GLM+vLLM 部署调用
GLM+vLLM 部署调用
vLLM 简介
vLLM 框架是一个高效的大型语言模型(LLM)推理和部署服务系统,具备以下特性:
- 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了内存浪费,优化了模型的运行效率。
- 高吞吐量:vLLM 支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度。
- 易用性:vLLM 与 HuggingFace 模型无缝集成,支持多种流行的大型语言模型,简化了模型部署和推理的过程。兼容 OpenAI 的 API 服务器。
- 分布式推理:框架支持在多 GPU 环境中进行分布式推理,通过模型并行策略和高效的数据通信,提升了处理大型模型的能力。
- 开源:vLLM 是开源的,拥有活跃的社区支持,便于开发者贡献和改进,共同推动技术发展。
环境准备
在 一个3090 显卡的ubuntu22.04系统上进行部署。
pip 换源加速下载并安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simplepip install modelscope==1.11.0
pip install openai==1.17.1
pip install torch==2.1.2+cu121
pip install tqdm==4.64.1
pip install transformers==4.39.3
# 下载flash-attn 请等待大约10分钟左右~
MAX_JOBS=8 pip install flash-attn --no-build-isolation
pip install vllm==0.4.0.post1
直接安装 vLLM 会安装 CUDA 12.1 版本。
pip install vllm
如果需要在 CUDA 11.8 的环境下安装 vLLM,可以指定 vLLM 版本和 python 版本下载。
export VLLM_VERSION=0.4.0
export PYTHON_VERSION=38
pip install https://github.com/vllm-project/vllm/releases/download/v${VLLM_VERSION}/vllm-${VLLM_VERSION}+cu118-cp${PYTHON_VERSION}-cp${PYTHON_VERSION}-manylinux1_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu118
vLLM 对 torch 版本要求较高,且越高的版本对模型的支持更全,效果更好,所以新建一个全新的镜像。 https://www.codewithgpu.com/i/datawhalechina/self-llm/GLM-4
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
在 /root/model 路径下新建 model_download.py 文件并在其中输入以下内容,粘贴代码后请及时保存文件,如下图所示。并运行 python /root/model/model_download.py 执行下载,模型大小为 14GB。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
osmodel_dir = snapshot_download('ZhipuAI/glm-4-9b-chat', cache_dir='/root/model', revision='master')
代码准备
python 文件
在 /root/model 路径下新建 vllm_model.py 文件并在其中输入以下内容,粘贴代码后请及时保存文件。下面的代码有很详细的注释,大家如有不理解的地方,欢迎提出 issue。
首先从 vLLM 库中导入 LLM 和 SamplingParams 类。LLM 类是使用 vLLM 引擎运行离线推理的主要类。SamplingParams 类指定采样过程的参数,用于控制和调整生成文本的随机性和多样性。
vLLM 提供了非常方便的封装,我们直接传入模型名称或模型路径即可,不必手动初始化模型和分词器。
我们可以通过这个 demo 熟悉下 vLLM 引擎的使用方式。被注释的部分内容可以丰富模型的能力,但不是必要的,大家可以按需选择。
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
import os
import json# 自动下载模型时,指定使用modelscope。不设置的话,会从 huggingface 下载
# os.environ['VLLM_USE_MODELSCOPE']='True'def get_completion(prompts, model, tokenizer=None, max_tokens=512, temperature=0.8, top_p=0.95, max_model_len=2048):stop_token_ids = [151329, 151336, 151338]# 创建采样参数。temperature 控制生成文本的多样性,top_p 控制核心采样的概率sampling_params = SamplingParams(temperature=temperature, top_p=top_p, max_tokens=max_tokens, stop_token_ids=stop_token_ids)# 初始化 vLLM 推理引擎llm = LLM(model=model, tokenizer=tokenizer, max_model_len=max_model_len,trust_remote_code=True)outputs = llm.generate(prompts, sampling_params)return outputsif __name__ == "__main__": # 初始化 vLLM 推理引擎model='/root/model/ZhipuAI/glm-4-9b-chat' # 指定模型路径# model="THUDM/glm-4-9b-chat" # 指定模型名称,自动下载模型tokenizer = None# tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False) # 加载分词器后传入vLLM 模型,但不是必要的。# 修改后的文本内容text = ["请描述一下大型语言模型的最新进展。","提供一些提高编程技能的建议。"]outputs = get_completion(text, model, tokenizer=tokenizer, max_tokens=512, temperature=1, top_p=1, max_model_len=2048)# 输出是一个包含 prompt、生成文本和其他信息的 RequestOutput 对象列表。# 打印输出。for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")结果如下:
Prompt: '给我介绍一下大型语言模型。', Generated text: '大型语言模型是自然语言处理领域的一项突破性技术,它们通过分析和理解大量文本数据,学习如何生成和理解自然语言。这些模型通常具有数十亿甚至数万亿的参数,能够处理和理解复杂的语言结构,包括语法、语义和上下文关系。大型语言模型在多个领域有广泛的应用,包括文本生成、机器翻译、情感分析、问答系统和聊天机器人等。它们能够生成连贯的文本,提供准确的翻译,理解用户的查询,并生成相关的回答。这些模型的训练需要大量的计算资源和海量的数据。随着技术的进步,模型的规模和性能都在不断提高,使得它们在自然语言处理任务中的表现越来越接近人类水平。然而,它们也面临着一些挑战,包括偏见、泛化和解释性问题。未来,大型语言模型可能会在更多领域发挥作用,包括教育、医疗和创意产业等。它们有望成为人们日常生活和工作中不可或缺的一部分,提供更加智能和便捷的语言交互体验。'部署兼容 OpenAI API 的 vLLM 服务器
