数据预处理 #数据挖掘 #python
数据分析中的预处理步骤是数据分析流程中的重要环节,它的目的是清洗、转换和整理原始数据,以便后续的分析能够准确、有效。预处理通常包括以下几个关键步骤:
-
数据收集:确定数据来源,可能是数据库、文件、API或网络抓取,确保数据的质量和完整性。
-
数据清洗(Data Cleaning):
- 缺失值处理:填充、删除或估算缺失的数据。
- 异常值检测:识别并可能修复或排除不合理的数值。
- 重复值检查:删除重复记录,保持数据唯一性。
- 数据类型转换:将数据调整为正确的格式,如日期时间格式化、数值类型等。
-
数据集成(Data Integration):如果数据来自多个源,需要合并和统一数据格式。
-
数据转换(Data Transformation):
- 标准化或归一化:使数据具有可比性,例如Z-score标准化或Min-Max缩放。
- 编码分类变量:如One-Hot Encoding或Label Encoding。
- 特征工程:创建新的特征,比如从文本中提取关键词或计算衍生指标。
-
数据降维(Dimensionality Reduction):如果数据维度过高,可能使用PCA(主成分分析)或LDA(潜在狄利克雷分配)等方法减少冗余。
-
数据划分(Data Splitting):将数据集分为训练集、验证集和测试集,用于模型的训练和评估。
-
数据采样(Sampling):对于大规模数据,可能需要进行随机抽样或分层抽样以平衡类别分布。
-
数据可视化(Exploratory Data Analysis, EDA):初步了解数据的分布、关联性和模式。
完成这些预处理步骤后,数据就准备好了供机器学习模型进行训练和预测。预处理的质量直接影响到分析结果的可靠性。
接下来进行一个小小案例讲解:
- 1、缺失值处理
#1、
#读取数据
import pandas as pd
data = pd.read_excel('学生信息表.xlsx')
#查看属性缺失值情况
data.info()
data.isnull()
#删除“籍贯”为空的行
data = data.dropna(subset=["籍贯"])
#使用平均年龄填充“年龄”属性为空的数据
data['年龄'].fillna(data['年龄'].mean(),inplace=True)
#使用性别的众数填充“性别”属性为空的列
data.fillna({'性别':data['性别'].mode()[0]},inplace=True)- (1)读取“学生信息表.xlsx”。
-
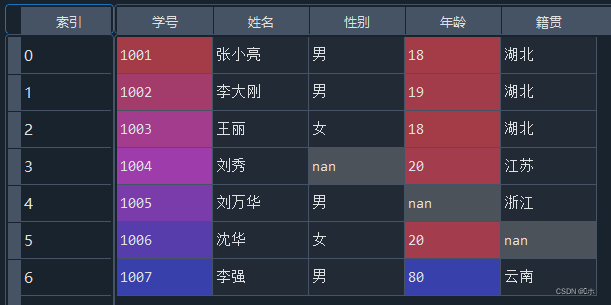
- (2)使用info()方法查看每一属性的缺失值情况。
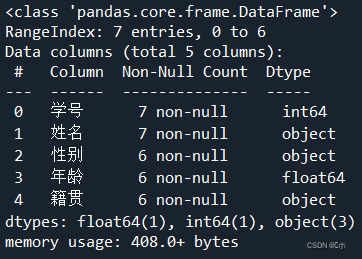
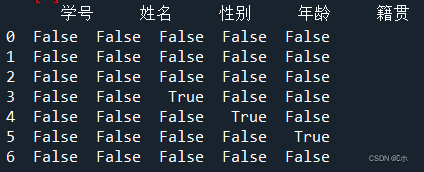
- (3)删除“籍贯”属性为空的行。
-
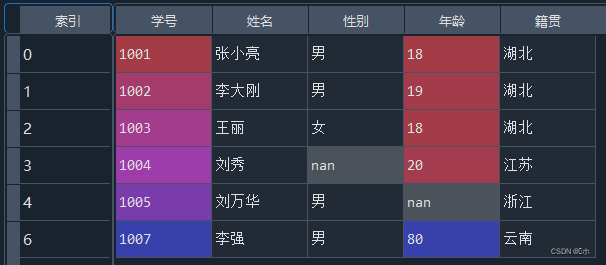
- (4)使用平均年龄填充“年龄”属性为空的数据。
-
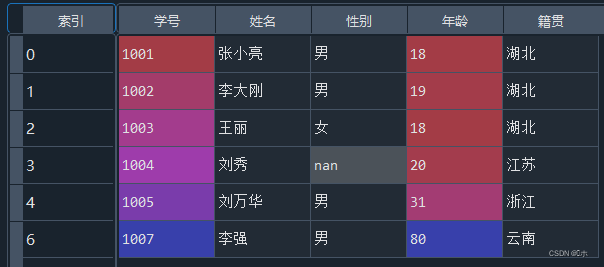
- (5)使用性别的众数填充“性别”属性为空的列。
-

