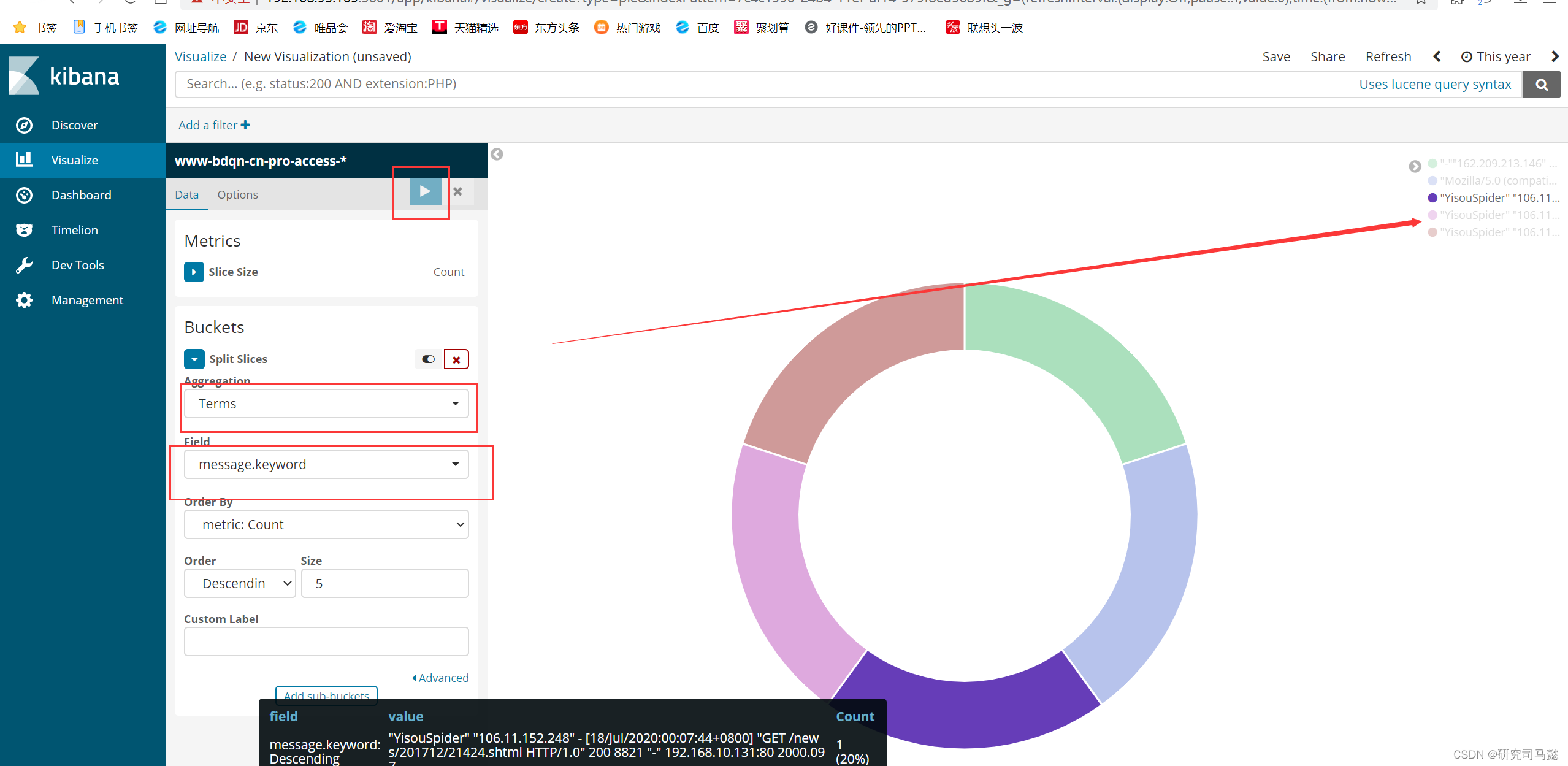
- 打开kibana的管理姐买你,单击“visualize”标签——Create a visualization,选择饼状图pie,添加索引www-bdqn-cn-por-access-*,点开SplitSlices,选中Terms,再从FieId选中messagekeyword,最后点击上面三角按钮即可生成可访问最多的5个公网IP地址
相关文章:
Docker搭建ELKF日志分析系统
Docker搭建ELKF日志分析系统 文章目录 Docker搭建ELKF日志分析系统资源列表基础环境一、系统环境准备1.1、创建所需的映射目录1.2、修改系统参数1.3、单击创建elk-kgc网络桥接 二、基于Dockerfile构建Elasticsearch镜像2.1、创建Elasticsearch工作目录2.2、上传资源到指定工作路…...
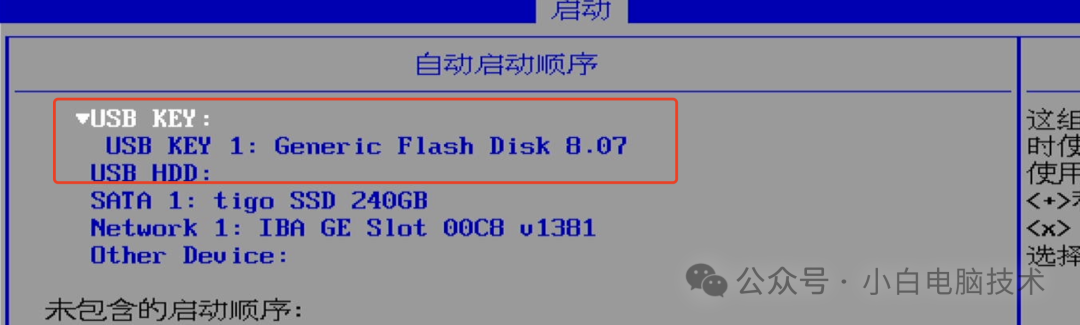
把系统引导做到U盘,实现插上U盘才能开机
前言 有个小伙伴提出了这样一个问题:能不能把U盘制作成电脑开机的钥匙? 小白稍微思考了一下,便做了这样一个回复:可以。 至于为什么要思考一下,这样会显得我有认真思考他提出的问题。 Windows7或以上系统均支持UEF…...
【计算机网络基础知识】
首先举一个生活化的例子,当你和朋友打电话时,你可能会使用三次握手和四次挥手的过程进行类比: 三次握手(Three-Way Handshake): 你打电话给朋友:你首先拨打你朋友的电话号码并等待他接听。这就…...

