大模型学习之GLM结构

探索GLM:一种新型的通用语言模型预训练方法
随着人工智能技术的不断进步,自然语言处理(NLP)领域也迎来了革命性的发展。OpenAI的ChatGPT及其后续产品在全球范围内引起了广泛关注,展示了大型语言模型(LLM)的强大能力。在这一背景下,GLM(General Language Model)作为一种创新的预训练语言模型,以其独特的自编码和自回归结合的训练方法,为NLP领域带来了新的视角。
GLM的核心特点
GLM模型结合了自编码和自回归两种预训练方法的优点,通过随机MASK输入中连续跨度的token,并使用自回归空白填充的方法重新构建这些跨度中的内容。此外,GLM还采用了二维编码技术,以更好地表示跨间和跨内的信息。这种独特的结合使得GLM在处理多种NLP任务时都能展现出优异的性能。
预训练目标:自回归空白填充
GLM的预训练目标是通过自回归空白填充来优化的。具体来说,给定一个输入文本,模型会从中采样多个文本片段,并将这些片段用[MASK]符号替换,形成一个损坏的文本。模型随后以自回归的方式,从损坏的文本中预测缺失的词。为了捕捉不同片段之间的相互依赖关系,GLM会随机打乱片段的顺序,类似于排列语言模型。
架构与实现
GLM的架构设计巧妙地结合了双向编码器和单向解码器。在模型的输入部分,文本被分为两部分:Part A是损坏的文本,Part B是被遮盖的片段。Part A的词可以相互看到,但不能看到Part B中的任何词;而Part B的词可以看到Part A和Part B中的前置词,但不能看到Part B中的后续词。这种设计使得模型能够在统一的框架内同时学习双向和单向的注意力机制。
GLM预训练方法分析
输入文本处理
- 输入文本:给定一个输入文本 x = [ x 1 , . . . , x n ] \bm{x} = [x_1, ..., x_n] x=[x1,...,xn],模型从中采样多个文本片段 { s 1 , . . . , s m } \{ \bm{s}_1, ..., \bm{s}_m \} {s1,...,sm}。
- 文本片段:每个片段 s i \bm{s}_i si 对应于输入文本中的一系列连续的词 [ s i , 1 , . . . , s i , l i ] [s_{i,1}, ..., s_{i,l_i}] [si,1,...,si,li]。
损坏文本的生成
- [MASK]替换:每个采样的文本片段 s i \bm{s}_i si 被一个单独的 [MASK] 符号替换,形成一个损坏的文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt。