- 2、非数值数据处理
-
#2、 #将“性别”属性设置为哑变量,删除“性别_女”,并将“性别_男”改为“性别” data = pd.get_dummies(data,columns=['性别']) data = data.drop(columns = '性别_女') data = data.rename(columns={'性别_男':'性别'}) #对“籍贯”属性进行编号处理 from sklearn.preprocessing import LabelEncoder le = LabelEncoder() label = le.fit_transform(data['籍贯']) data['籍贯'] = label - (1)将“性别”属性设置为哑变量,删除“性别_女”,并将“性别_男”改为“性别”。
- (1为性别男,0为性别女)
-
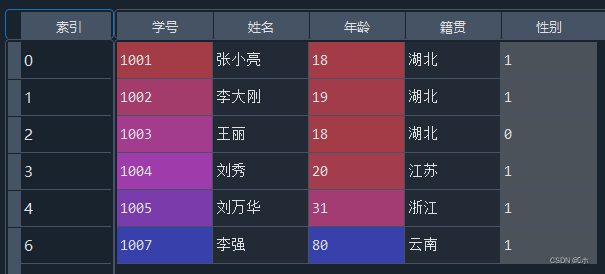
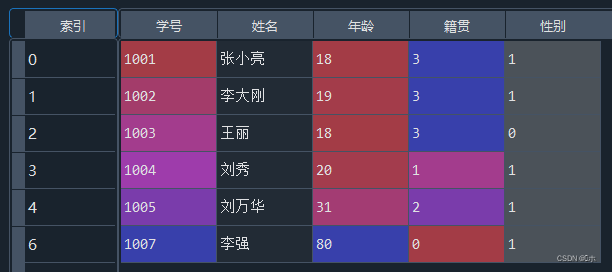
- (2)对“籍贯”属性进行编号处理。
- (0为云南;1为江苏;2为浙江;3为湖北)
-
- 3、异常值的处理
-
#3、 #箱线图观察“年龄”属性有无异常值 data.boxplot(column ='年龄' ) #对异常值进行标注,标注在out1属性中 import numpy as np data['out1'] = np.where(data['年龄'] < 30,0,1) #使用2倍标准差法标注异常值,标注在out2属性中 data['out2'] = abs((data['年龄']-data['年龄'].mean())/data['年龄'].std()) > 2 - (1)箱线图观察“年龄”属性有无异常值;
-
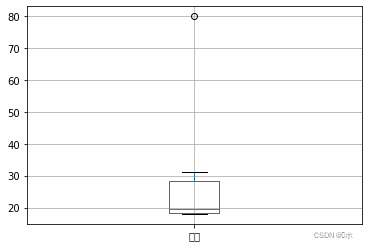
- (2)对异常值进行标注,标注在out1属性中;
-
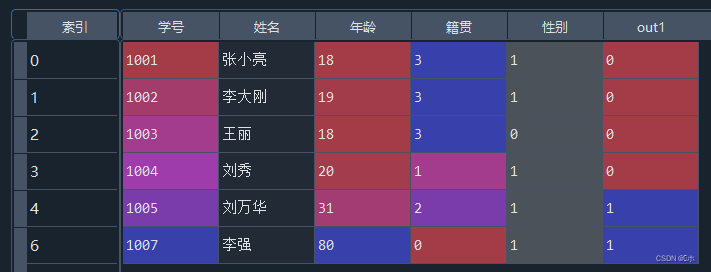
- (3)使用2倍标准差法标注异常值,标注在out2属性中。
-
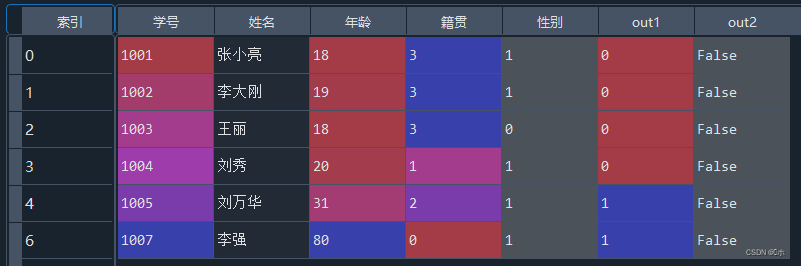
- 4、数据标准化
-
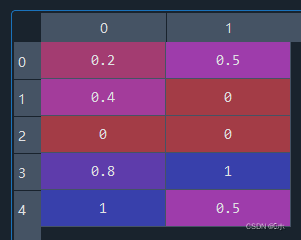
#4、 #生成数据 data2 = pd.DataFrame({'酒精含量(%)': [50, 60, 40, 80, 90], '苹果酸含量(%)': [2, 1, 1, 3, 2]}) print(data2) #对各列进行z-score标准化 from sklearn.preprocessing import StandardScaler data2_new1 = StandardScaler().fit_transform(data2) print(data2_new1) #对各列进行min-max标准化 from sklearn.preprocessing import MinMaxScaler data2_new2 = MinMaxScaler().fit_transform(data2) print(data2_new2) - 如下数据:
