当JS遇上NLP:开启图片分析的奇幻之旅
前言
在当今科技飞速发展的时代,JavaScript(JS)作为广泛应用的编程语言,展现出了强大的活力与无限的可能性。与此同时,自然语言处理(NLP)领域也正在经历着深刻的变革与进步。
当这两者碰撞在一起时,一个全新的领域就此打开——图片分析。
实现
效果展示

通过点击上传图片按钮上传图片后,通过AI帮助我们对图像进行识别

实现过程
页面
<main class="container"><label for="file-upload" class="custom-file-upload"><!-- <input type="file" id="file-upload" accept="image/*"> --><input type="file" accept="image/*" id="file-upload">上传图片</label><div id="image-container"></div><p id="status"></p></main>
<main class="container">: 这是一个<main>元素,表示页面的主要内容区域<label for="file-upload" class="custom-file-upload">: 这是一个<label>元素,它与file-upload输入框关联<input type="file" accept="image/*" id="file-upload">: 这是一个<input>元素,类型为file。accept="image/*"属性表示只允许上传图片文件。id="file-upload"属性用于与<label>元素关联<div id="image-container"></div>: 这是一个空的<div>元素,其id为image-container。用于显示上传的图片预览
js代码
// transformers库导入pipeline模块 npl 任务
import { pipeline, env } from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0"
首先从导入transformers库导入pipeline模块和env
- transformers 是一个由 Hugging Face 开发的开源 Python 库,用于快速开发和部署最先进的自然语言处理(NLP)模型,为 NLP 开发者提供了一个强大、灵活和易用的工具集。无论是进行基础的文本分类还是构建复杂的对话系统,transformers 都可以成为开发者的首选。
// 设置当前的环境对象 不要加载本地模型,使用远程加载 transformers库
env.allowLocalModels = false;
设置当前的环境对象 不要加载本地模型,使用远程加载 transformers库
// 通过id获取input元素const fileUpload = document.getElementById('file-upload');const imageContainer = document.getElementById('image-container')// 文件输入框元素添加监听器 事件名称change 指定触发事件执行的函数fileUpload.addEventListener('change', function (e) {// 获取目标事件看看效果 只要获取的第第一张图片(只上传一张图片)// console.log(e.target.files[0]);const file = e.target.files[0];// 新建一个FileReader 对象, 文件的本质是 01 序列 // 图片比较大 const reader = new FileReader();reader.onload = function (e2) {// 读完了, 加载完成const image = document.createElement('img'); // 图片对象console.log(e2.target.result);image.src = e2.target.result;//添加图片src获取图片展示到div中imageContainer.appendChild(image)// 启动ai任务 功能模块化,封装出去detect(image)}reader.readAsDataURL(file)})
-
获取 HTML 元素:
const fileUpload = document.getElementById('file-upload');: 通过 ID 获取文件上传的 input 元素。const imageContainer = document.getElementById('image-container');: 通过 ID 获取用于显示图片的容器 div。
-
添加事件监听器:
fileUpload.addEventListener('change', function (e) { ... });: 给文件上传 input 添加 ‘change’ 事件监听器,当用户选择文件时触发。
-
处理上传文件:
const file = e.target.files[0];:获取用户选择的第一个文件。const reader = new FileReader();: 创建一个 FileReader 对象,用于读取文件内容。reader.onload = function (e2) { ... };: 当文件读取完成时,触发 ‘onload’ 回调函数。const image = document.createElement('img');: 创建一个新的 img 元素用于显示图片。image.src = e2.target.result;: 将读取到的文件内容设置为 img 元素的 src 属性,显示图片。imageContainer.appendChild(image);: 将 img 元素添加到图片容器 div 中,完成图片预览。
-
触发 AI 检测:
detect(image);: 在图片加载完成后,调用一个名为detect的函数来执行 AI 检测任务。这个函数没有在代码中定义,需要在其他地方实现。
其中将detect单独模块化,体现了封装的思想
const status = document.getElementById('status');// 通过pipeline启动一个检测图片的AI任务并选择合适的模型const detect = async (image) => {status.textContent = "分析中...";const detector = await pipeline("object-detection","Xenova/detr-resnet-50") // 适合对象检测的模型 model 实例化了detector对象const output = await detector(image.src, {threshold: 0.1,percentage: true})// console.log(output);output.forEach(rendesrBox)}
上述代码
