GPU显卡计算能力怎么算?
GPU的算力指的是什么?
GPU的计算能力可以使用FLOPS表示,FLOPS是floating-point operations per second的缩写,表示“每秒所执行的浮点运算次数”。是被用来估算处理的计算能力
1 MFLOPS = 每秒可以执行一百万(10^6)次浮点运算
1 GFLOPS = 每秒可以执行十亿(10^9)次浮点运算
1 TFLOPS = 每秒可以执行一万亿(10^12)次浮点运算
1TOPS:代表的是每秒执行一万亿次运算次数
TFLOPS和 TOPS都是描述深度学习设备计算能力的单位
这2者的区别在于:FL即float浮点,大多数NPU(Neural Processing Unit)都是定点运算,通常是用 TOPS来标称算力。它们之间的转换通常可以用公式:1TFLOPS=2*1TOPS来计算,但是需要注意TFLOPS中有单精度FP32 和半精度FP16的区别,一般默认是FP16。
Nvidia GPU的流处理器单元是两个ALU单元,每个时钟周期进行两次浮点预算。。
FLOPS= 处理器个数 × 处理器主频 × 单个处理器一个时钟周期进行浮点运算次数
以最新的RTX4080为例:核心数量是:9728,最大主频为:2.51GHz。那么计算如下:
显卡FLOPS =9728 *2.51*2= 48834.56Gflops=49 TFLOPS
相关文章:

GPU显卡计算能力怎么算?
GPU的算力指的是什么? GPU的计算能力可以使用FLOPS表示,FLOPS是floating-point operations per second的缩写,表示“每秒所执行的浮点运算次数”。是被用来估算处理的计算能力 1 MFLOPS 每秒可以执行一百万(10^6)次浮点运算 1 GFLOPS 每秒可以执行十…...

Spark参数配置不合理的情况
1.1 内存设置 💾 常见的内存设置有两类:堆内和堆外 💡 我们作业中大量的设置 driver 和 executor 的堆外内存为 4g,造成资源浪费 📉。 通常 executor 堆外内存在 executor.cores1 的时候,1g 足够了&…...

【OpenGL学习】OpenGL不同版本渲染管线汇总
文章目录 一、《OpenGL编程指南》第6版/第7版的渲染管线二、《OpenGL编程指南》第8版/第9版的渲染管线 一、《OpenGL编程指南》第6版/第7版的渲染管线 图1. OpenGL 2.1、OpenGL 3.0、OpenGL 3.1 等支持的渲染管线 二、《OpenGL编程指南》第8版/第9版的渲染管线 图2. OpenGL …...

等保测评练习
等级保护初级测评师试题11 姓名: 成绩: 判断题(10110分) 1. windows使用"service -status-all | grep running"命令查看危险的网络服务是否已经关闭。( F ) …...

第十五届蓝桥杯大赛 国赛 pb组F题【括号与字母】(15分) 栈的应用
博客主页:誓则盟约系列专栏:IT竞赛 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 试题F:括号与字母 【问题描述】 给定一个仅包含小写字母和括号的字符串 S …...
)
MYSQL 三、mysql基础知识 4(存储过程与函数)
MySQL从5.0版本开始支持存储过程和函数。存储过程和函数能够将复杂的SQL逻辑封装在一起,应用程序无须关注存储过程和函数内部复杂的SQL逻辑,而只需要简单地调用存储过程和函数即可。 一、存储过程概述: 1.1理解: 含义&am…...

鸿蒙开发文件管理:【@ohos.statfs (statfs)】
statfs 该模块提供文件系统相关存储信息的功能,向应用程序提供获取文件系统总字节数、空闲字节数的JS接口。 说明: 本模块首批接口从API version 8开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 import stat…...

