kafka 快速上手
下载 Apache Kafka
演示window 安装
编写启动脚本,脚本的路径根据自己实际的来

启动说明
先启动zookeeper后启动kafka,关闭是先关kafka,然后关闭zookeeper
巧记: 铲屎官(zookeeper)总是第一个到,最后一个走
启动zookeeper
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties
启动kafka
call bin/windows/kafka-server-start.bat config/server.properties
测试脚本,主要用于创建主题 ‘test-topic’
# 创建主题(窗口1)
bin/window> kafka-topics.bat --bootstrap-server localhost:9092 --topic test-topic --create# 查看主题
bin/window> kafka-topics.bat --bootstrap-server localhost:9092 --list
bin/window> kafka-topics.bat --bootstrap-server localhost:9092 --topic test-topic --describe# 修改某主题的分区
bin/window> kafka-topics.bat --bootstrap-server localhost:9092 --topic test-topic --alter --partitions 2# 生产消息(窗口2)向test-topic主题发送消息
bin/window> kafka-console-producer.bat --bootstrap-server localhost:9092 --topic test-topic
>hello kafka# 消费消息(窗口3)消费test-topic主题的消息
bin/window> kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test-topicpackage com.ldj.kafka.admin;import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.CreateTopicsResult;
import org.apache.kafka.clients.admin.NewTopic;import java.util.*;/*** User: ldj* Date: 2024/6/13* Time: 0:00* Description: 创建主题*/
public class AdminTopic {public static void main(String[] args) {Map<String, Object> adminConfigMap = new HashMap<>();adminConfigMap.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");AdminClient adminClient = AdminClient.create(adminConfigMap);/*** 使用kafka默认的分区算法创建分区*/NewTopic topic1 = new NewTopic("topic-01", 1, (short) 1);NewTopic topic2 = new NewTopic("topic-02", 2, (short) 2);CreateTopicsResult addResult1 = adminClient.createTopics(Arrays.asList(topic1, topic2));/*** 手动为主题(topic-03)分配分区* topic-03主题下的0号分区有2个副本,它们中的一个在节点id=1中,一个在节点id=2中;* list里第一个副本就是leader(主写),后面都是follower(主备份)* 例如:0分区,nodeId=1的节点里的副本是主写、2分区,nodeId=3的节点里的副本是主写*/Map<Integer, List<Integer>> partition = new HashMap<>();partition.put(0, Arrays.asList(1, 2));partition.put(1, Arrays.asList(2, 3));partition.put(2, Arrays.asList(3, 1));NewTopic topic3 = new NewTopic("topic-03", partition);CreateTopicsResult addResult2 = adminClient.createTopics(Collections.singletonList(topic3));//DeleteTopicsResult delResult = adminClient.deleteTopics(Arrays.asList("topic-02"));adminClient.close();}}
package com.ldj.kafka.producer;import com.alibaba.fastjson.JSON;
import com.ldj.kafka.model.UserEntity;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
import java.util.concurrent.Future;/*** User: ldj* Date: 2024/6/12* Time: 21:08* Description: 生产者*/
public class KfkProducer {public static void main(String[] args) throws Exception {//生产者配置Map<String, Object> producerConfigMap = new HashMap<>();producerConfigMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");producerConfigMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);producerConfigMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);//批量发送producerConfigMap.put(ProducerConfig.BATCH_SIZE_CONFIG, 2);//消息传输应答安全级别 0-消息到达broker(效率高,但不安全) 1-消息在leader副本持久化(折中方案) -1/all -消息在leader和flower副本都持久化(安全,但效率低)producerConfigMap.put(ProducerConfig.ACKS_CONFIG, "all");//ProducerState 缓存5条数据,重试数据会与5条数据做比较,结论只能保证一个分区的数据幂等性,跨会话幂等性需要通过事务操作解决(重启后全局消息id的随机id会发生改变)//消息发送失败重试次数,重试会导致消息重复!!(考虑幂等性),消息乱序(判断偏移量是否连续,错乱消息回到在缓冲区重新排序)!!producerConfigMap.put(ProducerConfig.RETRIES_CONFIG, 3);//kafka有消息幂等性处理(全局唯一消息id/随机id-分区-偏移量),默认false-不开启producerConfigMap.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);//解决跨会话幂等性,还需结合事务操作,忽略//producerConfigMap.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "tx_id");//创建生产者KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfigMap);//TODO 事务初始化方法//producer.initTransactions();//构建消息 ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers)try {//TODO 开启事务//producer.beginTransaction();for (int i = 0; i < 10; i++) {UserEntity userEntity = new UserEntity().setUserId(2436687942335620L + i).setUsername("lisi").setGender(1).setAge(18);ProducerRecord<String, String> record = new ProducerRecord<>("test-topic",userEntity.getUserId().toString(),JSON.toJSONString(userEntity));//发送数据到BrokerFuture<RecordMetadata> future = producer.send(record, (RecordMetadata var1, Exception var2) -> {if (Objects.isNull(var2)) {System.out.printf("[%s]消息发送成功!", userEntity.getUserId());} else {System.out.printf("[%s]消息发送失败!err:%s", userEntity.getUserId(), var2.getCause());}});//TODO 提交事务//producer.commitTransaction();//注意没有下面这行代码,是异步线程从缓冲区读取数据异步发送消息,反之是同步发送,必须等待回调消息返回才会往下执行System.out.printf("发送消息[%s]----", userEntity.getUserId());RecordMetadata recordMetadata = future.get();System.out.println(recordMetadata.offset());}} finally {//TODO 终止事务//producer.abortTransaction();//关闭通道producer.close();}}}
package com.ldj.kafka.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;/*** User: ldj* Date: 2024/6/12* Time: 21:10* Description: 消费者*/
public class KfkConsumer {public static void main(String[] args) {//消费者配置Map<String, Object> consumerConfigMap = new HashMap<>();consumerConfigMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");consumerConfigMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);consumerConfigMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);//所属消费组consumerConfigMap.put(ConsumerConfig.GROUP_ID_CONFIG, "test123456");//创建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerConfigMap);//消费主题的消息 ConsumerRebalanceListenerconsumer.subscribe(Collections.singletonList("test-topic"));try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5));//数据存储结构:Map<TopicPartition, List<ConsumerRecord<K, V>>> records;for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());}}} finally {//关闭消费者consumer.close();}}}
相关文章:
kafka 快速上手
下载 Apache Kafka 演示window 安装 编写启动脚本,脚本的路径根据自己实际的来 启动说明 先启动zookeeper后启动kafka,关闭是先关kafka,然后关闭zookeeper 巧记: 铲屎官(zookeeper)总是第一个到,最后一个走 启动zookeeper call bi…...