个股场外期权个人如何参与买卖?
个股场外期权作为一种金融衍生品,为个人投资者提供了多样化的投资选择和风险管理工具。想要参与个股场外期权的买卖,以下是一些关键步骤和考虑因素。 文章来源/:财智财经 第一步:选择合适的金融机构 首先,个人投资者需…...
程序猿大战Python——pycharm软件的使用
基础配置 目标:了解PyCharm软件的基础配置处理。 修改背景颜色: Appearance -> Theme 修改字体大小: 搜索font -> Font 例如,一起完成背景、字体大小的修改。 总结: (1)如果要对PyChar…...

Unity Standard shader 修改(增加本地坐标裁剪)
本想随便找一个裁剪的shader,可无奈的是没找到一个shader符合要求,美术制作的场景都是用的都标准的着色器他们不在乎你的功能逻辑需求,他们只关心场景的表现,那又找不到和unity标准着色器表现一样的shader 1.通过贴图的透明通道做…...

【数据结构】排序——插入排序,选择排序
前言 本篇博客我们正式开启数据结构中的排序,说到排序,我们能联想到我之前在C语言博客中的冒泡排序,它是排序中的一种,但实现效率太慢,这篇博客我们介绍两种新排序,并好好深入理解排序 💓 个人主…...

2024.6.9刷题记录
目录 一、1103. 分糖果 II 1.模拟 2.数学 二、312. 戳气球 1.递归-记忆化搜索 2.区间dp 三、2. 两数相加 1.迭代 2.递归-新建节点 3.递归-原节点 四、4. 寻找两个正序数组的中位数 1.堆 2.双指针二分 五、5. 最长回文子串 1.动态规划 2.中心扩展算法 六、6. Z…...
