SQL进阶day10————多表查询
目录
1嵌套子查询
1.1月均完成试卷数不小于3的用户爱作答的类别
1.2月均完成试卷数不小于3的用户爱作答的类别
编辑1.3 作答试卷得分大于过80的人的用户等级分布
2合并查询
2.1每个题目和每份试卷被作答的人数和次数
2.2分别满足两个活动的人
3连接查询
3.1满足条件的用户的试卷完成数和题目练习数
3.2 每个6/7级用户活跃情况
1嵌套子查询
1.1月均完成试卷数不小于3的用户爱作答的类别

我的代码:思路就是这么个思路,反正没有搞出来当月均完成试卷数
select tag,count(submit_time) tag_cnt
from exam_record er join examination_info ei
on er.exam_id = ei.exam_id
where uid in (当月均完成试卷数>=3)
group by tag
order by tag_cnt desc反正没有搞出来当月均完成试卷数,报错:

大佬正确答案:
居然和我的差不多,我就分组的时候少了uid,还有按照uid进行分组。此外,作答次数=count(start_time),而不是提交次数。
select tag, count(start_time) as tag_cnt
from exam_record er inner join examination_info ei
on er.exam_id = ei.exam_id
where uid in
(select uid
from exam_record er
group by uid, month(start_time)
having count(submit_time) >= 3)
group by tag
order by tag_cnt desc复盘:
(1)uid,month(submit_time)是啥呢,如果原来只是按照month(submit_time)进行分组,1002,1003,1005都有多个

(2)如果按照uid,month(submit_time)进行分组,情况如下

(3)这么如果只是按照month(submit_time) 分组,uid,month(submit_time)只有9和null两种情况,当使用GROUP BY子句时,NULL值将被视为一个独立的分组,并在结果集中显示一个额外的分组来表示它。
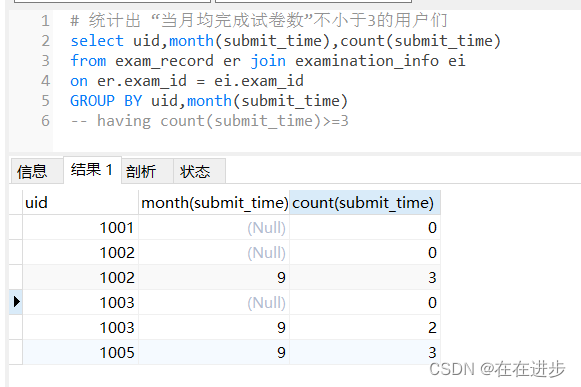
(4)结果显示只有1002,1005这两个用户满足要求,然后查找这两个用户的作答的类别及作答次数。

(5)验证:where uid =1002 or uid = 1005 等价于 子查询的效果

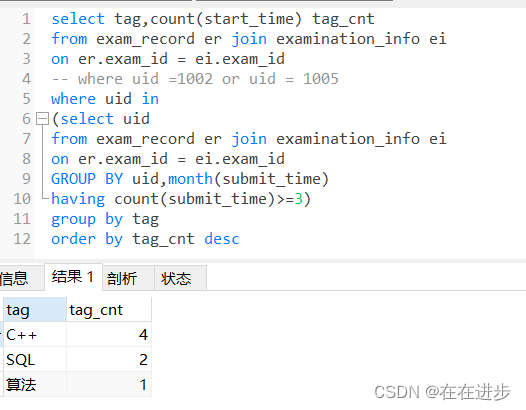
还有一种大佬做法是:
select tag,count(start_time) tag_cnt
from exam_record er join examination_info ei
on er.exam_id = ei.exam_id
-- where uid =1002 or uid = 1005
WHERE er.uid IN (SELECT uidFROM exam_recordGROUP BY uidHAVING COUNT(submit_time) / COUNT(DISTINCT DATE_FORMAT(submit_time, "%Y%m")) >= 3
)
group by tag
order by tag_cnt desc这样出来的两个用户也是1002和1005:
- 相当于:月均完成试卷数 = 总完成次数/哪些月份提交了数据
COUNT(DISTINCT DATE_FORMAT(submit_time, "%Y%m"))=1,所以答案一样的。

COUNT(DISTINCT DATE_FORMAT(submit_time, "%Y%m"))中的distinct很重要:

