数据结构刷题-链表
数据结构刷题-链表
- 总结:
- 1 链表的解法总结:
- 1 链表的知识点:
- 1 LC链表合集:
- 1.1 lc206反转链表: 双指针:
- lc25: K个一组翻转链表:栈
- 1.2 lc203移除链表元素:
- 1.3 设计链表:
- 1.4 lc160相交链表: 双指针:指针相遇;
- 1.5 lc2两个链表相加;双指针:
- lc 141环形链表:双指针:快慢指针;龟兔赛跑;
- lc142 环形链表2:
- lc21 合并两个有序链表:三指针
- lc19 删除链表的倒数第N个节点:双指针:快慢指针;
- lc148 排序链表:重点,可以复习排序算法;
- lc23 合并k个升序链表:hard:
- lc146 LRU缓存:
- 2 面试手撕-关于链表:
链表应该是面试时被提及最频繁的数据结构。链表的结构很简单,它由指针把若干个节点连接乘链状结构。链表的常见,插入节点,删除节点,等操作只需要20行左右代码就可以实现,其代码量非常适合面试。所以这也是我面试百度的时候,面试官上来就问我如何反转一个链表? 以及如何以K组进行链表的反转?所以lc hot100上面关于链表的题目,基本上都要能背出来的水平。
总结:
1 链表的解法总结:
- 1,双指针:
比如翻转链表,环形链表,删除倒数第n个节点;相交链表;
链表题目是把双指针发挥利用到极致的题目,因为只能一步一步遍历,没有办法。
- 2,虚拟头结点;合并有序链表(虚拟头+双指针)
链表的一大问题就是操作当前节点必须要找前一个节点才能操作。这就造成了,头结点的尴尬,因为头结点没有前一个节点了。
每次对应头结点的情况都要单独处理,所以使用虚拟头结点的技巧,就可以解决这个问题。
- 3,排序问题:排序算法
其实排序链表,基本上就算是数组排序的变种吧,感觉差别不是很大。
1 链表的知识点:
链表是一个动态数据结构,在创建链表时,无须知道链表的长度。当插入一个节点时,只需要为这个新节点分配内存,然后调整指针指向就好了。 内存分配也不是在常见链表时一次性完成的,而是每添加一个节点分配一次内存。 由于没有闲置内存,所以链表的空间效率较高。
单向链表的节点定义如下:
Definition for singly-linked list.
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = next由于链表中的内存不是一次性分配的,因而我们在访问链表中第i个节点时,只能从头开始,按照指向去找到某个节点。
感觉就跟走地图一样,你只有先走到某个地方,然后按照npc的指引,才能到达目的地。而列表就相当于你已经把这些地方打通关了,到时候要是想再来这个地方,直接传送就好了。
要掌握链表的操作方式,如何使用以及如何连接下一级;
值是值,next是next;看你调用啥。
一般来说,如下面代码所示:head不是一个列表形式的,不能遍历的。
只是一个节点,本身具有值以及指向后面的值。
比如下面这张图所示,head只是开头的数字节点罢了。
也很简单,那就是找到你想要输出顺序的头,比如下面的代码,最后输出的是pre,因为pre就是指向性的头。这样的话,代码会自动的输出整个链表的值。
就是因为没有搞懂链表,所以连输出都不会输出,甚至连指向啥的也不会。
return dummy_head.next
1 LC链表合集:
1.1 lc206反转链表: 双指针:
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。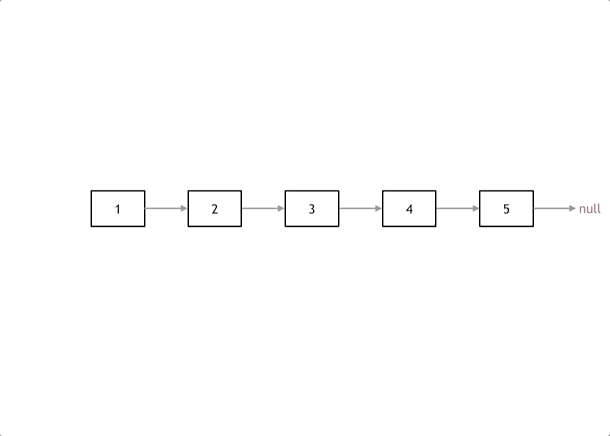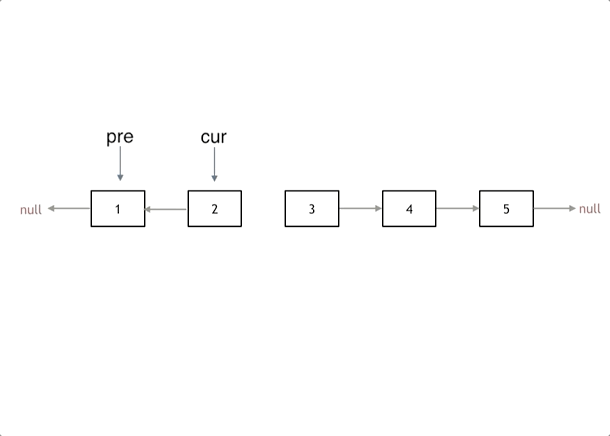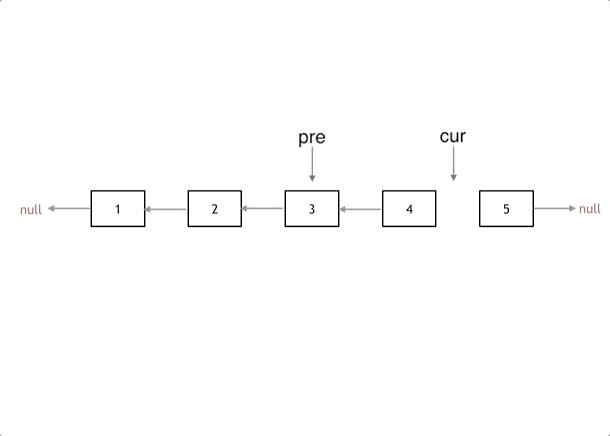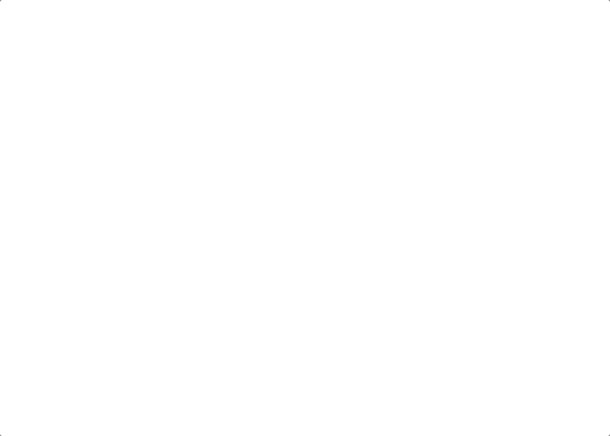
解法:1,添加为无的pre; 2,暂存下一节点;3,反转;4,两个节点,移动更新;
使用技法:双指针;
#Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = nextclass Solution:def reverseList(self, head: ListNode) -> ListNode:cur = head pre = None # 虚拟头,未构建关联;后面会构建指向;while cur:next_node = cur.next # 保存一下 cur的下一个节点,因为接下来要改变cur->nextcur.next = pre #反转#更新pre、cur指针pre = curcur = next_nodereturn pre
lc25: K个一组翻转链表:栈
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
自己想了好几种解法,都没有办法写出来,但是看到一种解法,感觉非常有意思。
借助了栈的帮助,把问题变的非常简单了。
