从零开始使用 Elasticsearch(8.14.0)搭建全文搜索引擎
Elasticsearch 是目前最常用的全文搜索引擎。它可以快速地存储、搜索和分析海量数据,广泛应用于维基百科、Stack Overflow、Github 等网站。
Elasticsearch 的底层是开源库 Lucene。直接使用 Lucene 需要写大量代码,而 Elasticsearch 对其进行了封装,提供了 REST API,使其开箱即用。
本文将详细讲解如何使用最新版本的 Elasticsearch 8.14.0 搭建自己的全文搜索引擎。
一、安装
Elasticsearch 需要 Java 环境。首先,确保你的机器上安装了 Java。如果没有,请先安装 Java,并正确设置环境变量 JAVA_HOME。
1. 下载和安装 Elasticsearch
可以从 Elasticsearch 的官方网站下载最新版本的 Elasticsearch:
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.14.0-linux-x86_64.tar.gz
$ tar -xzf elasticsearch-8.14.0-linux-x86_64.tar.gz
$ cd elasticsearch-8.14.0/
2. 启动 Elasticsearch
进入解压后的目录,运行以下命令启动 Elasticsearch:
$ ./bin/elasticsearch
如果遇到错误 "max virtual memory areas vm.max_map_count [65530] is too low",请运行以下命令解决:
$ sudo sysctl -w vm.max_map_count=262144
正常启动后,Elasticsearch 会在默认的 9200 端口运行。打开另一个命令行窗口,请求该端口以验证安装:
$ curl -k --user elastic 'https://localhost:9200'
你应该会看到类似以下的 JSON 响应,包含节点、集群、版本等信息:
{"name" : "node-1","cluster_name" : "elasticsearch","cluster_uuid" : "tf9250XhQ6ee4h7YI11anA","version" : {"number" : "8.14.0","build_flavor" : "default","build_type" : "tar","build_hash" : "19c13d0","build_date" : "2024-01-18T20:44:24.823Z","build_snapshot" : false,"lucene_version" : "8.11.1","minimum_wire_compatibility_version" : "7.10.0","minimum_index_compatibility_version" : "7.0.0"},"tagline" : "You Know, for Search"
}
按下 Ctrl + C 可以停止 Elasticsearch。
如果需要远程访问 Elasticsearch,可以修改安装目录中的 config/elasticsearch.yml 文件,取消 network.host 的注释并将其值改为 0.0.0.0:
network.host: 0.0.0.0
重新启动 Elasticsearch 后,即可远程访问。但线上服务不要这样设置,要设成具体的 IP。
二、基本概念
2.1 Node 与 Cluster
Elasticsearch 是一个分布式数据库,允许多台服务器协同工作。每台服务器可以运行多个 Elasticsearch 实例,单个实例称为一个节点(node),一组节点构成一个集群(cluster)。
2.2 Index
Elasticsearch 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。数据管理的顶层单位是 Index(索引),类似于关系型数据库的数据库。每个 Index 的名字必须是小写。
查看当前节点的所有 Index:
$ curl -X GET 'http://localhost:9200/_cat/indices?v'
2.3 Document
Index 中的单条记录称为 Document(文档)。Document 使用 JSON 格式表示,例如:
{"user": "张三","title": "工程师","desc": "数据库管理"
}
同一个 Index 里的 Document 结构不要求完全一致,但最好保持相同,以提高搜索效率。
2.4 Type
Document 可以分组,这种分组称为 Type。Type 是逻辑分组,用来过滤 Document。不同的 Type 应该有相似的结构(schema)。Elasticsearch 6.x 版本后,每个 Index 只允许包含一个 Type,7.x 版本彻底移除 Type。
列出每个 Index 包含的 Type:
$ curl 'localhost:9200/_mapping?pretty=true'
三、新建和删除 Index
新建 Index:
$ curl -X PUT 'localhost:9200/weather'
服务器返回的 JSON 对象中,acknowledged 字段表示操作成功:
{"acknowledged": true,"shards_acknowledged": true
}
删除 Index:
$ curl -X DELETE 'localhost:9200/weather'
四、中文分词设置
安装中文分词插件(以 ik 为例):
$ ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.14.0/elasticsearch-analysis-ik-8.14.0.zip
