【星海随笔】云解决方案学习日志篇(一) ELK,kibana,Logstash安装
心路历程
本来想最近再研究研究DPDK的。但是自己做一个东西很多时候没有回报。因为自己的低学历问题,类似工作的面试都没有。所以很多东西学了很快就忘了,没有地方可以用。
今天看到了一个大佬,除了发型外,很多想法还是很共鸣的。
Shay Banon
决定开始跟着大佬的文章研究一段时间。这样梯度的学习中,自己就算没有一线的经验也可以学到很多一线的东西。
大佬是Elastic的创始人,决定先从ELK开始研究。
例如Elastic与Amazon, Elastic 和 Grafana Labs ,Elasticsearch、Kibana 及 X-Pack 、Kafka等。。。
在这当中,Kafka的作用是明显的,作为一个中间件,一个缓冲,它起到了提高吞吐,隔离峰值影响,缓存日志数据,快速落盘,同时通过producer/consumer模式,让Logstash能够横向拓展的作用,还能够用作数据的多路分发。
大多数时候,我们看到的实际架构,按数据流转顺序排列,应该是BKLEK架构。
Filebeat+kfaka+ELK
Elastic 社区
参考文档
https://blog.csdn.net/weixin_44991162/article/details/90257265
前置 Kibana 安装
Elasticsearch和Kibana之间的关系是紧密的,它们共同构成了Elastic Stack,也被称为ELK Stack
Elasticsearch是一个开源的分布式搜索和分析引擎负责存储和搜索数据。
而Kibana是一个数据可视化工具
用于可视化和分析这些数据。
它们之间通过RESTful API 进行通信,使得集成非常简单。
Kibana提供了多种可视化工具,如线图、柱状图、饼图等,以及各种数据分析功能,如日志分析、监控、搜索等,可以帮助用户更好地理解和分析数据。
Kibana 通常与 Elasticsearch 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 提供图形化的 web 界面来浏览 Elasticsearch 日志数据,可以用来汇总、分析和搜索重要数据。
STEP1
首先要关闭Iptables 和 Selinux
Logstash 依赖于JAVA
Oracle 修复了 Java 超过一半的问题。所以我们到Oracle 官方网站上下载 java 的JDK
https://www.oracle.com/java/technologies/downloads/#java11
tar -zxf jdk-11.0.18_linux-x64_bin.tar.gz -C /usr/local/
配置环境变量
cat >> /etc/profile << "EOF"
export JAVA_HOME=/usr/local/jdk-11.0.18
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH
EOF
#加载环境变量
source /etc/profile
#验证版本
java -version
Kibana 安装
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.16.1-linux-x86_64.tar.gz
tar -zxf kibana-7.16.1-linux-x86_64.tar.gz -C /usr/local/
mv /usr/local/kibana-7.16.1-linux-x86_64 /usr/local/kibana-7.16.1
ls /usr/local/kibana-7.16.
环境变量配置:
cat >> /etc/profile << "EOF"
export PATH=$PATH:/usr/local/kibana-7.16.1/bin
EOF
source /etc/profile修改Kibana配置kibana.yml
vim /usr/local/kibana-7.16.1/config/kibana.yml
#简单使用,只修改下面两个选项即可
server.port: 5601
server.host: "0.0.0.0"
创建Kibana 用户、授予Kibana 权限,并启动服务
#添加kibana用户,禁止ssh登录
useradd -s /sbin/nologin kibana#授权
chown -R kibana:kibana /usr/local/kibana-7.16.1/#切换kibana 用户,验证版本
su - kibana -s /bin/bash
kibana --version#启动服务
nohup kibana >/tmp/kibana.log 2>&1 &
#查看端口是否监听