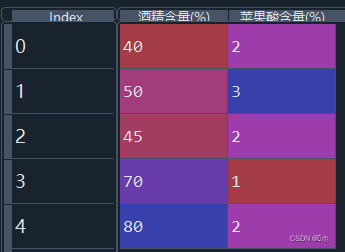
- (1)对以上数据的各列进行z-score标准化;
-
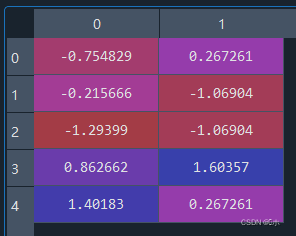
- (2)对以上数据的各列进行min-max标准化。
-
- 5、生成多项式特征
-
#5、 #生成多项式特征 from sklearn.preprocessing import PolynomialFeatures data3 = np.array([[2,3],[2,4]]) print(data3) pf1=PolynomialFeatures(degree=2) print(pf1.fit_transform(data3)) pf2=PolynomialFeatures(degree=2,include_bias=False) print(pf2.fit_transform(data3)) pf3=PolynomialFeatures(degree=2,include_bias=False,interaction_only=True) print(pf3.fit_transform(data3)) - 现在有(a,b)两个特征,生成二次多项式则为(1,a, b , ab, a^2, b^2),并用以下数据做测试:data3:
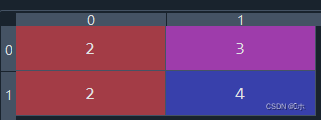
pf1:![]()
pf2:![]()
pf3:![]()
相关文章:
数据预处理 #数据挖掘 #python
数据分析中的预处理步骤是数据分析流程中的重要环节,它的目的是清洗、转换和整理原始数据,以便后续的分析能够准确、有效。预处理通常包括以下几个关键步骤: 数据收集:确定数据来源,可能是数据库、文件、API或网络抓取…...
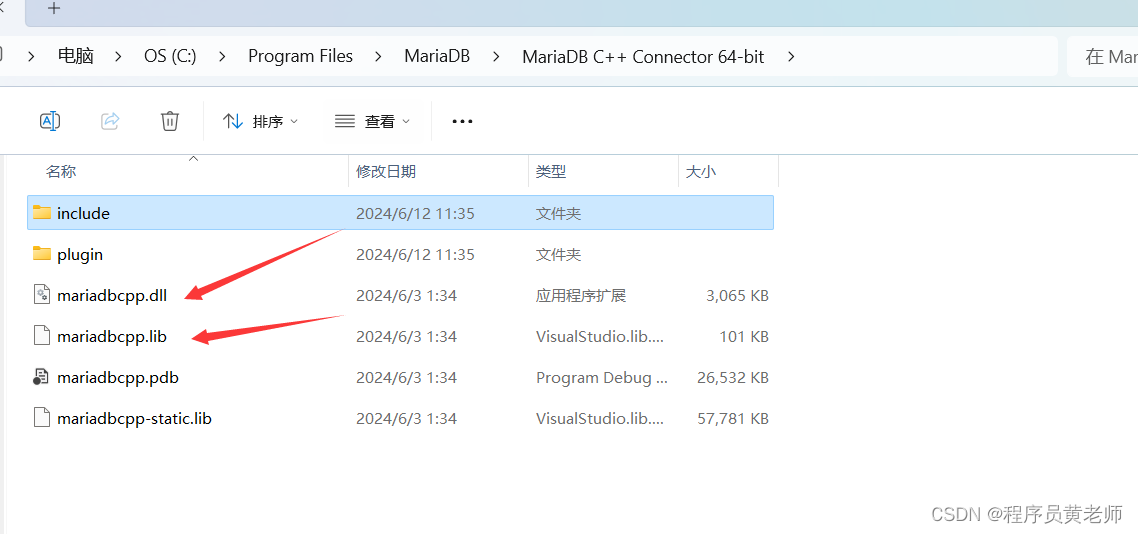
VS2022 使用C++访问 mariadb 数据库
首先,下载 MariaDB Connector/C++ 库 MariaDB Products & Tools Downloads | MariaDB 第二步,安装后 第三步,写代码 #include <iostream> #include <cstring> #include <memory> #include <windows.h>#include <mariadb/conncpp.hpp>…...