重新启动 Elasticsearch 后,自动加载这个新安装的插件。
新建 Index 并指定需要分词的字段:
$ curl -X PUT 'localhost:9200/accounts' -H 'Content-Type: application/json' -d '
{"mappings": {"properties": {"user": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"},"title": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"},"desc": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"}}}
}'
上面代码中,新建一个名为 accounts 的 Index,其中有三个字段 user、title 和 desc 都需要使用中文分词器 ik_max_word。
五、数据操作
5.1 新增记录
向指定的 /Index/_doc 发送 PUT 请求,可以在 Index 中新增一条记录:
$ curl -X PUT 'localhost:9200/accounts/_doc/1' -H 'Content-Type: application/json' -d '
{"user": "张三","title": "工程师","desc": "数据库管理"
}'
服务器返回 JSON 对象,给出 Index、Id、Version 等信息:
{"_index": "accounts","_id": "1","_version": 1,"result": "created"
}
新增记录时,可以不指定 Id,这时要改为 POST 请求:
$ curl -X POST 'localhost:9200/accounts/_doc/' -H 'Content-Type: application/json' -d '
{"user": "李四","title": "工程师","desc": "系统管理"
}'
返回的 JSON 对象中,_id 字段为随机字符串:
{"_index": "accounts","_id": "AV3qGfrC6jMbsbXb6k1p","_version": 1,"result": "created"
}
5.2 查看记录
向 /Index/_doc/Id 发出 GET 请求查看记录:
$ curl 'localhost:9200/accounts/_doc/1?pretty=true'
返回的数据中,found 字段表示查询成功,_source 字段返回原始记录:
{"_index" : "accounts","_id" : "1","_version" : 1,"found" : true,"_source" : {"user" : "张三","title" : "工程师","desc" : "数据库管理"}
}
5.3 删除记录
删除记录:
$ curl -X DELETE 'localhost:9200/accounts/_doc/1'
5.4 更新记录
更新记录:
$ curl -X PUT 'localhost:9200/accounts/_doc/1' -H 'Content-Type: application/json' -d '
{"user": "张三","title": "工程师","desc": "数据库管理,软件开发"
}'
返回结果中,版本(version)和操作类型(result)字段发生变化:
{"_index": "accounts","_id": "1","_version": 2,"result": "updated"
}
六、数据查询
6.1 返回所有记录
使用 GET 方法,直接请求 /Index/_search 返回所有记录
:
$ curl 'localhost:9200/accounts/_search'
返回结果中,took 字段表示操作耗时,hits 字段表示命中的记录:
{"took": 2,"timed_out": false,"hits": {"total": {"value": 2,"relation": "eq"},"hits": [{"_index": "accounts","_id": "1","_source": {"user": "张三","title": "工程师","desc": "数据库管理"}},{"_index": "accounts","_id": "2","_source": {"user": "李四","title": "工程师","desc": "系统管理"}}]}
}
至此,你已经学会了如何使用 Elasticsearch 8.14.0 安装、配置和执行基本的增删查改操作。希望这篇文章能帮助你搭建起自己的全文搜索引擎。
相关文章:
搭建全文搜索引擎)
从零开始使用 Elasticsearch(8.14.0)搭建全文搜索引擎
Elasticsearch 是目前最常用的全文搜索引擎。它可以快速地存储、搜索和分析海量数据,广泛应用于维基百科、Stack Overflow、Github 等网站。 Elasticsearch 的底层是开源库 Lucene。直接使用 Lucene 需要写大量代码,而 Elasticsearch 对其进行了封装&am…...
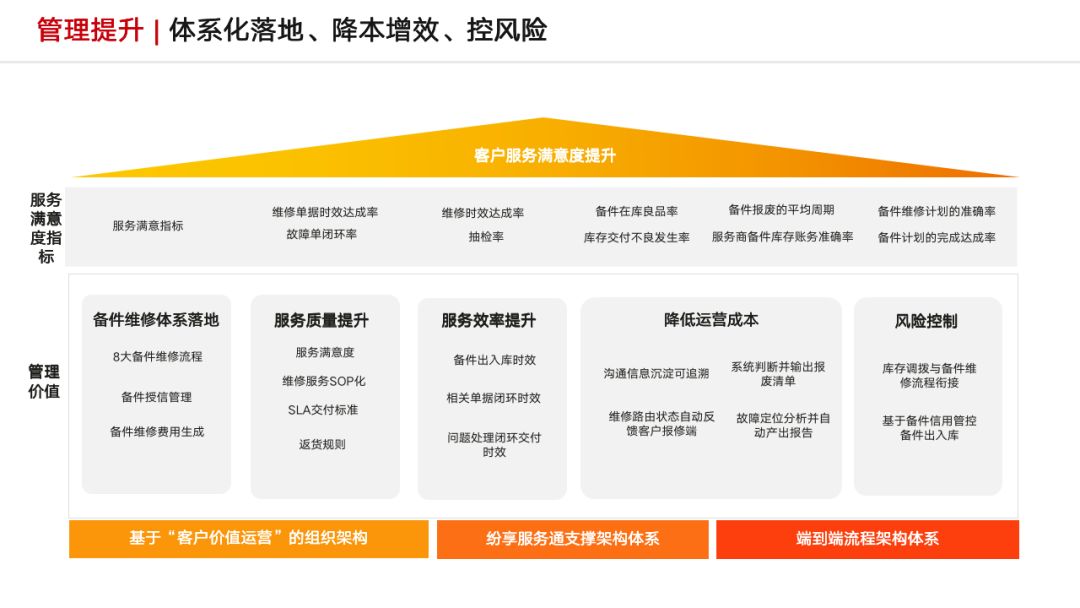
流程与IT双驱动:锐捷网络如何构建持续领先的服务竞争力?
AI大模型及相关应用进入“竞赛时代”,算力作为关键要素备受关注,由于算力行业对网络设备和性能有较大需求,其发展也在推动ICT解决方案提供商加速升级,提升服务响应速度和服务质量。 锐捷网络是行业领先的ICT基础设施及行业解决方…...

