爬虫基本原理?介绍|实现|问题解决
爬虫基本原理:
-
模拟用户行为:
- 网络爬虫(Web Crawler)是一种自动化的程序,它模拟人类用户访问网站的方式,通过发送HTTP/HTTPS请求到服务器以获取网页内容。
-
请求与响应:
- 爬虫首先构建并发送带有特定URL和其他可能的请求头(如User-Agent、Cookie等)的HTTP请求。
- 服务器接收到请求后,根据请求内容返回HTTP响应,其中包括状态码、响应头以及网页的HTML、JSON或其他格式的数据。
-
数据解析:
- 收到响应后,爬虫需要解析响应中的有效数据,通常通过HTML或XML解析器,提取有用的信息(如文本、链接、图片等)。
-
链接跟踪与调度:
- 在解析过程中,爬虫会发现新的URL链接并将其加入待抓取队列,遵循一定的抓取策略(如深度优先搜索DFS、广度优先搜索BFS等)继续遍历网络。
-
遵守协议与策略:
- 爬虫需遵守网站的robots.txt文件规定,尊重网站的抓取频率限制,以免对服务器造成过大压力。
- 高效爬虫还需要处理各种反爬机制,如验证码、IP限制、动态加载内容等问题。
爬虫实现:
-
工具与库:
- Python是最常用的爬虫开发语言之一,其中
requests库用于发送HTTP请求,BeautifulSoup、lxml等库用于解析HTML,Scrapy、PyQuery等框架提供更完整的爬虫解决方案。 - 其他编程语言也有相应的库,如JavaScript的Puppeteer、Java的Jsoup和HttpClient等。
- Python是最常用的爬虫开发语言之一,其中
-
工作流程实现:
- 初始化爬虫,设置起始URL。
- 发送请求,获取响应内容。
- 解析响应内容,提取数据并存储。
- 检测到新链接时,将它们加入待抓取队列。
- 根据爬虫策略循环执行上述步骤直至达到停止条件(如抓取完成指定数量的页面、无更多可抓取链接等)。
import requests
from bs4 import BeautifulSoup
import time# 初始URL列表(待抓取队列)
start_urls = ['http://example.com']
visited_urls = set() # 已访问URL集合,防止重复抓取def crawl(url):if url in visited_urls:returnvisited_urls.add(url)# 发送请求,获取响应内容response = requests.get(url)response.raise_for_status() # 如果响应状态不是200,则抛出异常# 解析响应内容soup = BeautifulSoup(response.text, 'html.parser')# 提取并存储数据(这里仅示例提取a标签的href属性作为链接)for link in soup.find_all('a'):href = link.get('href')if href and href.startswith('http'):print(f'Found new link: {href}')# 将新链接加入待抓取队列(此处仅为演示打印出来,实际应用中应添加到队列中)crawl(href)# 实际项目中可能需要在此处存储其他所需数据# 主程序,循环抓取直到满足停止条件
while start_urls:current_url = start_urls.pop(0)crawl(current_url)time.sleep(1) # 添加延时,避免频繁请求导致被封IP# 假设爬虫策略是抓取完初始URL列表即停止
print("Crawling finished.")# 注:本示例为简单单线程爬虫,实际项目中可能需要用到多线程/异步IO、队列管理等更复杂的技术
爬虫问题解决:
-
反爬措施应对:
- 使用代理IP池避免IP被封禁。
- 动态更换User-Agent伪装成不同浏览器。
- 处理JavaScript渲染的动态页面,可能需要使用Selenium等工具模拟浏览器环境。
- 对于验证码,可以通过OCR识别或使用第三方服务绕过。
-
性能优化:
- 异步IO或多线程/多进程提高并发请求能力。
- 缓存已访问过的网页或请求结果,减少重复抓取。
- 设计合理的爬取延迟,避免给目标网站带来过大负担。
-
合法性与道德规范:
- 遵守相关法律法规,确保爬取数据不侵犯隐私,不违反版权法等。
- 尊重网站的服务条款和API使用政策。
设计和实现一个爬虫需要综合运用网络请求、数据解析、队列管理、策略设计等多种技术手段,并且在实际运行中不断调试和优化,以适应不同网站的结构特点和反爬策略。同时,始终关注法律和伦理边界,确保合法合规地获取和使用数据。
相关文章:

爬虫基本原理?介绍|实现|问题解决
爬虫基本原理: 模拟用户行为: 网络爬虫(Web Crawler)是一种自动化的程序,它模拟人类用户访问网站的方式,通过发送HTTP/HTTPS请求到服务器以获取网页内容。 请求与响应: 爬虫首先构建并发送带有…...
)
DevOps的原理及应用详解(六)
本系列文章简介: 在当今快速变化的商业环境中,企业对于软件交付的速度、质量和安全性要求日益提高。传统的软件开发和运维模式已经难以满足这些需求,因此,DevOps(Development和Operations的组合)应运而生&a…...
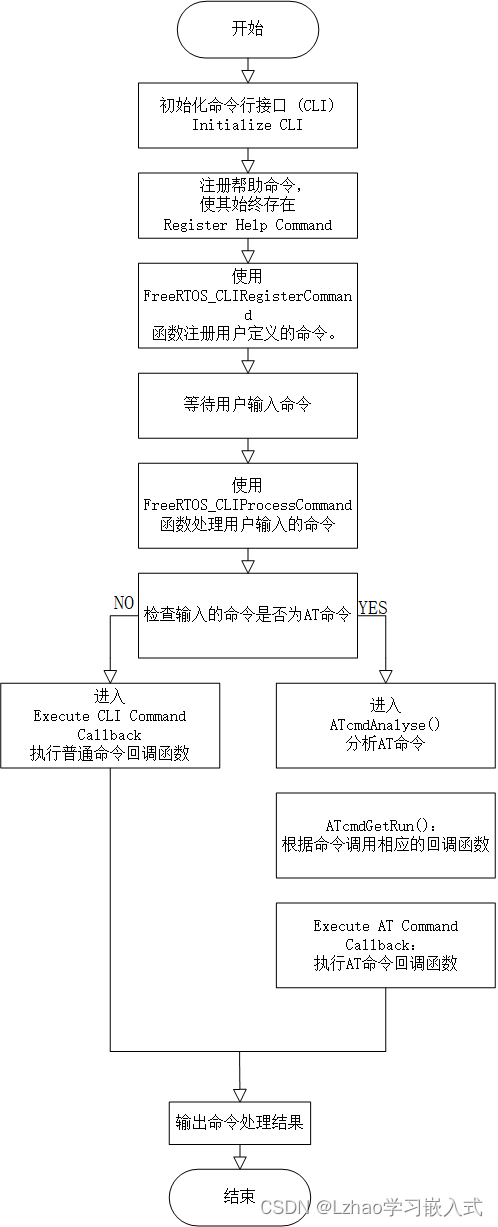
手撸 串口交互命令行 及 AT应用层协议解析框架
在嵌入式系统开发中,命令行接口(CLI)和AT命令解析是常见的需求。CLI提供了方便的调试接口,而AT命令则常用于模块间的通信控制。本文将介绍如何手动实现一个串口交互的命令行及AT应用层协议解析框架,适用于FreeRTOS系统…...

