ccc-pytorch-RNN(7)
文章目录
- 一、RNN简介
- 二、RNN关键结构
- 三、RNN的训练方式
- 四、时间序列预测
- 五、梯度弥散和梯度爆炸问题
一、RNN简介
RNN(Recurrent Neural Network)中文循环神经网络,用于处理序列数据。它与传统人工神经网络和卷积神经网络的输入和输出相互独立不同,依赖它独特的神经结构(循环核)获得“记忆能力”
注意与递归神经网络(Recursive Neural Network)RNN区分,同时循环神经网络为短期记忆,与(Long Short-Term Memory networks)LSTM的长期记忆不同
二、RNN关键结构
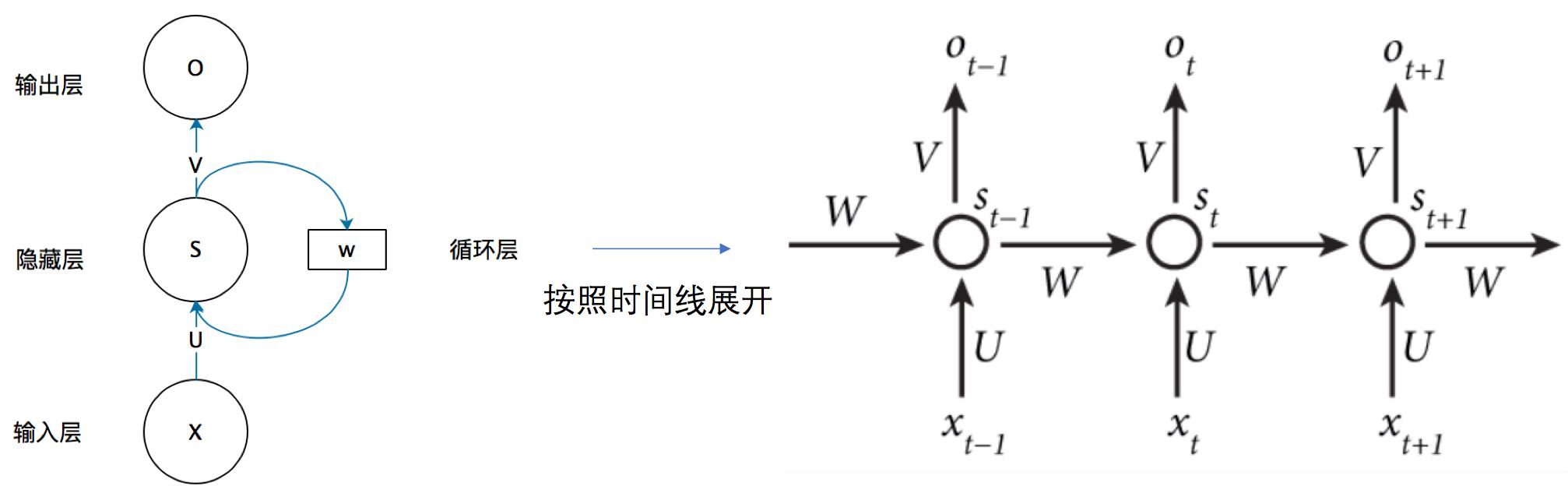
各参数含义:
- xtx_txt:序列t的输入层的值,sts_tst:序列t的隐藏层的值 ,oto_tot:序列t的输出层的值
- UUU:输入层到隐藏层的权重矩阵 ,VVV:隐藏层到输出层的权重矩阵
- WWW:隐藏层上一次的值作为这一次输入的权重
注意事项:
- 同不同序列t时的W,V,U相同,即RNN的Weight sharing
- 结构图中每一步都会有输出,但实际中很可能只需最后一步的输出
- 为了降低网络复杂度,sts_tst只包含前面若干隐藏层的状态
三、RNN的训练方式
本质还是梯度下降的反向传播,由前向传播得到的预测值与真实值构建损失函数,更新W、U、V求解最小值:
St=f(U⋅Xt+W⋅St−1+b)Ot=g(V⋅St)Lt=12(Yt−Ot)2S_t=f(U\cdot X_t+W\cdot S_{t-1}+b) \\O_t = g(V\cdot S_t) \\ L_t=\frac{1}{2}(Y_t-O_t)^2St=f(U⋅Xt+W⋅St−1+b)Ot=g(V⋅St)Lt=21(Yt−Ot)2
如果对t3t_3t3的U、V、W求偏导如下:
∂L3∂V=∂L3∂O3∂O3∂V∂L3∂U=∂L3∂O3∂O3∂S3∂S3∂U+∂L3∂O3∂O3∂S3∂S3∂S2∂S2∂U+∂L3∂O3∂O3∂S3∂S3∂S2∂S2∂S1∂S1∂U∂L3∂W=∂L3∂O3∂O3∂S3∂S3∂W+∂L3∂O3∂O3∂S3∂S3∂S2∂S2∂W+∂L3∂O3∂O3∂S3∂S3∂S2∂S2∂S1∂S1∂W因为有:O3=VS3+b2S3=UX3+WS2+b1S2=UX2+WS1+b1S1=UX1+WS0+b1\begin{aligned} &\frac{\partial L_3}{\partial V}=\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial V} \\ &\frac{\partial L_3}{\partial U}=\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial U}+\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2}\frac{\partial S_2}{\partial U}+\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2}\frac{\partial S_2}{\partial S_1}\frac{\partial S_1}{\partial U} \\&\frac{\partial L_3}{\partial W}=\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial W}+\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2}\frac{\partial S_2}{\partial W}+\frac{\partial L_3}{\partial O_3}\frac{\partial O_3}{\partial S_3} \frac{\partial S_3}{\partial S_2}\frac{\partial S_2}{\partial S_1}\frac{\partial S_1}{\partial W} \\ &因为有:\\&O_3 = VS_3 + b_2\\&S_3 =UX_3+WS_2+b_1\\&S_2 =UX_2+WS_1+b_1\\&S_1=UX_1+WS_0+b_1 \end{aligned}∂V∂L3=∂O3∂L3∂V∂O3∂U∂L3=∂O3∂L3∂S3∂O3∂U∂S3+∂O3∂L3∂S3∂O3∂S2∂S3∂U∂S2+∂O3∂L3∂S3∂O3∂S2∂S3∂S1∂S2∂U∂S1∂W∂L3=∂O3∂L3∂S3∂O3∂W∂S3+∂O3∂L3∂S3∂O3∂S2∂S3∂W∂S2+∂O3∂L3∂S3∂O3∂S2∂S3∂S1∂S2∂W∂S1因为有:O3=VS3+b2S3=UX3+WS2+b1S2=UX2+WS1+b1S1=UX1+WS0+b1
可以看到U和W对于序列产生了依赖,并且可以得到:
∂Lt∂U=∑k=0t∂Lt∂Ot∂Ot∂St(∏j=k+1t∂Sj∂Sj−1)∂Sk∂U∂Lt∂W=∑k=0t∂Lt∂Ot∂Ot∂St(∏j=k+1t∂Sj∂Sj−1)∂Sk∂W\begin{aligned} &\frac{\partial L_t}{\partial U}= \sum_{k=0}^{t}\frac{\partial L_t}{\partial O_t}\frac{\partial O_t}{\partial S_t}(\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}})\frac{\partial S_k}{\partial U}\\&\frac{\partial L_t}{\partial W}= \sum_{k=0}^{t}\frac{\partial L_t}{\partial O_t}\frac{\partial O_t}{\partial S_t}(\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}})\frac{\partial S_k}{\partial W} \end{aligned} ∂U∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot(j=k+1∏t∂Sj−1∂Sj)∂U∂Sk∂W∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot(j=k+1∏t∂Sj−1∂Sj)∂W∂Sk
最后将结果放入激活函数即可
四、时间序列预测
预测一个正弦函数的走势
第一部分:构建样本数据
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
第二部分:构建循环神经网络结构
class Net(nn.Module):def __init__(self, ):super(Net, self).__init__()self.rnn = nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=1,batch_first=True,)for p in self.rnn.parameters():nn.init.normal_(p, mean=0.0, std=0.001)self.linear = nn.Linear(hidden_size, output_size)def forward(self, x, hidden_prev):out, hidden_prev = self.rnn(x, hidden_prev)# [b, seq, h]out = out.view(-1, hidden_size)out = self.linear(out) # [seq,h] => [seq,1]out = out.unsqueeze(dim=0)# [1,seq,1]return out, hidden_prev
第三部分:迭代训练并计算loss
model = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr)hidden_prev = torch.zeros(1, 1, hidden_size)for iter in range(6000):start = np.random.randint(10, size=1)[0]time_steps = np.linspace(start, start + 10, num_time_steps)data = np.sin(time_steps)data = data.reshape(num_time_steps, 1)x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)output, hidden_prev = model(x, hidden_prev)hidden_prev = hidden_prev.detach() #不会具有梯度loss = criterion(output, y)model.zero_grad()loss.backward()optimizer.step()if iter % 100 == 0:print("Iteration: {} loss {}".format(iter, loss.item()))
第四部分:绘制预测值并比较
predictions = []
input = x[:, 0, :]
for _ in range(x.shape[1]):input = input.view(1, 1, 1)(pred, hidden_prev) = model(input, hidden_prev)input = predpredictions.append(pred.detach().numpy().ravel()[0])x = x.data.numpy().ravel()
y = y.data.numpy()
plt.scatter(time_steps[:-1], x, s=90)
plt.plot(time_steps[:-1], x)plt.scatter(time_steps[1:], predictions)
plt.show()
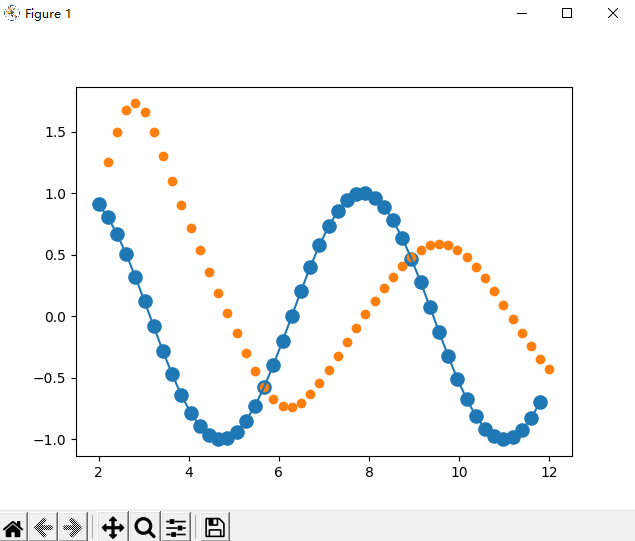
迭代200次的图像:
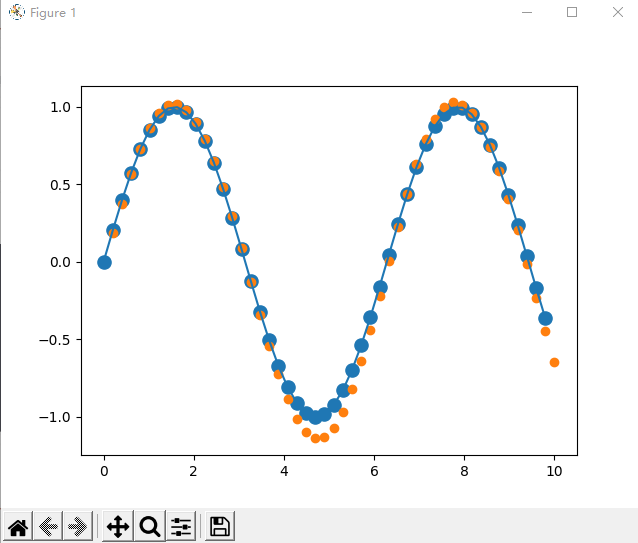
