3D数学系列之——再谈特卡洛积分和重要性采样
目录
- 一、前篇文章回顾
- 二、积分的黎曼和形式
- 三、积分的概率形式(蒙特卡洛积分)
- 四、误差
- 五、蒙特卡洛积分计算与收敛速度
- 六、重要性采样
- 七、重要性采样方法和过程
- 八、重要性采样的优缺点
一、前篇文章回顾
在前一篇文章3D数学系列之——从“蒙的挺准”到“蒙的真准”解密蒙特卡洛积分!中,介绍了下面的这些朴素的公式:
灰色部分中点数总的点数≈灰色部分面积矩形面积⇒灰色部分面积≈矩形面积×灰色部分中点数总的点数\begin{align} & \cfrac{ 灰色部分中点数 } {总的点数} \approx \cfrac{灰色部分面积} {矩形面积} \\[2ex] & \Rightarrow 灰色部分面积 \approx 矩形面积 \times \cfrac{ 灰色部分中点数 } {总的点数} \end{align} 总的点数灰色部分中点数≈矩形面积灰色部分面积⇒灰色部分面积≈矩形面积×总的点数灰色部分中点数
灰色部分面积≈矩形面积×P(P为点落在灰色部分的概率)灰色部分面积 \approx 矩形面积 \times P \quad (P为点落在灰色部分的概率) 灰色部分面积≈矩形面积×P(P为点落在灰色部分的概率)
虽然最终通过一个简单的概率乘法就可以计算出积分值,但是如何得到这个精确的概率值从而得到比较精确的积分值却不是那么简单的。并且这个方法直接用于计算或者说模拟计算来说,不确定的东西太多。下面我们就继续从积分的基本公式开始,讨论一下看看有没有进一步更形式化和更精确一点的方法。
二、积分的黎曼和形式
对于数值积分计算来说,积分的黎曼和形式是最基本的形式:
∫abf(x)dx≈∑n=1Nf(xn)b−aN(1)\int \limits_a^b {f}(x) \mathrm{d} x \approx \sum \limits_{n=1}^N {f}(x_n) \cfrac{b-a}{N} \tag{1} a∫bf(x)dx≈n=1∑Nf(xn)Nb−a(1)
这是一个常见和基本的可以用于积分计算程序的基本公式。
三、积分的概率形式(蒙特卡洛积分)
接着我们对黎曼和使用著名的”陶哲轩瞪眼法“进行观察。
首先对于求和来说,第一项是 f(xn){f}(x_n)f(xn) ,这里我们一般会比较容易知道 f(x){f}(x)f(x) 的解析形式或者可以知道它的一些离散值。
在实际计算中需要生成的是 xnx_nxn 的序列,这个序列是跟后面的 (b−a)N\cfrac{(b-a)}{N}N(b−a) 紧密关联的,因为需要保证 xi−xi−1=b−aNx_{i}-x_{i-1} = \cfrac{b-a}{N}xi−xi−1=Nb−a 即 xnx_nxn 序列是个等差数列,间隔是就是 (b−a)N\cfrac{(b-a)}{N}N(b−a) 。
这时,我们先打开思路,既然前一讲中已经可以通过随机变量的形式来计算积分,那么这时我们可不可以用一组随机数的序列来代替 xnx_nxn 的序列呢?
既然讲到随机,那么回忆一下概率论中关于“均匀分布随机变量”的概率密度函数(The Probability Distribution Function,缩写为 PDF):
p(x)={1b−a,a<x<b0,其他(2)\mathrm{p}(x) = \begin{cases} \cfrac{1}{b-a}, \quad a \lt x \lt b \\[2ex] 0, \quad 其他 \end{cases} \tag{2} p(x)=⎩⎨⎧b−a1,a<x<b0,其他(2)
接着我们用"陶哲轩瞪眼法"观察黎曼和公式与上面这个公式,此时我们应灵光乍现想到下面这样的形式:
∫abf(x)dx≈∑n=1Nf(xn)b−aN=1N∑n=1Nf(xn)×(b−a)根据乘以一个数等于除以一个数的倒数这个法则,有:=1N∑n=1Nf(xn)p(xn)(3)\int \limits_a^b {f}(x) \mathrm{d} x \approx \sum \limits_{n=1}^N {f}(x_n) \cfrac{b-a}{N} \\[2ex] = \cfrac{1}{N} \sum \limits_{n=1}^{N} {f}(x_n) \times (b-a) \\[2ex] 根据乘以一个数等于除以一个数的倒数这个法则,有: \\[2ex] = \cfrac{1}{N} \sum \limits_{n=1}^{N} \cfrac{{f}(x_n)}{\mathrm{p}(x_n)} \tag{3} a∫bf(x)dx≈n=1∑Nf(xn)Nb−a=N1n=1∑Nf(xn)×(b−a)根据乘以一个数等于除以一个数的倒数这个法则,有:=N1n=1∑Np(xn)f(xn)(3)