const detector = await pipeline("object-detection", "Xenova/detr-resnet-50");: 使用 Hugging Face 的pipeline函数加载预训练的对象检测模型。这里选择了 “Xenova/detr-resnet-50” 模型,它适用于对象检测任务。const output = await detector(image.src, { threshold: 0.1, percentage: true });: 使用加载的对象检测模型对图像进行分析,返回检测结果。这里设置了置信度阈值为 0.1,并将结果以百分比的形式返回。output.forEach(renderBox);: 遍历检测结果,对每个检测到的对象调用一个名为renderBox的函数进行渲染。
function renderBox({ box, label }) {console.log(box, label);const { xmax, xmin, ymax, ymin } = boxconst boxElement = document.createElement("div");boxElement.className = "bounding-box"Object.assign(boxElement.style, {borderColor: '#123123',borderWidth: '1px',borderStyle: 'solid',left: 100 * xmin + '%',top: 100 * ymin + '%',width: 100 * (xmax - xmin) + "%",height: 100 * (ymax - ymin) + "%"})const labelElement = document.createElement('span');labelElement.textContent = label;labelElement.className = "bounding-box-label"labelElement.style.backgroundColor = '#000000'boxElement.appendChild(labelElement);imageContainer.appendChild(boxElement);}
对于每个检测到的对象,都会在图像容器中渲染一个带有标签的边界框,以可视化地显示检测结果
完整js代码
<script type="module">// transformers库导入pipeline模块 npl 任务 import { pipeline, env } from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0"// 设置当前的环境对象 不要加载本地模型,使用远程加载 transformers库env.allowLocalModels = false;// 通过id获取input元素const fileUpload = document.getElementById('file-upload');const imageContainer = document.getElementById('image-container')// 文件输入框元素添加监听器 事件名称change 指定触发事件执行的函数fileUpload.addEventListener('change', function (e) {// 获取目标事件看看效果 只要获取的第第一张图片(只上传一张图片)// console.log(e.target.files[0]);const file = e.target.files[0];// 新建一个FileReader 对象, 文件的本质是 01 序列 // 图片比较大 const reader = new FileReader();reader.onload = function (e2) {// 读完了, 加载完成const image = document.createElement('img'); // 图片对象console.log(e2.target.result);image.src = e2.target.result;//添加图片src获取图片展示到div中imageContainer.appendChild(image)// 启动ai任务 功能模块化,封装出去detect(image)}reader.readAsDataURL(file)})const status = document.getElementById('status');// 通过pipeline启动一个检测图片的AI任务并选择合适的模型const detect = async (image) => {status.textContent = "分析中...";const detector = await pipeline("object-detection","Xenova/detr-resnet-50") // 适合对象检测的模型 model 实例化了detector对象const output = await detector(image.src, {threshold: 0.1,percentage: true})// console.log(output);output.forEach(rendesrBox)}function renderBox({ box, label }) {console.log(box, label);const { xmax, xmin, ymax, ymin } = boxconst boxElement = document.createElement("div");boxElement.className = "bounding-box"Object.assign(boxElement.style, {borderColor: '#123123',borderWidth: '1px',borderStyle: 'solid',left: 100 * xmin + '%',top: 100 * ymin + '%',width: 100 * (xmax - xmin) + "%",height: 100 * (ymax - ymin) + "%"})const labelElement = document.createElement('span');labelElement.textContent = label;labelElement.className = "bounding-box-label"labelElement.style.backgroundColor = '#000000'boxElement.appendChild(labelElement);imageContainer.appendChild(boxElement);}</script>
总结
AI 技术的发展带来了很多新的可能性,前端技术结合AI将有更广阔的未来
相关文章:
当JS遇上NLP:开启图片分析的奇幻之旅
前言 在当今科技飞速发展的时代,JavaScript(JS)作为广泛应用的编程语言,展现出了强大的活力与无限的可能性。与此同时,自然语言处理(NLP)领域也正在经历着深刻的变革与进步。 当这两者碰撞在一…...