C++和C语言到底有什么区别?
引言:C和C语言是两种非常常见的编程语言,由于其广泛的应用和灵活性,它们在计算机科学领域内受到了广泛的关注。虽然C是从C语言发展而来的,但是这两种语言在许多方面都有所不同。本文将对C和C语言进行比较和分析,以便更…...
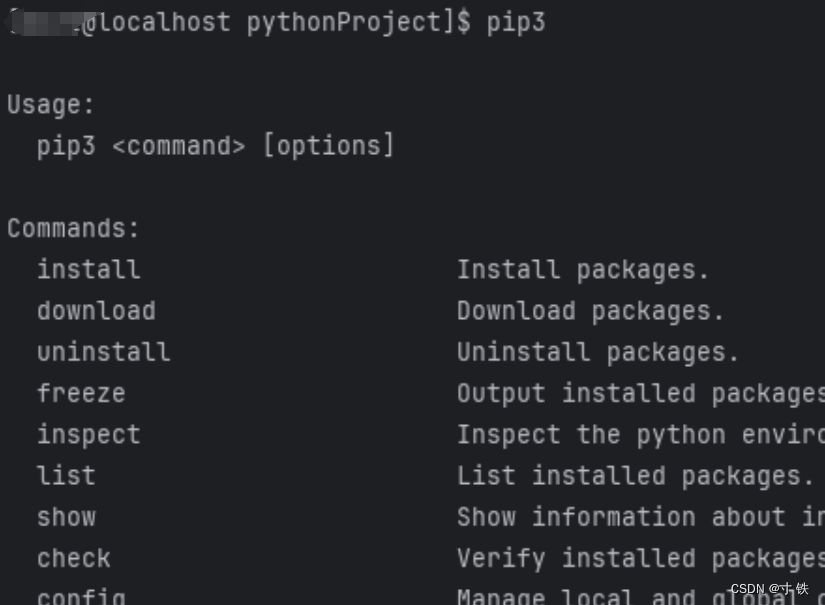
【Centos】深度解析:CentOS下安装pip的完整指南
【Centos】深度解析:CentOS下安装pip的完整指南 大家好 我是寸铁👊 总结了一篇【Centos】深度解析:CentOS下安装pip的完整指南✨ 喜欢的小伙伴可以点点关注 💝 方式1(推荐) 下载get-pip.py到本地 sudo wget https://bootstrap.p…...