迭代6000次的图像:
完整代码:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from matplotlib import pyplot as plt
num_time_steps = 50
input_size = 1
hidden_size = 16
output_size = 1
lr=0.01class Net(nn.Module):def __init__(self, ):super(Net, self).__init__()self.rnn = nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=1,batch_first=True,)for p in self.rnn.parameters():nn.init.normal_(p, mean=0.0, std=0.001)self.linear = nn.Linear(hidden_size, output_size)def forward(self, x, hidden_prev):out, hidden_prev = self.rnn(x, hidden_prev)# [b, seq, h]out = out.view(-1, hidden_size)out = self.linear(out) # [seq,h] => [seq,1]out = out.unsqueeze(dim=0)# [1,seq,1]return out, hidden_prevmodel = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr)hidden_prev = torch.zeros(1, 1, hidden_size)for iter in range(200):start = np.random.randint(10, size=1)[0]time_steps = np.linspace(start, start + 10, num_time_steps)data = np.sin(time_steps)data = data.reshape(num_time_steps, 1)x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)output, hidden_prev = model(x, hidden_prev)hidden_prev = hidden_prev.detach() #不会具有梯度loss = criterion(output, y)model.zero_grad()loss.backward()optimizer.step()if iter % 100 == 0:print("Iteration: {} loss {}".format(iter, loss.item()))start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)predictions = []
input = x[:, 0, :]
for _ in range(x.shape[1]):input = input.view(1, 1, 1)(pred, hidden_prev) = model(input, hidden_prev)input = predpredictions.append(pred.detach().numpy().ravel()[0])x = x.data.numpy().ravel()
y = y.data.numpy()
plt.scatter(time_steps[:-1], x, s=90)
plt.plot(time_steps[:-1], x)plt.scatter(time_steps[1:], predictions)
plt.show()
五、梯度弥散和梯度爆炸问题
- 梯度弥散(消失):由于导数的链式法则,连续多层小于1的梯度相乘会使梯度越来越小,最终导致某层梯度为0。梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系
- 梯度爆炸:初始化权值过大,梯度更新量是会成指数级增长的,前面层会比后面层变化的更快,就会导致权值越来越大
上面两个问题都是RNN训练时的难题,解决它们需要不断的实操经验和更加升入的理解
相关文章:
ccc-pytorch-RNN(7)
文章目录一、RNN简介二、RNN关键结构三、RNN的训练方式四、时间序列预测五、梯度弥散和梯度爆炸问题一、RNN简介 RNN(Recurrent Neural Network)中文循环神经网络,用于处理序列数据。它与传统人工神经网络和卷积神经网络的输入和输出相互独立…...
)
docker安装(linux)
安装需要的软件包 yum install -y yum-utils 设置stable镜像仓库(使用阿里云镜像) yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo 更新yum软件包索引 yum makecache fast 安装DOCKER 引擎 yum -y…...

