【Redis】Redis常见问题——缓存更新/内存淘汰机制/缓存一致性
目录
- 回顾
- 数据库的问题
- 如何提高 mysql 能承担的并发量?
- 缓存解决方案应对的场景
- 缓存更新
- 问题
- 定期生成
- 如何定期统计
- 定期生成的优缺点
- 实时生成
- maxmemory 设置成多少合适呢?
- 项目类型上来说
- 新的问题
- 内存淘汰策略
- Redis淘汰策略
- 为什么redis要内存淘汰
- 内存淘汰过程
- 缓存预热
- 原因
- 缓存和数据库数据同步问题
- 解决方案
- 缓存一致性解决方案
- 问题
- 解决方案
回顾
数据库的问题
- 数据库的访问操作速度相对来说比较慢,尤其是一旦短时间内有大量请求来临,就有可能使数据库压力过大,导致宕机。
- 这里通常指的是服务器每次处理一个请求,都要消耗一些硬件资源(cpu、内存、硬盘、网络…)
- 任何一种资源的消耗超出了机器提供的上限,就很容易出现故障了.
如何提高 mysql 能承担的并发量?
-
开源:引入更多的机器,构成数据库集群,例如 主从复制(即使主节点宕机,也可以通过提升从节点为主节点来解决)、分库分表…
-
节流:引入缓存,就是典型的方案. 把一些频繁的读取的热点数据保存到缓存上,后续再查询数据的时候,如果缓存已经存在了,就直接把从缓存上读到的数据返回,也就不在访问 mysql 了.
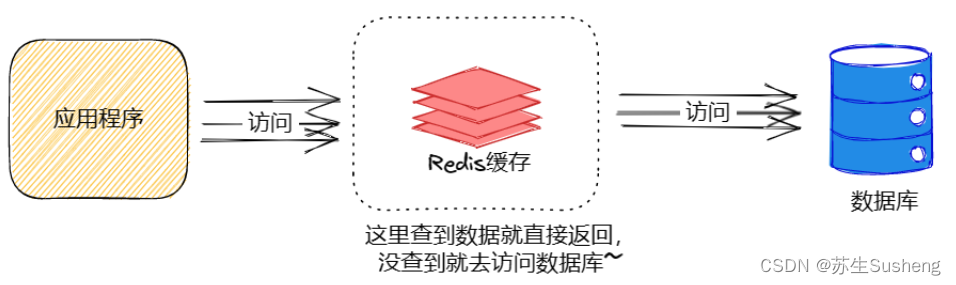
缓存解决方案应对的场景
- 即时性、数据一致性要求不高:引入缓存就会引入一致性问题,因为我们一般都会先去缓存上去读取数据,如果缓存上没有才去数据库中读. 这就导致一旦数据库中的数据发生变化,需要通过 异步/同步 的方式(具体要看业务要求强一致,还是最终一致)来更新缓存上是数据. 如果是异步更新缓存,就可能出现短暂的不一致现象.
- 访问量大,并且更新频率不高的数据(读多写少):更新频率高的数据为了保证数据一致性,会带来更大开销.
例如,电商系统中,商品分类,热门的商品等都适合缓存并设置一个过期时间(根据数据更新频率而定). 比如后台发布一个商品,买家需要 5 分钟才能看到一个商品一般还是可以接受的.
缓存更新
问题
在实际的工作中,如何知道 redis 中应该存储哪些数据?如何知道哪些数据是热点数据呢
定期生成
- 每隔⼀定的周期 (比如⼀天/⼀周/⼀个⽉) , 对于访问的数据频次进⾏统计,并以日志的形式记录下来,最后挑选出访问频次最⾼的前 N% 的数据,放到缓存中。例如搜索引擎:
- 搜索引擎的 “查询词” 就是要关注的 “访问的数据”,通过日志,把每天(也可以按一周、一月)都使用到了哪些词,给记录下来,就可以针对这些日志进行统计
- 这里的统计数据量非常大,需要写个程序来统计,数量大到可能需要使用分布式系统来存储日志 HDFS,统计这一天中,每个词出现的频率,再根据频率降序排序,提取出 前 20% 的词,就可以认为这些词是 “热点词” 。
- 接下来就可以把这些热点词,以及涉及到的搜索结构都提前拎出来,放到类似 “ redis” 这样的缓存中了。
如何定期统计
- 可以写一套离线流程(往往使用 shell,python 写脚本代码),然后通过 定时任务 来触发(一天更新一次、一个月更新一次等),具体如下:
- 完成统计热词的过程.
- 根据热词,找到搜索结果的数据.
- 把得到缓存数据同步到缓存服务器上.
- 控制这些缓存服务器自动重启.
定期生成的优缺点
-
优点:实现起来比较简单,过程可控(缓存中有什么东西,是比较固定的),方便排查问题.
-
缺点:实时性不够,如果出现一些突发性的事件,出现了一些新的热点词,新的热词就可能对数据库带来较大的压力(缓存中查询没有,直接打到数据库),例如,过年的前几天,“春节晚会” 这个词就会变的特别高频、或者是某个突发的新闻等
实时生成
- 先给缓存设定容量上限(可以通过 Redis 配置⽂件的 maxmemory 参数设定)。之后用户每次查询:
- 如果在 Redis 中查到了,就直接返回.
- 如果 Redis 中没有,就从数据库查询,在把查到的结果写入 Redis.
- 经过一段时间的 “动态平衡” ,redis 中的 key 就逐渐变成了热点数据。
- redis.conf中的maxmemory这个值表示对redis的内存使用,maxmemory为0的时候表示我们对Redis的内存使用没有限制。
maxmemory 设置成多少合适呢?
合适的maxmemory设置取决于你的具体场景和需求。以下是一些考虑因素:
-
系统内存容量:首先需要考虑系统的内存容量。maxmemory的值不能超过系统的可用内存,否则可能导致系统性能下降或崩溃。
-
数据规模:maxmemory的设置也要考虑数据规模。如果你的数据量很大,可以设置较大的maxmemory值,以便更多的数据可被缓存。但是如果数据量较小,设置过大的maxmemory可能会导致过度消耗系统资源。
-
缓存需求:根据你的缓存需求,确定需要缓存的数据量和存活时间。如果需要缓存大量的数据且存活时间较长,可能需要更大的maxmemory。如果只需缓存一小部分数据或数据存活时间较短,可以设置较小的maxmemory。
-
可扩展性:考虑到未来的数据增长,可以根据预估的增长率来设置较大的maxmemory,以便保证在未来一段时间内不会出现内存不足的情况。
项目类型上来说
- 小型项目:对于内存需求较小的小型项目,通常可以将maxmemory设置为较低的值,例如100MB到500MB。这样的设置可以满足基本的缓存和存储需求,同时不会消耗过多的系统资源。
- 中型项目:对于中型项目,可能需要处理更多的数据和请求,因此建议将maxmemory设置在500MB到2GB之间。这个范围可以提供足够的内存来支持更复杂的操作和数据存储。
- 大型项目:对于大型项目,可能需要处理大量的数据和高并发的请求。在这种情况下,建议将maxmemory设置在2GB以上,甚至可以达到数十GB或更多。这样可以确保Redis能够有足够的内存来处理大量的数据和请求。
另外,如果开启了Redis的快照功能(RDB或AOF),maxmemory的设置还需要考虑快照文件的大小和频率。为了确保系统的稳定性和性能,建议将maxmemory设置为物理内存的45%(如果开启了快照功能)或系统可用内存的95%(如果没有开启快照功能)
新的问题
redis中这样不停的写,那么redis 中的数据就会越来越多,达到 redis 配置的容量上限之后怎么办?——内存淘汰策略
内存淘汰策略
-
FIFO (First In First Out) :先进先出。把缓存中存在时间最久的 (也就是先来的数据) 淘汰掉.
-
LRU (Least Recently Used) :淘汰最久未使⽤的。记录每个 key 的最近访问时间. 把最近访问时间最⽼的 key 淘汰掉.
-
LFU (Least Frequently Used) :淘汰访问次数最少的。记录每个 key 最近⼀段时间的访问次数. 把访问次数最少的淘汰掉
-
Random 随机淘汰:从所有的 key 中抽取幸运儿被随机淘汰掉
Redis淘汰策略
| 策略 | 说明 |
|---|---|
| volatile-ttl | 相当于 FIFO, 只不过是局限于过期的 key,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰. |
| volatile-lru | 就是 LRU,只不过局限于过期的 key ,当内存不足以容纳新写⼊数据时,从设置了过期时间的key中使⽤LRU(最近最少使用)算法进行淘汰. |
| allkeys-lru | 就是 LRU,针对所有 key ,当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LRU(最近最少使用)算法进行淘汰 |