半导体PW和NPW的一些小知识
芯片制造厂内的晶圆主要由两种,生产晶圆(PW:Product Wafer)和非生产晶圆(NPW:None Product Wafer)。 一、生产晶圆(PW) 生产晶圆的一些关键特点: 高纯度硅材料:生产晶…...
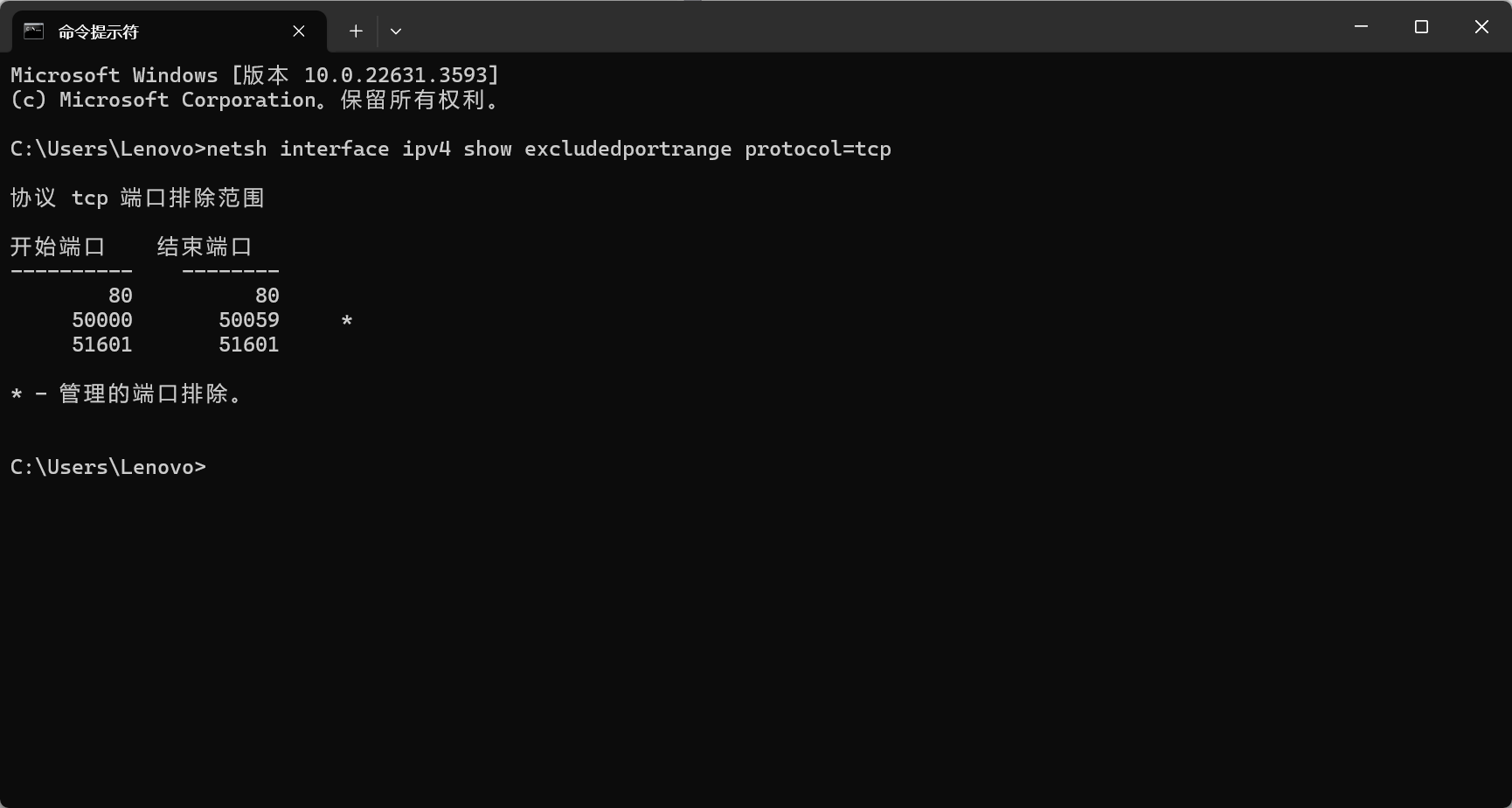
后端启动项目端口冲突问题解决
后端启动项目端口冲突 原因: Vindows Hyper-V虚拟化平台占用了端口。 解决方案一: 查看被占用的端口范围,然后选择一个没被占用的端口启动项目。netsh interface ipv4 show excludedportrange protocoltcp 解决方案二: 禁用H…...

