实现开源可商用的 ChatPDF RAG:密集向量检索(R)+上下文学习(AG)
实现 ChatPDF & RAG:密集向量检索(R)+上下文学习(AG)
- RAG 是啥?
- 实现 ChatPDF
- 怎么优化 RAG?
RAG 是啥?
RAG 是检索增强生成的缩写,是一种结合了信息检索技术与语言生成模型的人工智能技术。
这种技术主要用于增强 LLM 的能力,使其能够生成更准确且符合上下文的答案,同时减少模型幻觉。
RAG通过将检索模型和生成模型结合起来,利用专有数据源的信息(比如多文档)来辅助文本生成。
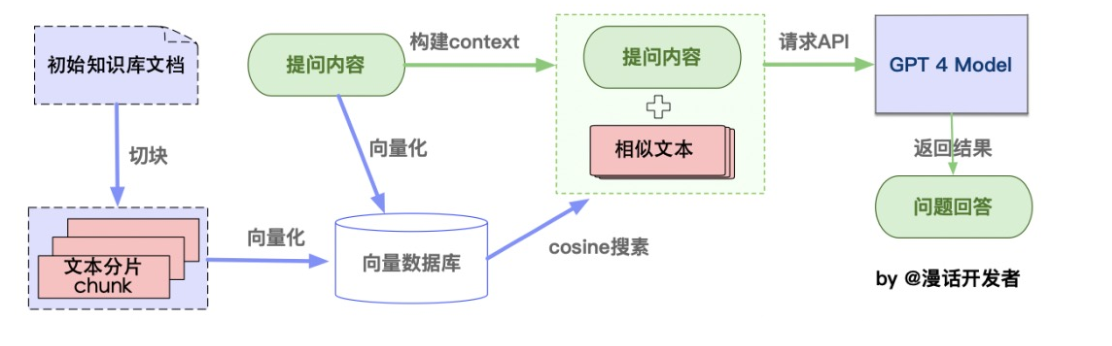
从本地文档加载到生成语言模型回答的整个流程。
-
文本分块:
- 加载文件:这一步骤涉及从本地存储读取文件。
- 读取文件:将读取的文件内容转换为文本格式。
- 文本分割:按照一定的规则(例如按段落、句子或词语)将文本分割成小块,便于处理。
-
向量化存储:
- 文本向量化:使用NLP技术(如TF-IDF、word2vec、BERT)将文本转换为数值向量。
- 存储到向量数据库:将文本的向量存储在向量数据库中,如使用FAISS进行高效存储和检索。
-
问句向量化:
- 这一步将用户的查询或问题转换为向量,使用的方法应与文本向量化相同,确保在相同的向量空间中比较。
-
在文本向量中匹配相似向量:
- 通过计算余弦相似度或欧式距离等,找出与查询向量最相似的顶部k个文本向量。
-
构建问题的上下文:
- 将匹配出的文本作为问题的上下文,与问题一起构成prompt,输入给语言模型。
-
生成回答:
- 将问题和其上下文提交给语言模型(如GPT系列),由模型生成相应的回答。
通用 RAG 就是如此,最终目的是提供精确和相关的信息回答。
实现 ChatPDF
实现 RAG 步骤有很多步,涉及的知识点也很多,直接上已实现的开源项目,不用深入理解里面每个知识点,能用就行。
开源项目:https://github.com/chatchat-space/Langchain-Chatchat
这个项目是 Apache-2.0 license,开源可商用。
conda create -n chatpdf python==3.11.7 # 创建虚拟环境# 拉取仓库
$ git clone https://github.com/chatchat-space/Langchain-Chatchat.git# 进入目录
$ cd Langchain-Chatchat# 安装全部依赖
$ pip install -r requirements.txt
$ pip install -r requirements_api.txt
$ pip install -r requirements_webui.txt # 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。# 模型下载
$ git lfs install
$ git clone https://huggingface.co/THUDM/chatglm4-9b
$ git clone https://huggingface.co/BAAI/bge-large-zh# 初始化知识库和配置文件
$ python copy_config_example.py
$ python init_database.py --recreate-vs# 启动项目
$ python startup.py -a
这个自己实现的 ChatPDF 功能:
- 解读文档,任何领域任何书籍任何专业,都能让人看懂
- 使用RAG,回答是检索不是生成,极大减少幻觉
- 能多文档,不会被长上下文限制(200k)
- 本地部署的模型,不是调用api,不会泄露数据
怎么优化 RAG?
方案1:不同领域下,通用 RAG 方案效果也不好,一般需要按场景定制优化的。
- 比如医学领域,用户搜索感冒,但医学数据库里面是风热流感,关键词不匹配就造成检索错位,只能得到通用信息
- 分解子问题查询 + 多步查询
方案2:通用 RAG 在文本分块的时候,通常只是粗暴的把 pdf 划分为 1500 块,很多关联的上下文被迫分隔。
- 最好是按照规则分块,而不是固定一个块,比如按标题(一级标题、二级标题、三级标题…),这样整个子块的内容都完整
- 再链接每个子块和父文档,复现上下文的相关性
- 如果那个作者标题写法不好,可以使用语义分割(阿里语义分割模型SeqModel)
方案3:PDF 解析时错漏很多信息,比如老年糖尿病标准变成了糖尿病标准,这个很影响效果
- 不能使用 pdf 加载器自动拆分,而是要手动精细拆分,再加上多个选项排序,得到最精准的那个
方案4:词嵌入模型没有经过微调,比如我的数据都是医学的,使用的 embedding 模型 没有经过医学微调,很多名词、概念把握不清,只能捕捉到一些通用的医学术语和语法结构
- 尝试更多embedding模型,获得更精确的检索结果。如:piccolo-large-zh 或 bge-large-zh-v1.5、text2vec、M3E、bge、text-embedding-3 等,或者自己微调词嵌入模型
方案5:如果涉及大量文档,使用 pgVector - 高性能向量数据库引擎,如果存在较多相似的内容,可以考虑分类存放数据,减少冲突的内容
方案6:改进传统 RAG 算法
- 比如动态检索和重排序
- 比如multihop多跳检索
方案7:基于文档中的表格问题,通用 RAG 这块效果不好。
- 优先转为HTML、xml 格式,也可以 OCR
方案8:引入动态 RAG
- 静态 RAG,使用提示词和已向量的数据,检索交互
- 动态 RAG,一边交互,一边把交互内容,生成搜索词,会呼吸的RAG,实现自主更新
相关文章:
实现开源可商用的 ChatPDF RAG:密集向量检索(R)+上下文学习(AG)
实现 ChatPDF & RAG:密集向量检索(R)上下文学习(AG) RAG 是啥?实现 ChatPDF怎么优化 RAG? RAG 是啥? RAG 是检索增强生成的缩写,是一种结合了信息检索技术与语言生成…...

