基于某评论的TF-IDF下的LDA主题模型分析
完整代码:
import numpy as np
import re
import pandas as pd
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocationdf1 = pd.read_csv('小红书评论.csv') # 读取同目录下csv文件
# df1 = df1.drop_duplicates(subset=['用户id']) # 获取一个id只评论一次的数据
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
df1['cut'] = df1['内容'].apply(lambda x: str(x))
df1['cut'] = df1['cut'].apply(lambda x: re.sub(pattern, ' ', x)) #对评论内容作清洗,只保留中文汉字,生成新的cut行
df1['cut'] = df1['cut'].apply(lambda x: " ".join(jieba.lcut(x))) #对评论内容作分词和拼接
print(df1['cut'])
print(type(df1['cut']))# 1.构造TF-IDF
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df1['cut'])
# 2.特征词列表
feature_names = tf_idf_vectorizer.get_feature_names_out()
# 3.将特征矩阵转变为pandas DataFrame
matrix = tf_idf.toarray()
feature_names_df = pd.DataFrame(matrix,columns=feature_names)
print(feature_names_df)
# 所有的特征词组成列,所有的评论组成行,矩阵中的元素表示这个特征词在该评论中所占的重要性,即tf-idf值,0表示该句评论中没有该词。n_topics = 5
# 定义LDA对象
lda = LatentDirichletAllocation(n_components=n_topics,max_iter=50,learning_method='online',learning_offset=50.,random_state=0
)
# 核心,将TF-IDF矩阵放入LDA模型中
lda.fit(tf_idf)#第1部分
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 50
def top_words_data_frame(model: LatentDirichletAllocation,tf_idf_vectorizer: TfidfVectorizer,n_top_words: int) -> pd.DataFrame:rows = []feature_names = tf_idf_vectorizer.get_feature_names_out()for topic in model.components_:top_words = [feature_names[i]for i in topic.argsort()[:-n_top_words - 1:-1]]rows.append(top_words)columns = [f'topic {i + 1}' for i in range(n_top_words)]df = pd.DataFrame(rows, columns=columns)return df#2
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:matrix = model.transform(X)columns = [f'P(topic {i + 1})' for i in range(len(model.components_))]df = pd.DataFrame(matrix, columns=columns)return df# 要输出的每个主题的前 n_top_words 个主题词数# 计算 n_top_words 个主题词
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)# 获取五个主题的前五十个特征词
print(top_words_df)# 转 tf_idf 为数组,以便后面使用它来对文本主题概率分布进行计算
X = tf_idf.toarray()# 计算完毕主题概率分布情况
predict_df = predict_to_data_frame(lda, X)# 获取五个主题,对于每个评论,分别属于这五个主题的概率
print(predict_df)
import pyLDAvis
import pyLDAvis.sklearnpanel = pyLDAvis.sklearn.prepare(lda, tf_idf, tf_idf_vectorizer)
pyLDAvis.save_html(panel, 'lda_visualization.html')
pyLDAvis.display(panel)一、数据清洗
代码逐行讲解:
df1 = pd.read_csv('小红书评论.csv') # 读取同目录下csv文件
# df1 = df1.drop_duplicates(subset=['用户id']) # 获取一个id只评论一次的数据
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
df1['cut'] = df1['内容'].apply(lambda x: str(x))
df1['cut'] = df1['cut'].apply(lambda x: re.sub(pattern, ' ', x)) #对评论内容作清洗,只保留中文汉字,生成新的cut行
df1['cut'] = df1['cut'].apply(lambda x: " ".join(jieba.lcut(x))) #对评论内容作分词和拼接
print(df1['cut'])
print(type(df1['cut']))读取同目录下的文件,df1是数据框格式
提取评论内容,并对评论内容做清洗,采用正则表达式,去除标点和英文。
用jieba对每一行的数据作分词处理,最后得到的数据展现以及数据类型。