trpc快速上手
tRPC (Type-safe Remote Procedure Call) 是一个用于构建类型安全的 API 的框架,它能够在前端和后端之间共享类型,确保类型安全性。这对于使用 TypeScript 的项目特别有用,因为它消除了前后端类型不一致的问题,提高了开发效率和代…...
知识图谱存在的挑战---隐私、安全和伦理相关和测试认证相关
文章目录 隐私、安全和伦理相关测试认证相关 隐私、安全和伦理相关 从部署拓扑结构而言,知识图谱技术以数据为核心、数据库为载体的方式来存储,有单机、云平台、集群及其组合的部署方式,结合大数据平台、云平台、业务系统、灾备、网络系统及其…...

课时155:脚本发布_简单脚本_命令罗列
2.1.1 命令罗列 学习目标 这一节,我们从 基础知识、简单实践、小结 三个方面来学习 基础知识 简介 目的:实现代码仓库主机上的操作命令功能即可简单实践 实践 查看脚本内容 #!/bin/bash # 功能:打包代码 # 版本: v0.1 # 作者: 书记 # …...

借助ollama实现AI绘画提示词自由,操作简单只需一个节点!
只需要将ollama部署到本地,借助comfyui ollama节点即可给你的Ai绘画提示词插上想象的翅膀。具体看详细步骤! 第一步打开ollama官网:https://ollama.com/,并选择models显存太小选择的是llama3\8b参数的instruct-q6_k的这个模型。 运…...
PyTorch -- Visdom 快速实践
安装:pip install visdom 注:如果安装后启动报错可能是 visdom 版本选择问题 启动:python -m visdom.server 之后打开出现的链接 http://localhost:8097Checking for scripts. Its Alive! INFO:root:Application Started INFO:root:Working…...

基于xilinx FPGA的QSFP调试使用经验
1 概述 本文用于记录QSFP在调试使用时遇到的一些经验教训,防止后来者踩相同的坑。 参考手册: 《AMQ28-SR4-M1_V1.0》 《QSFP-DD-Hardware-rev4p0-9-12-18-clean》 2 QSFP简介 QSFP(Quad Small Form-facor Pluggable)即四通道SFP…...

WPF 使用Image控件显示图片
Source属性 Source属性用来告诉Image组件要展示哪张图片资源的一个入口,通常是图片的路径。也许是本地路径,也许是网络路径。 本地图片路径加载方式 使用相对路径,相对于工程目录的路径,当设置Width属性时,图片会等…...

