树的4种遍历
目录
树的四种遍历方式的总结
1. 前序遍历(Pre-order Traversal)
2. 中序遍历(In-order Traversal)
3. 后序遍历(Post-order Traversal)
4. 层序遍历(Level-order Traversal 或 广度优先遍历,Breadth-First Traversal)
以下是这四种遍历方式的C语言实现示例:
1. 定义二叉树节点
2. 前序遍历(根-左-右)
3. 中序遍历(左-根-右)
4. 后序遍历(左-右-根)
5. 层序遍历(广度优先遍历)
树的四种遍历方式的总结
树的四种遍历方式(前序遍历、中序遍历、后序遍历和层序遍历)是理解和操作二叉树的基础。以下是这四种遍历方式的总结:
1. 前序遍历(Pre-order Traversal)
访问顺序:根节点 -> 左子树 -> 右子树
递归实现简单直观,先访问根节点,然后递归遍历左子树,最后递归遍历右子树。
非递归实现通常使用栈来辅助遍历,先将根节点压栈,然后在循环中出栈并访问当前节点,接着将右子节点和左子节点依次压栈(注意顺序)。
2. 中序遍历(In-order Traversal)
访问顺序:左子树 -> 根节点 -> 右子树
在二叉搜索树中,中序遍历的结果是一个有序序列。
递归实现时,先递归遍历左子树,然后访问根节点,最后递归遍历右子树。
非递归实现同样使用栈,但需要标记节点来源(是否来自左子树)来确保先遍历左子树。
3. 后序遍历(Post-order Traversal)
访问顺序:左子树 -> 右子树 -> 根节点
递归实现简单,但非递归实现相对复杂。
非递归实现通常使用两个栈或结合栈和指针来追踪节点和它们的子节点,确保在访问根节点之前已经遍历了左右子树。
4. 层序遍历(Level-order Traversal 或 广度优先遍历,Breadth-First Traversal)
访问顺序:从上到下,从左到右(即按层次顺序)
使用队列来辅助实现,先将根节点入队,然后在循环中每次出队一个节点并访问,接着将其非空子节点依次入队(通常先左后右)。
层序遍历在二叉树的层次结构分析、图的广度优先搜索等场景中非常有用。
注意事项
递归实现简洁明了,但可能导致栈溢出,特别是在处理深度很大的树时。
非递归实现通常使用栈或队列等数据结构来辅助遍历,需要注意数据结构的正确操作和管理。
在遍历过程中,要时刻注意空指针的情况,避免访问空指针导致的程序崩溃。
根据不同的应用场景选择合适的遍历方式,例如在二叉搜索树中,中序遍历的结果是有序的,而在分析树的层次结构时,层序遍历更为直观。
以下是这四种遍历方式的C语言实现示例:
1. 定义二叉树节点
#include <stdio.h>
#include <stdlib.h>typedef struct TreeNode {int val;struct TreeNode *left;struct TreeNode *right;
} TreeNode;2. 前序遍历(根-左-右)
void preOrderTraversal(TreeNode* root) {if (root == NULL) return;printf("%d ", root->val);preOrderTraversal(root->left);preOrderTraversal(root->right);
}3. 中序遍历(左-根-右)
void inOrderTraversal(TreeNode* root) {if (root == NULL) return;inOrderTraversal(root->left);printf("%d ", root->val);inOrderTraversal(root->right);
}4. 后序遍历(左-右-根)
void postOrderTraversal(TreeNode* root) {if (root == NULL) return;postOrderTraversal(root->left);postOrderTraversal(root->right);printf("%d ", root->val);
}5. 层序遍历(广度优先遍历)
在C语言中实现二叉树的层序遍历(广度优先遍历)需要借助队列数据结构。由于C标准库没有直接提供队列,我们可以使用数组或链表配合指针来模拟队列的行为。以下是一个使用数组模拟队列实现层序遍历的示例:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
// 定义二叉树节点
typedef struct TreeNode {int val;struct TreeNode *left;struct TreeNode *right;
} TreeNode;// 创建一个新节点
TreeNode* createNode(int val) {TreeNode* newNode = (TreeNode*)malloc(sizeof(TreeNode));if (!newNode) {exit(EXIT_FAILURE);}newNode->val = val;newNode->left = NULL;newNode->right = NULL;return newNode;
}// 层序遍历(广度优先遍历)
void levelOrderTraversal(TreeNode* root) {if (root == NULL) return;// 创建一个队列TreeNode* queue[1000]; // 假设队列最大长度为1000int front = 0, rear = 0;// 将根节点入队queue[rear++] = root;while (front < rear) {// 出队一个节点TreeNode* node = queue[front++];printf("%d ", node->val);// 将左孩子和右孩子入队if (node->left) {queue[rear++] = node->left;}if (node->right) {queue[rear++] = node->right;}}
}int main() {// 创建一个简单的二叉树进行测试TreeNode* root = createNode(1);root->left = createNode(2);root->right = createNode(3);root->left->left = createNode(4);root->left->right = createNode(5);// 层序遍历二叉树levelOrderTraversal(root);// 清理内存(这里省略了详细的内存清理代码)return 0;
}
在上面的代码中,我们定义了一个固定大小的队列数组queue,以及两个指针front和rear来模拟队列的头部和尾部。需要注意的是,这里假设了队列的最大长度为1000,但在实际应用中,我们可能需要动态分配内存或使用链表来实现一个更灵活的队列。
在levelOrderTraversal函数中,我们首先将根节点入队,然后进入一个循环,直到队列为空。在每次循环中,我们出队一个节点并打印其值,然后将该节点的左孩子和右孩子(如果存在)入队。这样,我们就能按照层次顺序遍历整个二叉树。
注意:上面的层序遍历示例使用了C++的std::queue,因为C标准库并没有直接提供队列的数据结构。在纯C中,你需要自己实现一个队列或者使用数组来模拟队列。
在实际使用时,你可以根据需要选择适合的遍历方式。
相关文章:

树的4种遍历
目录 树的四种遍历方式的总结 1. 前序遍历(Pre-order Traversal) 2. 中序遍历(In-order Traversal) 3. 后序遍历(Post-order Traversal) 4. 层序遍历(Level-order Traversal 或 广度优先遍…...

深入探讨5种单例模式
文章目录 一、对比总览详细解释 二、代码1. 饿汉式2. 饱汉式3. 饱汉式-双检锁4. 静态内部类5. 枚举单例 三、性能对比 一、对比总览 以下是不同单例模式实现方式的特性对比表格。表格从线程安全性、延迟加载、实现复杂度、反序列化安全性、防反射攻击性等多个方面进行考量。 …...

SPOOL
-----How to Pass UNIX Variable to SPOOL Command (Doc ID 1029440.6) setenv只有csh才有不行啊PROBLEM DESCRIPTION: You would like to put a file name in Unix and have SQL*Plus read that file name, instead of hardcoding it, because it will change.You want to pa…...

挑战绝对不可能:再证有长度不同的射线
黄小宁 一空间坐标系中有公共汽车A,A中各座位到司机处的距离h是随着座位的不同而不同的变数,例如5号座位到司机处的距离是h3,…h5,…。A移动了一段距离变为汽车B≌A,B中5号座位到司机处的距离h’h3,…h’h5…...