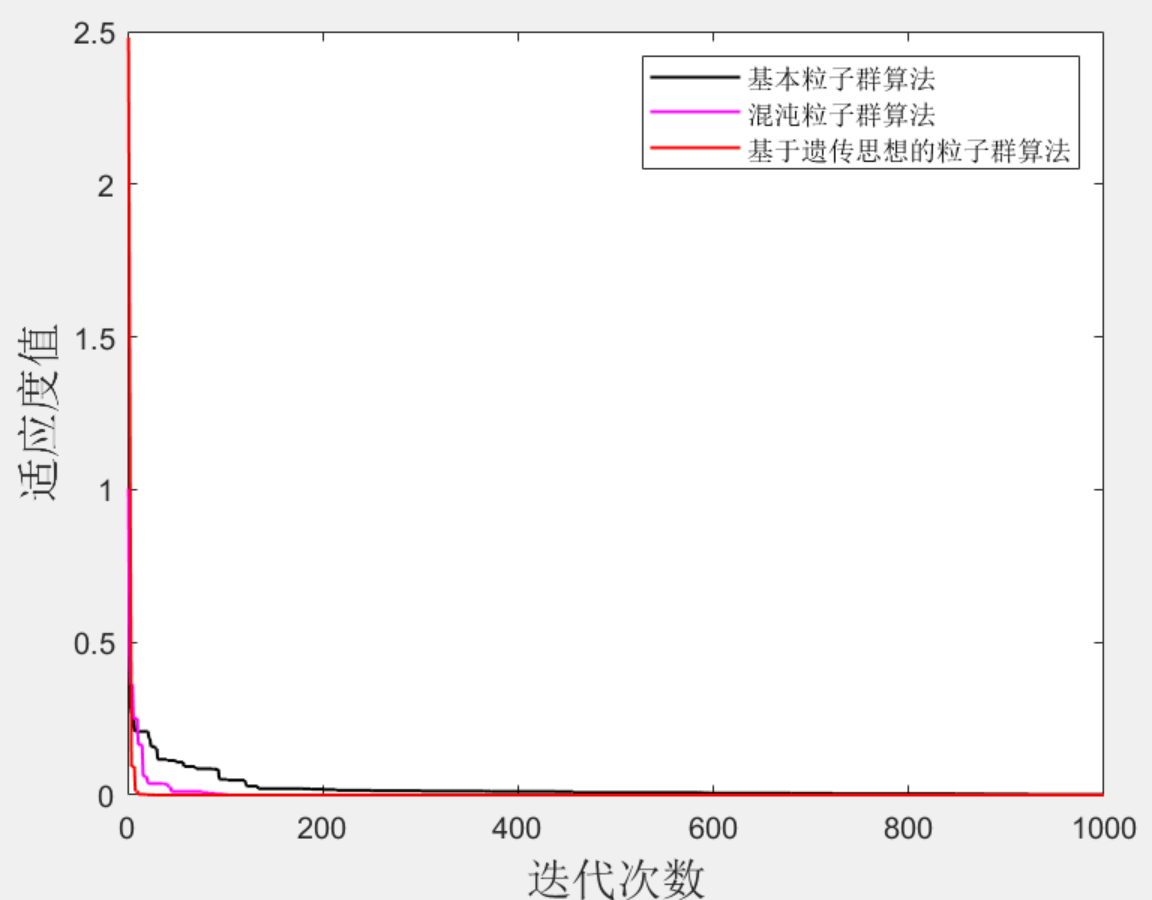
Matlab|遗传粒子群-混沌粒子群-基本粒子群
目录 1 主要内容 2 部分代码 3 效果图 4 下载链接 1 主要内容 很多同学在发文章时候最犯愁的就是创新点创新点创新点(重要的事情说三遍),对于采用智能算法的模型,可以采用算法改进的方式来达到提高整个文章创新水平的目的&…...
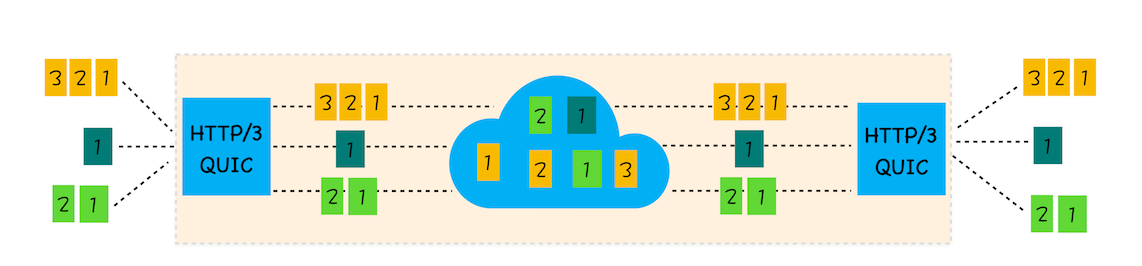
31|HTTP3:甩掉TCP、TLS 的包袱,构建高效网络
前面两篇文章我们分析了HTTP/1和HTTP/2,在HTTP/2出现之前,开发者需要采取很多变通的方式来解决HTTP/1所存在的问题,不过HTTP/2在2018年就开始得到了大规模的应用,HTTP/1中存在的一大堆缺陷都得到了解决。 HTTP/2的一个核心特性是…...
2 程序的灵魂—算法-2.2 简单算法举例-【例 2.3】
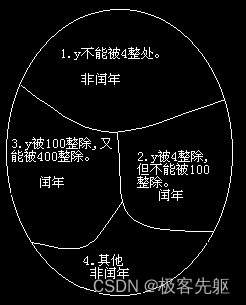
【例 2.3】判定 2000 — 2500 年中的每一年是否闰年,将结果输出。 润年的条件: 1. 能被 4 整除,但不能被 100 整除的年份; 2. 能被 100 整除,又能被 400 整除的年份; 设 y 为被检测的年份,则算法可表示如下…...
模块)
Python中的上下文管理器(contextlib)模块
Python中的contextlib模块提供了一些用于创建和管理上下文管理器(context managers)的工具。上下文管理器是实现了__enter__()和__exit__()方法的对象,它们通常用于确保在代码块执行前后执行某些操作,比如资源获取与释放、设置和重…...