netstat -lntp |grep 5601
#服务没问题后退出当前用户
exit
Elasticsearch 安装
ElasticSearch是基于Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。
Elasticsearch 是用 Java 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与 Elasticsearch 通信。
Elasticsearch是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大容量的日志数据,也可用于搜索许多不同类型的文档。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.16.1-linux-x86_64.tar.gz
tar -zxf elasticsearch-7.16.1-linux-x86_64.tar.gz -C /usr/local/
ls /usr/local/elasticsearch-7.16.1/
cat >> /etc/profile << "EOF"
export PATH=$PATH:/usr/local/elasticsearch-7.16.1/bin
EOF
source /etc/profile
修改 Elasticsearch配置文件
vim /usr/local/elasticsearch-7.16.1/config/elasticsearch.yml
#只需修改添加下面几个选项即可
#可自定义数据存储路径(注意授权)
path.data: data
#可自定义日志存在路径(注意授权)
path.logs: logs
#监听的ip根据自己的情况修改,我的服务都部署在一台机器,所以监听127.0.0.1
network.host: 127.0.0.1
http.port: 9200
#开启密码认证
xpack.security.enabled: true
#集群模式,single-node 是单节点
discovery.type: single-node修改ES JVM的内存限制
vim /usr/local/elasticsearch-7.16.1/config/jvm.options
#建议调至当前可用内存的一半
-Xms2g
-Xmx2g
创建elastic 用户、授予elastic 权限,并启动服务
#添加elastic用户,禁止ssh登录
useradd -s /sbin/nologin elastic#授权
chown -R elastic:elastic /usr/local/elasticsearch-7.16.1/#切换 elastic 用户,验证版本
su - elastic -s /bin/bash
elasticsearch --version#启动服务
elasticsearch -d
#查看端口是否监听
netstat -lntp |grep 9200
#服务没问题后退出当前用户
exit
Elasticsearch 设置密码
/usr/local/elasticsearch-7.16.1/bin/elasticsearch-setup-passwords interactive
输入:y
输入自定义密码:1234567
验证密码
curl -u elastic:elk@2023 127.0.0.1:9200
修改 Kibana 配置,添加 es 密码认证
vim /usr/local/kibana-7.16.1/config/kibana.yml
elasticsearch.hosts: ["http://127.0.0.1:9200"]
elasticsearch.username: "elstic"
elasticsearch.password: "1234567"
重启 Kibana
su - kibana -s /bin/bash
#停止服务重新启动
ps -ef |grep -w kibana-7.16.1 |grep -v grep | awk '{print $2}' |xargs kill
nohup kibana >/tmp/kibana.log 2>&1 &
#查看端口是否监听
netstat -lntp |grep 5601
#观察日志有无错误输出
tailf /tmp/kibana.log
#服务没问题后退出当前用户
exit
访问 Kibana :5601
Logstash 安装
Logstash 由 Ruby 语言编写,运行在 Java 虚拟机(JVM)上,是一款强大的数据处理工具, 可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。