【机器学习】Python与深度学习的完美结合——深度学习在医学影像诊断中的惊人表现
🔥 个人主页:空白诗 文章目录 一、引言二、深度学习在医学影像诊断中的突破1. 技术原理2. 实际应用3. 性能表现 三、深度学习在医学影像诊断中的惊人表现1. 提高疾病诊断准确率2. 辅助制定治疗方案 四、深度学习对医疗行业的影响和推动作用 一、引言 随着…...
MapStruct的用法总结及示例
MapStruct是一个代码生成器,它基于约定优于配置的原则,使用Java注解来简化从源对象到目标对象的映射过程。它主要用于减少样板代码,提高开发效率,并且通过编译时代码生成来保证性能。 我的个人实践方面是在2021年前那时候在项目中…...

redis 05 复制 ,哨兵
01.redis的复制功能,使用命令slaveof 2. 2.1 2.2 3. 3.1 3.1.1 3.1.2 3.1.3 4 4.1 4.2 例子 5.1 这里是从客户端发出的指令 5.2 套接字就是socket 这里是和redis事件相关的知识 5.3 ping一下...

强大的.NET的word模版引擎NVeloDocx
在Javer的世界里,存在了一些看起来还不错的模版引擎,比如poi-tl看起来就很不错,但是那是人家Javer们专属的,与我们.Neter关系不大。.NET的世界里Word模版引擎完全是一个空白。 很多人不得不采用使用Word XML结合其他的模版引擎来…...