对待谷歌百度等搜索引擎的正确方式
对待百度、谷歌等搜索引擎的方式是,你要站在搜索引擎之上,保持自己的独立思想和意见。 当谷歌宣布他们将会根据一个名为“Alphabet”的新控股公司来进行业务调整时,在科技界引起了一片恐慌之声。 永远不要说这是一个公司一直在做的事情。不…...

pikachu靶场通关全流程
目录 暴力破解: 1.基于表单的暴力破解: 2.验证码绕过(on server): 3.验证码绕过(on client): token防爆破: XSS: 1.反射型xss(get): 2.反射性xss(post): 3.存储型xss&#…...
实现k8s网络互通
前言 不管是docker还是k8s都会在物理机组件虚拟局域网,只不过是它们实现的目标不同。 docker:针对同一个物理机(宿主机) k8s:针对的是多台物理机(宿主机) Docker 虚拟局域网 K8S虚拟局域网 …...

diffusers 使用脚本导入自定义数据集
在训练扩散模型时,如果附加额外的条件图片数据,则需要我们准备相应的数据集。此时我们可以使用官网提供的脚本模板来控制导入我们需要的数据。 您可以参考官方的教程来实现具体的功能需求,为了更加简洁,我将简单描述一下整个流程…...

【Android面试八股文】请讲一讲synchronized和ReentrantLock的区别
文章目录 请讲一讲synchronized和ReentrantLock的区别这道题想考察什么 ?考察的知识点应该如何回答?Synchronized 的原理ReentrantLock 的原理Synchronized 和 ReentrantLock 的区别总结请讲一讲synchronized和ReentrantLock的区别 这道题想考察什么 ? 是否了解并发相关的理…...

springmvc 全局异常处理器配置的三种方式深入底层源码分析原理
文章目录 springmvc 全局异常处理器配置的三种方式&深入底层源码分析原理配置全局异常处理器的三种方式实现接口HandlerExceptionResolver并配置到WebMvcConfigurer注解式配置ExceptionHandlercontroller里方法上定义ExceptionHandler 深入源码分析进入DispatcherServlet执…...

MySQL 8.0 安装、配置、启动、登录、连接、卸载教程
目录 前言1. 安装 MySQL 8.01.1 下载 MySQL 8.01.2 安装 MySQL 8.0 2. 配置 MySQL 8.02.1打开环境变量2.2新建变量 MYSQL_HOME2.3编辑 Path 变量 3. 启动MySQL 8.03.1验证安装与配置是否成功3.2初始化并注册MYSQL3.3 启动MYSQL服务 4.登录MySQL4.1修改账户默认密码4.2登录MYSQL…...
Pythone 程序打包成 exe
1.安装pyinstaller # 安装 pip install pyinstaller # 查看版本 pyinstaller -v2.更新pyinstaller 版本 # 更新 pip install --upgrade pyinstaller # 查看版本 pyinstaller -v3.切换到 py文件所在目录 #切换到.py所在的目录 E: cd cd E:\x-svn_x-local\04PythoneProjects\A…...

