使用‘消除’技术绕过LLM的安全机制,不用训练就可以创建自己的nsfw模型
开源的大模型在理解和遵循指令方面都表现十分出色。但是这些模型都有审查的机制,在获得被认为是有害的输入的时候会拒绝执行指令,例如会返回“As an AI assistant, I cannot help you.”。这个安全功能对于防止误用至关重要,但它限制了模型的灵活性和响应能力。
在本文中,我们将探索一种称为“abliteration”的技术,它可以在不进行再训练的情况下取消LLM审查。这种技术有效地消除了模型的内置拒绝机制,允许它响应所有类型的提示。

什么是abliteration?
现代LLM在安全性和教学遵循方面进行了微调,这意味着他们接受了拒绝有害要求的输入。Arditi等人在他们的博客文章中表明,这种拒绝行为是由模型残差流中的特定方向产生的。也就是说如果我们阻止模型表示这个方向,它就会失去拒绝请求的能力。相反,如果人为地添加这个方向会导致模型拒绝任何请求。
在传统的仅解码器的类LLAMA架构中,我们可以关注三个残差流:每个块的开始(“pre”),注意力层和MLP层之间(“mid”),以及MLP层之后(“post”)。下图显示了每个残差流的位置。
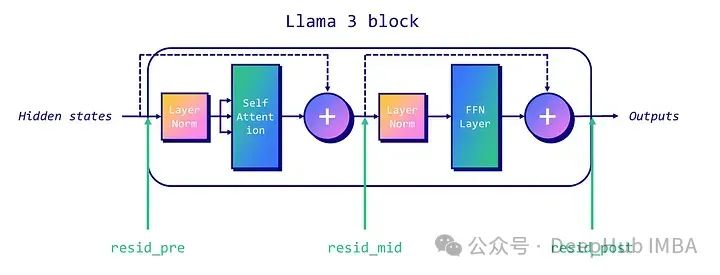
为了取消LLM的这个机制,我们首先需要确定模型中的“拒绝方向”。这个过程涉及几个技术步骤:
- 数据收集:在一组有害指令和一组无害指令上运行模型,记录每个指令在最后一个令牌位置的残差激活情况。
- 平均差值:计算有害指令和无害指令激活之间的平均差值。这给了我们一个表示模型每一层的“拒绝方向”的向量。
- 选择:将这些向量归一化,并对它们进行评估,以选择一个最佳的“拒绝方向”。
一旦确定了拒绝方向,我们就可以“消融”它,这样就可以消除模型表示该特征的能力。并且这可以通过推理时间干预临时取消或者使用权重正交化来永久的消除它。
我们先谈谈推理时间干预。对于写入残差流的每个组件(例如注意头),计算其输出到拒绝方向的投影并减去该投影。这种减法应用于每个令牌和每个层,确保模型永远不会表示拒绝方向。
如果想永久消除则需要使用权重的正交化,这涉及到直接修改模型权值。通过将分量权重相对于拒绝方向正交化,防止模型完全写入该方向。这可以通过调整写入残差流的矩阵来实现的,确保它们不会影响拒绝方向。
下面我们将演示如何使用权重的正交化永久消除限制。
代码实现
下面的实现基于FailSpy的abliterator,我对它进行了调整和简化,使其更容易理解。这一节代码相当多,所以可以看到内部发生了什么,但是如果你对技术细节不太感兴趣,可以使用FailSpy的abliterator库,因为我们这个代码就是基于abliterator的
让我们安装必要的包并导入它们。
!pipinstalltransformerstransformers_stream_generatortiktokentransformer_lenseinopsjaxtypingimporttorchimportfunctoolsimporteinopsimportgcfromdatasetsimportload_datasetfromtqdmimporttqdmfromtorchimportTensorfromtypingimportListfromtransformer_lensimportHookedTransformer, utilsfromtransformer_lens.hook_pointsimportHookPointfromtransformersimportAutoModelForCausalLM, AutoTokenizerfromjaxtypingimportFloat, Intfromcollectionsimportdefaultdict# Turn automatic differentiation off to save GPU memory (credit: Undi95)torch.set_grad_enabled(False)
然后我们需要两个数据集:一个包含无害指令,另一个包含有害指令。我们将使用tatsu-lab/alpaca以及llm-attacks.的数据。
加载指令并将其重新格式化为具有“role”和“content”键的字典列表。这使得它与apply_chat_tokenizer()方法兼容,因为该方法遵循Llama 3的聊天模板。
defreformat_texts(texts):return [[{"role": "user", "content": text}] fortextintexts]# Get harmful and harmless datasetsdefget_harmful_instructions():deephub_dataset=load_dataset('mlabonne/harmful_behaviors')returnreformat_texts(deephub_dataset['train']['text']), reformat_texts(dataset['test']['text'])defget_harmless_instructions():dataset=load_dataset('mlabonne/harmless_alpaca')returnreformat_texts(dataset['train']['text']), reformat_texts(dataset['test']['text'])harmful_inst_train, harmful_inst_test=get_harmful_instructions()harmless_inst_train, harmless_inst_test=get_harmless_instructions()
现在我们有了数据集,下面就是加载我们想要删除的模型。但是这里不能使用HookedTransformer直接加载自定义模型。所以我们使用了FailSpy中描述的一个技巧,下载并将其重命名为meta-llama/Meta-Llama-3-8B-Instruct. 如果你的GPU与BF16不兼容,请使用float16格式。
MODEL_ID="mlabonne/Daredevil-8B"MODEL_TYPE="meta-llama/Meta-Llama-3-8B-Instruct"# Download and load model!gitclonehttps://huggingface.co/{MODEL_ID} {MODEL_TYPE}# Load model and tokenizermodel=HookedTransformer.from_pretrained_no_processing(MODEL_TYPE,local_files_only=True,dtype=torch.bfloat16,default_padding_side='left')tokenizer=AutoTokenizer.from_pretrained(MODEL_TYPE)tokenizer.padding_side='left'tokenizer.pad_token=tokenizer.eos_token
现在我们就可以标记我们的数据集了。使用相同数量的样本进行无害和有害的说明。
deftokenize_instructions(tokenizer, instructions):returntokenizer.apply_chat_template(instructions,padding=True,truncation=False,return_tensors="pt",return_dict=True,add_generation_prompt=True,).input_idsn_inst_train=min(256, len(harmful_inst_train), len(harmless_inst_train))# Tokenize datasetsharmful_tokens=tokenize_instructions(tokenizer,instructions=harmful_inst_train[:n_inst_train],)harmless_tokens=tokenize_instructions(tokenizer,instructions=harmless_inst_train[:n_inst_train],)
