【Linux网络】传输层协议 - UDP
文章目录
- 一、传输层(运输层)
- 运输层的特点
- 复用和分用
- 再谈端口号
- 端口号范围划分
- 认识知名端口号(Well-Know Port Number)
- 两个问题
- ① 一个进程是否可以绑定多个端口号?
- ② 一个端口号是否可以被多个进程绑定?
- netstat命令
- pidof命令
- 二、UDP协议
- UDP协议格式
- 理解报头
- UDP的特点
- 面向数据报
- UDP的缓冲区
- ① 为什么UDP只有接收缓冲区,而没有发送缓冲区?
- ② 如何理解缓冲区?
- 操作系统中的缓冲区管理
- UDP使用的注意事项
- 基于UDP的应用层协议
一、传输层(运输层)
运输层的特点
运输层向它上面的应用层提供通信服务
我们知道,IP协议能够把源主机A发送出的分组,按照首部中的目的地址,送交到目的主机B。
都已经送到目标主机了,为什么还需要运输层呢?对IP层来说,通信的两端是两台主机。IP数据报的首部明确地标志了这两台主机的IP地址。但“两台主机之间的通信”这种说法还不够明确。真正进行通信的实体是在主机中的哪个构件呢?是主机中的应用进程,是一台主机中的应用进程和另一台主机中的应用进程在交换数据。
因此严格地讲,两台主机进行网络通信的本质是两台主机中的应用的进程之间互相通信,端到端的通信是应用进程之间的通信。IP协议虽然能把分组送到目的主机,但是这个分组还停留在主机的网络层而没有交付主机中的应用进程。也就是说,网络层的IP协议只是解决了数据包从哪台主机发送到哪台主机,而并没有具体指出是从哪个进程到哪个进程。而运输层做的工作正是负责将数据从发送端进程传输到接收端的进程。
一句话总结:
网络层为主机之间的通信提供服务,而运输层则在网络层的基础上,为应用进程之间的通信提供服务。
我们还应指出,运输层向高层用户屏蔽了下面网络核心的细节(如网络拓扑、所采用的路由选择协议等),它使应用进程看见的就是好像在两个运输层实体之间有一条端到端的逻辑通信信道,但这条逻辑通信信道对上层的表现却因运输层使用的不同协议而有很大的差别: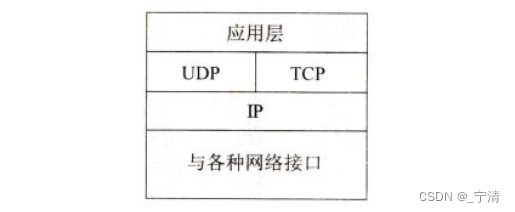
- 当运输层采用面向连接的TCP协议时,尽管下面的网络是不可靠的(只提供尽最大努力服务),但这种逻辑通信信道就相当于一条全双工的可靠信道:
- 但当运输层采用无连接的UDP协议时,这种逻辑通信信道仍然是一条不可靠信道。
复用和分用
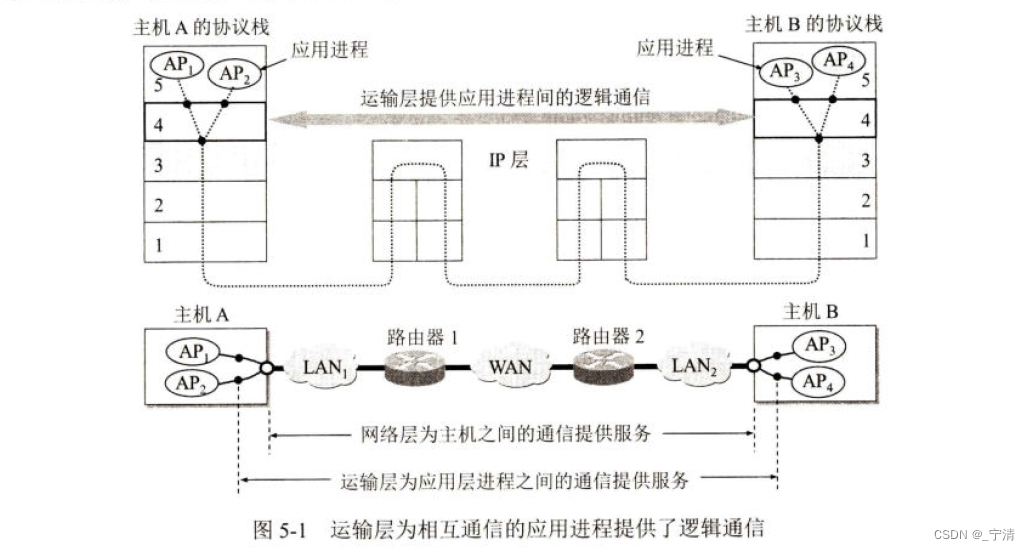
在一台主机中经常有多个应用进程同时分别和另一台主机中的多个应用进程通信。例如,某用户在使用浏览器查找某网站的信息时,其主机的应用层运行浏览器客户进程。如果在浏览网页的同时,还要用电子邮件给网站发送反馈意见,那么主机的应用层就还要运行电子邮件的客户进程。在图5-1中,主机A的应用进程AP1和主机B的应用进程AP3通信,而与此同时,应用进程AP2也和对方的应用进程AP4通信。
这表明运输层有两个个很重要的功能:
- 复用(multiplexing)
- 分用(demultiplexing)
这里的“复用”是指在发送方不同的应用进程都可以使用同一个运输层协议传送数据(当然需要加上适当的首部),而“分用”是指接收方的运输层在剥去报文的首部后能够把这些数据正确交付目的应用进程。
图5-1中两个运输层之间有一个深色双向粗箭头,写明“运输层提供应用进程间的逻辑通信”。“逻辑通信”的意思是:从应用层来看,只要把应用层报文交给下面的运输层,运输层就可以把这报文传送到对方的运输层,好像这种通信就是沿水平方向直接传送数据(因为传输层帮它屏蔽了底层的通信细节)。但事实上这两个运输层之间并没有一条水平方向的物理连接。数据的传送是沿着图中的虚线方向(经过多个层次)传送的。
再谈端口号
端口号(Port)标识了一个主机上进行通信的不同的应用程序
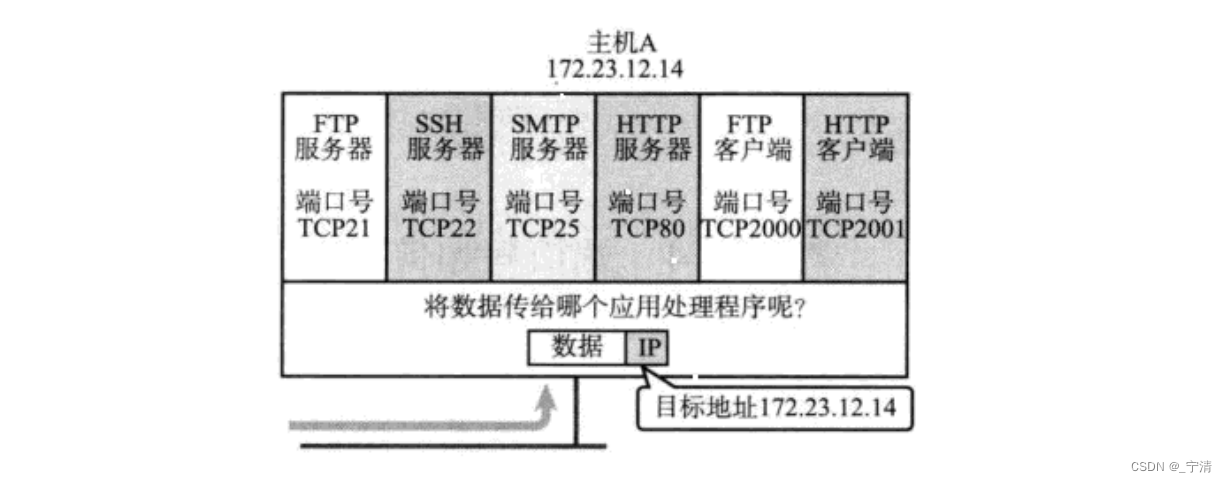
