encoding Token和embedding 傻傻分不清楚?
encoding 编码
“encoding” 是一个在计算机科学和人工智能领域广泛使用的术语,它可以指代多种不同的过程和方法。核心就是编码:用某些数字来表示特定的信息。当然你或许会说字符集(Unicode)更理解这种概念,编码更强调这种动态的过程。而字符集是静态的。以下是一些具体的例子和用法,帮助你更全面地理解这个概念:
字符编码(Character Encoding)
UTF-8 Encoding:将Unicode字符转换为字节序列。
text = "你好,世界"
encoded_text = text.encode('utf-8')
print(encoded_text) # 输出: b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c'
Base64 Encoding:将二进制数据编码为ASCII字符串,常用于在URL、电子邮件等中传输二进制数据。
一般我们调用云服务进行什么QQ截图识别,截图的这个图像就是通过base64字符串进行传播的。
import base64
data = b"hello world"
encoded_data = base64.b64encode(data)
print(encoded_data) # 输出: b'aGVsbG8gd29ybGQ='
序列编码(Sequence Encoding)
例如独热编码(One-Hot Encoding):将分类数据转换为二进制向量,每个向量中只有一个高位(1),其余为低位(0)。
from sklearn.preprocessing import OneHotEncoder
import numpy as npcategories = np.array(['apple', 'banana', 'cherry']).reshape(-1, 1)
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(categories)
print(one_hot_encoded)
# 输出: [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
词嵌入(Word Embeddings)
是的,Embedding其实也是一种encoding,更广义的,一篇文章切分成块以后,也可以把文本块转成成特定的向量。这里的word Embeddings特指把英文单词表示为向量。(杠精问中文单词怎么办,中文需要在进入embeddings前加一道分词的工序)
例如 Word2Vec:将单词表示为向量,使得语义相似的单词在向量空间中距离较近。
from gensim.models import Word2Vecsentences = [["hello", "world"], ["machine", "learning"], ["word", "embeddings"]]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
vector = model.wv['hello']
print(vector) # 输出: [0.1, -0.2, ..., 0.05] # 维度为100的向量
位置编码(Positional Encoding)
正弦和余弦位置编码(Sinusoidal Positional Encoding):在Transformer模型中用于注入位置信息。
import torch
import mathdef positional_encoding(max_len, d_model):pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)return pemax_len = 50
d_model = 512
pos_enc = positional_encoding(max_len, d_model)
print(pos_enc.shape) # 输出: torch.Size([50, 512])
图像编码(Image Encoding)
JPEG Encoding:将图像数据压缩并编码为JPEG格式。
from PIL import Image
import ioimage = Image.open("example.jpg")
buffer = io.BytesIO()
image.save(buffer, format="JPEG")
jpeg_encoded_image = buffer.getvalue()
print(jpeg_encoded_image[:10]) # 输出图像文件的前10个字节
PNG Encoding:将图像数据编码为PNG格式。
from PIL import Image
import ioimage = Image.open("example.png")
buffer = io.BytesIO()
image.save(buffer, format="PNG")
png_encoded_image = buffer.getvalue()
print(png_encoded_image[:10]) # 输出图像文件的前10个字节
Token
计算机领域
Token这一次不是最近才出现的,在计算机领域是早已有之。在计算机科学的早期,人们主要使用低级语言,如机器语言和汇编语言,直接与计算机硬件进行交互。这些语言的指令通常直接对应于计算机的基本操作,不需要像高级语言那样经过复杂的编译或解释过程。
随着高级编程语言的出现,如FORTRAN(1957)、COBOL(1959)、ALGOL(1960)等,编译器和解释器开始扮演重要的角色。这些语言引入了更抽象、更接近人类语言的语法和结构,需要通过编译或解释的过程转换为计算机可以直接执行的低级指令。
在这个过程中,词法分析(Lexical Analysis)作为编译器或解释器的第一步,负责将源代码划分为一系列的token。token的概念在这个时期开始在计算机领域广泛使用,用于表示源代码中的基本单元,如关键字、标识符、字面量等。
下面是一些编程语言中token的例子:
In C++:
- Keywords: if, else, for, while, int, float, etc.
- 关键字: if, else, for, while, int, float 等。
- Identifiers: variable names, function names, etc.
- 标识符: 变量名,函数名等。
- Operators: +, -, *, /, =, ==, !=, etc.
- 运算符: +, -,*, /, =, ==, != 等。
- Literals: 42, 3.14, “Hello, world!”, etc.
- 字面量: 42, 3.14, “Hello, world!” 等。(注意,在编译器的语言环境里,字面量这么一个字符串,就是一个token,和后面人工智能领域token的概念有差别.)
In Python:
- Keywords: if, elif, else, for, while, def, class, etc.
- 关键字: if, elif, else, for, while, def, class 等。
- Identifiers: variable names, function names, class names, etc.
- 标识符: 变量名,函数名,类名等。
- Operators: +, -, *, /, =, ==, !=, in, not, etc.
- 运算符: +, -, *, /, =, ==, !=, in, not 等。
- Literals: 42, 3.14, “Hello, world!”, [1, 2, 3], {“key”: “value”}, etc.
- 字面量: 42, 3.14, “Hello, world!”, [1, 2, 3], {“key”: “value”} 等。
自然语言处理
在自然语言处理(NLP)领域,token是一个基本而重要的概念。它源自编程语言的词法分析过程,表示源代码中的最小有意义单元,如关键字、标识符、字面量等。随着NLP技术的发展,token这一概念被引入到了人类语言的处理中,成为了文本分析和理解的基础。
早期的NLP研究受到了形式语言理论和生成语法的影响,致力于发现人类语言的结构化规则和范式。研究人员尝试将语法分析的方法应用于自然语言,将句子划分为更小的单元(即token)进行处理。在这个过程中,token可以表示单词、标点符号、停顿等语言元素。通过对token的分析和组合,研究人员希望揭示语言的底层结构,实现对人类语言的自动理解和生成。
然而,随着语言的不断发展和变化,传统的基于规则的方法面临着挑战。人类语言的表达方式灵活多变,新词、新语和隐喻不断涌现。例如,