C语言:定义和使用结构体变量
定义和使用结构体变量 介绍基础用法1.定义结构体2. 声明结构体变量3. 初始化和访问结构体成员4. 使用指针访问结构体成员5. 使用结构体数组 高级用法6. 嵌套结构体7. 匿名结构体8. 结构体和动态内存分配9. 结构体作为函数参数按值传递按引用传递 介绍 在C语言中,结…...

Vue3学习第二天记录
Vue3学习第二天记录 背景说明截图记录一个简单的JS文件Vue3的watch()函数Vue3的toRef()/toRefs()函数前端数据类型的分类前端写一个对外暴露的函数前端的...语法Vue3中watch()函数的总结Vue3中watchEffect()函数Vue3中watch()函数的坑Vue3中computed()函数 背景 最近在学习尚硅…...
C语言:双链表
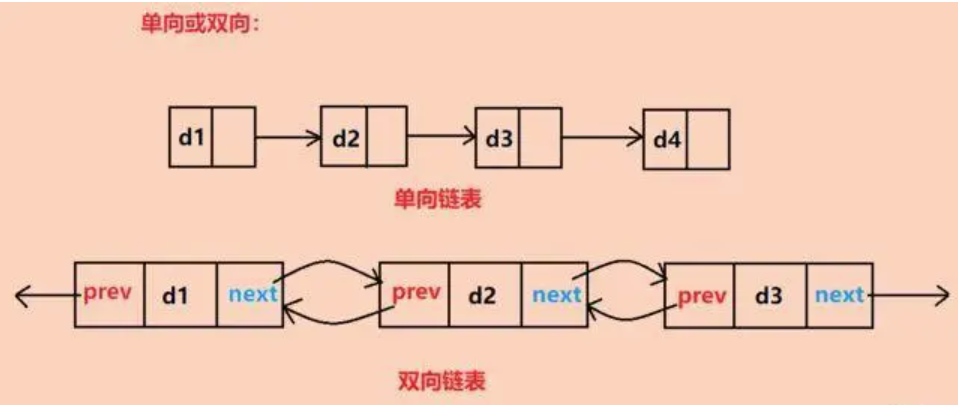
一、什么是双链表? 双链表,顾名思义,是一种每个节点都包含两个链接的链表:一个指向下一个节点,另一个指向前一个节点。这种结构使得双链表在遍历、插入和删除操作上都表现出色。与单链表相比,双链表不仅可以…...