在TCP/IP协议中,用“源IP地址”,“源端口号”,“目的IP地址”,“目的端口号”,“协议号”这样一个五元组来标识一个通信。因为网络通信的本质是网络中的两个进程在通信,用一组IP地址唯一标识两台主机,用一组端口号就可以唯一标识两台主机上各自的一个进程了。
比如有多台客户端主机同时访问服务器,这些客户端主机上可能有一个客户端进程,也可能有多个客户端进程,它们都在访问同一台服务器: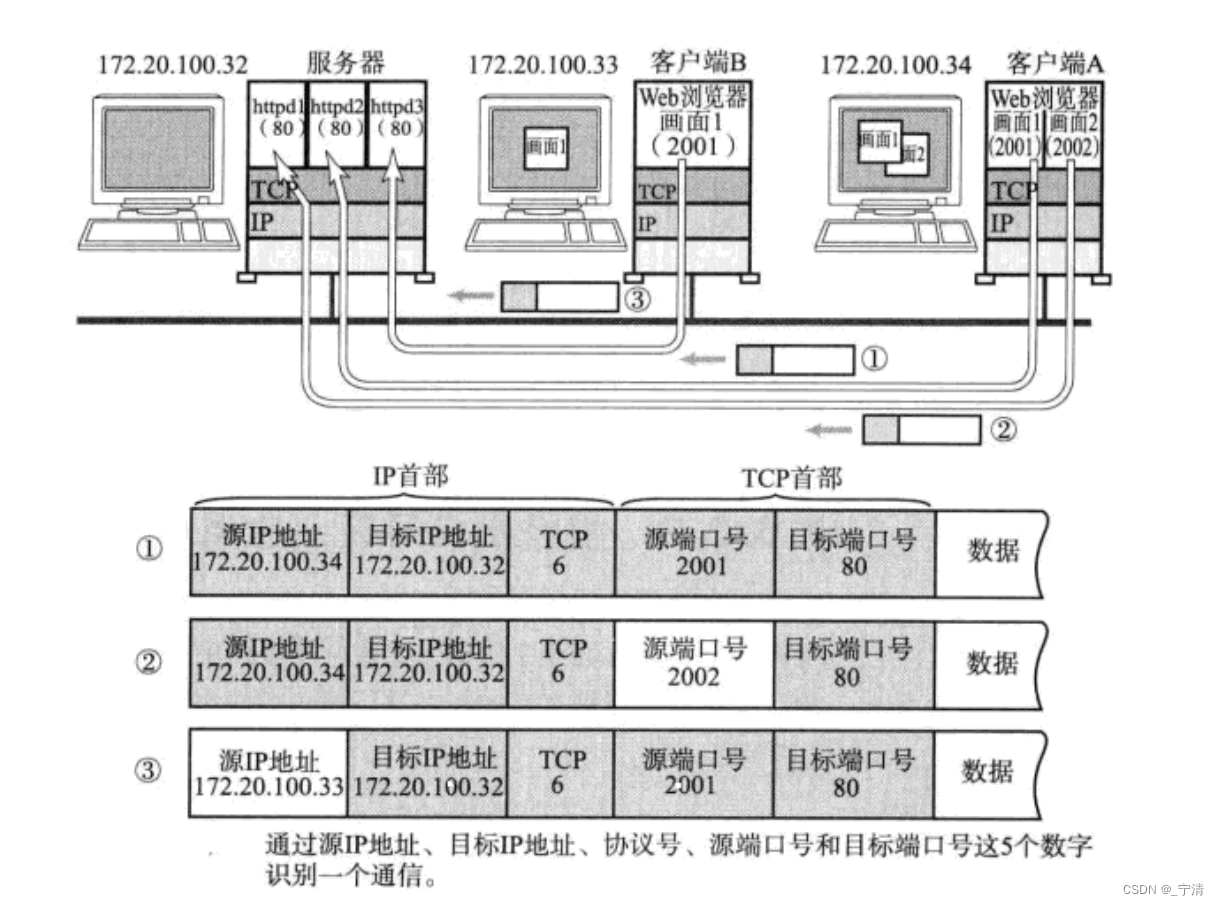
通过netstat命令可以查看到这样的五元组信息:
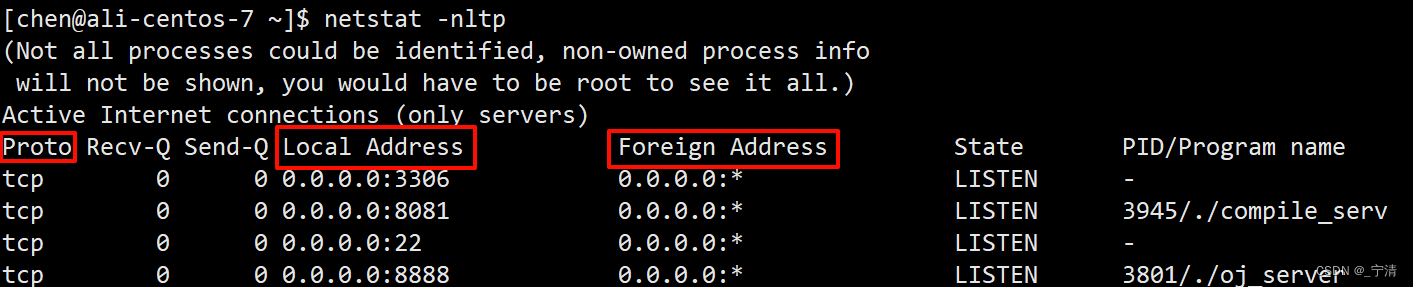
在 netstat -nltp 命令的输出中,“Local Address” 和 “Foreign Address” 列分别表示本地地址和远程地址。
- Local Address 中的
0.0.0.0:服务器在所有本地网络接口上监听指定端口。 - Foreign Address 中的
0.0.0.0和*:服务器可以接受来自任何远程地址和端口的连接。
端口号范围划分
端口号的长度是16位,因此端口号的范围是0 ~ 65535:
- 0 ~ 1023:知名端口号。比如HTTP,FTP,SSH等这些广为使用的应用层协议,它们的端口号都是固定的。
- 1024 ~ 65535:操作系统动态分配的端口号。客户端程序的端口号就是由操作系统从这个范围分配的。
认识知名端口号(Well-Know Port Number)
有些服务器是非常常用的,为了使用方便,人们约定一些常用的服务器,都是用以下这些固定的端口号:
| 服务 | 协议 | 端口号 |
|---|---|---|
| SSH | TCP | 22 |
| FTP | TCP | 21 |
| Telnet | TCP | 23 |
| HTTP | TCP | 80 |
| HTTPS | TCP | 443 |
下面的路径,可以看到知名端口号:
/etc/services
我们自己写一个程序使用端口号时,要避开这些知名端口号。
两个问题
① 一个进程是否可以绑定多个端口号?
是的,一个进程可以绑定多个端口号。通常情况下,这可以通过创建多个套接字(socket)并分别绑定到不同的端口来实现。以下是实现这个功能的一种常见方法:
- 创建多个套接字: 每个套接字绑定到不同的端口。
- 在每个套接字上监听连接: 进程可以在多个端口上监听传入的连接。
例如,一个 HTTP 服务器可以同时监听 80 端口和 8080 端口。
② 一个端口号是否可以被多个进程绑定?
通常情况下,一个端口号不能被多个进程同时绑定。如果一个进程已经绑定了一个特定端口号,其他进程将无法再绑定同一个端口号,这会导致 Address already in use 错误。这是为了防止端口冲突和数据包混乱。
但是,有一些特例和高级配置可以允许这种情况:
- SO_REUSEADDR 选项: 在某些情况下,两个进程可以设置
SO_REUSEADDR套接字选项,这允许在某些条件下重新使用同一端口。例如,两个进程在一个端口上同时监听 UDP 数据报(datagram)。 - 端口复用: 在某些负载均衡器和代理服务器的情况下,可以配置端口复用,以便多个进程处理同一端口上的流量,但这通常由一个主进程管理。
总结
- 一个进程可以绑定多个端口号。
- 一个端口号通常不能被多个进程同时绑定,但在某些特例和高级配置下,可以实现端口复用。
这种设计是为了保证网络通信的稳定和数据传输的明确性。
netstat命令
netstat是一个用来查看网络状态的重要工具。
语法:netstat [选项]
功能:查看网络状态
常用选项:
- n 拒绝显示别名,能显示数字的全部转化成数字
- l 仅列出有在 Listen (监听) 的服務状态
- p 显示建立相关链接的程序名
- t (tcp)仅显示tcp相关选项
- u (udp)仅显示udp相关选项
- a (all)显示所有选项,默认不显示LISTEN相关
pidof命令
在查看服务器的进程id时非常方便。
语法:pidof [进程名]