自回归预测
- 预测方式:模型以自回归的方式从损坏的文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt 中预测缺失的词。这意味着在预测一个片段中的缺失词时,模型可以访问损坏的文本和之前已经预测的片段。
片段顺序的随机打乱
- 打乱顺序:为了充分捕捉不同片段之间的相互依赖关系,模型随机打乱片段的顺序,类似于排列语言模型。
- 排列集合:令 Z m Z_m Zm 为长度为 m m m 的索引序列 [ 1 , 2 , . . . , m ] [1, 2, ..., m] [1,2,...,m] 的所有可能排列的集合。
- 片段表示:令 s z < i ∈ [ s z 1 , . . . , s z i − 1 ] \bm{s}_{z<i} \in [\bm{s}_{z_1}, ..., \bm{s}_{z_{i-1}}] sz<i∈[sz1,...,szi−1],表示在排列 z z z 中,索引小于 i i i 的片段。
GLM的预训练方法
通过自回归空白填充目标进行优化,这是一种结合了自编码和自回归特性的创新方法。下面是对这一过程的详细分析:
-
输入文本处理:
- 给定一个输入文本 x = [ x 1 , . . . , x n ] \bm{x} = [x_1, ..., x_n] x=[x1,...,xn],模型从中采样多个文本片段 { s 1 , . . . , s m } \{ \bm{s}_1, ..., \bm{s}_m \} {s1,...,sm}。
- 每个片段 (\bm{s}_i) 对应于输入文本中的一系列连续的词 [ s i , 1 , . . . , s i , l i ] [s_{i,1}, ..., s_{i,l_i}] [si,1,...,si,li]。
-
损坏文本的生成:
- 每个采样的文本片段 s i \bm{s}_i si被一个单独的 [MASK] 符号替换,形成一个损坏的文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt。
-
自回归预测:
- 模型以自回归的方式从损坏的文本 (\bm{x}_{\text{corrupt}}) 中预测缺失的词。这意味着在预测一个片段中的缺失词时,模型可以访问损坏的文本和之前已经预测的片段。
-
片段顺序的随机打乱:
- 为了充分捕捉不同片段之间的相互依赖关系,模型随机打乱片段的顺序,类似于排列语言模型。
$$ - 令 (Z_m) 为长度为 (m) 的索引序列 ([1, 2, …, m]) 的所有可能排列的集合。
- 令 s z < i ∈ [ s z 1 , . . . , s z i − 1 ] \bm{s}_{z<i} \in [\bm{s}_{z_1}, ..., \bm{s}_{z_{i-1}}] sz<i∈[sz1,...,szi−1],表示在排列 (z) 中,索引小于 (i) 的片段。
- 为了充分捕捉不同片段之间的相互依赖关系,模型随机打乱片段的顺序,类似于排列语言模型。
-
预训练目标函数:
- 预训练目标函数可以表示为最大化期望,即最大化模型在所有可能的片段排列下预测缺失词的对数概率之和。
- 数学表达式为:
max θ E z ∼ Z m [ ∑ i = 1 m log p θ ( s z i ∣ x corrupt , s z < i ) ] \underset{\theta}{\text{max}} \space \mathbb{E}_{z\sim Z_m} \left[ \sum_{i=1}^{m} \text{log} \space p_{\theta} \left( \bm{s}_{z_i} | \bm{x}_{\text{corrupt}}, \bm{s}_{z_{<i}} \right) \right] θmax Ez∼Zm[i=1∑mlog pθ(szi∣xcorrupt,sz<i)] - 这里, p θ ( s z i ∣ x corrupt , s z < i ) p_{\theta} \left( \bm{s}_{z_i} | \bm{x}_{\text{corrupt}}, \bm{s}_{z_{<i}} \right) pθ(szi∣xcorrupt,sz<i) 表示在给定损坏的文本和之前预测的片段条件下,模型预测当前片段 s z i \bm{s}_{z_i} szi 的概率。
按照从左到右的顺序生成每个空白中的词,即生成片段 s i \bm{s}_i si 的概率可以分解为:
p θ ( s i ∣ x corrupt , s z < i ) = ∏ j = 1 l i p ( s i , j ∣ x corrupt , s z < i , s i , < j ) (2) p_{\theta}\left( \bm{s}_i|\bm{x}_{\text{corrupt}},\bm{s}_{z_{<i}} \right) = \prod_{j=1}^{l_i}p\left( s_{i,j}|\bm{x}_{\text{corrupt}},\bm{s}_{z_{<i}},\bm{s}_{i,<j} \right) \tag{2} pθ(si∣xcorrupt,sz<i)=j=1∏lip(si,j∣xcorrupt,sz<i,si,<j)(2)
使用以下方式实现了自回归空白填充目标。
输入 x \bm{x} x 被分成两部分:Part A 是损坏的文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt,Part B 是被遮盖的片段。Part A 的词可以相互看到,但不能看到 Part B 中的任何词。Part B 的词可以看到 Part A 和 Part B 中的前置词,但不能看到 Part B 中的后续词。为了实现自回归生成,每个片段都用特殊的符号 [START] 和 [END] 进行填充,分别用于输入和输出。这样,模型就自动地在一个统一的模型中学习了一个双向编码器(用于 Part A)和一个单向解码器(用于 Part B)。
在GLM模型中,原始文本 x = [ x 1 , x 2 , x 3 , x 4 , x 5 , x 6 ] \bm{x} = [x_1, x_2, x_3, x_4, x_5, x_6] x=[x1,x2,x3,x4,x5,x6] 被随机地进行连续的掩码处理。假设我们掩码掉了 [ x 3 ] [x_3] [x3] 和 [ x 5 , x 6 ] [x_5, x_6] [x5,x6],这些跨度的长度遵循泊松分布(参数 λ = 3 \lambda = 3 λ=3),这一策略与BART模型相似。