合肥工业大学内容安全实验一:爬虫|爬新闻文本
✅作者简介:CSDN内容合伙人、信息安全专业在校大学生🏆 🔥系列专栏 :合肥工业大学实验课设 📃新人博主 :欢迎点赞收藏关注,会回访! 💬舞台再大,你不上台,永远是个观众。平台再好,你不参与,永远是局外人。能力再大,你不行动,只能看别人成功!没有人会关心你付…...
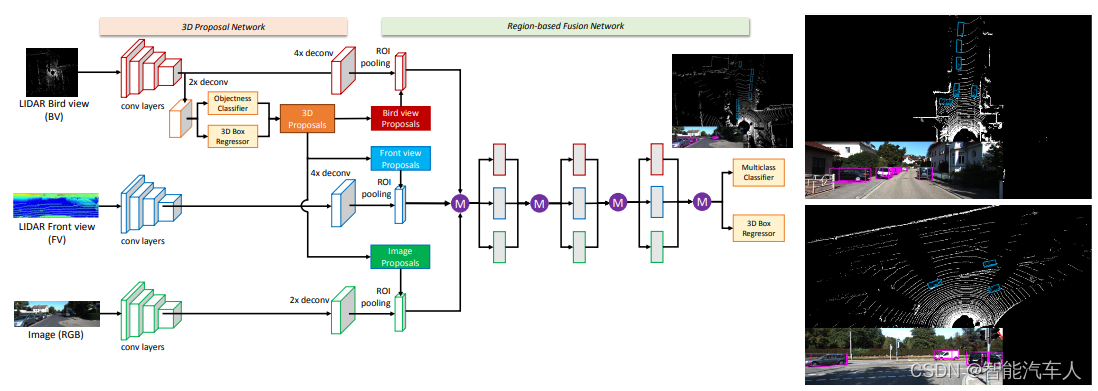
自动驾驶---Perception之视觉点云雷达点云
1 前言 在自动驾驶领域,点云技术的发展历程可以追溯到自动驾驶技术的早期阶段,特别是在环境感知和地图构建方面。 在自动驾驶技术的早期技术研究中,视觉点云和和雷达点云都有出现。20世纪60年代,美国MIT的Roberts从2D图像中提取3D…...
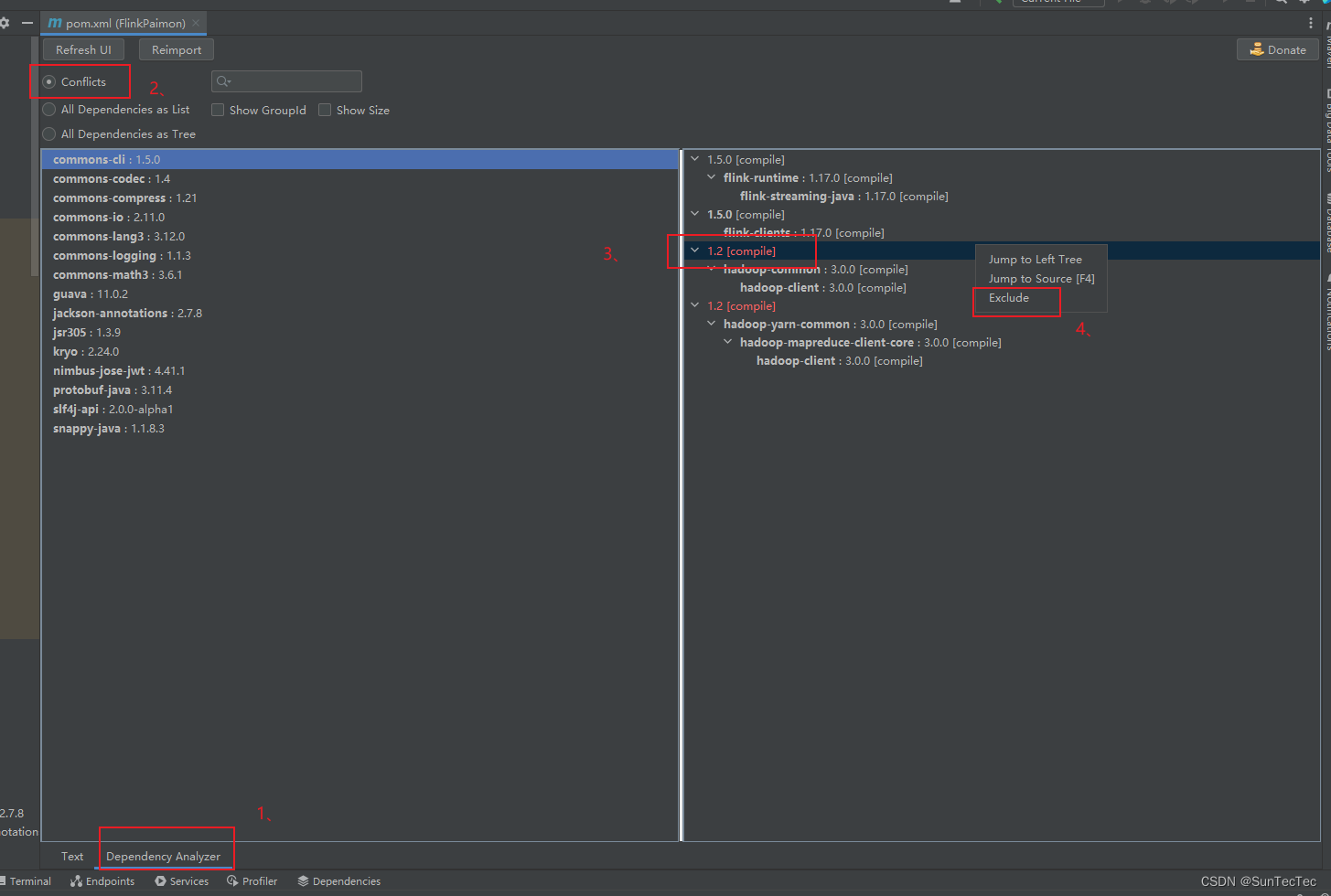