一切都设置好了,开始第一步,数据收集:对这些标记化的数据集进行处理,并将残差流激活以有害和无害的方式存储。这是由transformer_lens库管理的。
batch_size=32# Initialize defaultdicts to store activationsharmful=defaultdict(list)harmless=defaultdict(list)# Process the training data in batchesnum_batches= (n_inst_train+batch_size-1) //batch_sizeforiintqdm(range(num_batches)):print(i)start_idx=i*batch_sizeend_idx=min(n_inst_train, start_idx+batch_size)# Run models on harmful and harmless prompts, cache activationsharmful_logits, harmful_cache=model.run_with_cache(harmful_tokens[start_idx:end_idx],names_filter=lambdahook_name: 'resid'inhook_name,device='cpu',reset_hooks_end=True)harmless_logits, harmless_cache=model.run_with_cache(harmless_tokens[start_idx:end_idx],names_filter=lambdahook_name: 'resid'inhook_name,device='cpu',reset_hooks_end=True)# Collect and store the activationsforkeyinharmful_cache:harmful[key].append(harmful_cache[key])harmless[key].append(harmless_cache[key])# Flush RAM and VRAMdelharmful_logits, harmless_logits, harmful_cache, harmless_cachegc.collect()torch.cuda.empty_cache()# Concatenate the cached activationsharmful= {k: torch.cat(v) fork, vinharmful.items()}harmless= {k: torch.cat(v) fork, vinharmless.items()}
现在可以计算每一层的拒绝方向。这对应于有害指令和无害指令激活之间的平均差异,然后将其归一化。在activation_scores中按降序对它们进行排序。
# Helper function to get activation indexdefget_act_idx(cache_dict, act_name, layer):key= (act_name, layer)returncache_dict[utils.get_act_name(*key)]# Compute difference of means between harmful and harmless activations at intermediate layersactivation_layers= ["resid_pre", "resid_mid", "resid_post"]activation_refusals=defaultdict(list)forlayer_numinrange(1, model.cfg.n_layers):pos=-1 # Position indexfordeephub_layerinactivation_layers:harmful_mean_act=get_act_idx(harmful, deephub_layer, layer_num)[:, pos, :].mean(dim=0)harmless_mean_act=get_act_idx(harmless, deephub_layer, layer_num)[:, pos, :].mean(dim=0)refusal_dir=harmful_mean_act-harmless_mean_actrefusal_dir=refusal_dir/refusal_dir.norm()activation_refusals[layer].append(refusal_dir)selected_layers= ["resid_pre"]activation_scored=sorted([activation_refusals[layer][l-1]forlinrange(1, model.cfg.n_layers)forlayerinselected_layers],key=lambdax: abs(x.mean()),reverse=True,)
最后一步包需要评估我们计算的拒绝方向。将在推理期间对每个残差流和每个块应用拒绝方向。在下面的代码片段中,是得四个测试有害指令和20个块(或层)的输出。
def_generate_with_hooks(model: HookedTransformer,tokenizer: AutoTokenizer,tokens: Int[Tensor, "batch_size seq_len"],max_tokens_generated: int=64,fwd_hooks=[],) ->List[str]:all_tokens=torch.zeros((tokens.shape[0], tokens.shape[1] +max_tokens_generated),dtype=torch.long,device=tokens.device,)all_tokens[:, : tokens.shape[1]] =tokensforiinrange(max_tokens_generated):withmodel.hooks(fwd_hooks=fwd_hooks):logits=model(all_tokens[:, : -max_tokens_generated+i])next_tokens=logits[:, -1, :].argmax(dim=-1) # greedy sampling (temperature=0)all_tokens[:, -max_tokens_generated+i] =next_tokensreturntokenizer.batch_decode(all_tokens[:, tokens.shape[1] :], skip_special_tokens=True)defget_generations(deephub_model: HookedTransformer,tokenizer: AutoTokenizer,instructions: List[str],fwd_hooks=[],max_tokens_generated: int=64,batch_size: int=4,) ->List[str]:generations= []foriintqdm(range(0, len(instructions), batch_size)):tokens=tokenize_instructions(tokenizer, instructions=instructions[i : i+batch_size])generation=_generate_with_hooks(deephub_model,tokenizer,tokens,max_tokens_generated=max_tokens_generated,fwd_hooks=fwd_hooks,)generations.extend(generation)returngenerations# Inference-time intervention hookdefdirection_ablation_hook(activation: Float[Tensor, "... d_act"],deephub_hook: HookPoint,direction: Float[Tensor, "d_act"],):ifactivation.device!