具体操作是将 [ x 3 ] [x_3] [x3] 和 [ x 5 , x 6 ] [x_5, x_6] [x5,x6] 替换为特殊的 [M] 标志,代表 [MASK]。接着,我们将这些被掩码的片段(Part B)的顺序打乱,以捕捉跨度之间的内在联系。这种随机交换跨度顺序的做法有助于模型学习到更丰富的上下文信息。
GLM模型采用自回归的方式来生成Part B的内容。在输入时,每个片段前面会加上 [S] 标志,代表 [START],而在输出时,每个片段后面会加上 [E] 标志,代表 [END]。这种做法有助于模型明确每个片段的开始和结束。
为了更好地表示不同片段之间以及片段内部的位置关系,GLM引入了二维位置编码。这种编码方式使得模型能够更精确地理解文本的结构和语义。
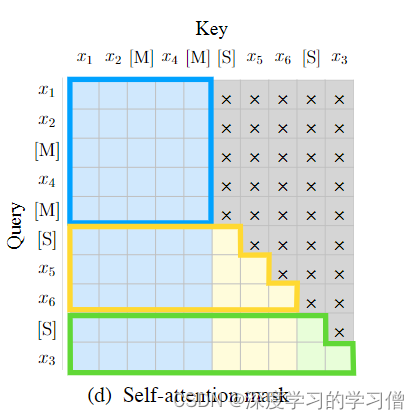
在自注意力机制中,使用了特定的掩码策略。灰色区域表示被掩盖的部分。Part A的词语可以相互看到(如图2(d)中的蓝色框所示),但不能看到Part B中的任何内容。相反,Part B的词语可以看到Part A和Part B中位于它们之前的词语(如图2(d)中的黄色和绿色框所示,分别对应两个不同的片段)。这种设计确保了模型在生成文本时能够考虑到正确的上下文信息。
通过这种方式,GLM模型不仅能够学习到文本中的上下文信息,还能够捕捉到不同文本片段之间的复杂依赖关系,从而在多种NLP任务中展现出优异的性能。这种结合了自编码和自回归特性的预训练方法,为语言模型的预训练提供了新的思路和方法。
GLM模型架构与微调方法分析
模型架构
GLM采用了一个单一的Transformer架构,并对其进行了一些关键的修改:
- 层归一化和残差连接的重新排列:这种调整对于避免大规模语言模型中的数值错误至关重要。
- 单一的线性层用于输出词预测:简化了输出层,提高了模型的预测效率。
- GeLU激活函数替换ReLU:GeLU(Gaussian Error Linear Unit)激活函数在许多现代神经网络模型中表现更好。
二维位置编码
GLM引入了二维位置编码,以更好地处理自回归空白填充任务中的位置信息。每个词使用两个位置ID进行编码:
- 第一个位置ID表示词在损坏文本 x corrupt \bm{x}_{\text{corrupt}} xcorrupt 中的位置。
- 第二个位置ID表示区域内的位置,Part A的词此ID为0,Part B的词此ID从1到区域长度。
这种编码方法确保模型在重建被遮盖的跨度时不知道其长度,与其他模型如XLNet和SpanBERT相比,这是一个显著的区别。
微调GLM
NLU分类任务
GLM将自然语言理解(NLU)分类任务重新制定为填空生成任务,遵循PET(Pattern Exploiting Training)方法。例如,情感分类任务可以被表述为“{SENTENCE}。这真的是 [MASK]”。标签如“positive”和“negative”分别映射到单词“good”和“bad”。
文本生成任务
对于文本生成任务,GLM可以直接应用预训练模型进行无条件生成,或者在条件生成任务上进行微调。给定的上下文构成了输入的Part A,末尾附加了一个mask符号,模型自回归地生成Part B的文本。
通过这些创新的方法和架构调整,GLM在处理各种自然语言处理任务时展现出了卓越的性能和灵活性。
应用与展望
GLM模型的出现,不仅为NLP领域提供了新的研究方向,也为实际应用带来了新的可能性。无论是在文本分类、翻译、问答还是文本生成等任务中,GLM都展现出了其独特的优势。随着模型的进一步优化和应用场景的拓展,GLM有望在未来的AI领域中扮演更加重要的角色。
总之,GLM作为一种结合了自编码和自回归优点的预训练语言模型,为NLP领域带来了新的活力。通过其独特的预训练方法和架构设计,GLM在多个NLP任务中都展现出了卓越的性能,预示着其在未来的广阔应用前景。
相关文章:
大模型学习之GLM结构
探索GLM:一种新型的通用语言模型预训练方法 随着人工智能技术的不断进步,自然语言处理(NLP)领域也迎来了革命性的发展。OpenAI的ChatGPT及其后续产品在全球范围内引起了广泛关注,展示了大型语言模型(LLM&a…...