Python记忆组合透明度语言模型
🎯要点 🎯浏览器语言推理识别神经网络 | 🎯不同语言秽语训练识别数据集 | 🎯交互式语言处理解释 Transformer 语言模型 | 🎯可视化Transformer 语言模型 | 🎯语言模型生成优质歌词 | 🎯模型不确…...
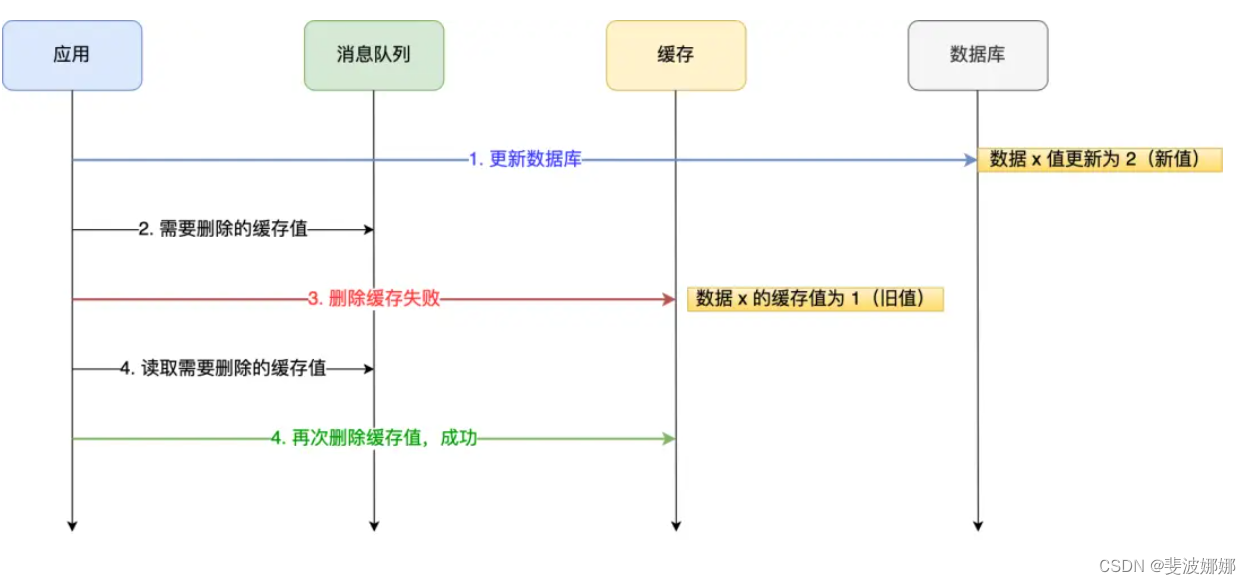
如何保证数据库和缓存的一致性
背景:为了提高查询效率,一般会用redis作为缓存。客户端查询数据时,如果能直接命中缓存,就不用再去查数据库,从而减轻数据库的压力,而且redis是基于内存的数据库,读取速度比数据库要快很多。 更新…...