"好样的!精神点!别丢分!"这样的口语表达,其中蕴含了丰富的情感和语境信息,而这些信息难以用简单的词法和语法规则来捕捉。再比如,"坤坤"这样的网络流行语,其指代对象可能与字面意思完全不同。传统的NLP方法难以应对这种语言的动态性和创造性。
随着深度学习和神经网络的兴起,NLP领域出现了新的突破。基于transformer架构的语言模型,如BERT、GPT等,展现了强大的语言理解和生成能力。这些模型不再依赖于预定义的语法规则,而是通过从海量文本数据中学习语言的统计规律和上下文信息,自动捕捉语言的复杂特征。在这个过程中,token的概念得到了延续和发展。现代的NLP模型通过tokenization(分词)将文本转换为token序列,再通过神经网络对token序列进行编码和解码,生成丰富的语言表示。在英语等语言中,单词之间通常用空格或标点符号分隔,因此tokenization的任务相对简单,通常可以通过识别空格和标点符号来实现。例如,给定一个英文句子"I love natural language processing!“,tokenization的结果将是:

然而,在中文等没有明显单词边界的语言中,tokenization(分词)的任务就更加复杂。中文句子中的字与字之间没有明显的分隔符,因此需要使用更复杂的方法来识别单词的边界。例如,给定一个中文句子"我爱自然语言处理!”,分词的结果可能是:

不像英文可以用空格无缝分词,中文的分词又是另一门学问了,句读的说法是古已有之。
总之,在当前的NLP实践中,tokenization是文本处理管道中不可或缺的一步。对于英语等语言,tokenization通常基于空格和标点符号进行分割。而对于中文等没有明显单词边界的语言,则需要使用更复杂的分词算法,如基于字典、统计、规则或机器学习的方法。分词的目标是将连续的文本切分成有意义的最小单元,为后续的语言理解和生成任务奠定基础。
扩展token的含义,可以详细看看这篇文章-Token在不同领域内的中文译名浅析