maven 显式依赖包包含隐式依赖包,引起依赖包冲突
问题:FlinkCDC 3.0.1 代码 maven依赖包冲突 什么是依赖冲突 依赖冲突是指项目依赖的某一个jar包,有多个不同的版本,因而造成类包版本冲突 依赖冲突的原因 依赖冲突很经常是类包之间的间接依赖引起的。每个显式声明的类包都会依赖于一些其它…...
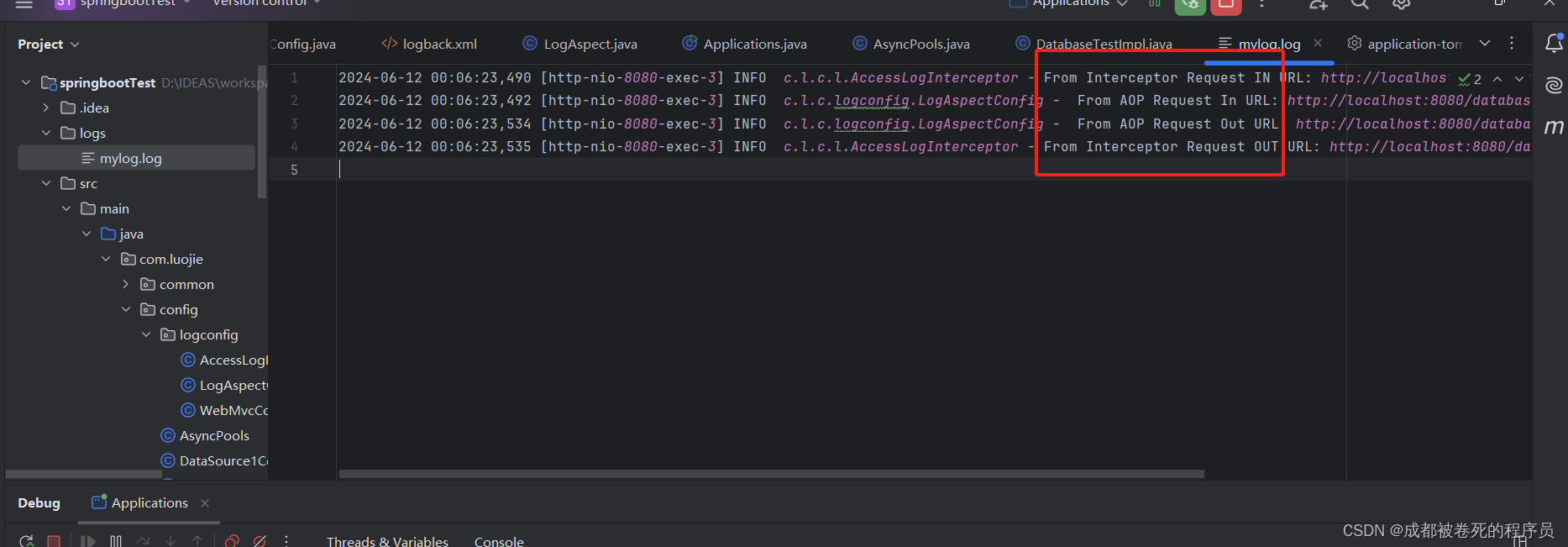
Spring应用如何打印access日志和out日志(用于分析请求总共在服务耗费多长时间)
我们经常会被问到这样一个问题。你接口返回的好慢呀,能不能提升一下接口响应时间啊?这个时候我们就需要去分析,为什么慢,慢在哪。而这首先应该做的就是确定接口返回时间过长确实是在服务内消耗的时间。而不是我们将请求发给网关或…...