Java基础 - 多线程
多线程 创建新线程 实例化一个Thread实例,然后调用它的start()方法 Thread t new Thread(); t.start(); // 启动新线程从Thread派生一个自定义类,然后覆写run()方法: public class Main {public static void main(String[] args) {Threa…...

云顶之弈-测试报告
一. 项目背景 个人博客系统采用前后端分离的方法来实现,同时使用了数据库来存储相关的数据,同时将其部署到云服务器上。前端主要有四个页面构成:登录页、列表页、详情页以及编辑页,以上模拟实现了最简单的个人博客系统。其结合后…...
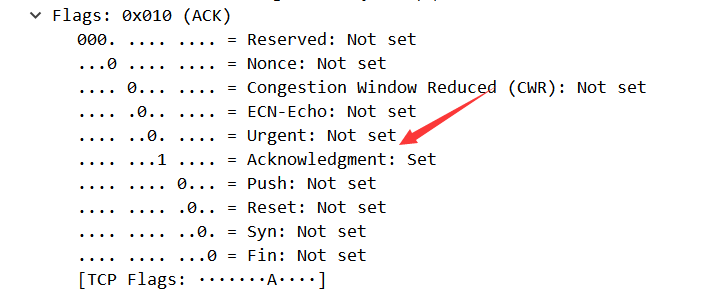
TCP/IP协议分析实验:通过一次下载任务抓包分析
TCP/IP协议分析 一、实验简介 本实验主要讲解TCP/IP协议的应用,通过一次下载任务,抓取TCP/IP数据报文,对TCP连接和断开的过程进行分析,查看TCP“三次握手”和“四次挥手”的数据报文,并对其进行简单的分析。 二、实…...
)
Python项目开发实战:企业QQ小程序(案例教程)
一、引言 在当今数字化快速发展的时代,企业对于线上服务的需求日益增长。企业QQ小程序作为一种轻量级的应用形态,因其无需下载安装、即开即用、占用内存少等优势,受到了越来越多企业的青睐。本文将以Python语言为基础,探讨如何开发一款企业QQ小程序,以满足企业的实际需求。…...

list模拟与实现(附源码)
文章目录 声明list的简单介绍list的简单使用list中sort效率测试list的简单模拟封装迭代器insert模拟erase模拟头插、尾插、头删、尾删模拟自定义类型迭代器遍历const迭代器clear和析构函数拷贝构造(传统写法)拷贝构造(现代写法) 源…...