| volatile-lfu | 就是 LFU,只不过局限于过期的 key, 4.0版本新增,当内存不⾜以容纳新写⼊数据时,在过期的key中,使⽤LFU算法 进行删除key. |
| allkeys-lfu | 就是 LFU,针对所有 key, 4.0版本新增,当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LFU算法进行淘汰. |
| volatile-random | 当内存不⾜以容纳新写⼊数据时,从设置了过期时间的key中,随机淘汰数据. |
| allkeys-random | 当内存不⾜以容纳新写⼊数据时,从所有key中随机淘汰数据. |
| noeviction | 默认策略,当内存不⾜以容纳新写⼊数据时,新写⼊操作会报错. |
为什么redis要内存淘汰
Redis需要缓存更新或内存淘汰的原因如下:
-
提高读取性能:Redis将数据存储在内存中,读取速度非常快。通过缓存更新,Redis可以将经常访问的数据保存在内存中,减少读取数据库的次数,从而提高读取性能。
-
减少数据库负载:缓存更新可以减轻数据库的读写压力。当缓存中存在请求的数据时,Redis可以直接从内存中读取,而不需要访问数据库。这样可以减少数据库的读取请求,减轻数据库的负载。
-
解决高并发问题:缓存更新可以有效解决高并发访问数据库的问题。当多个用户同时访问数据库时,通过缓存更新,可以减少对数据库的访问,提高系统的并发性能。
-
空间限制:Redis将数据存储在内存中,而内存是有限的资源。当数据量超过Redis的内存限制时,需要进行内存淘汰操作,即删除一部分数据,以腾出空间存储新的数据。
-
数据过期:Redis中的数据可以设置过期时间,当数据过期时,需要进行内存淘汰操作,将过期的数据从内存中删除,以释放空间。
一句话总结:内存的淘汰机制的初衷是为了更好地使用内存,用一定的缓存miss来换取内存的使用效率。
内存淘汰过程
- 客户端发起了需要申请更多内存的命令(如set)。
- Redis检查内存使用情况,如果已使用的内存大于maxmemory则开始根据用户配置的不同淘汰策略来淘汰内存(key),从而换取一定的内存。
- 如果上面都没问题,则这个命令执行成功。
缓存预热
- 缓存预热是指在系统正式启动运行之前,提前将需要频繁使用的数据加载到缓存中的过程。
- 在系统启动后,缓存中已经有了预先加载的数据,可以提高系统的响应速度和性能。
原因
- 使用缓存预热的主要目的是减少系统的响应时间。
- 当系统启动后,如果没有进行缓存预热,那么用户首次访问某个数据时,系统需要从数据库或其他数据源中获取数据,并将其放入缓存中。
- 这个过程需要时间,因此会导致用户在首次访问时面临较长的等待时间。
- 而通过缓存预热,系统可以在启动之前将热门数据提前加载到缓存中,当用户首次访问时,可以直接从缓存中获取数据,避免了从数据源中获取数据的开销,从而提高了系统的响应速度。
- 此外,缓存预热还可以减轻数据库的压力。通过将热门数据提前加载到缓存中,系统可以减少对数据库的频繁查询,从而减轻数据库的负载,提高系统的稳定性和可靠性。
缓存和数据库数据同步问题
- 引入缓存就会引入和数据库中数据的一致性问题。
- 由于缓存的读写速度远高于数据库,所以在数据库中的数据更新后,缓存中的数据可能会出现不一致的情况
- 例如缓存和数据库中都保存了商品信息,但是数据库中的商品数据被修改了,那么缓存上的数据也应该被更新,否则就会导致用户下次访问的时候还是读取的缓存上的旧数据
解决方案
-
主动更新:在数据库中进行数据更新的同时,主动更新缓存中对应的数据。这可以通过在数据更新操作后,直接调用缓存系统的接口,将数据更新到缓存中。这种方式可以保证数据一致性,但也会增加数据库操作的时间。
-
超时失效:在数据更新之后,可以设置缓存的失效时间,在缓存失效之后,再从数据库中获取最新的数据存入缓存。这样可以避免频繁的数据更新操作,但是会增加读取时的查询延迟。
-
