基于python实现视频和音频长度对齐合成并添加字幕
在许多视频编辑任务中,我们常常需要将视频和音频进行对齐,并添加字幕。本文将详细介绍如何使用Python实现这一功能,并在视频中添加中文字幕。我们将使用OpenCV处理视频帧,使用MoviePy处理音频和视频的合成,使用PIL库绘制中文字幕。
环境设置
首先,我们需要安装必要的库。可以使用以下命令来安装它们:
pip install opencv-python moviepy Pillow
准备工作
- 准备音频和视频文件:确保你有需要对齐的音频和视频文件。
- 下载支持中文的字体文件:例如SimHei.ttf,并将其保存到合适的位置。在示例中,我们使用NotoSansCJKsc-Regular.ttf。
实现代码
以下是实现音视频对齐并添加中文字幕的完整Python代码。你可以将这段代码保存为一个Python文件,并根据需要进行调用。
import cv2
import numpy as np
from moviepy.editor import AudioFileClip, VideoFileClip
from pydub import AudioSegment
from PIL import Image, ImageDraw, ImageFont
import tempfile
import os
import re def replace_punctuation_with_at(input_string):# 使用正则表达式匹配所有标点符号并替换为 @result = re.sub(r'[^\w\s]', '@', input_string)return resultdef add_chinese_subtitle_to_frame(frame, subtitle_text, position, font_path, font_size, font_color):# 将OpenCV图像转换为PIL图像img_pil = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(img_pil)font = ImageFont.truetype(font_path, font_size)# 获取字幕文本的宽度和高度text_bbox = draw.textbbox((0, 0), subtitle_text, font=font)text_width = text_bbox[2] - text_bbox[0]text_height = text_bbox[3] - text_bbox[1]# 计算字幕的放置位置x = position[0] - text_width // 2y = position[1] - text_height // 2# 在PIL图像上添加字幕draw.text((x, y), subtitle_text, font=font, fill=font_color)# 将PIL图像转换回OpenCV图像frame = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)return framedef sync_audio_video_add_subtitle(audio_path, video_path, output_path, subtitle_text, font_path, font_size=24, font_color=(255, 255, 255), subtitle_bottom_margin=30, audio_volume=1.0):# 加载音频文件并调整音量original_audio = AudioSegment.from_file(audio_path)original_audio = original_audio + (audio_volume * 10 - 10) # 调整音量silence = AudioSegment.silent(duration=500) # 0.5秒的静音audio_with_silence = silence + original_audio + silence# 创建临时文件以保存修改后的音频temp_audio_path = os.path.join(tempfile.gettempdir(), "temp_audio.mp3")audio_with_silence.export(temp_audio_path, format="mp3")# 加载修改后的音频文件audio_clip = AudioFileClip(temp_audio_path)audio_duration = audio_clip.duration# 加载视频文件cap = cv2.VideoCapture(video_path)fps = cap.get(cv2.CAP_PROP_FPS)frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))video_duration = frame_count / fps# 计算新的视频帧率new_fps = fps * (video_duration / audio_duration)# 获取视频尺寸width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))# 创建临时文件以存储中间视频结果temp_video_path = os.path.join(tempfile.gettempdir(), "temp_video.mp4")# 