class Solution:def reverseKGroup(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:# 双指针# 使用栈;# 虚拟头;# 如果不满足K的时候,不翻转,这个怎么做到的?直接返回h = t = dum = ListNode(next = head)p,stack = head,[]while True:for _ in range(k):# 入栈if p:stack.append(p)p = p.nextelse:# 输出return h.next# 出栈for _ in range(k):t.next = stack.pop()t = t.next#中间连接t.next = p1.2 lc203移除链表元素:
果然,自己写过的题目,还是不会写。其原因在于没有深层次的搞明白。深层次的总结他们区别。内化成自己的东西。
使用技法:虚拟头;虚拟头指向head,避免第一个元素就要删除的麻烦。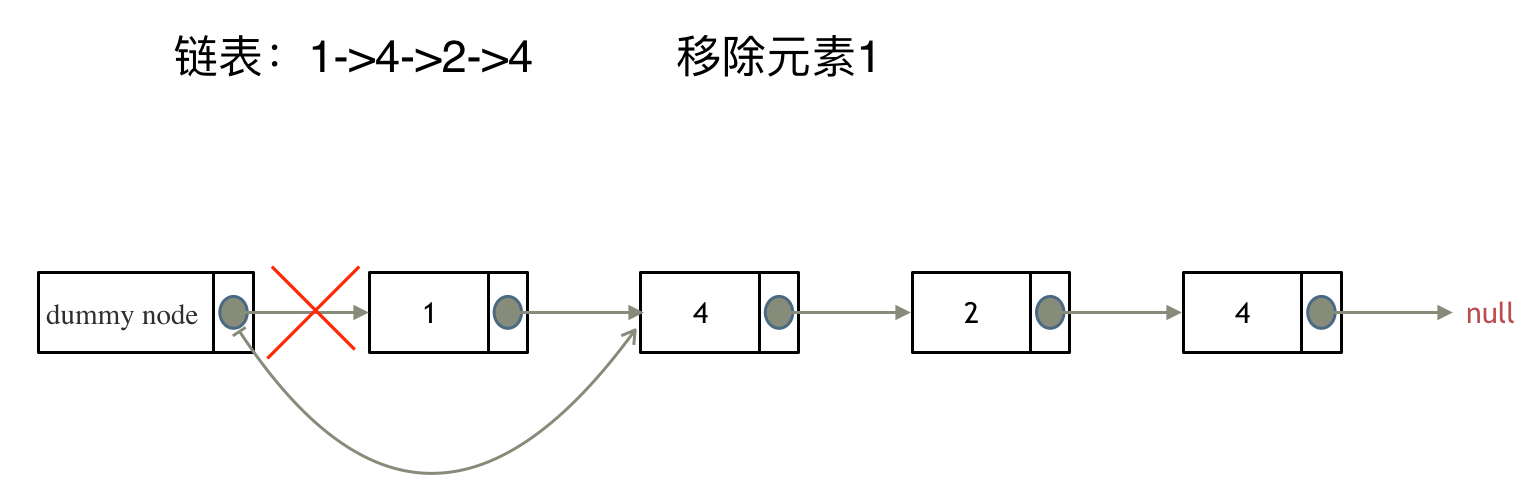
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def removeElements(self, head: Optional[ListNode], val: int) -> Optional[ListNode]:# 使用虚拟头的方法,# 每次检查当前值的下一个值是否为目标值,如果为目标值,则讲目标值的后面一个值变成下一个# 构建虚拟头, 构建关联dummy_head = ListNode(next = head)# 遍历curr = dummy_headwhile curr.next:if curr.next.val == val:curr.next = curr.next.nextelse:curr = curr.nextreturn dummy_head.next- 时间复杂度: O(n)
- 空间复杂度: O(1)
1.3 设计链表:
通过设计链表,感受到了链表是如何进行操作的。
比如说,虚拟头,感觉这个虚拟头挺有用的。
重点可以可能啊get,这个里面想要得到某个值,需要curr = dummy_head.next,然后一步一步的走,才能到第多少个,难道不能像列表那样,直接得到某个位置的值吗?
不可以直接得到,因为内存不是连续的,不知道下面一个是啥。
(版本一)单链表法
class ListNode:def __init__(self, val=0, next=None):self.val = valself.next = nextclass MyLinkedList:def __init__(self):self.dummy_head = ListNode()self.size = 0def get(self, index: int) -> int:if index < 0 or index >= self.size:return -1current = self.dummy_head.nextfor i in range(index):current = current.nextreturn current.valdef addAtHead(self, val: int) -> None:self.dummy_head.next = ListNode(val, self.dummy_head.next)self.size += 1def addAtTail(self, val: int) -> None:current = self.dummy_headwhile current.next:current = current.nextcurrent.next = ListNode(val)self.size += 1def addAtIndex(self, index: int, val: int) -> None:if index < 0 or index > self.size:returncurrent = self.dummy_headfor i in range(index):current = current.nextcurrent.next = ListNode(val, current.next)self.size += 1def deleteAtIndex(self, index: int) -> None:if index < 0 or index >= self.size:returncurrent = self.dummy_headfor i in range(index):current = current.nextcurrent.next = current.next.nextself.size -= 1# Your MyLinkedList object will be instantiated and called as such:
# obj = MyLinkedList()
# param_1 = obj.get(index)
# obj.addAtHead(val)
# obj.addAtTail(val)
# obj.addAtIndex(index,val)
# obj.deleteAtIndex(index)
1.4 lc160相交链表: 双指针:指针相遇;
解法:
就是走路问题,感觉跟脑筋急转弯一样。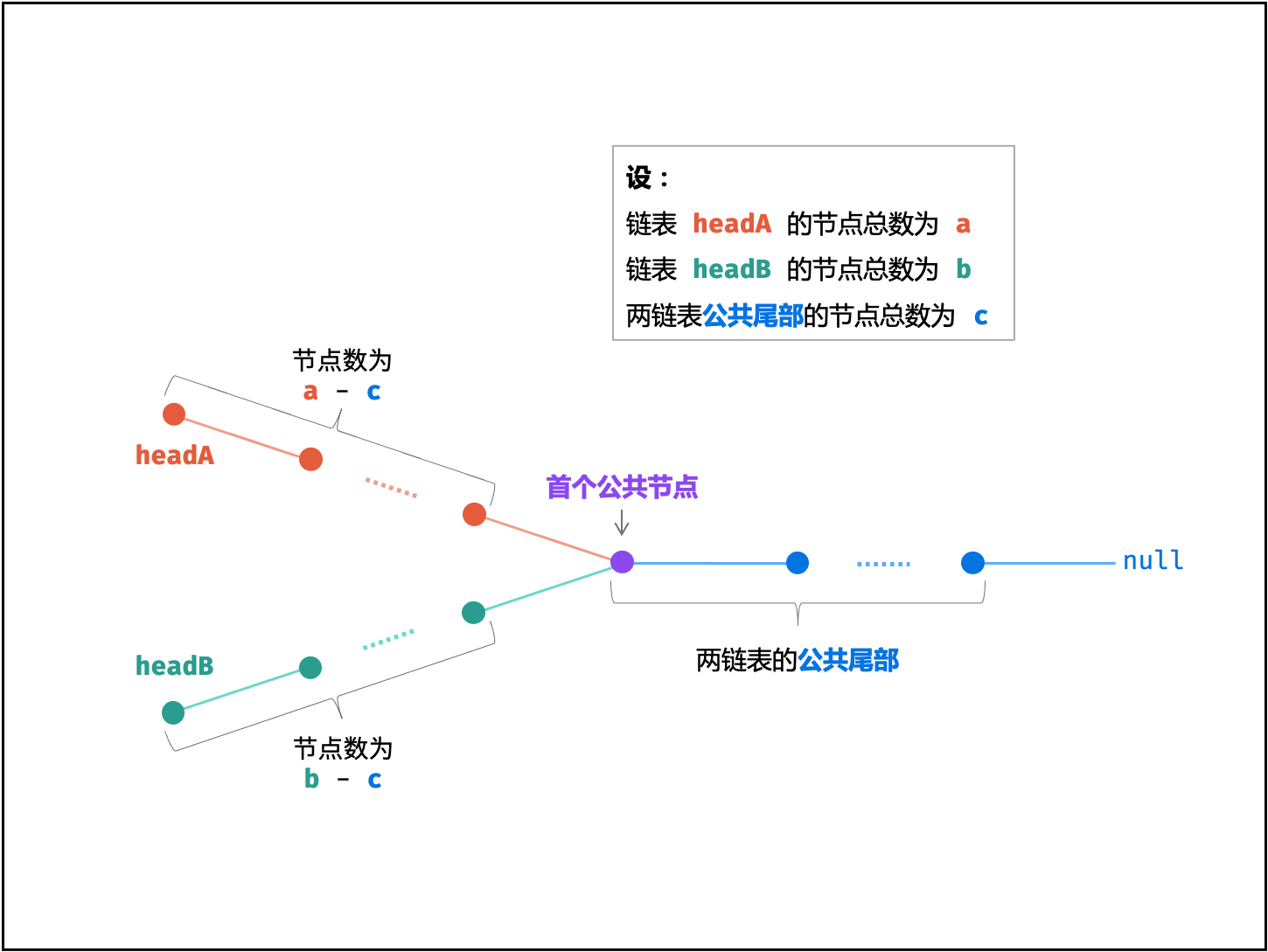