Embedding:
Embedding是将token或其他离散单元映射到连续向量空间的过程。
在自然语言处理中,embedding通常用于将词语映射到高维向量空间,捕捉词语之间的语义关系。例如,词嵌入(word embedding)可以将词语映射到一个密集的实数向量。
Embedding的目的是将离散的token转换为连续的向量表示,以便在神经网络和其他机器学习模型中进行处理和计算。
常见的词嵌入方法包括Word2Vec、GloVe和FastText等。这些方法通过在大规模文本语料库上训练,学习词语之间的语义关系,并生成词向量。
Token和Embedding的关系大概是这样:
Token是embedding的输入。在进行embedding之前,首先需要将文本划分为一系列的token。
Embedding是在token级别上进行的。每个token都会被映射到一个对应的向量表示。
Embedding的结果是一个向量表示,而不是token本身。Embedding将token转换为连续的向量空间中的点。
举个例子,对于前面这个句子"I love natural language processing!",分词后得到的token序列为[“I”, “love”, “natural”, “language”, “processing”, “!”]。通过embedding,每个token都会被映射到一个对应的向量表示,例如:
from gensim.models import KeyedVectors# 加载预训练的word2vec模型(这里使用Google News语料库训练的300d词向量)
model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)# 输入一个句子
sentence = "I love natural language processing!"# 将句子转换为词语列表
words = sentence.lower().split()# 打印每个词的embedding向量
for word in words:if word in model.vocab:print(f"{word}: {model[word]}")else:print(f"{word}: 不在词汇表中")
结果可以看到像这样,每个token都被相同维度的向量来表示。
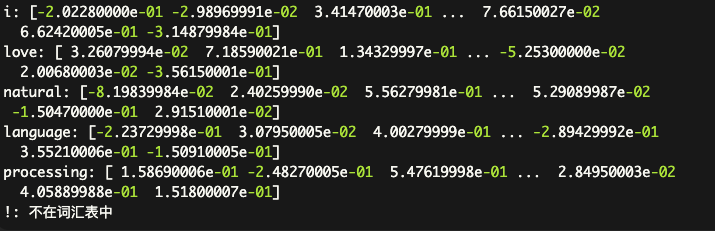
这些向量表示捕捉了token之间的语义关系,并可以用于下游的自然语言处理任务,如文本分类等等等等等
相关文章:
encoding Token和embedding 傻傻分不清楚?
encoding 编码 “encoding” 是一个在计算机科学和人工智能领域广泛使用的术语,它可以指代多种不同的过程和方法。核心就是编码:用某些数字来表示特定的信息。当然你或许会说字符集(Unicode)更理解这种概念,编码更强调这种动态的过程。而字符…...
一个公用的数据状态修改组件
灵感来自于一项重复的工作,下图中,这类禁用启用、审核通过不通过、设计成是什么状态否什么状态的场景很多。每一个都需要单独提供接口。重复工作还蛮大的。于是,基于该组件类捕获组件跳转写了这款通用接口。省时省力。 代码如下:…...

[python]yfinance国内不能使用
yfinance国内不能使用,可以使用tushare、akshare代替 import yfinance as yf# 输入股票代码 stock_symbol AAPL # 替换为你想要查询的股票代码# 获取股票数据 data yf.download(stock_symbol)# 打印实时数据 print(data) pip install akshare import akshare …...
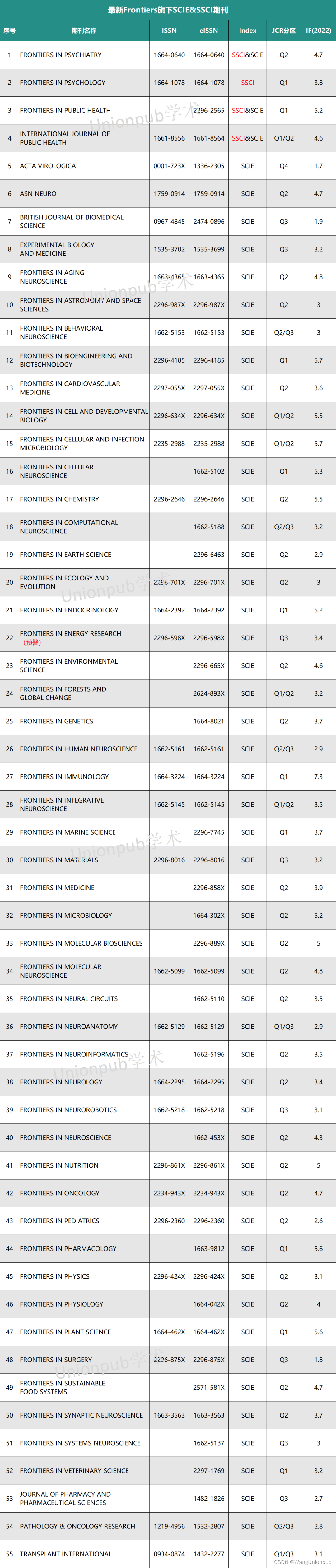
Frontiers旗下期刊,23年分区表整理出炉!它还值得投吗?
本周投稿推荐 SSCI • 中科院2区,6.0-7.0(录用友好) EI • 各领域沾边均可(2天录用) CNKI • 7天录用-检索(急录友好) SCI&EI • 4区生物医学类,0.5-1.0(录用…...

