浅谈golang字符编码
1、 Golang 字符编码
Golang 的代码是由 Unicode 字符组成的,并由 Unicode 编码规范中的 UTF-8 编码格式进行编码并存储。
Unicode 是编码字符集,囊括了当今世界使用的全部语言和符号的字符。有三种编码形式:UTF-8,UTF-16,UTF-32。(UTF: Unicode Transformation Format,统一码转换格式)
在这几种编码格式的名称中,- 右边的整数的含义是,以多少个比特作为一个编码单元。以 UTF-8 为例,它会以 8 个比特也就是一个字节,作为一个编码单元。并且,它与标准的 ASCII 编码是完全兼容的。也就是说,在 [0x00, 0x7F]的范围内,这两种编码表示的字符都是相同的,这也是 UTF-8 编码格式的一个巨大优势(这里不探讨 UTF-16 及 UTF-32)。
UTF-8 是一种可变长的编码方案。换句话说,它会用一个或多个字节来表示某个字符,最多使用四个字节。比如,对于一个英文字符,它仅用一个字节就可以表示,而对于一个中文字符,它需要使用三个字节才能够表示。不论怎样,一个受支持的字符总是可以由 UTF-8 编码为一个字节序列。以下会简称后者为 UTF-8 编码值。
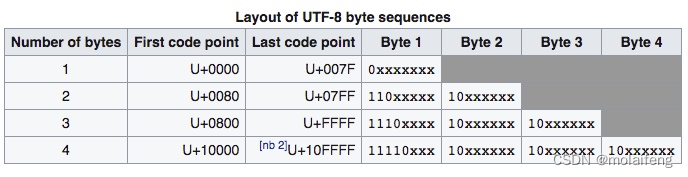
从上图可知 UTF-8 的编码方式:
- 什么时候读
1个字节的字符?- 字节的第一位为
0,后面7位为符号的unicode码。所以这样看,英语字母的utf-8和ascii一致。
- 字节的第一位为
- 什么时候读多个字节的字符?
- 对于有
n个字节的字符,(n>1)…. 其中第一个字节的高n位就为1,换句话说:- 第一个字节读到
0,那就是读1个字节 - 第一个字节读到
n个1,就要读n个字节
- 第一个字节读到
- 对于有
0xxxxxxx # 读1个字节
110xxxxx 10xxxxxx # 读2个字节
1110xxxx 10xxxxxx 10xxxxxx #读3个字节
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx #读4个字节Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
------------------ -+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
那 Unicode 是如何填充UTF-8各个字节的呢?
比如 码 这个汉字,对应的 unicode编码为 U+7801
- 对应的十六进制处于
0000 0800-0000 FFFF中,也就是3个字节,相应的二进制为1110xxxx 10xxxxxx 10xxxxxx 码的unicode编码为U+7801对应的二进制为111100000000001,为了和接下来填充字节方便,这里做个格式优化111 100000 000001- 从后向前填充,高位不够的补
0 000001填充第三个字节(从左往右数)10000001100000填充第二个字节10100000111填充第一个字节,高位不够的就补0,为11100111- 最终结果为
11100111 10100000 10000001(对应的十六进制分别对应e7 a0 81)
func TestInt(t *testing.T) {s1 := "码"for i := 0; i < len(s1); i++ {fmt.Printf("%x ", s1[i])}
}
打印的结果为 e7 a0 81,和上面演算的一致。
2、string 数据结构
先来看看 Golang 的 string 的数据结构
type StringHeader struct {Data uintptrLen int
}
其中包含指向字节数组的指针 Data 和数组的大小 Len,后者 Len 方便在 len() 时可以 O(1) 时间给出大小,就是常见的以空间换时间。字符串由字符组成,字符的底层由字节组成,而一个字符串在底层的表示是一个字节序列,这个字节序列就存储在 Data 里,不过是只读的。
import ("fmt""testing"
)func TestStr(t *testing.T) {str := "Hello World"fmt.Println(str)
}
把上面代码 go tool compile -S str_test.go > str_test.S 生成汇编代码,然后找到
go.string."Hello World" SRODATA dupok size=110x0000 48 65 6c 6c 6f 20 57 6f 72 6c 64 Hello World
能够看到 Hello World 旁有一个 SRODATA 的标记,在 Golang 中编译器会将只读数据标记成 SRODATA。
再来看看 slice 的数据结构
type SliceHeader struct {Data uintptrLen intCap int
}
相比 string 多了个 Cap,因此在 Golang 中,字符串实际上是只读的字节切片。
那么对于只读的 string,若是想要改值应该怎么弄呢?