【数据库概论】10.1 事务及其作用
事务是一系列的数据库操作,是数据库应用程序的基本逻辑单元 10.1 事务的基本概念 1.事务 事务是用户定义的一个数据库操作序列,是一个具有原子性的操作,不可再分,一个事务内的操作要么全做、要么都不做。一般来说,一…...

通讯录(C++实现)
系统需求通讯录是一个可以记录亲人、好友信息的工具。本章主要利用C来实现一个通讯录管理系统系统中需要实现的功能如下:添加联系人:向通讯录中添加新人,信息包括(姓名、性别、年龄、联系电话、家庭住址)最多记录1000人显示联系人:显示通讯录…...

轻松掌握C++的模板与类模板,将Tamplate广泛运用于我们的编程生活
C提高编程 本阶段主要针对C泛型编程和STL技术做详细讲解,探讨C更深层的使用 泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。 模板 1.模板的概念 模板就是建立通用的模具,大大提高复用性 例如: 2.函数模板 C另一种编程思想称…...
pandas 数据预处理+数据概览 处理技巧整理(持续更新版)
这篇文章主要是整理下使用pandas的一些技巧,因为经常不用它,这些指令忘得真的很快。前段时间在数模美赛中已经栽过跟头了,不希望以后遇到相关问题的时候还去网上查(主要是太杂了)。可能读者跟我有一样的问题࿰…...
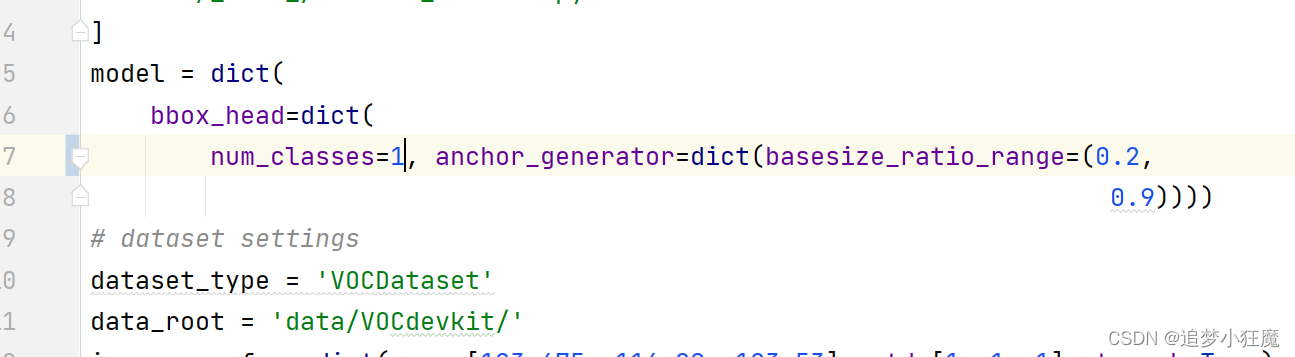
mmdetectionV2.x版本 训练自己的VOC数据集
mmdetection目录下创建data文件夹,路劲如图所示,不带yololabels 修改配置文件 mmdet/datasets/voc.py 配置图片格式 mmdet/datasets/xml_style.py 如果图片是jpg则改成jpg,是png格式就改成png,这里我不需要改,本…...