啊哈!太好了,这一切看似是公式间的一种巧合或者说技巧性的,接着我们思考下它的意义。因为刚才我们已经说过原来的xnx_nxn 序列是个等差序列,本身就是均匀分布的,所以其概率密度函数(PDF)就是均匀分布变量的 PDF。如果我们取一个随机的 xnx_nxn 序列,并假设知道它的 PDF p(xn)\mathrm{p}(x_n)p(xn) 那么就可以根据上面这个式子的结果来计算积分值了。并且当 xnx_nxn 不断增多时,和 1N∑n=1Nf(xn)p(xn)\cfrac{1}{N} \sum \limits_{n=1}^{N} \cfrac{{f}(x_n)}{\mathrm{p}(x_n)}N1n=1∑Np(xn)f(xn) 也就越接近原始的积分值!这也就是传说中的蒙特卡洛积分的基本形式。它是合理且有意义的,起码我们不用只靠前一讲中的“蒙的真准”的方法了。需要注意的就是其中 f(xn)p(xn)\cfrac{{f}(x_n)}{p(x_n)}p(xn)f(xn) 项看上去虽然很奇怪,但他其实是有实际含义的,一般被称作概率平均。
当然使用随机序列 xnx_nxn 是有条件的,即要求:
∫−∞+∞p(x)=1(4)\int \limits_{-\infty}^{+\infty} \mathrm{p}(x) = 1 \tag{4} −∞∫+∞p(x)=1(4)
接着我们继续观察(还是使用 “陶哲轩瞪眼法”)那个带有 PDF 的蒙特卡洛积分公式,发现其中还有个 1N\cfrac{1}{N}N1 , 这时我们应该突然明白其实这个式子还是个平均值的公式,而讲到平均值,学过概率论的同学就应该立刻想到“数学期望”。一般的数学期望的定义:
E[f(X)]=∑n=1∞f(xn)p(xn)E[{f}(X)] = \mathop{\sum}\limits_{n = 1}^{\infty} {f}(x_n) \mathrm{p}(x_n) E[f(X)]=n=1∑∞f(xn)p(xn)
也就是说如果我们知道了随机变量 xnx_nxn 的随机 PDF: p(xn)\mathrm{p}(x_n)p(xn),那么随机变量函数的数学期望就可以用上式计算。当然如果 xnx_nxn 是连续的随机变量,那么就可以用积分形式来表示上面的表达式:
E[f(X)]=∫−∞+∞f(x)p(x)dxE[{f}(X)] = \mathop{\int}\limits_{-\infty}^{+\infty} {f}(x) \mathrm{p}(x) dx E[f(X)]=−∞∫+∞f(x)p(x)dx
这时,为了验证蒙特卡洛积分公式的正确性,我们来看看它的数学期望:
E(F(X))=E[1N∑n=1Nf(xn)p(xn)]=1N∑n=1N∫abf(x)p(x)×p(x)dx=1N∑n=1N∫abf(x)dx=∫abf(x)dxE(F(X)) = E \left[ \cfrac{1}{N} \sum \limits_{n=1}^{N} \cfrac{{f}(x_n)}{\mathrm{p}(x_n)} \right] \\[2ex] = \cfrac{1}{N} \sum \limits_{n=1}^{N} \int \limits_{a}^{b} \cfrac{{f}(x)}{\mathrm{p}(x)} \times \mathrm{p}(x) \mathrm{d}x \\[2ex] = \cfrac{1}{N} \sum \limits_{n=1}^{N} \int \limits_{a}^{b} {f}(x) \mathrm{d} x \\[2ex] = \int \limits_{a}^{b} {f}(x) \mathrm{d}x E(F(X))=E[N1n=1∑Np(xn)f(xn)]=N1n=1∑Na∫bp(x)f(x)×p(x)dx=N1n=1∑Na∫bf(x)dx=a∫bf(x)dx
这个结果简直太棒了!它说明蒙特卡洛积分公式的数学期望就是我们要求的积分值。这也间接的证明我们前面靠瞪眼法得到的公式本质上是正确的。或者说,蒙特卡洛积分的结果对于积分真值是无偏差的,也就是说是原积分的无偏估计。这个可以由“大数定理”来保证。只是不同的随机变量序列 xnx_nxn 会以不同的“速度”靠近积分原值。
四、误差
按照数学家们的“尿性”,一定会严格的分析一下整个“蒙的挺准”的过程中的误差。既然刚才已经分析了蒙特卡洛积分的数学期望,那么继续根据概率论的知识,我们来分析下它的误差。一般对于随机序列来说,我们取其方差来评估其靠近真实值的程度。那么就让我们来计算下蒙特卡洛积分的方差:
