实战 | 通过微调SegFormer改进车道检测效果(数据集 + 源码)
背景介绍
SegFormer:实例分割在自动驾驶汽车技术的快速发展中发挥了关键作用。对于任何在道路上行驶的车辆来说,车道检测都是必不可少的。车道是道路上的标记,有助于区分道路上可行驶区域和不可行驶区域。车道检测算法有很多种,每种算法都有各自的优缺点。

在本文中,我们将使用Berkeley Deep Drive数据集对HuggingFace(Enze Xie、Wenhai Wang、Zhiding Yu 等人)中非常著名的SegFormer 模型进行微调,以对车辆的POV视频进行车道检测。此实验甚至适用于处理起来很复杂的夜间驾驶场景。
车道检测在ADAS中的作用
总体而言,车道检测对ADAS系统产生了深远影响。让我们在这里探讨其中的几个:
-
车道保持:除了警告系统之外,车道检测也是车道保持辅助 (LKA) 技术不可或缺的一部分,它不仅可以提醒驾驶员,还可以采取纠正措施,例如轻柔的转向干预,以使车辆保持在车道中央。
-
交通流分析:车道检测使车辆能够了解道路几何形状,这在合并和变道等复杂驾驶场景中至关重要,并且对于根据周围交通流量调整速度的自适应巡航控制系统至关重要。
-
自动导航:对于半自动或自动驾驶汽车,车道检测是使车辆能够在道路基础设施内导航和保持其位置的基本组件。它对于自动驾驶算法中的路线规划和决策过程至关重要。
-
驾驶舒适度:使用车道检测的系统可以接管部分驾驶任务,减少驾驶员疲劳,提供更舒适的驾驶体验,尤其是在高速公路长途行驶时。
-
道路状况监测:车道检测系统也有助于监测道路状况。例如,如果系统持续检测到车道标记不清晰或根本没有车道标记,则可以反馈此信息以用于基础设施维护和改进。
伯克利Deep Drive数据集
Berkeley Deep Drive 100K (BDD100K) 数据集是从各个城市和郊区收集的各种驾驶视频序列的综合集合。其主要用于促进自动驾驶的研究和开发。该数据集非常庞大,包含约100,000 个视频,每个视频时长 40 秒,涵盖各种驾驶场景、天气条件和一天中的时间。BDD100K 数据集中的每个视频都附有一组丰富的帧级注释。这些注释包括车道、可驾驶区域、物体(如车辆、行人和交通标志)的标签以及全帧实例分割。数据集的多样性对于开发强大的车道检测算法至关重要,因为它可以将模型暴露给各种车道标记、道路类型和环境条件。

在本文中, BDD100K 数据集的10% 样本用于微调 SegFormer 模型。这种子采样方法允许更易于管理的数据集大小,同时保持整个数据集中存在的整体多样性的代表性子集。10% 的样本包括10,000 张图像,这些图像是经过精心挑选以代表数据集的全面驾驶条件和场景。
让我们看一下示例数据集中的一些示例图像和标注掩码:



从上图可以看出,对于BDD数据集中的每个图像,都有一个有效的真实二进制掩码,可协助完成车道检测任务。这可以视为一个2 类分割问题,其中车道由一个类表示,背景是另一个类。在这种情况下,训练集有7000张图像和掩码,有效集有大约3000张图像和掩码。
接下来,让我们为这个实验构建训练管道。
代码演练
在本节中,我们将探讨使用 BDD 数据集微调HuggingFace SegFormer 模型(本文还解释了内部架构)所涉及的各种过程。
先决条件
'BDDDataset' 类的主要目的是高效地从指定目录加载和预处理图像数据及其相应的分割掩码。它负责以下功能:
-
-
使用路径加载图像及其对应的蒙版。
-
图像转换为 RGB 格式,而蒙版转换为灰度(单通道)。
-
然后将掩码转换为二进制格式,其中非零像素被视为车道的一部分(假设车道分割任务)。
-
将蒙版调整大小以匹配图像尺寸,然后转换为张量。
-
最后,将掩码阈值化回二进制值并转换为 LongTensor,适合 PyTorch 中的分割任务
-
class BDDDataset(Dataset):def __init__(self, images_dir, masks_dir, transform=None):self.images_dir = images_dirself.masks_dir = masks_dirself.transform = transformself.images = [img for img in os.listdir(images_dir) if img.endswith('.jpg')]self.masks = [mask.replace('.jpg', '.png') for mask in self.images]def __len__(self):return len(self.images)def __getitem__(self, idx):image_path = os.path.join(self.images_dir, self.images[idx])mask_path = os.path.join(self.masks_dir, self.masks[idx])image = Image.open(image_path).convert("RGB")mask = Image.open(mask_path).convert('L') # Convert mask to grayscale# Convert mask to binary format with 0 and 1 valuesmask = np.array(mask)mask = (mask > 0).astype(np.uint8) # Assuming non-zero pixels are lanes# Convert to PIL Image for consistency in transformsmask = Image.fromarray(mask)if self.transform:image = self.transform(image)# Assuming to_tensor transform is included which scales pixel values between 0-1# mask = to_tensor(mask) # Convert the mask to [0, 1] rangemask = TF.functional.resize(img=mask, size=[360, 640], interpolation=Image.NEAREST)mask = TF.functional.to_tensor(mask)mask = (mask > 0).long() # Threshold back to binary and convert to LongTensorreturn image, mask
数据加载器定义和初始化
使用之前创建的“BDDDataset”类,我们需要定义和初始化数据加载器。为此,必须创建两个单独的数据加载器,一个用于训练集,另一个用于验证集。训练数据加载器还需要一些转换。下面的代码片段可用于此目的:
# Define the appropriate transformationstransform = TF.Compose([TF.Resize((360, 640)),TF.ToTensor(),TF.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# Create the datasettrain_dataset = BDDDataset(images_dir='deep_drive_10K/train/images',masks_dir='deep_drive_10K/train/masks',transform=transform)valid_dataset = BDDDataset(images_dir='deep_drive_10K/valid/images',masks_dir='deep_drive_10K/valid/masks',transform=transform)# Create the data loaderstrain_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=6)valid_loader = DataLoader(valid_dataset, batch_size=4, shuffle=False, num_workers=6)
让我们看一下该管道中使用的转换。
-
TF.Resize((360, 640)):将图像大小调整为 360×640 像素的统一大小。
-
TF.ToTensor():将图像转换为 PyTorch 张量。
-
TF.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):使用指定的平均值和标准差对图像进行归一化,这些平均值和标准差通常来自 ImageNet 数据集。此步骤对于在ImageNet上预训练的模型至关重要。
根据自己的计算资源,您可能希望调整“batch_size”和“num_workers”等参数。
HuggingFace SegFormer 🤗 模型初始化
# Load the pre-trained modelmodel = SegformerForSemanticSegmentation.from_pretrained('nvidia/segformer-b2-finetuned-ade-512-512')# Adjust the number of classes for BDD datasetmodel.config.num_labels = 2 # Replace with the actual number of classes
上面的代码片段初始化了 HuggingFace 预训练语义分割模型库中的 SegFormer-b2 模型。由于我们试图将车道从道路中分割出来,因此这将被视为 2 类分割问题。
# Check for CUDA accelerationdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device);
在此过程中,请检查您的深度学习环境是否支持使用 Nvidia GPU 的CUDA 加速。在此实验中,使用配备12GB vRAM的Nvidia RTX 3080 Ti进行训练。
训练和验证
在本节中,让我们看一下微调此模型所需的训练和验证流程。但在此之前,您将如何评估此模型的性能?
对于像这样的语义分割问题,IoU(或)并集交集是评估的主要指标。这有助于我们了解预测掩码与 GT 掩码的重叠程度。