Redis几种部署模式介绍
Redis 提供了几种不同的部署模式,以满足不同的使用场景和可用性需求。这些模式包括单机模式、主从复制、哨兵模式和集群模式。下面我将简要介绍每种模式的特点和用途: 单机模式: 描述:单个 Redis 服务器实例运行在一台机器上&…...
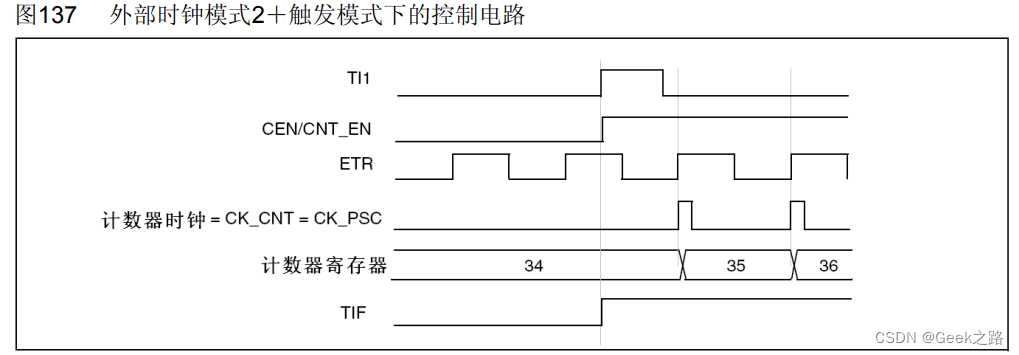
【STM32HAL库学习】定时器功能、时钟以及各种模式理解
一、文章目的 记录自己从学习了定时器理论->代码实现使用定时->查询数据手册,加深了对定时器的理解以及该过程遇到了的一些不清楚的知识。 上图为参考手册里通用定时器框图,关于定时器各种情况的工作都在上面了,在理论学习和实际应用后…...

3588麒麟系统硬解码实战
目录 安装rockchip-mpp deb 查找头文件 .pro文件添加 检查库是否已安装 error: stdlib.h: No such file or directory ffmpeg 查找ffmpeg路径: 查找FFmpeg库和头文件的位置 使用pkg-config工具查找FFmpeg路径 ok的ffmpeg配置: ffmpeg查看是否支持libx264 ffmpeg …...

十二 nginx中location重写和匹配规则
十二 location匹配规则 ^~ ~ ~* !~ !~* /a / 内部服务跳转 十三 nginx地址重写rewrite if rewrite set return 13.1 if 应用环境 server location -x 文件是否可执行 $args $document_rot $host $limit_rate $remote_addr $server_name $document_uri if …...

python的视频处理FFmpeg库使用
FFmpeg 是一个强大的多媒体处理工具,用于录制、转换和流式传输音频和视频。它支持几乎所有的音频和视频格式,并且可以在各种平台上运行。FFmpeg 在 Python 中的使用可以通过调用其命令行工具或使用专门的库如 ffmpeg-python。以下是详细介绍如何在 Python 中使用 FFmpeg,包括…...

接口测试时, 数据Mock为何如此重要?
一、为什么要mock 工作中遇到以下问题,我们可以使用mock解决: 1、无法控制第三方系统某接口的返回,返回的数据不满足要求 2、某依赖系统还未开发完成,就需要对被测系统进行测试 3、有些系统不支持重复请求,或有访问…...

未授权与绕过漏洞
1、Laravel Framework 11 - Credential Leakage(CVE-2024-29291)认证泄漏 导航这个路径storage/logs/laravel.log搜索以下信息: PDO->__construct(mysql:host 2、 Flowise 1.6.5 - Authentication Bypass(CVE-2024-31621&am…...

云原生周刊:Kubernetes 十周年 | 2024.6.11
开源项目推荐 Kubernetes Goat Kubernetes Goat 是一个故意设计成有漏洞的 Kubernetes 集群环境,旨在通过交互式实践场地来学习并练习 Kubernetes 安全性。 kube-state-metrics (KSM) kube-state-metrics 是一个用于收集 Kubernetes 集群状态信息的开源项目&…...
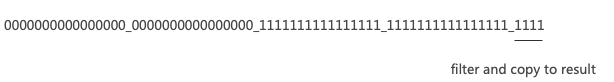
ClickHouse内幕(1)数据存储与过滤机制
本文主要讲述ClickHouse中的数据存储结构,包括文件组织结构和索引结构,以及建立在其基础上的数据过滤机制,从Part裁剪到Mark裁剪,最后到基于SIMD的行过滤机制。 数据过滤机制实质上是构建在数据存储格式之上的算法,所…...