Java物业管理系统+数据库应用程序开发[JavaSE+JDBC+idea控制台+MySQL]
背景: 使用JavaSEJDBCMySQL技术实现一个物业管理系统,具体要求如下 物业管理系统需求: 需求分析 1.1用户需求分析 在进入系统之前,要进行身份确认,只有用户名和用户密码都相符的用户方可进入本系统,为…...
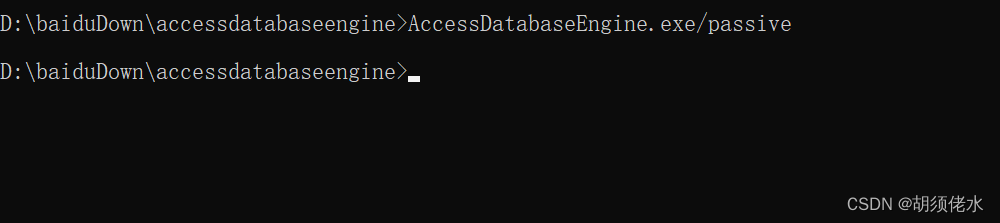
未在本地计算机上注册“Microsoft.ACE.OLEDB.12.0”提供程序。.net 读取excel的时候报错(实测有效)
1. 下载AccessDatabaseEngine.exe 下载链接 添加链接描述 2. office excel是64为的需要安装【AccessDatabaseEngine.exe】、32位的【AccessDatabaseEngine_X64.exe】 3. 我的是64为,跳过32位安装检测 1. 找到下载的安装包 2.输入安装包文件全称并在后面加上/pas…...