=direction.device:direction=direction.to(activation.device)proj= (einops.einsum(activation, direction.view(-1, 1), "... d_act, d_act single -> ... single")*direction)returnactivation-proj# Testing baselineN_INST_TEST=4baseline_generations=get_generations(model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=[])# Evaluating layers defined earlier (needs human evaluation to determine best layer for refusal inhibition)EVAL_N=20 # Evaluate how many of the top N potential directionsevals= []forrefusal_dirintqdm(activation_scored[:EVAL_N]):deephub_hook_fn=functools.partial(direction_ablation_hook, direction=refusal_dir)fwd_hooks= [(utils.get_act_name(act_name, layer), deephub_hook_fn)forlayerinlist(range(model.cfg.n_layers))foract_nameinactivation_layers]intervention_generations=get_generations(model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=fwd_hooks)evals.append(intervention_generations)
将所有的generations存储在eval列表中。现在可以打印它们并手动选择为每个指令提供未经审查的响应的层(块)。
如果你找不到满足这些要求的层,可能需要测试前面的selected_layers列表中的其他残差流、指令、附加块等,这个可能和模型架构有关系需要仔细的比对。
下面代码自动排除包含“我不能”和“我不能”的回复,这样就可以过滤掉不想要的回答。
# Print generations for human evaluationblacklist = ["I cannot", "I can't"]for i in range(N_INST_TEST):print(f"\033[1mINSTRUCTION {i}: {harmful_inst_test[i]}")print(f"\nBASELINE COMPLETION:\n{baseline_generations[i]}\033[0m")for layer_candidate in range(EVAL_N):if not any(word in evals[layer_candidate][i] for word in blacklist):print(f"\n---\n\nLAYER CANDIDATE #{layer_candidate} INTERVENTION COMPLETION:")print(evals[layer_candidate][i])
这个例子中,候选层9为这四个指令提供了未经审查的答案。这是我们将选择的拒绝方向。下面就是实现权值正交化来修改权值,防止模型创建具有该方向的输出。可以通过打印补全来验证模型是否成功地不受审查。
defget_orthogonalized_matrix(matrix: Float[Tensor, "... d_model"], vec: Float[Tensor, "d_model"]) ->Float[Tensor, "... d_model"]:proj= (einops.einsum(matrix, vec.view(-1, 1), "... d_model, d_model single -> ... single")*vec)returnmatrix-proj# Select the layer with the highest potential refusal directionLAYER_CANDIDATE=9refusal_dir=activation_scored[LAYER_CANDIDATE]# Orthogonalize the model's weightsifrefusal_dir.device!=model.W_E.device:refusal_dir=refusal_dir.to(model.W_E.device)model.W_E.data=get_orthogonalized_matrix(model.W_E, refusal_dir)forblockintqdm(model.blocks):ifrefusal_dir.device!=block.attn.W_O.device:refusal_dir=refusal_dir.to(block.attn.W_O.device)block.attn.W_O.data=get_orthogonalized_matrix(block.attn.W_O, refusal_dir)block.mlp.W_out.data=get_orthogonalized_matrix(block.mlp.W_out, refusal_dir)# Generate text with abliterated modelorthogonalized_generations=get_generations(model, tokenizer, harmful_inst_test[:N_INST_TEST], fwd_hooks=[])# Print generationsforiinrange(N_INST_TEST):iflen(baseline_generations) >i:print(f"INSTRUCTION {i}: {harmful_inst_test[i]}")print(f"\033[92mBASELINE COMPLETION:\n{baseline_generations[i]}")print(f"\033[91mINTERVENTION COMPLETION:\n{evals[LAYER_CANDIDATE][i]}")print(f"\033[95mORTHOGONALIZED COMPLETION:\n{orthogonalized_generations[i]}\n")
这样我们就修改完成了这个模型。将其转换回Hugging Face 格式,也可以上传到HF hub上
# Convert model back to HF safetensorshf_model=AutoModelForCausalLM.from_pretrained(MODEL_TYPE, torch_dtype=torch.bfloat16)lm_model=hf_model.modelstate_dict=model.state_dict()lm_model.embed_tokens.weight=torch.nn.Parameter(state_dict["embed.W_E"].cpu())forlinrange(model.cfg.n_layers):lm_model.layers[l].self_attn.o_proj.weight=torch.nn.Parameter(einops.rearrange(state_dict[f"blocks.{l}.attn.W_O"], "n h m->m (n h)", n=model.cfg.n_heads).contiguous())lm_model.layers[l].mlp.down_proj.weight=torch.nn.Parameter(torch.transpose(state_dict[f"blocks.{l}.mlp.W_out"], 0, 1).contiguous())hf_model.push_to_hub(f"{MODEL_ID}-abliterated")
DPO微调
在Open LLM排行榜和Nous的基准测试上评估了上面的删除模型和源模型。结果如下:

源模型明显优于 Llama 3 8B Instruct。但是我们修改的模型降低了模型的质量。
为了解决这个问题,我们可以来对他进行微调,但是Llama 3 8B Instruct在监督微调方面非常脆弱。额外的SFT可能会破坏模型的性能。
所以我们这里选择偏好对齐。因为他是相当轻量的,不应该使我们的模型损失性能。DPO是一个很好的候选,因为它易于使用和良好的跟踪记录。这里我使用了LazyAxolotl和mlabonne/orpo-dpo-mix-40k数据集。下面是我使用的配置:
base_model: mlabonne/Daredevil-8B-abliteratedmodel_type: LlamaForCausalLMtokenizer_type: AutoTokenizerload_in_8bit: falseload_in_4bit: truestrict: falsesave_safetensors: truerl: dpochat_template: chatmldatasets:- path: mlabonne/orpo-dpo-mix-40ksplit: traintype: chatml.inteldataset_prepared_path:val_set_size: 0.0output_dir: ./outadapter: qloralora_model_dir:sequence_len: 2048sample_packing: falsepad_to_sequence_len: falselora_r: 64lora_alpha: 32lora_dropout: 0.05lora_target_linear: truelora_fan_in_fan_out:wandb_project: axolotlwandb_entity:wandb_watch:wandb_name:wandb_log_model:gradient_accumulation_steps: 8micro_batch_size: 1num_epochs: 1optimizer: paged_adamw_8bitlr_scheduler: cosinelearning_rate: 5e-6train_on_inputs: falsegroup_by_length: falsebf16: autofp16:tf32:gradient_checkpointing: trueearly_stopping_patience:resume_from_checkpoint:local_rank:logging_steps: 1xformers_attention:flash_attention: truewarmup_steps: 100evals_per_epoch: 0eval_table_size:eval_table_max_new_tokens: 128saves_per_epoch: 1debug:deepspeed: deepspeed_configs/zero2.jsonweight_decay: 0.0special_tokens:pad_token: <|end_of_text|>
用6个A6000 和DeepSpeed ZeRO-2来训练它。这次训练耗时约6小时45分钟。以下是我从W&B得到的训练曲线:

我们来看看微调模型的表现:

我们可以看到,这种额外的训练使我们能够恢复由于“消字”而导致的大部分性能下降。模型没有改进的一个领域是GSM8K,这是肯定的,因为它是一个数学数据集,跟我们的研究方向无关。
总结
在这篇文章中,我们介绍了“消除”的概念。该技术利用模型在无害和有害提示上的激活来计算拒绝方向。然后,它使用这个方向来修改模型的权重,并确保我们不输出拒绝信息。这项技术也证明了安全微调的脆弱性,并引发了伦理问题。
对模型进行了消除后会降低了模型的性能。我们则可以使用DPO修复了它,这样就可以得到一个完整的并且效果十分不错的模型。
但是“消除”并不应局限于去除对齐,应该被视为一种无需再训练的微调技术。因为它可以创造性地应用于其他目标,比如FailSpy的MopeyMule(它采用了忧郁的对话风格)。
最后github库
https://avoid.overfit.cn/post/e828cf84358d42f6b4690d4c1c5669d8
作者:Maxime Labonne
相关文章:
使用‘消除’技术绕过LLM的安全机制,不用训练就可以创建自己的nsfw模型
开源的大模型在理解和遵循指令方面都表现十分出色。但是这些模型都有审查的机制,在获得被认为是有害的输入的时候会拒绝执行指令,例如会返回“As an AI assistant, I cannot help you.”。这个安全功能对于防止误用至关重要,但它限制了模型的…...

解决使用elmessage 没有样式的问题
错误情况 这里使用了一个消息提示,但是没有出现正确的样式, 错误原因和解决方法 出现这种情况是因为,在全局使用了按需导入,而又在局部组件中导入了ElMessage组件,我们只需要将局部组件的import删除就可以了 import…...

pxe批量部署linux介绍
1、PXE批量部署的作用及必要性: 1)智能实现操作系统的批量安装(无人值守安装)2)减少管理员工作,提高工作效率3)可以定制操作系统的安装流程a.标准流程定制(ks.cfg)b.自定义流程定制(ks.cfg(%pos…...