SpringBoot整合SpringDataRedis
目录 1.导入Maven坐标 2.配置相关的数据源 3.编写配置类 4.通过RedisTemplate对象操作Redis SpringBoot整合Redis有很多种,这里使用的是Spring Data Redis。接下来就springboot整合springDataRedis步骤做一个详细介绍。 1.导入Maven坐标 首先,需要导…...
电脑怎么录制游戏视频?轻松捕捉每一帧精彩
随着游戏产业的蓬勃发展,越来越多的玩家不仅满足于在游戏世界中的探索与冒险,更希望将自己的游戏精彩瞬间记录下来,分享给更多的朋友。可是电脑怎么录制游戏视频呢?本文旨在为广大游戏爱好者提供一份详细的电脑游戏视频录制攻略&a…...

【Elasticsearch】索引快照并还原到其他集群
【Elasticsearch】索引快照并还原到其他集群 前提:es节点的所有用户id和组id都需要相同,最好在新建集群时指定用户id和组id,否则挂载后执行curl时会提示权限报错。 解决方法(gpt生成),不敢在生产尝试。 点…...

QT--DAY1
不使用图形化界面实现一个登陆界面 #include "widget.h"Widget::Widget(QWidget *parent): QWidget(parent) {//设置窗口标题this->setWindowTitle("登录界面");//设置窗口大小this->resize(535,410);//固定窗口大小this->setFixedSize(535,410)…...
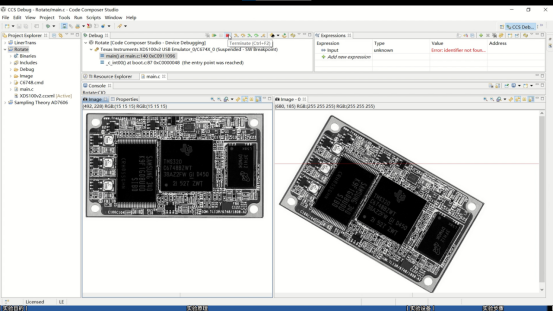
DSP教学实验箱_数字图像处理_操作教程:5-1 图像旋转
一、实验目的 学习图像旋转的原理,掌握图像的读取方法,并实现图像旋转。 二、实验原理 图像旋转 图像的旋转是指以图像的某一点为原点以逆时针或顺时针旋转一定的角度。其本质是以图像的中心为原点,将图像上的所有像素都旋转一个相同的角…...
- MyBatis实现原理(三))
MyBatis总结(2)- MyBatis实现原理(三)
核心配置 JavaBeanMapper.xml(sql映射) 作用 JavaBeanMapper.xml实现: 用来干什么? 定义Sql语句映射。相对照JDBC的实现,是将原本的Sql代码提取出来,最终根据映射关系执行Sql操作。 好处? 解…...