1.2月均完成试卷数不小于3的用户爱作答的类别

我的代码:答案错误,但是我能发现的的改了,
(1)SQL类,(2)当天,(3)作答人数
select er.exam_id,
any_value(count(er.submit_time)) uv,
round(avg(er.score),1) avg_score
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
where ei.tag = "SQL"
and day(submit_time)=day(release_time)
and er.uid in
(select uid
from user_info
where level > 5)
group by er.exam_id
order by uv desc,avg_score asc
正确代码:
select er.exam_id,
any_value(count(distinct er.uid)) uv,
round(avg(er.score),1) avg_score
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
where ei.tag = "SQL"
and date_format(submit_time,'%Y%m%d')=date_format(release_time,'%Y%m%d')
and er.uid in
(select uid
from user_info
where level > 5)
group by er.exam_id
order by uv desc,avg_score asc复盘:
(1)同一天,不能用day函数,0901和0201的day都是1,但是不是同一天。

(2)计算人数时,要加distinct才对:
原数据有这种离谱的情况??
 1.3 作答试卷得分大于过80的人的用户等级分布
1.3 作答试卷得分大于过80的人的用户等级分布

我的正确代码:直接三表连接
select level,count(level) level_cnt
from user_info u
join exam_record er
on u.uid = er.uid
join examination_info ei
on ei.exam_id = er.exam_id
where ei.tag = 'SQL'
and er.score>80
group by level嵌套子查询的方法代码:
SELECT level,
COUNT(level) AS level_cnt
FROM user_info
WHERE uid IN (SELECT DISTINCT uidFROM exam_recordWHERE score > 80AND exam_id IN (SELECT exam_id FROM examination_info WHERE tag = 'SQL'))
GROUP BY level
ORDER BY level_cnt DESC;2合并查询
2.1每个题目和每份试卷被作答的人数和次数
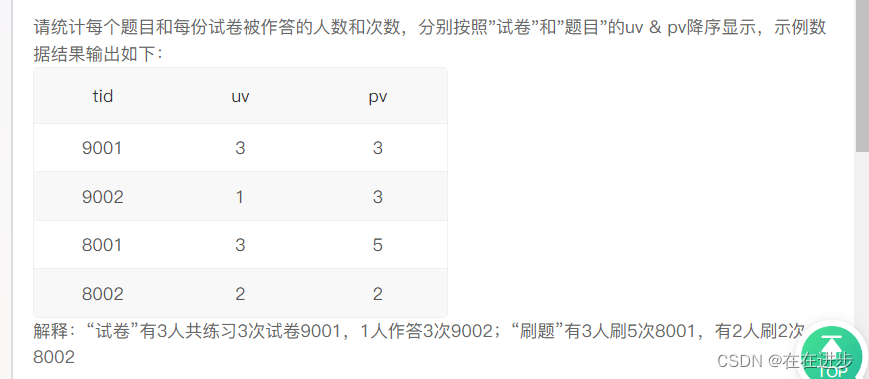
我的代码:分别查询然后用union all合并起来,但是答案错了
select exam_id tid,
count(distinct er.uid) uv,
count(distinct pr.submit_time) pv
from exam_record er join practice_record pr
using(uid)
group by exam_idunion allselect question_id tid,
count(distinct er.uid) uv,
count(distinct pr.submit_time) pv
from exam_record er join practice_record pr
using(uid)
group by question_id正确答案:
select * from
(SELECT exam_id tid,count(DISTINCT uid) uv,count(uid) pv from exam_record
group by exam_id
order by uv desc,pv desc)a
UNION ALL
SELECT * FROM
(SELECT question_id tid,count(DISTINCT uid) uv,count(uid) pv from practice_record
GROUP BY question_id
order by uv desc,pv desc)b我的代码改正:这个题最后不要合并,题目和试卷在不同的表里,分别查询在合并就好了
select exam_id tid,