二、模型构建
tf_idf_vectorizer = TfidfVectorizer()
tf_idf = tf_idf_vectorizer.fit_transform(df1['cut'])
# 2.特征词列表
feature_names = tf_idf_vectorizer.get_feature_names_out()
# 3.将特征矩阵转变为pandas DataFrame
matrix = tf_idf.toarray()
feature_names_df = pd.DataFrame(matrix,columns=feature_names)
print(feature_names_df)
# 所有的特征词组成列,所有的评论组成行,矩阵中的元素表示这个特征词在该评论中所占的重要性,即tf-idf值,0表示该句评论中没有该词。# 定义LDA对象
n_topics = 5
lda = LatentDirichletAllocation(n_components=n_topics, max_iter=50,learning_method='online',learning_offset=50.,random_state=0
)
# 核心,将TF-IDF矩阵放入LDA模型中
lda.fit(tf_idf)-
tf_idf_vectorizer = TfidfVectorizer()- 这行代码创建了一个
TfidfVectorizer对象,这是scikit-learn库中的一个文本向量化工具。它将文本数据转换为TF-IDF特征矩阵,这是一种常用的文本表示形式,能够反映出文本中单词的重要性。
- 这行代码创建了一个
-
tf_idf = tf_idf_vectorizer.fit_transform(df1['cut'])- 这行代码执行了两个操作:
fit: 根据提供的文本数据(df1['cut'])来学习词汇表和计算IDF(逆文档频率)。transform: 使用学习到的词汇表和IDF来转换文本数据为TF-IDF矩阵。结果tf_idf是一个稀疏矩阵,其中每一行代表一个文档,每一列代表一个单词,矩阵中的值表示该单词在文档中的重要性(TF-IDF权重)。
- 这行代码执行了两个操作:
-
# 定义LDA对象- 这是一个注释行,说明接下来的代码将定义一个LDA(隐狄利克雷分配)模型对象。
-
n_topics = 5- 这行代码设置了一个变量
n_topics,其值为5,表示LDA模型中的主题数量。
- 这行代码设置了一个变量
-
lda = LatentDirichletAllocation( ...)- 这行代码创建了一个
LatentDirichletAllocation对象,即LDA模型,用于主题建模。它接受多个参数:n_components=n_topics: 设置模型中的主题数量,这里与之前定义的n_topics变量相等。max_iter=50: 设置模型训练的最大迭代次数。learning_method='online': 指定学习算法,这里使用在线学习算法。learning_offset=50.: 在线学习算法中的学习偏移量。random_state=0: 设置随机状态,以确保结果的可重复性。
- 这行代码创建了一个
-
lda.fit(tf_idf)- 这行代码将之前转换得到的TF-IDF矩阵
tf_idf用于训练LDA模型。fit方法将根据文档-词项矩阵和设置的主题数量来学习文档的主题分布以及词项在各个主题下的分布。
- 这行代码将之前转换得到的TF-IDF矩阵
总的来说,这段代码的目的是使用LDA模型来发现文档集合中的潜在主题。首先,它通过TF-IDF向量化器将文本数据转换为数值矩阵,然后使用这个矩阵来训练LDA模型,最后可以通过模型来分析文档的主题分布。
打印出来的结果为:
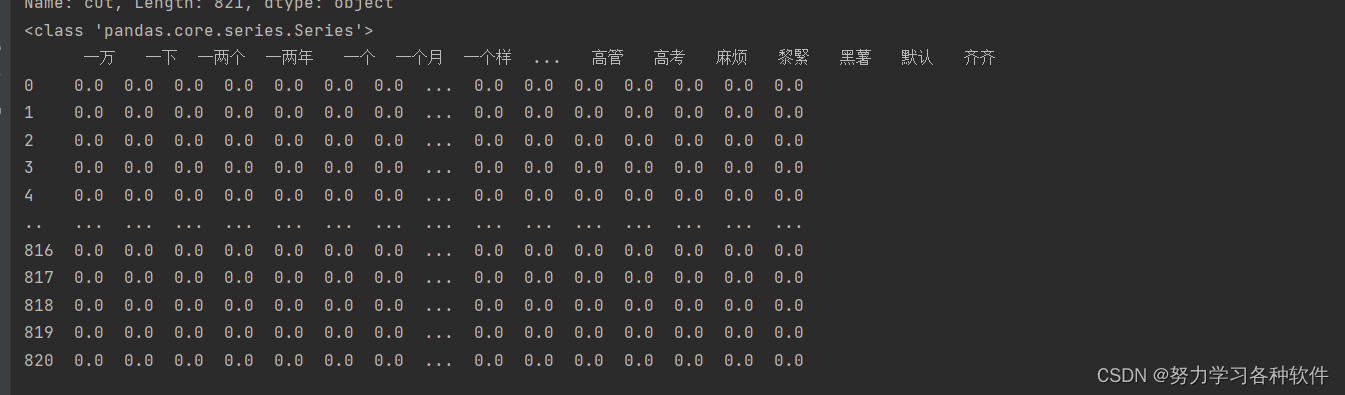
三、结果展现
#第1部分
# 要输出的每个主题的前 n_top_words 个主题词数
n_top_words = 50
def top_words_data_frame(model: LatentDirichletAllocation,tf_idf_vectorizer: TfidfVectorizer,n_top_words: int) -> pd.DataFrame:rows = []feature_names = tf_idf_vectorizer.get_feature_names_out()for topic in model.components_:top_words = [feature_names[i]for i in topic.argsort()[:-n_top_words - 1:-1]]rows.append(top_words)columns = [f'topic {i + 1}' for i in range(n_top_words)]df = pd.DataFrame(rows, columns=columns)return df#2
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:matrix = model.transform(X)columns = [f'P(topic {i + 1})' for i in range(len(model.components_))]df = pd.DataFrame(matrix, columns=columns)return df# 要输出的每个主题的前 n_top_words 个主题词数# 计算 n_top_words 个主题词
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)# 获取五个主题的前五十个特征词
print(top_words_df)# 转 tf_idf 为数组,以便后面使用它来对文本主题概率分布进行计算
X = tf_idf.toarray()# 计算完毕主题概率分布情况
predict_df = predict_to_data_frame(lda, X)# 获取五个主题,对于每个评论,分别属于这五个主题的概率
print(predict_df)这段代码是用于分析和可视化LDA(Latent Dirichlet Allocation,隐狄利克雷分配)模型的输出结果的。以下是对代码的逐行解释:
这部分代码定义了两个函数,用于处理和展示LDA模型的结果。
-
n_top_words = 50- 设置变量
n_top_words为50,表示每个主题中要提取的前50个最重要的词。
- 设置变量
-
def top_words_data_frame(...) -> pd.DataFrame:- 定义了一个名为
top_words_data_frame的函数,它接受一个LDA模型、一个TF-IDF向量化器和一个整数n_top_words作为参数,并返回一个包含每个主题的前n_top_words个词的DataFrame。
- 定义了一个名为
-
rows = []- 初始化一个空列表
rows,用于存储每个主题的顶级词汇。
- 初始化一个空列表
-