功能:通过进程名,查看进程id
比如我们可以查看自己写的服务器,通过进程的名称查询pid,进程名称就是可执行程序的名称:
二、UDP协议
UDP协议格式
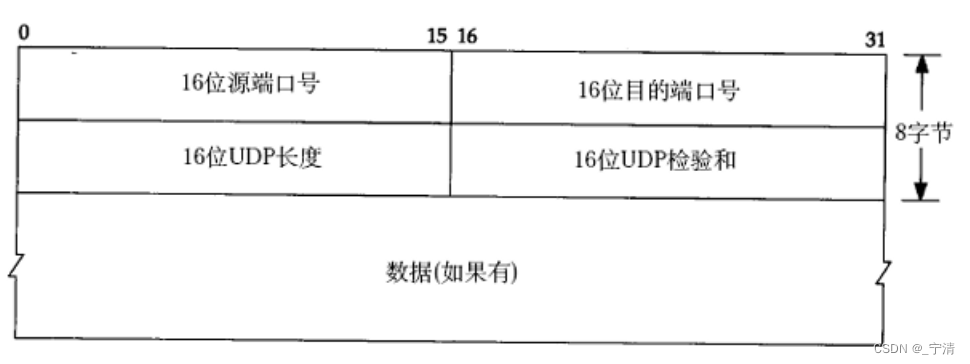
- 16位源端口号:表示数据从哪里来。
- 16位目的端口号:表示数据要到哪里去。
- 16位UDP长度:表示整个数据报(UDP首部+UDP数据)的长度。
- 16位UDP检验和:如果UDP报文的检验和出错,就会直接将报文丢弃。
UDP如何将报头与有效载荷进行分离?
UDP的报头当中只包含四个字段,每个字段的长度都是16位,总共8字节。因此UDP采用的实际上是一种定长报头,UDP在读取报文时读取完前8个字节后剩下的就都是有效载荷了。
UDP如何决定将有效载荷交付给上层的哪一个协议?
UDP上层也有很多应用层协议,因此UDP必须想办法将有效载荷交给对应的上层协议,也就是交给应用层对应的进程。内核中用哈希的方式维护了端口号与进程ID之间的映射关系,因此传输层可以通过端口号快速找到其对应的进程ID,进而找到对应的应用层进程。
理解报头
如何理解UDP的报头呢?
Linux操作系统是C语言写的,而UDP协议又是属于内核协议栈的,因此UDP协议也一定是用C语言编写的,UDP报头实际就是一个C语言位段类型(或使用短整型):
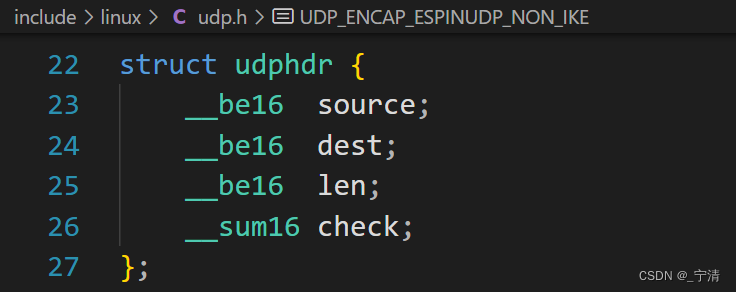
展开就是:
struct udphdr {unsigned short source; //源端口号unsigned short dest; //目的端口unsigned short len; //UDP长度unsigned short check; //检验和
};
复习一下C语言结构体中的位段(Bit-Fields)
位段是结构体的一部分,它允许我们在结构体中定义和访问比普通数据类型更小的位。位段通常用于需要直接访问特定位的场景,例如硬件寄存器编程、协议解析等。
位段不是一种独立的类型,而是结构体成员的一种特殊声明方式。
定义位段
位段在结构体中定义,语法如下:
struct {unsigned int field_name : bit_width; };
unsigned int或signed int:位段的类型(通常为无符号整型)。field_name:位段的名称。bit_width:位段的位宽,指定该字段占用的位数。
示例
下面是一个简单的例子,演示如何定义和使用位段:
#include <stdio.h>struct {unsigned int a : 3; // 3 bits for aunsigned int b : 5; // 5 bits for bunsigned int c : 8; // 8 bits for c } myBitField;int main() {myBitField.a = 5;myBitField.b = 17;myBitField.c = 255;printf("a: %u\n", myBitField.a);printf("b: %u\n", myBitField.b);printf("c: %u\n", myBitField.c);return 0; }在这个示例中,结构体包含三个位段:
a、b和c。位段a占用3位,b占用5位,c占用8位。输出结果如下:a: 5 b: 17 c: 255
注意事项
位段的总宽度和对齐:位段的总宽度不能超过结构体成员的类型宽度。如果需要跨越边界,编译器可能会插入填充位。位段的对齐也需要注意,不同编译器的行为可能不同。
可移植性:由于位段的对齐和填充方式依赖于编译器,因此不同编译器之间的位段布局可能不同,位段结构体在不同平台上的可移植性较差。
使用位段的类型:尽量使用无符号类型,因为有符号类型的行为可能不明确,尤其是在跨平台使用时。
位段的访问和操作:由于位段通常需要用来操作具体的位,因此直接操作其值时需要注意位操作的基本原理。
总结