count(distinct er.uid) uv,
count(er.uid) pv
from exam_record er
group by exam_idunion allselect question_id tid,
count(distinct pr.uid) uv,
count(pr.uid) pv
from practice_record pr
group by question_id还没排序:
但是使用 union 和 多个order by 不加括号 【报错】,order by 在 union 连接的子句不起作用,但是在子句的子句中起作用。
方法一:所以加两个order的话正确要这样写:
#正确代码
select * from
(
select exam_id as tid,count(distinct uid) as uv,count(uid) as pv
from exam_record a
group by exam_id
order by uv desc, pv desc
) a
union
select * from
(
select question_id as tid,count(distinct uid) as uv,count(uid) as pv
from practice_record b
group by question_id
order by uv desc, pv desc
) attr方法二:或者利用left(str,length) 函数: str左边开始的长度为 length 的子字符串,在本例中为‘9’和‘8’。
order by left(tid,1) desc,uv desc,pv desc
解释:试卷编号以‘9’开头、题目编号以‘8’开头,对编号进行降序就是对"试卷"和"题目"分别进行排序。
(#每份试卷被作答的人数和次数selectexam_id as tid,count(distinct uid) as uv,count(*) as pv
from exam_record
group by exam_id
)
union
(#每个题目被作答的人数和次数selectquestion_id as tid,count(distinct uid) as uv,count(*) as pv
from practice_record
group by question_id
)
#分别按照"试卷"和"题目"的uv & pv降序显示
order by left(tid,1) desc,uv desc,pv desc2.2分别满足两个活动的人
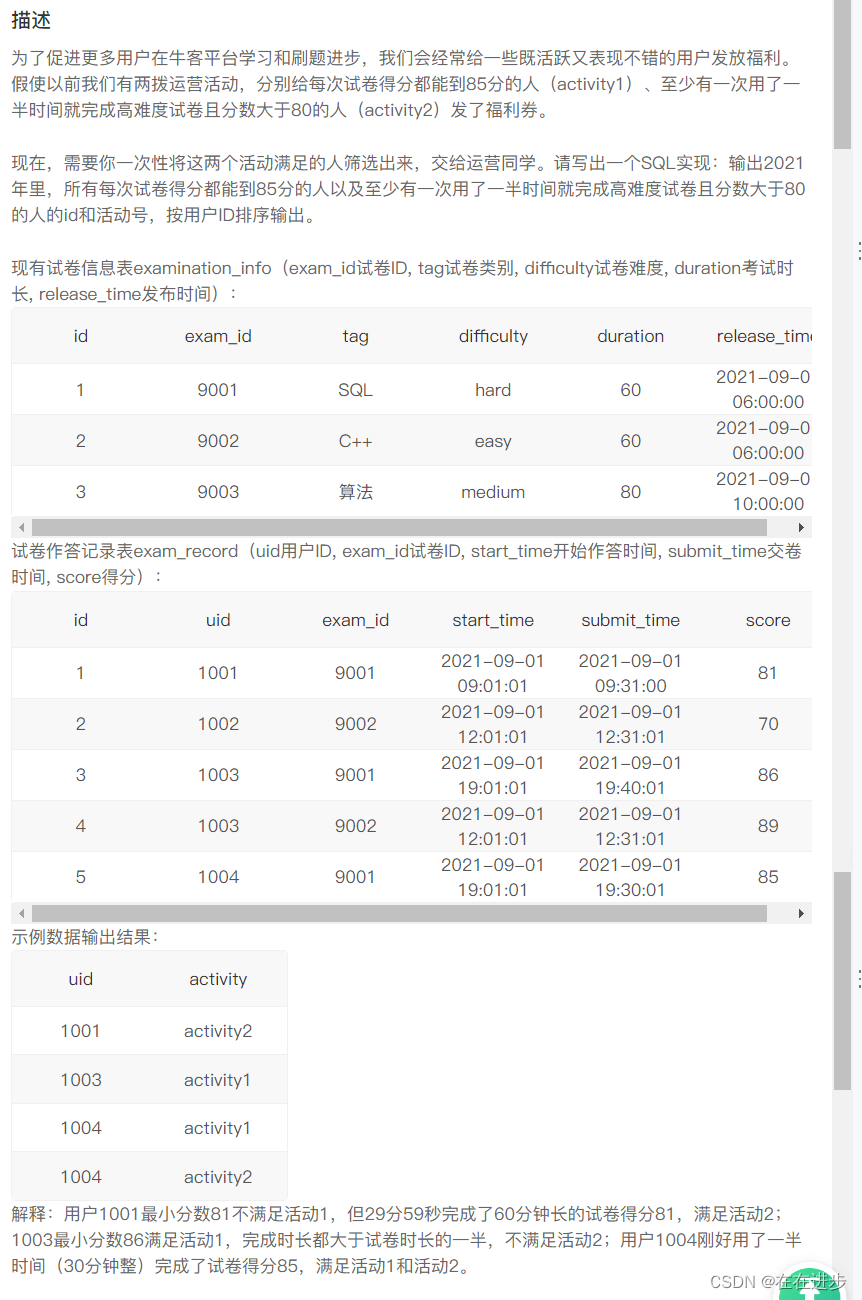
我的垃圾代码:不知道新的值怎么弄
(select uidfrom exam_recordgroup by 1001having score>85
)tselect uid t.activity
from examination_info ei join exam_record er
on ei.exam_id = er.exam_id
大佬代码:
(select uid,'activity1' as activity
from exam_record er
where year(start_time)='2021'
group by uid
having min(score)>=85)
union ALL
(select uid,'activity2' as activity
from exam_record er left join examination_info ei on er.exam_id=ei.exam_id
where year(start_time)='2021' and ei.difficulty='hard' and score>=80
and timestampdiff(second,er.start_time,er.submit_time)<= ei.duration*30
group by uid)
order by uid;复盘:
(1)select uid,'activity1' as activity...,这样就把activity这一列就设置出来了。
(2)时间差函数:timestampdiff,如计算差多少分钟,timestampdiff(minute,时间1,时间2),是时间2-时间1,单位是minute。
这里是至少有一次用了一半时间就完成:
完成时间<=考试时长/2 (单位为分钟minute)
完成时间<=考试时长*60/2 =考试时长*30(单位为秒second)
timestampdiff(second,er.start_time,er.submit_time)<= ei.duration*30
(3)每次试卷得分都能到85分,相当于最低分min>=85
3连接查询
3.1满足条件的用户的试卷完成数和题目练习数