C#类库打包支持多个版本的类库
修改csproj <Project Sdk"Microsoft.NET.Sdk"><PropertyGroup><TargetFrameworks>netcoreapp3.1;net5.0;net6.0;net7.0;net8.0</TargetFrameworks><PackageId>xxxx</PackageId><Version>1.0.0</Version><Author…...

一文介绍暗区突围手游 游戏特色、具体玩法和独特的玩法体验
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 《暗区突围》是一款由腾讯魔方工作室群开发的第一人称射击游戏,于 2022 年 7 月 13 日正式公测,支持 Android 和 iOS 平台。这款游戏以从虚构的暗区收集物资并安全撤离作为最终目…...

Unity基础(三)3D场景搭建
目录 简介: 一.下载新手资源 二.创建基本地形 三.添加场景细节 四,添加水 五,其他 六. 总结 简介: 在 Unity 中进行 3D 场景搭建是创建富有立体感和真实感的虚拟环境的关键步骤。 首先,需要导入各种 3D 模型资源,如建筑物、角色、道具等。这些模…...

在Spring Boot中使用Sa-Token实现路径拦截和特定接口放行
在Spring Boot中使用Sa-Token实现路径拦截和特定接口放行 很喜欢的一段话:别想太多,好好生活,也许日子过着过着就会有答案,努力走着走着就会有温柔的着落。 春在路上,花在枝上,所有的美好都在路上ÿ…...

【面经总结】Java基础 - 注解
注解 什么是注解 一种特殊的注释 注解的作用 编译器可以使用注解来检测错误或抑制警告。处理注解信息以生成代码或配置文件等。可以在运行时检查某些注解并处理。 注解的缺点 侵入式编程,增加耦合度产生问题定位困难需要利用反射来获取属性,破坏代…...

Matlab笔记
quit/exit 退出Matlab pause(x) 停止x秒 标识符最多63位--namelengthmax who/whos显示变量信息 double--64bit(双精度) single--32bit(单精度) format long/short/compact 改变格式 2017后matlab默认double--single(pi)变…...

android 编译源码添加日志打印
最近闲来无事,把源码编译一下,然后把这个源码编译到pixel3手机上,并且简单修改一下源码的网络请求,添加一些日志打印,堆栈打印,记录一下防止忘记 首先需要下载源码 下载对应源码对应的驱动 https://develop…...
Vue19-key的原理
一、v-for中key的作用 给节点进行一个标识,类似于身份证号。 1-1、需求1: 点击按钮,在<li>的最前面添加一个老刘的信息 <body><div id"root"><h1>人员信息</h1><button click.once"add&qu…...