1.Mongodb 介绍及部署
MongoDB 是一个开源的文档导向数据库,采用NoSQL(非关系型数据库)的设计理念。MongoDB是一个基于分布式文件存储的数据库。 分布式文件存储是一种将文件数据分布式的存储在多台计算机上。MongoDB是一款强大的文档导向数据库,适合处…...

Java 技巧:如何获取字符串中最后一个英文逗号后面的内容
在日常的Java编程中,处理字符串是非常常见的任务之一。有时我们需要从一个字符串中截取特定部分,例如获取最后一个英文逗号后的内容。这篇文章将详细介绍如何使用Java来实现这一需求,并提供一个示例代码来演示其实现过程。 需求分析 假设我们…...
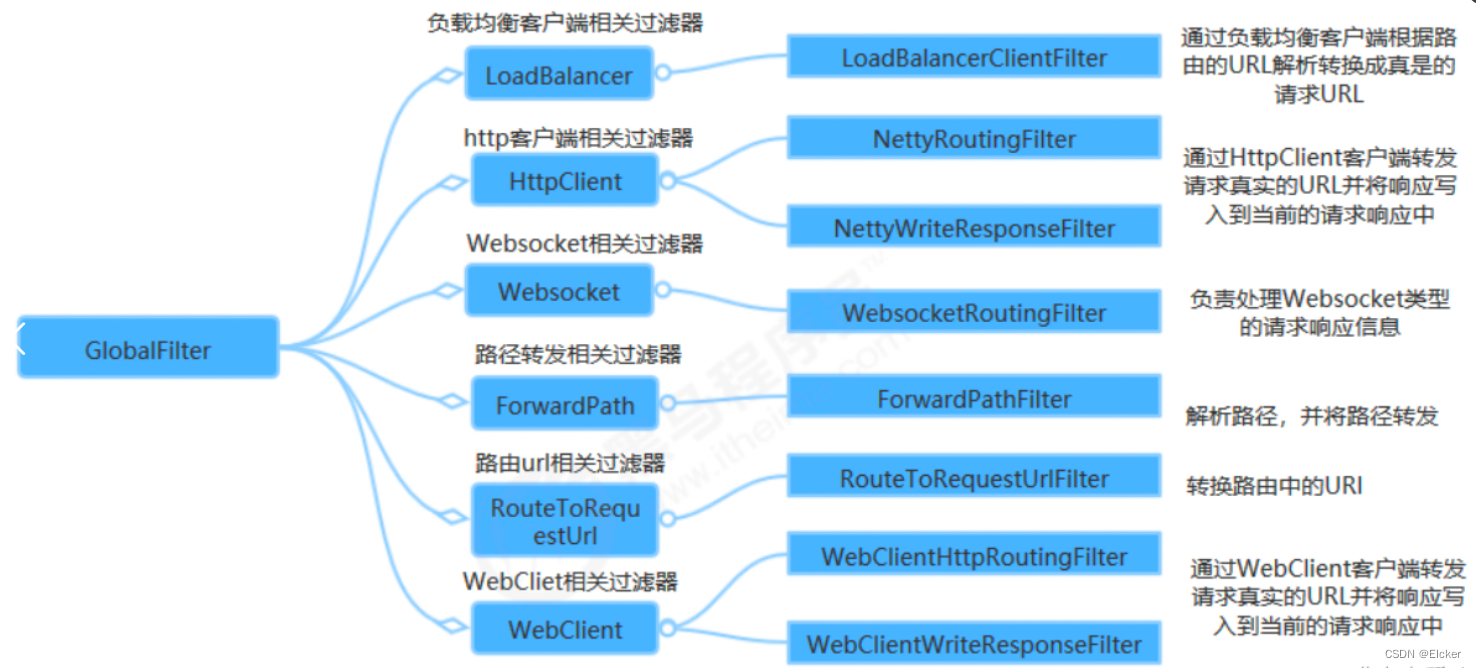
玩转微服务-GateWay
目录 一. 背景二. API网关1. 概念2. API网关定义3. API网关的四大职能4. API网关分类5. 开源API网关介绍6. 开源网关的选择 三. Spring Cloud Gateway1. 文档地址2. 三个核心概念3. 工作流程4. 运行原理4.1 路由原理4.2 RouteLocator 5. Predicate 断言6. 过滤器 Filter6.1. 过…...