【优选算法】优先级队列 {优先级队列解决TopK问题,利用大小堆维护数据流的中位数}
一、经验总结 优先级队列(堆),常用于在集合中筛选最值或解决TopK问题。 提示:对于固定序列的TopK问题,最优解决方案是快速选择算法,时间复杂度为O(N)比堆算法O(NlogK)更优;而对于动态维护数据流…...
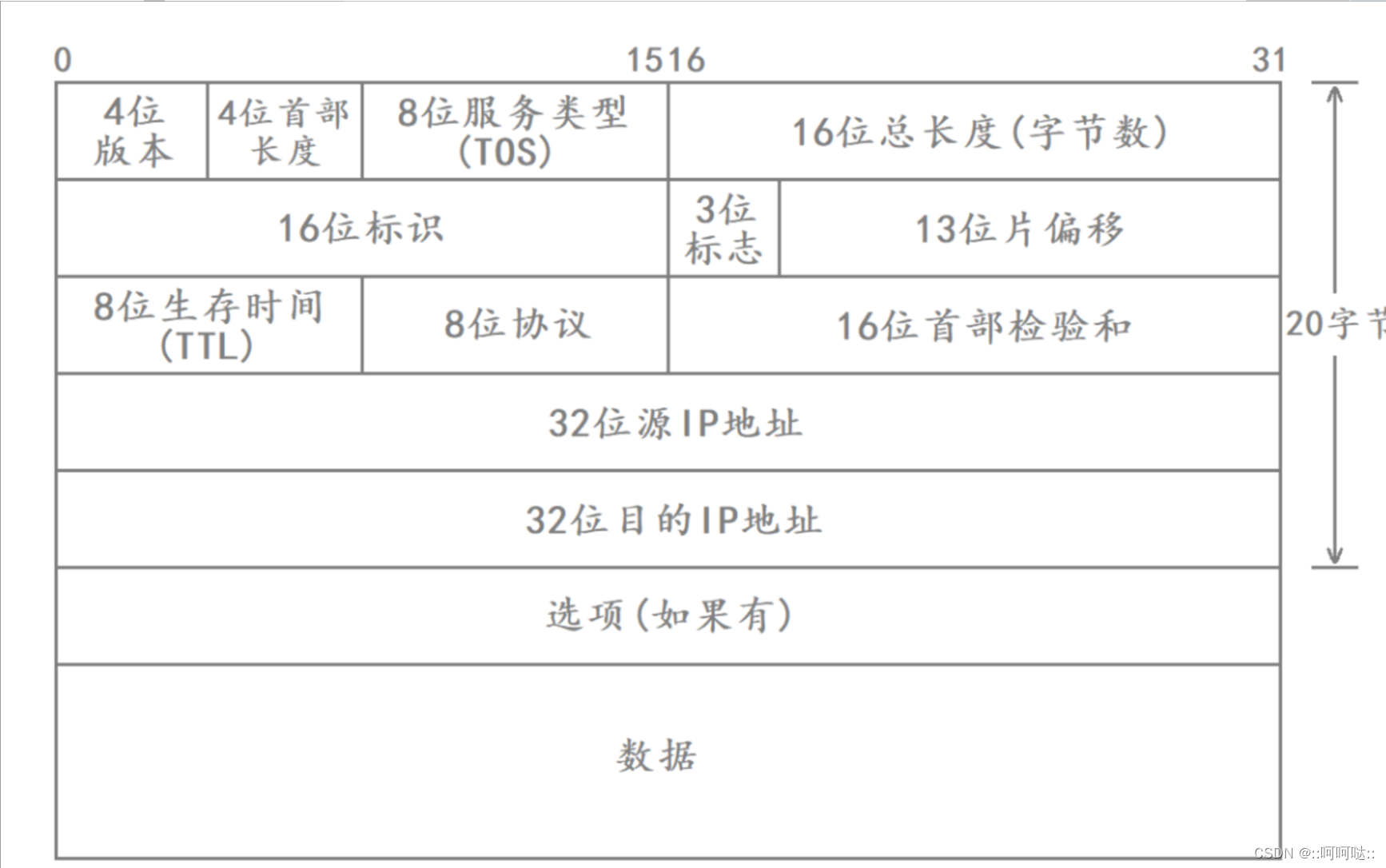
11 IP协议 - IP协议头部
什么是 IP 协议 IP(Internet Protocol)是一种网络通信协议,它是互联网的核心协议之一,负责在计算机网络中路由数据包,使数据能够在不同设备之间进行有效的传输。IP协议的主要作用包括寻址、分组、路由和转发数据包&am…...