func TestModifyString(t *testing.T) {str := "golang编程"l := []byte(str)l[0] = 'G'fmt.Println(string(l)) // Golang编程
}
转成相应的字节数组,然后以索引的形式更新值。
3、string 编码方式
前面说过,字符串由字符组成,字符的底层由字节组成,而一个字符串在底层的表示是一个字节序列。在 Golang 中,字符可以被分成两种类型处理:对占 1 个字节的英文类字符,可以使用 byte(或者 unit8);对占 1 ~ 4 个字节的其他字符,可以使用 rune(或者int32),如中文、特殊符号等。
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is
// used, by convention, to distinguish byte values from 8-bit unsigned
// integer values.
type byte = uint8// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32
可以看到 byte 、 rune 其实分别就是 uint8、int32 的别名,byte 占 1 个字节, rune 占 4个字节。
func TestStrLen(t *testing.T) {str1 := "go"str2 := "go编程"fmt.Printf("%v len is %d\n", str1, len(str1))fmt.Printf("%v len is %d\n", str2, len(str2))}
运行后,发现 str1 长度为 2 这个没问题,但 str2 的长度不是 4 而是 8,这是什么原因呢?
先不着急找答案,看看下面的代码
func printBytes(s string) {fmt.Printf("Bytes: ")for i := 0; i < len(s); i++ {fmt.Printf("%x ", s[i]) // 按十六进制输出}fmt.Printf("\n")
}func printChars(s string) {fmt.Printf("Charaters: ")for i := 0; i < len(s); i++ {fmt.Printf("%c ", s[i]) // 将数字转换成它对应的 Unicode 字符}fmt.Printf("\n")
}func TestInt(t *testing.T) {s1 := "go编程"fmt.Printf("s1: %s, bytes len(s1)=%d\n", s1, len(s1))fmt.Printf("s1: %s, rune len(s1)=%d\n", s1, len([]rune(s1)))printBytes(s1)printChars(s1)
}
运行后打印如下
s1: go编程, bytes len(s1)=8
s1: go编程, rune len(s1)=4
Bytes: 67 6f e7 bc 96 e7 a8 8b
Charaters: g o ç ¼ – ç ¨
仔细看,发现 rune 类型的输出了 4,另外 printChars 输出乱码了。
先来看看 rune 类型,是 int32 的别名,也就是说,一个 rune 类型的值会由 4 个字节宽度的空间来存储。它的存储空间总是能够存下一个 UTF-8 编码值。一个 rune 类型的值在底层其实就是一个 UTF-8 编码值。前者是(便于我们人类理解的)外部展现,后者是(便于计算机系统理解的)内在表达。
Golang 中常用 rune 类型来处理中文。printChars 之所以输出乱码,是因为在第一节中提到的在 UTF-8 中汉字是以三个字节存储的,len() 是按单字节来计算长度,因此对于三个字节的中文来说输出三分之铁定乱码。那么如何输出才不乱码呢?
func TestRune(t *testing.T) {str := "golang编程"l := []rune(str)for i := 0; i < len(l); i++ {fmt.Printf("%c ", l[i])}
}
打印输出 g o l a n g 编 程。
当然了,还可以使用 for range 来打印字符串里的中文。
func TestRange(t *testing.T) {str := "golang编程"for i, s := range str {fmt.Printf("%d: %c\n", i, s)}
}
打印输出
0: g
1: o
2: l
3: a
4: n
5: g
6: 编
9: 程
那为什么会这样呢?原因就在 Golang 中,会把 for range 结构转换成如下所示的形式
// Transform string range statements like "for v1, v2 = range a" intoha := afor hv1 := 0; hv1 < len(ha); {hv1t := hv1hv2 := rune(ha[hv1])if hv2 < utf8.RuneSelf {hv1++} else {hv2, hv1 = decoderune(ha, hv1)}v1, v2 = hv1t, hv2// original body}
