Ubuntu20.04配置qwen0.5B记录
环境简介
Ubuntu20.04、
NVIDIA-SMI 545.29.06、
Cuda 11.4、
python3.10、
pytorch1.11.0
开始搭建
python环境设置
创建虚拟环境
conda create --name qewn python==3.10
预安装modelscope和transformers
pip install modelscope
pip install transformers
安装pytorch
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3
模型需要下载
创建一个python文件
gedit download.py
里面复制如下内容
from modelscope.hub.file_download import model_file_downloadmodel_dir = model_file_download(model_id='qwen/Qwen1.5-0.5B-Chat-GGUF',file_path='qwen1_5-0_5b-chat-q5_k_m.gguf',revision='master',cache_dir='path/to/local/dir')
运行python文件进行下载
python download.py
下载llama.cpp
使⽤git命令克隆llama.cpp项⽬
git clone https://github.com/ggerganov/llama.cpp
克隆完成之后我们进入llama.cpp目录中,对项目进行编译
cd llama.cpp
make -j
模型下载
在魔搭社区中下载模型运行
https://www.modelscope.cn/models/qwen/Qwen1.5-0.5B-Chat-GGUF/files
本人下载的是qwen1_5-0_5b-chat-q5_k_m.gguf
终端运行,其中模型替换为自己的模型地址(官方给的-cml参数在help中没有找到,且影响运行,所以我删除掉了)
官方:
./main -m /path/to/local/dir/qwen/Qwen1.5-0.5B-Chat-GGUF/qwen1_5-0_5b-chat-q5_k_m.gguf -n 512 --color -i -cml -f prompts/chat-with-qwen.txt
我运行:
./main -m /path/to/local/dir/qwen/Qwen1.5-0.5B-Chat-GGUF/qwen1_5-0_5b-chat-q5_k_m.gguf -n 512 --color -i -f prompts/chat-with-qwen.txt
help内容:
usage: ./main [options]general:-h, --help, --usage print usage and exit--version show version and build info-v, --verbose print verbose information--verbosity N set specific verbosity level (default: 0)--verbose-prompt print a verbose prompt before generation (default: false)--no-display-prompt don't print prompt at generation (default: false)-co, --color colorise output to distinguish prompt and user input from generations (default: false)-s, --seed SEED RNG seed (default: -1, use random seed for < 0)-t, --threads N number of threads to use during generation (default: 8)-tb, --threads-batch N number of threads to use during batch and prompt processing (default: same as --threads)-td, --threads-draft N number of threads to use during generation (default: same as --threads)-tbd, --threads-batch-draft N number of threads to use during batch and prompt processing (default: same as --threads-draft)--draft N number of tokens to draft for speculative decoding (default: 5)-ps, --p-split N speculative decoding split probability (default: 0.1)-lcs, --lookup-cache-static FNAMEpath to static lookup cache to use for lookup decoding (not updated by generation)-lcd, --lookup-cache-dynamic FNAMEpath to dynamic lookup cache to use for lookup decoding (updated by generation)-c, --ctx-size N size of the prompt context (default: 0, 0 = loaded from model)-n, --predict N number of tokens to predict (default: -1, -1 = infinity, -2 = until context filled)-b, --batch-size N logical maximum batch size (default: 2048)-ub, --ubatch-size N physical maximum batch size (default: 512)--keep N number of tokens to keep from the initial prompt (default: 0, -1 = all)--chunks N max number of chunks to process (default: -1, -1 = all)-fa, --flash-attn enable Flash Attention (default: disabled)-p, --prompt PROMPT prompt to start generation with (default: '')-f, --file FNAME a file containing the prompt (default: none)--in-file FNAME an input file (repeat to specify multiple files)-bf, --binary-file FNAME binary file containing the prompt (default: none)-e, --escape process escapes sequences (\n, \r, \t, \', \", \\) (default: true)--no-escape do not process escape sequences-ptc, --print-token-count N print token count every N tokens (default: -1)--prompt-cache FNAME file to cache prompt state for faster startup (default: none)--prompt-cache-all if specified, saves user input and generations to cache as wellnot supported with --interactive or other interactive options--prompt-cache-ro if specified, uses the prompt cache but does not update it-r, --reverse-prompt PROMPT halt generation at PROMPT, return control in interactive modecan be specified more than once for multiple prompts-sp, --special special tokens output enabled (default: false)-cnv, --conversation run in conversation mode (does not print special tokens and suffix/prefix) (default: false)-i, --interactive run in interactive mode (default: false)-if, --interactive-first run in interactive mode and wait for input right away (default: false)-mli, --multiline-input allows you to write or paste multiple lines without ending each in '\'--in-prefix-bos prefix BOS to user inputs, preceding the `--in-prefix` string--in-prefix STRING string to prefix user inputs with (default: empty)--in-suffix STRING string to suffix after user inputs with (default: empty)sampling:--samplers SAMPLERS samplers that will be used for generation in the order, separated by ';'(default: top_k;tfs_z;typical_p;top_p;min_p;temperature)--sampling-seq