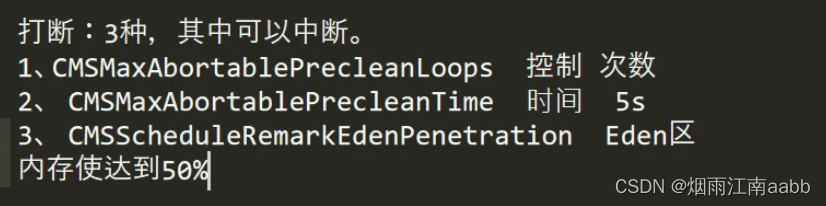
JVM垃圾收集器和性能调优
目标: 1.JVM垃圾收集器有哪几种? 2.CMS垃圾收集器回收步骤。 一、JVM常见的垃圾回收器 为什么垃圾回收的时候需要STW? 标记垃圾的时候,如果不STW,可能用户线程就会不停的产生垃圾。 1.1 单线程收集 Serial和SerialOld使用单…...
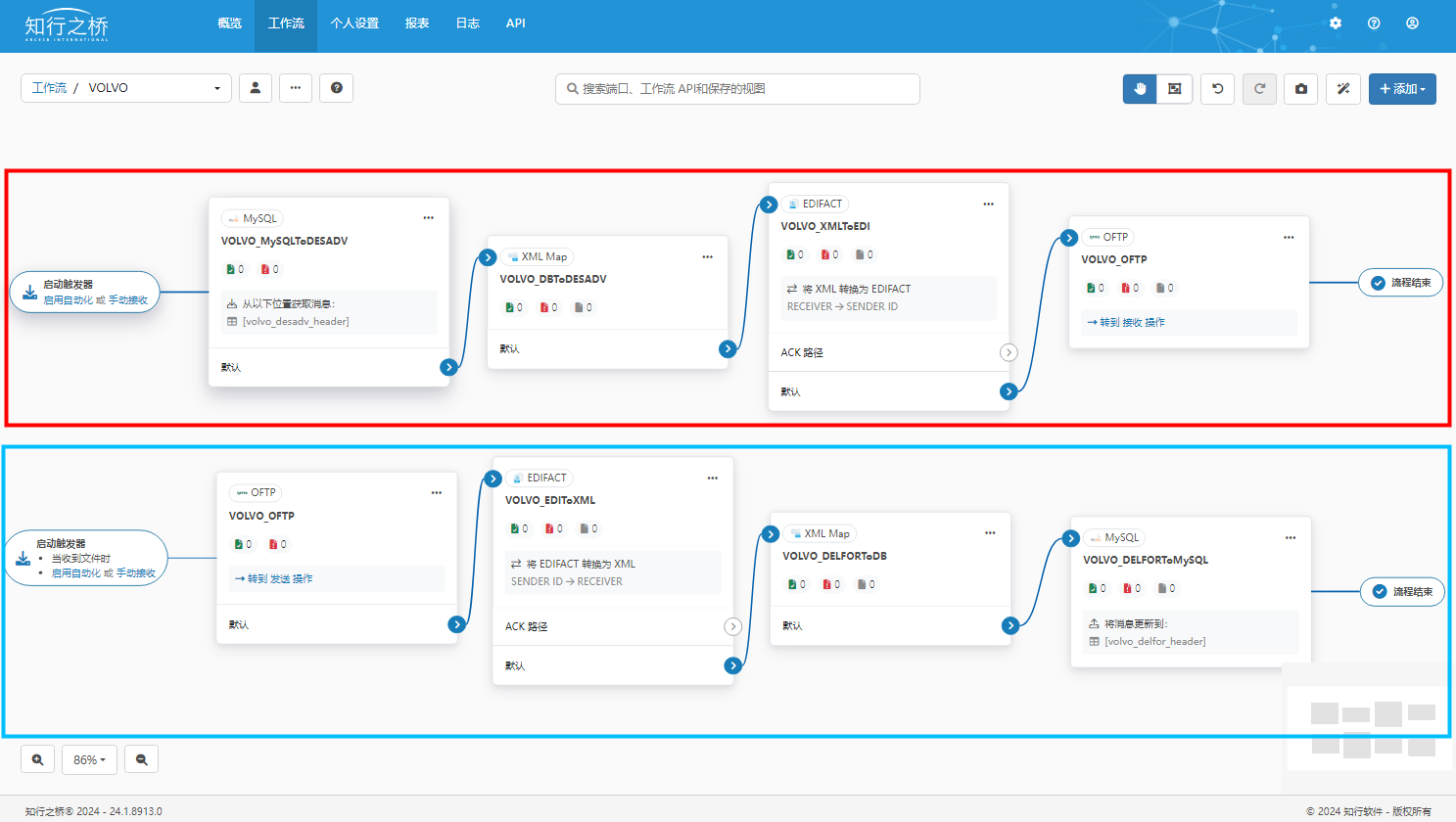
汽车EDI——Volvo EDI 项目案例
项目背景 作为Volvo的长期合作伙伴,C公司收到Volvo的EDI对接邀请,需要实现EDI对接。C公司将会面临哪些挑战?又应该相应地选择何种EDI解决方案呢? 汽车行业强调供需双方的高效协同(比如研发设计、生产计划、物流信息等…...