位段是C语言中一种强大的工具,可以高效地管理和操作小于标准数据类型宽度的数据。正确使用位段可以显著提高程序的性能和可读性,但同时也需要注意跨平台的兼容性和编译器的实现细节。
UDP的特点
-
无连接:知道对端的IP和端口号就直接进行传输,不需要建立连接,因此减少了开销和发送数据之前的时延。
-
尽最大努力交付:即不保证可靠交付,因此主机不需要维持复杂的连接状态表,没有确认机制,没有重传机制;如果因为网络故障该段无法发到对方,UDP协议层也不会给应用层返回任何错误信息。
-
面向数据报:不能够灵活的控制读写数据的次数和数量。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。这就是说,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文,如图5-3所示。
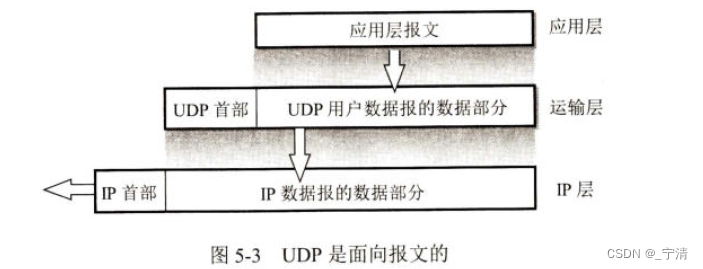
在接收方的UDP,对IP层交上来的UDP用户数据报,在去除首部后就原封不动地交付上层的应用进程。也就是说,UDP一次交付一个完整的报文。因此,应用程序必须选择合适大小的报文:- 若报文太长,UDP把它交给IP层后,IP层在传送时可能要进行分片,这会降低IP层的效率。
- 若报文太短,UDP把它交给IP层后,会使IP数据报的首部的相对长度太大,这也降低了IP层的效率。
-
UDP没有拥塞控制,因此网络出现的拥塞不会使源主机的发送速率降低。这对某些实时应用是很重要的。很多的实时应用(如IP电话、实时视频会议等)要求源主机以恒定的速率发送数据,并且允许在网络发生拥塞时丢失一些数据,但却不允许数据有太大的时延。UDP正好适合这种要求。
-
UDP支持一对一、一对多、多对一和多对多的交互通信。
-
UDP的首部开销小,只有8个字节,比TCP的20个字节的首部要短。
面向数据报
应用层交给UDP多长的报文,UDP原样发送,既不会拆分,也不会合并。
用UDP传输100个字节的数据,是整体发送整体接收的:
- 如果发送端调用一次
sendto,发送100个字节,那么接收端也必须调用对应的一次recvfrom,接收100个字节。 - 而不能循环调用10次
recvfrom,每次接收10个字节。
UDP的缓冲区
- UDP没有真正意义上的发送缓冲区。调用sendto会直接交给内核,由内核将数据传给网络层协议进行后续的传输动作;
- UDP具有接收缓冲区。但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致;如果缓冲区满了,再到达的UDP数据就会被丢弃;
- UDP的socket既能读,也能写,因此UDP是全双工的。
UDP协议本身是不面向连接的,不保证数据的可靠性、顺序性和无重复性。因此,UDP在设计上更加简单和轻量级,主要是为了快速传输数据。但是,UDP仍然需要接收缓冲区来暂存接收到的数据包,避免数据丢失。
① 为什么UDP只有接收缓冲区,而没有发送缓冲区?
-
接收缓冲区的必要性:
- 当UDP接收到数据包时,如果上层应用程序没有及时读取数据包,那么这些数据包需要一个临时的存放地方,以避免数据丢失。接收缓冲区就是用来暂存这些数据包的。
- 如果没有接收缓冲区,数据包可能会在到达时被直接丢弃,因为上层应用程序可能没有及时处理所有的数据包。接收缓冲区的存在可以减少数据丢失,确保尽可能多的数据包能够被上层应用程序接收和处理。
-
发送缓冲区的可选性:
- 虽然UDP协议本身不提供发送缓冲区的概念,但这并不意味着实际实现中没有类似机制。在某些操作系统和网络栈中,可能会为UDP提供一些发送缓冲机制,以便上层应用程序可以快速发送数据而不必等待底层网络接口完全空闲。
- 但是,从协议设计的角度来看,UDP的发送操作是非阻塞的,也就是说,应用程序调用发送函数后,数据包会立即被提交给底层网络栈,网络栈会尽快将数据包发送出去。这种设计减少了延迟,提高了数据传输的实时性。
-
发送数据的处理方式:
- UDP不需要像TCP那样维护连接状态、重传丢失的数据包、保证数据包顺序等复杂的机制。因此,UDP的发送操作非常简单,数据包一旦生成,就会立即尝试发送出去,而不需要在发送缓冲区中等待处理。