读写穿透处理:在读取缓存数据之前,先查询缓存中是否存在,如果不存在则查询数据库并将数据存入缓存。这样可以避免缓存中的脏数据,但是会增加一定的数据库查询操作。
-
双写策略:在数据更新的同时,先更新数据库,然后异步或延迟更新缓存,以减少对数据库操作的影响。这种方式可以提高系统的性能,但是会带来一定的数据不一致风险。
-
基于事件的缓存更新:通过使用发布订阅模式,当数据库中的数据发生变化时,发布一个事件通知,缓存作为订阅者接收到通知后进行相应的数据更新操作。这种方式可以保证缓存和数据库的数据同步,但是需要引入事件机制和相应的消息队列等组件。
在选择缓存和数据库的同步方案时,需要根据业务需求和系统性能要求进行权衡。每种方案都有其优缺点,需要根据具体场景来选择最合适的解决方案。
缓存一致性解决方案
- 缓存一致性是指缓存中的数据与数据源中的数据保持一致。
- 在使用缓存的系统中,由于系统的高并发和分布式特性,可能会导致缓存中的数据与数据源中的数据存在不一致的情况
问题
对于缓存数据库数据同步问题,无论是双写模式还是失效模式,都可能存在多个实例并发读写导致缓存不一致的问题
- 双写模式:例如有 实例A 和 实例B 同时对同一数据进行双写操作(数据库 + 缓存),但是由于 实例A 在写数据库的时候花费的时间比较长,而此时 实例B 已经双写完成,之后 实例A 才去更新 缓存. 此时,就相当于 实例B 之前写的数据无效.
- 失效模式:例如有 实例A 对数据进行失效模式,但是在写数据库的时候花费的时间比较长,还没来得及删除缓存,此时有一个 实例B 对同一数据进行读取,发现缓存上有,就把这个 实例A 即将要删除的缓存数据读到了
解决方案
-
读写穿透:在查询缓存之前,先查询数据源,如果数据源中不存在该数据,则将该空数据放入缓存,避免了缓存中的“空数据”。这种方法可以减轻缓存雪崩的风险。
-
更新缓存策略:在数据源中进行数据更新时,即时更新缓存中的数据。可以通过以下几种方式实现更新缓存的策略:
-
Cache-Aside模式:在查询数据时,先从缓存中获取数据,如果缓存中不存在,则从数据源中获取数据,并将数据存入缓存。在更新数据时,先更新数据源,再删除缓存中的旧数据,下次查询时会重新加载最新的数据存入缓存。
-
Write-Through模式:在更新数据时,先更新数据源,再更新缓存中的数据,保持数据源和缓存的一致性。
-
Write-Back模式:在更新数据时,先更新缓存中的数据,然后异步更新数据源中的数据,可以提高写操作的性能。
-
-
缓存失效策略:设置合适的缓存失效时间,确保缓存中的数据与数据源中的数据保持一致。可以根据业务需求和数据更新频率来设置缓存的失效时间,避免数据的过期问题。
-
缓存更新通知:当数据源中的数据更新时,主动通知缓存进行数据更新。可以使用发布订阅模式,当数据发生变更时,发送通知给订阅者,缓存作为订阅者接收到通知后进行数据更新。
-
分布式锁:在进行缓存更新时,使用分布式锁来保证只有一个线程可以更新缓存。通过使用分布式锁,可以避免多个线程同时更新缓存导致的并发问题,保证缓存的一致性。
相关文章:
【Redis】Redis常见问题——缓存更新/内存淘汰机制/缓存一致性
目录 回顾数据库的问题如何提高 mysql 能承担的并发量?缓存解决方案应对的场景 缓存更新问题定期生成如何定期统计定期生成的优缺点 实时生成maxmemory 设置成多少合适呢?项目类型上来说 新的问题 内存淘汰策略Redis淘汰策略为什么redis要内存淘汰内存淘…...
【redis】redis事务
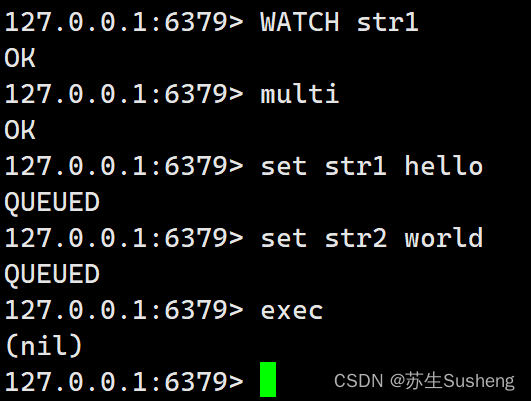
目录 Redis事务四个命令redis事务特性redis事务执行原理 Redis 事务的使用基本使用watch 监控watch 实现原理补充 Redis事务 Redis事务是一种将多个命令打包成一个单独操作的机制,它保证了在执行这些命令期间,其他命令无法插入。 四个命令 Redis事务通…...