CopyOnWriteArrayList 详细讲解以及示范
CopyOnWriteArrayList是Java集合框架中的一种线程安全的列表实现,特别适用于读多写少的并发场景。 它是通过“写时复制”(Copy-On-Write)策略来保证线程安全的,这意味着当有线程尝试修改列表时,它会先复制原列表到一个…...
01-Java和Android环境配置
appium是做app自动化测试最火的一个框架,它的主要优势是支持android和ios,同时也支持Java和Python脚本语言。而学习appium最大的难处在于环境的安装配置,本文主要介绍Java和Android环境配置,在后续文章中将会介绍appium的安装和具…...
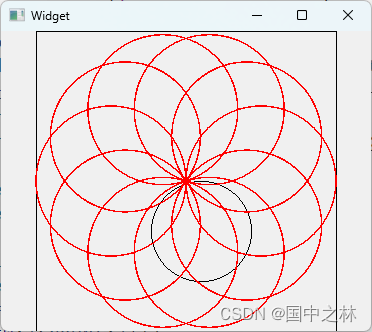
【qt】视口和窗口坐标
视口和窗口坐标 一.视口和窗口坐标的原理二.视口和窗口坐标的好处三.演示好处四.总结 一.视口和窗口坐标的原理 在绘图事件中进行绘图 void Widget::paintEvent(QPaintEvent *event) {QPainter painter(this);QRect rect(200,0,200,200);painter.drawRect(rect);//设置视口的…...