Amortized bootstrapping via Automorphisms
参考文献: [MS18] Micciancio D, Sorrell J. Ring packing and amortized FHEW bootstrapping. ICALP 2018: 100:1-100:14.[GPV23] Guimares A, Pereira H V L, Van Leeuwen B. Amortized bootstrapping revisited: Simpler, asymptotically-faster, implemented. …...

【人工智能】ChatGPT基本工作原理
ChatGPT 是由 OpenAI 开发的一种基于深度学习技术的自然语言处理模型,它使用了名为 GPT(Generative Pre-trained Transformer)的架构。GPT 模型是一种基于 Transformer 架构的预训练语言模型,它通过大量的文本数据进行预训练&…...
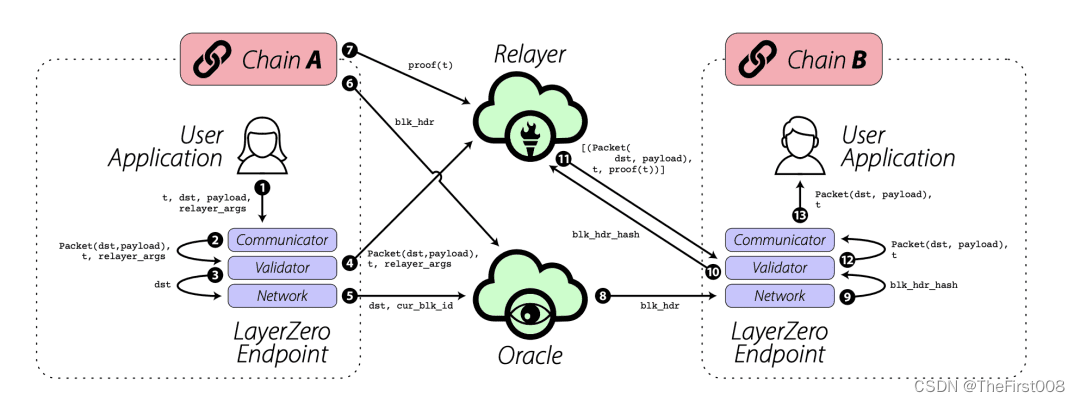
The First项目报告:Stargate Finance重塑跨链金融的未来
Stargate Finance是一个基于LayerZero协议的去中心化金融平台,自2022年3月由LayerZero Labs创建以来,一直致力于为不同区块链之间的资产转移提供高效、低成本的解决方案。凭借其独特的跨链技术和丰富的DeFi服务,Stargate Finance已成为连接不…...