GLM4 模型与 OpenAI API 协议兼容,因此我们可以利用 vLLM 快速搭建一个符合 OpenAI API 标准的服务器。此服务器默认在 http://localhost:8000 上启动,并且一次只能服务一个模型。它支持模型列表查询、文本补全(completions)和对话补全(chat completions)等接口。
- 文本补全(completions):适用于基础的文本生成任务,模型会在给定提示后生成文本。常用于撰写文章、故事、邮件等。
- 对话补全(chat completions):专用于对话场景,模型需理解和生成对话内容。适用于开发聊天机器人或对话系统。
在部署服务器时,我们可以自定义多种参数,如模型名称、路径、聊天模板等。 --host和--port用于指定服务器的地址和端口。--model指定模型的路径。--chat-template用于指定对话的模板。--served-model-name设置服务中模型的名称。--max-model-len限制模型的最大处理长度。
由于 GLM4-9b-Chat 模型的最大长度较长(128K),为了避免 vLLM 初始化缓存时消耗过多资源,这里我们将--max-model-len设置为 2048。
python -m vllm.entrypoints.openai.api_server \--model /root/autodl-tmp/ZhipuAI/glm-4-9b-chat \--served-model-name glm-4-9b-chat \--max-model-len=2048 \--trust-remote-code
测试服务器
- 查看模型列表
使用 curl 命令向服务器发送请求,查看当前可用的模型列表。
返回如下结果:curl http://localhost:8000/v1/models{"object":"list","data":[{"id":"glm-4-9b-chat","object":"model","created":1717567231,"owned_by":"vllm","root":"glm-4-9b-chat","parent":null,"permission":[{"id":"modelperm-4fdf01c1999f4df1a0fe8ef96fd07c2f","object":"model_permission","created":1717567231,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}] } - 测试 OpenAI Completions API
通过 curl 命令测试文本补全功能。
收到的响应如下:curl http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "glm-4-9b-chat","prompt": "你好","max_tokens": 7,"temperature": 0}'
同样,您也可以使用 Python 脚本向 OpenAI Completions API 发送请求。如果标准 OpenAI API 功能无法满足您的需求,您可以根据 vLLM 官方文档中的说明,添加额外的参数{"id":"cmpl-8bba2df7cfa1400da705c58946389cc1","object":"text_completion","created":1717568865,"model":"glm-4-9b-chat","choices":[{"index":0,"text":",请问有什么可以帮助您的?您好","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":3,"total_tokens":10,"completion_tokens":7} }extra_body,例如传入stop_token_ids以控制生成过程。
更多信息请参考 vLLM 官方文档:https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html。
也可以用 python 脚本请求 OpenAI Completions API 。这里面设置了额外参数 extra_body,我们传入了 stop_token_ids 停止词 id。当 openai api 无法满足时可以采用 vllm 官方文档方式添加。https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1",api_key="token-abc123", # 随便设,只是为了通过接口参数校验
)completion = client.chat.completions.create(model="glm-4-9b-chat",messages=[{"role": "user", "content": "你好"}],# 设置额外参数extra_body={"stop_token_ids": [151329, 151336, 151338]}
)print(completion.choices[0].message)
得到的返回值如下所示:
ChatCompletionMessage(content='\n你好👋!很高兴见到你,有什么可以帮助你的吗?', role='assistant', function_call=None, tool_calls=None)
- 用 curl 命令测试 OpenAI Chat Completions API 。
curl http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{ "model": "glm-4-9b-chat","messages": [ {"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "你好"}],"max_tokens": 7, "temperature": 0 }'
得到的返回值如下所示:
{"id":"cmpl-8b02ae787c7747ecaf1fb6f72144b798","object":"chat.completion","created":1717569334,"model":"glm-4-9b-chat","choices":[{"index":0,"message":{"role":"assistant","content":"\n你好👋!很高兴"},"logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":16,"total_tokens":23,"completion_tokens":7}
也可以用 python 脚本请求 OpenAI Chat Completions API 。
from openai import OpenAIopenai_api_key = "EMPTY" # 随便设,只是为了通过接口参数校验openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)chat_outputs = client.chat.completions.create(model="glm-4-9b-chat",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "你好"},],# 设置额外参数extra_body={"stop_token_ids": [151329, 151336, 151338]}
)
print(chat_outputs)
在处理请求时 API 后端也会打印一些日志和统计信息。
相关文章:

GLM+vLLM 部署调用
GLMvLLM 部署调用 vLLM 简介 vLLM 框架是一个高效的大型语言模型(LLM)推理和部署服务系统,具备以下特性: 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了…...

leetcode 122 买卖股票的最佳时机||(动态规划解法)
题目分析 题目描述的已经十分清楚了,不做过多阐述 算法原理 状态表示 我们假设第i天的最大利润是dp[i] 我们来画一下状态机 有两个状态,买入后和卖出后,我们就可以使用两个dp表来解决问题 f[i]表示当天买入后的最大利润 g[i]表示当天卖出…...

C++设计模式---组合模式
1、介绍 组合模式(Composite)是一种结构型设计模式,也被称为部分-整体模式。它将复杂对象视为由多个简单对象(称为“组件”)组成的树形结构,这些组件能够共享相同的行为。每个组件都可能包含一个或多个子组…...
C/C++版本)
工厂方法模式(大话设计模式)C/C++版本
工厂方法模式 C 参考:https://www.cnblogs.com/Galesaur-wcy/p/15926711.html #include <iostream> #include <memory> using namespace std;// 运算类 class Operation { private:double _NumA;double _NumB;public:void SetNumA(){cout << &…...

[NCTF 2018]flask真香
打开题目后没有提示框,尝试扫描后也没有什么结果,猜想是ssti。所以尝试寻找ssti的注入点并判断模版。 模版判断方式: 在url地址中输入{7*7} 后发现不能识别执行。 尝试{{7*7}} ,执行成功,继续往下走注入{{7*7}},如果执…...

性能测试3【搬代码】
1.Linux服务器性能分析命令及详解 2.GarafanainfluxDB监控jmeter数据 3.GarafanaPrometheus监控服务器和数据库性能 4.性能瓶颈分析以及性能调优方案详解 一、无界面压测时, top load average:平均负载 htop 二、Garafana监控平台 传统项目:centosphpm…...

<tesseract><opencv><Python>基于python和opencv,使用ocr识别图片中的文本并进行替换
前言 本文是在python中,利用opencv处理图片,利用tesseractOCR来识别图片中的文本并进行替换的一种实现方法。 环境配置 系统:windows 平台:visual studio code 语言:python 库:pyqt5、opencv、tesseractOCR 代码介绍 本文程序功能实现,主要依赖于tesseractOCR这个库,…...