Shell - crontab 定时 git 拉取并执行 maven 打包
目录 一.引言 二.踩坑与实践 1.原始代码 2.mvn package 未执行与解决 [导入环境变量] 3.git pull 未执行与解决 [添加绝对路径] 三.总结 一.引言 git 任务部署在通道机,每天6点需要定时更新 jar 包并打包上线,所以需要在 linux 服务器上ÿ…...
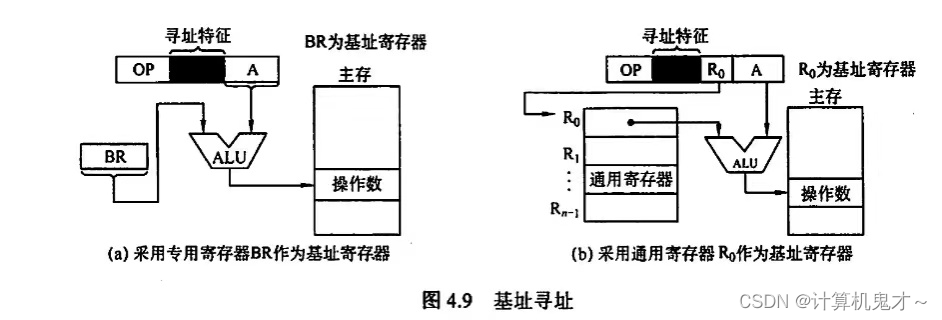
408考研计算机之计算机组成与设计——知识点及其做题经验篇目3:指令的寻址方式
上篇文章我们讲到,指令的基本格式,一条指令通常包括操作码字段和地址码字段两部分: 操作码字段地址码字段并且我们还讲到根据操作数地址码的数目不同,可将指令分为零一二三四地址指令。感兴趣的小伙伴们可以看看小编的上一篇文章…...

前端包管理工具:npm,yarn、cnpm、npx、pnpm
包管理工具npm Node Package Manager,也就是Node包管理器; 但是目前已经不仅仅是Node包管理器了,在前端项目中我们也在使用它来管理依赖的包; 比如vue、vue-router、vuex、express、koa、react、react-dom、axios、babel、webpack…...

推荐系统 FM因式分解
reference:知乎 FM算法解析 LR算法没有二阶交叉 如果是id类特征,这里的x是0/1,raw的特征输入就是float,当然,在我的理解里,一般会把raw的特征进行分桶,还是映射到0/1特征,不然这个w…...
Maven基础入门
文章目录Maven简介Maven 工作模式1.仓库2.坐标Maven的基本使用1.常用命令2.生命周期依赖管理1.依赖配置2.依赖传递3.可选依赖4.排除依赖5.依赖范围IDEA配置MavenMaven简介 Apache Maven 是一个项目管理和构建工具,它基于项目对象模型(POM)的概念,通过一…...
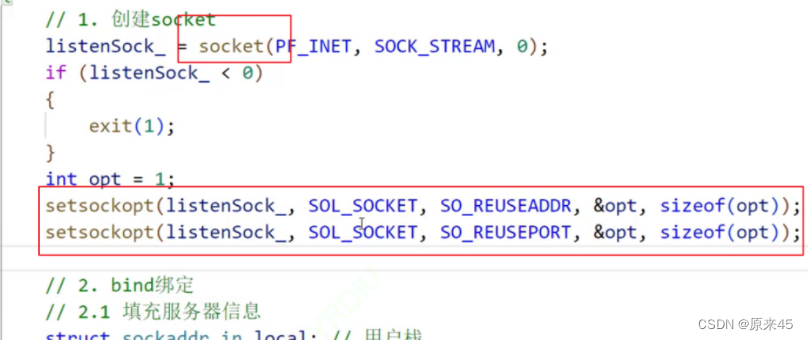
传输层协议 TCP UDP
目录 协议前菜 端口号 编辑端口号范围划分 认识知名端口号(Well-Know Port Number) netstat pidof 传输层协议 UDP协议 UDP协议端格式 UDP的特点 面向数据报 UDP的缓冲区 UDP使用注意事项 基于UDP的应用层协议 TCP协议 TCP协议概念 TCP协议段格式 标志…...
一点就分享系列(实践篇6——上篇)【迟到补发】Yolo-High_level系列算法开源项目融入V8 旨在研究和兼容使用【持续更新】
一点就分享系列(实践篇5-补更篇)[迟到补发]—Yolo系列算法开源项目融入V8旨在研究和兼容使用[持续更新] 题外话 去年我一直复读机式强调High-level在工业界已经饱和的情况,目的是呼吁更多人看准自己,不管是数字孪生交叉领域&#…...
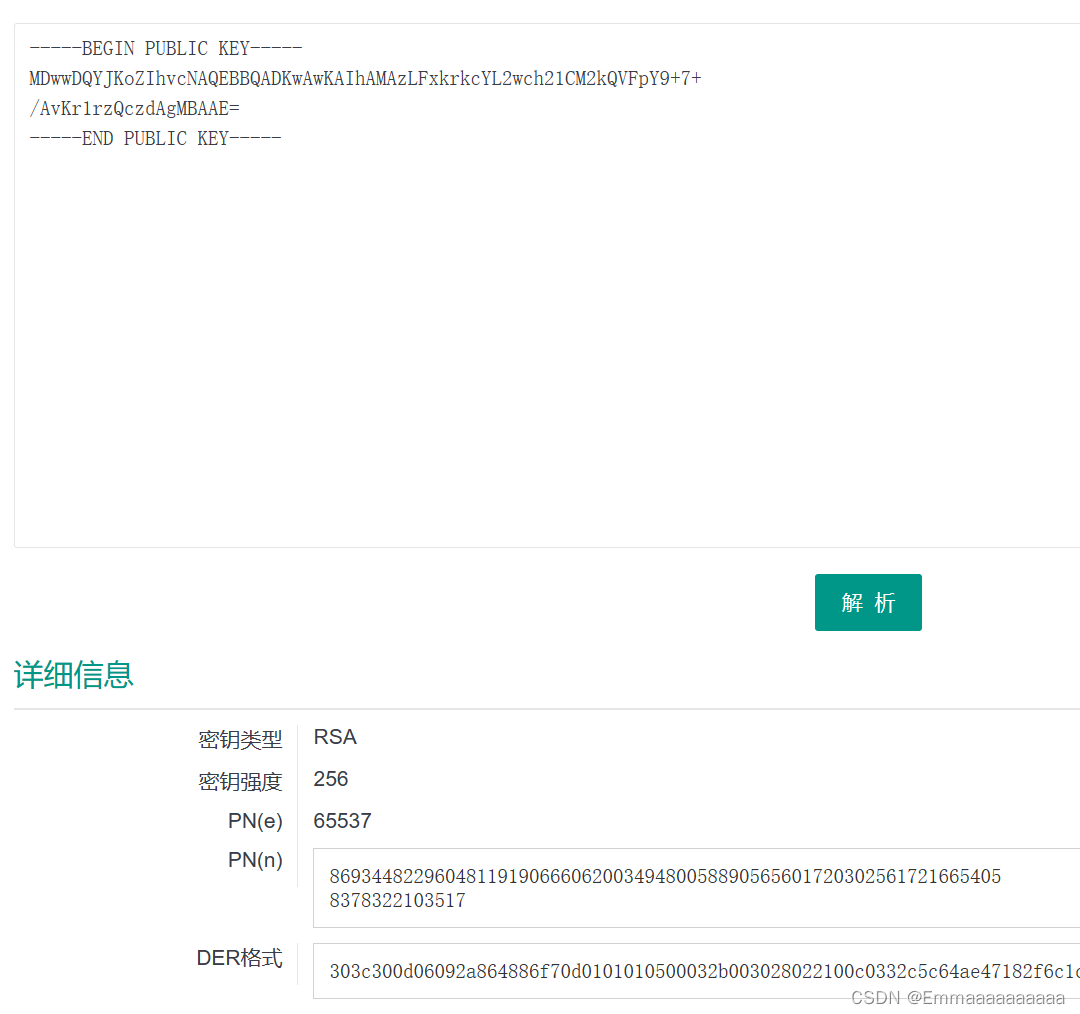
buu RSA 1 (Crypto 第一页)
题目描述: 两个文件,都用记事本打开,记住用记事本打开 pub.key: -----BEGIN PUBLIC KEY----- MDwwDQYJKoZIhvcNAQEBBQADKwAwKAIhAMAzLFxkrkcYL2wch21CM2kQVFpY97 /AvKr1rzQczdAgMBAAE -----END PUBLIC KEY-----flag.enc: A柪YJ^ 柛x秥?y…...