for range 循环在迭代字符串时会逐个处理字符串中的 Unicode 码点(rune),而不是字节。由于 Golang 的原生字符串类型是以 UTF-8 编码的,UTF-8 是一种能够表示 Unicode 码点的变长编码方式,for range 循环能够正确处理这种编码。
通俗点就是 for range 会先把被遍历的字符串值拆成一个字节序列,然后再试图找出这个字节序列中包含的每一个 UTF-8 编码值,或者说每一个 Unicode字符。
func TestRange(t *testing.T) {str := "golang编程"for i, s := range str {fmt.Printf("%d: %c [% x]\n", i, s, []byte(string(s)))}
}
打印输出
0: g [67]
1: o [6f]
2: l [6c]
3: a [61]
4: n [6e]
5: g [67]
6: 编 [e7 bc 96]
9: 程 [e7 a8 8b]
由此可以看出,字符串中相邻 Unicode 字符的索引值不一定是连续的。 这取决于前一个 Unicode 字符是否为单字节字符(byte)。Golang 中的一个 string 类型值会由若干个 Unicode 字符组成,每个 Unicode 字符都可以由一个 rune 类型的值来承载。这些字符在底层都会被转换为 UTF-8 编码值,而这些 UTF-8 编码值又会以字节序列的形式表达和存储。因此,一个string 类型的值在底层就是一个能够表达若干个 UTF-8 编码值的字节序列。
ok,到这里了,发现两种不同的 for 循环在输出字符串的字符时会有所不同,这里做个归类
for-standalone会遍历字符串的每一个字节(Byte类型),在遇到字符串中有汉字时会乱码for-range会遍历字符串的每一个Unicode字符(Rune类型) ,在遇到字符串中有汉字时不会乱码
最后说说 string、byte 和 rune 三者之间的关系。
string在底层的表示是由单个字节组成的只读的字节序列,Golang的字符串是以UTF-8编码存储的,这意味着它们可以包含任意的Unicode字符。Golang把字符分byte和rune两种类型处理。byte是类型unit8的别名,用于存放占1个字节的ASCII字符,如英文字符,返回的是字符原始字节。由于Golang的字符串是以UTF-8编码的,一个byte可能表示一个字符的一部分(对于多字节字符如中文字符),也可能表示一个完整的字符(对于ASCII字符)。rune是类型int32的别名,用于存放多字节字符,如占3字节的中文字符,返回的是字符Unicode码点值(或者说它代表一个Unicode码点)。在处理字符串时,rune用于表示字符串中的一个完整的Unicode字符,无论这个字符是由多少个字节组成的。rune类型的变量可以存储任何Unicode字符,包括那些由多个字节表示的字符。
等等,等等,到这里,不妨再多看看。那么如果计算一个字符串的长度呢,用自带的 len() 函数对于单字节的字符串来说是准确的,若是带有中文字符这种多字节的字符串就不准确了,这时除了自己造轮子外,其实可以用 Golang 内置的 utf8.RuneCountInString 来统计。
func TestCountStr(t *testing.T) {str := "golang编程"fmt.Println(utf8.RuneCountInString(str)) // 8
}
有兴趣的读者可以看看其内部实现。
// RuneCountInString is like RuneCount but its input is a string.
func RuneCountInString(s string) (n int) {ns := len(s)for i := 0; i < ns; n++ {c := s[i]if c < RuneSelf {// ASCII fast pathi++continue}x := first[c]if x == xx {i++ // invalid.continue}size := int(x & 7)if i+size > ns {i++ // Short or invalid.continue}accept := acceptRanges[x>>4]if c := s[i+1]; c < accept.lo || accept.hi < c {size = 1} else if size == 2 {} else if c := s[i+2]; c < locb || hicb < c {size = 1} else if size == 3 {} else if c := s[i+3]; c < locb || hicb < c {size = 1}i += size}return n
}
相关文章:
浅谈golang字符编码
1、 Golang 字符编码 Golang 的代码是由 Unicode 字符组成的,并由 Unicode 编码规范中的 UTF-8 编码格式进行编码并存储。 Unicode 是编码字符集,囊括了当今世界使用的全部语言和符号的字符。有三种编码形式:UTF-8,UTF-16&#…...