基于JSP的毕业生就业信息管理系统
开头语: 你好,我是专注于信息系统开发的学长猫哥。如果您对毕业生就业信息管理或相关技术感兴趣,欢迎联系我交流。 开发语言: JSP 数据库: MySQL 技术: JSP技术 SSM框架 工具: Eclips…...

CDN、CNAME、DNS
CDN、CNAME、DNS 域名解析是将域名转换为IP地址的过程。当用户在浏览器中输入域名时,计算机需要在DNS系统中找到对应的IP地址,以便能够访问该网站。 CDN(Content Delivery Network,内容分发网络)是一种用于加速网站访…...

直播商城源码-PC+APP+H5+小程序现成源码
随着电商行业的不断演进,直播商城已成为连接消费者和商品的新兴桥梁。直播商城源码提供了一个完整的解决方案,使得企业能够迅速搭建起一个覆盖PC、APP、H5和小程序的全渠道电商平台。本文将探讨直播商城源码的优势、关键功能以及如何选择适合的现成源码。…...

16. 《C语言》——【牛客网BC124 —— BC130题目讲解】
亲爱的读者,大家好!我是一名正在学习编程的高校生。在这个博客里,我将和大家一起探讨编程技巧、分享实用工具,并交流学习心得。希望通过我的博客,你能学到有用的知识,提高自己的技能,成为一名优…...

Docker 国内镜像源更换
实现 替换docker 镜像源 前提要求 安装 docker docker-compose 参考创建一键更换docker国内镜像源 Docker 镜像代理DaoCloud 镜像站百度云 https://mirror.baidubce.com南京大学镜像站...