def mean_iou(preds, labels, num_classes):# Flatten predictions and labelspreds_flat = preds.view(-1)labels_flat = labels.view(-1)# Check that the number of elements in the flattened predictions# and labels are equalif preds_flat.shape[0] != labels_flat.shape[0]:raise ValueError(f"Predictions and labels have mismatched shapes: "f"{preds_flat.shape} vs {labels_flat.shape}")# Calculate the Jaccard score for each classiou = jaccard_score(labels_flat.cpu().numpy(), preds_flat.cpu().numpy(),average=None, labels=range(num_classes))# Return the mean IoUreturn np.mean(iou)
上述函数“mean_iou”执行以下操作:
-
-
扁平化预测和标签:使用 .view(-1) 方法扁平化预测和标签。需要进行这种重塑,以便逐像素比较每个预测与其对应的标签。
-
形状验证:该函数检查 preds_flat 和 labels_flat 中的元素数量是否相等。这是一项至关重要的检查,以确保每个预测都对应一个标签。
-
杰卡德分数计算:使用 jaccard_score 函数(通常来自 scikit-learn 等库)计算每个类的杰卡德分数 (IoU)。IoU 是在扁平预测和标签之间计算的。它是针对每个类单独计算的,如 average=None 和 labels=range(num_classes) 所示。
-
平均 IoU 计算:平均 IoU 是通过计算所有类别的 IoU 分数的平均值来计算的。这提供了一个单一的性能指标,总结了模型的预测与所有类别的基本事实的一致程度。
-
# Define the optimizeroptimizer = AdamW(model.parameters(), lr=5e-5)# Define the learning rate schedulernum_epochs = 30num_training_steps = num_epochs * len(train_loader)lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps)# Placeholder for best mean IoU and best model weightsbest_iou = 0.0best_model_wts = copy.deepcopy(model.state_dict())
对于模型优化,我们使用了著名的 Adam 优化器,其 `learning_rate` 为 5e-5。在这个实验中,微调过程进行了 30 个 `epochs`。
for epoch in range(num_epochs):model.train()train_iterator = tqdm(train_loader, desc=f"Epoch {epoch + 1}/{num_epochs}", unit="batch")for batch in train_iterator:images, masks = batchimages = images.to(device)masks = masks.to(device).long() # Ensure masks are LongTensors# Remove the channel dimension from the masks tensormasks = masks.squeeze(1) # This changes the shape from [batch, 1, H, W] to [batch, H, W]optimizer.zero_grad()# Pass pixel_values and labels to the modeloutputs = model(pixel_values=images, labels=masks,return_dict=True)loss = outputs["loss"]loss.backward()optimizer.step()lr_scheduler.step()outputs = F.interpolate(outputs["logits"], size=masks.shape[-2:], mode="bilinear", align_corners=False)train_iterator.set_postfix(loss=loss.item())
上面的代码片段说明了微调过程的训练循环。对于每个时期,循环都会遍历训练数据加载器“train_loader”,它提供成批的图像和掩码对。这些是车道图像及其相应的分割掩码。每批图像和掩码都会移动到计算设备(如 GPU,称为“设备”)。掩码张量的通道维度被移除以匹配模型所需的输入格式。
该模型执行前向传递,接收图像和掩码作为输入。在本例中,`pixel_values` 参数接收图像,labels 参数接收掩码。模型输出包括损失值(用于训练)和 logits(原始预测)。此后,损失反向传播以更新模型的权重。此后,优化器和学习率调度程序 `lr_scheduler` 在训练期间调整学习率和其他参数。使用双线性插值调整模型中的 logits 的大小以匹配掩码的大小。此步骤对于将模型的预测与地面真实掩码进行比较至关重要。
# Evaluation loop for each epochmodel.eval()total_iou = 0num_batches = 0valid_iterator = tqdm(valid_loader, desc="Validation", unit="batch")for batch in valid_iterator:images, masks = batchimages = images.to(device)masks = masks.to(device).long()with torch.no_grad():# Get the logits from the model and apply argmax to get the predictionsoutputs = model(pixel_values=images,return_dict=True)outputs = F.interpolate(outputs["logits"], size=masks.shape[-2:], mode="bilinear", align_corners=False)preds = torch.argmax(outputs, dim=1)preds = torch.unsqueeze(preds, dim=1)preds = preds.view(-1)masks = masks.view(-1)# Compute IoUiou = mean_iou(preds, masks, model.config.num_labels)total_iou += iounum_batches += 1valid_iterator.set_postfix(mean_iou=iou)epoch_iou = total_iou / num_batchesprint(f"Epoch {epoch+1}/{num_epochs} - Mean IoU: {epoch_iou:.4f}")# Check for improvementif epoch_iou > best_iou:print(f"Validation IoU improved from {best_iou:.4f} to {epoch_iou:.4f}")best_iou = epoch_ioubest_model_wts = copy.deepcopy(model.state_dict())torch.save(best_model_wts, 'best_model.pth')
对于此过程的验证方面,模型设置为评估模式 (model.eval()),这会禁用仅在训练期间使用的某些层和行为(如 dropout)。在这种情况下,对于验证数据集中的每个批次,模型都会生成预测。这些预测会调整大小并进行处理,以计算交并比 (IoU) 指标。计算并汇总每个批次的平均 IoU,以得出该时期的平均 IoU。在每个时期之后,将 IoU 与之前时期获得的最佳 IoU 进行比较。如果当前 IoU 更高,则表示有所改进,并且模型的状态将保存为迄今为止的最佳模型。