复杂度分析:
时间复杂度 O(a+b): 最差情况下(即 ∣a−b∣=1 , c=0 ),此时需遍历 a+b个节点。
空间复杂度 O(1): 节点指针 A , B 使用常数大小的额外空间。
作者:Krahets
链接:https://leetcode.cn/problems/intersection-of-two-linked-lists/solutions/12624/intersection-of-two-linked-lists-shuang-zhi-zhen-l/
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = Noneclass Solution:def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> Optional[ListNode]:# 怎么感觉1也那么像呢?怎么判断的呢?# 看了题解,就明白了,两个链表相交的点,# 就是a走一步,b走一步, a走完自己去走b,b走完自己去走a;他们第二次相遇的地方,就是重合的地方;因为走的距离是一样的;# 也算是双指针;a ,b = headA,headBwhile a != b:if a:a = a.nextelse:a = headBif b:b = b.nextelse:b = headAreturn a
1.5 lc2两个链表相加;双指针:
自己的解法超时了,确实太冗余了:其实本身把各位放在前面,就是为了方便你进位的;
自己的这种想法太垃圾了,太慢了,应该把计算进位一起放到求和里面;
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:# 1,先读取,然后数字再相加,然后再生成链表?def get_num(list_node):num = 0res = 0while list_node:res = list_node.val*(10**num) + resnum += 1return resnum1 = get_num(l1)num2 = get_num(l2)num = num1 +num2# 构建反向列表,以虚拟头0为开头dummy_node = ListNode(0)prev = dummy_nodewhile num == 0:prev.next = num%10# 更新num = num//10prev = prev.nextreturn dummy_node.next按照自己的想法写了一个版本,但是还是不对,超时了,不知道什么情况。
而且他的这种写法非常Nb,通过or判断,判断进位是否用完了。
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:# 1,依次读取,相加进位# 新建一个,从0开始的虚拟头dummy_node = ListNode(0)cur = dummy_nodenum_jin = 0while l1 or l2 or num_jin:# 需要加上一些判断,因为l1和l2长度不一样num_jin = (l1.val if l1 else 0) + (l2.val if l2 else 0) + num_jincur.next = ListNode(num_jin%10)num_jin //= 10cur = cur.next# 记得更新if l1 :l1 = l1.nextif l2:l2 = l2.nextreturn dummy_node.next
lc 141环形链表:双指针:快慢指针;龟兔赛跑;
给你一个链表的头节点 head ,判断链表中是否有环。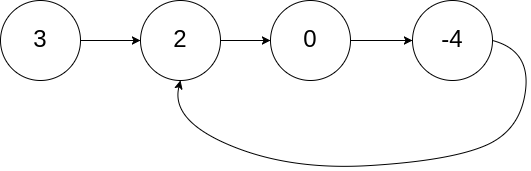
解法:
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = Noneclass Solution:def hasCycle(self, head: Optional[ListNode]) -> bool:# 龟兔赛跑fast = headslow = head# 如果fast的下面一个值没有值;while fast and fast.next:fast = fast.next.nextslow = slow.nextif fast == slow:return Truereturn False
lc142 环形链表2:
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
考察两个知识点:1,有无环;2,环的开头;
有无环使用快慢指针,环的开头需要推导: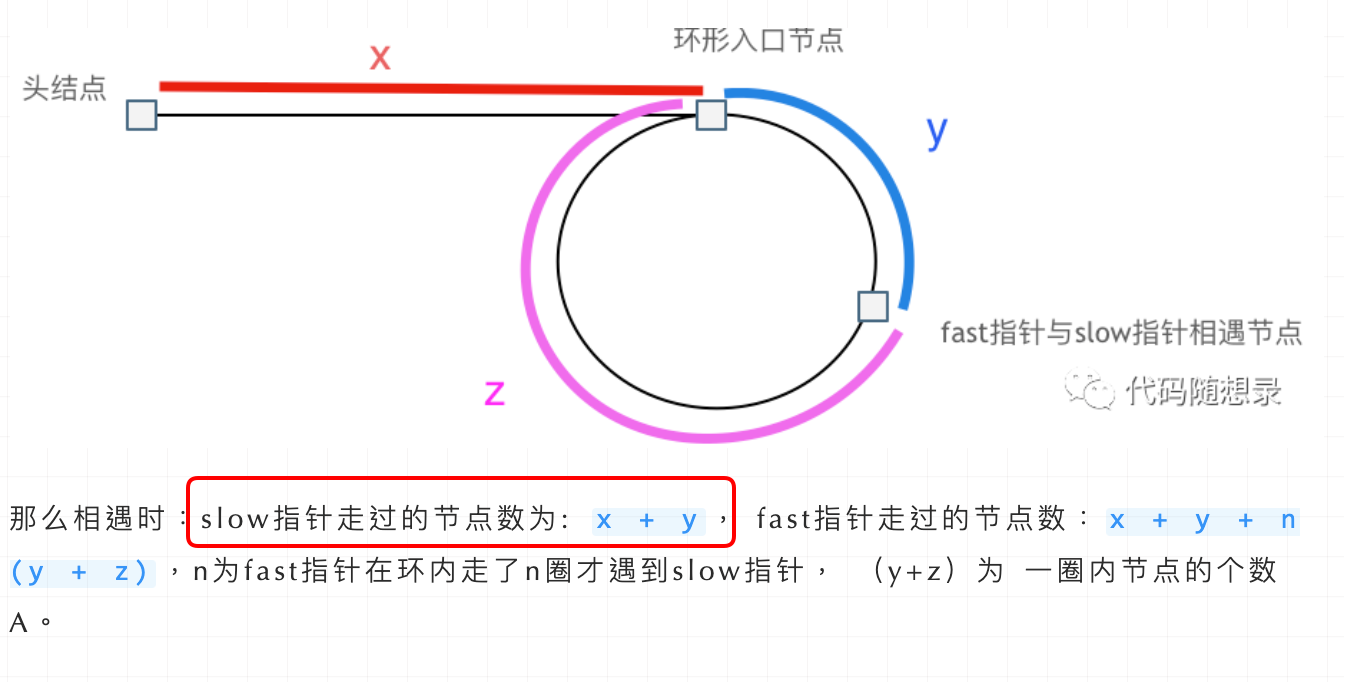
解法1; 快慢指针:
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = Noneclass Solution:def detectCycle(self, head: Optional[ListNode]) -> Optional[ListNode]:# 首先是判断有环,使用龟兔赛跑;# 然后是判断环的入口,使用乌龟的路径? # 使用龟兔的双指针是可以的,但是感觉推导非常的繁琐;# 虽然可以使用哈希表的方法,但是假如遇到那种节点相同的元素,可能就不怎么适用了# 使用快慢指针的公式推导fast,slow = head,headwhile fast and fast.next:fast = fast.next.nextslow = slow.nextif fast == slow:slow = headwhile slow != fast:slow= slow.nextfast=fast.nextreturn fastreturn None
解法2:哈希表:但是感觉不鲁棒: 如果遇到相同的数字,就直接G了。
class Solution(object): def detectCycle(self, head): a = head dic = {} while a: if a in dic: return a dic[a] = True # 这里只需要一个标记,不需要具体的值 a = a.next return None
lc21 合并两个有序链表:三指针
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
相当于三指针:两个指针进行比较;一个指针进行构建;
重点在于构建虚拟头:prehead = Listnode(0);
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:# 通过比较,来构建指向;# 双指针# 需要在最前面构建一个节点,这个节点方便构建整个链表# 构建这个prehead也是为了方便输出;prehead = ListNode(0) # prev = preheadwhile list1 and list2:# 对比 1和2if list1.val <= list2.val:prev.next = list1# 更新list1 = list1.nextelse:prev.next = list2# list2 = list2.next# prev也要动,更新prev = prev.next# 某个链表里面还剩下一个;prev.next = list1 if list1 else list2return prehead.next
lc19 删除链表的倒数第N个节点:双指针:快慢指针;
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
解法:删除链表中某个节点简单,但是因为链表中没有节点数量这一说。 怎么去对链表的节点数量进行计数呢? 而且是倒数第N个节点。
下面是我的想法,是先利用列表来进行计算;但是感觉太繁琐了,使用了两次遍历;