Java应用中文件上传安全性分析与安全实践
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 目录 引言 一. 文件上传的风险 二. 使用合适的框架和库 1. Spr…...
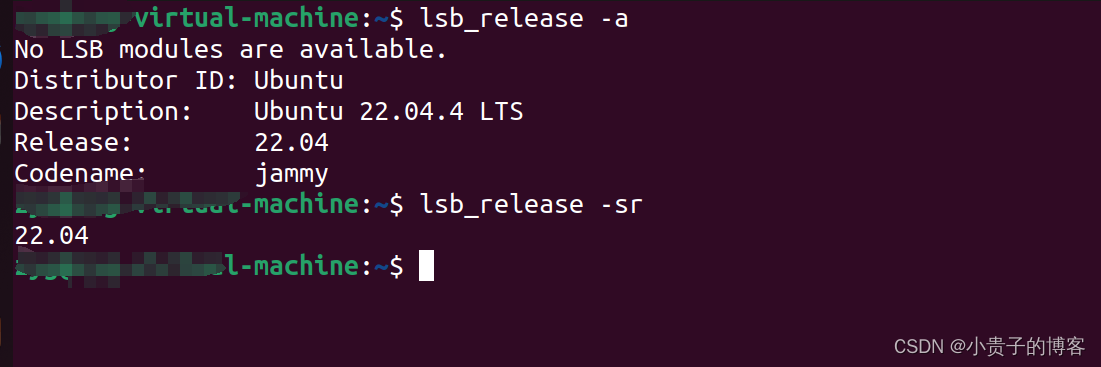
noVNC 小记
1. 怎么查看Ubuntu版本...
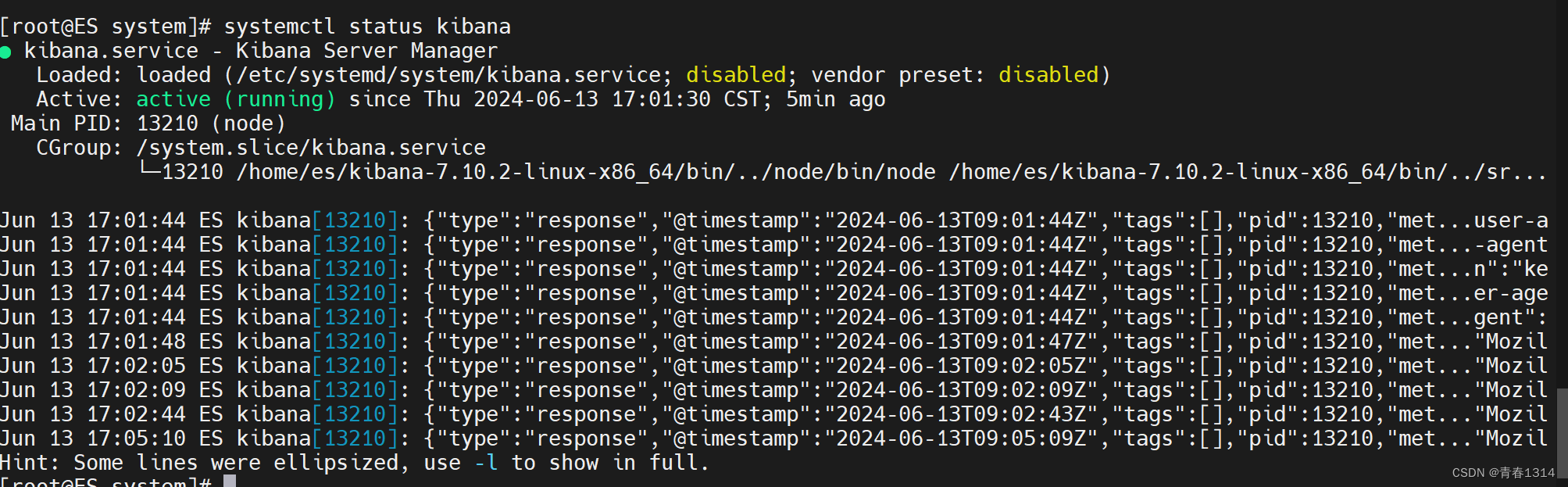
设置systemctl start kibana启动kibana
1、编辑kibana.service vi /etc/systemd/system/kibana.service [Unit] DescriptionKibana Server Manager [Service] Typesimple Useres ExecStart/home/es/kibana-7.10.2-linux-x86_64/bin/kibana PrivateTmptrue [Install] WantedBymulti-user.target 2、启动kibana # 刷…...

PostgreSQL:在CASE WHEN语句中使用SELECT语句
CASE WHEN语句是一种条件语句,用于多条件查询,相当于java的if/else。它允许我们根据不同的条件执行不同的操作。你甚至能在条件里面写子查询。而在一些情况下,我们可能需要在CASE WHEN语句中使用SELECT语句来检索数据或计算结果。下面是一些示…...

游戏心理学Day13
游戏成瘾 成瘾的概念来自于药物依赖,表现为为了感受药物带来的精神效应,或是为了避免由于断药所引起的不适和强迫性,连续定期使用该药的 行为现在成瘾除了药物成瘾外,还包括行为成瘾。成瘾的核心特征是不知道成瘾的概念来自于药…...

GitLab中用户权限
0 Preface/Foreword 1 权限介绍 包含5种权限: Guest(访客):可以创建issue、发表comment,不能读写版本库Reporter(报告者):可以克隆代码,不能提交。适合QA/PMDeveloper&…...

RunMe_About PreparationForDellBiosWUTTest
:: ***************************************************************************************************************************************************************** :: 20240613 :: 该脚本可以用作BIOS WU测试前的准备工作,包括:自动检测"C:\DellB…...