我的报错代码:看来不是这么简单粗暴的事情
select u.uid,
count(er.submit_time) exam_cnt,
count(pr.submit_time) question_cnt
from user_info u join exam_record er
on u.uid = er.uid
join practice_record pr
on pr.uid = u.uid
join examination_info ei
on ei.exam_id = er.exam_id
where year(er.submit_time)='2021'
group by u.uid
having ei.tag = 'SQL'
and ei.difficulty = 'hard'
and u.level = 7
and avg(er.score)>80正确代码:
# select er.uid as uid,
# count(distinct er.submit_time) as exam_cnt,
# count(distinct pr.submit_time) as question_cnt
select er.uid as uid,
count(distinct er.exam_id) as exam_cnt,
count(distinct pr.id) as question_cntfrom exam_record er
left join practice_record pr
on er.uid=pr.uid
and year(er.submit_time)=2021
and year(pr.submit_time)=2021where er.uid in(select er.uidfrom exam_record er left join examination_info ei on er.exam_id = ei.exam_idleft join user_info ui on er.uid = ui.uid where tag='SQL' and difficulty='hard' and level = 7group by er.uidhaving avg(score) > 80)
group by er.uid
order by exam_cnt,question_cnt desc复盘:
有4个表,很多个条件
(1)先通过子查询中连接,er,ui和ei筛选出高难度SQL试卷得分平均值大于80并且是7级的红名大佬(返回用户uid)

(2) 再统计这些大佬的2021年试卷总完成次数,和题目总练习次数
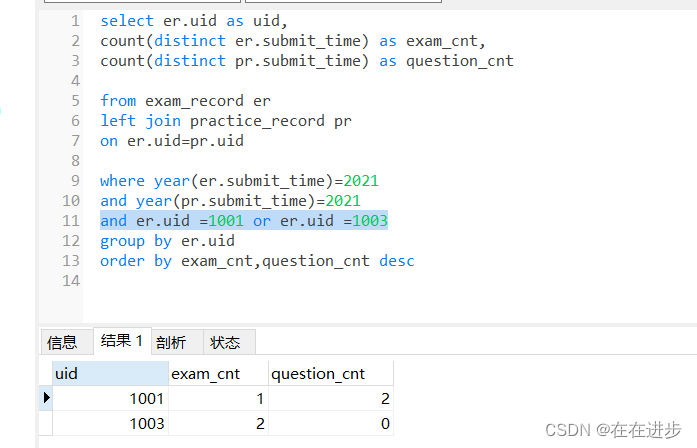
(3)注意第(2)步中连接是左连接,不应该出现试卷为null,题目不为null的情况!
from exam_record er left join practice_record pr
(4)不懂为什么不能用 er.submit_time, pr.submit_time来计算
# select er.uid as uid,
# count(distinct er.submit_time) as exam_cnt,
# count(distinct pr.submit_time) as question_cnt
select er.uid as uid,
count(distinct er.exam_id) as exam_cnt,
count(distinct pr.id) as question_cnt
3.2 每个6/7级用户活跃情况