优化SQL查询的策略和技巧 - AI提供
优化SQL查询以提高处理大型数据集的数据库性能是一个重要课题。 以下是一些关键策略和技巧,可以帮助您提升查询效率: 1、创建合适索引: 针对频繁出现在WHERE、JOIN、ORDER BY和GROUP BY子句中的列创建索引。索引能够显著加速数据检索过程。…...

平安科技智能运维案例
平安科技智能运维案例 在信息技术迅速发展的背景下,平安科技面临着运维规模庞大、内容复杂和交付要求高等挑战。通过探索智能运维,平安科技建立了集中配置管理、完善的运营管理体系和全生命周期运维平台,实施了全链路监控,显著提…...

基于深度学习的向量图预测
基于深度学习的向量图预测 向量图预测(Vector Graphics Prediction)是计算机视觉和图形学中的一个新兴任务,旨在从像素图像(栅格图像)生成相应的向量图像。向量图像由几何图形(如线条、曲线、多边形等&…...
与$rawfile(““)的区别)
鸿蒙HarmonyOS $r(““)与$rawfile(““)的区别
在鸿蒙(HarmonyOS)开发中,$r(“”) 和 $rawfile(“”) 是两种不同的资源引用方式,它们分别用于引用不同的资源类型。 1、$r(“”) $r 函数通常用于引用字符串、颜色、尺寸、样式等定义在资源文件(如 strings.json, c…...

简单了解java中的Collection集合
集合 1、Collection-了解 1.1、集合概述 集合就是一种能够存储多个数据的容器,常见的容器有集合和数组 那么集合和数组有什么区别嘞? 1、集合长度可变,数组的长度不可变 2、集合只能存储引用数据类型(如果要存储基本数据类型…...
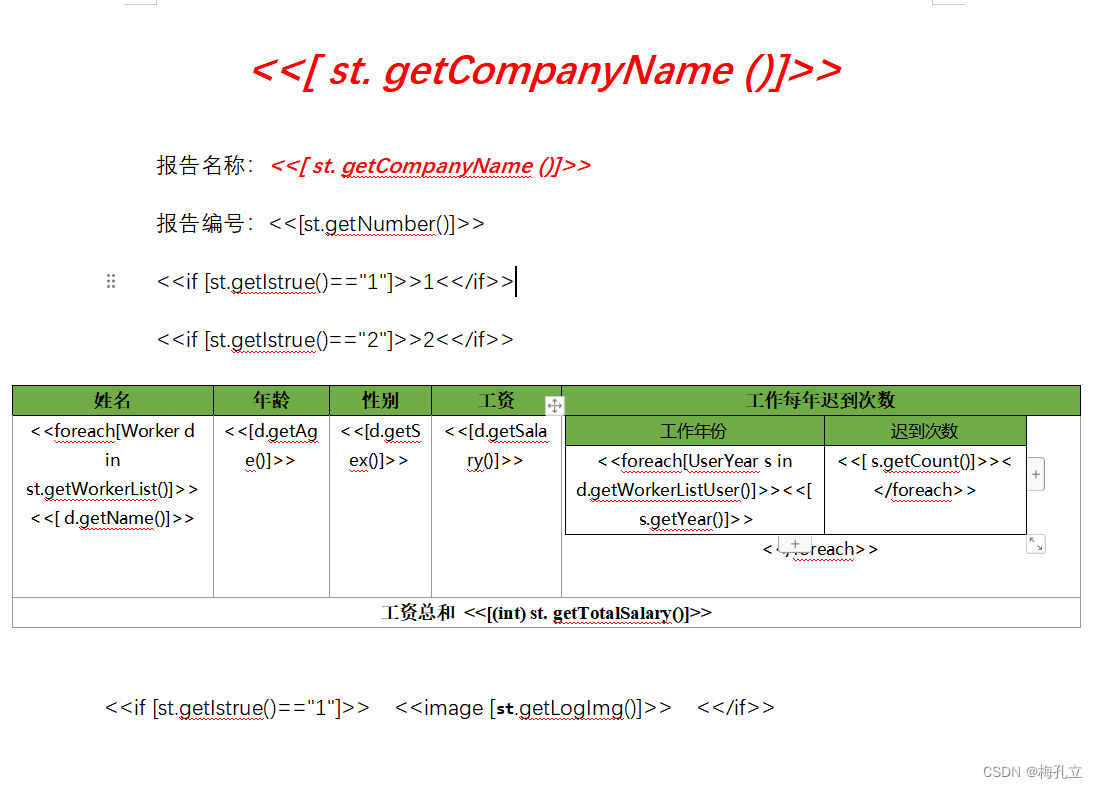
java 实现导出word 自定义word 使用aspose教程包含图片 for 循环 自定义参数等功能
java 实现导出word 主要有一下几个知识点 1,aspose导入 jar包 和 java编写基础代码下载使用 aspose-words jar包导入 aspose jar 包 使用 maven导入java代码编写 2,if判断 是否显示2,显示指定值3,循环显示List 集合列表 使用 fore…...
)
CSS动画(炫酷表单)
1.整体效果 https://mmbiz.qpic.cn/sz_mmbiz_gif/EGZdlrTDJa6yORMSqiaEKgpwibBgfcTQZNV0pI3M8t8HQm5XliaicSO42eBiboEUC3jxQOL1bRe0xlsd8bv04xXoKwg/640?wx_fmtgif&fromappmsg&wxfrom13 表单,也需要具有吸引力和实用性。HTML源码酷炫表单不仅能够提供给用户…...