Python 二分查找:bisect库的使用
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...
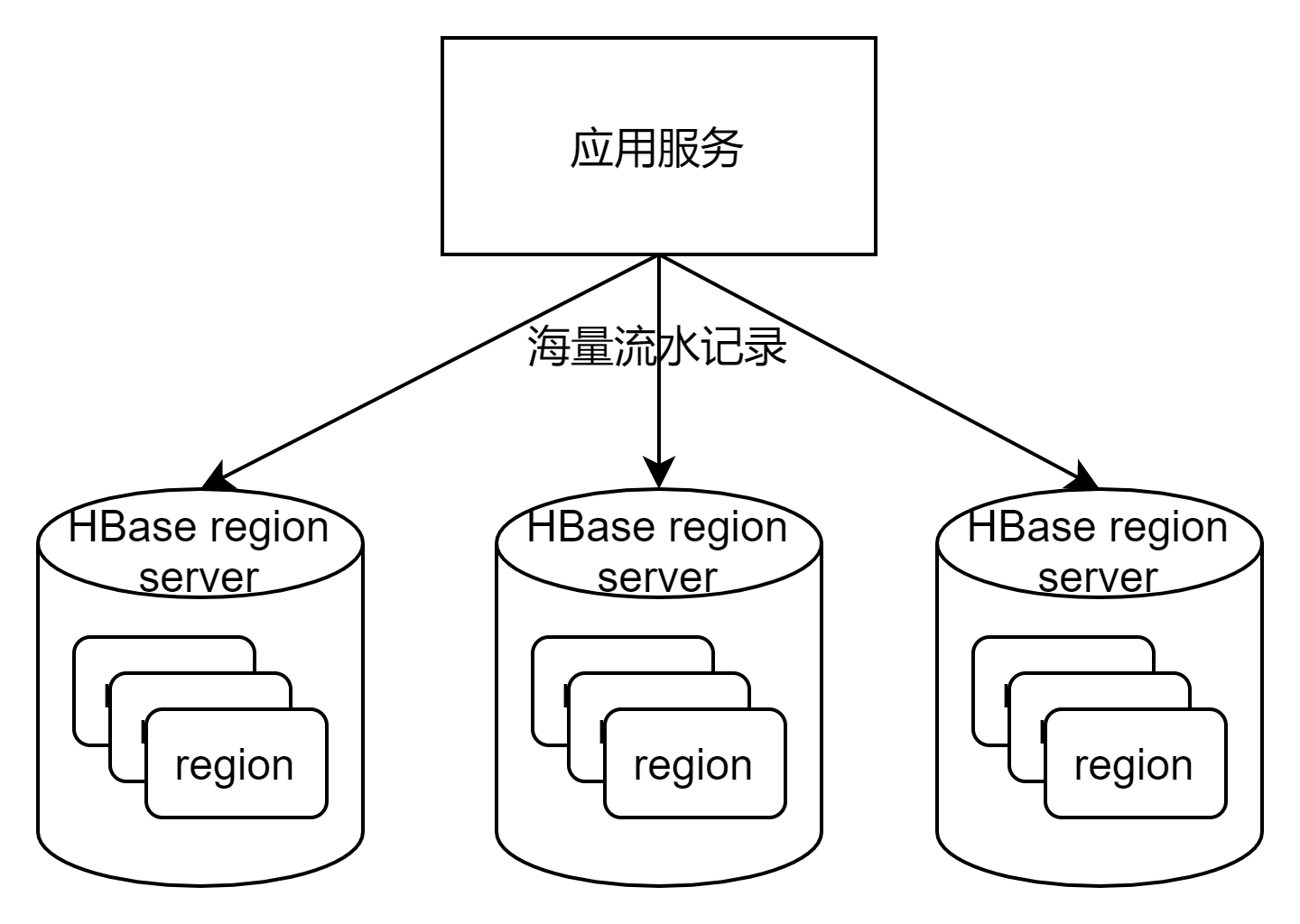
性能优化之HBase性能调优
HBase是Hadoop生态系统中的一个组件,是一个分布式、面向列存储的内存型开源数据库,可以支持数百万列(MySQL4张表在HBase中对应1个表,4个列)、超过10亿行的数据存储。可用作:冷热数据分离HBase适合作为冷数据…...