零一科技Yi-VL 6B视觉大模型环境搭建推理
引子 最近看新闻博客说零一科技的Yi-VL-Plus视觉大模型效果很不错,那就想着尝尝鲜。这是第四篇关于视觉大模型的博客。之前有写过一篇零一科技的chat大模型零一科技Yi-34B Chat大模型环境搭建&推理_python部署大模型yi-34b-chat-CSDN博客,感兴趣的童…...
Django面试题
1. 什么是wsgi? WSGI 是 “Web Server Gateway Interface” 的缩写,它是一种用于 Python Web 应用程序和 Web 服务器之间通信的标准接口。它定义了一组规则和约定,使 Web 服务器能够与任何符合 WSGI 规范的 Python Web 应用程序进行交互。 #…...

Perl语言入门学习
文心一言 Perl语言入门学习可以遵循以下步骤和要点: 1. 了解Perl语言 Perl是一种功能丰富的计算机程序语言,运行在超过100种计算机平台上。Perl最初是为文本处理而开发的,但现在用于各种任务,包括系统管理、Web开发、网络编程、…...
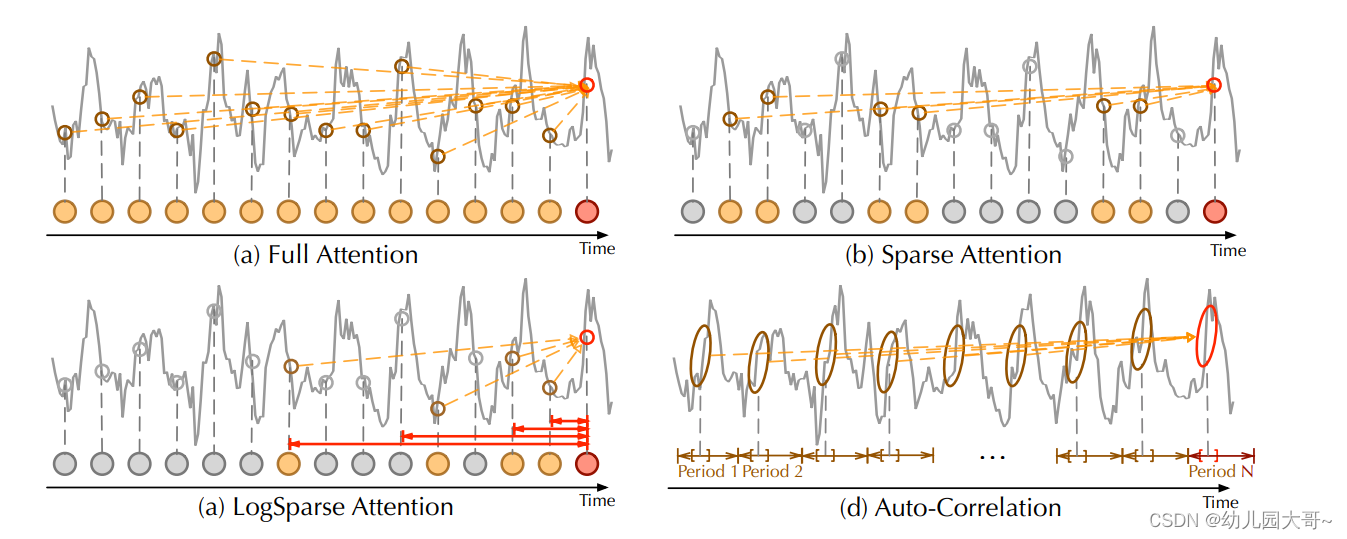
Autoformer
A u t o f o r m e r Autoformer Autoformer 摘要 我们设计了 A u t o f o r m e r Autoformer Autoformer作为一种新型分解架构,带有自相关机制。我们打破了序列分解的预处理惯例,并将其革新为深度模型的基本内部模块。这种设计使 A u t o f o r m…...
uniapp录音播放功能
ui效果如上。 播放就开始倒计时,并且改变播放icon,另外录音则停止上一次录音。 播放按钮(三角形)是播放功能,两竖是暂停播放功能。 const innerAudioContext wx.createInnerAudioContext();export default{data(){ret…...