Stream
Stream 也叫Stream流,是Jdk8开始新增的一套API (java.util.stream.*),可以用于操作集合或者数组的数据。 优势: Stream流大量的结合了Lambda的语法风格来编程,提供了一种更加强大,更加简单的方式操作集合或者数组中的…...

鸿蒙轻内核A核源码分析系列五 虚实映射(5)虚实映射解除
虚实映射解除函数LOS_ArchMmuUnmap解除进程空间虚拟地址区间与物理地址区间的映射关系,其中参数包含MMU结构体、解除映射的虚拟地址和解除映射的数量count,数量的单位是内存页数。 ⑴处函数OsGetPte1用于获取指定虚拟地址对应的L1页表项数据。⑵处计算需要解除的无效…...

编程初学者用什么软件电脑:全方位指南及深度解析
编程初学者用什么软件电脑:全方位指南及深度解析 在数字化浪潮席卷而来的今天,编程技能逐渐成为了一项必备的基本素养。对于初学者来说,选择一款合适的编程软件电脑至关重要。本文将从四个方面、五个方面、六个方面和七个方面,深…...

代理IP池功能组件
1.IP池管理器:用于管理IP池,包括IP地址的添加、删除、查询和更新等操作。 2.代理IP获取器:用于从外部资源中获取代理IP,例如从公开代理IP网站上爬取代理IP、从代理服务商订购代理IP等。 3.IP质量检测器:用于检测代理…...