python07
__init__.py from . import p1 from . import p2 # 理解:import p2 先导入 p2 文件, 然后该文件的内容全要 from . # # 告诉调用者,哪些文件需要使用 p1.py def sum(a,b):print(a b) p2.py def max(a,b):if a > b:print(a)else:pri…...
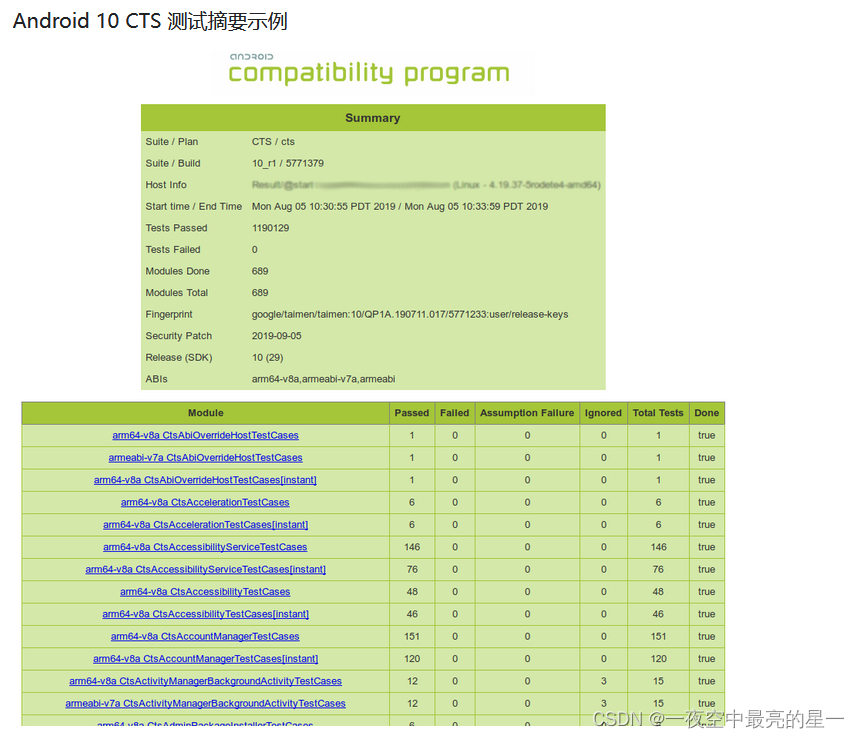
【CTS】android CTS测试
android CTS测试 1.硬件准备2. 软件准备3. 下载 CTS3.1 cts3.2 解压 CTS 包: 4 配置adb fastboot5 检查 Java 版本6 安装aapt26.1 下载并安装 Android SDK6.2 找到 aapt2 工具6.3 配置环境变量 7. 准备测试设备8. 运行 CTS 测试8.1 启动 CTS: 9. 查看测试…...
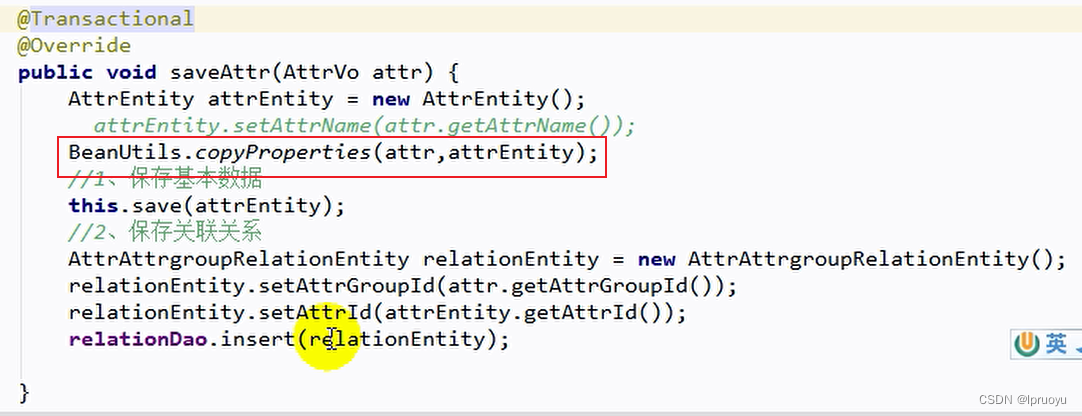
【雷丰阳-谷粒商城 】【分布式基础篇-全栈开发篇】【08】【商品服务】Object划分_批量删除
持续学习&持续更新中… 守破离 【雷丰阳-谷粒商城 】【分布式基础篇-全栈开发篇】【08】【商品服务】Object划分_批量删除 Object划分批量删除/添加参考 Object划分 数据库中对于一张表的数据,由于拥有隐私字段、多余字段、字段过少等原因,不应该直…...
JAVA开发 PDF文件生成表格,表格根据内容自动调整高度
1、展示效果 2、相关功能实现 JAVA开发 使用Apache PDFBox库生成PDF文件,绘制表格 3、实现代码 import org.apache.pdfbox.pdmodel.PDDocument; import org.apache.pdfbox.pdmodel.PDPage; import org.apache.pdfbox.pdmodel.PDPageContentStream; import org.ap…...

OSINT技术情报精选·2024年6月第1周
OSINT技术情报精选2024年6月第1周 2024.6.11版权声明:本文为博主chszs的原创文章,未经博主允许不得转载。 1、经合组织:《2024数字经济展望:第1卷,拥抱技术前沿》 经合组织近日发布《2024数字经济展望》报告第一卷,…...

惊艳的短视频:成都科成博通文化传媒公司
惊艳的短视频:瞬间之美,震撼心灵 在数字化时代,短视频以其短小精悍、内容丰富的特点,迅速占领了我们的屏幕和时间。而在这个浩如烟海的视频海洋中,总有一些短视频能够脱颖而出,以其惊艳的视觉效果、深刻的…...

消费增值模式引领业绩飙升与用户活跃
大家好,我是吴军,致力于为您揭示私域电商领域的独特魅力与机遇。 今日,我很高兴与大家分享一个激动人心的成功案例。我们的客户在短短一个月的时间里,业绩就飙升至上百万级别,其用户活跃度更是居高不下,日…...