视频推理
好了,我们现在有了一个经过充分微调的 SegFormer,它专门用于自动驾驶汽车的车道检测。但是,我们如何看待结果呢?在本节中,让我们探索这个实验的推理部分。
首先,必须加载预先训练的 SegFormer 权重。还需要定义类的数量。这是使用 `model.config.num_labels=2` 完成的,因为我们要处理 2 个类。
从这里开始,还需要加载上一个代码片段导出的“best_model.pth”权重文件。这包含微调模型的最佳训练权重。模型必须设置为评估模式。
# Load the trained modeldevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = SegformerForSemanticSegmentation.from_pretrained('nvidia/segformer-b2-finetuned-ade-512-512')# Replace with the actual number of classesmodel.config.num_labels = 2# Load the state from the fine-tuned model and set to model.eval() modemodel.load_state_dict(torch.load('segformer_inference-360640-b2/best_model.pth'))model.to(device)model.eval()# Video inferencecap = cv2.VideoCapture('test-footages/test-2.mp4')fourcc = cv2.VideoWriter_fourcc(*'XVID')out = cv2.VideoWriter('output_video.avi', fourcc, 20.0, (int(cap.get(3)), int(cap.get(4))))
为了加载和读取视频,使用了 OpenCV,并使用 `cv2.VideoWriter` 方法导出最终推理视频,其中蒙版与源视频片段重叠。
# Perform transformationsdata_transforms = TF.Compose([TF.ToPILImage(),TF.Resize((360, 640)),TF.ToTensor(),TF.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
需要记住的一件非常重要的事情是,在数据集预处理期间使用的相同“变换”也必须在推理阶段使用。视频中的每一帧都会经历一系列变换,以匹配模型所需的输入格式。这些变换包括调整大小、张量转换和规范化。
# Inference loopwhile(cap.isOpened()):ret, frame = cap.read()if ret == True:# Preprocess the frameinput_tensor = data_transforms(frame).unsqueeze(0).to(device)with torch.no_grad():outputs = model(pixel_values=input_tensor,return_dict=True)outputs = F.interpolate(outputs["logits"], size=(360, 640), mode="bilinear", align_corners=False)preds = torch.argmax(outputs, dim=1)preds = torch.unsqueeze(preds, dim=1)predicted_mask = (torch.sigmoid(preds) > 0.5).float()# Create an RGB version of the mask to overlay on the original framemask_np = predicted_mask.cpu().squeeze().numpy()mask_resized = cv2.resize(mask_np, (frame.shape[1], frame.shape[0]))# Modify this section to create a green maskmask_rgb = np.zeros((mask_resized.shape[0], mask_resized.shape[1], 3), dtype=np.uint8)mask_rgb[:, :, 1] = (mask_resized * 255).astype(np.uint8) # Set only the green channel# Post-processing for mask smoothening# Remove noisekernel = np.ones((3,3), np.uint8)opening = cv2.morphologyEx(mask_rgb, cv2.MORPH_OPEN, kernel, iterations=2)# Close small holesclosing = cv2.morphologyEx(opening, cv2.MORPH_CLOSE, kernel, iterations=2)# Overlay the mask on the frameblended = cv2.addWeighted(frame, 0.65, closing, 0.6, 0)# Write the blended frame to the output videoout.write(blended)else:breakcap.release()out.release()cv2.destroyAllWindows()
在推理循环中,每个预处理过的帧都会被输入到模型中。模型输出对数,然后将其插值到原始帧大小并通过 argmax 函数来获得预测的分割掩码。阈值操作将这些预测转换为二进制掩码,突出显示检测到的车道。
为了更好地进行可视化,二进制掩码被转换为 RGB 格式,车道颜色为绿色。应用一些后处理步骤(如噪声消除和孔洞填充)来平滑掩码。然后将此掩码与原始帧混合以创建检测到的车道的视觉叠加。
最后,将混合后的帧写入输出视频文件,脚本继续对输入视频中的所有帧执行此过程并关闭所有文件流。这样会生成一个输出视频,其中检测到的车道会以视觉方式突出显示,从而展示该模型在现实场景中执行车道检测的能力。
实验结果
现在来看看本文最有趣的部分——推理结果!在最后一部分中,让我们看一下经过微调的 HuggingFace SegFormer 模型在车道检测中的推理结果。