✊构建浏览器工作原理知识体系(网络协议篇)
🌻 前言 书接上回~ 系列文章目录: # ✊构建浏览器工作原理知识体系(开篇)# ✊构建浏览器工作原理知识体系(浏览器内核篇)# ✊构建浏览器工作原理知识体系(网络协议篇)✊构建浏览器工作原理知识体系(网页加载超详细全过程篇)为什么你觉得偶尔看浏览器的工作原理,…...

【AI大模型】Transformers大模型库(八):大模型微调之LoraConfig
目录 一、引言 二、LoraConfig配置参数 2.1 概述 2.2 LoraConfig参数说明 2.3 代码示例 三、总结 一、引言 这里的Transformers指的是huggingface开发的大模型库,为huggingface上数以万计的预训练大模型提供预测、训练等服务。 🤗 Transformers …...
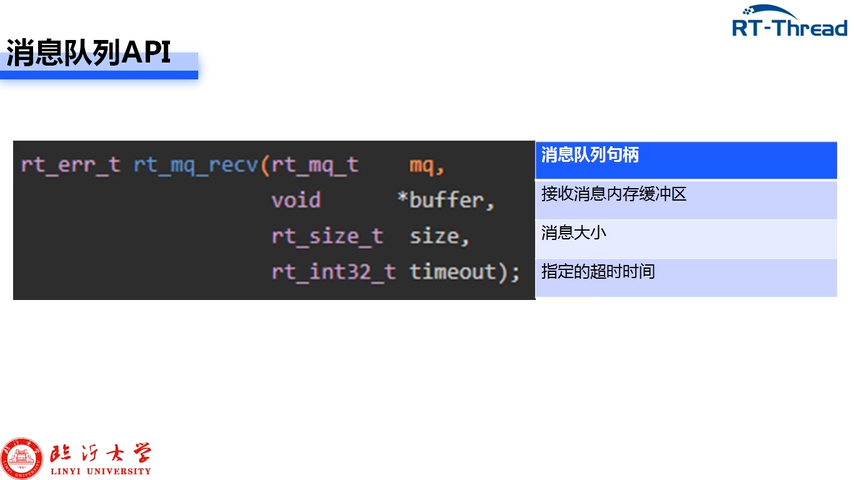
8-1RT-Thread消息队列
8-1RT-Thread消息队列 消息队列又称队列,是一种常用于线程间通信的数据结构。 消息队列控制块里有两个链表,空闲列表用来挂接空的小几块,另一个链表是用来挂接存有消息的消息框。其中消息链表头指向消息队列当中的第一个消息框,而…...
解除网站IP抓取限制的方法有哪些?
在爬取网站数据时,经常会遇到IP被限制,导致返回的数据无法显示或者直接空白的情况。这时候就需要采取一些方法来解除网站对IP的爬取限制。IP代理是帮助用户绕过网站限制,保持稳定连接,实现数据顺畅爬取的重要解决方案。 1、IP代理…...

“手撕”二叉树的OJ习题
故事的开头,我们先来三道不是oj的开胃菜,练练手感,后面9道都是OJ题。 目录 第一题 第二题 第三题 第四题 第五题 第六题 第七题 第八题 第九题 第十题 第十一题 第一题 二叉树前序非递归遍历实现 。 首先我们需要一个栈来存放二…...

Linux Mint 21.3简介
Linux Mint 21.3是一个更新版本,其中包含了许多新特性和改进。以下是一些主要更新内容: 1. Cinnamon 6.0桌面环境:Linux Mint 21.3采用了最新的Cinnamon 6.0桌面环境,带来了新的功能和改进,例如支持Wayland会话&#…...