二叉树从入门到AC(3)完全二叉树与堆
完全二叉树与堆 前言优先队列:堆向下调整维护堆向上调整维护堆堆的作用 前言 本文算是补充之前的系列,在前文中,讲了二叉树的基本结构与应用 二叉树从入门到AC(1)构建和前中后序遍历 二叉树从入门到AC(2&a…...
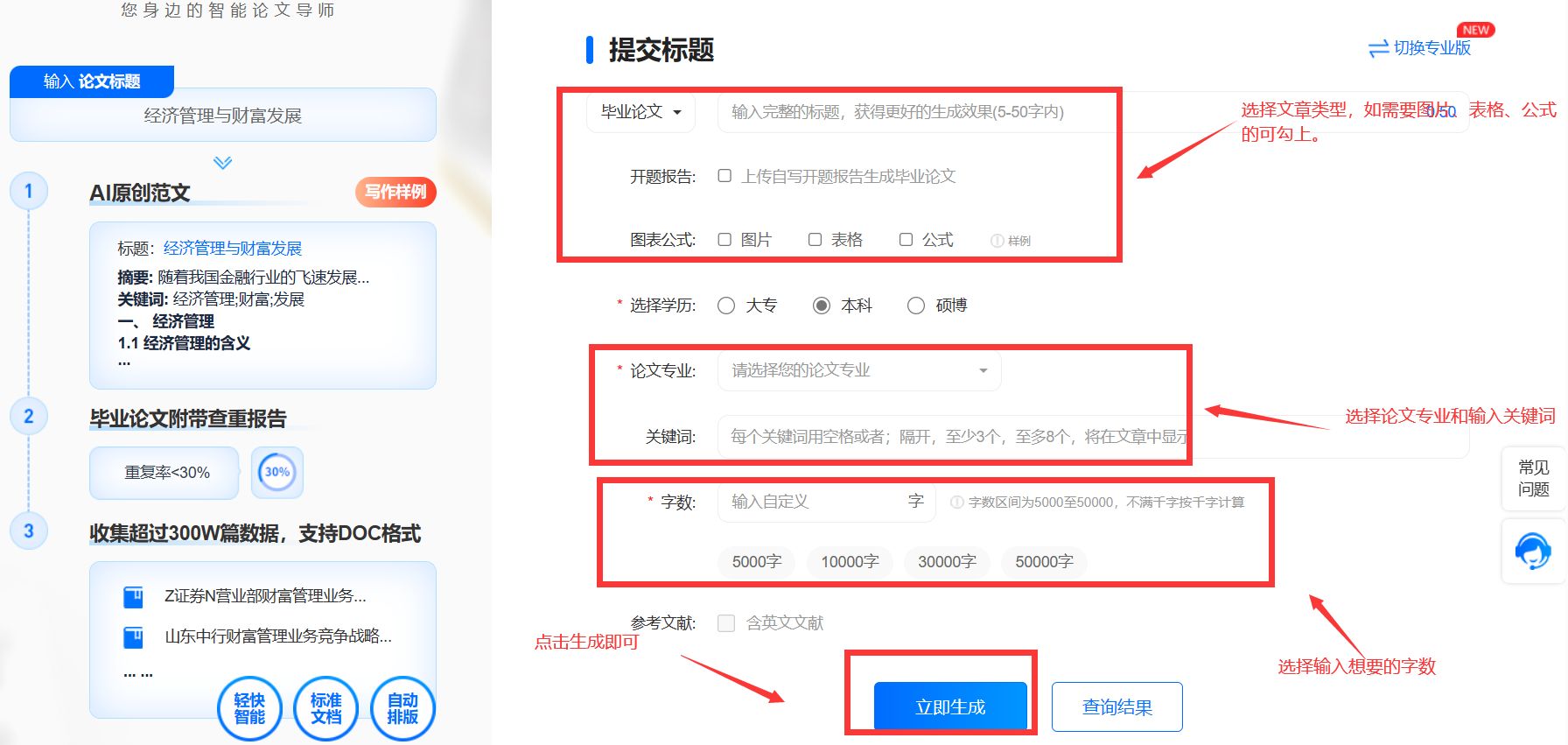
AI写作:如何让创作过程更流畅?
写作这件事一直让我们从小学生头痛到打工人,初高中时期800字的作文让我们焦头烂额,一篇作文里用尽了口水话,拼拼凑凑才勉强完成。 大学时期以为可以轻松顺利毕业,结果毕业前的最后一道坎拦住我们的是毕业论文,苦战几个…...