feature_names = tf_idf_vectorizer.get_feature_names_out()- 从TF-IDF向量化器中获取词汇表,以便知道每个特征索引对应的词。
-
for topic in model.components_:- 遍历LDA模型的每个主题。
-
top_words = [feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1])- 对每个主题,获取其权重数组的排序索引,然后选择前
n_top_words个索引对应的词。
- 对每个主题,获取其权重数组的排序索引,然后选择前
-
rows.append(top_words)- 将每个主题的顶级词汇列表添加到
rows列表中。
- 将每个主题的顶级词汇列表添加到
-
columns = [f'topic {i + 1}' for i in range(n_top_words)]- 创建DataFrame的列名,表示每个主题的顶级词汇。
-
df = pd.DataFrame(rows, columns=columns)- 使用
rows数据和columns列名创建一个DataFrame。
- 使用
-
return df- 返回包含每个主题顶级词汇的DataFrame。
这部分代码使用LDA模型对文档进行主题预测,并展示结果。
-
def predict_to_data_frame(model: LatentDirichletAllocation, X: np.ndarray) -> pd.DataFrame:- 定义了一个名为
predict_to_data_frame的函数,它接受一个LDA模型和一个NumPy数组X作为参数,并返回一个包含文档主题概率分布的DataFrame。
- 定义了一个名为
-
matrix = model.transform(X)- 使用LDA模型的
transform方法将文档集X转换为每个文档的主题概率分布矩阵。
- 使用LDA模型的
-
columns = [f'P(topic {i + 1})' for i in range(len(model.components_))]- 创建列名,表示每个文档属于每个主题的概率。
-
df = pd.DataFrame(matrix, columns=columns)- 使用转换得到的主题概率矩阵和列名创建一个DataFrame。
-
return df- 返回包含文档主题概率分布的DataFrame。
这部分代码执行了上述定义的函数,并打印了结果。
-
top_words_df = top_words_data_frame(lda, tf_idf_vectorizer, n_top_words)- 调用
top_words_data_frame函数,获取LDA模型的每个主题的前50个词。
- 调用
-
print(top_words_df)- 打印每个主题的前50个词。
-
X = tf_idf.toarray()- 将TF-IDF矩阵转换为一个NumPy数组,以便用于主题预测。
-
predict_df = predict_to_data_frame(lda, X)- 调用
predict_to_data_frame函数,获取文档的主题概率分布。
- 调用
-
print(predict_df)- 打印每个文档属于每个主题的概率。
这段代码的目的是分析LDA模型的结果,展示每个主题的代表性词汇以及文档的主题概率分布,从而帮助理解文档集合中的潜在主题结构。
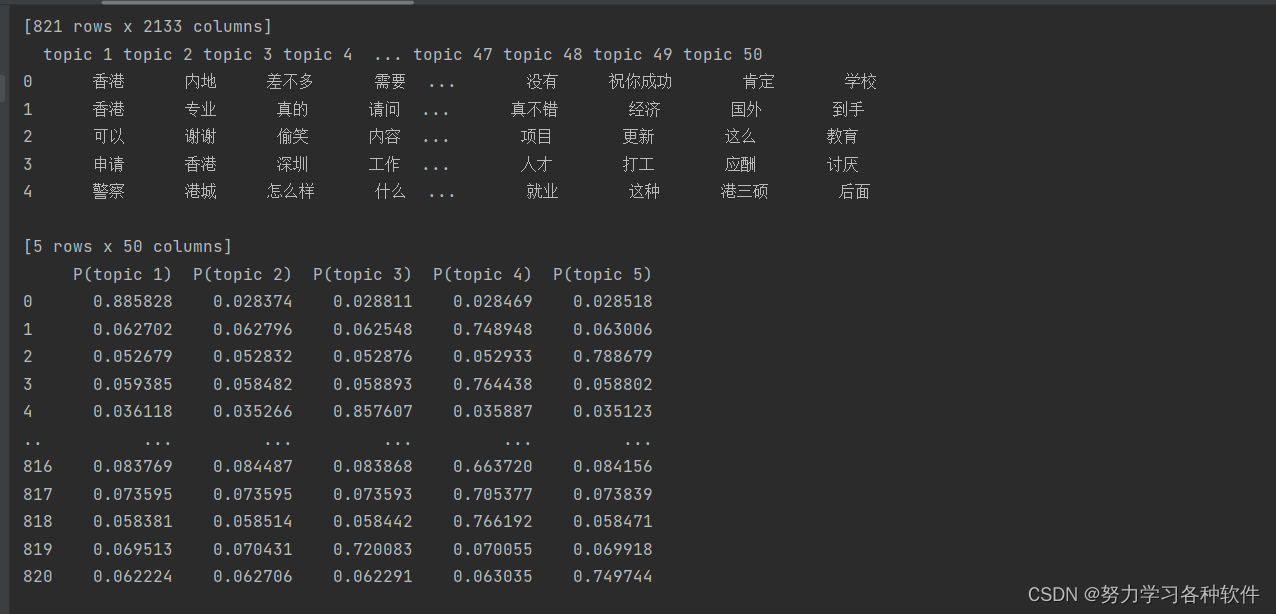
四、可视化分析
# 获取五个主题,对于每个评论,分别属于这五个主题的概率
print(predict_df)
import pyLDAvis
import pyLDAvis.sklearnpanel = pyLDAvis.sklearn.prepare(lda, tf_idf, tf_idf_vectorizer)
pyLDAvis.save_html(panel, 'lda_visualization.html')
pyLDAvis.display(panel)结果展现:
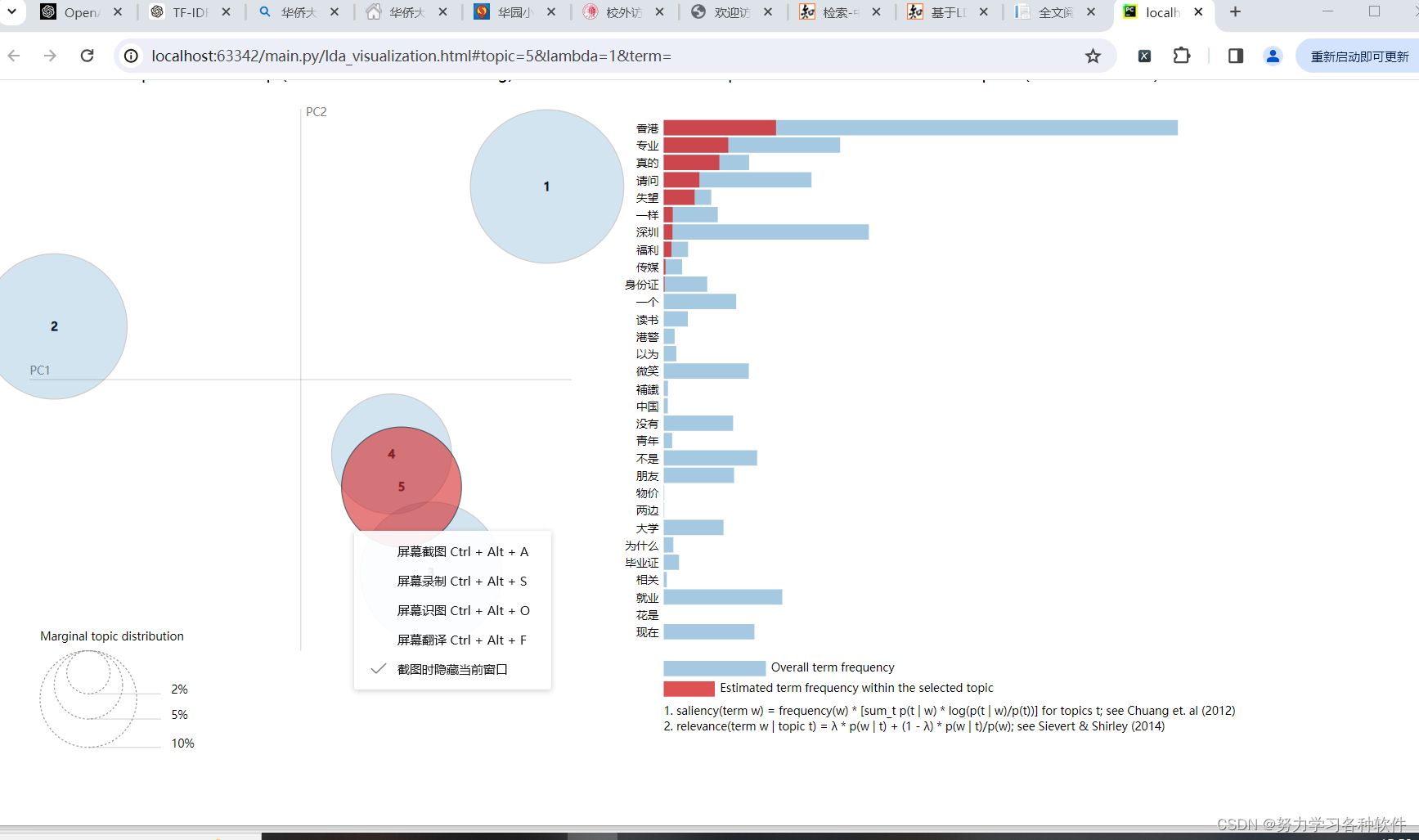
五、词云图分析
另写代码,加入停用词后,对数据内容作词云图分析:
import numpy as np
import re
import pandas as pd
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
from wordcloud import WordCloud # 导入 WordCloud 类
import matplotlib.pyplot as plt# 读取小红书评论数据
df1 = pd.read_csv('小红书评论.csv')
pattern = u'[\\s\\d,.<>/?:;\'\"[\\]{}()\\|~!\t"@#$%^&*\\-_=+a-zA-Z,。\n《》、?:;“”‘’{}【】()…¥!—┄-]+'
df1['cut'] = df1['内容'].apply(lambda x: str(x))
df1['cut'] = df1['cut'].apply(lambda x: re.sub(pattern, ' ', x))# 定义停用词列表,将你、了、的、我、你等常见词加入其中
stop_words = set(['你', '了', '的', '我', '你', '他', '她', '它','是','有','哭','都','吗','也','啊'])# 分词并过滤停用词
df1['cut'] = df1['cut'].apply(lambda x: " ".join([word for word in jieba.lcut(x) if word not in stop_words]))# 生成小红书评论的词云图
def generate_wordcloud(text):wordcloud = WordCloud(background_color='white', font_path='msyh.ttc').generate(text)plt.figure()plt.imshow(wordcloud, interpolation="bilinear")plt.title("小红书评论词云")plt.axis("off")plt.show()# 获取小红书评论的文本
all_comments_text = ' '.join(df1['cut'])# 生成词云图
generate_wordcloud(all_comments_text)结果展现:
数据我在上方绑定了,需要可自取。
相关文章:
基于某评论的TF-IDF下的LDA主题模型分析
完整代码: import numpy as np import re import pandas as pd import jieba from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.decomposition import LatentDirichletAllocationdf1 pd.read_csv(小红书评论.csv) # 读取同目录下csv文件…...