我的错误代码:
总活跃月份数?其他都是2021年的,活跃是啥意思?
select er.uid,
# act_month_total,
count(er.start_time) act_days_2021,
count(er.submit_time) act_days_2021_exam,
count(pr.submit_time) act_days_2021_question
from exam_record er left join practice_record pr
on er.uid=pr.uid
where year(er.submit_time)=2021
and er.uid in
(select uid
from user_info
where level = 7 or level = 6)
group by er.uid正确代码
selectuser_info.uid,count(distinct act_month) as act_month_total,count(distinct casewhen year (act_time) = '2021' then act_dayend) as act_days_2021,count(distinct casewhen year (act_time) = '2021'and tag = 'exam' then act_dayend) as act_days_2021_exam,count(distinct casewhen year (act_time) = '2021'and tag = 'question' then act_dayend) as act_days_2021_question
from(SELECTuid,exam_id as ans_id,start_time as act_time,date_format (start_time, '%Y%m') as act_month,date_format (start_time, '%Y%m%d') as act_day,'exam' as tagfromexam_recordUNION ALLselectuid,question_id as ans_id,submit_time as act_time,date_format (submit_time, '%Y%m') as act_month,date_format (submit_time, '%Y%m%d') as act_day,'question' as tagfrompractice_record) totalright join user_info on total.uid = user_info.uid
whereuser_info.level in (6, 7)
group byuser_info.uid
order byact_month_total desc,act_days_2021 desc
复盘
(1)case when是关键
(2)2021年活跃天数 = 2021年试卷作答活跃天数 + 2021年答题活跃天数
则 exam as tag 和 practice as tag,自定义一列,为了区分是考试还是练习,便于区别计算
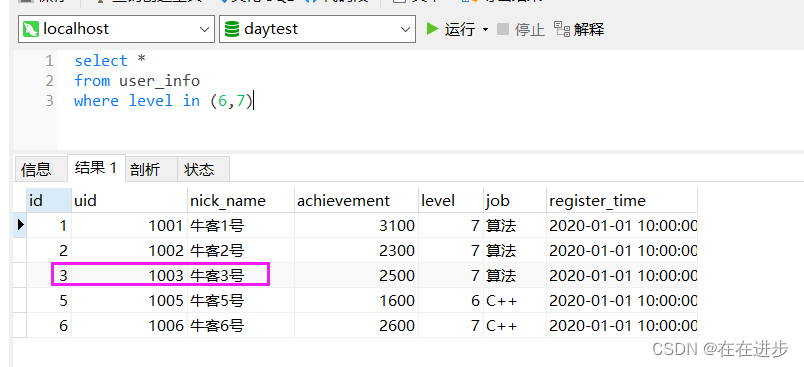
(3)右连接 total right join user_info on total.uid = user_info.uid
因为自组合的total表:没有1003

原本的user_info表:

但是6/7级的大佬中是有1003的
相关文章:
SQL进阶day10————多表查询
目录 1嵌套子查询 1.1月均完成试卷数不小于3的用户爱作答的类别 1.2月均完成试卷数不小于3的用户爱作答的类别 编辑1.3 作答试卷得分大于过80的人的用户等级分布 2合并查询 2.1每个题目和每份试卷被作答的人数和次数 2.2分别满足两个活动的人 3连接查询 3.1满足条件…...
debug调试_以Pycharm为例
文章目录 作用步骤打断点调试调试窗口 作用 主要是检查逻辑错误,而非语法错误。 步骤 打断点 在需要调试的代码行前打断点,执行后会停顿在断点位置(不运行) 调试 右键“debug”,或者直接点击右上角的小虫子 调试…...

wms第三方海外仓系统:如何为中小型海外仓注入新活力
对于中小型海外仓来说,想在大型集团海外仓同台竞争中获得优胜,提升其管理效率是非常关键的一环。 我们所熟知的wms系统,也就是第三方成熟海外仓系统,正是这些海外仓企业提升管理水平、降低成本的重要工具。 1、wms第三方海外仓系…...

html是什么?http是什么?
html Html是什么?http是什么? Html 超文本标记语言;负责网页的架构; http((HyperText Transfer Protocol)超文本传输协议; https(全称:Hypertext Transfer Protocol …...