Python魔法之旅-魔法方法(22)
目录 一、概述 1、定义 2、作用 二、应用场景 1、构造和析构 2、操作符重载 3、字符串和表示 4、容器管理 5、可调用对象 6、上下文管理 7、属性访问和描述符 8、迭代器和生成器 9、数值类型 10、复制和序列化 11、自定义元类行为 12、自定义类行为 13、类型检…...
)
公司面试题总结(三)
13.说说你对 BOM 的理解,常见的 BOM 对象你了解哪些? BOM (Browser Object Model),浏览器对象模型, ⚫ 提供了独立于内容与浏览器窗口进行交互的对象 ⚫ 其作用就是跟浏览器做一些交互效果 ⚫ 比如如何进行页面的后退&…...
高效实现Windows任务栏个性化的5个极简方案:轻量级透明化工具TranslucentTB全指南
高效实现Windows任务栏个性化的5个极简方案:轻量级透明化工具TranslucentTB全指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB …...
)
保姆级教程:用 Modelfile 快速部署 ModelScope 的 GGUF 模型到 Ollama(以 DeepSeek 为例)
从零到一:用Modelfile高效部署ModelScope的GGUF模型至Ollama实战指南 在本地运行大语言模型正成为开发者探索AI边界的新常态。不同于直接调用云端API,本地部署能带来数据隐私保障、响应速度提升以及模型深度定制等独特优势。Ollama作为轻量级模型运行框架…...

西门子S7-1200 PLC如何通过EtherCat转Profinet网关实现高效IO控制?5步搞定配置
西门子S7-1200 PLC与EtherCat设备的高效集成:5步实现Profinet网关配置 在工业自动化领域,不同协议设备之间的无缝通信一直是工程师面临的挑战。当您需要将EtherCat设备接入西门子S7-1200 PLC的Profinet网络时,协议转换网关成为关键桥梁。本文…...

VS2022项目复制后报错打不开?别慌,手把手教你用记事本5分钟修复.sln文件
VS2022项目复制后报错打不开?记事本5分钟修复.sln文件全指南 刚复制完的VS2022项目一打开就报错?解决方案资源管理器一片空白?别急着重装或放弃,这很可能只是.sln文件中的路径需要手动更新。作为经历过数十次类似问题的开发者&…...

Windows系统下Python 3.11环境配置全攻略
1. Python 3.11环境配置前的准备工作 在开始安装Python 3.11之前,我们需要做一些准备工作。首先确认你的Windows系统版本,右键点击"此电脑"选择"属性",在系统类型中查看是32位还是64位系统。Python 3.11官方已经停止对32…...
)
WPF图片处理避坑指南:Image控件Stretch属性的4种模式详解(含效果对比图)
WPF图片处理避坑指南:Image控件Stretch属性的4种模式详解 刚接触WPF开发的工程师们,是否经常遇到图片显示变形、比例失调的困扰?Image控件的Stretch属性看似简单,却藏着不少设计哲学。今天我们就来彻底拆解这个影响图片显示效果的…...

从Kinect到奥比中光:为什么我的深度学习项目选了Gemini 2L?附Python SDK踩坑实录
从Kinect到奥比中光:为什么我的深度学习项目选了Gemini 2L?附Python SDK踩坑实录 深度视觉技术正在重塑人机交互的边界。当我的团队启动一个需要实时三维重建的农业机器人项目时,我们面临着一个关键抉择:在众多深度相机品牌中&…...

ChatTTS 安装与部署实战:从零搭建到性能调优
最近在做一个语音合成的项目,选型时看中了 ChatTTS,它开源的特性、不错的音质和可控性很吸引人。但在实际动手安装和部署时,发现从个人电脑跑起来到服务器上稳定服务,中间有不少坑。今天就把我这一路从零搭建到性能调优的实战经验…...

七年之痒:从零复现MaskRCNN的踩坑与重生指南
1. 为什么2024年还要复现MaskRCNN? 七年前第一次看到MaskRCNN的物体检测效果时,那种震撼感至今难忘。作为首个实现实例分割的经典网络,它在COCO数据集上展现的精准边界识别能力,让当时还在用Faster R-CNN的我们直呼"魔法&quo…...

无限级数求和与Java实现优化教程
本教程详细讨论了如何准确计算形状 S -(2x)^2/2! (2x)^4/4! - (2x)^6/6! ... 指定范围内的无限级数 [0.1, 1.5] 内部和。文章首先分析了这个级数和 cos(2x) - 1 数学等价性,然后对Java代码中常见的错误进行了深入分析ÿ…...