四、Nginx配置文件-负载均衡
目录 一、负载均衡的作用 二、负载均衡状态 三、负载均衡的指令 1、upstream 指令 2、server指令 四、负载均衡几种方式 1、轮询(Round Robin 常用) 2、IP Hash (较少) 3、最少连接数(Least Connections 较少&…...
ofd文件预览
文件列表 <template><div><div classfile v-if$myUtils.coll.isNotEmpty(filesList)><div classfile-view><div classfile-view-item :style{justifyContent: align } v-for(item, index) in filesList :keyindex><img classfile-view-item-…...
)
浅浅了解下Spring中生命周期函数(Spring6全攻略)
你好,这里是codetrend专栏“Spring6全攻略”。 Spring框架设计生命周期回调函数的主要目的是为了提供一种机制,使开发人员能够在对象创建、初始化和销毁等生命周期阶段执行特定的操作。这种机制可以帮助开发人员编写更加灵活和可维护的代码。 举个例子…...
建议收藏!亚马逊卖家必须知道的37个常用术语解释
运营亚马逊,经常会看到很多个专业术语,想必大部分新手卖家都比较陌生,熟悉这些常用术语的含义有助于你更好地运营亚马逊。下面为各位整理了37个在亚马逊跨境电商中常见的术语及其解释,建议收藏! 1、SKU Stock Keeping…...
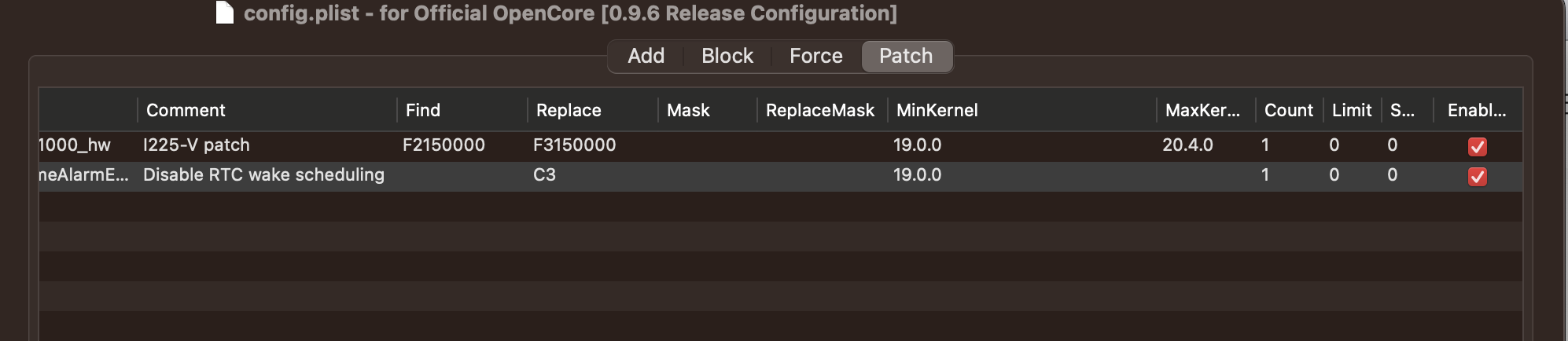
黑苹果睡眠总是自动唤醒(RTC)
黑苹果睡眠总是自动唤醒【RTC】 1. 问题2. 解决方案2.1. 查看重启日志2.2. 配置Disable RTC wake scheduling补丁 3. 后续4. 参考 1. 问题 黑苹果EFI 更换后,总是在手动 睡眠后,间歇性重启,然后再次睡眠,然后再重启。原因归结为&…...