σ2[Fn(X)]=σ2[1N∑n=1Nf(xn)p(xn)]=1N2∑n=1N∫ab(f(x)p(x)−E(Fn(X)))2×p(x)dx=1N[∫ab(f(x)p(x))2×p(x)dx−E(Fx(X))2]=1N[∫abf(x)2p(x)dx−E(Fn(X))2](5)\sigma^2[F_n(X)] \\[2ex] = \sigma^2 \left[ \cfrac{1}{N} \sum \limits_{n=1}^{N} \cfrac{f(x_n)}{\mathrm{p}(x_n)} \right] \\[2ex] = \cfrac{1}{N^2} \sum \limits_{n=1}^{N} \int \limits_a^b \left( \cfrac{f(x)}{\mathrm{p}(x)} - E(F_n(X)) \right)^2 \times \mathrm{p}(x) \mathrm{d}x \\[2ex] =\cfrac{1}{N}\left[ \int \limits_a^b \left( \cfrac{{f}(x)}{\mathrm{p}(x)} \right)^2 \times \mathrm{p}(x) \mathrm{d}x - E(F_x(X))^2 \right] \\[2ex] = \cfrac{1}{N} \left[ \int \limits_a^b \cfrac{{f}(x)^2}{\mathrm{p}(x)} \mathrm{d}x - E(F_n(X))^2 \right] \tag{5} σ2[Fn(X)]=σ2[N1n=1∑Np(xn)f(xn)]=N21n=1∑Na∫b(p(x)f(x)−E(Fn(X)))2×p(x)dx=N1a∫b(p(x)f(x))2×p(x)dx−E(Fx(X))2=N1a∫bp(x)f(x)2dx−E(Fn(X))2(5)
上面最终包含了 1N\cfrac{1}{N}N1 项的最终的一堆公式,就是蒙特卡洛积分的方差,根据概率论的定义,其标准差就是方差的算术平方根。
按照最终的证明结果,蒙特卡洛积分值与积分真实值之间的标准差(误差)有如下的形式:
误差∝1N(6)误差 \varpropto \cfrac{1}{\sqrt{N}} \tag{6} 误差∝N1(6)
即最终误差正比于N的平方根的倒数。
五、蒙特卡洛积分计算与收敛速度
有了前面这些数学知识的加持,那么我们就可以来看看用蒙特卡洛积分来计算积分时到底“速度”如何?
其实看到这里,大家应该有个疑惑,我们费劲巴拉的推导了半天,到底在图个啥?
那么如果你看了前一篇文章(3D数学系列之——从“蒙的挺准”到“蒙的真准”解密蒙特卡洛积分!),首先应该想到有了蒙特卡洛积分公式,我们是不是可以开始靠“蒙”来计算积分了?答案是肯定的,要计算蒙特卡洛积分,我们就需要产生一个随机变量的序列 xnx_nxn 并且需要知道其概率密度函数(PDF)p(xn)\mathrm{p}(x_n)p(xn) (有时候不需要知道 PDF 的表达式,只需要知道每个随机变量对应的概率值即可) 然后代入公式的右侧进行计算:
∫abf(x)dx≈1N∑n=1Nf(xn)p(xn)(3)\int \limits_a^b {f}(x) \mathrm{d} x \approx \cfrac{1}{N} \sum \limits_{n=1}^{N} \cfrac{{f}(x_n)}{\mathrm{p}(x_n)} \tag{3} a∫bf(x)dx≈N1n=1∑Np(xn)f(xn)(3)
这样计算的好处是,我们可以用大一些(计算能力充足时)或者小一些(计算能力不足时)的随机变量序列来进行计算。
当然这样计算的限制是,根据对蒙特卡洛方法标准差的计算,最终可以知道如果我们想提高计算精度一倍,那么差不多就需要将N提高4倍( 14=12\cfrac{1}{\sqrt{4}}=\cfrac{1}{2}41=21 ,即误差减小一半)。所以这就是平常所说的蒙特卡洛积分法收敛慢的根本原因。
例如在我们关注的图形的光照积分估算过程中,这是个麻烦的问题,比如原先需要每个点采样1000条光线近似计算最终光照效果,要提高一倍精确度从而改进画质效果的话,那么每个点就需要采集4000条光线进行积分。因此,基本上现实中很少直接用蒙特卡洛积分的基本形式来求积分值的。
所以最终这个结论是有点令人灰心丧气的,不过请继续往后看,这么好的方法一定已经有很多人帮我们想了很多办法来解决问题的。
六、重要性采样
OK,看到这里你还没有晕过去的话,请为自己点个赞先!
鉴于前面说的直接运用蒙特卡洛方法进行积分计算时,因为固有偏差的问题,而导致算法过程收敛过慢(N的平方根倒数的量级)所以在计算效率上是不尽人意的。那么既然是因为偏差导致的问题,我们就继续从偏差来分析看看:
σ2[Fn(X)]=1N[∫abf(x)2p(x)dx−E(Fn(X))2]=1N[∫abf(x)2p(x)dx−(∫abf(x)dx)2]\sigma^2[F_n(X)] \\[2ex] = \cfrac{1}{N} \left[ \int \limits_a^b \cfrac{{f}(x)^2}{\mathrm{p}(x)} \mathrm{d}x - E(F_n(X))^2 \right] \\[2ex] =\cfrac{1}{N} \left[ \int \limits_a^b \cfrac{{f}(x)^2}{\mathrm{p}(x)} \mathrm{d}x - \left( \int \limits_a^b {f}(x) \mathrm{d}x \right)^2 \right] σ2[Fn(X)]=N1a∫bp(x)f(x)2dx−E(Fn(X))2=N1a∫bp(x)f(x)2dx−a∫bf(x)dx2
这时如果我们想要标准差(方差的开方)最小,那么就需要让上式结果等于0,此时我们继续使用瞪眼法可以发现,这需要下面的等式成立:
p(x)=∣f(x)∣∫abf(x)dx(7)\mathrm{p}(x) = \cfrac{|{f}(x)|}{\int \limits_a^b {f}(x) \mathrm{d}x} \tag{7} p(x)=a∫bf(x)dx∣f(x)∣(7)
在很多其他的资料中,推得这个式子之后,忽略了讲解它的意义。乍看上去,貌似我们要知道我们需要使用的随机变量的概率密度,就需要先知道最终积分的结果,使得这个式子变成了无用的“鸡肋”。
其实不然,这个式子恰恰给我们指明了一个非常明确的方向。
它说明,如果我们要使得方差、标准差最小,那么就要找到一个随机变量序列使得它的概率密度函数与被积函数 f(x){f}(x)f(x) 在“形状”上要高度一致!这是个很重要的信息。为什么这样说呢?其实仔细观察这个式子可以发现其中的定积分其实是个常数 ∫abf(x)dx\int \limits_a^b {f}(x) \mathrm{d}xa∫bf(x)dx ,所以整个式子表达的意思是说 :
p(x)=∣f(x)∣S=A∣f(x)∣(8)\mathrm{p}(x) = \cfrac{|{f}(x)|}{S} = A|{f}(x)| \tag{8} p(x)=S∣f(x)∣=A∣f(x)∣(8)
即最终当概率密度函数其实就是被积函数的一个常数倍的时候,整个方差最小,也即标准差会非常小。
这是整个重要性采样的出发点,也就是说我们可以依据被积函数的特征,构造一个与之匹配的概率分布函数的形状,然后生成特意构造的随机序列,再返回到蒙特卡洛积分 ∫abf(x)dx≈1N∑n=1Nf(xn)p(xn)\int \limits_a^b {f}(x) \mathrm{d} x \approx \cfrac{1}{N} \sum \limits_{n=1}^{N} \cfrac{{f}(x_n)}{\mathrm{p}(x_n)}a∫bf(x)dx≈N1n=1∑Np(xn)f(xn) 进行计算,那么只需要非常少的 xnx_nxn 就可以得到非常精确的积分结果,因为这样的序列计算后使得蒙特卡洛积分最终的方差、标准差都变得非常小,甚至为0。
也就是说这样的随机序列,使得蒙特卡洛积分能够快速收敛!也就是说,咱们之前说的普通的蒙特卡洛积分过程误差与 1N\cfrac{1}{\sqrt{N}}N1 成正比导致我们必须付出平方倍的计算量,才能使的误差变小的规律可以被打破了,因为这个因子的后面那堆复杂的表达式在我们特意的设计下几乎 = 0,所以我们完全不用浪费过多的计算量来获取较精确的积分结果。 这个过程就被称为重要性采样!
七、重要性采样方法和过程
那么最终如何进行上面所说的重要性采样呢?其实核心就是构造使的蒙特卡洛积分方差和标准差最小的随机数序列 xnx_nxn 。
1、根据定义 ∫abp(x)dx\int \limits_a^b \mathrm{p}(x) \mathrm{d}xa∫bp(x)dx 就是概率密度函数 p(x)p(x)p(x) 对应的累积分布函数(Cumulative Distribution Function),简称做 CDF,通常其正式定义如下:
CDF(x)=∫−∞xp(x~)dx~(9)\mathrm{CDF}(x) = \int \limits_{-\infty}^{x} p( \tilde{x} ) \mathrm{d} \tilde{x} \tag{9} CDF(x)=−∞∫xp(x~)dx~(9)
然后选择一个跟被积分的函数“相类似”的概率密度函数 PDF 来计算其 CDF;
2、接着推导出 CDF 的反函数 CDF−1(x)\mathrm{CDF}^{-1}(x)CDF−1(x) ;
3、然后生成一个均匀分布的随机变量序列 un∈[0,1]u_n \in [0,1]un∈[0,1] ;
4、使用 unu_nun 代入 CDF 的反函数 CDF−1(x)\mathrm{CDF}^{-1} (x)CDF−1(x) 计算出随机序列 xnx_nxn ;
5、最后将 xnx_nxn 代入蒙特卡洛积分中计算函数的积分值;
通常在很小规模的 xnx_nxn 序列下,就可以计算出很高精度的积分值。