图像金字塔,原理、实现及应用
什么是图像金字塔 图像金字塔是对图像的一种多尺度表达,将各个尺度的图像按照分辨率从小到大,依次从上到下排列,就会形成类似金字塔的结构,因此称为图像金字塔。 常见的图像金字塔有两类,一种是高斯金字塔࿰…...
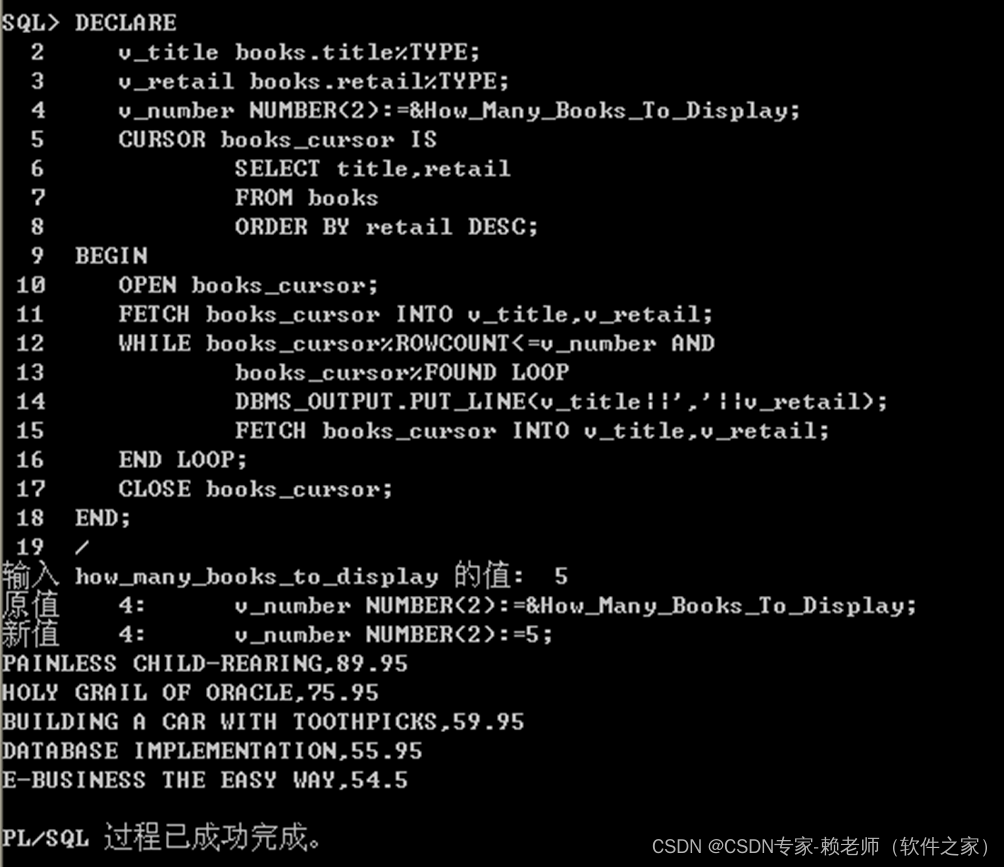
08-Oracle游标管理(定义,打开、获取数据及关闭游标)
目标 1.确定何时需要显示游标2.声明、打开和关闭显示游标3.从显示游标中提取数据4.了解与游标有关的属性5.使用游标FOR循环检索游标中的数据6.在游标FOR循环的子查询中声明游标7.评估使用逻辑运算符结合在一起的布尔条件游标 1、在使用一个PL/SQL块来执行DML语句或只返回一行结…...