“卫星-无人机-地面”遥感数据快速使用及地物含量计算
随着我国高分系列、欧比特系列、自然资源卫星系列等卫星数据的获取,以及美国Headwall、芬兰SPECIM、挪威HySpex、我国双利合谱、智科远达、中科谱光等无人机数据的兴起,遥感数据越来越易得。这些多源数据,在与典型地面点结合后,将…...
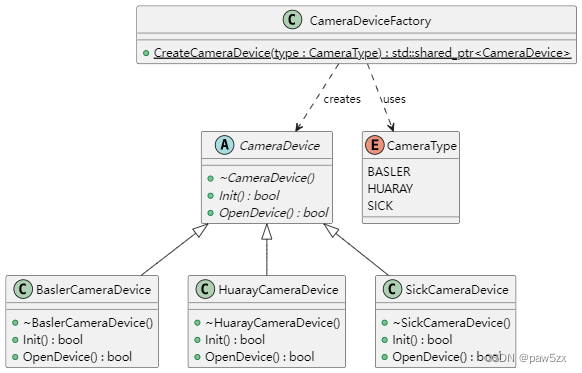
设计模式学习(二)工厂模式——简单工厂模式
设计模式学习(二)工厂模式——简单工厂模式 前言简单工厂模式简介示例优点缺点使用场景 前言 工厂模式是一种常用的设计模式,属于创建型模式之一。它的主要目的是为了解耦组件之间的依赖关系。通过使用工厂模式,系统中的具体类的…...
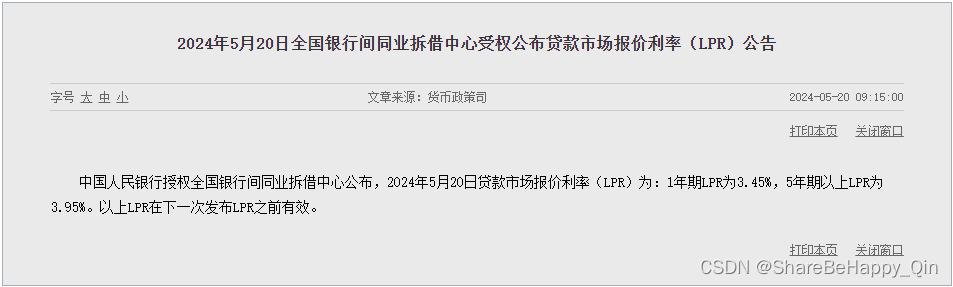
贷款业务——LPR、APR、IRR