RAG 实践-Ollama+AnythingLLM 搭建本地知识库
什么是 RAG RAG,即检索增强生成(Retrieval-Augmented Generation),是一种先进的自然语言处理技术架构,它旨在克服传统大型语言模型(LLMs)在处理开放域问题时的信息容量限制和时效性不足。RAG的…...

【超详细】使用RedissonClient实现Redis分布式锁
使用RedissonClient实现Redis分布式锁是一个非常简洁和高效的方式。Redisson是一个基于Redis的Java客户端,它提供了许多高级功能,包括分布式锁、分布式集合、分布式映射等,简化了分布式系统中的并发控制。 添加依赖 首先,你需要…...

CC攻击的有效应对方案
随着互联网的发展,网络安全问题愈发突出。CC攻击(Challenge Collapsar Attack),一种针对Web应用程序的分布式拒绝服务(DDoS)攻击方式,已经成为许多网络管理员和网站拥有者不得不面对的重大挑战。…...

自动驾驶基础一车辆模型
模型概述: 自行车动力学模型通常用于研究自行车在骑行过程中的行为,如稳定性、操控性和速度等。模型可以基于不同的简化假设和复杂度,从简单的二维模型到复杂的三维模型,甚至包括骑行者的动态。力学方程: 基础物理学方…...
机器学习:数据分布的漂移问题及应对方案
首先,让我们从一位高管告诉我的一个故事开始,很多读者可能对此感同身受。 大约两年前,他的公司聘请了一家咨询公司开发一个机器学习模型,帮助他们预测下周每种食品杂货需要多少,以便他们可以相应地补货。这家咨询公司…...

公链常用的共识算法
1. 工作量证明(Proof of Work, PoW) 工作原理:要求节点(矿工)解决一个数学难题,这个过程称为挖矿。第一个解决难题的矿工将有权添加一个新的区块到区块链上,并获得一定数量的加密货币作为奖励。…...

详解 Flink Table API 和 Flink SQL 之函数
一、系统内置函数 1. 比较函数 API函数表达式示例Table API,>,<,!,>,<id1001,age>18SQL,>,<,!,>,<id‘1001’&…...

rsa加签验签C#和js以及java互通
js实现rsa加签验签 https://github.com/kjur/jsrsasign 11.1.0版本 解压选择需要的版本,这里选择all版本了 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>JS RSA加签验签</title&g…...

C语言中数组和指针的关系
在C语言中,数组和指针之间存在着密切的关系,尽管它们在概念上是不同的。以下是关于C语言中数组和指针关系的一些要点: 数组名作为指针: 在大多数情况下,数组名在表达式中会被当作指向其第一个元素的指针。例如&#x…...
项目)
idea 新建一个 JSP(JavaServer Pages)项目
环境设置: 确保你的开发环境中已经安装了 Java 开发工具包(JDK)和一个 Java Web 开发的集成开发环境(IDE),比如 Eclipse、IntelliJ IDEA 或者 NetBeans。你还需要一个 Web 服务器,比如 Apache T…...

【名词解释】Unity中的表格布局组件及其使用示例
Unity中的表格布局组件通常指的是GridLayoutGroup,这是一个在Unity的UI系统中用来布局子对象的组件。它可以帮助开发者将UI元素按照网格的形式进行排列,非常适合创建表格、网格视图等布局。 名词解释: GridLayoutGroup:Unity UI…...