【java】【python】leetcode刷题记录--二叉树
144.二叉树的前序遍历 题目链接 前、中、后的遍历的递归做法实际上都是一样的,区别就是遍历操作的位置不同。 对于先序遍历,也就是先根,即把查看当前结点的操作放在最前面即可。 class Solution {public List<Integer> preorderTrav…...
EVA-CLIP实战
摘要 EVA-CLIP,这是一种基于对比语言图像预训练(CLIP)技术改进的模型,通过引入新的表示学习、优化和增强技术,显著提高了CLIP的训练效率和效果。EVA-CLIP系列模型在保持较低训练成本的同时,实现了与先前具有相似参数数量的CLIP模型相比更高的性能。特别地,文中提到的EV…...

限定法术施放目标
实现目标 法术只对特定 creature | gameobject 施放,否则无法施放 实现方法 conditions SourceTypeOrReferenceId:13(CONDITION_SOURCE_TYPE_SPELL_IMPLICIT_TARGET)SourceGroup:受条件影响的法术效果掩码…...

【通信原理】数字频带传输系统
二进制数字调制,解调原理:2ASK,2FSK 二进制数字调制,解调原理:2PSK,2DPSK 二进制数字已调制信号的功率谱 二进制数字调制系统的抗噪声性能 二进制调制系统的性能总结...
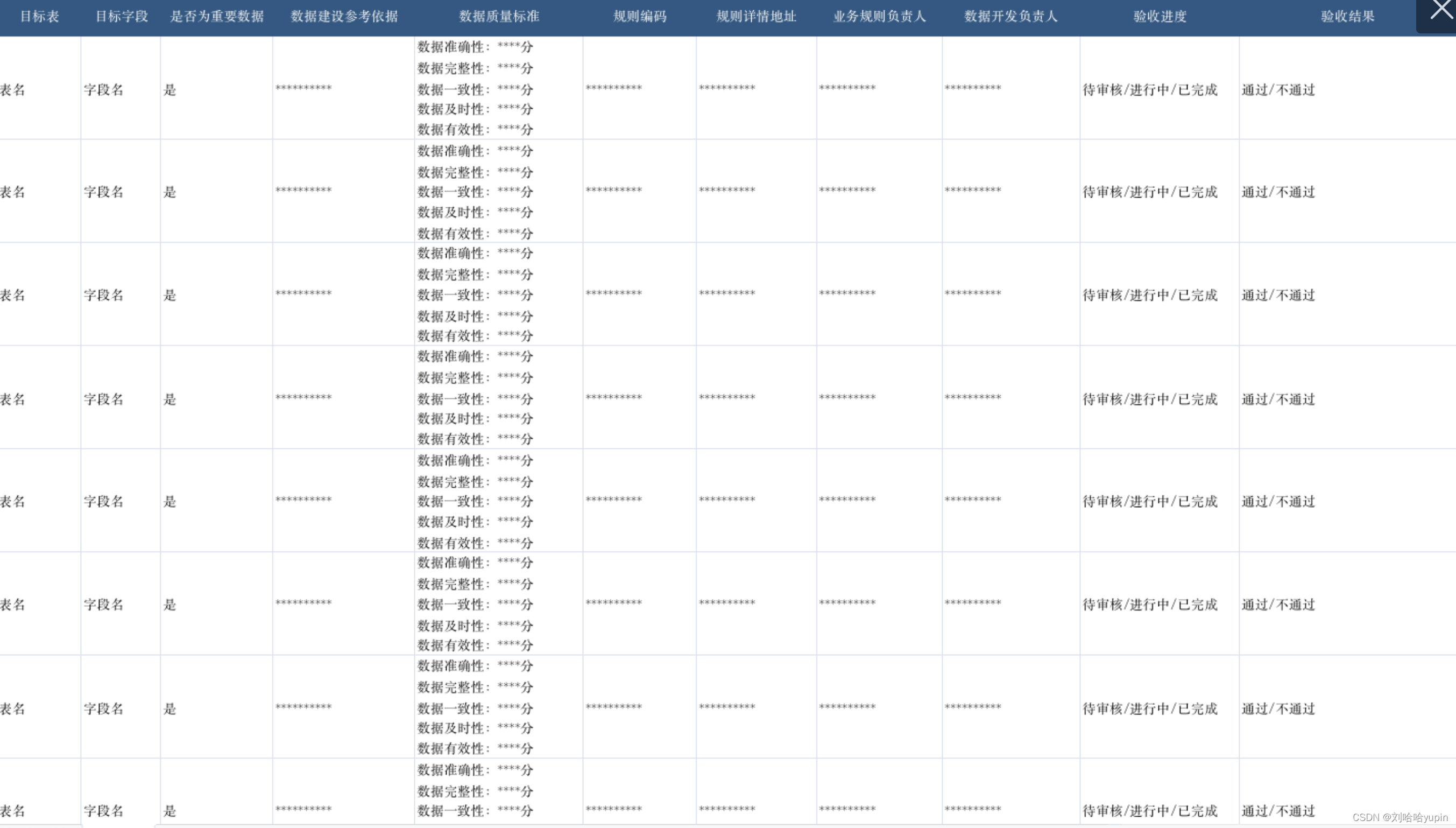
数据价值管理-数据验收标准
前情提要:数据价值管理是指通过一系列管理策略和技术手段,帮助企业把庞大的、无序的、低价值的数据资源转变为高价值密度的数据资产的过程,即数据治理和价值变现。第一讲介绍了业务架构设计的基本逻辑和思路。前面我们讲完了数据资产建设标准…...