文章目录 LPR(Loan Prime Rate)贷款市场报价利率APR(Annual Percentage Rate)年化百分比利率IRR(Internal Rate of Return)内部收益率 LPR、APR 和 IRR 是三个不同的金融术语,LPR 是一种市场利率…...
Simscape Multibody与RigidBodyTree:机器人建模
RigidBodyTree:主要用于表示机器人刚体结构的动力学模型,重点关注机器人的几何结构、质量和力矩,以及它们如何随时间变化。它通常用于计算机器人的运动和受力情况。Simscape Multibody:作为Simscape的一个子模块,专门用…...
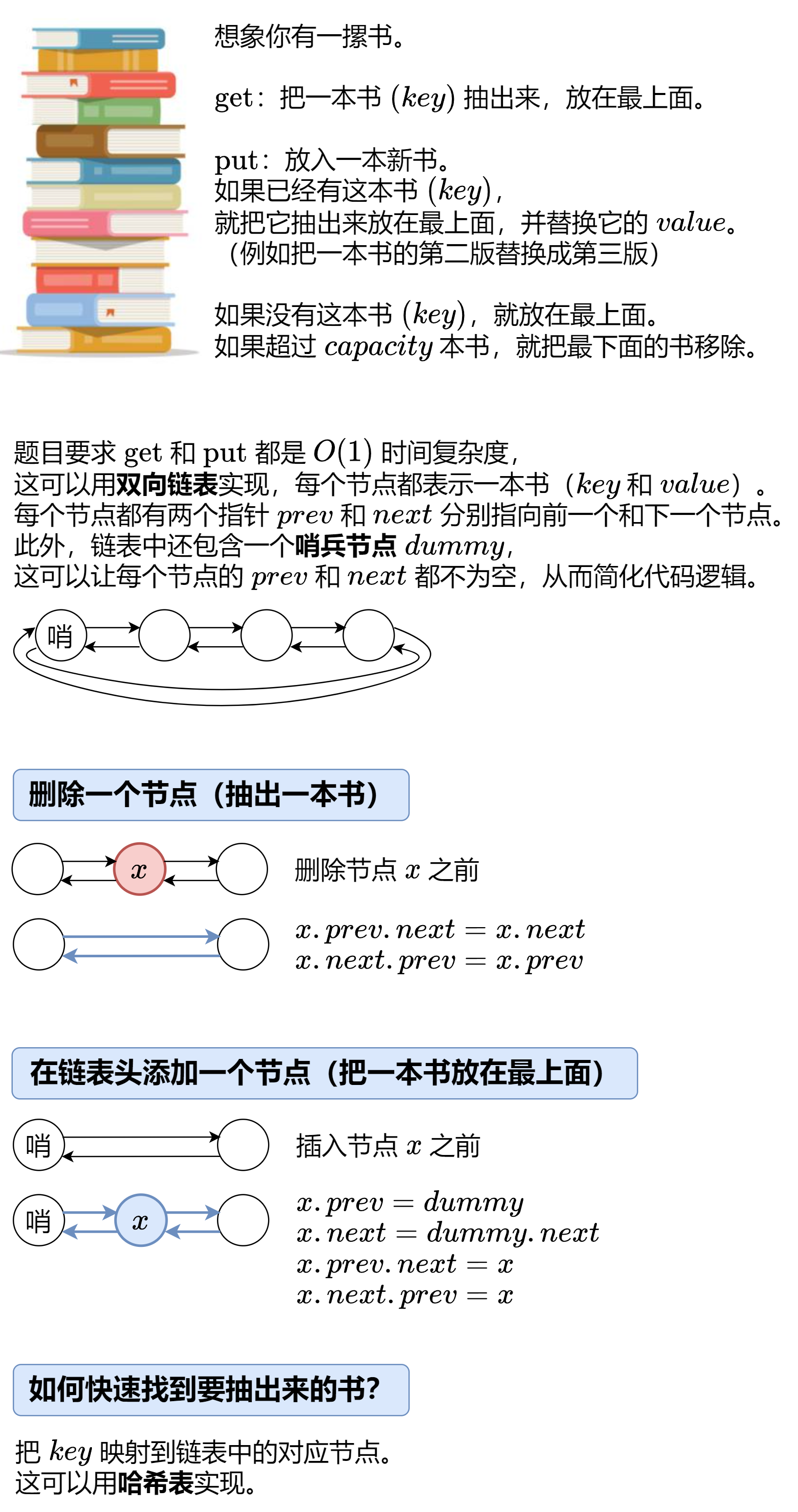
数据结构刷题-链表
数据结构刷题-链表 总结:1 链表的解法总结: 1 链表的知识点:1 LC链表合集:1.1 lc206反转链表: 双指针:lc25: K个一组翻转链表:栈1.2 lc203移除链表元素:1.3 设计链表:1.4…...