【代码随想录训练营】【Day 49+】【动态规划-8】| Leetcode 121, 122, 123
【代码随想录训练营】【Day 49】【动态规划-8】| Leetcode 121, 122, 123 需强化知识点 买卖股票系列 题目 121. 买卖股票的最佳时机 动态规划贪心:记录左侧的最小值 class Solution:def maxProfit(self, prices: List[int]) -> int:# n len(prices)# # 0…...
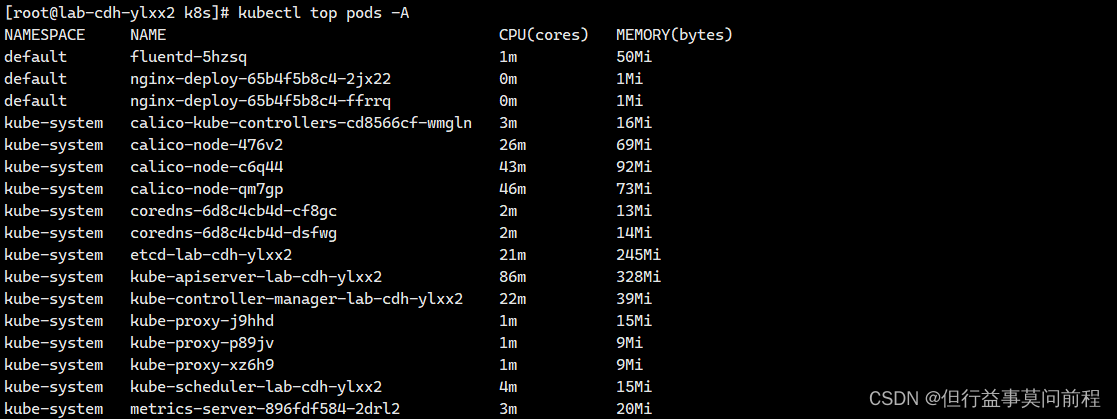
k8s metrics-server服务监控pod 的 cpu、内存
项目场景: 需要开启指标服务,依据pod 的 cpu、内存使用率进行自动的扩容或缩容 pod 的数量 解决方案: 下载 metrics-server 组件配置文件: wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/…...