Intel Quark SoC X1000:物联网边缘计算的核心技术解析
1. Intel Quark SoC X1000:物联网边缘计算的小型化革命在工业自动化现场,一台装备了温度传感器的风机正在持续监测轴承状态。传统方案需要将每秒数百个采样点全部上传云端,不仅占用带宽,延迟更是达到秒级。而采用Intel Quark SoC …...

ZYNQ UltraScale+ MPSoC实战:基于PL端AXI_UART16550 IP核与PS端中断机制,实现RS485多帧长数据可靠接收
1. 工业通信场景下的ZYNQ UltraScale MPSoC实战 在工业自动化领域,RS485总线因其抗干扰能力强、传输距离远等优势,成为设备间通信的主流选择。而ZYNQ UltraScale MPSoC凭借其独特的PSPL架构,能够完美应对工业通信中对实时性和可靠性的严苛要求…...

scp 命令的使用方法 什么软件支持 .git bash xshell .openssh
scp 命令的使用方法 什么软件支持 .git bash xshell .openssh scp backup.sh deploy.sh rollback.sh userserver:/path/to/project/ 这个命令主要在 Linux、macOS 或 Windows (10/11) 的 命令行终端(Terminal / Command Prompt / PowerShellÿ…...

全网珍藏网安学习网站大全,一次性整理齐全,错过容易被删速收藏!
我们学习网络安全,很多学习路线都有提到多逛论坛,阅读他人的技术分析帖,学习其挖洞思路和技巧。但是往往对于初学者来说,不知道去哪里寻找技术分析帖,也不知道网络安全有哪些相关论坛或网站,所以在这里给大…...

Python调用Claude API实战:非官方库集成与自动化应用指南
1. 项目概述与核心价值 最近在尝试构建一些智能化的个人工作流时,我遇到了一个痛点:如何将 Anthropic 公司强大的 Claude 模型,像使用 OpenAI 的 GPT 模型那样,方便地集成到自己的脚本、应用或者自动化工具里。OpenAI 的 API 封装…...

为AI智能体构建自动化RSS信息管道:agent-rss工具详解与实践
1. 项目概述:为AI智能体打造的RSS信息管道 如果你正在构建或使用AI智能体(比如Claude Code、OpenClaw这类工具),并且希望它们能像人类一样,定时、定向地获取互联网上的最新信息,那么你很可能需要一个专门为…...

PyTorch自动微分知识点讲解
PyTorch自动微分知识点讲解 知识导图 PyTorch自动微分 ├── 基础认知 │ ├── 自动微分的核心概念 │ └── autograd模块的作用 ├── 梯度计算 │ ├── 梯度计算的规则 │ └── backward与grad的使用 └── 实战案例├── 单参数的更新└── 多参数的更…...

告别手动传包!用Pypiserver在内网搭建Python私有源,团队协作效率翻倍
告别手动传包!用Pypiserver在内网搭建Python私有源,团队协作效率翻倍 在团队开发中,Python依赖管理常常成为效率瓶颈。想象这样的场景:新同事加入项目,需要配置开发环境,却因为内网限制无法直接访问PyPI&a…...

ClawSuite:模块化网络安全工具集在渗透测试中的实战应用
1. 项目概述:ClawSuite,一个被低估的网络安全工具集如果你在网络安全领域摸爬滚打了一段时间,尤其是在渗透测试或者红队评估的圈子里,你大概率听说过或者用过像 Metasploit、Nmap、Burp Suite 这些耳熟能详的“瑞士军刀”。但今天…...

MobaXterm 全能终端神器:实战指南
写在前面:作为Windows下最全能的远程终端工具,MobaXterm 在 2026 年已迭代至 v26.0 版本。本文基于最新版,从工具选型对比、核心功能实战到效率提升技巧,带你真正掌握这款"瑞士军刀"。文末附赠快捷键大全和安全配置清单…...