Vite和Webpack的区别是什么,你站队谁?
Vite和Webpack有很多相同之处,也有区别,很多老铁分不清,贝格前端工场借助此文为大家详细介绍一下。 一、关于Vite和Webpack Vite和Webpack都是前端开发中常用的构建工具,用于将源代码转换为可在浏览器中运行的静态资源。它们在一…...
【微信小程序】事件传参的两种方式
文章目录 1.什么是事件传参2.data-*方式传参3.mark自定义数据 1.什么是事件传参 事件传参:在触发事件时,将一些数据作为参数传递给事件处理函数的过程,就是事件传参 在微信小程序中,我们经常会在组件上添加一些自定义数据,然后在…...

前端针对需要递增的固定数据
这里递增的是1到12 data(){return{cycleOptions:Array.from({ length: 12 }, (v, k) > ({value: k 1,label: String(k 1)})),} }<el-select v-model"ruleForm.monthLength" placeholder"请选择周期数量"><el-optionv-for"item in cycle…...

红酒保存中的氧气管理:适度接触与避免过度氧化
在保存云仓酒庄雷盛红酒的过程中,我们不得不面对一个微妙的问题:氧气管理。氧气,这个我们生活中无处不在的气体,对于红酒的保存却有着至关重要的影响。适度接触氧气对红酒的陈年过程和品质维护具有积极作用,然而过度氧…...

从零开始搭建开源智慧城市项目(三)上升线效果
前言 上一节实现了添加建筑物线框,模型外墙和道路地面材质添加。这一节准备通过简单的shader实现上升线效果。 思路 简单的说一下思路,通过获取模型顶点坐标所在的高度Z来进行筛选,高度再某一区间内设置成上升线的颜色,其余高度…...
unity基础(五)地形详解
目录 一 创建地形 二 调整地形大小 三 创建相邻地形 四 创建山峰 五 创建树木 七 添加风 八 添加水 简介: Unity 中的基础地形是构建虚拟场景的重要元素之一。 它提供了一种直观且灵活的方式来创建各种地形地貌,如山脉、平原、山谷等。 通过 Unity 的地形…...

postman接口测试工具详解
Postman 是一个功能强大的 API 开发和测试工具,广泛应用于开发人员和测试人员进行 API 的调试、测试、文档生成等工作。以下是对 Postman 的详细介绍。 1. 功能概览 1.1 请求构建 请求类型: 支持 GET、POST、PUT、DELETE、PATCH、OPTIONS 等多种 HTTP 方法。URL …...
作者:————LJS)
2024年护网行动全国各地面试题汇总(3)作者:————LJS
应急响应基本思路和流程 收集信息:收集客户信息和中毒主机信息,包括样本判断类型:判断是否是安全事件,何种安全事件,勒索、挖矿、断网、DoS 等等抑制范围:隔离使受害⾯不继续扩⼤深入分析:日志分…...

计算机专业的学生要达到什么水平才能进入大厂工作?越早知道越好
计算机专业的学生要达到什么水平才能进入BAT等大厂工作?越早知道越好. 一、算法题 各大公司笔试、面试基本都考这个,别的不说,《剑指Offer》所有题目背下来,Leetcode高频题目刷个一两百遍,搞过ACM也可以,…...

巡检费时费力?试试AI自动巡检
随着企业IT规模不断增长,设备、系统越来越多,运维工作压力也与日俱增。保障设备、系统健康稳定地运行,日常巡检是运维工作不可或缺的部分。通过巡检可以及时发现设备、系统的异常问题,提前预防及时处理,避免问题扩大产…...

46-4 等级保护 - 网络安全等级保护概述
一、网络安全等级保护概述 原文:没有网络安全就没有国家安全 二、网络安全法 - 安全立法 中华人民共和国主席令 第五十三号 《中华人民共和国网络安全法》已于2016年11月7日由中华人民共和国第十二届全国人民代表大会常务委员会第二十四次会议通过,并自2017年6月1日起正式…...

css引入方式有几种?link和@import有什么区别?
在CSS中,引入外部样式表的方式主要有两种:<link>标签和import规则。 使用<link>标签引入外部样式表: <link rel"stylesheet" href"path/to/style.css">这种方式是在HTML文档的<head>部分或者…...

使用‘消除’技术绕过LLM的安全机制,不用训练就可以创建自己的nsfw模型
开源的大模型在理解和遵循指令方面都表现十分出色。但是这些模型都有审查的机制,在获得被认为是有害的输入的时候会拒绝执行指令,例如会返回“As an AI assistant, I cannot help you.”。这个安全功能对于防止误用至关重要,但它限制了模型的…...

解决使用elmessage 没有样式的问题
错误情况 这里使用了一个消息提示,但是没有出现正确的样式, 错误原因和解决方法 出现这种情况是因为,在全局使用了按需导入,而又在局部组件中导入了ElMessage组件,我们只需要将局部组件的import删除就可以了 import…...

pxe批量部署linux介绍
1、PXE批量部署的作用及必要性: 1)智能实现操作系统的批量安装(无人值守安装)2)减少管理员工作,提高工作效率3)可以定制操作系统的安装流程a.标准流程定制(ks.cfg)b.自定义流程定制(ks.cfg(%pos…...

RAG 实践-Ollama+AnythingLLM 搭建本地知识库
什么是 RAG RAG,即检索增强生成(Retrieval-Augmented Generation),是一种先进的自然语言处理技术架构,它旨在克服传统大型语言模型(LLMs)在处理开放域问题时的信息容量限制和时效性不足。RAG的…...