从上面显示的推理结果来看,我们可以得出结论,SegFormer 在车道检测方面效果很好。正如本文所述, SegFormer-b2 模型在大量 BDD 数据集的子样本上进行了 30 个 epoch 的微调。 为了增强您的理解并亲手操作代码,请在此处浏览代码。
为了获得更好、更准确的结果,建议选择更大、更准确的SegFormer-b5 模型,并可能在整个数据集上对其进行更多次训练。
结 论
在本次实验中,我们利用 BDD(Berkeley DeepDrive)车道检测数据集提供的丰富多样的数据,成功展示了微调的 SegFormer 模型在车道检测任务中的应用。这种方法凸显了微调的有效性以及 SegFormer 架构在处理自动驾驶和道路安全中的复杂语义分割任务时的稳健性,即使在漆黑的夜晚也是如此。
最终的输出结果(检测到的车道叠加在原始视频帧上)不仅可作为概念验证,还展示了该技术在实时应用中的潜力。车道检测的流畅性和准确性(在叠加的绿色蒙版中可视化)证明了该模型的有效性。最后,可以肯定的是,即使有多种尖端的车道检测算法,对 SegFormer 这样的模型进行微调也能获得出色的结果!
参考链接:
HuggingFace SegFormer:
https://huggingface.co/docs/transformers/model_doc/segformer伯克利 Deep Drive 数据集:
https://deepdrive.berkeley.edu/源码下载链接:
https://github.com/spmallick/learnopencv/tree/master/Fine-Tuning-SegFormer-For-Lane-Detection—THE END—
相关文章:
实战 | 通过微调SegFormer改进车道检测效果(数据集 + 源码)
背景介绍 SegFormer:实例分割在自动驾驶汽车技术的快速发展中发挥了关键作用。对于任何在道路上行驶的车辆来说,车道检测都是必不可少的。车道是道路上的标记,有助于区分道路上可行驶区域和不可行驶区域。车道检测算法有很多种,每…...
翻译《The Old New Thing》- Why do messages posted by PostThreadMessage disappear?
Why do messages posted by PostThreadMessage disappear? - The Old New Thing (microsoft.com)https://devblogs.microsoft.com/oldnewthing/20090930-00/?p16553 Raymond Chen 2008年09月30日 为什么 PostThreadMessage 发布的信息会消失? 在显示用户界面的线…...