- 如果底层网络接口忙碌,发送操作可能会失败(例如,返回错误代码),应用程序可以根据需要重试发送数据或采取其他措施。由于UDP本身不保证数据传输的可靠性,因此发送缓冲区的需求不如接收缓冲区那么强烈。
UDP的设计初衷是为了提供一种简单、快速的传输方式,而不是为了提供可靠的数据传输。接收缓冲区的存在是为了应对数据包到达时应用程序处理不及时的情况,防止数据丢失。而发送缓冲区则不是UDP的核心需求,因为UDP的发送操作本身就是快速、非阻塞的。
② 如何理解缓冲区?
在Linux系统中,网络协议栈处理网络数据包的过程涉及多个缓冲区和数据结构。UDP的缓冲区的本质实际上是sk_buff结构体对象连接起来的双向链表。
-
sk_buff结构:在Linux内核中,
sk_buff(socket buffer)结构体用于管理和存储网络数据包。下面是sk_buff结构体的主要组成部分:-
数据指针:指向实际的数据缓冲区。
-
头部和尾部指针:用于管理数据的头部和尾部,支持在数据包前后动态添加协议头部或其他信息。
-
链表指针:将多个
sk_buff结构体链接在一起,形成发送或接收队列。 -
控制信息:如网络设备信息、协议信息、时间戳等。
我们目前关心的是指向数据的指针字段:struct sk_buff {struct sk_buff *next;struct sk_buff *prev;unsigned char *head; // 内存块的起始位置unsigned char *data; // 实际数据的起始位置unsigned char *tail; // 当前数据的结尾位置unsigned char *end; // 内存块的末尾位置... };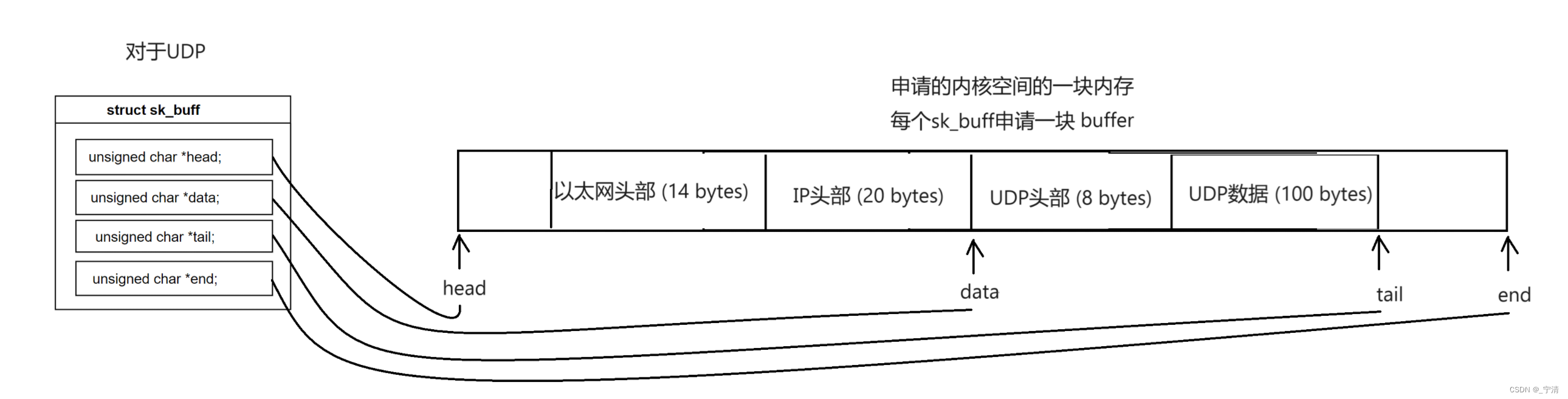
-
-
双向链表:
sk_buff结构体通过双向链表链接在一起,这张链表就是所谓的“UDP接收缓冲区”: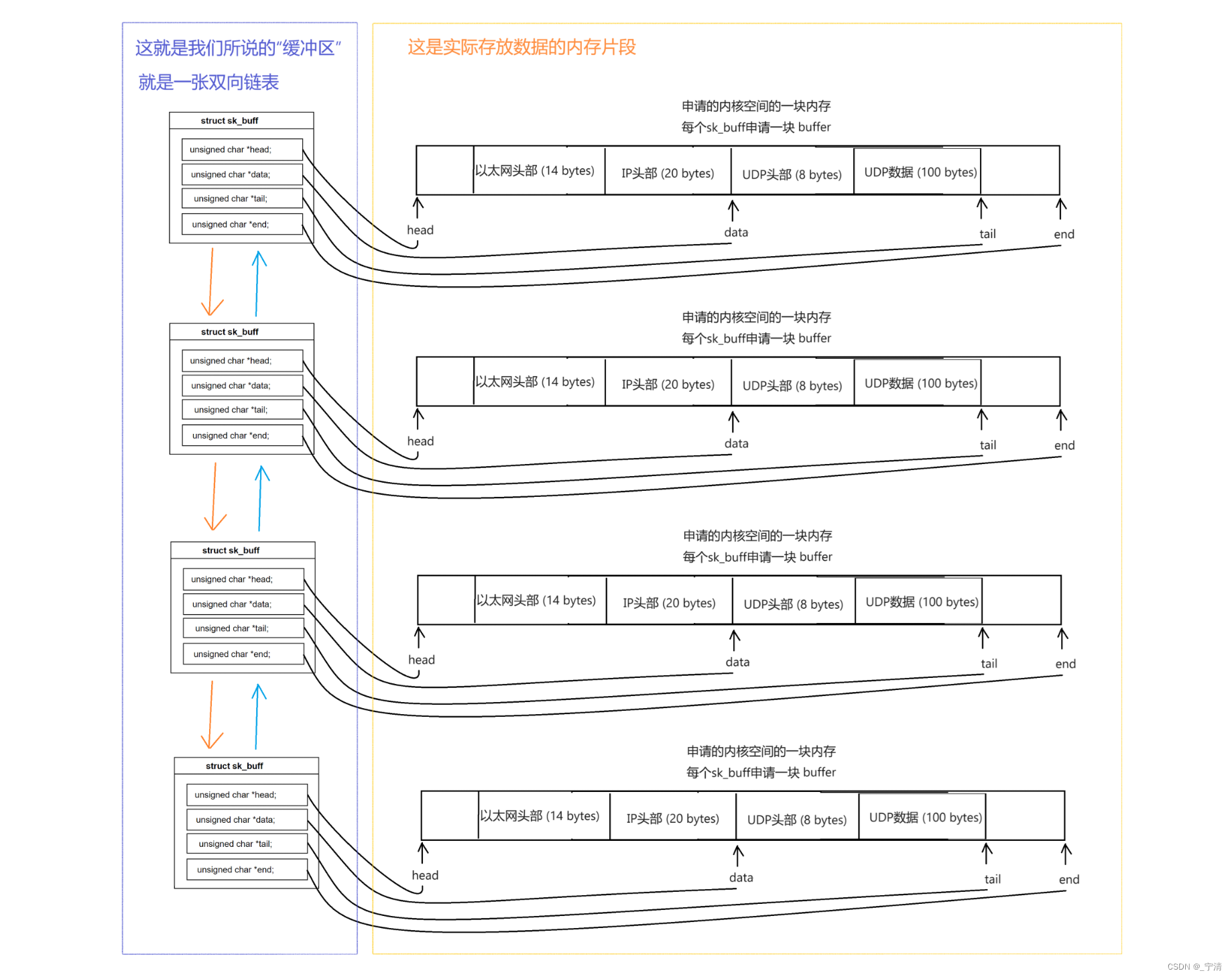
sk_buff结构体通过指针指向数据包实际占据的内存。而实际存数据的位置的内存通常是动态分配的,并且各个数据包的内存区域在物理上不必是连续的。
操作系统中的缓冲区管理
因为要进行UDP的网络通信,所以一台机器上可能会存在大量发过来的UDP报文,此时操作系统就不得不对这些连接进行管理。
操作系统在管理这些报文时需要“先描述,再组织”:
- 在操作系统中一定有一个描述连接的结构体,该结构体当中包含了连接的各种属性字段,这个结构体就是上面的
sk_buff。 - 所有定义出来的连接结构体最终都会以某种数据结构组织起来,这里采用双向链表把
sk_buff连接起来,此时操作系统对连接的管理就变成了对该双向链表的增删查改。
UDP使用的注意事项
需要注意的是,UDP协议报头当中的UDP最大长度是16位的,因此一个UDP报文的最大长度是64K(包含UDP报头的大小)。
然而64K在当今的互联网环境下,是一个非常小的数字。如果需要传输的数据超过64K,就需要在应用层进行手动分包,多次发送,并在接收端进行手动拼装。
基于UDP的应用层协议
- NFS:网络文件系统。
- TFTP:简单文件传输协议。
- DHCP:动态主机配置协议。
- BOOTP:启动协议(用于无盘设备启动)。
- DNS:域名解析协议。
相关文章:
【Linux网络】传输层协议 - UDP
文章目录 一、传输层(运输层)运输层的特点复用和分用再谈端口号端口号范围划分认识知名端口号(Well-Know Port Number)两个问题① 一个进程是否可以绑定多个端口号?② 一个端口号是否可以被多个进程绑定? n…...
:源代码)
debugger(四):源代码
〇、前言 终于来到令人激动的源代码 level 了,这里将会有一些很有意思的算法,来实现源代码级别的调试,这将会非常有趣。 一、使用 libelfin 库 我们不可能直接去读取整个 .debug info 段来进行设置,这是没有必要的,…...

