大数据领域的workload是什么意思?
什么是workload?
在大数据领域,"workload"指的是需要处理的数据集和对其执行的操作的组合。它描述了大数据系统需要执行的任务的类型和规模。
我们可以从以下几个维度来理解大数据领域的 workload:
数据的特征:
数据量
需要处理的数据量大小,通常以 TB、PB 甚至 ZB 来衡量。
数据速度
数据产生的速度,例如每秒钟产生的数据量,也称为数据吞吐量。
数据种类
数据的结构和类型,例如结构化数据、半结构化数据或非结构化数据。
数据质量
数据的准确性、完整性和一致性。
计算的特征:
计算类型:
需要对数据执行的操作类型,例如数据清洗、转换、聚合、分析、机器学习等。
计算复杂度
计算任务的复杂程度,例如简单的统计分析还是复杂的机器学习模型训练。
计算模式
批处理、流处理、交互式查询等。
性能需求
对数据处理速度、延迟、吞吐量等方面的要求。
常见的大数据 workload:
批处理 (Batch Processing)
处理大量静态数据,例如日志分析、数据仓库 ETL 等。这类 workload 通常数据量大,但对实时性要求不高。
流处理 (Stream Processing)
实时处理连续不断产生的数据流,例如实时监控、欺诈检测等。这类 workload 对实时性要求高,需要低延迟的处理能力。
交互式查询 (Interactive Query)
对大规模数据集进行快速查询和分析,例如商业智能、数据探索等。这类 workload 需要较低的查询延迟,以保证用户体验。
机器学习 (Machine Learning)
使用大规模数据集训练和部署机器学习模型,例如图像识别、自然语言处理等。这类 workload 通常需要大量的计算资源和较长的处理时间。
图处理 (Graph Processing)
处理图结构数据,例如社交网络分析、推荐系统等。这类 workload 需要专门的图计算引擎和算法。
了解workload有什么用?
了解不同类型的大数据 workload 对于选择合适的工具和技术至关重要。例如,Apache Hadoop Map/Reduce,Apache Beam,Apache Spark更适合批处理 workload,而 Apache Storm,Apache Flink 更适合流处理 workload。对于批处理,更进一步来看,Apache Map/Reduce每一次计算都会读写HDFS,这部分开销很大。而Apache Spark会将中间结果存入内存,加快运行效率,所以更适合机器学习,相应的对内存资源需求更大。而Apache Beam抽象的更 高级,API相对简单,是一个轻量级的框架。可以运行在Apache Spark或者Apache Flink中,但处理数据量不如Spark大,而且对于状态管理和容错机制相对简单,如果需要实现一个更可靠的,更稳定的系统,需要开发者自行实现相对应的功能。而容错这一点Apache Spark/Apache Flink做得会更好。
当总结出了自己业务数据的workload,再加上了解各个主流的大数据技术栈,可以更快速准确高效得选择出应当使用的技术栈。可以事半功倍的达成目标。
相关文章:

大数据领域的workload是什么意思?
什么是workload? 在大数据领域,"workload"指的是需要处理的数据集和对其执行的操作的组合。它描述了大数据系统需要执行的任务的类型和规模。 我们可以从以下几个维度来理解大数据领域的 workload: 数据的特征: 数据量 需要处…...

引入别人的安卓项目报错
buildscript { repositories { google() jcenter() } dependencies { classpath com.android.tools.build:gradle:4.1.0 // 使用最新版本的插件 } } allprojects { repositories { google() jcenter() } } 在…...
Python Excel 指定内容修改
需求描述 在处理Excel 自动化时,财务部门经常有一个繁琐的场景,需要读取分发的Excel文件内容复制到汇总Excel文件对应的单元格内,如下图所示: 这种需求可以延申为,财务同事制作一个模板,将模板发送给各员工,财务同事需收取邮件将员工填写的excel文件下载到本机,再类似…...

【力扣高频题】003.无重复字符的最长子串
前段时间和小米的某面试官聊天。因为我一直在做 算法文章 的更新,就多聊了几句算法方面的知识。 并且在聊天过程中获得了一个“重要情报”:只要他来面试,基本上每次的算法题,都会去考察关于 子串和子序列 的问题。 的确…...
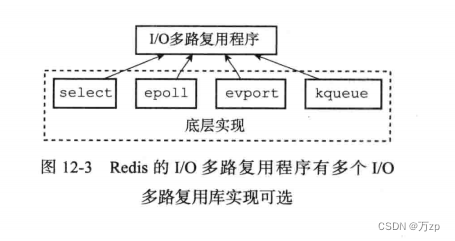
redis03 补充 事件
1.文件事件...

绿联Nas docker 中 redis 老访问失败的排查
部署了一些服务,老隔3-5 天其他服务就联不上 redis 了,未确定具体原因,只记录观察到的现象 宿主机访问 只有 ipv6 绑定了,ipv4 绑定挂掉了 其他容器访问 也无法访问成功 当重启容器后: 一切又恢复正常。 可能的解…...
Linux入门学习(2)
1.相关复习新的指令学习 (1)我们需要自己创建一个用户,这个用户前期可以是一个root用户,后期使用创建的普通用户 (2)文件等于文件内容加上文件属性,对于文件的操作就包括对于文件内容的操作和文件属性&…...