举例来说,假设我们需要求一个形似 ∫0πAsin(x)dx\int \limits_0^{\pi} A \sin(x) \mathrm{d}x0∫πAsin(x)dx 的积分,此时根据被积函数为正弦函数的特征,构造 p(x)=csin(x)x∈[0,π]p(x) = c \sin(x) \quad x \in [0,\pi]p(x)=csin(x)x∈[0,π] ,然后我们计算它的 CDF:
∫0πcsin(x)dx=c[−cos(x)]0π=2c=1∵∫0πp(x)dx=1⇒c=12用x替换积分上限,得到CDF的表达式,有:CDF(x)=∫0x12sin(t)dt=12[−cos(t)]0x=12(1−cos(x))\int \limits_{0}^{\pi} c \sin(x) \mathrm{d}x = c \Biggl[-\cos(x)\Biggr]_0^{\pi} = 2 c = 1 \\[2ex] \because \quad \int_0^{\pi} p(x) \mathrm{d}x = 1 \\[2ex] \Rightarrow c = \cfrac{1}{2} \\[2ex] 用 x 替换积分上限,得到CDF 的表达式,有: \\[2ex] CDF(x) = \int\limits_0^x \cfrac{1}{2} \sin(t)\mathrm{d}t = \cfrac{1}{2} \Biggl[ -\cos(t) \Biggr]_0^{x} = \cfrac{1}{2}(1-\cos(x)) 0∫πcsin(x)dx=c[−cos(x)]0π=2c=1∵∫0πp(x)dx=1⇒c=21用x替换积分上限,得到CDF的表达式,有:CDF(x)=0∫x21sin(t)dt=21[−cos(t)]0x=21(1−cos(x))
有了 CDF 那么我们来计算其反函数:
y=12(1−cos(x))⇒x=arccos(1−2y)y = \cfrac{1}{2}(1-\cos(x)) \\[2ex] \Rightarrow \quad x = \arccos(1-2y) y=21(1−cos(x))⇒x=arccos(1−2y)
接着我们生成一个均匀分布的随机数序列 unun∼[0,1]u_n \quad u_n \sim [0,1]unun∼[0,1] 代入上式中计算得到指定分布的随机序列 xn=arccos(1−2un)x_n = \arccos(1-2u_n)xn=arccos(1−2un),最终用这个序列按照蒙特卡洛积分公式计算即可快速得到 ∫0πAsin(x)dx\int \limits_0^{\pi} A \sin(x) \mathrm{d}x0∫πAsin(x)dx 的积分值。
那么详细的计算过程和程序就先略过了,在后续的 IBL 教程中将有更详细的应用讲解和实际工程中的代码。有兴趣的同学可以自己编写程序比较一下,即先用黎曼和及库函数sin计算得到积分结果,然后与库函数cos的直接计算结果进行比较,最好能求出方差,然后再用刚才推导出的 CDF−1CDF^{-1}CDF−1 函数计算的序列代入蒙特卡洛积分公式中计算积分结果,同样与cos函数直接计算的结果求差,或者求方差,看看有什么区别?
八、重要性采样的优缺点
根据前面的叙述,重要性采样的全部目的就是为了缩小 xnx_nxn 的规模,同时还能保证一定的精度,其实就是之前标题所说的从 “蒙的挺准” 到 “蒙的更准”,而且计算量还大大变小了,这对于很多需要数值积分的计算来说是非常非常好的优化方法。另外对于高维的积分来说,重要性采样的方法依然有效!这样带来的好处就是,原本复杂度可能是 O(nα)α∈Z+,α⩾1O(n^{\alpha}) \quad \alpha \in Z^+,\alpha \geqslant 1O(nα)α∈Z+,α⩾1 的问题,有可能直接变成了 O(n)O(n)O(n) 的问题,这对于我们关注的图形光照计算领域来说简直就是福音!因为我们需要处理的图形往往都是 n3n^3n3 维度的,并且在复杂光照渲染算法中需要大量的 3D 积分,所以有了蒙特卡洛积分和重要性采样方法,就使得该过程的计算量几何级数的被减少,这最终使得实时 PBR 渲染成为可能。
当然重要性采样也有缺点,根据刚才描述的过程,大家应该能想到,第一,如果被积函数 f(x){f}(x)f(x) 过于复杂时,我们基本无法简单的模拟出一个形似的 p(x)p(x)p(x) 函数,从而整个过程有可能就前功尽弃;第二个方面就是说,通过 CDF−1CDF^{-1}CDF−1 函数计算出的序列 xnx_nxn 有可能使得 f(x){f}(x)f(x) 的值过于集中于一些较大函数值得地方,从而导致最终积分的结果与真值之间产生正偏差。
当然幸运的是这两条缺点在我们的 PBR 渲染中几乎碰不到,也就没什么太大的影响。
相关文章:

3D数学系列之——再谈特卡洛积分和重要性采样
目录一、前篇文章回顾二、积分的黎曼和形式三、积分的概率形式(蒙特卡洛积分)四、误差五、蒙特卡洛积分计算与收敛速度六、重要性采样七、重要性采样方法和过程八、重要性采样的优缺点一、前篇文章回顾 在前一篇文章3D数学系列之——从“蒙的挺准”到“蒙…...

Python错误 TypeError: ‘NoneType‘ object is not subscriptable解决方案汇总
目录前言一、引发错误来源二、解决方案2-1、解决方案一(检查变量)2-2、解决方案二(使用 [] 而不是 None)2-3、解决方案三(设置默认值)2-4、解决方案四(使用异常处理)2-5、解决方案五…...

VMware空间不足又无法删除快照的解决办法
如果因为快照删除半路取消或者失败,快照管理器就不再显示这个快照,但是其占用的空间还在,最终导致硬盘不足。 可以百度到解决方案,就是在快照管理器,先新建一个,再点删除,等待删除完成就可以将…...
类和对象(一)
类和对象(一) C并不是纯面向对象语言 C是面向过程和面向对象语言的! 面向过程和面向对象初步认识: C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题。 C是基…...
Java 不同路径
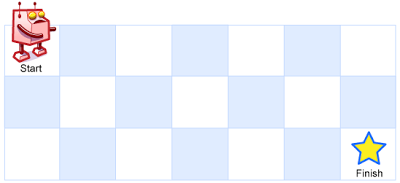
不同路径中等一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。问总共有多少条不同的路径?…...