kotlin 语法糖
Use of “when” Expression Instead of “switch” fun getDayOfWeek(day: Int): String {return when (day) {1 -> "Monday"2 -> "Tuesday"3 -> "Wednesday"4 -> "Thursday"5 -> "Friday"6 -> "Sa…...
.NET MAUI Sqlite数据库操作(一)
一、安装 NuGet 包 安装 sqlite-net-pcl 安装 SQLitePCLRawEx.bundle_green 二、配置数据库(数据库文件名和路径) namespace TodoSQLite; public static class Constants {public const string DatabaseFilename "TodoSQLite.db3";//数据库…...
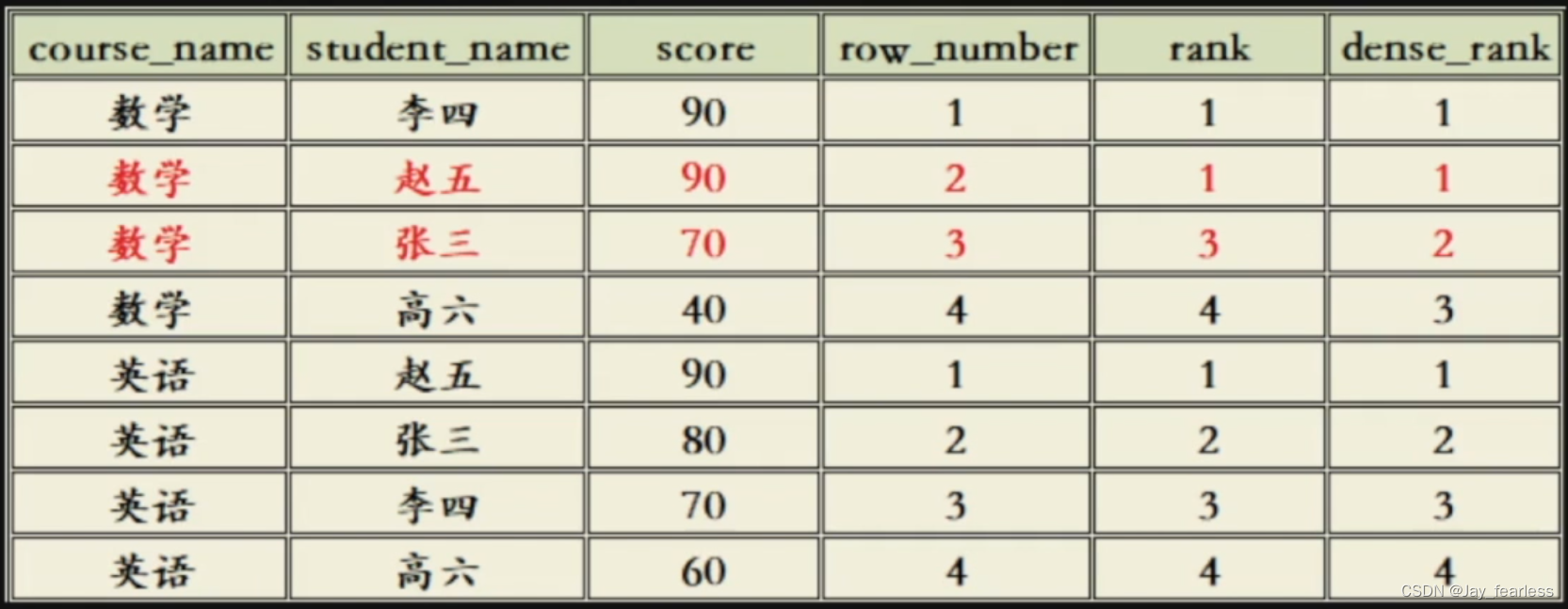
SQL 窗口函数
1.窗口函数之排序函数 RANK, DENSE_RANK, ROW_NUMBER RANK函数 计算排序时,如果存在相同位次的记录,则会跳过之后的位次 有 3 条记录排在第 1 位时: 1 位、1 位、1 位、4 位…DENSE_RANK函数 同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次 有 3 条记录排在…...
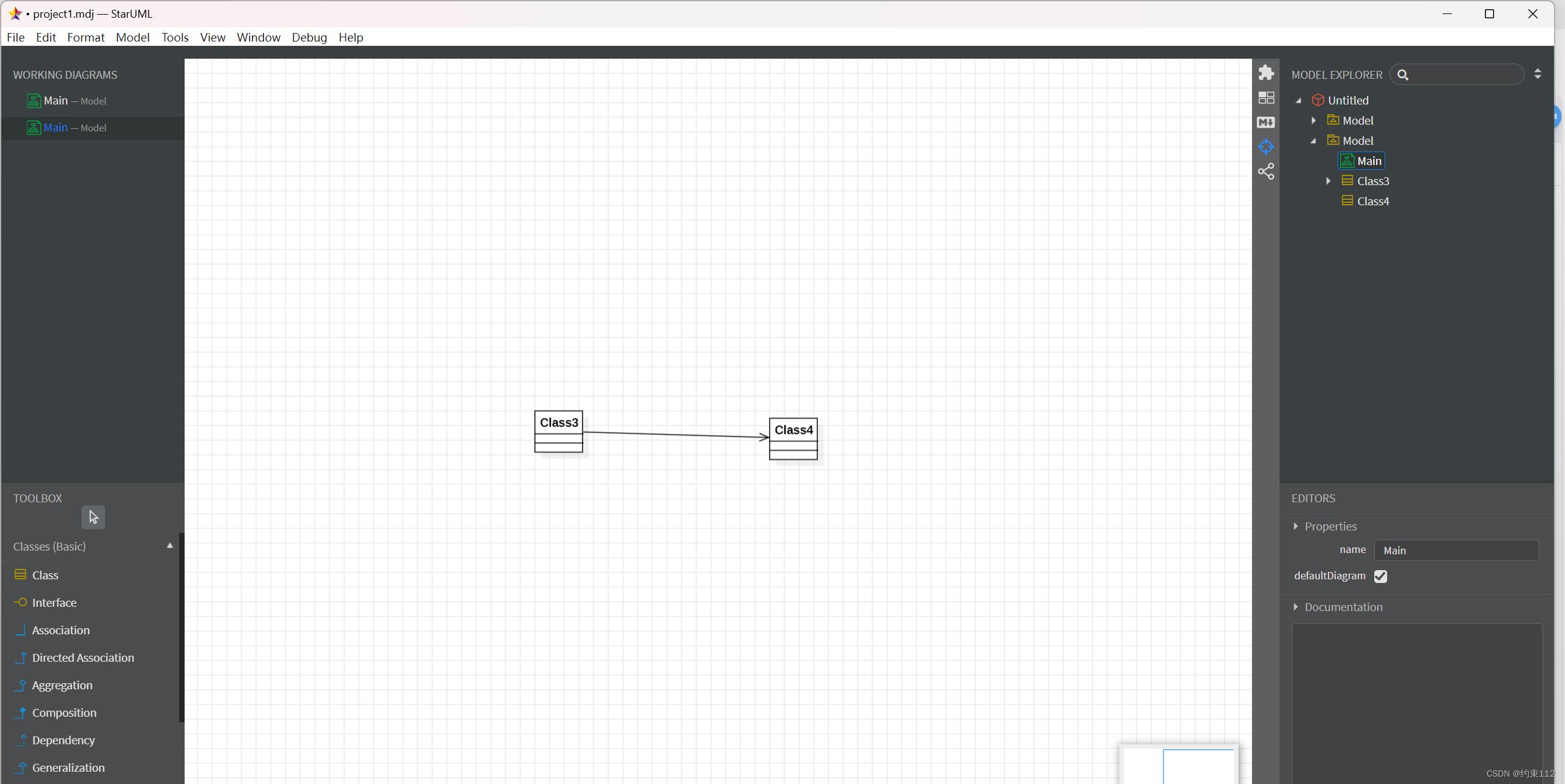
staruml怎么合并多个Project工程文件
如图现在有两个staruml文件 现在我想要把project2合并到project1里面 步骤如下: 1、首先打开project2 2、如图选择导出Fragment 3、选中自己想导出的模块(可以不止一个) 4、将其保存在桌面 5、打开project1 6、选择导入 7、选中刚刚…...