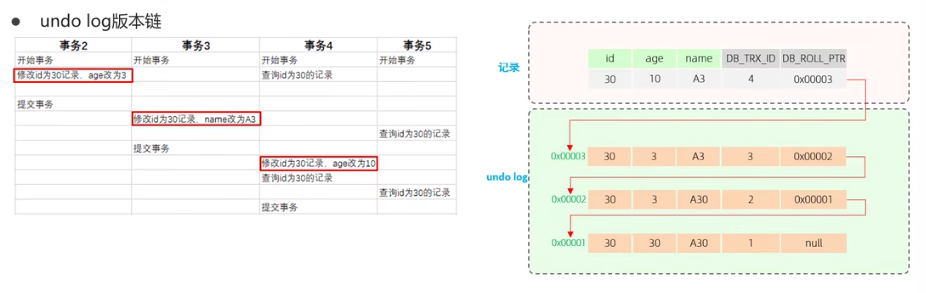
MySQL中所有常见知识点汇总
存储引擎 这一张是关于整个存储引擎的汇总知识了。 MySQL体系结构 这里是MySQL的体系结构图: 一般将MySQL分为server层和存储引擎两个部分。 其实MySQL体系结构主要分为下面这几个部分: 连接器:负责跟客户端建立连 接、获取权限、维持和管理…...
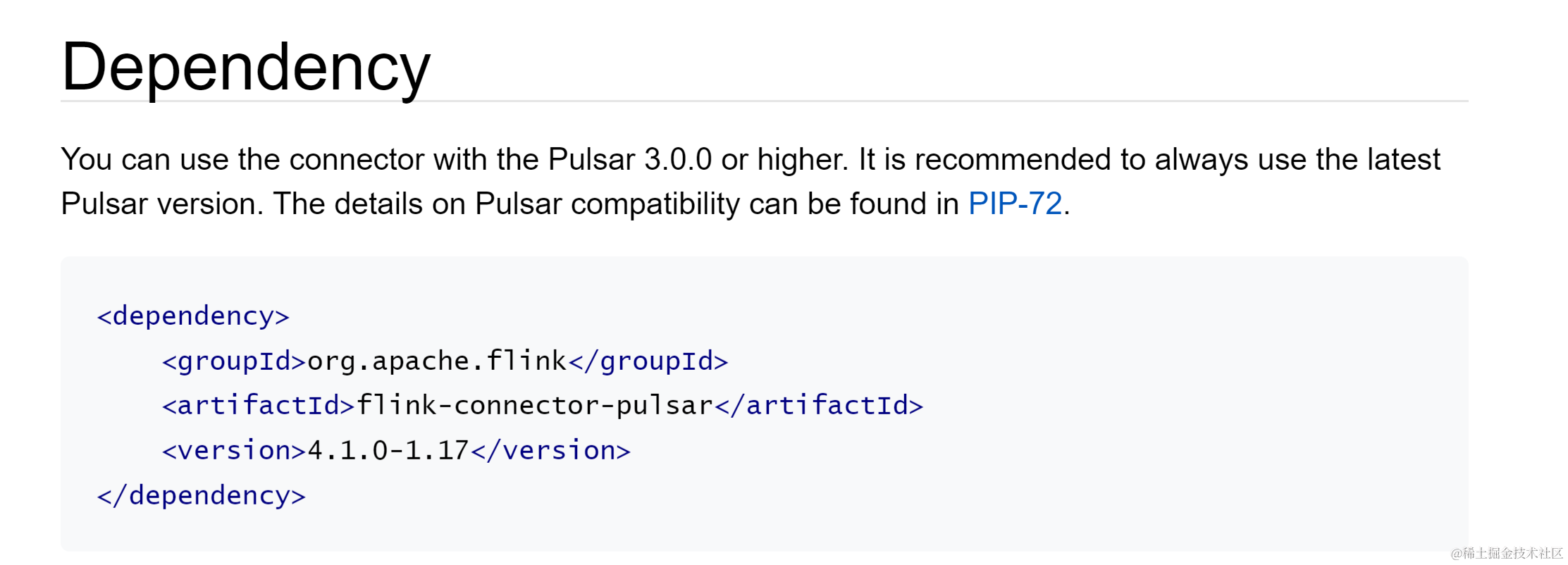
Flink 基于 TDMQ Apache Pulsar 的离线场景使用实践
背景 Apache Flink 是一个开源的流处理和批处理框架,具有高吞吐量、低延迟的流式引擎,支持事件时间处理和状态管理,以及确保在机器故障时的容错性和一次性语义。Flink 的核心是一个分布式流数据处理引擎,支持 Java、Scala、Pytho…...
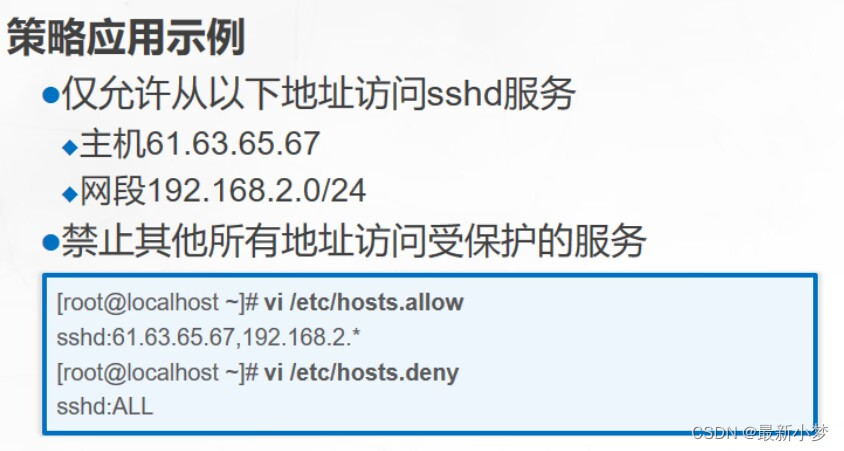
远程访问及控制
SSH协议 是一种安全通道协议 对通信数据进行了加密处理,用于远程管理 OpenSSH(SSH由OpenSSH提供) 服务名称:sshd 服务端控制程序: /usr/sbin/sshd 服务端配置文件: /etc/ssh/sshd_config ssh存放的客户端的配置文件 ssh是服务端额…...