Spring boot开启跨域配置
Spring boot开启跨域配置 背景 跨域(Cross-Origin)是指在互联网上的一个域下的文档或脚本尝试请求另一个域下的资源时,域名、协议或端口不同的这种情况。具体来说,如果一个网页试图通过脚本(如JavaScript)…...

java面试题:hashCode的作用
在Java集合中,hashCode起着至关重要的作用,特别是在基于哈希的集合类如HashMap、HashSet和Hashtable中。以下是hashCode在集合中的主要作用: 快速查找和定位: hashCode被用作确定对象在哈希表中存储位置的索引(或称为“…...

从零开始精通Onvif之获取设备信息
💡 如果想阅读最新的文章,或者有技术问题需要交流和沟通,可搜索并关注微信公众号“希望睿智”。 与设备交互的第一步 发现设备之后,与设备进行交互的第一步,是连接上设备,并获取设备的信息。连接设备&#…...

FiRa标准UWB MAC实现(三)——距离如何获得?
继续前期FiRa MAC相关介绍,将FiRa UWB MAC层相关细节进一步进行剖析,介绍了UWB技术中最重要的一个点,高精度的距离是怎么获得的,具体使用的测距方法都有哪些,原理又是什么。为后续FiRa UWB MAC的实现进行铺垫。 3、测距方法 3.1 SS-TWR SS-TWR为Single-Sided Two-Way Ra…...

基于百度翻译API的火车头PHP翻译插件,可以翻译HTML片段
关于火车头的百度翻译插件,相信大家在火车头官网或网上都能找到相关代码,百度翻译插件是PHP写的,就一个PHP文件,简单灵活,不受火车头软件版本限制,任何有PHP插件权限的火车头版本都可以使用。但是百度API翻…...

mysql高级用法常用函数
mysql高级用法 1、自定义排序 select * from movies order by field(actors, 成龙, 靳东, 刘亦菲, 范冰冰); // 字段中存在null值 select * from movies order by field (coalesce(actors,null),成龙, 靳东, 刘亦菲, 范冰冰,null)2、空值NULL排序(ORDER BY IF(ISN…...

【打印100个常用Linux命令】
#!/bin/bash 定义一个函数,用于打印100个常用Linux命令 print_commands() { echo “以下是一些常用的Linux命令:” echo “----------------------------------” echo “1. pwd - 显示当前工作目录” echo “2. ls - 列出当前目录下的文件和文件夹” …...
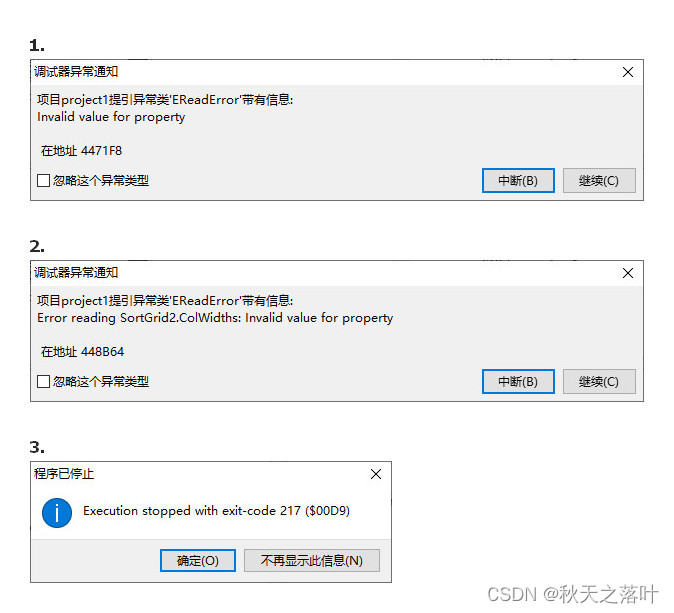
友情提示:lazarus的tsortgrid.autofillcolumns存在BUG
直接在tsortgrid的属性中设置autofillcolumns为true,会提示:123个错误。即使修改为false,编译运行照样会出现上述错误。唯一解决的办法就是删除sortgrid重新添加一个。 代码设置SortGrid1.AutoFillColumns : TRUE不受影响。...

github的个人readme文件
一个好的svg图: Simon-He95/profile-3d-contrib/profile-season-animate.svg at 4281d9f46e3d5416bd8f8cc5779157bfdaa8589d Simon-He95/Simon-He95 GitHub 请访问他的主页从提交记录就可以看到这个立体的登录github的图...