电脑自带录屏在哪?电脑录屏,4个详细方法
在现代社会中,越来越多的人需要在电脑上录制视频,比如录制游戏操作、制作教学视频、演示文稿等等。因此,电脑录屏成为了一项非常重要的功能。那么电脑自带录屏在哪?本文将带领大家看看可以使用哪些方法进行录屏。 录屏方法一&…...
[Cloud Networking] Layer3 (Continue)
文章目录 1. DHCP Protocol1.1 DHCP 三种分配方式1.2 DHCP Relay (中继) 2. 路由协议 (Routing Protocol)2.1 RIP (Routing Information Protocol)2.2 OSPF Protocol2.2.1 OSPF Area2.2.2 Route ID / DR / BDR2.2.3 LSA / OSPF 邻居表 / LSDB / OSPF路由表 2.3 BGP Protocol2.4…...

missing authentication credentials for REST request
1、报错截图 2、解决办法 将elasticsearch的elasticsearch.yml的 xpack.security.enabled: true 改为 xpack.security.enabled: false...
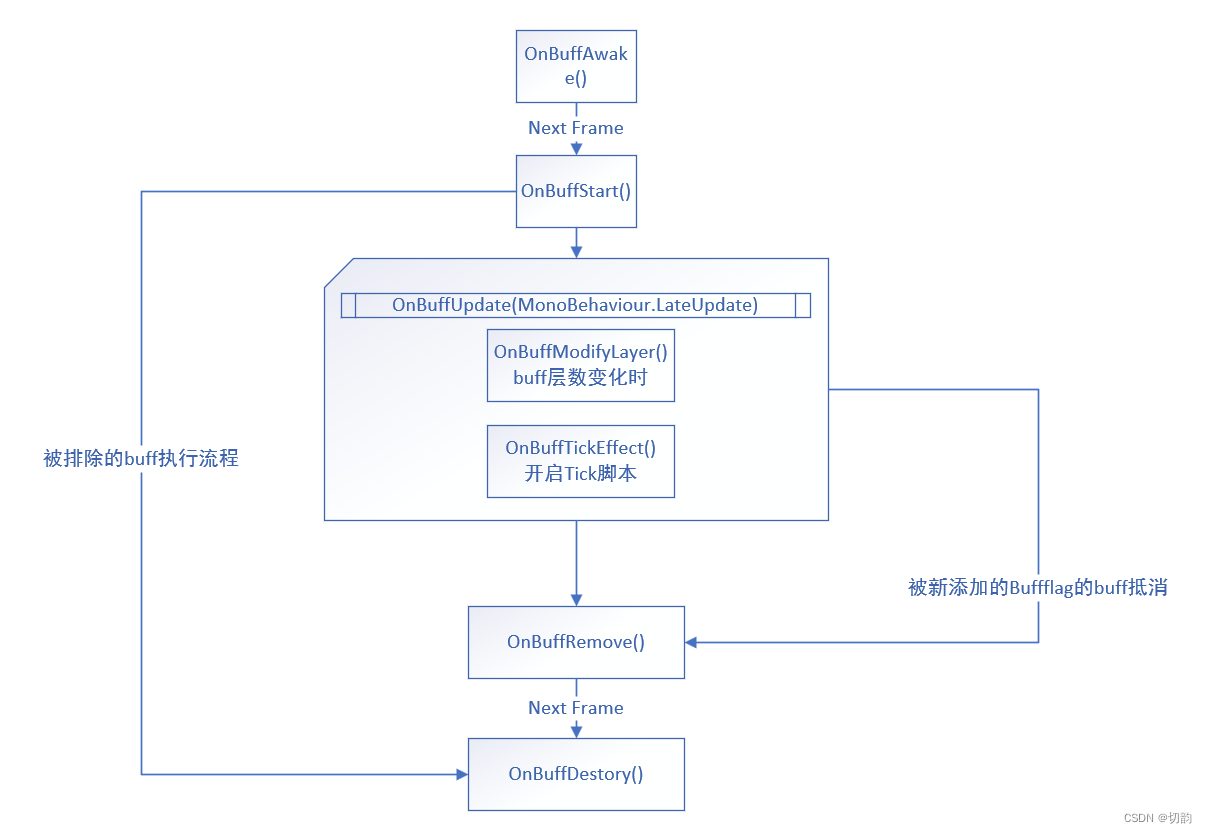
Unity 从0开始编写一个技能编辑器_02_Buff系统的生命周期
工作也有一年了,对技能编辑器也有了一些自己的看法,从刚接触时的惊讶,到大量工作时觉得有一些设计的冗余,在到特殊需求的修改,运行效率低时的优化,技能编辑器在我眼中已经不再是神圣不可攀的存在的…...