C++中变量的使用细节和命名方案
C中变量的使用细节和命名方案 C提倡使用有一定含义的变量名。如果变量表示差旅费,应将其命名为cost_of_trip或 costOfTrip,而不要将其命名为x或cot。必须遵循几种简单的 C命名规则。 在名称中只能使用字母字符、数字和下划线()。 名称的第一个字符不能是数字。 区分…...

[ACTF新生赛2020]SoulLike
两个文件 ubuntu运行 IDA打开 清晰的逻辑 很明显,我们要sub83a 返回ture 这里第一个知识点来了 你点开汇编会发现 这里一堆xor巨多 然后IDA初始化设置的函数,根本不能分析这么多 我们要去改IDA的设置 cfg 里面的 hexrays文件 在max_funsize这 修改为1024,默认是64 等待一…...

C#——析构函数详情
析构函数 C# 中的析构函数(也被称作“终结器”)同样是类中的一个特殊成员函数,主要用于在垃圾回收器回收类实例时执行一些必要的清理操作。 析构函数: 当一个对象被释放的时候执行 C# 中的析构函数具有以下特点: * 析构函数只…...

探索重要的无监督学习方法:K-means 聚类模型
在数据科学和机器学习领域,聚类分析是一种重要的无监督学习方法,用于将数据集中的对象分成多个组(簇),使得同一簇中的对象相似度较高,而不同簇中的对象相似度较低。K-means 聚类是最广泛使用的聚类算法之一,它以其简单、快速和易于理解的特点受到了广泛关注。本文将深入…...

将web项目打包成electron桌面端教程(二)vue3+vite+ts
说明:我用的demo项目是vue3vitets,如果是vue2/cli就不用往下看啦,建议找找其他教程哦~下依赖npm下载不下来的,基本换成cnpm/pnpm/yarn就可以了 一、项目准备 1、自己新创建一个,这里就不过多赘述了 2、将需要打包成…...

Arm Corstone SSE-300内存架构与安全设计解析
1. Arm Corstone SSE-300内存架构深度解析在嵌入式系统设计中,内存映射是连接软件与硬件的关键纽带。作为Arm最新推出的子系统解决方案,Corstone SSE-300通过精心设计的内存架构,为开发者提供了高性能、高安全性的开发平台。我在实际项目中使…...

Claude Code、Cursor、GitHub Copilot、Codex 怎么选?别再按“哪个最强”来判断了
AI 编程工具越来越像“工具箱”,而不是单个聊天窗口。如果你还在问“Claude Code、Cursor、Copilot、Codex 哪个最强”,这个问题本身就有点偏。更好的判断方式是:你当前的任务发生在哪里、需要改多少文件、是否需要跑测试、结果要不要进入 PR…...

proxy-doctor:自动化诊断与修复开发工具代理配置的利器
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的项目时,遇到了一个老生常谈但又极其恼人的问题:代理配置。无论是开发环境里的包管理工具,还是日常使用的命令行工具,一旦涉及到网络请求,代理设置不对ÿ…...

Go语言开源漏洞扫描器Abyss-Scanner:架构解析与CI/CD集成实践
1. 项目概述:一个为安全而生的开源漏洞扫描器最近在整理自己的开源项目工具箱,发现一个挺有意思的工具,叫 Abyss-Scanner。这名字起得挺有深意,“深渊扫描器”,听起来就有点探索未知、发现潜在风险的味道。简单来说&am…...

柔性LED灯丝DIY:从电路原理到创意饰品制作全攻略
1. 项目概述:当生日遇上柔性LED灯丝给孩子的生日派对准备一份独一无二的、会发光的惊喜,是很多家长和手工爱好者的心愿。这次,我们不买现成的塑料灯牌,而是亲手做一个能戴在头上或挂在脖子上的“生日数字灯冠”。这个项目的核心&a…...

告别showSoftInput失效:一文读懂Android 11+的WindowInsetsController输入法控制
Android输入法控制演进:从InputMethodManager到WindowInsetsController的深度解析 在移动应用开发中,输入法交互是最基础却又最容易被忽视的细节之一。许多开发者都曾遇到过这样的场景:精心设计的登录界面,光标在输入框闪烁&#…...

NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南
NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专业的显卡优化工具,专为…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

DLP/SLA光固化3D打印技术解析与Ember打印机实战指南
1. DLP/SLA 3D打印技术深度解析:从光与树脂的对话说起如果你是从FDM(熔丝制造)打印转向树脂打印的,那感觉就像从开手动挡卡车换到了开精密数控机床。DLP(数字光处理)和SLA(立体光刻)…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...