基于运动控制卡的圆柱坐标机械臂设计
1 方案简介 介绍一种基于运动控制卡制作一款scara圆柱坐标的机械臂设计方案,该方案控制器用运动控制卡制作一台三轴机械臂,用于自动抓取和放料操作。 2 组成部分 该机械臂的组成部分有研华运动控制卡,触摸屏,三轴圆柱坐标的平面运…...

MongoDBTemplate-基本文档查询
文章目录 流程概述步骤1:创建一个MongoDB的连接步骤2:创建一个查询对象Query步骤3:设置需要查询的字段步骤4:使用查询对象执行查询操作 流程概述 步骤描述步骤1创建一个MongoDB的连接步骤2创建一个查询对象Query步骤3设置需要查询…...

23种设计模式——创建型模式
设计模式 文章目录 设计模式创建型模式单例模式 [1-小明的购物车](https://kamacoder.com/problempage.php?pid1074)工厂模式 [2-积木工厂](https://kamacoder.com/problempage.php?pid1076)抽象⼯⼚模式 [3-家具工厂](https://kamacoder.com/problempage.php?pid1077)建造者…...

idm究竟有哪些优势
IDM(Internet Download Manager)是一款广受好评的下载管理工具,其主要优势包括: 高速下载:IDM支持最大32线程的下载,可以显著提升下载速度1。文件分类下载:IDM可以根据文件后缀进行分类&#x…...