编程入门费用:揭开学习成本的神秘面纱
编程入门费用:揭开学习成本的神秘面纱 编程,这一曾被视为专业领域的技能,如今已逐渐走入大众视野。越来越多的人开始尝试学习编程,然而,对于初学者来说,编程入门费用无疑是一个重要的考虑因素。那么&#…...

js/javascript获取时间戳的5种方法
1.获取时间戳精确到秒,13位 const timestamp Date.parse(new Date()); console.log(timestamp);//输出 1591669256000 13位 2.获取时间戳精确到毫秒,13位 const timestamp Math.round(new Date()); console.log(timestamp);//输出 1591669961203 13位 3.获取时间戳精…...

window系统下为django自动绘制模型类关系图
Django 提供第三方包 django-extensions,可以用来将 Django 中的 Models 生成 E-R 图。 1 安装包 pip install django-extensions 2 配置 在 Django settings.py 文件, INSTALLED_APPS 中添加 django_extensions INSTALLED_APPS (django_extension…...

Redis的数据淘汰策略和集群部署
05- Redis的数据淘汰策略有哪些 ? Redis 提供 8 种数据淘汰策略: 淘汰易失数据(具有过期时间的数据) volatile-lru(least recently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少…...
解决CentOS 7无法识别ntfs的问题
解决CentOS 7无法识别ntfs的问题 方式一: Centos默认不支持ntfs文件格式,直接在Centos7上插U盘或移动硬盘无法识别,安装 ntfs-3g即可: # yum install epel-release -y # yum install ntfs-3g -y[rootbogon ~]# rpm -qa | grep nt…...
排名前五的 Android 数据恢复软件
正在寻找数据恢复软件来从 Android 设备恢复数据?本指南将为您提供 5 款最佳 Android 数据恢复软件。浏览这些软件,然后选择您喜欢的一款来恢复 Android 数据。 ndroid 设备上的数据丢失可能是一种令人沮丧的经历,无论是由于意外删除、系统崩…...