【深度学习】—— 神经网络介绍
神经网络介绍 本系列主要是吴恩达深度学习系列视频的笔记,传送门:https://www.coursera.org/deeplearning-ai 目录 神经网络介绍神经网络的应用深度学习兴起的原因 神经网络,全称人工神经网络(Artificial Neural Network…...

python-数字黑洞
[题目描述] 给定一个三位数,要求各位不能相同。例如,352是符合要求的,112是不符合要求的。将这个三位数的三个数字重新排列,得到的最大的数,减去得到的最小的数,形成一个新的三位数。对这个新的三位数可以重…...

SpringCloud 负载均衡 spring-cloud-starter-loadbalancer
简述 spring-cloud-starter-loadbalancer 是 Spring Cloud 中的一个组件,它提供了客户端负载均衡的功能。在 Spring Cloud 的早期版本中,Netflix Ribbon 被广泛用作客户端负载均衡器,但随着时间推移和 Netflix Ribbon 进入维护模式ÿ…...

牛客周赛-46
牛客周赛-46 a乐奈吃冰b素世喝茶c爱音开灯d小灯做题 a乐奈吃冰 ac code #include<iostream> using namespace std; int main(){long long a,b;cin>>a>>b;int tmpmin(b,a/2);long long resatmp;cout<<res;return 0; }b素世喝茶 #include<iostream…...

多模态vlm综述:An Introduction to Vision-Language Modeling 论文解读
目录 1、基于对比学习的VLMs 1.1 CLIP 2、基于mask的VLMs 2.1 FLAVA 2.2 MaskVLM 2.3 关于VLM目标的信息理论视角 3、基于生成的VLM 3.1 学习文本生成器的例子: 3.2 多模态生成模型的示例: 3.3 使用生成的文本到图像模型进行下游视觉语言任务 4、 基于预训练主干网…...
28.找零
上海市计算机学会竞赛平台 | YACSYACS 是由上海市计算机学会于2019年发起的活动,旨在激发青少年对学习人工智能与算法设计的热情与兴趣,提升青少年科学素养,引导青少年投身创新发现和科研实践活动。https://www.iai.sh.cn/problem/744 题目描述 有一台自动售票机,每张票卖 …...

[方法] 《鸣潮》/《原神》呼出与锁定光标的功能细节
本方法适用于Cinemachine - FreeLook。 1. 锁定与呼出光标的功能实现 // 锁定光标 private void LockMouse() {// 将光标锁定在屏幕中间Cursor.lockState CursorLockMode.Locked;// 隐藏光标Cursor.visible false; }// 呼出光标 private void UnLockMouse() {// 释放光标Cu…...
计算机网络-NAT配置与ACL
目录 一、ACL 1、ACL概述 2、ACL的作用 3、ACL的分类 4、ACL的配置格式 二、NAT 1、NAT概述 2、NAT分类 2.1 、 静态NAT 2.2 、 动态NAT 3、NAT的功能 4、NAT的工作原理 三、NAT配置 1、静态NAT配置 2、动态NAT配置 四、总结 一、ACL 1、ACL概述 ACLÿ…...

哈尔滨三级等保测评需要测哪些设备?
哈尔滨三级等保测评需要测的设备,主要包括物理安全设备、网络安全设备和应用安全设备三大类别。这些设备在保障哈尔滨地区信息系统安全方面发挥着至关重要的作用。 首先,物理安全设备是确保信息系统实体安全的基础。在哈尔滨三级等保测评中,物…...
(华中科技大学) 中国大学MOOC答案2024版100分完整版)
大学体育(二)(华中科技大学) 中国大学MOOC答案2024版100分完整版
大学体育(二)(华中科技大学) 中国大学MOOC答案2024版100分完整版 有氧运动 有氧运动单元测验 1、 世界卫生组织对18-64岁年龄组成年人的运动建议是:每周至少( )分钟的中等强度有氧身体活动,或者每周至少&a…...