SEQUENCE simplified sequence for samplers that will be used (default: kfypmt)--ignore-eos ignore end of stream token and continue generating (implies --logit-bias EOS-inf)--penalize-nl penalize newline tokens (default: false)--temp N temperature (default: 0.8)--top-k N top-k sampling (default: 40, 0 = disabled)--top-p N top-p sampling (default: 0.9, 1.0 = disabled)--min-p N min-p sampling (default: 0.1, 0.0 = disabled)--tfs N tail free sampling, parameter z (default: 1.0, 1.0 = disabled)--typical N locally typical sampling, parameter p (default: 1.0, 1.0 = disabled)--repeat-last-n N last n tokens to consider for penalize (default: 64, 0 = disabled, -1 = ctx_size)--repeat-penalty N penalize repeat sequence of tokens (default: 1.0, 1.0 = disabled)--presence-penalty N repeat alpha presence penalty (default: 0.0, 0.0 = disabled)--frequency-penalty N repeat alpha frequency penalty (default: 0.0, 0.0 = disabled)--dynatemp-range N dynamic temperature range (default: 0.0, 0.0 = disabled)--dynatemp-exp N dynamic temperature exponent (default: 1.0)--mirostat N use Mirostat sampling.Top K, Nucleus, Tail Free and Locally Typical samplers are ignored if used.(default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0)--mirostat-lr N Mirostat learning rate, parameter eta (default: 0.1)--mirostat-ent N Mirostat target entropy, parameter tau (default: 5.0)-l TOKEN_ID(+/-)BIAS modifies the likelihood of token appearing in the completion,i.e. `--logit-bias 15043+1` to increase likelihood of token ' Hello',or `--logit-bias 15043-1` to decrease likelihood of token ' Hello'--cfg-negative-prompt PROMPTnegative prompt to use for guidance (default: '')--cfg-negative-prompt-file FNAMEnegative prompt file to use for guidance--cfg-scale N strength of guidance (default: 1.0, 1.0 = disable)grammar:--grammar GRAMMAR BNF-like grammar to constrain generations (see samples in grammars/ dir) (default: '')--grammar-file FNAME file to read grammar from-j, --json-schema SCHEMA JSON schema to constrain generations (https://json-schema.org/), e.g. `{}` for any JSON objectFor schemas w/ external $refs, use --grammar + example/json_schema_to_grammar.py insteadembedding:--pooling {none,mean,cls}pooling type for embeddings, use model default if unspecifiedcontext hacking:--rope-scaling {none,linear,yarn}RoPE frequency scaling method, defaults to linear unless specified by the model--rope-scale N RoPE context scaling factor, expands context by a factor of N--rope-freq-base N RoPE base frequency, used by NTK-aware scaling (default: loaded from model)--rope-freq-scale N RoPE frequency scaling factor, expands context by a factor of 1/N--yarn-orig-ctx N YaRN: original context size of model (default: 0 = model training context size)--yarn-ext-factor N YaRN: extrapolation mix factor (default: -1.0, 0.0 = full interpolation)--yarn-attn-factor N YaRN: scale sqrt(t) or attention magnitude (default: 1.0)--yarn-beta-slow N YaRN: high correction dim or alpha (default: 1.0)--yarn-beta-fast N YaRN: low correction dim or beta (default: 32.0)-gan, --grp-attn-n N group-attention factor (default: 1)-gaw, --grp-attn-w N group-attention width (default: 512.0)-dkvc, --dump-kv-cache verbose print of the KV cache-nkvo, --no-kv-offload disable KV offload-ctk, --cache-type-k TYPE KV cache data type for K (default: f16)-ctv, --cache-type-v TYPE KV cache data type for V (default: f16)perplexity:--all-logits return logits for all tokens in the batch (default: false)--hellaswag compute HellaSwag score over random tasks from datafile supplied with -f--hellaswag-tasks N number of tasks to use when computing the HellaSwag score (default: 400)--winogrande compute Winogrande score over random tasks from datafile supplied with -f--winogrande-tasks N number of tasks to use when computing the Winogrande score (default: 0)--multiple-choice compute multiple choice score over random tasks from datafile supplied with -f--multiple-choice-tasks Nnumber of tasks to use when computing the multiple choice score (default: 0)--kl-divergence computes KL-divergence to logits provided via --kl-divergence-base--ppl-stride N stride for perplexity calculation (default: 0)--ppl-output-type {0,1} output type for perplexity calculation (default: 0)parallel:-dt, --defrag-thold N KV cache defragmentation threshold (default: -1.0, < 0 - disabled)-np, --parallel N number of parallel sequences to decode (default: 1)-ns, --sequences N number of sequences to decode (default: 1)-cb, --cont-batching enable continuous batching (a.k.a dynamic batching) (default: enabled)multi-modality:--mmproj FILE path to a multimodal projector file for LLaVA. see examples/llava/README.md--image FILE path to an image file. use with multimodal