设计模式——外观模式
外观模式(Facade) 为系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。 #include <iostream>using namespace std;// 四个系统子类 class SubSystemOne { public:void MethodOne(){cout <&l…...

开源-Docker部署Cook菜谱工具
开源-Docker部署Cook菜谱工具 文章目录 开源-Docker部署Cook菜谱工具介绍资源列表基础环境一、安装Docker二、配置加速器三、查看Docker版本四、拉取cook镜像五、部署cook菜谱工具5.1、创建cook容器5.2、查看容器运行状态5.3、查看cook容器日志 六、访问cook菜谱服务6.1、访问c…...

使用PHP对接企业微信审批接口的问题与解决办法(二)
在现代企业中,审批流程是非常重要的一环,它涉及到企业内部各种业务流程的规范和高效运转。而随着企业微信的流行,许多企业希望将审批流程整合到企业微信中,以实现更便捷的审批操作。本文将介绍如何使用PHP对接企业微信审批接口&am…...
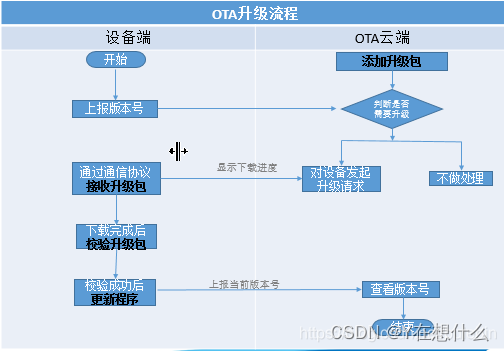
RK3288 android7.1 实现ota升级时清除用户数据
一,OTA简介(整包,差分包) OTA全称为Over-The-Air technology(空中下载技术),通过移动通信的接口实现对软件进行远程管理。 1. 用途: OTA两种类型最大的区别莫过于他们的”出发点“(我们对两种不同升级包的创建&…...

okHttp的https请求忽略ssl证书认证
使用okhttp请求第三方https接口返回异常 sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target意思就是非安全的调用&#…...