创建VideoWriter对象out = cv2.VideoWriter(temp_video_path, cv2.VideoWriter_fourcc(*'mp4v'), new_fps, (width, height))# 分批读取和写入视频帧,并添加字幕subtitle_text = replace_punctuation_with_at(subtitle_text)subtitle_text_list = [text for text in subtitle_text.split("@") if text]print(subtitle_text_list)subtitles_per_frame = frame_count // len(subtitle_text_list)current_subtitle_index = 0for frame_idx in range(frame_count):ret, frame = cap.read()if not ret:break# 添加当前字幕到帧if frame_idx // subtitles_per_frame >= current_subtitle_index and current_subtitle_index < len(subtitle_text_list):frame = add_chinese_subtitle_to_frame(frame, subtitle_text_list[current_subtitle_index], (width // 2, height - subtitle_bottom_margin), font_path, font_size, font_color)if frame_idx // subtitles_per_frame > current_subtitle_index:current_subtitle_index += 1out.write(frame)cap.release()out.release()# 使用MoviePy将音频和调整后的视频合并video_clip = VideoFileClip(temp_video_path).set_duration(audio_duration)final_clip = video_clip.set_audio(audio_clip)# Trim the last 0.3 secondsfinal_clip = final_clip.subclip(0, final_clip.duration - 0.3)# Write the final video filefinal_clip.write_videofile(output_path, codec="libx264", audio_codec="aac")# Close the clips to release the filefinal_clip.close()video_clip.close()audio_clip.close()# 删除临时文件os.remove(temp_audio_path)os.remove(temp_video_path)if __name__ == "__main__":# 示例用法audio_path = r"C:\Users\60568\Pictures\create\屈原\mp3\00000002.mp3"video_path = r"C:\Users\60568\Pictures\create\屈原\mp4\03.mp4"subtitle_text='然而屈原的直言进谏,引来了朝中权臣的嫉恨,他成为了政治斗争的牺牲品。'output_path = "synced_video.mp4"sync_audio_video_add_subtitle(audio_path, video_path, output_path,subtitle_text=subtitle_text,font_path="./NotoSansCJKsc-Regular.ttf",font_size=40, # 设置字体大小font_color=(255, 255, 255), # 设置字体颜色subtitle_bottom_margin=80, # 设置字幕底部的位置audio_volume=2) # 调整音频音量,1.0为原始音量,1.5为增加50%音量代码说明
- add_chinese_subtitle_to_frame: 这个函数将字幕添加到给定的帧上。它使用PIL库来绘制字幕,然后将图像转换回OpenCV格式。
- sync_audio_video_add_subtitle: 这个函数处理音频和视频的对齐,并将字幕添加到每一帧上。最终,它将处理好的视频和音频合并,并生成输出文件。
保证音频长度不变,调整视频长度
在此代码中,我们特别强调了保证音频长度不变,通过调整视频的帧率来匹配音频长度。这是通过计算新的帧率 new_fps 实现的:
new_fps = fps * (video_duration / audio_duration)
调整参数
你可以通过调整以下参数来修改字幕的显示效果和位置:
font_size: 字体大小。font_color: 字体颜色。subtitle_bottom_margin: 字幕距离视频底部的距离。
运行示例
你可以使用提供的示例用法来运行代码,只需将audio_path、video_path和font_path替换为你自己的文件路径即可。
通过这个教程,你应该能够使用Python轻松地实现视频和音频的对齐,并在视频中添加中文字幕。如果你有任何问题或建议,请在评论区留言!
相关文章:

基于python实现视频和音频长度对齐合成并添加字幕
在许多视频编辑任务中,我们常常需要将视频和音频进行对齐,并添加字幕。本文将详细介绍如何使用Python实现这一功能,并在视频中添加中文字幕。我们将使用OpenCV处理视频帧,使用MoviePy处理音频和视频的合成,使用PIL库绘…...
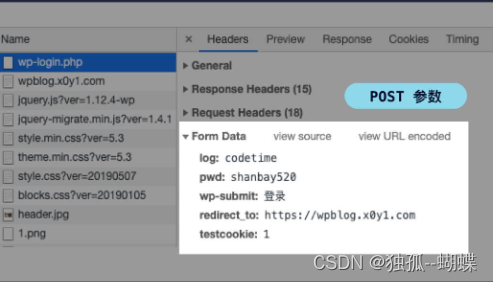
爬虫-模拟登陆博客
import requests from bs4 import BeautifulSoupheaders {user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36 } # 登录参数 login_data {log: codetime,pwd: shanbay520,wp-submit: …...

【深度学习】【NLP】Bert理论,代码
论文 : https://arxiv.org/abs/1810.04805 文章目录 一、Bert理论BERT 模型公式1. 输入表示 (Input Representation)2. 自注意力机制 (Self-Attention Mechanism)3. Transformer 层 (Transformer Layer) 二、便于理解Bert的代码1. 自注意力机制2. Transformer 层3. …...
element table 点击某一行中按钮加载
在Element UI中,实现表格(element-table)中的这种功能通常涉及到数据处理和状态管理。当你点击某一行的按钮时,其他行的按钮需要动态地切换为加载状态,这可以通过以下步骤实现: 1.表格组件:使用…...
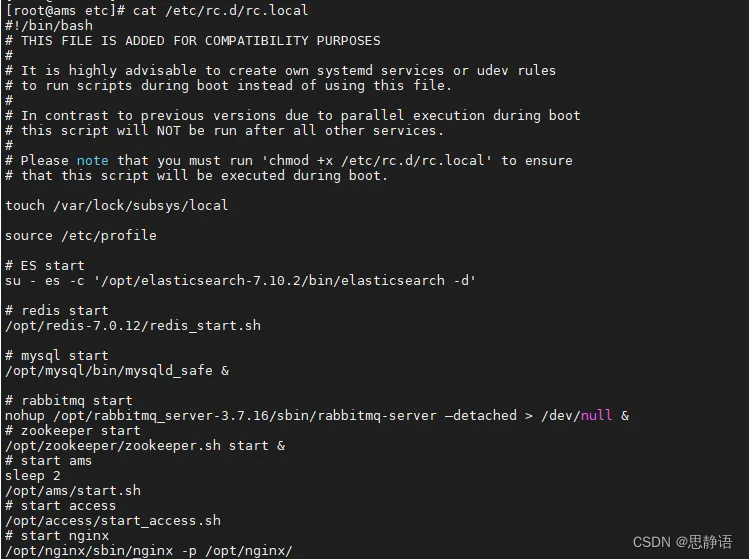
Linux开机自启/etc/init.d和/etc/rc.d/rc.local
文章目录 /etc/init.d和/etc/rc.d/rc.local的区别/etc/init.dsystemd介绍 /etc/init.d和/etc/rc.d/rc.local的区别 目的不同: /etc/rc.d/rc.local:用于在系统启动后执行用户自定义命令,适合简单的启动任务。 /etc/init.d:用于管理…...
DP:两个数组的dp问题
解决两个数组的dp问题的常用状态表示: 1、选取第一个字符串[0-i]区间以及第二个字符串[0,j]区间作为研究对象 2、根据题目的要求确定状态表示 字符串dp的常见技巧 1、空串是有研究意义的,引入空串可以帮助我们思考虚拟的边界如何进行初始化。 2、如…...