models. Specify multiple times for batchingbackend:--rpc SERVERS comma separated list of RPC servers--mlock force system to keep model in RAM rather than swapping or compressing--no-mmap do not memory-map model (slower load but may reduce pageouts if not using mlock)--numa TYPE attempt optimizations that help on some NUMA systems- distribute: spread execution evenly over all nodes- isolate: only spawn threads on CPUs on the node that execution started on- numactl: use the CPU map provided by numactlif run without this previously, it is recommended to drop the system page cache before using thissee https://github.com/ggerganov/llama.cpp/issues/1437model:--check-tensors check model tensor data for invalid values (default: false)--override-kv KEY=TYPE:VALUEadvanced option to override model metadata by key. may be specified multiple times.types: int, float, bool, str. example: --override-kv tokenizer.ggml.add_bos_token=bool:false--lora FNAME apply LoRA adapter (implies --no-mmap)--lora-scaled FNAME S apply LoRA adapter with user defined scaling S (implies --no-mmap)--lora-base FNAME optional model to use as a base for the layers modified by the LoRA adapter--control-vector FNAME add a control vector--control-vector-scaled FNAME SCALEadd a control vector with user defined scaling SCALE--control-vector-layer-range START ENDlayer range to apply the control vector(s) to, start and end inclusive-m, --model FNAME model path (default: models/$filename with filename from --hf-fileor --model-url if set, otherwise models/7B/ggml-model-f16.gguf)-md, --model-draft FNAME draft model for speculative decoding (default: unused)-mu, --model-url MODEL_URL model download url (default: unused)-hfr, --hf-repo REPO Hugging Face model repository (default: unused)-hff, --hf-file FILE Hugging Face model file (default: unused)retrieval:--context-file FNAME file to load context from (repeat to specify multiple files)--chunk-size N minimum length of embedded text chunks (default: 64)--chunk-separator STRING separator between chunks (default: '')passkey:--junk N number of times to repeat the junk text (default: 250)--pos N position of the passkey in the junk text (default: -1)imatrix:-o, --output FNAME output file (default: 'imatrix.dat')--output-frequency N output the imatrix every N iterations (default: 10)--save-frequency N save an imatrix copy every N iterations (default: 0)--process-output collect data for the output tensor (default: false)--no-ppl do not compute perplexity (default: true)--chunk N start processing the input from chunk N (default: 0)bench:-pps is the prompt shared across parallel sequences (default: false)-npp n0,n1,... number of prompt tokens-ntg n0,n1,... number of text generation tokens-npl n0,n1,... number of parallel promptsserver:--host HOST ip address to listen (default: 127.0.0.1)--port PORT port to listen (default: 8080)--path PATH path to serve static files from (default: )--embedding(s) enable embedding endpoint (default: disabled)--api-key KEY API key to use for authentication (default: none)--api-key-file FNAME path to file containing API keys (default: none)--ssl-key-file FNAME path to file a PEM-encoded SSL private key--ssl-cert-file FNAME path to file a PEM-encoded SSL certificate--timeout N server read/write timeout in seconds (default: 600)--threads-http N number of threads used to process HTTP requests (default: -1)--system-prompt-file FNAMEset a file to load a system prompt (initial prompt of all slots), this is useful for chat applications--log-format {text,json} log output format: json or text (default: json)--metrics enable prometheus compatible metrics endpoint (default: disabled)--no-slots disables slots monitoring endpoint (default: enabled)--slot-save-path PATH path to save slot kv cache (default: disabled)--chat-template JINJA_TEMPLATEset custom jinja chat template (default: template taken from model's metadata)only commonly used templates are accepted:https://github.com/ggerganov/llama.cpp/wiki/Templates-supported-by-llama_chat_apply_template-sps, --slot-prompt-similarity SIMILARITYhow much the prompt of a request must match the prompt of a slot in order to use that slot (default: 0.50, 0.0 = disabled)logging:--simple-io use basic IO for better compatibility in subprocesses and limited consoles-ld, --logdir LOGDIR path under which to save YAML logs (no logging if unset)--log-test Run simple logging test--log-disable Disable trace logs--log-enable Enable trace logs--log-file FNAME Specify a log filename (without extension)--log-new Create a separate new log file on start. Each log file will have unique name: "<name>.<ID>.log"--log-append Don't truncate the old log file.参考文章
(Qwen)通义千问大模型安装部署教程2024最新
相关文章:

Ubuntu20.04配置qwen0.5B记录
环境简介 Ubuntu20.04、 NVIDIA-SMI 545.29.06、 Cuda 11.4、 python3.10、 pytorch1.11.0 开始搭建 python环境设置 创建虚拟环境 conda create --name qewn python3.10预安装modelscope和transformers pip install modelscope pip install transformers安装pytorch co…...
java自学阶段二:JavaWeb开发--day80(项目实战2之苍穹外卖)
《项目案例—黑马苍穹外卖》 目录: 学习目标项目介绍前端环境搭建(前期直接导入老师的项目,后期自己敲)后端环境搭建(导入初始项目,新建仓库使用git管理项目,新建数据库,修改登录功能ÿ…...

HPUX系统Oracle RAC如何添加ASM磁盘
前言 HPUX简介 HP-UX (Hewlett-Packard Unix) 是惠普公司开发的类 Unix 操作系统。自 1980 年代问世以来,HP-UX 在技术和功能上不断发展,适应了多种硬件平台和企业计算需求。以下是 HP-UX 的发展历史概述: 1980 年代:起源与早期…...
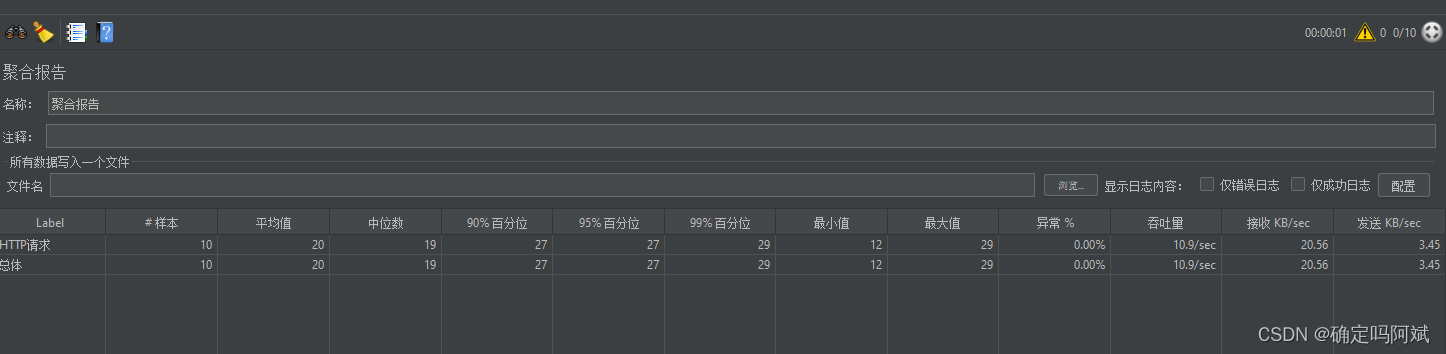
Jmeter 压力测测试的简单入门
下载安装 官方网站:Apache JMeter - Download Apache JMeter 下载完成解压即可。 配置 1. 找到 bin 目录下的 ApacheJMeter.jar 包,直接打开 如果向图片这样不能直接打开,就在此路径运行 CMD,然后输入下面的命令即可启动。 ja…...