计算机网络简答题
第一章 计算机网络 1.因特网是一个世界范围的计算机网络,记一个互联了遍及全世界的计算机设备的网络。 2.计算机网络将众多分散的、自治的(一台坏了不影响其他)计算机系统,通过通信设备与线路连接起来,由功能完善的软件实现资源共享和信息传递的系统。 3.计算机网络的组…...

探索Java 8 Stream API:现代数据处理的新纪元
Stream流 Stream初探:何方神圣? Stream流是一种处理集合数据的高效工具,它可以让你以声明性的方式处理数据集合。Stream不是存储数据的数据结构,而是对数据源(如集合、数组)的运算操作概念,支…...

vim 删除光标到最后一行的所有内容
在 Vim 中删除从光标所在位置到文件末尾的所有内容 删除从光标所在位置到文件末尾的所有内容使用 dG 命令 参考 删除从光标所在位置到文件末尾的所有内容 使用 dG 命令 确保你在正常模式下(按 Esc 键)。移动光标到你想要开始删除的位置。输入以下命令&…...
k8s之kubelet证书时间过期升级
1.查看当前证书时间 # kubeadm alpha certs renew kubelet Kubeadm experimental sub-commands kubeadm是一个用于引导Kubernetes集群的工具,它提供了许多命令和子命令来管理集群的一生周期。过去,某些功能被标记为实验性的,并通过kubeadm a…...
5G消息 x 文旅 | 一站式智慧文旅解决方案
5G消息 x 文旅 | 一站式智慧文旅解决方案 文旅 x 5G 消息将进一步强化资源整合,满足游客服务需求、企业营销需求、政府管理需求,推进文化旅游项目的智慧化、数字化,增强传播力、竞争力和可持续性。5G 消息的“原生入口”、“超强呈现”、“智…...