【SAP PO】X-DOC:SAP PO 接口配置 REST 服务对接填坑记
X-DOC:SAP PO 接口配置 REST 服务对接填坑记1、背景2、PO SLD配置3、PO https证书导入1、背景 (1)需求背景: SAP中BOM频繁变更,技术人员在对BOM进行变更后,希望及时通知到相关使用人员 (2&…...
最新研究!美国爱荷华州立大学利用量子计算模拟原子核
爱荷华州立大学物理学和天文学教授James Vary(图片来源:网络)美国爱荷华州立大学物理学和天文学教授James Vary和来自爱荷华州立大学、马萨诸塞州塔夫茨大学,以及美国能源部加利福尼亚州劳伦斯伯克利国家实验室的研究人员…...

零入门kubernetes网络实战-22->基于tun设备实现在用户空间可以ping通外部节点(golang版本)
《零入门kubernetes网络实战》视频专栏地址 https://www.ixigua.com/7193641905282875942 本篇文章视频地址(稍后上传) 本篇文章主要是想做一个测试: 实现的目的是 希望在宿主机-1上,在用户空间里使用ping命令发起ping请求,产生的icmp类型的…...

web安全——Mybatis防止SQL注入 ssrf漏洞利用 DNS污染同源策略
目录 0x01 Mybatis防止SQL注入 0x02 sqlmap中报错注入判断 0x03 ssrf漏洞利用 0x04 SSRF重绑定 0x05 DNS污染...
smp_init过程解析
当你看到这样的log,会不会很慌张?竟然由CPU没有启动成功,除了什么故障?本文将结合我遇到的一个问题,将启动过程中bringup secondary cpu的过程分析一下。smp_init代码如下:602 void __init smp_init(void) …...

判断推理之逻辑判断
考点一翻译推理(一)题目特征题干或选项中出现多组“逻辑关联词”,如:“如果……那么……”、“只要……就……”、“只有……才……”、“所有”、“有些”、“……且……”、“ ……或……”等典型逻辑关联词。(二&am…...
2023金三银四常见Handler面试总结,附带答案
以下的Handler的面试题都是在面试过程中总结出来比较常见的面试题,现在分享给大家,希望可以帮助你们!1.Handler的实现原理从四个方面看Handler、Message、MessageQueue 和 Looper Handler:负责消息的发送和处理 Message:消息对象,…...

为什么机器人操作系统ROS1、ROS2这么难学
AI回复:ROS1、ROS2是机器人操作系统,涉及到很多复杂的概念和技术,需要有一定的编程和机器人知识基础才能学习。此外,ROS1和ROS2的架构和设计也有很大的不同,需要花费一定的时间和精力去学习和适应。但是,一…...

day01
授课老师 :陶国荣 联系方式 : taogrtedu.cn 授课阶段 : Web前端基础 授课内容 : HTML CSS JavaScript 文章目录一、讲师和课程介绍二、Web前端介绍1. 什么是网页2. 网页的组成3. 网页的优势4. 开发前的准备三、 HTML语法介绍…...
)
第四十章 linux-并发解决方法五(顺序锁seqlock)
第四十章 linux-并发解决方法四(顺序锁seqlock) 文章目录第四十章 linux-并发解决方法四(顺序锁seqlock)顺序锁的设计思想是,对某一共享数据读取时不加锁,写的时候加锁。为了保证读取的过程中不会因为写入名…...

【SPSS】交叉设计方差分析和协方差分析详细操作教程(附案例实战)
🤵♂️ 个人主页:@艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+ 目录 方差分析概述 交叉设计方差分析...

playwright--核心概念和Selector定位
文章目录前言一、浏览器二、浏览器上下文三、页面和框架四、Selectors1、data-test-id selector2、CSS and XPath selector3、text 文本selector4、id定位selector5、Selector 组合定位五、内置Selector前言 Playwright提供了一组API可自动化操作Chromium,Firefox和…...

响应式操作实战案例
Project Reactor 框架 在Spring Boot 项目 Maven 中添加依赖管理。 <dependency><groupId>io.projectreactor</groupId><artifactId>reactor-core</artifactId> </dependency><dependency><groupId>io.projectreactor</g…...