如何学习Golang语言!
第一部分:Go语言概述 起源与设计哲学:Go语言由Robert Griesemer、Rob Pike和Ken Thompson三位Google工程师设计,旨在解决现代编程中的一些常见问题,如编译速度、运行效率和并发编程。主要特点:Go语言的语法简单、编译…...
Redis系列之淘汰策略介绍
Redis系列之淘汰策略介绍 文章目录 为什么需要Redis淘汰策略?Redis淘汰策略分类Redis数据淘汰流程源码验证淘汰流程Redis中的LRU算法Redis中的LFU算法 为什么需要Redis淘汰策略? 由于Redis内存是有大小的,当内存快满的时候,又没有…...

sql 调优
sql 调优 SQL调优是一个复杂的过程,涉及多个方面,包括查询优化、索引优化、表结构优化等。以下是一些基本的SQL调优策略: 使用索引:确保查询中涉及的列都有适当的索引。 查询优化:避免使用SELECT *,只选取…...
【UML用户指南】-13-对高级结构建模-包
目录 1、名称 2、元素 3、可见性 4、引入与引出 用包把建模元素安排成可作为一个组来处理的较大组块。可以控制这些元素的可见性,使一些元素在包外是可见的,而另一些元素要隐藏在包内。也可以用包表示系统体系结构的不同视图。 狗窝并不复杂&#x…...

前端面试题日常练-day63 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末 1. TypeScript中,以下哪个关键字用于声明一个类的构造函数? a) constructor b) init c) create d) initialize 2. 在TypeScript中,以下哪个符号用于声明可选的函…...
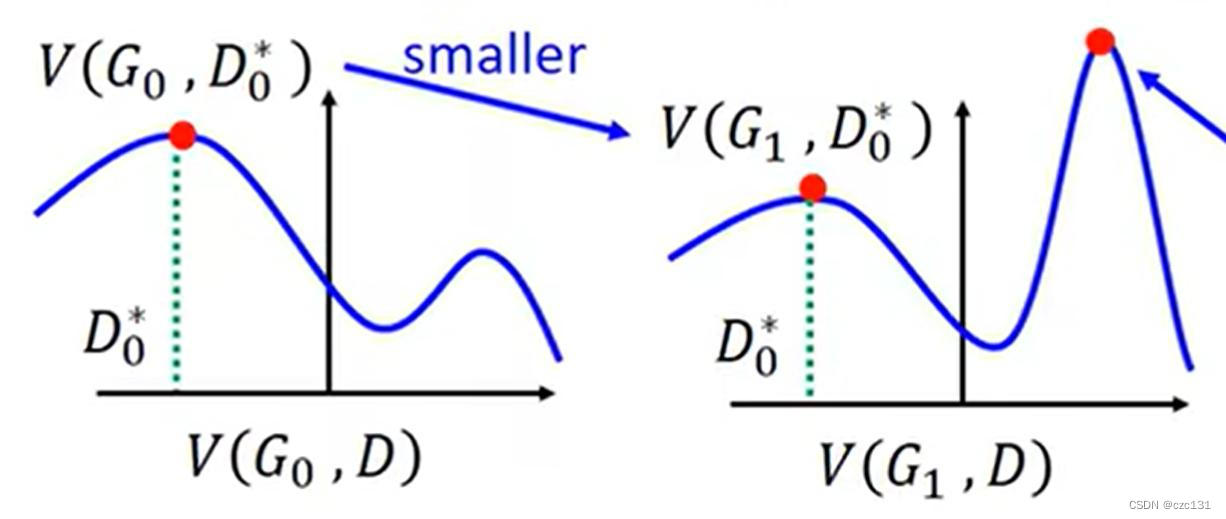
GAN的入门理解
这一篇主要是关于生成对抗网络的模型笔记,有一些简单的证明和原理,是根据李宏毅老师的课程整理的,下面有链接。本篇文章主要就是梳理基础的概念和训练过程,如果有什么问题的话也可以指出的。 李宏毅老师的课程链接 1.概述 GAN是…...