N叉树的层序遍历-力扣
本题同样是二叉树的层序遍历的扩展,只不过二叉树每个节点的子节点只有左右节点,而N叉树的子节点是一个数组,层序遍历到一个节点时,需要将这个节点的子节点数组的每个节点都入队。 代码如下: /* // Definition for a N…...
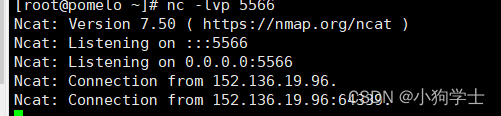
解决阿里云的端口添加安全组仍然无法扫描到
发现用线上的网站扫不到这个端口,这个端口关了,但是没有更详细信息了 我用nmap扫了一下我的这个端口,发现主机是活跃的,但是有防火墙,我们列出云服务器上面的这个防火墙list,发现确实没有5566端口 参考&a…...
【因果推断python】26_双重稳健估计1
目录 不要把所有的鸡蛋放在一个篮子里 双重稳健估计 关键思想 不要把所有的鸡蛋放在一个篮子里 我们已经学会了如何使用线性回归和倾向得分加权来估计 。但是我们应该在什么时候使用哪一个呢?在不明确的情况下,请同时使用两者!双重稳健估计…...

C语言 图形化界面方式连接MySQL【C/C++】【图形化界面组件分享】
博客主页:花果山~程序猿-CSDN博客 文章分栏:MySQL之旅_花果山~程序猿的博客-CSDN博客 关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力,一起成长! 目录 一.配置开发环境 二…...
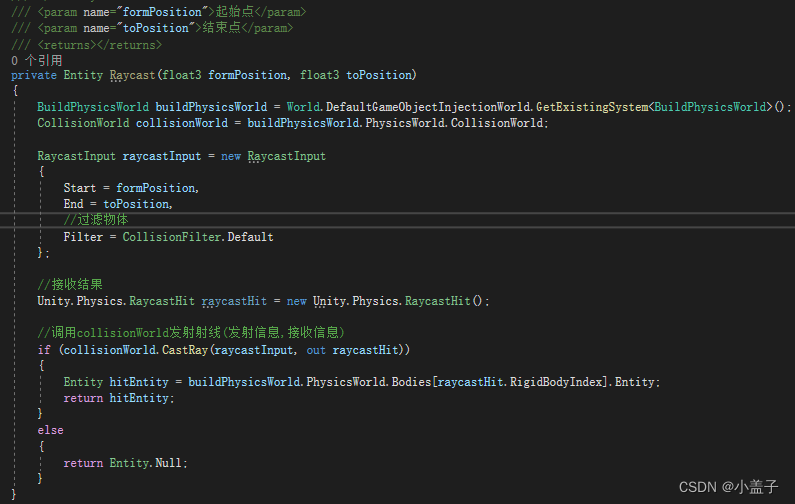
Unity DOTS技术(十五) 物理系统
要解决性能的瓶颈问题,在DOTS中我们将不再使用Unity自带的物理组件. 下面来分享一下在DOTS中当如何使用物理插件. 一.导入插件 在使用DOTS系创建的实体我们会发现,游戏物体无法受物理系统影响进行运动.于是我们需要添加物理系统插件. 1.打开Package Manager > 搜索插件Uni…...