在Java中使用Spring Boot设置全局的BusinessException
在线工具站 推荐一个程序员在线工具站:程序员常用工具(http://cxytools.com),有时间戳、JSON格式化、文本对比、HASH生成、UUID生成等常用工具,效率加倍嘎嘎好用。 程序员资料站 推荐一个程序员编程资料站:…...

Java 异常处理 -- Java 语言的异常、异常链与断言
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 009 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进一步完善自己对整个 Java 技术体系来充实自…...

Spring Cloud Nacos 详解:服务注册与发现及配置管理平台
Spring Cloud Nacos 详解:服务注册与发现及配置管理平台 Spring Cloud Nacos 是 Spring Cloud 生态系统中的一个子项目,提供了服务注册与发现、配置管理等功能,基于 Alibaba 开源的 Nacos 项目。Nacos 是一个易于使用的动态服务发现、配置管…...

java多线程临界区介绍
在Java多线程编程中,"临界区"是指一段必须互斥执行的代码区域。当多个线程访问共享资源时,为了防止数据不一致或逻辑错误,需要确保同一时刻只有一个线程可以进入临界区。Java提供了多种机制来实现这一点,例如synchroniz…...
基于JSP的超市管理系统
你好呀,我是计算机学长猫哥!如果有相关需求,文末可以找到我的联系方式。 开发语言:Java 数据库:MySQL 技术:JSP MyBatis 工具:IDEA/Eclipse、Navicat、Maven 系统展示 员工管理界面图 管…...
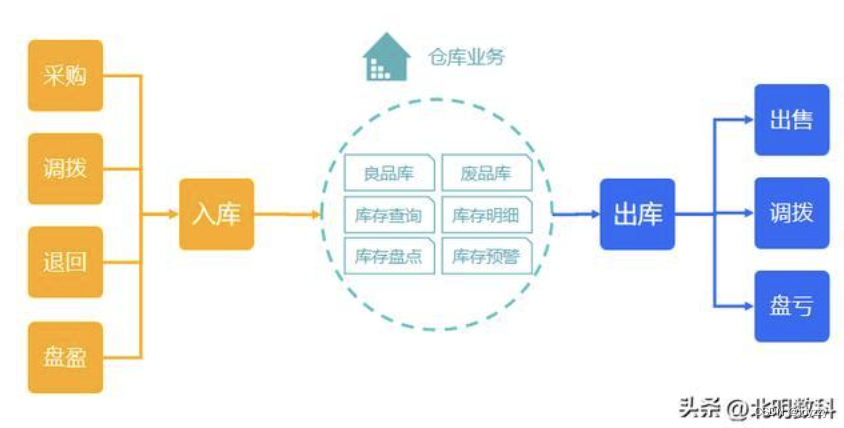
一文讲清:生产报工系统的功能、报价以及如何选择
最近这几年,企业越来越注重生产的速度和成本,尤其是“性价比”,生产报工系统已经变成了制造业里不可或缺的一部分。不过,市场上生产报工系统的选择太多,价格也都不一样,这就给很多企业出了个难题࿱…...

blender bpy将顶点颜色转换为UV纹理vertex color to texture
一、关于环境 安装blender的bpy,不需要额外再安装blender软件。在python控制台中直接输入pip install bpy即可。 二、关于代码 本文所给出代码仅为参考,禁止转载和引用,仅供个人学习。 本文所给出的例子是https://download.csdn.net/downl…...