Web前端策划:从理念到实现的全方位解析
Web前端策划:从理念到实现的全方位解析 在数字化时代的浪潮中,Web前端策划作为连接技术与用户界面的桥梁,扮演着至关重要的角色。它涉及从用户需求分析、设计构思到技术实现的全方位过程,要求策划者具备深厚的技术功底和敏锐的市…...

经济与安全兼顾:茶饮店购买可燃气体报警器的价格考量
可燃气体报警器在如今的社会中扮演着至关重要的角色。它们用于检测环境中的可燃气体浓度,及早发现潜在的火灾隐患,保护人们的生命和财产安全。 在这篇文章中,佰德将介绍可燃气体报警器的安装、检定以及价格,通过实际案例和数据&a…...

鞠小云张霖浩闪耀北京广播电视台春晚发布会,豪门姐弟感爆棚
昨日,2025年北京广播电视台“追梦春晚”全国海选发布会在杭州举行,中国内地青年女演员鞠小云同人气幕后张霖浩,受主办方盛情邀请出席本次活动。从现场流露出的照片中可以看出,鞠小云一袭白色长裙灵动温婉素雅,而张霖浩…...

java Function 用法
**Function 接口是 Java 8 引入的一个核心函数式接口,用于表示一个接受单一输入参数并产生结果的函数**。Function 接口主要用在数据处理和转换操作中,如集合处理、流处理等场景。下面将深入探讨 Function 接口的用法: 1. **基本概念**&…...
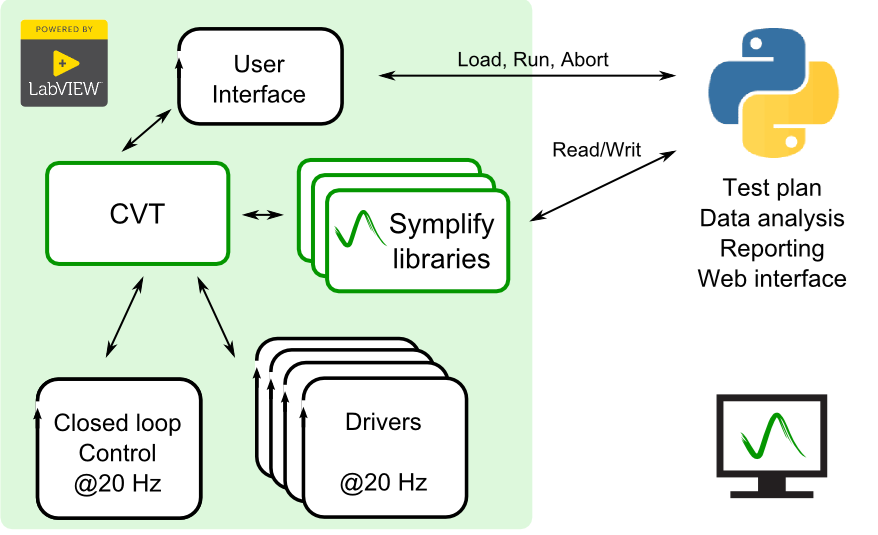
LabVIEW与Python的比较及联合开发
LabVIEW和Python在工业自动化和数据处理领域各具优势,联合开发可以充分发挥两者的优点。本文将从语言特性、开发效率、应用场景等多个角度进行比较,并详细介绍如何实现LabVIEW与Python的联合开发。 语言特性 LabVIEW 图形化编程:LabVIEW使用…...

RAG技术在教育领域的应用
一、引言 点击可以查看最新资源 随着人工智能技术的飞速发展,教育领域正迎来一场深刻的变革。大型语言模型(LLM)和检索增强生成(Retrieval-Augmented Generation,RAG)技术的结合,为教育领域注入…...

玉米粒计数检测数据集VOC+YOLO格式107张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):107 标注数量(xml文件个数):107 标注数量(txt文件个数):107 标注类别…...