嵌入式Linux:格式化I/O
目录 1、格式化输出函数 1.1、printf()函数 1.2、fprintf()函数 1.3、dprintf()函数 1.4、sprintf()函数 1.5、snprintf()函数 2、格式化输入函数 2.1、scanf()函数 2.2、fscanf()函数 2.3、sscanf()函数 在Linux中,格式化I/O(formatted I/O&a…...
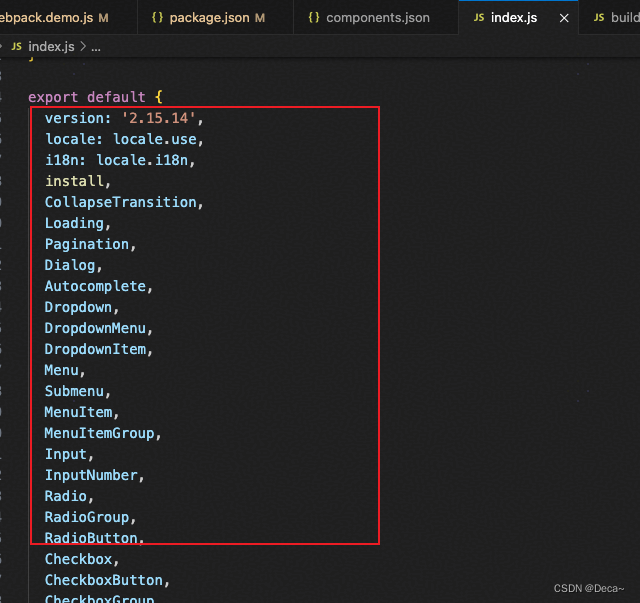
【elementui源码解析】如何实现自动渲染md文档-第二篇
目录 1.概要 2.引用文件 1)components.json 2)json-template/string 3)os.EOL 3.变量定义 4.模版填充 5.MAIN_TEMPLATE填充 6.src下的index.js文件 1)install 2)export 7.总结 1.概要 今天看第二个命令no…...
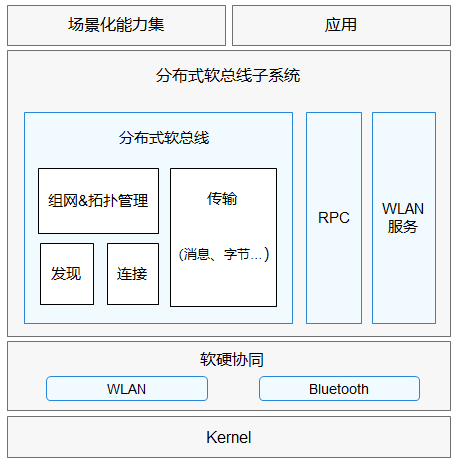
热门开源项目OpenHarmony
目录 1.概述 1.1.开源项目的意义 1.2.开源项目对软件行业的促进作用 1.3.小结 2.OpenHarmony 2.1.技术架构 2.2.分布式软总线 2.2.1.架构 2.2.2.代码介绍 2.2.2.1.代码目录 2.2.2.2.说明 2.2.2.3.发现组网和传输 2.2.2.3.1.发现 2.2.2.3.2.组网 2.2.2.3.3.传输…...

NewspaceAi之GPT使用新体验
GPT功能 使用地址:https://newspace.ai0.cn/ 上车 挂挡 踩油门,一脚到底,开始你的表演 问题1:你能做什么详细告诉我? 下面内容是GPT的回答 当然!作为一个基于GPT-4架构的AI,我能够在许多方面为…...

详解红黑树
红黑树规则 节点是红色或黑色。根节点是黑色。每个叶子节点都是黑色的空节点(NIL节点)。每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。 红黑树…...

探索JavaScript逆向工程与风控等级
探索JavaScript逆向工程与风控等级 在当今的网络安全领域,JavaScript逆向工程(简称JS逆向)已成为许多开发者和安全专家关注的焦点。JS逆向主要涉及对JavaScript代码的分析与理解,以发现其内部逻辑、数据流及潜在漏洞。这种技术常用…...

C++ 22 之 立方体案例
c22立方体案例.cpp #include <iostream> #include <string>using namespace std;class Cube{ private:int cube_l; // 长int cube_w; // 宽int cube_h; // 高public:// 设置长void set_l(int l){cube_l 1;}// 设置宽void set_w(int w){cube_w w;}// 设置高void …...

vue2使用antv/g6-editor实现可拖拽流程图
依赖下载 照着这个引入就好,然后npm install 源码 <template><div id"vue-g6-editor"><el-row><el-col :span"24"></el-col></el-row><!-- 工具栏 --><el-row><el-col :span"24&qu…...

springboot学习小结
背景 业务上需要开发,组里一位前辈给我指路 spring基础 什么是spring spring提供一个容器称为spring应用上下文,容器里可以创建和管理组件,组件会在容器里装配好,组件也可以叫bean。 装配不由组件创建他依赖的组件࿰…...