Java线程安全
线程安全 线程安全:线程安全:synchronized同步代码块:同步方法:成员同步方法:静态同步方法: Lock:应用: 单例模式:懒汉式:饿汉式:枚举饿汉式:双重检验锁: 线程…...

Solidity选择使用 require 语句还是条件语句结合手动触发 revert 操作?回滚交易和抛出异常如何选择?
文章目录 Solidity选择使用 require 语句还是条件语句结合手动触发 revert 操作?场景举例:回滚交易和抛出异常如何选择? Solidity选择使用 require 语句还是条件语句结合手动触发 revert 操作? IERC721 nft IERC721(nftAddress)…...

SpringCloud 网关配置websocket
一、nginx https://域名.com location /websocket/ { proxy_pass http://172.1.1.173:8181/; #内网网关IP proxy_http_version 1.1; proxy_read_timeout 360s; proxy_redirect off; proxy_set_header Upgrade $http_upgrade; …...

基于JavaScript 实现近邻算法以及优化方案
前言 近邻算法(K-Nearest Neighbors,简称 KNN)是一种简单的、广泛使用的分类和回归算法。它的基本思想是:给定一个待分类的样本,找到这个样本在特征空间中距离最近的 k 个样本,这 k 个样本的多数类别作为待…...

移动端适配和响应式页面中的常用单位
在移动端适配和响应式页面中,一般采用以下几种单位: 百分比(%):百分比单位是相对于父元素的大小计算的。它可以用于设置宽度、高度、字体大小等属性,使得元素能够随着父元素的大小自动调整。百分比单位在响…...

麒麟v10系统arm64架构openssh9.7p1的rpm包
制作openssh 说明 理论上制作的多个rpm在arm64架构(aarch64)都适用 系统信息:4.19.90-17.ky10.aarch64 GNU/Linux 升级前备份好文件/etc/ssh、/etc/pam.d等以及开启telnet 升级后确认正常后关闭telnet 在之前制作过openssh-9.5p1基础上继续…...

刚刚❗️德勤2025校招暑期实习测评笔试SHL测评题库已发(答案)
📣德勤 2024暑期实习测评已发,正在申请的小伙伴看过来哦👀 ㊙️本次暑期实习优先考虑2025年本科及以上学历的毕业生,此次只有“审计及鉴定”“税务与商务咨询”两个部门开放了岗位~ ⚠️测评注意事项: ὄ…...

python对视频进行帧处理以及裁减部分区域
视频截取帧 废话不多说直接上代码: from cv2 import VideoCapture from cv2 import imwrite# 定义保存图片函数 # image:要保存的图片名字 # addr;图片地址与相片名字的前部分 # num: 相片,名字的后缀。int 类型 def save_image(image, add…...