2024中国海洋装备展暨航海装备大会(福州海峡国际会展中心)
关于邀请参加2024中国海洋装备博览会的函 为加快推动海洋强国建设。在福建省人民政府的大力支持下,第二届中国海洋装备博览会将于2024年11月15-18日在福州举办。 博览会将进一步聚焦产业链和供应链协同创新,着力推动现代海洋产业体系建设,促进海洋科技…...

CyberDAO:引领Web3时代的DAO社区文化
致力于Web3研究和孵化 CyberDAO自成立以来,致力于推动Web3研究和孵化,吸引了来自技术、资本、商业、应用与流量等领域的上千名热忱成员。我们为社区提供多元的Web3产品和商业机会,触达行业核心,助力成员捕获Web3.0时代的红利。 目…...

30.【Verilog】Verilog 除法器设计
第一步:分析与整理Verilog 除法器设计 1. 除法器原理(定点)与十进制竖式除法类似,以 27 5 为例(二进制): 取被除数高位(与除数同宽,如 3bit),与除…...

南京数字化申报实战开启:提交材料后,如何确保您的技术底座不被“合规性审计”一票否决?
【行动指南:从填报到过审】截至 2026年5月12日,南京市中小企业数字化转型城市试点的线上申报通道已正式运行。在首批提交材料的企业反馈中,一个核心细节引起了市场的高度关注:申报系统不仅要求填写投入金额,更强化了对…...
)
PyTorch/TensorFlow深度学习环境搭建:在Windows10上一步到位搞定CUDA和cuDNN(避坑合集)
PyTorch/TensorFlow深度学习环境搭建:在Windows10上一步到位搞定CUDA和cuDNN(避坑合集) 刚入坑深度学习的开发者,最头疼的莫过于环境配置。明明按照教程一步步安装了PyTorch或TensorFlow,却在代码运行时看到CUDA不可用…...

植物大战僵尸95版下载2026最新版及与原本区别介绍
一、游戏版本简介 植物大战僵尸95版是基于官方原版修改优化的经典改版,也是国内玩家知名度最高、流传最广的怀旧改版之一。该版本保留原版全部关卡、场景、背景音乐以及基础玩法,没有大幅度颠覆原作设定,仅对植物属性、僵尸数值、判定机制进…...

小波散射网络:从理论优势到小样本图像分类实践
1. 小波散射网络为什么值得关注 第一次听说小波散射网络时,我和大多数搞机器学习的朋友反应一样:"这玩意儿和普通卷积神经网络(CNN)有什么区别?"直到去年接手一个医疗影像项目,手头只有200张标注…...

Poppins字体:免费开源的现代几何无衬线字体终极指南
Poppins字体:免费开源的现代几何无衬线字体终极指南 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 你是否正在寻找一款既美观又实用的字体来提升设计项目的视觉品质…...

基于MCP协议构建地方财政智能体:开源项目实践与开发指南
1. 项目概述:当MCP遇上地方财政,一个开源智能体的诞生最近在开源社区里,一个名为apifyforge/municipal-fiscal-intelligence-mcp的项目引起了我的注意。这个项目名听起来有点“学术”,但拆解开来,其实指向了一个非常具…...
深度探秘:以一次文件打开操作为例)
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例 当我们在终端输入cat /etc/shadow时,系统背后究竟发生了什么?这个看似简单的操作,实际上触发了一系列精妙的安全检查机制。本文将带您深入Linux内…...

Zsh插件实现Git输出路径美化:绝对路径转相对路径原理与实践
1. 项目概述与核心价值最近在终端里敲git status或者git diff的时候,你是不是也经常被那一长串的绝对路径搞得有点烦躁?尤其是在一个嵌套比较深的项目里,输出的文件路径长得能占满半个屏幕,想快速定位到具体是哪个文件改了&#x…...

iPaaS平台排名:五大主流产品的市场表现与核心能力
在数字化转型加速推进的当下,iPaaS(集成平台即服务)已成为企业构建敏捷IT架构、打通数据孤岛的关键基础设施。市场上涌现出多款各具特色的集成平台,它们在产品定位、技术架构与行业深耕上形成了差异化优势。本文基于公开资料&…...