class Solution:def removeNthFromEnd(self, head: Optional[ListNode], n: int) -> Optional[ListNode]:# 可以使用栈吗?使用栈还不如使用列表吗?# 加入列表,计数# 需要加上虚拟头;为了防止只有一个数的;cur = headlist1 = []while cur:list1.append(cur.val)cur = cur.nextif len(list1) <=1:return Nonel = len(list1)-n# 需要加上虚拟头;为了防止只有一个数的;dum = ListNode(next = head)cur = dumcount = 0while cur and cur.next:if count == l:cur.next = cur.next.nextelse:cur = cur.nextcount += 1return dum.next双指针:快慢指针法:快指针先走n步;
class Solution:def removeNthFromEnd(self, head: Optional[ListNode], n: int) -> Optional[ListNode]:# 双指针;快慢指针# 需要加上虚拟头;为了防止只有一个数的;dum = ListNode(next=head)fast= slow = dum# 快指针先走;for _ in range(n+1):fast = fast.next # 然后一起走,当fast为空,slow也到了while fast:fast = fast.nextslow = slow.next# 然后删除slow.next = slow.next.nextreturn dum.next
lc148 排序链表:重点,可以复习排序算法;
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。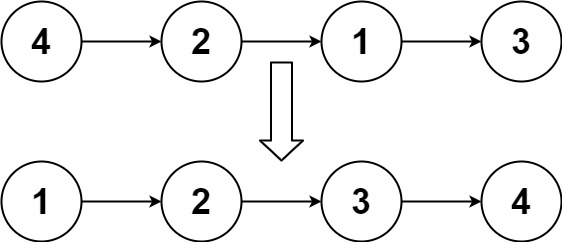
解法:
作者:ITCharge
链接:https://leetcode.cn/problems/sort-list/solutions/1785874/by-itcharge-01zg/
可以参考数据排序的知识点。在数组排序中,常见的排序算法有:冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序、堆排序、计数排序、桶排序、基数排序等。
而对于链表排序而言,因为链表不支持随机访问,访问链表后面的节点只能依靠 next 指针从头部顺序遍历,所以相对于数组排序问题来说,链表排序问题会更加复杂一点。
下面先来总结一下适合链表排序与不适合链表排序的算法:
适合链表的排序算法:冒泡排序、选择排序、插入排序、归并排序、快速排序、计数排序、桶排序、基数排序。
不适合链表的排序算法:希尔排序。
可以用于链表排序但不建议使用的排序算法:堆排序。
希尔排序为什么不适合链表排序?
希尔排序:希尔排序中经常涉及到对序列中第 i + gap 的元素进行操作,其中 gap 是希尔排序中当前的步长。而链表不支持随机访问的特性,导致这种操作不适合链表,因而希尔排序算法不适合进行链表排序。
为什么不建议使用堆排序?
堆排序:堆排序所使用的最大堆 / 最小堆结构本质上是一棵完全二叉树。而完全二叉树适合采用顺序存储结构(数组)。因为数组存储的完全二叉树可以很方便的通过下标序号来确定父亲节点和孩子节点,并且可以极大限度的节省存储空间。
而链表用在存储完全二叉树的时候,因为不支持随机访问的特性,导致其寻找子节点和父亲节点会比较耗时,如果增加指向父亲节点的变量,又会浪费大量存储空间。所以堆排序算法不适合进行链表排序。
如果一定要对链表进行堆排序,则可以使用额外的数组空间表示堆结构。然后将链表中各个节点的值依次添加入堆结构中,对数组进行堆排序。排序后,再按照堆中元素顺序,依次建立链表节点,构建新的链表并返回新链表头节点。
需要用到额外的辅助空间进行排序的算法
刚才我们说到如果一定要对链表进行堆排序,则需要使用额外的数组空间。除此之外,计数排序、桶排序、基数排序都需要用到额外的数组空间。
接下来,我们将对适合链表排序的 8 种算法进行一一讲解。当然,这些排序算法不用完全掌握,重点是掌握 「链表插入排序」、「链表归并排序」 这两种排序算法。
**思路1:**链表冒泡排序(超时),让我学到的是,竟然可以直接就像数组一样,直接交换节点的数值;好像并没有改变指向性。
class Solution:def bubbleSort(self, head: ListNode):node_i = headtail = None# 外层循环次数为 链表节点个数while node_i:node_j = headwhile node_j and node_j.next != tail:if node_j.val > node_j.next.val:# 交换两个节点的值node_j.val, node_j.next.val = node_j.next.val, node_j.valnode_j = node_j.next# 尾指针向前移动 1 位,此时尾指针右侧为排好序的链表tail = node_jnode_i = node_i.nextreturn headdef sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:return self.bubbleSort(head)
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
思路2:链表选择排序:超时;
每次找最小值,然后放在前面;
class Solution:def sectionSort(self, head: ListNode):node_i = head# node_i 为当前未排序链表的第一个链节点while node_i and node_i.next:# min_node 为未排序链表中的值最小节点min_node = node_inode_j = node_i.nextwhile node_j:if node_j.val < min_node.val:min_node = node_jnode_j = node_j.next# 交换值最小节点与未排序链表中第一个节点的值if node_i != min_node:node_i.val, min_node.val = min_node.val, node_i.valnode_i = node_i.nextreturn headdef sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:return self.sectionSort(head)
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
思路3:链表插入排序(超时)
创建一个新的链表,然后一个一个通过比较,插入进去。
class Solution:def insertionSort(self, head: ListNode):if not head or not head.next:return headdummy_head = ListNode(-1)dummy_head.next = headsorted_list = headcur = head.next while cur:if sorted_list.val <= cur.val:# 将 cur 插入到 sorted_list 之后sorted_list = sorted_list.next else:prev = dummy_headwhile prev.next.val <= cur.val:prev = prev.next# 将 cur 到链表中间sorted_list.next = cur.nextcur.next = prev.nextprev.next = curcur = sorted_list.next return dummy_head.nextdef sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:return self.insertionSort(head)
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
思路4:链表归并排序:(通过)
题目要求时间空间复杂度分别为 O(nlogn) 和 O(1),根据时间复杂度我们自然想到二分法,从而联想到归并排序;
通过递归实现链表归并排序,有以下两个环节: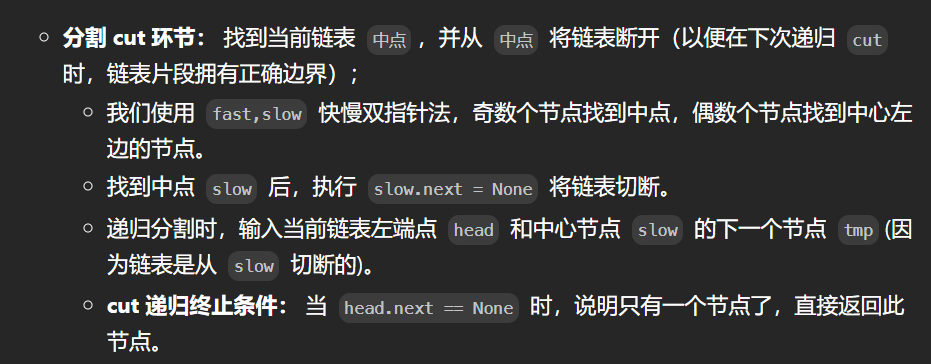