Python栈的编程题目
你好,我是悦创。 下面是三道关于栈的编程题目,适合不同难度级别的练习: 1. 有效的括号(简单) 题目描述: 给定一个只包括 (,),{,},[ 和 ] 的字符串…...
ROS云课三分钟外传之CoppeliaSim_Edu_V4_1_0_Ubuntu16_04
三分钟热度试一试吧,走过路过不要错过。 参考之前: 从云课五分钟到一分钟之v-rep_pro_edu_v3_6_2-CSDN博客 git clone https://gitcode.net/ZhangRelay/v-rep_pro_edu_v3_6_2_ubuntu16_04.gittar -xf v-rep_pro_edu_v3_6_2_ubuntu16_04/V-REP_PRO_EDU…...

day28回溯算法part04| 93.复原IP地址 78.子集 90.子集II
**93.复原IP地址 ** 本期本来是很有难度的,不过 大家做完 分割回文串 之后,本题就容易很多了 题目链接/文章讲解 | 视频讲解 class Solution { public:vector<string> result;// pointNum记录加入的点的数量,其等于3的时候停止void b…...

Sunshine游戏串流终极指南:5步搭建你的私人云游戏服务器
Sunshine游戏串流终极指南:5步搭建你的私人云游戏服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款功能强大的开源游戏串流服务器,专为…...

ThinkPad风扇控制终极指南:如何让你的笔记本在静音与散热之间找到完美平衡
ThinkPad风扇控制终极指南:如何让你的笔记本在静音与散热之间找到完美平衡 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经在深夜工作时…...

基于树莓派的智能直播状态指示器:物联网与API轮询实践
1. 项目概述与核心价值 如果你和我一样,经常在Ustream或Google Hangouts上观看固定的直播节目,或者自己就是一名内容创作者,那你肯定理解那种“直播是否开始了”的焦虑。是继续刷新页面,还是去做点别的?对于家庭或小型…...

C++ 如何在VS中“强制”链接?
如何在VS中“强制”链接? 打开你的game_mobile项目,按下图设置。 方法一:强制链接(最直接) 这是彻底忽略LNK1169及其引发的所有LNK2005错误,强制生成可执行文件的方法。 打开项目的“属性页”。导航到“配置…...

电商客服机器人如何通过 Taotoken 动态选择性价比最优的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 电商客服机器人如何通过 Taotoken 动态选择性价比最优的模型 在电商客服场景中,用户咨询的问题复杂度差异巨大。从简单…...

终极指南:如何用MAA Assistant Arknights实现明日方舟全自动化
终极指南:如何用MAA Assistant Arknights实现明日方舟全自动化 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: htt…...
)
保姆级教程:用PyTorch在MuJoCo的Ant-v2环境跑通PPO算法(附完整代码)
从零实现PPO算法:MuJoCo Ant-v2环境实战指南 在强化学习领域,让一个虚拟蚂蚁学会行走是经典的基准测试任务。本文将带你用PyTorch框架,在MuJoCo的Ant-v2环境中完整实现PPO算法。不同于理论讲解,我们聚焦于可运行的代码实现和实际…...

游戏资源提取终极指南:如何用QuickBMS轻松解包400+格式的游戏文件
游戏资源提取终极指南:如何用QuickBMS轻松解包400格式的游戏文件 【免费下载链接】QuickBMS QuickBMS by aluigi - Github Mirror 项目地址: https://gitcode.com/gh_mirrors/qui/QuickBMS 想要从游戏中提取音乐、贴图、模型等资源吗?QuickBMS是…...

终极指南:如何用免费软件完全掌控Windows电脑风扇噪音与散热平衡
终极指南:如何用免费软件完全掌控Windows电脑风扇噪音与散热平衡 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_T…...

Git报‘dubious ownership’错误?除了safe.directory,还有这3种更灵活的权限管理姿势
Git权限管理进阶:超越safe.directory的四种灵活解决方案 当你从团队仓库克隆代码到本地,正准备提交修改时,突然遭遇dubious ownership错误——这种场景对中高级开发者而言绝不陌生。Git的安全机制本意是保护项目免受未授权修改,但…...