Java 程序结构 -- Java 语言的变量、方法、运算符与注释
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 003 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...

淘宝/天猫商品详情优惠券获取API 接口
天猫商品优惠券数据API接口是一种用于获取天猫商品优惠券信息的接口。通过该接口,商家或开发者可以获取到商品的优惠券信息,包括优惠券的名称、金额、使用条件等。 该接口的主要参数包括商品ID、优惠券ID等,通过传入这些参数,可以…...
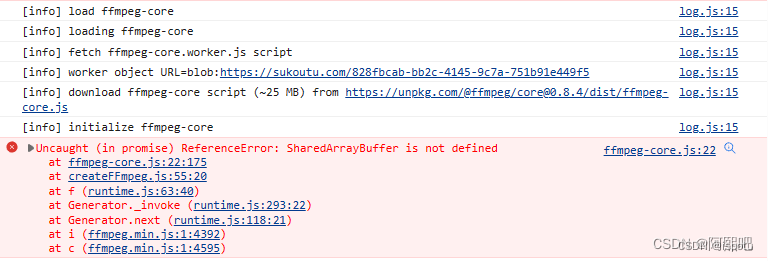
Vue前端ffmpeg压缩视频再上传(全网唯一公开真正实现)
1.Vue项目中安装插件ffmpeg 1.1 插件版本依赖配置 两个插件的版本 "ffmpeg/core": "^0.10.0", "ffmpeg/ffmpeg": "^0.10.1"package.json 和 package-lock.json 都加入如下ffmpeg的版本配置: 1.2 把ffmpeg安装到项目依…...

样式的双向绑定的2种方式,实现样式交互效果
与样式标签实现双向绑定 通过布尔值来决定样式是出现还是消失 show代表着布尔值,show的初始值是false所以文本不会有高亮的效果,当用户点击了按钮,就会调用shows这个函数,并将show的相反值true赋值并覆盖给show,此时show的值为tru…...

供应链经理面试题
供应链经理面试题通常会涉及对供应链管理的基本理解、工作经验、解决问题的能力以及团队协作等多个方面。 请简要介绍一下你在供应链管理领域的工作经验和取得的成绩。你如何定义供应链管理?它在企业中的作用是什么?你认为供应链经理最重要的职责是什么…...

快速理解 Node.js 版本差异:3 分钟指南
Node.js 是一个广泛使用的 JavaScript 运行时环境,允许开发者在服务器端运行 JavaScript 代码。随着技术的发展,Node.js 不断推出新版本,引入新特性和改进。了解不同版本之间的差异对于开发者来说至关重要。以下是一个快速指南,帮…...

【Qt实现录频】
在Qt中实现录制视频可以通过使用Qt Multimedia模块来实现。你可以使用QCamera类来访问摄像头并捕获视频数据。以下是一个简单的示例代码,用于在Qt中实现录制视频: #include <QCamera> #include <QCameraInfo> #include <QCameraViewfinder> #include <…...

Golang编译导致的代码错觉
文章目录 背景分析代码疑问 直接上汇编gdb调试优化后的汇编staticunit64s查看禁止优化后的汇编 查看编译过程的SSA生成SSAb对应的SSAc对应的SSAgo官方文档的解释 对比C语言的表现总结 背景 网上看到一段代码,来源是Golang 编译器优化那些事,百思不得其解…...

SpringBoot整合H2数据库并将其打包成jar包、转换成exe文件
SpringBoot整合H2数据库并将其打包成jar包、转换成exe文件 H2 是一个用 Java 开发的嵌入式数据库,它的主要特性使其成为嵌入式应用程序的理想选择。H2 仅是一个类库,可以直接嵌入到应用项目中,而无需独立安装客户端和服务器端。 常用开源数…...