L1-007 念数字js实现
异步解法 const readline require("readline"); const rl readline.createInterface({input: process.stdin,output: process.stdout, }); const input_arr [];//储存数据 rl.on(line, function (line) {input_arr.push(line); } ); rl.on(close, function () {/…...

Perl 运算符
Perl 运算符 Perl 是一种功能强大的编程语言,广泛应用于系统管理、网络编程、GUI 创建、数据库访问等众多领域。Perl 的语法灵活,支持多种编程范式,包括过程式、面向对象和函数式编程。在 Perl 中,运算符扮演着重要的角色&#x…...
语法04 C++ 标准输入语句
标准输入 使用格式:cin >> 输入的意思就是把一个值放到变量里面去,也就是变量的赋值,这个值是由我们自己输入的。 (注意:输入变量前要先定义,输入完之后要按Enter键。) 输入多个变量,与输出类似,…...

python数据分析--- ch6-7 python容器类型的数据及字符串
python数据分析---ch6-7 python容器类型的数据及字符串 1. Ch6--容器类型的数据1.1 序列1.1.1 序列的索引操作1.1.2 加和乘操作1.1.3 切片操作1.1.4 成员测试 1.2 列表1.2.1 创建列表1.2.2 追加元素1.2.3 插入元素1.2.4 替换元素1.2.5 删除元素1.2.6 列表排序(1&…...

【Linux取经路】守护进程
文章目录 一、前台进程和后台进程二、Linux 的进程间关系三、setsid——将当前进程设置为守护进程四、daemon——设置为守护进程五、结语 一、前台进程和后台进程 Linux 中每一次用户登录都是一个 session,一个 session 中只能有一个前台进程在运行,键盘…...

Nginx之文件下载服务器
1.概述 在对外分享文件时,利用Nginx搭建一个简单的下 载文件管理服务器,文件分享就会变得非常方便。利 用Nginx的诸多内置指令可实现自动生成下载文件列表 页、限制下载带宽等功能。配置样例如下: server {listen 8080;server_name localhos…...

OpenCV学习(4.11) OpenCV中的图像转换
1. 目标 在本节中,我们将学习 使用OpenCV查找图像的傅立叶变换利用Numpy中可用的FFT功能傅立叶变换的一些应用我们将看到以下函数:**cv.dft()** ,**cv.idft()** 等 理论 傅立叶变换用于分析各种滤波器的频率特性。对于图像,使用…...

2024.6.13每日一题
LeetCode 子序列最大优雅度 题目链接:2813. 子序列最大优雅度 - 力扣(LeetCode) 题目描述 给你一个长度为 n 的二维整数数组 items 和一个整数 k 。 items[i] [profiti, categoryi],其中 profiti 和 categoryi 分别表示第 i…...

Linux命令详解(2)
文本处理是Linux命令行的重要应用之一。通过一系列强大的命令,用户可以轻松地对文本文件进行编辑、查询和转换。 cat: 这个命令用于查看文件内容。它可以一次性显示整个文件,或者分页显示。此外,cat 还可以用于合并多个文件的内容…...

iOS ReactiveCocoa MVVM
学习了在MVVM中如何使用RactiveCocoa,简单的写上一个demo。重点在于如何在MVVM各层之间使用RAC的信号来更方便的在各个层之间进行响应式数据交互。 demo需求:一个登录界面(登录界面只有账号和密码都有输入,登录按钮才可以点击操作)࿰…...

图文解析ASN.1中BER编码:结构类型、编码方法、编码实例
本文将详细介绍ASN.1中的BER编码规则,包括其编码机制、数据类型表示、以及如何将复杂的数据结构转换为二进制数据。通过本文的阅读,读者将对ASN.1中的BER编码有一个全面的理解。 目录 一.引言 二.BER编码基本结构 ▐ 1. 类型域(Type&#…...

jQuery如何停止动画队列
在jQuery中,你可以使用.stop()方法来停止动画队列。.stop()方法有几个可选的参数,可以用来控制停止动画的方式。 以下是.stop()方法的基本用法和一些参数选项: 无参数:立即停止当前动画,并跳到最后的状态。后续的动画…...

vue3+electron搭建桌面软件
vue3electron开发桌面软件 最近有个小项目, 客户希望像打开 网易云音乐 那么简单的运行起来系统. 前端用 Vue 会比较快一些, 因此决定使用 electron 结合 Vue3 的方式来完成该项目. 然而, 在实施过程中发现没有完整的博客能够记录从创建到打包的流程, 摸索一番之后, 随即梳理…...

oracle常用经典SQL查询
oracle常用经典SQL查询(转贴) oracle常用经典SQL查询 常用SQL查询: 1、查看表空间的名称及大小 select t.tablespace_name, round(sum(bytes/(1024*1024)),0) ts_size from dba_tablespaces t, dba_data_files d where t.tablespace_name d.tablespace_name grou…...