Filebeat是一个轻量级的日志收集器,主要用于从文件中读取日志行并将其传输到其他地方,如Elasticsearch或Logstash。它适合部署在收集的最前端,用于日志收集和传输。
Logstash是一个功能强大的数据处理管道,可以从多种来源接收数据,并进行复杂的转换和过滤,然后将数据发送到许多不同的目标。它适用于大规模的日志处理任务,提供了更多的过滤插件和处理选项,可以进行更复杂的数据转换和处理操作。
由于其轻量级的设计,Filebeat占用的系统资源较少,适用于在较小的环境中部署。
而Logstash由于其更强大的功能和灵活性,需要更多的系统资源来运行,适用于大规模的日志处理任务。
logstash 超大规模日志时,日志先存到kafka,再通过logstash同步到elasticsearch
对于日志规模不大时,不需要用到logstash。
由于Elasticsearch具有解析的能力(如Logstash过滤器)— Ingest,这意味着可以将数据直接用Filebeat推送到Elasticsearch,并让Elasticsearch既做解析的事情,又做存储的事情
下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.16.1-linux-x86_64.tar.gz
加压安装包
tar -zxf logstash-7.16.1-linux-x86_64.tar.gz -C /usr/local/
ll /usr/local/logstash-7.16.1/
设置环境变量
cat >> /etc/profile << "EOF"
export PATH=$PATH:/usr/local/logstash-7.16.1/bin
EOF
source /etc/profile
Logstash JVM的内存限制
vim /usr/local/logstash-7.16.1/config/jvm.options
#建议调至当前可用内存的一半
-Xms1g
-Xmx1g
查看版本
[root@VM-5-163-centos ~]# logstash --version
Using bundled JDK: /usr/local/logstash-7.16.1/jdk
logstash 7.16.1
Logstash 不强制使用普通用户启动,如需普通用户启动,可以参考前面创建用户步骤
测试采集 nginx 日志
创建 logstash config配置文件
cat > /usr/local/logstash-7.16.1/config/logstash.conf << "EOF"
input {file {path => "/usr/local/nginx/logs/access.log"}
}
filter {grok {match => {"message" => '(?<remote_ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) - - \[(?<timestamp>\S+ \+\d+)\] "(?<method>[A-Z]+) (?<request>\S+) HTTP/\d.\d" (?<status>\d+) (?<bytes>\d+) "[^"]+" "(?<agent>[^"]+)"'}remove_field => ["message","@version","path"]}date {match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]target => "@timestamp"}
}
output {elasticsearch {hosts => ["http://127.0.0.1:9200"]user => "elastic"password => "elk@2023"index => "logstash-%{+YYYY.MM.dd}"}
}
EOF
启动logstash
logstash -f /usr/local/logstash-7.16.1/config/logstash.conf
Kibana 查看ES 是否已经有Logstash 的 index
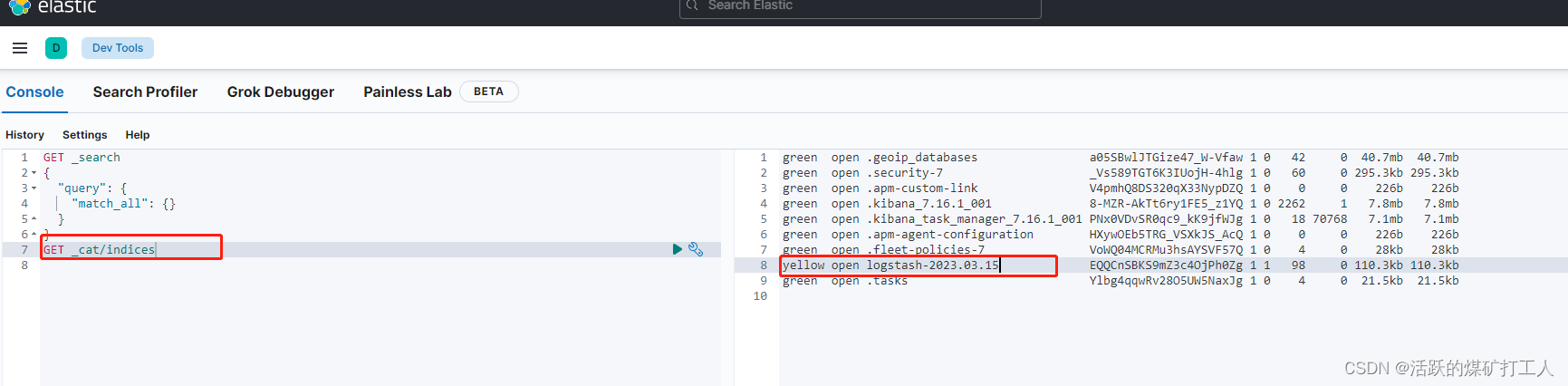
添加索引
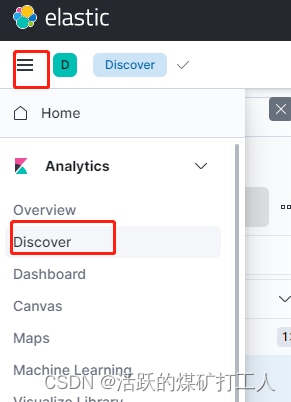
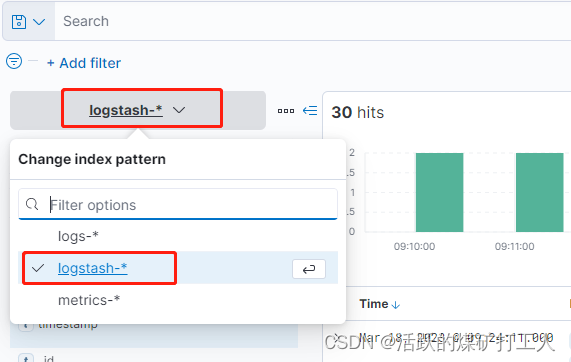
相关文章:
【星海随笔】云解决方案学习日志篇(一) ELK,kibana,Logstash安装
心路历程 本来想最近再研究研究DPDK的。但是自己做一个东西很多时候没有回报。因为自己的低学历问题,类似工作的面试都没有。所以很多东西学了很快就忘了,没有地方可以用。 今天看到了一个大佬,除了发型外,很多想法还是很共鸣的。 Shay Banon 决定开始跟…...