如何评估员工在新版FMEA培训后应用知识的效果?
随着制造业的快速发展,新版FMEA已成为企业提升产品质量、减少故障风险的关键一环。然而,培训只是第一步,如何有效评估员工在新版FMEA培训后应用知识的效果,才是确保培训成果转化的关键所在。 评估员工知识应用效果的首要步骤是制定…...

python脚本之解析命令参数
import requests import argparseprint(f"{__name__}:start")parser argparse.ArgumentParser(description使用方法) parser.add_argument(-p, --prefix, typestr, help域名) parser.add_argument(-t, --token, typestr, helptoken) parser.add_argument(-i, --queu…...

当JS遇上NLP:开启图片分析的奇幻之旅
前言 在当今科技飞速发展的时代,JavaScript(JS)作为广泛应用的编程语言,展现出了强大的活力与无限的可能性。与此同时,自然语言处理(NLP)领域也正在经历着深刻的变革与进步。 当这两者碰撞在一…...

余姚加工中心编程培训排行榜单
舜龙模具数控培训执行标准:学习进度一对一、培训一人、合格一人、成就一人;舜龙自有模具工厂,全程实战教学,所学贴合岗位实操,毕业即可对接就业。1998年-2026年,舜龙28年匠心传承。舜龙模具数控培训&#x…...

Phi-4-mini-reasoning开源模型优势:轻量级+高精度+低GPU资源占用实测
Phi-4-mini-reasoning开源模型优势:轻量级高精度低GPU资源占用实测 1. 模型概述 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理数学题、逻辑题、多步分析和简洁结论输出。与通用聊天模型不同,它采用了"题目输…...

4月底就要交论文,现在开始降AI率来得及吗?完整应急方案
4月底就要交论文,现在开始降AI率来得及吗?完整应急方案 今天是4月1日。 如果你的论文要在4月底提交,现在翻出来一查,AI率50%,或者知网标红一片——你可能已经开始冒冷汗了。 先别慌。来得及,但要马上开始&a…...

新能源车BMS低压管理避坑指南:如何解决上下电时序中的典型问题
新能源车BMS低压管理避坑指南:如何解决上下电时序中的典型问题 在新能源汽车的电池管理系统(BMS)开发中,低压上下电时序控制是确保系统稳定运行的关键环节。许多开发团队在实际项目中都会遇到信号冲突、时序错乱、异常处理机制不完…...

国产铷原子钟 快稳铷原子钟突破铷钟启动时长痛点 铷钟 特种铷原子钟
在数字化浪潮席卷全球的今天,时频同步已成为支撑通信、电力、国防、科研等关键领域稳定运行的核心基石。从6G基站的纳秒级协同,到智能电网的故障精准定位,再到北斗导航的车道级精度保障,每一个场景都对时间频率的准确度、稳定度提…...

学术场景实战:DeepSeek-OCR-2驱动深求·墨鉴实现论文公式精准提取
学术场景实战:DeepSeek-OCR-2驱动深求墨鉴实现论文公式精准提取 1. 引言:学术研究中的公式提取痛点 如果你是一名理工科的研究生、科研工作者,或者经常需要阅读学术论文,你一定遇到过这样的场景:在PDF论文里看到一个…...

m4s-converter:释放B站缓存价值的格式转换利器
m4s-converter:释放B站缓存价值的格式转换利器 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 价值对比:格式转换前后的效…...
 - 机器数据管理和分析)
Splunk Enterprise 9.4.10 (macOS, Linux, Windows) - 机器数据管理和分析
Splunk Enterprise 9.4.10 (macOS, Linux, Windows) - 机器数据管理和分析 安全信息和事件管理 (SIEM)、全面的日志管理和分析平台 请访问原文链接:https://sysin.org/blog/splunk-9/ 查看最新版。原创作品,转载请保留出处。 作者主页:sys…...
及使用vcs管理多仓库)
MoveIt2新手必看:如何正确选择安装分支(main vs. tutorials)及使用vcs管理多仓库
MoveIt2分支选择与多仓库管理实战指南 当你在ROS2生态中开始使用MoveIt2时,第一个拦路虎往往不是算法理解或代码编写,而是如何正确搭建开发环境。MoveIt2作为由数十个独立Git仓库组成的复杂项目,其分支管理和版本协同问题困扰着许多中级开发者…...

ISO/SAE 21434:2021 逐条审核判定表
A 章节号|B 条款|C 要求内容|D 符合性|E 证据 / 说明|F:不符合整改项符合性选项:符合 / 部分符合 / 不符合 / 不适用章节号条款审核要求内容符合性证据 / 备注整改项44.1建立网络安全生命周…...