class Solution:def sortList(self, head: ListNode) -> ListNode:if not head or not head.next: return head # termination.# cut the LinkedList at the mid index.slow, fast = head, head.nextwhile fast and fast.next:fast, slow = fast.next.next, slow.nextmid, slow.next = slow.next, None # save and cut.# recursive for cutting.left, right = self.sortList(head), self.sortList(mid)# merge `left` and `right` linked list and return it.h = res = ListNode(0)while left and right:if left.val < right.val: h.next, left = left, left.nextelse: h.next, right = right, right.nexth = h.nexth.next = left if left else rightreturn res.next作者:Krahets
链接:https://leetcode.cn/problems/sort-list/solutions/13728/sort-list-gui-bing-pai-xu-lian-biao-by-jyd/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
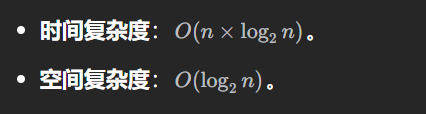
思路5:链表快速排序:超时,感觉这些算法,很多只要你把数组上的理解了,放到链表上也不是问题。
从链表中找到一个基准值 pivot,这里以头节点为基准值。
然后通过快慢指针 node_i、node_j 在链表中移动,使得 node_i 之前的节点值都小于基准值,node_i 之后的节点值都大于基准值。从而把数组拆分为左右两个部分。
再对左右两个部分分别重复第二步,直到各个部分只有一个节点,则排序结束。
注意:
虽然链表快速排序算法的平均时间复杂度为 O(n×log2n)。但链表快速排序算法中基准值 pivot 的取值做不到数组快速排序算法中的随机选择。一旦给定数据是有序链表,时间复杂度就会退化到O(n^2)。这也是这道题目使用链表快速排序容易超时的原因。
class Solution:def partition(self, left: ListNode, right: ListNode):# 左闭右开,区间没有元素或者只有一个元素,直接返回第一个节点if left == right or left.next == right:return left# 选择头节点为基准节点pivot = left.val# 使用 node_i, node_j 双指针,保证 node_i 之前的节点值都小于基准节点值,node_i 与 node_j 之间的节点值都大于等于基准节点值node_i, node_j = left, left.nextwhile node_j != right:# 发现一个小与基准值的元素if node_j.val < pivot:# 因为 node_i 之前节点都小于基准值,所以先将 node_i 向右移动一位(此时 node_i 节点值大于等于基准节点值)node_i = node_i.next# 将小于基准值的元素 node_j 与当前 node_i 换位,换位后可以保证 node_i 之前的节点都小于基准节点值node_i.val, node_j.val = node_j.val, node_i.valnode_j = node_j.next# 将基准节点放到正确位置上node_i.val, left.val = left.val, node_i.valreturn node_idef quickSort(self, left: ListNode, right: ListNode):if left == right or left.next == right:return leftpi = self.partition(left, right)self.quickSort(left, pi)self.quickSort(pi.next, right)return leftdef sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:if not head or not head.next:return headreturn self.quickSort(head, None)lc23 合并k个升序链表:hard:
给你一个链表数组,每个链表都已经按升序排列。请你将所有链表合并到一个升序链表中,返回合并后的链表。
解法:
思路1:两两合并: time>16%
我知道如何合并,如何合并两个,那三个是不是一样?
重点注意在两两合并时,不要忽略当l1或l2某一个已经完成之后,另外一个还没完成,要接上去。
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:# 两个可以合并,三个是不是调用两个的函数就ok了# 合并两个def merge_two(list1,list2):dum = ListNode(0)cur = dumwhile list1 and list2:if list1.val < list2.val:cur.next = list1list1 = list1.nextelse:cur.next = list2list2 = list2.nextcur = cur.next# 连接后续非空链表cur.next = list1 if list1 else list2return dum.nextif not lists:return Noneres = lists[0]for i in range(len(lists)-1):res = merge_two(res,lists[i+1])return res思路2:归并排序:time>60%
最后的两链表合并部分不变,上部的两两合并改成归并形式的递归操作。
class Solution:def mergeKLists(self, lists: List[ListNode]) -> ListNode:if not lists: return Nonen = len(lists) #记录子链表数量return self.mergeSort(lists, 0, n - 1) #调用归并排序函数def mergeSort(self, lists: List[ListNode], l: int, r: int) -> ListNode:if l == r:return lists[l]m = (l + r) // 2L = self.mergeSort(lists, l, m) #循环的递归部分R = self.mergeSort(lists, m + 1, r)return self.mergeTwoLists(L, R) #调用两链表合并函数def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:dummy = ListNode(0) #构造虚节点move = dummy #设置移动节点等于虚节点while l1 and l2: #都不空时if l1.val < l2.val:move.next = l1 #移动节点指向数小的链表l1 = l1.nextelse:move.next = l2l2 = l2.nextmove = move.nextmove.next = l1 if l1 else l2 #连接后续非空链表return dummy.next #虚节点仍在开头
思路3:最小堆: time>90%:
利用堆的数据结构,可以极大地简化代码。
class Solution:def mergeKLists(self, lists: List[ListNode]) -> ListNode:import heapq #调用堆minHeap = []for listi in lists: while listi:heapq.heappush(minHeap, listi.val) #把listi中的数据逐个加到堆中listi = listi.nextdummy = ListNode(0) #构造虚节点p = dummywhile minHeap:p.next = ListNode(heapq.heappop(minHeap)) #依次弹出最小堆的数据p = p.nextreturn dummy.next
lc146 LRU缓存:
没看懂,感觉应该也不会考这种题目。
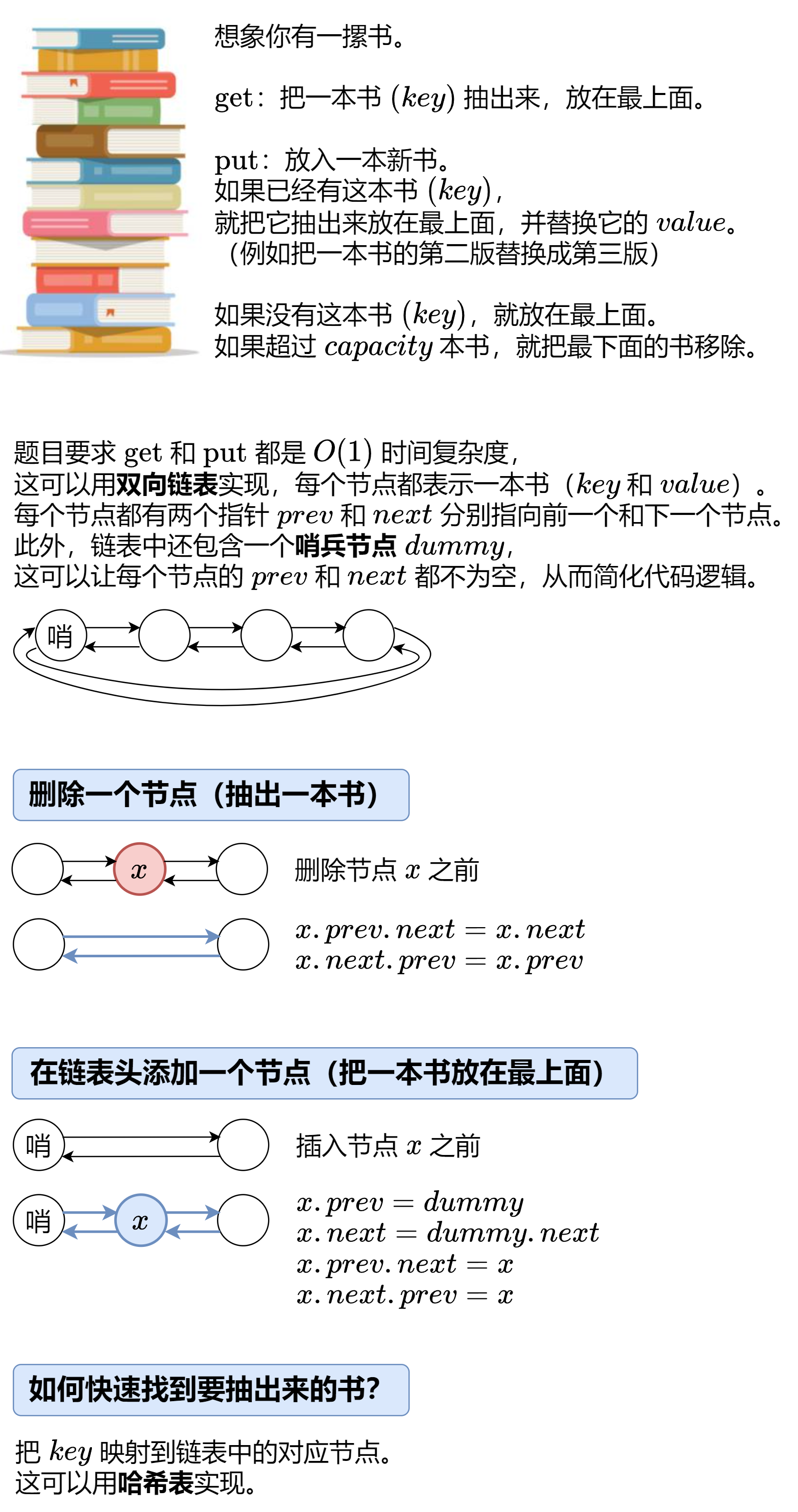
class Node:# 提高访问属性的速度,并节省内存__slots__ = 'prev', 'next', 'key', 'value'def __init__(self, key=0, value=0):self.key = keyself.value = valueclass LRUCache:def __init__(self, capacity: int):self.capacity = capacityself.dummy = Node() # 哨兵节点self.dummy.prev = self.dummyself.dummy.next = self.dummyself.key_to_node = dict()def get_node(self, key: int) -> Optional[Node]:if key not in self.key_to_node: # 没有这本书return Nonenode = self.key_to_node[key] # 有这本书self.remove(node) # 把这本书抽出来self.push_front(node) # 放在最上面return nodedef get(self, key: int) -> int:node = self.get_node(key)return node.value if node else -1def put(self, key: int, value: int) -> None:node = self.get_node(key)if node: # 有这本书node.value = value # 更新 valuereturnself.key_to_node[key] = node = Node(key, value) # 新书self.push_front(node) # 放在最上面if len(self.key_to_node) > self.capacity: # 书太多了back_node = self.dummy.prevdel self.key_to_node[back_node.key]self.remove(back_node) # 去掉最后一本书# 删除一个节点(抽出一本书)def remove(self, x: Node) -> None:x.prev.next = x.nextx.next.prev = x.prev# 在链表头添加一个节点(把一本书放在最上面)def push_front(self, x: Node) -> None:x.prev = self.dummyx.next = self.dummy.nextx.prev.next = xx.next.prev = x作者:灵茶山艾府
链接:https://leetcode.cn/problems/lru-cache/solutions/2456294/tu-jie-yi-zhang-tu-miao-dong-lrupythonja-czgt/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2 面试手撕-关于链表:
2.1 百度-模型工程:
问题:请你反转链表; 请你以K为一组反转链表;
注意要自己定义链表类;
翻转链表:双指针;
以K为一组翻转链表: 使用栈;
2.2 虾皮笔试:合并升序链表:lc21:
这个比较简单,参考lc21;k可以说是使用三指针;注意合并的时候,某一个还剩下的尾巴。
2.3 暑期字节一面:阿里云暑期一面:拼多多面试:
要求要有优化;
合并K个升序链表,原题;请看lc23,可以两两合并,也可以使用归并-递归的方式。
2.4 华为:链表去重;
2.5 华为:手撕:删除链表倒数第n个节点:
2.6 字节跳动:找到两链表第一个公共节点,翻转单链表,判断链表是否有环
相关文章:
数据结构刷题-链表
数据结构刷题-链表 总结:1 链表的解法总结: 1 链表的知识点:1 LC链表合集:1.1 lc206反转链表: 双指针:lc25: K个一组翻转链表:栈1.2 lc203移除链表元素:1.3 设计链表:1.4…...