【代码随想录训练营】【Day 44】【动态规划-4】| 卡码 46, Leetcode 416
【代码随想录训练营】【Day 44】【动态规划-4】| 卡码 46, Leetcode 416 需强化知识点 背包理论知识 题目 卡码 46. 携带研究材料 01 背包理论基础01 背包理论基础(滚动数组)01 背包 二维版本:dp[i][j] 表示从下标为[0-i]的物…...

html5实现个人网站源码
文章目录 1.设计来源1.1 网站首页页面1.2 个人工具页面1.3 个人日志页面1.4 个人相册页面1.5 给我留言页面 2.效果和源码2.1 动态效果2.2 目录结构 源码下载 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/139564407 ht…...

【内存管理】内存布局
ARM32位系统的内存布局图 32位操作系统的内存布局很经典,很多书籍都是以32位系统为例子去讲解的。32位的系统可访问的地址空间为4GB,用户空间为1GB ~ 3GB,内核空间为3GB ~ 4GB。 为什么要划分为用户空间和内核空间呢? 一般处理器…...

软件试运行方案(Word)
软件试运行方案(直接套用实际项目,原件获取通过本文末个人名片直接获取。) 一、试运行目的 二、试运行的准备 三、试运行时间 四、试运行制度 五、试运行具体内容与要求...
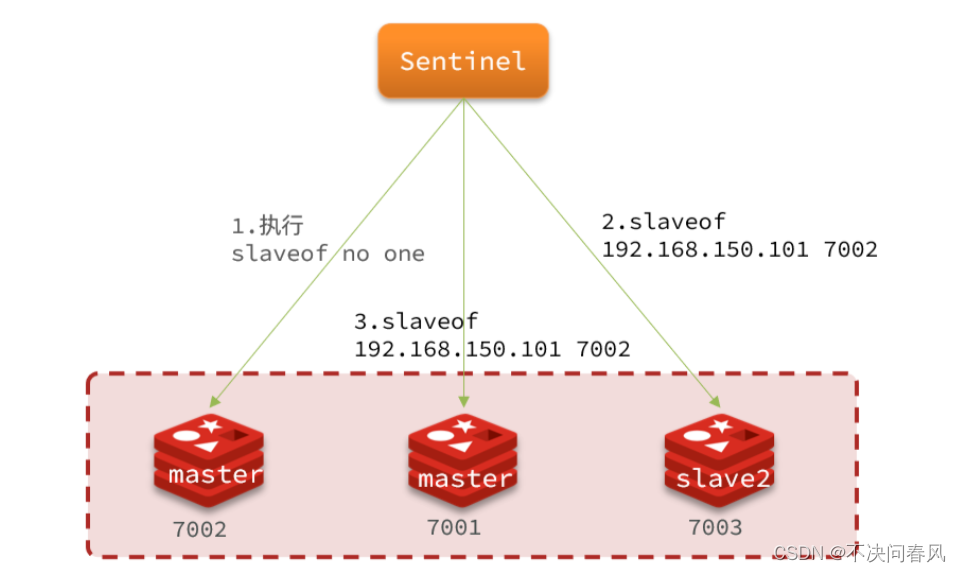
Redis原理篇——哨兵机制
Redis原理篇——哨兵机制 1.Redis哨兵2.哨兵工作原理2.1.哨兵作用2.2.状态监控2.3.选举leader2.4.failover 1.Redis哨兵 主从结构中master节点的作用非常重要,一旦故障就会导致集群不可用。那么有什么办法能保证主从集群的高可用性呢? 2.哨兵工作原理 …...