【超详细】使用RedissonClient实现Redis分布式锁
使用RedissonClient实现Redis分布式锁是一个非常简洁和高效的方式。Redisson是一个基于Redis的Java客户端,它提供了许多高级功能,包括分布式锁、分布式集合、分布式映射等,简化了分布式系统中的并发控制。 添加依赖 首先,你需要…...

CC攻击的有效应对方案
随着互联网的发展,网络安全问题愈发突出。CC攻击(Challenge Collapsar Attack),一种针对Web应用程序的分布式拒绝服务(DDoS)攻击方式,已经成为许多网络管理员和网站拥有者不得不面对的重大挑战。…...

自动驾驶基础一车辆模型
模型概述: 自行车动力学模型通常用于研究自行车在骑行过程中的行为,如稳定性、操控性和速度等。模型可以基于不同的简化假设和复杂度,从简单的二维模型到复杂的三维模型,甚至包括骑行者的动态。力学方程: 基础物理学方…...

基于个性化机器学习与智能穿戴数据的痴呆症行为预测系统
1. 项目概述:当智能手表学会“预见”痴呆症患者的情绪风暴在痴呆症照护的漫长征途中,照护者最棘手的挑战往往不是记忆的衰退,而是那些突如其来、难以捉摸的行为与心理症状。想象一下,你照顾的长辈平时温和安静,却在某个…...

3分钟上手!BilibiliDown:免费开源B站视频下载工具终极指南
3分钟上手!BilibiliDown:免费开源B站视频下载工具终极指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.c…...

量化精度不妥协,吞吐翻2.8倍——DeepSeek-R1推理优化黄金参数组合大曝光,仅限本周公开
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1推理优化的底层逻辑与精度守恒原理 DeepSeek-R1作为面向长上下文、高吞吐场景设计的开源大语言模型,其推理优化并非以牺牲数值精度为代价换取速度提升,而是建立在计算…...

Windows电脑安装安卓应用:告别模拟器的轻量级解决方案
Windows电脑安装安卓应用:告别模拟器的轻量级解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经渴望在Windows电脑上运行安卓应用…...

79.2万条中文医疗对话数据如何重塑AI医疗问答的未来?
79.2万条中文医疗对话数据如何重塑AI医疗问答的未来? 【免费下载链接】Chinese-medical-dialogue-data Chinese medical dialogue data 中文医疗对话数据集 项目地址: https://gitcode.com/gh_mirrors/ch/Chinese-medical-dialogue-data 在医疗AI快速发展的今…...

3大核心功能!茉莉花插件让Zotero中文文献管理效率提升90%
3大核心功能!茉莉花插件让Zotero中文文献管理效率提升90% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为Zoter…...
)
RHEL 9保姆级教程:手把手教你用阿里云镜像替换官方yum源(附完整命令)
RHEL 9极速配置指南:阿里云镜像源一键切换实战刚拿到RHEL 9服务器时,最令人抓狂的莫过于看着进度条像蜗牛一样缓慢爬行。官方源的速度不仅影响工作效率,更可能让紧急部署变成一场噩梦。本文将用最直白的操作语言,带你三步完成阿里…...

量子计算模拟Hubbard模型:算法实现与噪声分析
1. Hubbard模型与量子计算模拟概述在凝聚态物理研究中,Hubbard模型堪称是研究强关联电子系统的"果蝇模型"。这个看似简单的理论框架却能展现出从金属-绝缘体相变到高温超导等丰富物理现象。模型的核心哈密顿量包含两项关键竞争:H -t∑⟨i,j⟩…...

Outlook CVE-2023-36895:MAPI与HTML渲染器间的类型混淆漏洞
1. 这个漏洞不是“点开邮件就中招”,但比你想象的更危险CVE-2023-36895,微软在2023年8月补丁星期二发布的那个Outlook远程代码执行漏洞,标题里写着“远程代码执行”,很多人第一反应是:“完了,我昨天刚看了封…...
:金融、电商、教育三大垂直领域实测数据首度公开)
企业级AI写作Agent部署全链路(从POC到规模化上线):金融、电商、教育三大垂直领域实测数据首度公开
更多请点击: https://kaifayun.com 第一章:企业级AI写作Agent部署全链路(从POC到规模化上线):金融、电商、教育三大垂直领域实测数据首度公开 企业级AI写作Agent的落地并非模型调用的简单叠加,而是涵盖需求…...