Python判断字符串是否包含特定子串的7种方法
目录1、使用 in 和 not in2、使用 find 方法3、使用 index 方法4、使用 count 方法5、通过魔法方法6、借助 operator7、使用正则匹配转自:https://cloud.tencent.com/developer/article/1699719我们经常会遇这样一个需求:判断字符串中是否包含某个关键词…...

C++智能指针详解:原理、使用及避坑指南
文章目录 前言 一、智能指针核心原理:RAII机制 二、C常用智能指针详解(重点掌握后两种) 三、智能指针高频坑点(重中之重) 四、三大智能指针对比(选择指南) 五、实战案例:智能指…...

NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿
NHSE:5分钟掌握动物森友会存档编辑,打造你的完美岛屿 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 你是否曾经为了收集某个稀有家具而花费数周时间?是否因为地…...

别只把Docker当虚拟机!《Docker实践》没细说的5个生产环境‘骚操作’
别只把Docker当虚拟机!5个生产环境高阶实践指南 当团队从开发测试转向生产环境时,Docker的使用方式往往需要质的飞跃。许多工程师在初期将容器简单视为轻量级虚拟机,却忽略了容器化架构真正的威力。本文将揭示那些官方文档鲜少提及࿰…...

Cursor编辑器配置重置工具:自动化清理与恢复出厂设置
1. 项目概述与核心价值 最近在折腾代码编辑器,特别是像 Cursor 这类深度整合了 AI 能力的 IDE,发现一个挺有意思但容易被忽略的问题: 编辑器配置的“熵增” 。简单来说,就是你用久了之后,各种插件、主题、快捷键、代…...

国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案
国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内…...

嵌入式Linux SPI屏驱动踩坑实录:fbtft模块加载失败与dmesg排错指南
嵌入式Linux SPI屏驱动深度排错指南:从dmesg到硬件配置的全链路解析 当你在树莓派或全志H3开发板上折腾那块SPI接口的TFT屏幕时,是否经历过这样的绝望时刻?设备树配置看起来完美无缺,insmod命令执行后却只收获一片漆黑的屏幕和满屏…...

APK Installer终极指南:如何在Windows上快速安装安卓应用?
APK Installer终极指南:如何在Windows上快速安装安卓应用? 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows上安装安卓应用而烦恼吗…...

基于Chrome DevTools协议实现AI与浏览器实时交互的实践指南
1. 项目概述:让AI与你的浏览器实时对话如果你正在探索如何让AI助手(比如Claude、GPTs或者你自己开发的智能体)不只是处理静态文本,而是能“看到”并操作你正在浏览的真实网页,那么你很可能已经接触过“浏览器自动化”这…...

LabVIEW数字IO编程避坑指南:单点采样、连续采样到底怎么选?NI-MAX测试面板帮你验证
LabVIEW数字IO编程实战:采样模式选择与NI-MAX验证全攻略 在工业自动化测试领域,LabVIEW的数字IO模块是最基础也最常用的功能之一。许多工程师在初次接触数字IO编程时,往往会被各种采样模式搞得晕头转向——单点采样、N采样、连续采样…...

告别模拟器!3种方法在Windows上直接安装Android应用
告别模拟器!3种方法在Windows上直接安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上流畅运行Android应用,却厌…...