成功解决IndexError: index 0 is out of bounds for axis 1 with size 0.
成功解决IndexError: index 0 is out of bounds for axis 1 with size 0. 🌈 欢迎莅临我的个人主页👈这里是我深耕Python编程、机器学习和自然语言处理(NLP)领域,并乐于分享知识与经验的小天地!Ἰ…...

spawnfile:轻量级进程编排工具,提升本地开发与测试效率
1. 项目概述:一个被低估的进程管理利器如果你在Linux或macOS环境下做过开发,尤其是需要频繁启动、停止、监控一堆后台服务(比如微服务架构下的多个组件),那你一定对进程管理工具不陌生。从最基础的nohup加&&#x…...
)
从协议到代码:用Python仿真5G NR下行同步全流程(含PBCH解码与MIB解析)
从协议到代码:用Python仿真5G NR下行同步全流程(含PBCH解码与MIB解析) 在通信系统设计中,下行同步是终端接入网络的第一步关键操作。5G新空口(NR)技术引入了更复杂的同步信号结构,这对算法工程师和研究人员提出了更高要…...

AI智能体开发工具栈全解析:从框架、可观测性到部署实战指南
1. 项目概述与核心价值如果你正在构建AI智能体应用,并且已经厌倦了在GitHub、Twitter和各种技术论坛里大海捞针般地寻找合适的开发工具,那么你很可能已经遇到了一个共同的痛点:生态碎片化。从让大语言模型(LLM)具备“记…...

为什么92%的数据分析师还没用上Gemini Sheets功能?—— 一份被谷歌官方忽略的AI分析落地清单
更多请点击: https://intelliparadigm.com 第一章:Gemini Sheets数据分析的现状与认知断层 Gemini Sheets 作为 Google Workspace 生态中新兴的 AI 增强型电子表格工具,正逐步替代传统 Sheets 的部分分析场景。然而,当前用户实践…...

Specky:规范驱动开发平台,从AI氛围编程到确定性工程实践
1. Specky:一个重新定义AI辅助开发的确定性工程平台如果你和我一样,在过去几年里深度使用过GitHub Copilot、Claude Code这类AI编程助手,你肯定经历过那种又爱又恨的矛盾感。爱的是,它们确实能快速生成代码片段,把我们…...
)
Midjourney水彩风提示词已进入“语义过载”危机?2024Q2最新精简指令集发布(仅保留11个高响应关键词,准确率提升63.8%)
更多请点击: https://intelliparadigm.com 第一章:Midjourney水彩风提示词的语义过载现象本质解析 水彩风格生成中,“watercolor”、“gouache”、“loose brushstrokes”、“wet-on-wet”等提示词常被叠加使用,表面增强风格表征…...

苹果W1芯片如何通过低功耗无线技术重塑TWS耳机体验
1. 无线音频的功耗困局与苹果的破局思路 2016年9月,当苹果在发布会上首次亮出那对剪掉线缆的AirPods时,整个消费电子行业都在问同一个问题:它是怎么做到的?更具体地说,它如何解决了无线耳机领域最核心、也最令人头疼的…...
)
ClaudeCode入门08-Git配合(小白入门:不知道怎么写Git提交记录?让AI自动帮你写好)
🎯 本文目标 学会用 Claude Code 自动化 Git 工作流:自动写 Commit Message、管理分支、处理冲突。 😰 Git 新手的痛点 git commit -m "fix" git commit -m "update" git commit -m "修改了一些东西" 不知道 Conventional Commits 是什么 …...

从“抄答案”到“会解题”:我是如何利用头歌实训平台,真正掌握Python数据分析的?
从“抄答案”到“会解题”:我的Python数据分析思维进阶之路 记得第一次打开头歌实训平台的Python数据分析题目时,我像大多数初学者一样,迫不及待地寻找"正确答案"。复制、粘贴、运行——看到绿色通过提示的瞬间,以为自己…...

新手也能看懂的SQL注入绕过实战:以BUUCTF的BabySQL靶场为例,手把手教你双写绕过
从零破解BabySQL:双写绕过的艺术与科学 当你第一次接触CTF比赛中的SQL注入题目时,那种既兴奋又困惑的感觉一定记忆犹新。面对BabySQL这样的靶场,新手常会遇到一个典型困境:明明知道应该用union select来获取数据,却发现…...