web前端的MySQL:跨领域之旅的探索与困惑
web前端的MySQL:跨领域之旅的探索与困惑 在数字化浪潮的推动下,web前端与MySQL数据库似乎成为了两个不可或缺的领域。然而,当我们将这两者放在一起,尝试探索web前端与MySQL之间的交互与关联时,却发现这是一次充满困惑…...
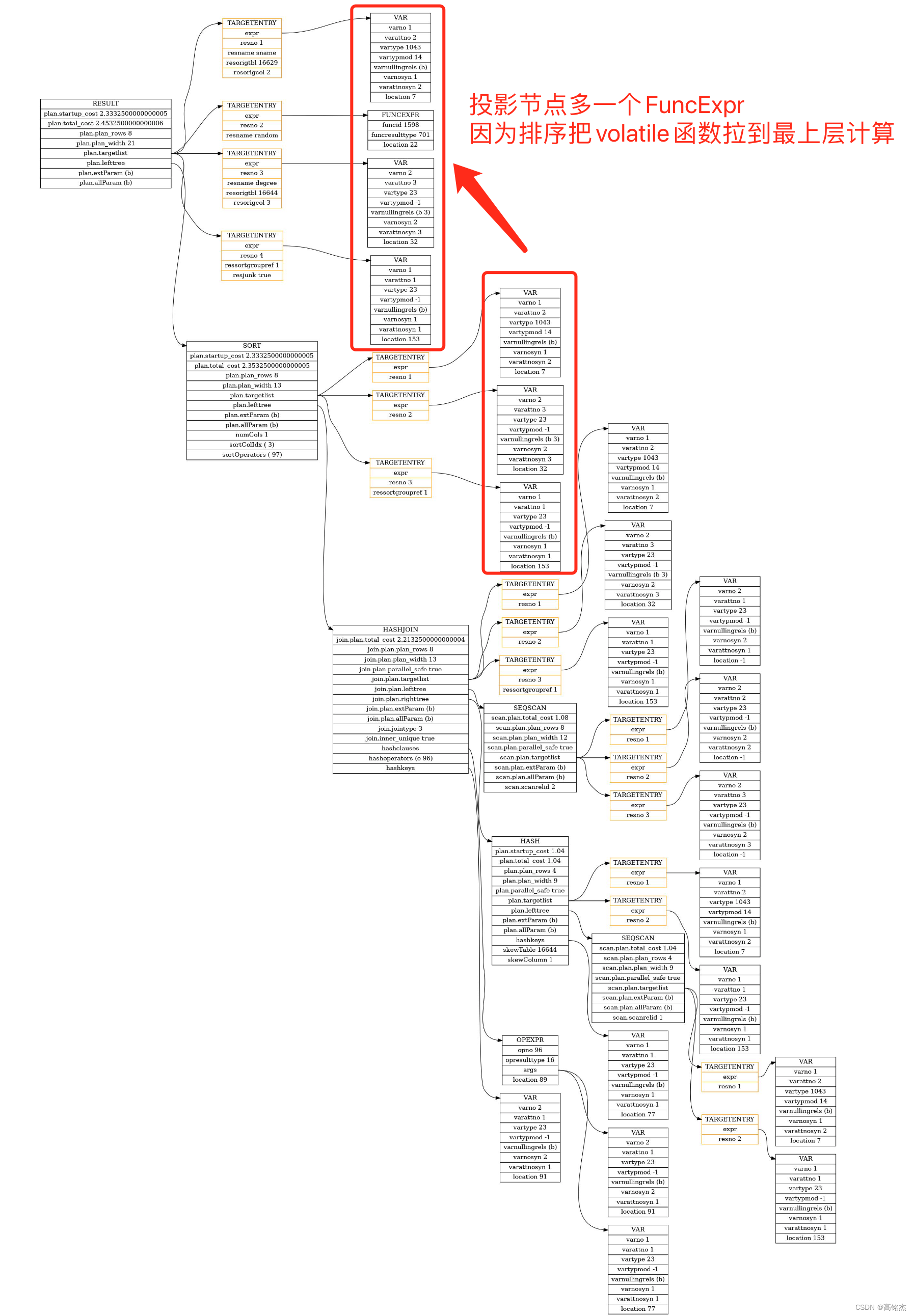
Postgresql源码(135)生成执行计划——Var的调整set_plan_references
1 总结 set_plan_references主要有两个功能: 拉平:生成拉平后的RTE列表(add_rtes_to_flat_rtable)。调整:调整前每一层计划中varno的引用都是相对于本层RTE的偏移量。放在一个整体计划后,需要指向一个统一…...