Java应届第一年规划
👽System.out.println(“👋🏼嗨,大家好,我是代码不会敲的小符,目前工作于上海某电商服务公司…”); 📚System.out.println(“🎈如果文章中有错误的地方,恳请大家指正&…...
js之简单轮播图
今天给大家封装一个简单的轮播图,可以点击下一张上一张以及自动轮播 <!DOCTYPE html> <html><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>走马…...

GitLab教程(二):快手上手Git
文章目录 1.将远端代码克隆到本地2.修改本地代码并提交到远程仓库3.Git命令总结git clonegit statusgit addgit commitgit pushgit log 首先,我在Gitlab上创建了一个远程仓库,用于演示使用Gitlab进行版本管理的完整流程: 1.将远端代码克隆到本…...
前端渲染大量数据思路【虚拟列表】【异步机制】
当浏览器遇到性能瓶颈导致页面卡顿时,你会怎么处理?如何查找问题的原因? 浏览器本身自带性能检测工具,通常我们分析由脚本导致的页面卡顿会选择 性能(performance) 选项卡,在其中我们可以找到导…...

Ubuntu24.04记录网易邮箱大师的安装
邮箱大师下载 官网自行下载,下载后文件名“mail.deb" https://dashi.163.com/ 安装发现缺少依赖 #mermaid-svg-8wqpqFSBVOPD7NGP {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-8wqpqFSBVOPD7NGP …...
PDF编辑与转换的终极工具智能PDF处理Acrobat Pro DC
Acrobat Pro DC 2023是一款功能全面的PDF编辑管理软件,支持创建、编辑、转换、签署和共享PDF文件。它具备OCR技术,可将扫描文档转换为可编辑文本,同时提供智能PDF处理技术,确保文件完整性和可读性。此外,软件还支持电子…...
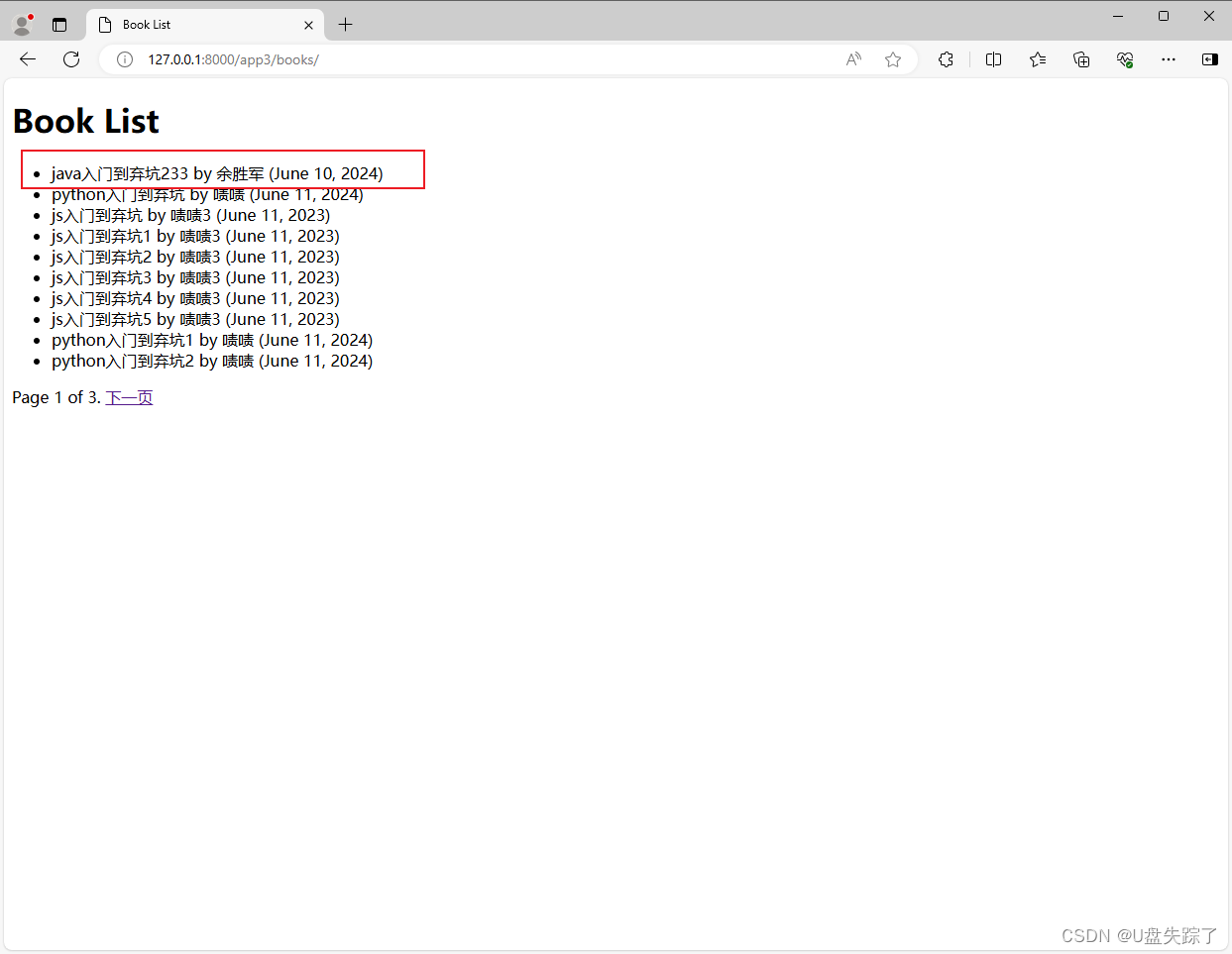
Django UpdateView视图
UpdateView是Django中的一个通用视图,用于处理对象的更新操作。它允许用户更新一个已经存在的对象。UpdateView通常与一个模型表单一起使用,这样用户就可以看到当前对象的值,并可以修改它们。 1,添加视图 Test/app3/views.py fr…...