web前端文本大小:从入门到精通的全方位解析
web前端文本大小:从入门到精通的全方位解析 在web前端开发的世界中,文本大小的处理既是基础也是关键的一环。无论是对于初学者还是资深开发者,正确且有效地处理文本大小都显得尤为重要。本文将从四个方面、五个方面、六个方面和七个方面&…...
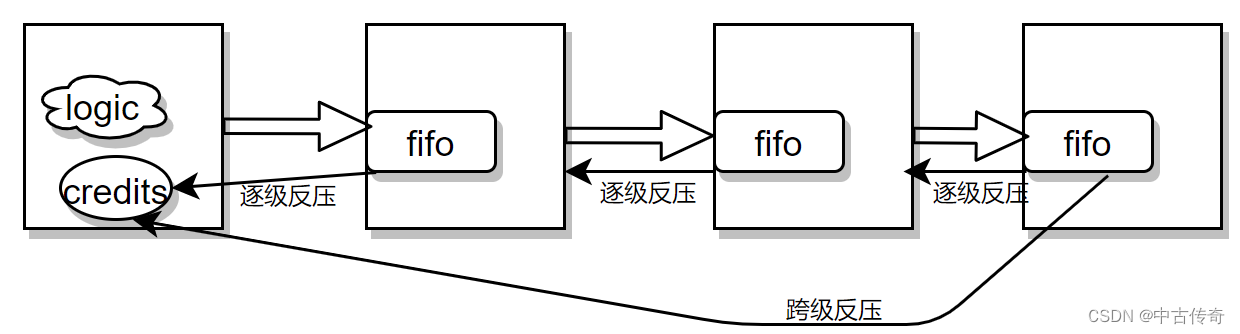
【报文数据流中的反压处理】
报文数据流中的反压处理 1 带存储体的反压1.1 原理图1.2 Demo 尤其是在NP芯片中,经常涉及到报文的数据流处理;为了防止数据丢失,和各模块的流水处理;因此需要到反压机制; 反压机制目前接触到的有两种:一是基…...
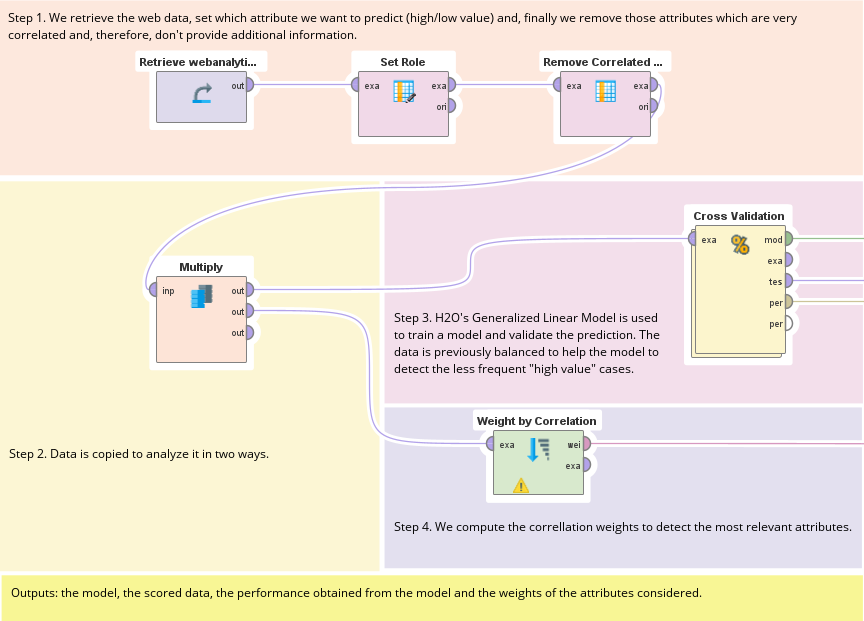
数据挖掘丨轻松应用RapidMiner机器学习内置数据分析案例模板详解(下篇)
RapidMiner 案例模板 RapidMiner 机器学习平台提供了一个可视化的操作界面,允许用户通过拖放的方式构建数据分析流程。RapidMiner目前内置了 13 种案例模板,这些模板是预定义的数据分析流程,可以帮助用户快速启动和执行常见的数据分析任务。 …...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...