Python魔法之旅专栏(导航)
目录 推荐阅读 1、Python筑基之旅 2、Python函数之旅 3、Python算法之旅 4、博客个人主页 首先,感谢老铁们一直以来对我的支持与厚爱,让我能坚持把Python魔法方法专栏更新完毕! 其次,为了方便大家查阅,我将此专栏…...
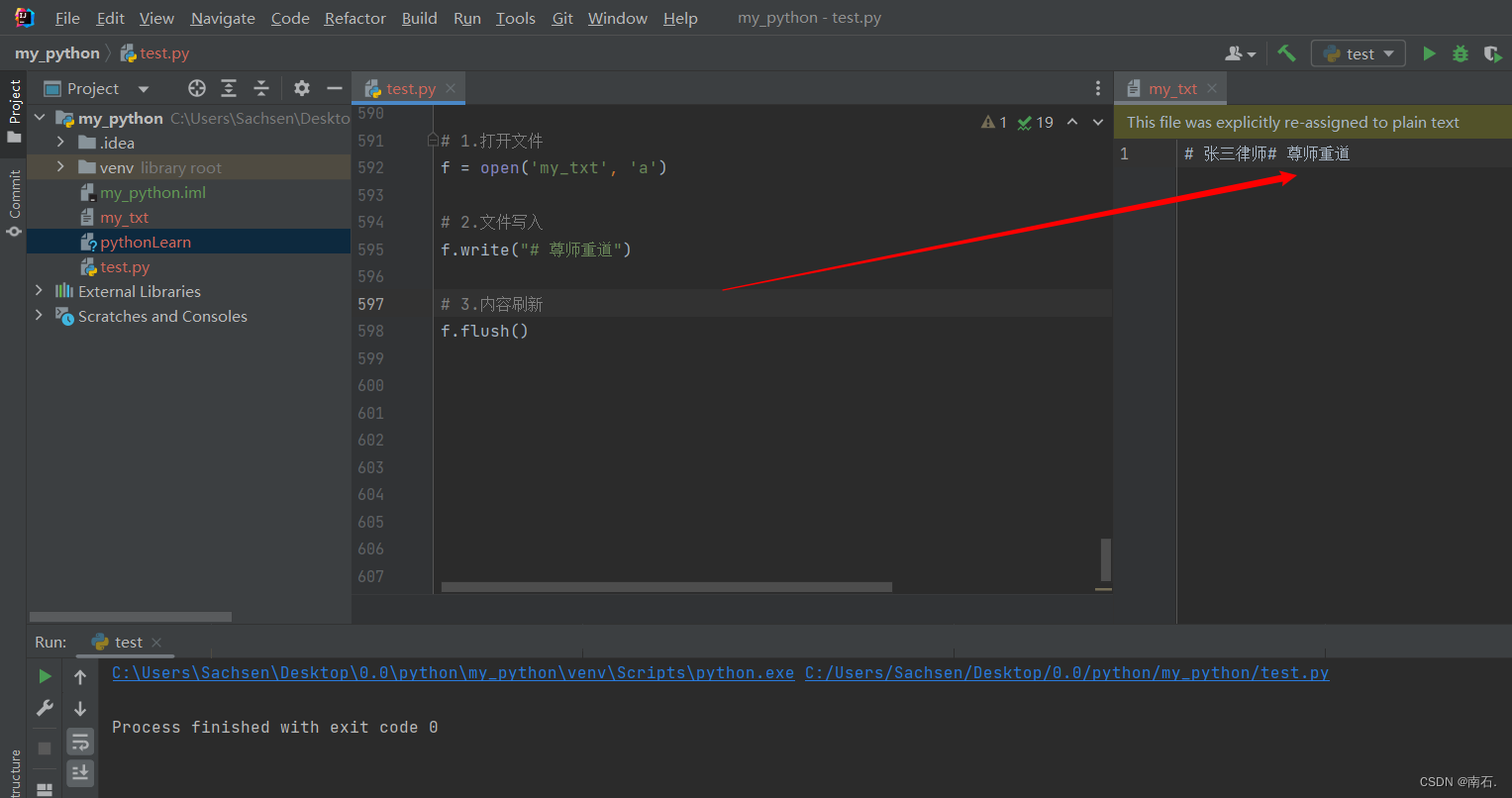
Python第二语言(五、Python文件相关操作)
目录 1. 文件编码的概念 2. 文件的读取操作 2.1 什么是文件 2.2 open()打开函数 2.3 mode常用的三种基础访问模式 2.4 文件操作及案例 3. 文件的写入操作及刷新文件:write与flush 4. 文件的追加操作 5. 文件操作的综合案例(文件备份操作&#x…...