海南云亿商务咨询有限公司解锁抖音电商新纪元
在当今数字化浪潮中,抖音电商以其独特的魅力和强大的用户基础,迅速成为企业营销的新宠。海南云亿商务咨询有限公司,作为专注于抖音电商服务的领先企业,凭借专业的团队和丰富的经验,为众多企业提供了高效、精准的电商服…...
)
arm64架构 统信UOS搭建PXE无盘启动Linux系统(麒麟桌面为例)
arm64架构 统信UOS搭建PXE无盘启动Linux系统(麒麟桌面为例) 搞了好久搞得头疼哎 1、准备服务器UOS服务器 准备服务IP 这里是192.168.1.100 1.1、安装程序 yum install -y dhcp tftp tftp-server xinetd nfs-utils rpcbind 2、修改配置 2.1、修改dhcpd.c…...
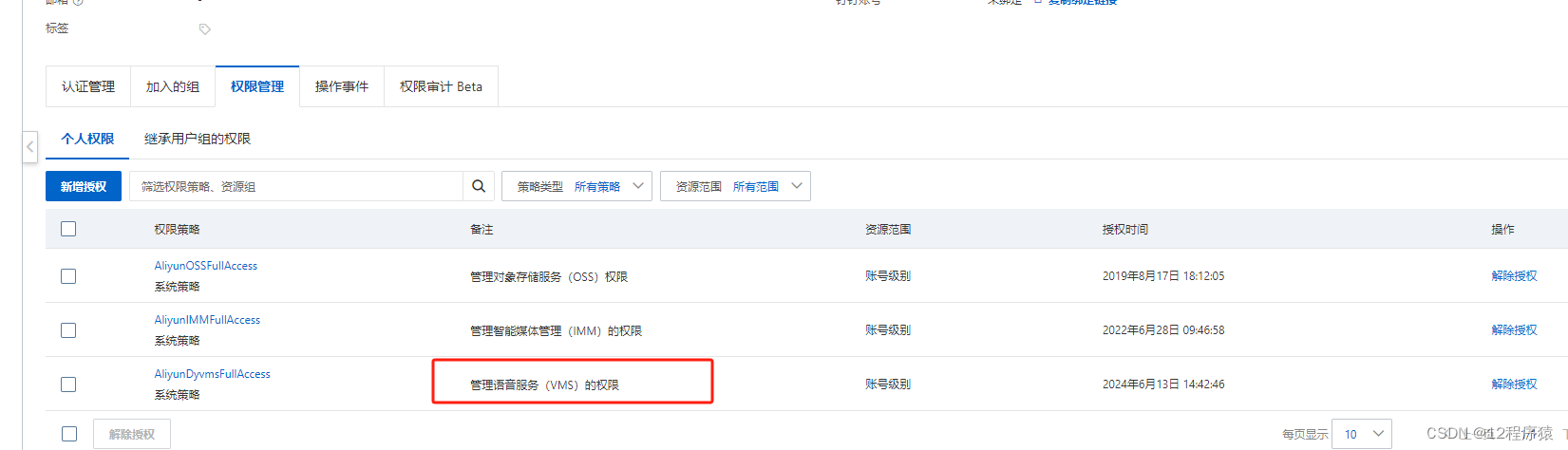
SpringBoot 实现 阿里云语音通知(SingleCallByTts)
目录 一、准备工作1.开通 阿里云语音服务2.申请企业资质3.创建语音通知模板,审核通过4.调用API接口---SingleCallByTts5.调试API接口---SingleCallByTts 二、代码实现1.导入依赖 com.aliyun:aliyun-java-sdk-dyvmsapi:3.0.22.创建工具类,用于发送语音通知…...
IDEA 连接GitHub仓库并上传项目(同时解决SSH问题)
目录 1 确认自己电脑上已经安装好Git 2 添加GitHub账号 2.1 Setting -> 搜索GitHub-> ‘’ -> Log In with Token 2.2 点击Generate 去GitHub生成Token 2.3 勾选SSH后其他不变直接生成token 2.4 然后复制token添加登录账号即可 3 点击导航栏中VCS -> Create…...

vue/react/js 常用的原生获取当前页面的url网址的相关方法
目录 第一章 场景 第二章 总结 第一章 场景 最近实现需求时遇到这么一种情况: 本地url —— 线上url —— 需求:需要将token清除掉 注意事项:token不是#/后面的参数,说明并不是我们前端返回的,vue路由的方法使用不…...