【保姆级教程】Linux 基于 Docker 部署 MySQL 和 Nacos 并配置两者连接
一、Linux 部署 Docker 1.1 卸载旧版本(如有) sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine1.2 安装 yum-utils 包 sudo yum install -y…...
Dev C++ 安装及使用方法教程-干活多超详细
Dev C 是一款非常好用,简约的C/C开发工具。可以减少很多创建工程的繁琐步骤,很快的进行开发。对于只用于来写代码的人来说,是比较轻量以及极速的。 Dev C 是一个windows下的c和c程序的集成开发环境。它使用mingw32/gcc编译器,遵循…...

STM32CubeMX实战指南:DMA驱动USART高效数据传输
1. DMA与USART协作的核心价值 第一次接触STM32的DMA功能时,我正被一个传感器数据采集项目折磨得焦头烂额。当时用传统的中断方式处理串口数据,CPU占用率直接飙到70%,整个系统卡得像老式拨号上网。直到尝试了DMAUSART组合,才真正体…...
)
CRT库链接冲突详解:为什么你的Visual Studio项目会警告LNK4098(含/NODEFAULTLIB使用指南)
CRT库链接冲突深度解析:从原理到实战解决LNK4098警告 当你用Visual Studio编译C项目时,突然蹦出"warning LNK4098: 默认库msvcrtd.lib与其他库的使用冲突"的提示,这就像开车时仪表盘突然亮起的警告灯——它不会立即让引擎熄火&…...

GZDoom未来展望:10个开源游戏引擎的发展趋势和路线图
GZDoom未来展望:10个开源游戏引擎的发展趋势和路线图 【免费下载链接】gzdoom GZDoom is a feature centric port for all Doom engine games, based on ZDoom, adding an OpenGL renderer and powerful scripting capabilities 项目地址: https://gitcode.com/gh…...

[LangChain智能体本质论-01]两种视角看待Agent和ReAct循环
作为LangChain智能体的Agent采用一种被称为ReAct循环的执行流程(如下图所示),这是一种结合了“推理”(Reasoning)与“行动”(Acting)的交互模式,旨在让Agent能像人类一样通过逻辑思考…...

镜头背后的AI魔法:Qwen-Edit多角度编辑技术的深度探索
镜头背后的AI魔法:Qwen-Edit多角度编辑技术的深度探索 【免费下载链接】Qwen-Edit-2509-Multiple-angles 项目地址: https://ai.gitcode.com/hf_mirrors/dx8152/Qwen-Edit-2509-Multiple-angles 问题溯源:当静态图像遇见动态视角需求 在博物馆的…...

终极指南:如何使用Harepacker-resurrected打造个性化MapleStory游戏体验
终极指南:如何使用Harepacker-resurrected打造个性化MapleStory游戏体验 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 你是否曾…...

ROS实战:UZH-FPV数据集下PL-EVIO与主流VIO算法的性能对比
1. UZH-FPV数据集与无人机视觉里程计的挑战 UZH-FPV数据集是苏黎世联邦理工学院发布的专门针对高速无人机场景的多模态数据集。这个数据集最大的特点在于它完整记录了无人机在高速机动飞行(最高速度超过10m/s)时的多传感器数据,包括双目事件相…...

SenseVoice-small实战教程:导出SRT/VTT字幕文件用于Premiere剪辑
SenseVoice-small实战教程:导出SRT/VTT字幕文件用于Premiere剪辑 你是不是经常遇到这样的烦恼?录了一段视频,或者拿到一段会议录音,想要给它配上精准的字幕,却发现自己要花几个小时去听写、校对、打时间轴?…...
)
基于SpringBoot + Vue的养老院管理系统(角色:家属、护工、管理员)
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...

别再让传感器‘各走各的时’:5种无线传感网时间同步协议实战对比与选型指南
无线传感网时间同步协议实战指南:从原理到选型的深度解析 在工业物联网和智能环境监测系统中,我们常常遇到这样的场景:分布在厂区各处的振动传感器记录着设备运行状态,但当工程师调取数据时,却发现各节点的时间戳存在…...