NetApp AFF A900:针对任务关键型应用程序的解决方案
NetApp AFF A900:适用于数据中心的解决方案 AFF A 系列中的 AFF A900 高端 NVMe 闪存存储功能强大、安全可靠、具有故障恢复能力,提供您为任务关键型企业级应用程序提供动力并保持数据始终可用且安全所需的一切。 AFF A900:针对任务关键型应…...
使用Houdini输出四面体网格并输出tetgen格式
我们的目标是从houdini输出生成的四面体,希望是tetgen格式的。 众所周知,houdini是不能直接输出四面体的。 有三方案去解决: 输出点云ply文件,然后利用tetgen生成网格。输出Hounidi内置的.geo格式文件,然后写个脚本…...

基于Matlab的正态云模型花卉特征提取:从理论到代码实现
257.基于matlab的正态云模型花卉特征提取,用正向正态云发生器和逆向正态云发生器来模拟花卉的部分特征提取 程序已调通,可直接运行在花卉研究领域,准确提取花卉特征对于花卉分类、品种识别等工作至关重要。今天咱们来聊聊基于Matlab的正态云模…...

OpenClaw负载均衡:多Qwen3-VL:30B实例轮询策略
OpenClaw负载均衡:多Qwen3-VL:30B实例轮询策略 1. 为什么需要多模型实例负载均衡 上周我遇到一个棘手问题:用OpenClaw处理批量图片分析任务时,单个Qwen3-VL:30B实例频繁触发速率限制,导致任务队列堆积。更糟的是,有次…...

避坑指南:用ESP32驱动LD2420毫米波雷达时,串口数据丢失和自动开机卡死的那些事儿
ESP32与LD2420毫米波雷达深度避坑实战:从数据丢失到系统卡死的全链路解决方案 当你在凌晨三点盯着逻辑分析仪上那些残缺的串口波形时,就会明白为什么LD2420毫米波雷达被称为"最熟悉的陌生人"。这个能穿透墙壁感知呼吸的24GHz传感器,…...

ECharts Geo Regions 进阶:自定义地图省份边界与区域样式的实战技巧
1. 理解ECharts中的geo.regions属性 ECharts作为一款强大的数据可视化工具,其地图组件在展示地理信息数据时尤为出色。在实际项目中,我们经常需要对特定省份或区域进行个性化样式设置,这时候geo.regions属性就派上用场了。这个属性允许我们对…...

如何实现SASM多语言支持:完整国际化配置与翻译指南
如何实现SASM多语言支持:完整国际化配置与翻译指南 【免费下载链接】SASM SASM - simple crossplatform IDE for NASM, MASM, GAS and FASM assembly languages 项目地址: https://gitcode.com/gh_mirrors/sa/SASM SASM(Simple Assembler IDE&…...

HY-Motion 1.0保姆级教程:解决CUDA OOM、Prompt截断等常见问题
HY-Motion 1.0保姆级教程:解决CUDA OOM、Prompt截断等常见问题 1. 前言:为什么需要这篇教程 你是不是也遇到过这样的情况:好不容易下载了HY-Motion 1.0这个强大的3D动作生成模型,准备大展身手,结果一运行就遇到CUDA内…...

Vue中实现动态标签页的切换优化与状态管理
1. 动态标签页的核心需求与实现思路 在后台管理系统这类多页面应用中,动态标签页几乎是标配功能。想象一下你正在使用某电商后台,同时开着商品管理、订单处理和用户分析三个页面,这时候标签页的流畅切换和状态保持就显得尤为重要。 我经历过一…...

N诺机试题
2.整除(末尾无空格用printf“ ”)#include<stdio.h>int main(){int count0;for(int i100;i<1000;i){if(i%50&&i%60){printf("%d",i);count;if(count%100) printf("\n");else printf(" "); }}return 0;…...
)
告别Makefile!用Zig 0.10.0自带的构建系统搞定ARM裸机开发(附完整项目配置)
用Zig构建系统重塑ARM裸机开发:告别Makefile的终极指南 当你在凌晨三点盯着第47个Makefile规则调试链接器错误时,是否想过——嵌入式开发必须这么痛苦吗?Zig 0.10.0带来的不仅是一门新语言,更是一套彻底革新裸机开发工作流的构建系…...

机票价格智能监控:如何用Flight Spy锁定最佳购票时机
机票价格智能监控:如何用Flight Spy锁定最佳购票时机 【免费下载链接】flight-spy Looking for the cheapest flights and dont have enough time to track all the prices? 项目地址: https://gitcode.com/gh_mirrors/fl/flight-spy 你是否曾在预订机票时陷…...