Sqlite3入门和c/c++下使用
1. SQLite3基本介绍 1.1 数据库的数据类型 1.2 基本语法 1. 创建数据表格 create table 表名(字段名 数据类型, 字段名 数据类型); create table student(id int, name varchar(256), address text, QQ char(32)); 2. 插入数据 insert into 表名 valu…...
pyinstaller打包exe多种失败原因解决方法
pyinstaller打包exe多种失败原因解决方法 目录 pyinstaller打包exe多种失败原因解决方法1、pyinstaller安装有问题1.1 安装pyinstaller1.2 采用anconda的环境启动 2、pyqt5与pyside6冲突2.1 打包生成.spec文件2.2 编辑spec文件 3、打包成功后打不开exe,exe闪退3.1 s…...
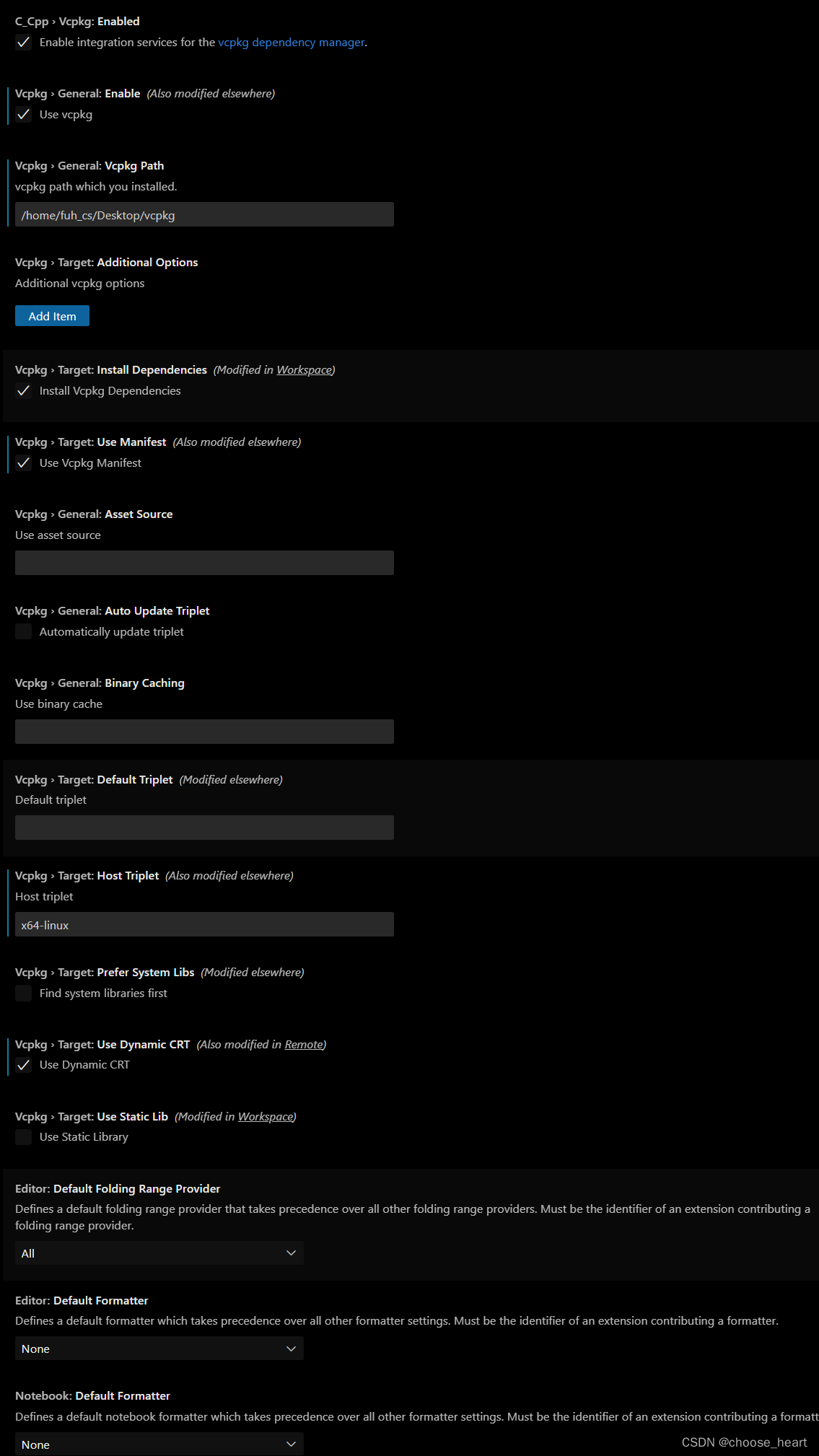
x64-linux下在vscode使用vcpkg
1.使用vscode远程连接上对应的linux ,或者直接在图形化界面上使用。 2.安装vcpkg 插件,然后打开插件设置。 注意:defalut和host的主机一定和你自己的主机一致,且必须符合vcpkg三元组格式,其中你可以选择工作台的设置&a…...
运营商二要素核验-手机号机主姓名核验接口-运营商二要素核验接口
通过电信运营商验证手机号码与姓名是否一致。广泛用于实名注册、风控审核等场景,如电商、游戏、直播、金融等需要用户实名认证的场景。支持携号转网核验。 更新周期:联通T1 电信T3 移动T3~5 均为工作日 接口地址: https://www.wapi.cn/api_de…...