java-final 关键字
## Java中的final关键字 ### 1. final关键字的基本概念 final是Java中一个非常重要的关键字,用于声明常量、阻止继承和重写,确保类、方法和变量的不可变性。具体来说,final关键字可以用来修饰类、方法和变量(包括成员变量和局部…...
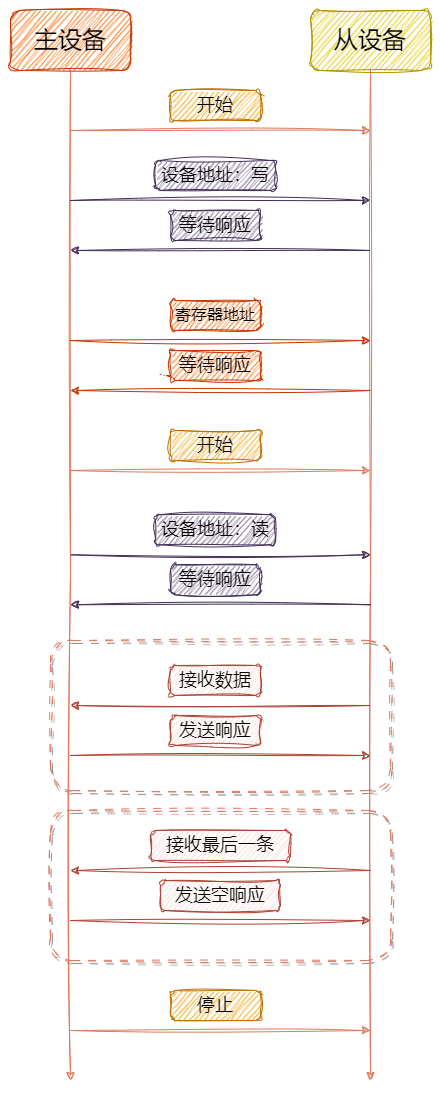
ARM32开发--IIC软实现
知不足而奋进 望远山而前行 目录 文章目录 前言 开发流程 GD32F4软件I2C初始化 GD32F4软件I2C引脚功能 写操作 读操作 总结 前言 在嵌入式系统开发中,软件实现的I2C通信协议扮演着至关重要的角色。本文将深入探讨如何在GD32F4系列微控制器上实现软件I2C功能…...
中实现拓扑排序与最短路径和最长路径算法)
在有向无环图(DAG)中实现拓扑排序与最短路径和最长路径算法
有向无环图(DAG)是一类非常重要的图结构,广泛应用于任务调度、数据依赖分析等领域。本文将介绍如何在DAG中实现拓扑排序、单源最短路径和单源最长路径算法,并提供完整的Java代码示例。 图结构定义 首先,我们定义一个…...

SQLServer按照年龄段进行分组查询数据
1.按照年龄段对数据进行分组, 将人群分为:青年,中年,老年三种类型,人群类型加上其他分组字段如:性别,进行多条件分组,统计各个年龄段多少人 Select case sex when 1 then ‘男’ when 2 then …...

开放式耳机哪个品牌质量比较好?2024高性价比机型推荐!
随着音乐技术的不断发展,开放式耳机已成为音乐发烧友们的另外一种选择。从最初的简单音质,到如今的高清解析,开放式耳机不断进化升级。音质纯净,佩戴舒适,无论是街头漫步还是家中放松时候,都能带给你身临其…...

Blender骨骼创建
骨骼系统 建立 使用Shift A添加骨骼或在添加|骨架中添加一段骨骼 骨骼的三种模式 -物体模式:做动画,摆人物pose时在该模式 -编辑模式:进行骨骼搭建(选择一段骨骼,然后按E挤出一段骨骼并进行调整) -姿…...
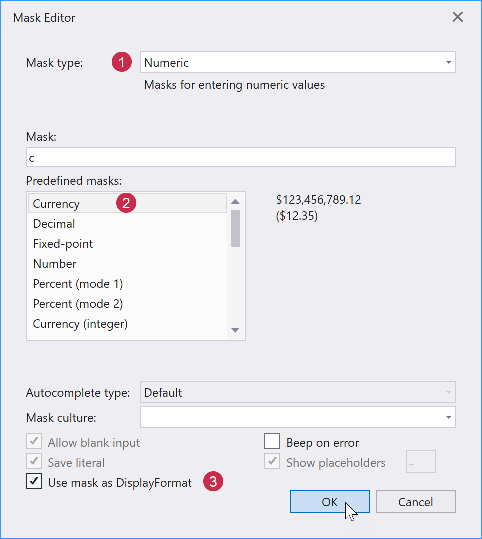
DevExpress WPF中文教程:Grid - 如何完成列和编辑器配置(设计时)?
DevExpress WPF拥有120个控件和库,将帮助您交付满足甚至超出企业需求的高性能业务应用程序。通过DevExpress WPF能创建有着强大互动功能的XAML基础应用程序,这些应用程序专注于当代客户的需求和构建未来新一代支持触摸的解决方案。 无论是Office办公软件…...