判断当前设备为移动端自适应 平板和pc端为375移动端样式
在libs的setRem.js中: let html document.querySelector("html"); function setRem() {let ui_w 375;let cl_w document.documentElement.clientWidth || document.body.clientWidth;cl_w > 750 ? cl_w 375 : "";html.style.fontSize …...
Science Advances|用于胃部pH监测和早期胃漏检测的生物可吸收无线无源柔性传感器(健康监测/柔性传感/柔性电子)
2024年4月19日,美国西北大学 John A. Rogers和中国科学技术大学吕頔(Di Lu)团队,在《Science Advances》上发布了一篇题为“Bioresorbable, wireless, passive sensors for continuous pH measurements and early detection of gastric leakage”的论文。论文内容如下: 一、…...
C# 使用 webview2 嵌入网页
需求:C#客户端程序, 窗口里嵌入一个web网页,可通过URL跳转的那种。并且,需要将登录的身份验证信息(token)设置到请求头里。 核心代码如下: // 打开按钮的点击事件 private void openBtn_Click(object sen…...
公司面试题总结(五)
25.谈一谈箭头函数与普通函数的区别,箭头函数主要解决什么问题? 箭头函数与普通函数的区别: ⚫ 语法简洁性: ◼ 箭头函数使用>符号定义,省略了 function 关键字,使得语法更为紧凑。 ◼ 对于单行函…...

Flutter笔记:关于WebView插件的用法(上)
Flutter笔记 关于WebView插件的用法(上) - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:htt…...

计算机毕业设计Python+Django农产品推荐系统 农产品爬虫 农产品商城 农产品大数据 农产品数据分析可视化 PySpark Hadoop Hive
课题研究的意义,国内外研究现状、水平和发展趋势 研究意义21世纪是一个信息爆炸的时代,人们在日常生活中可接触到的信息量非常之巨大。推荐系统逐步发展,其中又以个性化推荐系统最为瞩目。个性化推荐系统的核心在于个性化推荐算法,…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...

Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏
Godot卡牌游戏框架终极指南:3小时从零构建专业级卡牌游戏 【免费下载链接】godot-card-game-framework A framework which comes with prepared scenes and classes to kickstart your card game, as well as a powerful scripting engine to use to provide full r…...
)
告别Demo!用EMQX和Java模拟真实物联网设备上报数据流(Windows本地开发环境)
告别Demo!用EMQX和Java构建真实物联网数据流模拟方案 在物联网开发中,最令人头疼的莫过于缺乏真实设备进行测试。想象一下,当你精心设计的平台等待设备接入时,硬件团队却告诉你"下周才能交付原型机"。这种等待不仅拖延进…...

通达信数据解析终极指南:mootdx让金融数据获取变得如此简单
通达信数据解析终极指南:mootdx让金融数据获取变得如此简单 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易的世界里,获取准确、完整的市场数据是…...

Supabase AI Agent技能库:安全集成数据库操作与边缘函数调用
1. 项目概述:当Supabase遇上AI Agent,一个技能库的诞生最近在捣鼓AI Agent应用开发,发现一个挺有意思的现象:大家都能用LangChain、LlamaIndex这些框架快速搭出个Agent的架子,但真想让这个Agent去干点具体、有用的活儿…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...

模拟电路布局优化:多智能体强化学习实践
1. 模拟电路布局优化的挑战与机遇在集成电路设计领域,模拟电路布局一直是个令人头疼的问题。作为一名从业十余年的模拟电路设计师,我深刻体会到传统布局方法在面对现代工艺挑战时的局限性。每次手工调整晶体管位置时,那种"差之毫厘&…...

药物发现自动化:FEP计算工作流引擎faah的设计原理与实战
1. 项目概述:一个面向药物发现的自动化工作流引擎 最近在药物研发的自动化工具领域,一个名为 kiron0/faah 的项目引起了我的注意。这并非一个简单的脚本集合,而是一个设计精巧、旨在为药物发现中的自由能微扰计算提供端到端自动化解决方案的…...

Nextra:基于Next.js的现代化文档站构建利器
1. 项目概述:为什么Nextra能成为文档站构建的“瑞士军刀”?如果你最近在寻找一个构建技术文档、博客或个人知识库的工具,大概率会听到“Nextra”这个名字。它不是一个独立框架,而是一个基于Next.js的静态站点生成器,专…...

Nixtla时间序列预测生态:从统计模型到深度学习的统一实践
1. 项目概述:时间序列预测的“瑞士军刀”如果你正在处理时间序列数据,无论是销售预测、服务器监控、还是能源消耗分析,那么你很可能听说过或正在使用一些经典的库,比如statsmodels、prophet,或者更现代的深度学习框架。…...