【leetcode】hot100 哈希表
1. 两数之和 1.1 题目 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。…...
每日5题Day22 - LeetCode 106 - 110
每一步向前都是向自己的梦想更近一步,坚持不懈,勇往直前! 第一题:106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode) class Solution {public TreeNode buildTree(int[] inorder, int[] postorder) {…...

【Python】读取文件夹中所有excel文件拼接成一个excel表格 的方法
我们平常会遇到下载了一些Excel文件放在一个文件夹下,而这些Excel文件的格式都一样,这时候需要批量这些文件合并成一个excel 文件里。 在Python中,我们可以使用pandas库来读取文件夹中的所有Excel文件,并将它们拼接成一个Excel表…...

7. 通配符和正则表达式
文章目录 7.1 通配符7.1.1 通配符介绍7.1.2 通配符示例 7.2 正则表达式7.2.1 grep命令7.2.2 基本正则表达式7.2.3 扩展正则表达式 7.1 通配符 在 Shell 中通配符用于查找文件名和目录名。它是由 Shell 处理的,只会出现在命令的参数中。 7.1.1 通配符介绍 * 匹…...
ROS2底层机制源码分析
init ->init_and_remove_ros_arguments ->init ->Context::init 保存初始化传入的信号 ->install_signal_handlers→SignalHandler::install 开线程响应信号 ->_remove_ros_arguments 移除ros参数 ->SingleNodeManager::instance().…...

超越 Transformer开启高效开放语言模型的新篇章
在人工智能快速发展的今天,对于高效且性能卓越的语言模型的追求,促使谷歌DeepMind团队开发出了RecurrentGemma这一突破性模型。这款新型模型在论文《RecurrentGemma:超越Transformers的高效开放语言模型》中得到了详细介绍,它通过…...
快速排序-Hoare 递归版 C语言
个人主页点这里~ 快速排序的简介: 快速排序是Hoare于1962年提出的一种 二叉树结构 的 交换 排序方法,其基本思想为:任取待排序元素序列中 的某元素作为 基准值 ,按照该排序码将待排序集合分割成 两子序列 , 左子序列中所有元素均 …...

C语言经典指针运算笔试题图文解析
指针运算常常出现在面试题中,画图解决是最好的办法。 题目1: #include <stdio.h> int main() {int a[5] { 1, 2, 3, 4, 5 };int* ptr (int*)(&a 1);printf("%d,%d", *(a 1), *(ptr - 1));return 0; } //程序的结果是什么&…...

使用 KubeKey v3.1.1 离线部署原生 Kubernetes v1.28.8 实战
今天,我将为大家实战演示,如何基于操作系统 openEuler 22.03 LTS SP3,利用 KubeKey 制作 Kubernetes 离线安装包,并实战离线部署 Kubernetes v1.28.8 集群。 实战服务器配置 (架构 1:1 复刻小规模生产环境,配置略有不…...

DOS 命令
Dos: Disk Operating System 磁盘操作系统, 简单说一下 windows 的目录结构。 ..\ 到上一级目录 常用的dos 命令: 查看当前目录是有什么内容 dir dir d:\abc2\test200切换到其他盘下:盘符号 cd : change directory 案例演示:切换…...

如何用Java程序实现一个简单的消息队列?
在Java程序中,可以使用内置的java.util.concurrent.BlockingQueue作为消息队列存放的容器,来实现一个简单的消息队列。 具体实现如下,在这个例子中,我们创建了一个生产者线程和一个消费者线程,他们共享同一个阻塞队列…...

OpenAI 宕机事件:GPT 停摆的影响与应对
引言 2024年6月4日,OpenAI 的 GPT 模型发生了一次全球性的宕机,持续时间长达8小时。此次宕机不仅影响了OpenAI自家的服务,还导致大量用户涌向竞争对手平台,如Claude和Gemini,结果也导致这些平台出现故障。这次事件的广…...

linux常用的基础命令
ls - 列出目录内容。 cd - 更改目录。 pwd - 打印当前工作目录。 mkdir - 创建新目录。 rmdir - 删除空目录。 touch - 创建新文件或更新现有文件的时间戳。 cp - 复制文件或目录。 mv - 移动或重命名文件或目录。 rm - 删除文件或目录。 cat - 显示文件内容。 more - 分页显示…...

618家用智能投影仪推荐:这个高性价比品牌不容错过
随着科技的不断进步,家庭影院的概念已经从传统的大屏幕电视逐渐转向了更为灵活和便携的家用智能投影仪。随着618电商大促的到来,想要购买投影仪的用户们也开始摩拳擦掌了。本文将从投影仪的基础知识入手,为您推荐几款性价比很高的投影仪&…...

自愿离婚协议书
自愿离婚协议书 男方(夫): 女方(妻): 双方现因 原因,导致夫妻情感已破裂,自愿离婚…...