【CS.SE】2024年,你应该选择计算机专业吗?详细分析与未来展望
文章目录 1. 引言1.1 背景介绍 2. 计算机相关专业的现状与挑战2. 计算机相关专业的现状与挑战2.1 行业内的就业趋势2.1.1 现有就业数据2.1.2 行业需求变化 2.2 市场饱和度与竞争2.2.1 毕业生数量增长2.2.2 薪资与职业发展 2.3 技术创新与行业发展2.3.1 新兴技术的发展2.3.2 全球…...

后端开发面经系列 -- 华为OD -- C++面经(全)
华为OD – C面经(全) 公众号:阿Q技术站 文章目录 华为OD -- C面经(全)一面1、C结构体和类的区别,类默认的访问权限,结构体可以定义成员函数吗?2、多态的意义?多态的意义…...
3072. 将元素分配到两个数组中 II Rust 线段树 + 离散化
题目 给你一个下标从 1 开始、长度为 n 的整数数组 nums 。 现定义函数 greaterCount ,使得 greaterCount(arr, val) 返回数组 arr 中 严格大于 val 的元素数量。 你需要使用 n 次操作,将 nums 的所有元素分配到两个数组 arr1 和 arr2 中。在第一次操…...

day35|1005.K次取反后最大化的数组和 134. 加油站135. 分发糖果
文章目录 python语法记录 sort格式 1005.K次取反后最大化的数组和思路方法一方法二 按照绝对值排序 教程🎈✨ 背住 按照绝对值进行降序排序的语法是: 134. 加油站思路方法一 教程解法方法二 暴力求解 135. 分发糖果思路方法一 总结 python语法记录 sort …...

HWA和BSS区别
芯片中的HWA(Hardware Accelerator)模块功能主要是为了加速雷达信号处理的特定任务。HWA模块在雷达系统中起到关键作用,以下是其主要功能和作用: 信号预处理: 滤波:对接收到的雷达信号进行滤波,…...
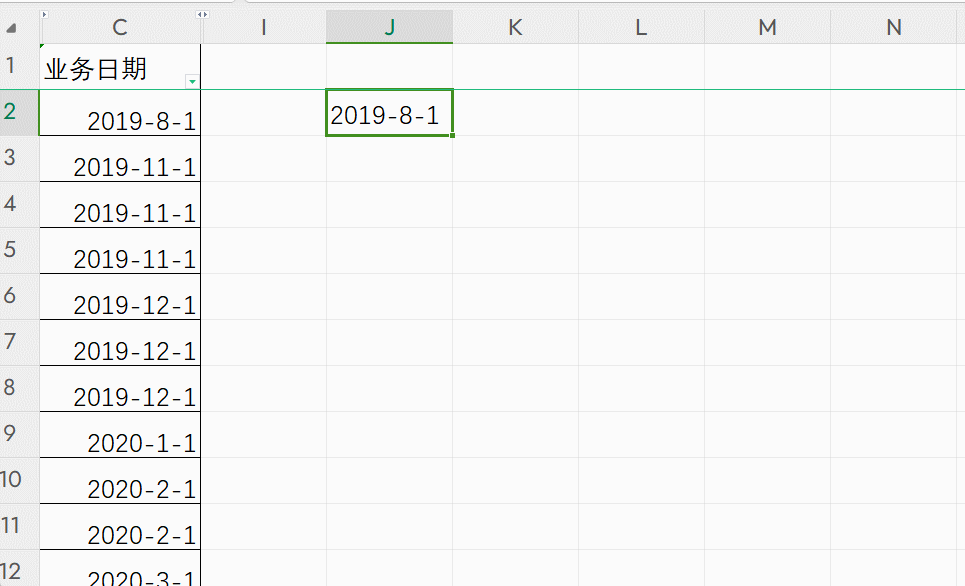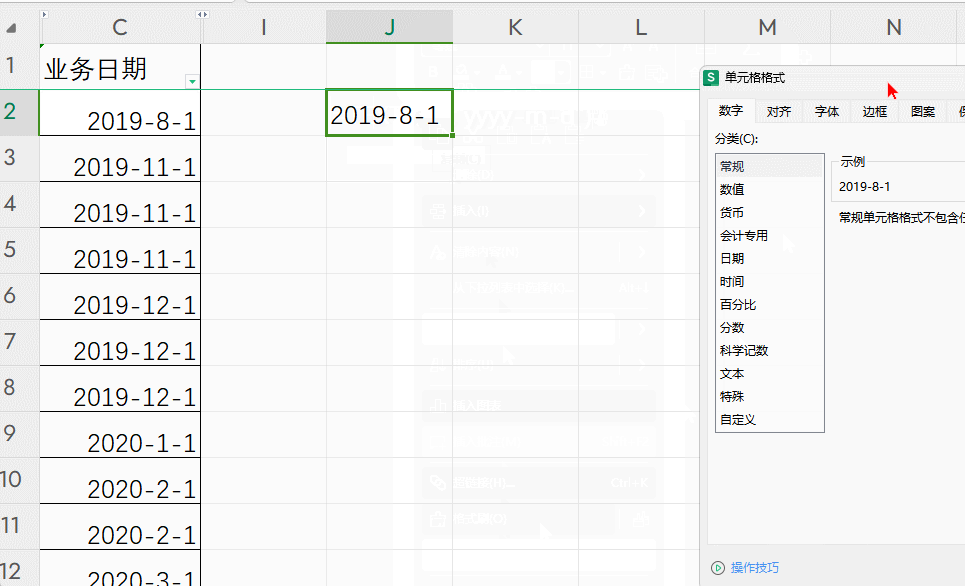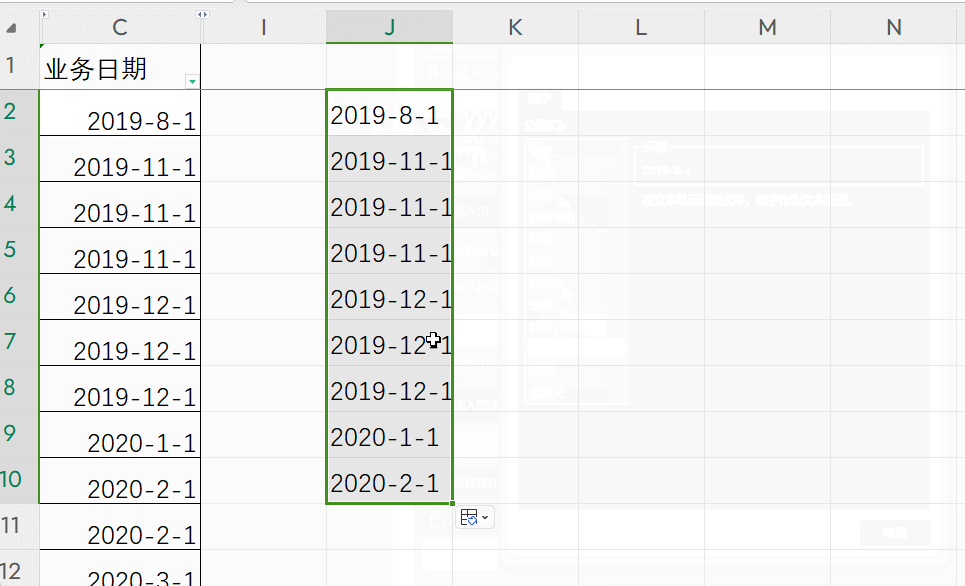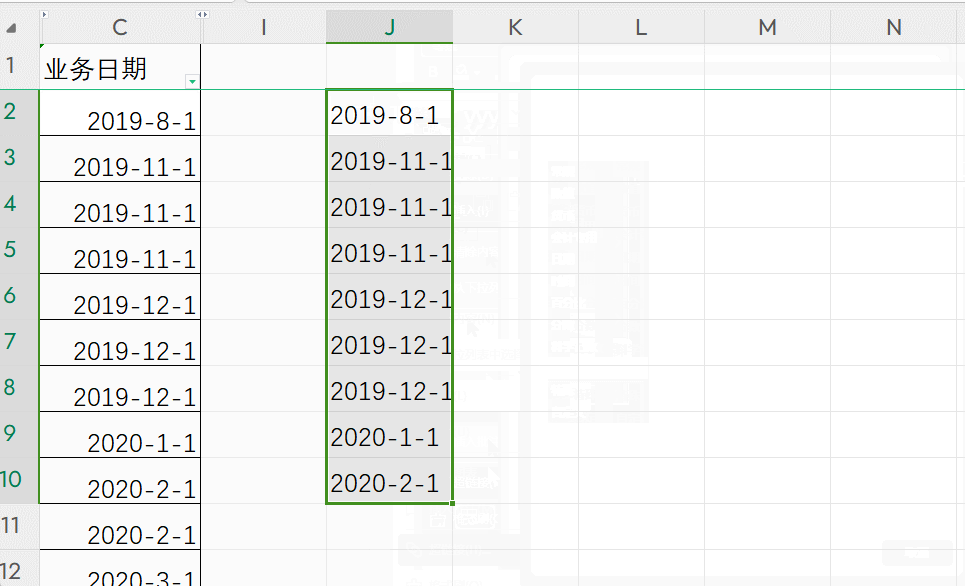
【Excel】Excel中将日期格式转换为文本格式,并按日期显示。
【问题需求】 在使用excel进行数据导入的过程中, 有的软件要求日期列必须是文本格式。 但是直接将日期列的格式改为文本后,显示一串数字,而不按日期显示。 进而无法导入使用。 【解决方法】 使用【TXET】函数公式进行处理, 在单…...