C++ 条件变量 condition_variable
<condition_variable> 是 C 标准库中用于多线程同步的核心头文件。它主要提供了条件变量(Condition Variable)机制,用来协调多个线程的执行顺序。 简单来说,它的作用就是让一个或多个线程在特定条件不满足时进入休眠&#x…...

避坑指南:树莓派4B用FFmpeg推USB摄像头流,我踩过的那些编译和权限的坑
树莓派4B USB摄像头推流实战:从编译陷阱到系统服务的深度排雷手册 当你在树莓派4B上尝试用FFmpeg推送USB摄像头流时,是否遇到过这样的场景:按照教程一步步操作,却在编译阶段卡在OMX报错,或是明明设备识别成功却提示权…...


如何高效评估ChatGLM3对话系统:全面测试用户体验与任务成功率的实用指南
如何高效评估ChatGLM3对话系统:全面测试用户体验与任务成功率的实用指南 【免费下载链接】ChatGLM3 ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型 项目地址: https://gitcode.com/gh_mirrors/ch/ChatGLM3 ChatGLM3作为开源双语对话语言…...

颠覆性网络拓扑可视化:基于Vue+SVG的一站式轻量级解决方案
颠覆性网络拓扑可视化:基于VueSVG的一站式轻量级解决方案 【免费下载链接】easy-topo vuesvgelement-ui 快捷画出网络拓扑图 项目地址: https://gitcode.com/gh_mirrors/ea/easy-topo 在复杂的网络架构设计和运维管理中,网络工程师和开发人员经常…...

先进制程EPE挑战:从系统误差到量测革命,如何驯服边缘位置误差
1. 从“理所当然”到“如履薄冰”:边缘位置误差如何成为先进制程的“隐形杀手”在半导体行业过去的黄金岁月里,工程师们有一个近乎奢侈的“共识”:芯片内部那些由光刻、刻蚀定义的特征边缘,可以被理所当然地看作是笔直且在不同工艺…...

PS抠头发太费劲?几种简单方法轻松搞定
作为一名从事平面设计5年的老选手,抠头发绝对是PS修图中最让人头疼的环节——要么抠不干净留杂边,要么太用力丢失细碎发丝,尤其是面对杂色背景、飘逸长发、逆光发丝时,更是让人束手无策。今天就给大家分享3种超实用的PS抠头发丝方…...

3分钟搞定抖音无水印下载:从新手到高手的完整指南
3分钟搞定抖音无水印下载:从新手到高手的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

PyCharm专业版SSH远程开发环境一站式部署指南
1. PyCharm专业版安装与激活 作为数据科学和算法开发的主力工具,PyCharm专业版提供了完整的远程开发支持。首先需要从JetBrains官网下载对应操作系统的安装包。这里有个小技巧:如果你使用的是Windows系统但需要连接Linux服务器开发,建议选择W…...
原理与应用全解析)
时序电路的心脏:钟控触发器(RS/D/JK/T)原理与应用全解析
1. 时序电路的心脏:为什么需要钟控触发器? 第一次接触数字电路时,我被各种触发器绕得头晕。直到老师用"心脏"来比喻钟控触发器,才恍然大悟——就像心脏通过规律跳动为全身供血一样,钟控触发器通过时钟脉冲协…...