java面试题: HashMap、HashSet 和 HashTable 的区别
HashMap 常用方法 HashMap 是一个基于哈希表的 Map 接口的实现。它允许使用 null 值和 null 键。 java 复制 // 创建一个HashMap HashMap<KeyType, ValueType> map new HashMap<>(); // 添加元素 map.put(key, value); // 获取元素 ValueType value map.get…...
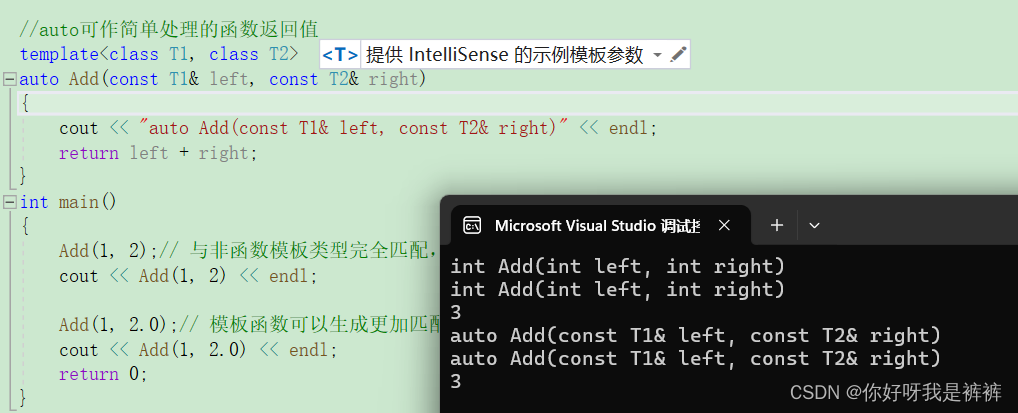
CPP初级:模板的运用!
目录 一.泛型编程 二.函数模板 1.函数模板概念 2.函数模板格式 3.函数模板的原理 三.函数模板的实例化 1.隐式实例化 2.显式实例化 3.模板参数的匹配原则 四.类模板 1.类模板的定义格式 2.类模板的实例化 一.泛型编程 泛型编程:编写与类型无关的通用代码…...

排序---基数排序
前言 个人小记 一、简介 基数排序是一种非比较排序,所以排序速度较快,当为32位int整数排序时,可以将数分为个位十位分别为2^16,使得拷贝只需要两轮,从而达到2*n,然后给一个偏移量,使得可以对负数排序。以…...
“新高考”下分班怎么分?
来自安徽的张女士告诉我:上一年孩子升入了高中,但没想到才高一,孩子就面临了一个困难的挑选:312”分班! 什么是312”分班呢?许多人或许不明白,便是要求学生在高一入学时,针对于3门必…...

终极PC游戏分屏解决方案:Universal Split Screen完全指南
终极PC游戏分屏解决方案:Universal Split Screen完全指南 【免费下载链接】UniversalSplitScreen Split screen multiplayer for any game with multiple keyboards, mice and controllers. 项目地址: https://gitcode.com/gh_mirrors/un/UniversalSplitScreen …...

3个技巧让你的技术文档阅读体验提升300%:Markdown Viewer深度指南
3个技巧让你的技术文档阅读体验提升300%:Markdown Viewer深度指南 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 还在为浏览器中那些丑陋的Markdown文件预览而烦恼吗…...
)
为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败?——2024最新L10n兼容性白皮书首发(附实测RTT延迟对比数据)
更多请点击: https://intelliparadigm.com 第一章:为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败? ElevenLabs 官方文档明确声明支持僧伽罗文(Sinhala),但实际部署中,斯里兰卡本地政…...

2026年阿里云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这
2026年阿里云部署OpenClaw/Hermes Agent 配置Token Plan怎么快速上手?看这。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token …...

终极指南:如何用MAA Assistant Arknights实现明日方舟全自动化
终极指南:如何用MAA Assistant Arknights实现明日方舟全自动化 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: htt…...

终极Citra 3DS模拟器完整指南:在电脑上免费畅玩任天堂3DS游戏
终极Citra 3DS模拟器完整指南:在电脑上免费畅玩任天堂3DS游戏 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/GitHub_Trending/ci/citra 想要在电脑上重温《精灵宝可梦》系列、《塞尔达传说》等经典3DS游戏吗?Ci…...

分享一些常见的SQL计算面试题
代码都是基于mysql实现,如果小伙伴们有其他的思路欢迎留言~ 1.行列转换2.分组求top-n3.连续登录问题(包括日期可间断和不可间断)4.找连续出现3次及以上的数字5.直播间同时在线人数统计1.行列转换 表tb1: 表tb2: 行转…...

Crustocean/conch:云原生容器化应用构建与部署的自动化工具箱
1. 项目概述与核心价值最近在折腾一个很有意思的项目,叫“Crustocean/conch”。光看这个名字,你可能觉得有点摸不着头脑,又是“甲壳海洋”又是“海螺”的。其实,这是一个非常典型的、由开发者社区驱动的开源项目命名风格ÿ…...

5分钟终极指南:永久免费使用Cursor Pro功能的完整解决方案
5分钟终极指南:永久免费使用Cursor Pro功能的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...
)
Midjourney V6树胶重铬酸盐输出崩溃?紧急修复指南(含--sref自定义光敏响应曲线参数实测数据)
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6树胶重铬酸盐输出崩溃现象与本质溯源 现象复现与触发条件 Midjourney V6 在启用 --style raw 且 prompt 中包含化学术语(如“重铬酸盐”、“树胶”、“potassium dichromate”…...