43【PS 作图】颜色速途
1 通过PS让画面细节模糊,避免被过多的颜色干扰 2 分析画面的颜色 3 作图 参考网站: 色感不好要怎么提升呢?分享一下我是怎么练习色感的!_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1h1421Z76p/?spm_id_from333.1007.…...

定个小目标之刷LeetCode热题(13)
今天来看看这道题,介绍两种解法 第一种动态规划,代码如下 class Solution {public int maxSubArray(int[] nums) {int pre 0, maxAns nums[0];for (int x : nums) {// 计算当前最大前缀和pre Math.max(pre x, x);// 更新最大前缀和maxAns Math.ma…...
【AI大模型】Prompt Engineering
目录 什么是提示工程(Prompt Engineering) Prompt 调优 Prompt 的典型构成 「定义角色」为什么有效? 防止 Prompt 攻击 攻击方式 1:著名的「奶奶漏洞」 攻击方式 2:Prompt 注入 防范措施 1:Prompt 注…...
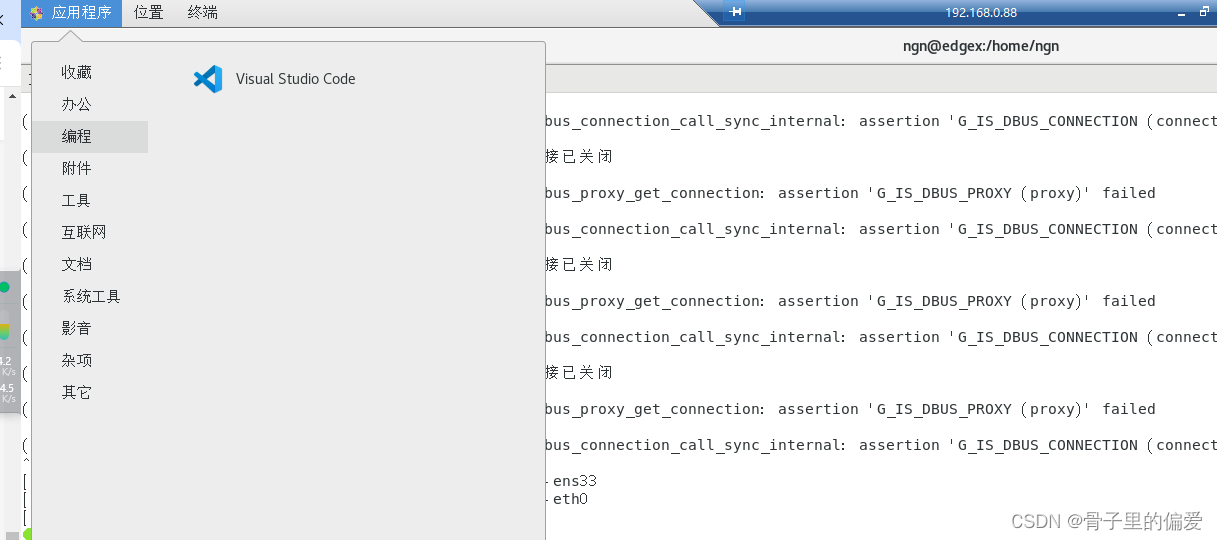
centos安装vscode的教程
centos安装vscode的教程 步骤一:打开vscode官网找到历史版本 历史版本链接 步骤二:找到文件下载的位置 在命令行中输入(稍等片刻即可打开): /usr/share/code/bin/code关闭vscode后,可在应用程序----编程…...

面试题------>MySQL!!!
一、连接查询 ①:左连接left join (小表在左,大表在右) ②:右连接right join(小表在右,大表在左) 二、聚合函数 SQL 中提供的聚合函数可以用来统计、求和、求最值等等 COUNT&…...

英伟达:史上最牛一笔天使投资
200万美元的天使投资,让刚成立就面临倒闭风险的英伟达由危转安,并由此缔造了一个2.8万亿美元的市值神话。 这是全球风投史上浓墨重彩的一笔。 前不久,黄仁勋在母校斯坦福大学的演讲中,提到了人生中的第一笔融资——1993年&#x…...

PDF分页处理:技术与实践
引言 在数字化办公和学习中,PDF文件因其便携性和格式稳定性而广受欢迎。然而,处理大型PDF文件时,我们经常需要将其拆分成单独的页面,以便于管理和分享。本文将探讨如何使用Python编程语言和一些流行的库来实现PDF文件的分页处理。…...
数据可视化——pyecharts库绘图
目录 官方文档 使用说明: 点击基本图表 可以点击你想要的图表 安装: 一些例图: 柱状图: 效果: 折线图: 效果: 环形图: 效果: 南丁格尔图(玫瑰图&am…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

茉莉花插件:如何让中文文献管理效率提升300%
茉莉花插件:如何让中文文献管理效率提升300% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献的元数据抓…...

【国家级攻防演练级建议】:DeepSeek私有化部署中4类隐蔽后门植入路径与实时检测方案
更多请点击: https://kaifayun.com 第一章:DeepSeek私有化部署中隐蔽后门植入的攻防对抗本质 在私有化场景下,DeepSeek模型的部署链路常跨越镜像构建、权重加载、推理服务启动及API网关接入等多个环节。攻击者可利用构建上下文污染、依赖包劫…...

从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式
从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发领域&am…...