Qt应用程序发布
一、静态编译发布 1.0:以Release模式构建工程 1.1:查看当前构建生成路径,并将所生成的.exe单独拷贝出来 1.2:将可执行文件*.exe拷贝至任一目标文件夹:D:\Temporary\QQIF 2:查看安装Qt时发布工具windeployqt.exe所在的目录 windeployqt.exe在Qt开发套件的bin目录下。Qt的每…...

终极指南:5分钟搭建SillyTavern AI聊天前端,解锁个性化角色对话体验
终极指南:5分钟搭建SillyTavern AI聊天前端,解锁个性化角色对话体验 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 想要创建专属的AI聊天伙伴,体验深度…...

家庭影院系统构建指南:从流媒体技术到硬件选型
1. 疫情下的娱乐变局:从影院到客厅的深度迁移作为一名长期关注消费电子与家庭娱乐领域的从业者,我亲历了过去几年行业最剧烈的震荡。疫情像一只无形的手,强行按下了社会运行的暂停键,却又为另一个赛道按下了加速键。当电影院的大门…...

计算机视觉入门:从OpenCV到PyTorch的实践指南
1. 项目概述:从“萌芽”到“入行”的视觉之旅 “对计算机视觉的萌芽迷恋”——这个标题精准地捕捉了无数技术爱好者,包括我自己,最初踏入这个领域时的心路历程。它描述的是一种状态:你或许被一张AI生成的艺术图片所震撼ÿ…...

告别混乱XML:Notepad++插件一键美化与智能纠错实战
1. 为什么我们需要XML格式化工具? 作为一个常年和XML打交道的开发者,我太清楚那种打开一个几千行XML文件时的绝望了——所有标签挤在一起,缩进混乱得像被猫抓过的毛线球,想找个节点得用CtrlF来回搜三遍。更可怕的是,有…...
技术演进与核心论文全景解读)
综述篇 | 2015-2024,情绪识别(Emotion Recognition)技术演进与核心论文全景解读
1. 情绪识别技术演进全景图(2015-2024) 十年前,当研究人员试图通过摄像头分析人脸肌肉变化来判断情绪时,准确率还停留在60%左右。如今,结合多模态数据的情绪识别系统在特定场景下已突破90%准确率。这九年间的技术跃迁可…...

从视频到文字:当B站知识需要被存档时,我们如何优雅地捕获声音
从视频到文字:当B站知识需要被存档时,我们如何优雅地捕获声音 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾有过这样的经历…...

Arduino与MAX4080S联手:打造高精度微安级电流监测方案
1. 为什么需要微安级电流监测? 在开发低功耗设备时,电流监测就像给设备装上了"健康监测仪"。我做过一个智能手环项目,发现待机状态下整机电流只有23微安,用普通万用表根本测不准,数值跳得跟心电图似的。这时…...
)
MathType 快捷键实战指南——数学建模效率飙升的秘诀(从入门到精通)
1. 为什么你需要掌握MathType快捷键? 如果你经常需要处理数学公式,肯定遇到过这样的场景:为了输入一个简单的积分符号,不得不从工具栏里翻找半天;调整公式对齐时反复用鼠标拖动;修改矩阵维度时逐个单元格调…...
实战分配指南(MDK/IAR双环境))
告别内存焦虑!STM32H743全系列SRAM(ITCM/DTCM/AXI)实战分配指南(MDK/IAR双环境)
STM32H743内存优化实战:从理论到精准分配的完整指南 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。STM32H743作为STMicroelectronics推出的高性能微控制器系列,其复杂的内存架构既带来了性能优势,也增加了开发难…...
)
基于SpringBoot的企业客户管理系统(附源码)
项目编号050 项目获取:合集 想学习Java开发却找不到合适的项目练手?这套基于Spring Boot的企业客户管理系统就是你的最佳选择!代码简单清晰,功能实用完整,非常适合初学者学习和二次开发。 这是什么项目? …...