Flink Sql:四种Join方式详解(基于flink1.15官方文档)
JOINs flink sql主要有四种连接方式,分别是Regular Joins、Interval Joins、Temporal Joins、lookup join 1、Regular Joins(常规连接 ) 这种连接方式和hive sql中的join是一样的,包括inner join,left joinÿ…...
 Object Pascal 学习笔记---第14章泛型第3节(泛型约束))
(delphi11最新学习资料) Object Pascal 学习笔记---第14章泛型第3节(泛型约束)
14.3 泛型约束 正如我们所看到的,您在泛型类的方法中可以做的事情非常少。您可以传递它(即分配它)并执行上面我介绍的泛型类型函数允许的有限操作。 为了能够执行泛型类的实际操作,通常需要对其进行约束。例如,…...

数据中心48V直连供电架构:从效率瓶颈到硬件设计实战
1. 数据中心供电演进:从香农理论到48V直连架构1948年,克劳德香农发表《通信的数学理论》,用1和0的二进制语言为信息时代奠基。六十八年后的今天,当我们谈论数据中心——这个承载着全球信息洪流的数字心脏时,讨论的焦点…...

金融机器学习实战:从特征工程到投资组合优化的完整工具库解析
1. 项目概述:金融机器学习的开源宝库如果你在量化金融、算法交易或者金融数据分析领域摸爬滚打过一段时间,大概率会和我有同样的感受:从零开始构建一个可靠的金融机器学习(Financial Machine Learning, FML)研究或交易…...

ARM错误恢复中断机制与ERRERICR2寄存器详解
1. ARM错误恢复中断机制概述在ARM架构的可靠性、可用性和可维护性(RAS)系统中,错误恢复中断是实现硬件容错的关键机制。当处理器检测到可恢复的错误条件时,通过这套机制能够快速通知系统进行错误处理,而ERRERICR2寄存器…...

CipherGuard:编译器级密文侧信道攻击防护技术解析
1. CipherGuard技术背景与核心挑战密文侧信道攻击(Ciphertext Side-Channel Attacks)已成为现代可信执行环境(TEE)中最棘手的安全威胁之一。这类攻击不直接破解加密算法本身,而是通过分析加密操作执行过程中产生的内存…...

5分钟掌握暗黑2存档编辑:免费开源工具d2s-editor完全指南
5分钟掌握暗黑2存档编辑:免费开源工具d2s-editor完全指南 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2重复刷装备而烦恼?想快速体验不同职业Build却不想从头练级?今天我要…...

AI代理如何通过MCP协议实现DeFi自动化操作与策略执行
1. 项目概述:当DeFi遇上AI代理,Robocular/defi-mcp的诞生最近在捣鼓链上自动化策略和AI代理,发现了一个挺有意思的项目——Robocular/defi-mcp。简单来说,这是一个专门为AI代理(特别是那些基于MCP,也就是Mo…...

基于物联网的泵车远程运维与主动服务解决方案
某设备制造商拥有大量在役泵车,分布在全国各地的基建工地和商混站。长期以来,售后服务团队面临着严峻的挑战:由于泵车多在户外流动作业、分布范围广,设备一旦发生故障,售后工程师需要千里奔波到现场才能判断问题&#…...

9D传感器融合技术:原理、优化与应用
1. 9D传感器融合技术概述在当今的智能设备领域,精确的姿态感知已成为标配功能。从智能手机的自动旋转屏幕到VR头显的动作追踪,背后都离不开多传感器数据的融合处理。9D传感器融合技术通过整合加速度计、陀螺仪和磁力计的数据(各提供3轴测量&a…...

温室大棚结构设计与选型指南:从荷载计算到智能控制系统
摘要 温室大棚作为现代农业的核心基础设施,其结构设计、材料选型及环境调控系统的合理性直接影响作物产量与运营成本。本文从工程技术角度出发,系统介绍日光温室、智能连栋温室、菌菇专用大棚等常见类型的技术特点、结构参数、荷载计算要点及智能控制系统…...

八、命令行参数和环境变量
八、命令行参数和环境变量8.1 命令行参数8.2 环境变量概念8.3 常见环境变量8.4 查看环境变量指令测试 PATH8.5 环境变量相关命令8.6 环境变量组织方式8.7 环境变量通常具有全局属性进程创建机制环境变量的存储结构代码执行流程总结8.8 获取环境变量命令行第三个参数通过第三方变…...