vue3模板语法总结
1. 响应式数据 Vue 3中的数据是响应式的,即当数据发生变化时,视图会自动更新。这是通过使用JavaScript的getter和setter来实现的。 2. 组件化 Vue 3采用组件化开发方式,允许创建可复用的组件。 每个组件都有自己的作用域,并且…...
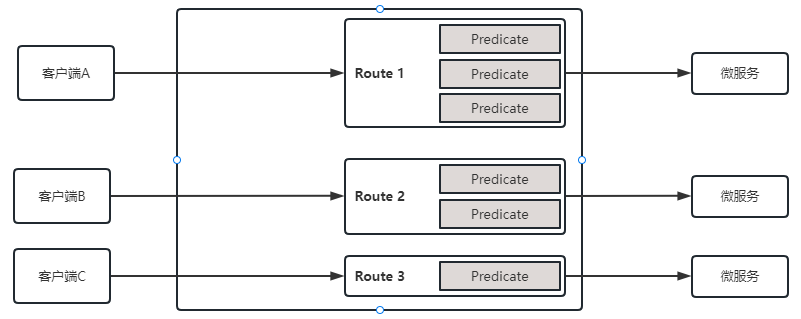
Spring Cloud 之 GateWay
前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z ChatGPT体验地址 文章目录 前言前言1、通过API网关访问服务2、Spring Cloud GateWay 最主要的功能就是路由…...

基于Git与Markdown的文档即代码协作平台CORP实践指南
1. 项目概述:一个面向未来的开源协作平台 最近在开源社区里,一个名为“CORP”的项目引起了我的注意。这个项目全称是“CORP-md/CORP”,从名字上看,它似乎是一个与Markdown文档和协作相关的工具。作为一个长期在开源项目和团队协作…...

智能体集成德国铁路实时信息:无需API的Node.js工具箱openclaw-bahn详解
1. 项目概述:一个为智能体打造的德国铁路工具箱如果你经常在德国乘坐火车,或者像我一样,需要为一些自动化流程(比如智能体)集成实时交通信息,那么你肯定对德国铁路(Deutsche Bahn, DB࿰…...

RE正则提取数字
RE正则提取数字import resddfff1234567890aasdfff s1s[::-1] print(fs:{s};s1:{s1}) option_str re.sub("\D", "", s) print(option_str )...

VS2019集成libigl实战:从零到一的图形学开发环境搭建
1. 环境准备:从零搭建开发基础 第一次接触libigl和VS2019的组合时,我完全能理解那种手足无措的感觉。记得当时为了赶图形学课程作业,我和室友熬了三个通宵才把环境跑通。现在回头看,其实只要掌握几个关键步骤,整个过程…...

本地部署AI代码解释器:基于大模型的对话式编程实践指南
1. 项目概述:当本地代码解释器遇上大模型最近在折腾一个挺有意思的项目,叫local-code-interpreter。这名字听起来有点学术,但说白了,它就是一个能让你在自己电脑上,通过自然语言对话来编写、执行和调试代码的“智能助手…...

自动驾驶卡车软件平台:技术架构、商业模式与商业化落地解析
1. 自动驾驶卡车软件平台全景解析最近几年,自动驾驶卡车这个赛道真是热闹非凡,感觉每周都有新融资、新合作或者新路测的消息出来。作为一个在汽车电子和软件行业摸爬滚打了十几年的老工程师,我一直在密切关注这个领域的动态。自动驾驶卡车&am…...

IGH-1.6.2-创龙RK3506-RT-----8-----my_master.c讲解【应用层PDO读写】
本文解决三个应用层问题: 第一,如何从 TxPDO 里读取 3 个 KEY。 第二,如何向 RxPDO 写入 5 个 LED。 第三,如何新增一个 UINT8 数据 PDO。 当前工程里的过程数据指针是 domain_pd,它是应用层读写 PDO 的基础。LED 和 KEY 的字节偏移、bit 位置,都是前面注册 PDO entry …...

开源机械爪智能增强:计算机视觉与运动规划赋予抓取超能力
1. 项目概述:当“机械爪”遇上“超能力”如果你玩过抓娃娃机,或者关注过工业自动化,对机械爪(Claw)这个概念一定不陌生。它的核心任务简单直接:识别、定位、抓取。但现实往往骨感——面对形状不规则、材质光…...

ImageGlass:Windows平台最强图像浏览器,90+格式全支持
ImageGlass:Windows平台最强图像浏览器,90格式全支持 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 你是否曾因Windows自带照片应用无法打开专业RA…...

PyTorch自动微分知识点讲解
PyTorch自动微分知识点讲解 知识导图 PyTorch自动微分 ├── 基础认知 │ ├── 自动微分的核心概念 │ └── autograd模块的作用 ├── 梯度计算 │ ├── 梯度计算的规则 │ └── backward与grad的使用 └── 实战案例├── 单参数的更新└── 多参数的更…...