高考完的三个月想自学点编程,有没有什么建议
👆点击关注 获取更多编程干货👆 对于刚刚完成高考的学生来说,无论未来是否选择计算机科学作为专业方向,自学编程技能是一项非常有价值的投资,掌握编程知识能够帮助同学们为将来的学习和科研 实践奠定一个基础。 随着…...

Qwen2.5-14B-Instruct入门指南:像素剧本圣殿UI组件与剧本结构映射关系解析
Qwen2.5-14B-Instruct入门指南:像素剧本圣殿UI组件与剧本结构映射关系解析 1. 工具概览与核心价值 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct大模型深度优化的专业剧本创作工具。它将AI强大的文本生成能力与独特的…...
)
告别PX4,试试APM!用ArduPilot+Gazebo搭建你的第一个无人机仿真环境(附QGC地面站连接)
从PX4到APM:ArduPilot无人机仿真环境全攻略 如果你已经熟悉PX4生态,却对ArduPilot(APM)固件在仿真领域的表现充满好奇,这篇文章将为你打开一扇新的大门。不同于市面上大量聚焦PX4的教程,我们将深入探讨APM在…...

QuickBMS深度解析:游戏资源提取与逆向工程的终极工具箱
QuickBMS深度解析:游戏资源提取与逆向工程的终极工具箱 【免费下载链接】QuickBMS QuickBMS by aluigi - Github Mirror 项目地址: https://gitcode.com/gh_mirrors/qui/QuickBMS 在游戏开发和逆向工程领域,面对数百种不同的压缩格式、加密算法和…...

不露脸也能当主播?一文了解VTuber
不露脸也能当主播?一文了解VTuber很多人提到 VTuber,脑子里就是“二次元纸片人”在直播间卖萌。 但其实,你每天换的微信头像、用过的苹果拟我表情,短视频平台的3D头套全都是它的“远房亲戚”。 今天我们就把这层科技外衣扒开&…...

为什么你的Java车载服务在-40℃冷启动失败?温度敏感型ClassLoader加载异常的12小时紧急修复路径
第一章:为什么你的Java车载服务在-40℃冷启动失败?温度敏感型ClassLoader加载异常的12小时紧急修复路径低温环境并非仅影响硬件可靠性——JVM 的类加载机制在极端低温下会触发底层文件系统与内存映射的隐式行为偏移。某车规级 Java 服务在-40℃冷启动时反…...

SEO优化对网站收录有什么作用
SEO优化对网站收录有什么作用 在当今互联网信息爆炸的时代,网站的收录问题显得尤为重要。SEO优化对于网站的收录有着至关重要的作用,无论是对于新开的网站还是已经运营一段时间的网站,优化都能为其带来更多的流量和潜在客户。SEO优化对网站收…...

ESP32 ILI9341高性能驱动:64字节DMA突发传输优化
1. 项目概述ILI9341_ESP32 是一款专为 ESP32 平台深度优化的 ILI9341 TFT LCD 显示驱动库。其核心设计目标并非简单实现显示功能,而是在硬件能力边界内榨取极致帧率与响应性能。该库直面 ESP32 的 SPI 总线特性——支持 64 字节一次性突发传输(burst tra…...

C语言回调函数在TCP客户端中的应用与实践
1. 回调函数基础概念解析回调函数是C语言中一种强大的编程机制,它允许我们将函数作为参数传递给其他函数。这种设计模式在现代编程中极为常见,特别是在事件驱动编程、异步操作和模块化设计中。1.1 回调函数的本质回调函数本质上是一个通过函数指针调用的…...
)
5分钟搞懂FGSM:用Python手把手教你生成第一个对抗样本(附代码)
5分钟搞懂FGSM:用Python手把手教你生成第一个对抗样本(附代码) 对抗样本生成听起来像是黑客的专属技能,但今天我要告诉你:用不到10行Python代码就能实现。去年我在一个图像识别项目中第一次遭遇对抗样本攻击——系统将…...

一键捕获完整网页:Full Page Screen Capture 高效解决方案
一键捕获完整网页:Full Page Screen Capture 高效解决方案 【免费下载链接】full-page-screen-capture-chrome-extension One-click full page screen captures in Google Chrome 项目地址: https://gitcode.com/gh_mirrors/fu/full-page-screen-capture-chrome-e…...