WPS JSA 宏脚本入门和样例
1入门 WPS window版本才支持JSA宏的功能。 可以自动化的操作文档中的一些内容。 参考文档: WPS API 参考文档:https://open.wps.cn/previous/docs/client/wpsLoad 微软的Word API文档:Microsoft.Office.Interop.Word 命名空间 | Microsoft …...
Printing and Exporting
打印 大多数DevExpress。NET控件(XtraGrid、XtraPivotGrid、XttraTreeList、XtraScheduler、XtraCharts)提供打印和导出功能。 所有可打印的DevExpress.NET控件是使用XtraPrinting库提供的方法打印的。 若要确定预览和打印选项是否可用,请检…...
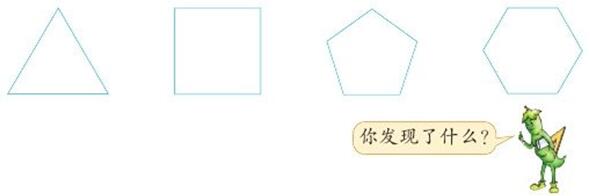
c++【入门】正多边形每个内角的度数
限制 时间限制 : 1 秒 内存限制 : 128 MB 题目 根据多边形内角和定理,正多边形内角和等于:(n - 2)180(n大于等于3且n为整数)(如下图所示是三角形、四边形、五边形、六边形的形状)…...

spring boot3登录开发-邮箱登录/注册接口实现
⛰️个人主页: 蒾酒 🔥系列专栏:《spring boot实战》 🌊山高路远,行路漫漫,终有归途 目录 写在前面 上文衔接 内容简介 功能分析 所需依赖 邮箱验证登录/注册实现 1.创建交互对象 2.登录注册业务逻辑实…...

MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案
MTKClient实战指南:联发科设备刷机与逆向工程全面解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科芯片设备设计的开源逆向工程与刷机工具&am…...

3PEAK思瑞浦 TPA3532-SO1R SOP8 运算放大器
特性 超低输入偏置电流:-在TA25C时最大土1pA(实验室测试限值)-在-40C至125C(实验室测试限值)下,最大土30皮安 低输入失调电压:250V(最大值)集成保护缓冲器,最大偏移电压200V低电压噪声密度:18nV/Hz(在1kHz时). 宽带宽:2.1MHz 供电电压:4.5V至16V(2.25V至…...

下行周期生存之道 = 低风险试错 × 即时反馈 × 长期复购
总结公式: 下行周期赚钱 低风险试错 即时反馈 长期复购 日本用30年验证了这套逻辑。 普通人现在能不能赚到钱,不在于胆子够不够大,而在于你能不能在大家焦虑的时候,给他一点确定感。 先收藏,慢慢找自己的切入口。...

淘宝商品详情 API 实现标题 / SKU / 主图批量采集
item_get_pro-获得淘宝商品详情高级版请求示例-- 请求示例 url 默认请求参数已经URL编码处理 curl -i "https://api-服务器.cn/taobao/item_get_pro/?key<您自己的apiKey>&secret<您自己的apiSecret>&num_iid678121631641"响应示例"num_ii…...
)
STM32实战:用HAL库搞定RS485 Modbus液压传感器数据采集(附自动收发电路避坑)
STM32实战:HAL库驱动RS485 Modbus液压传感器全流程解析 液压系统压力监测的稳定性往往取决于传感器数据采集的可靠性。在工业现场,RS485总线搭配Modbus RTU协议已成为液压传感器数据传输的黄金标准。本文将深入探讨基于STM32 HAL库的完整解决方案&#x…...

3分钟掌握Krita AI抠图:点一下就能完成的智能选区革命
3分钟掌握Krita AI抠图:点一下就能完成的智能选区革命 【免费下载链接】krita-vision-tools Krita plugin which adds selection tools to mask objects with a single click, or by drawing a bounding box. 项目地址: https://gitcode.com/gh_mirrors/kr/krita-…...

初次使用Taotoken平台从注册到完成API调用的全程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken平台从注册到完成API调用的全程指引 对于初次接触大模型API的开发者而言,从注册平台到成功发出第一个…...

Gemma 4大模型实战:从架构解析到生产部署与微调
1. 项目概述:为什么我们需要深入理解Gemma 4?如果你最近在关注开源大模型领域,一定绕不开“Gemma”这个名字。从年初Gemma 2B/7B的惊艳亮相,到如今关于下一代架构的种种猜测,Google的Gemma系列正以一种稳健而有力的姿态…...

使用Taotoken后如何清晰观测API用量与成本变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后如何清晰观测API用量与成本变化 对于团队管理者或开发者而言,将大模型能力集成到产品中后,资…...

高校vs中小学气象站:核心区别
绝大多数普通校园气象站仅适合中小学可视化科普展示,数据精度低、无原始数据导出、无开放接口、参数单一,完全无法满足高校教学科研需求。中小学设备:侧重外观展示、简单数据观看、趣味科普,精度普通、数据封闭、无科研溯源能力&a…...