Java应届第一年规划
👽System.out.println(“👋🏼嗨,大家好,我是代码不会敲的小符,目前工作于上海某电商服务公司…”); 📚System.out.println(“🎈如果文章中有错误的地方,恳请大家指正&…...
js之简单轮播图
今天给大家封装一个简单的轮播图,可以点击下一张上一张以及自动轮播 <!DOCTYPE html> <html><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>走马…...

GitLab教程(二):快手上手Git
文章目录 1.将远端代码克隆到本地2.修改本地代码并提交到远程仓库3.Git命令总结git clonegit statusgit addgit commitgit pushgit log 首先,我在Gitlab上创建了一个远程仓库,用于演示使用Gitlab进行版本管理的完整流程: 1.将远端代码克隆到本…...
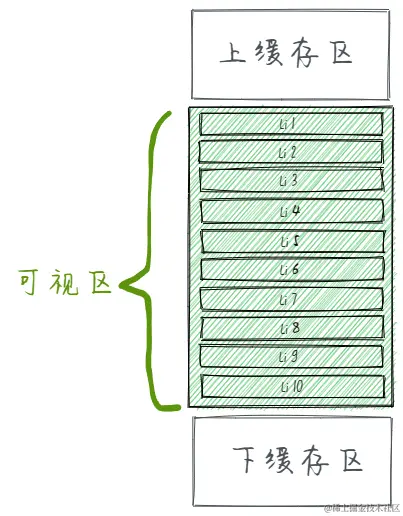
前端渲染大量数据思路【虚拟列表】【异步机制】
当浏览器遇到性能瓶颈导致页面卡顿时,你会怎么处理?如何查找问题的原因? 浏览器本身自带性能检测工具,通常我们分析由脚本导致的页面卡顿会选择 性能(performance) 选项卡,在其中我们可以找到导…...

Ubuntu24.04记录网易邮箱大师的安装
邮箱大师下载 官网自行下载,下载后文件名“mail.deb" https://dashi.163.com/ 安装发现缺少依赖 #mermaid-svg-8wqpqFSBVOPD7NGP {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-8wqpqFSBVOPD7NGP …...
PDF编辑与转换的终极工具智能PDF处理Acrobat Pro DC
Acrobat Pro DC 2023是一款功能全面的PDF编辑管理软件,支持创建、编辑、转换、签署和共享PDF文件。它具备OCR技术,可将扫描文档转换为可编辑文本,同时提供智能PDF处理技术,确保文件完整性和可读性。此外,软件还支持电子…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

DragonBones与Godot集成:骨骼动画的可编程化实践
1. 为什么在Godot里用DragonBones不是“锦上添花”,而是“绕不开的刚需” 去年上线一个横版动作手游Demo时,美术团队交来一套20个角色、每个角色含8套动画(待机/跑动/跳跃/攻击/受击/死亡/闪避/必杀)的Spine资源。我兴冲冲导入God…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

Taotoken如何帮助教育科技产品实现个性化学习辅导
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助教育科技产品实现个性化学习辅导 1. 场景与挑战 教育科技公司在开发个性化学习助手时,常常面临一个核…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...