Win11Debloat终极指南:如何轻松优化Windows 11系统性能
Win11Debloat终极指南:如何轻松优化Windows 11系统性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and c…...

终极PC游戏分屏解决方案:Universal Split Screen完全指南
终极PC游戏分屏解决方案:Universal Split Screen完全指南 【免费下载链接】UniversalSplitScreen Split screen multiplayer for any game with multiple keyboards, mice and controllers. 项目地址: https://gitcode.com/gh_mirrors/un/UniversalSplitScreen …...

保姆级教程:用R的ggstatsplot包,一键生成带统计检验的SCI级小提琴图
科研绘图革命:用ggstatsplot一键生成统计检验小提琴图的终极指南 在生物医学和生物信息学研究中,数据可视化与统计分析是论文写作中不可或缺的环节。传统流程中,研究者需要先进行统计检验,再将结果手动添加到图表中,这…...

VTube Studio API架构解析:构建下一代虚拟主播交互生态的核心技术
VTube Studio API架构解析:构建下一代虚拟主播交互生态的核心技术 【免费下载链接】VTubeStudio VTube Studio API Development Page 项目地址: https://gitcode.com/gh_mirrors/vt/VTubeStudio 探索虚拟主播技术生态的核心构建模块,VTube Studio…...

三步搞定Switch破解:大气层系统完整安装与配置指南
三步搞定Switch破解:大气层系统完整安装与配置指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 大气层(Atmosphere)系统是当前最稳定、最安全的Ninte…...

Taotoken用量看板如何帮助团队精细化管控大模型成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队精细化管控大模型成本 对于团队技术负责人或项目管理者而言,大模型API的调用成本正成为一…...

2025届毕业生推荐的六大AI辅助论文方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当人工智能技术广泛渗透开来,它于各行各业的应用在持续深入发展。在自动化客服方…...

从HelloWorld到第一个APK:用Android Studio 2022.3.1完整走一遍Android应用发布流程
从HelloWorld到第一个APK:Android Studio 2022.3.1全流程实战指南 当你第一次打开Android Studio,看到那只呆萌的长颈鹿图标时,可能既兴奋又迷茫。兴奋的是终于要开始Android开发之旅了,迷茫的是安装完成后该从哪里入手。本文将带…...
3个步骤让你的外文漫画秒变中文:BallonsTranslator零门槛入门指南
3个步骤让你的外文漫画秒变中文:BallonsTranslator零门槛入门指南 【免费下载链接】BallonsTranslator 深度学习辅助漫画翻译工具, 支持一键机翻和简单的图像/文本编辑 | Yet another computer-aided comic/manga translation tool powered by deeplearning 项目地…...

ChanlunX缠论插件:5分钟实现通达信专业缠论分析的完整指南
ChanlunX缠论插件:5分钟实现通达信专业缠论分析的完整指南 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX ChanlunX缠论插件是一款专为通达信用户设计的智能缠论分析工具,它通过DL…...