物联网学习小记
https://www.cnblogs.com/senior-engineer/p/10045658.html GOSP: 提供类似Qt的API接口,仅需要几百KB的硬件资源(比Qt小的多),能运行在Qt不支持的低配置硬件上(对Qt生态形成补充),适用于嵌入式…...
代码随想录-Day29
491. 非递减子序列 给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。 数组中可能含有重复元素,如出现两个整数相等,也可以视作递增序列的一种特殊情…...
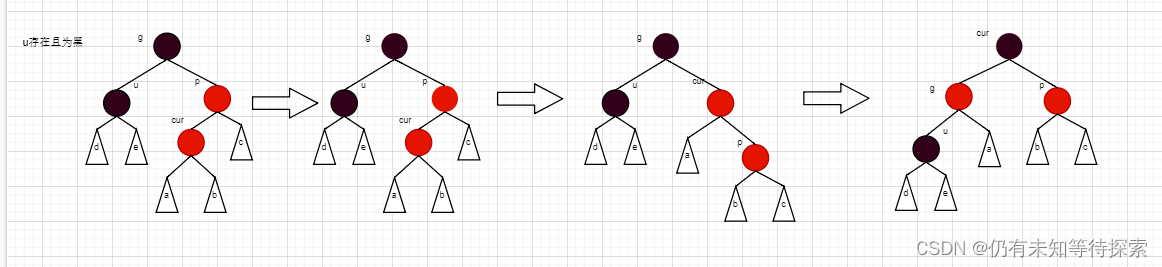
C/C++ 进阶(6)红黑树
个人主页:仍有未知等待探索-CSDN博客 专题分栏:C 目录 一、概念 性质 二、操作 插入 情况一:cur为红、p为红、g为黑,如果u存在且为红 步骤: 情况二:cur为红、p为红、g为黑,如果u不存在或…...

【Vue】构建vuex-cart模块
说明:既然明确数据要存 vuex,建议分模块存,购物车数据存 cart 模块,将来还会有 user 模块,article 模块… 新建 store/modules/cart.js 挂载到 vuex 仓库上 store/cart.js import Vue from vue import Vuex from vu…...

如何成为嵌入式系统工程师?
各位朋友,如果你们有意向投身于嵌入式开发领域,那么强烈建议你们在软件和硬件两个方面均展开深入且全面的学习。 嵌入式计算机作为嵌入式系统的核心技术支撑,其是直接面向用户、产品以及应用的,无论是软件还是硬件方面都能发挥重要…...

【AI大模型】Transformers大模型库(七):单机多卡推理之device_map
目录 一、引言 二、单机多卡推理之device_map 2.1 概述 2.2 自动配置,如device_map"auto" 2.3 手动配置,如device_map"cuda:1" 三、总结 一、引言 这里的Transformers指的是huggingface开发的大模型库&#x…...

开源技能管理工具rei-skills:从零构建个人技术能力图谱
1. 项目概述与核心价值 最近在折腾个人知识库和技能树管理,发现了一个挺有意思的开源项目 rootcastleco/rei-skills 。这项目名字乍一看有点神秘, rei 在日语里是“零”或“灵”的意思,结合 skills ,我理解它想表达的是一种…...

安全生产隐患识别太难?实测实在Agent:AI模型语义分析能力测评详解与信创落地指南
摘要: 步入2026年,安全生产已进入“全量数字化”与“法制化”深度融合的高压期。随着《安全生产法》的持续深化执行,企业面临着海量隐患识别、跨系统数据流转及信创环境适配的三重挑战。传统的人工排查与基于API的自动化手段,在面…...
ChatGPT 2026不是升级,是重构:Transformer-XL²架构、128K动态上下文、本地化模型热插拔——你还在用2023版?这5个信号说明你已被淘汰
更多请点击: https://intelliparadigm.com 第一章:ChatGPT 2026:一场从架构内核出发的范式革命 ChatGPT 2026 并非简单的能力叠加,而是以「动态稀疏混合专家(Dynamic Sparse MoE)」为核心重构推理路径&…...

PCL2启动器游戏启动失败的终极解决方案:3步快速修复指南
PCL2启动器游戏启动失败的终极解决方案:3步快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL Plain Craft Launcher 2(PCL2)…...

反PUA30天 Day15:“你格局小“——当这句话出现时,通常意味着对方已经没有别的论据了 |乐想屋
“本文来自「乐想屋」公众号,系列更新[职场反PUA30天觉醒计][职场生存暗规则],每天一篇清醒认知,拒绝内耗,少踩坑,快速成长。”绩效沟通那天,leader跟我说了一句话:「你不要老盯着自己那一亩三分…...

基于AI与贝叶斯学习的开源LinkedIn自动化销售探索代理部署指南
1. 项目概述:一个能自己找客户的AI销售代理如果你在B2B销售、市场拓展或者创业,你一定对LinkedIn又爱又恨。爱的是,它几乎是全球最精准的B2B客户数据库;恨的是,手动寻找、筛选、联系潜在客户,是一个极其耗时…...

WinMerge过滤器进阶:从基础规则到实战场景配置
1. WinMerge过滤器入门:从零开始理解规则配置 WinMerge作为一款老牌开源文件对比工具,其过滤器功能常常被低估。很多开发者只是用它来排除版本控制目录,但实际上它能做的远不止这些。我第一次接触WinMerge过滤器是在处理一个Java项目时&#…...

观察Taotoken在多模型并发调用时的延迟表现与稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型并发调用时的延迟表现与稳定性 在构建复杂的AI应用时,开发者常常需要同时或交替调用多个不同的大…...

Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南
Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...

《心核驱动:基于本质定义的AI性格自进化架构》
前言:拒绝表面调参,直击AI性格本质当前市面上的AI性格定制,大多停留在“表层调参”阶段——试图通过调整温度、Top-p等概率参数来模拟情感,结果往往顾此失彼,要么机械生硬,要么逻辑崩塌。真正的智能性格&am…...