Android shell 常用 debug 命令
目录 1、查看版本2、am 命令3、pm 命令4、dumpsys 命令5、sed命令6、log定位查看APK进程号7、log定位使用场景 1、查看版本 1.1、Android串口终端执行 getprop ro.build.version.release #获取Android版本 uname -a #查看linux内核版本信息 uname -r #单独查看内核版本 1.2、…...

Unity3D Shader数据传递语法详解
在Unity3D中,Shader是用于渲染图形的一种程序,它定义了物体在屏幕上的外观。Shader通过接收输入数据(如顶点位置、纹理坐标、光照信息等)并计算像素颜色来工作。为了使得Shader能够正确运行并产生期望的视觉效果,我们需…...

开源HR智能体:基于LLM与Agent架构的自动化HR流程实践
1. 项目概述:一个开源的HR智能体最近在关注AI如何真正落地到具体业务场景,而不是停留在概念演示。一个让我眼前一亮的项目是ArjunFrancis/openhr-agent。简单来说,这是一个开源的、基于大语言模型(LLM)的HR(…...

开源HR智能体openhr-agent:本地部署、模块化设计与核心应用场景解析
1. 项目概述:一个开源的HR智能体最近在GitHub上看到一个挺有意思的项目,叫openhr-agent。光看名字,你可能会觉得这又是一个“AI要取代HR”的噱头工具。但实际深入了解一下,我发现它的定位和设计思路,比想象中要务实和清…...

【仅限首批内测用户验证】:Midjourney v8“隐性美学协议”曝光——92%设计师尚未察觉的4类负向提示陷阱
更多请点击: https://intelliparadigm.com 第一章:Midjourney v8“隐性美学协议”的本质解构 Midjourney v8 并未公开发布传统意义上的“美学参数文档”,其核心创新在于将图像生成的审美判断内化为一套不可见但可触发的上下文响应机制——即…...

图片换背景底色怎么制作?2026年最全工具对比和实操指南
前几天,有个朋友问我怎样快速给证件照换个蓝色背景,我才意识到很多人其实不知道现在换背景底色有多简单。无论是证件照、商品图、还是自媒体头图,一键就能搞定。今天我就把自己用过的所有工具和方法整理出来,分享给大家。为什么越…...

DLSS Swapper完全指南:3步轻松优化游戏性能的终极方案
DLSS Swapper完全指南:3步轻松优化游戏性能的终极方案 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为游戏玩家设计的智能工具,能够自动管理、下载和替换游戏中的DLSS、F…...

5分钟快速上手!FanControl:你的Windows风扇智能管家终极指南
5分钟快速上手!FanControl:你的Windows风扇智能管家终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/G…...
)
跟着 MDN 学 HTML day_51:(深入理解 XPathEvaluator 接口)
在前端开发中,我们经常需要对 DOM 树进行复杂的节点查询。虽然 querySelector 和 querySelectorAll 已经能够满足大部分 CSS 选择器需求,但在某些场景下,我们需要更强大的查询能力,比如根据节点的文本内容查找、根据属性是否存在进…...
【AI大模型】Transformer 架构是什么?关键模块都有哪些
【AI大模型】Transformer 架构是什么?关键模块都有哪些? Transformer 出自 2017 年经典论文 Attention Is All You Need,它完全抛弃 RNN 结构,仅靠注意力 前馈网络实现序列建模,是现在 GPT、BERT、ViT、T5 等所有大模…...

LaTeX-PPT:3分钟掌握PowerPoint专业公式编辑的神器
LaTeX-PPT:3分钟掌握PowerPoint专业公式编辑的神器 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint中编辑复杂数学公式而头疼吗?LaTeX-PPT这款开源插件彻底改变了游…...
如何快速设置Translumo:面向初学者的完整实时屏幕翻译指南
如何快速设置Translumo:面向初学者的完整实时屏幕翻译指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是…...