vue聊天发送Emoji表情
在用web端写聊天发送表情的功能中,使用web端有系统自带的unicode表情会出现每端不统一的情况,不好用不能统一,在这里我想到了一个非常好的思路,可以解决这个问题! 那就是发送表情用图片的形式呈现,然后发给…...
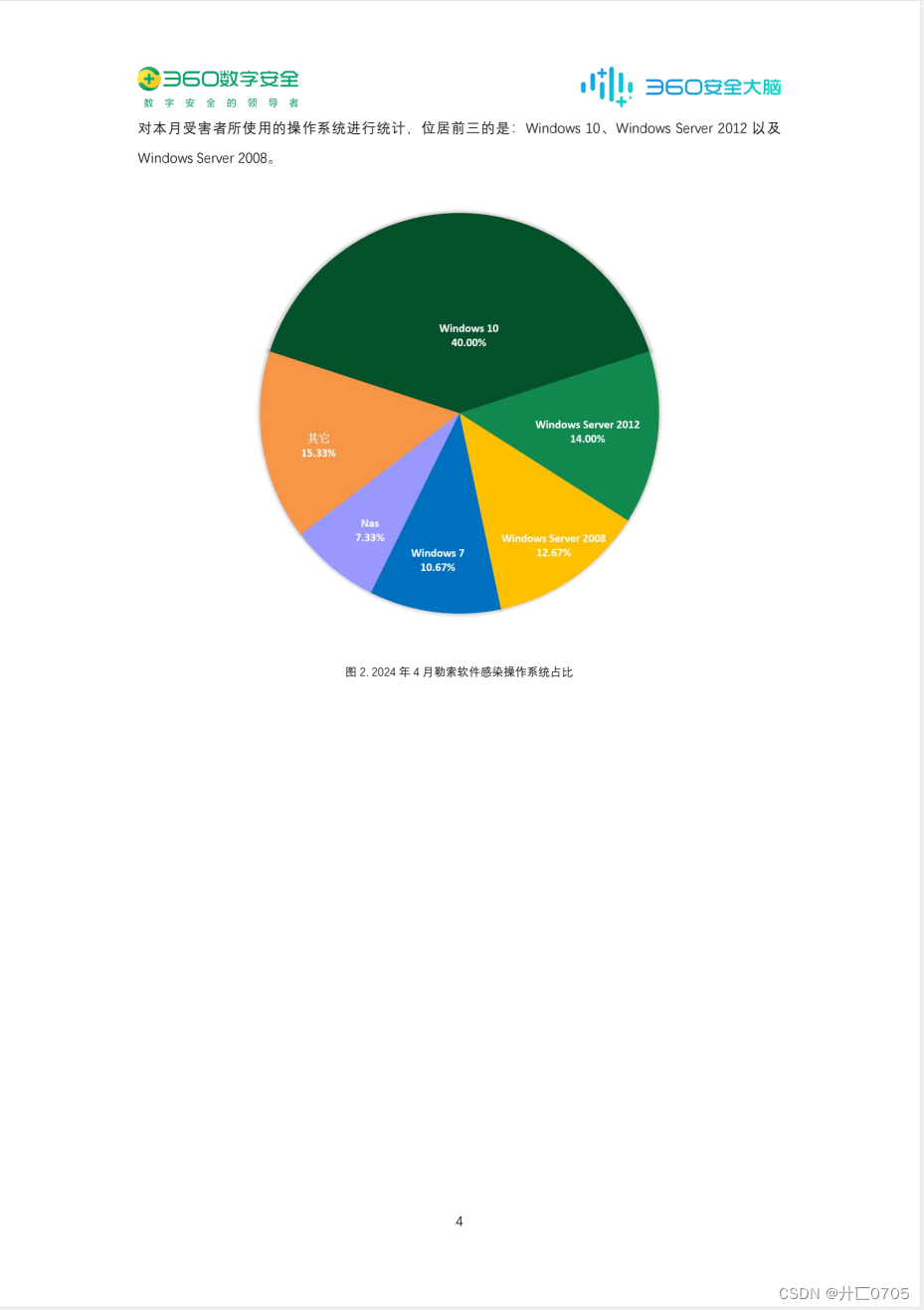
360数字安全:2024年4月勒索软件流行态势分析报告
勒索软件传播至今,360 反勒索服务已累计接收到数万勒索软件感染求助。随着新型勒索软件的快速蔓延,企业数据泄露风险不断上升,勒索金额在数百万到近亿美元的勒索案件不断出现。勒索软件给企业和个人带来的影响范围越来越广,危害性…...
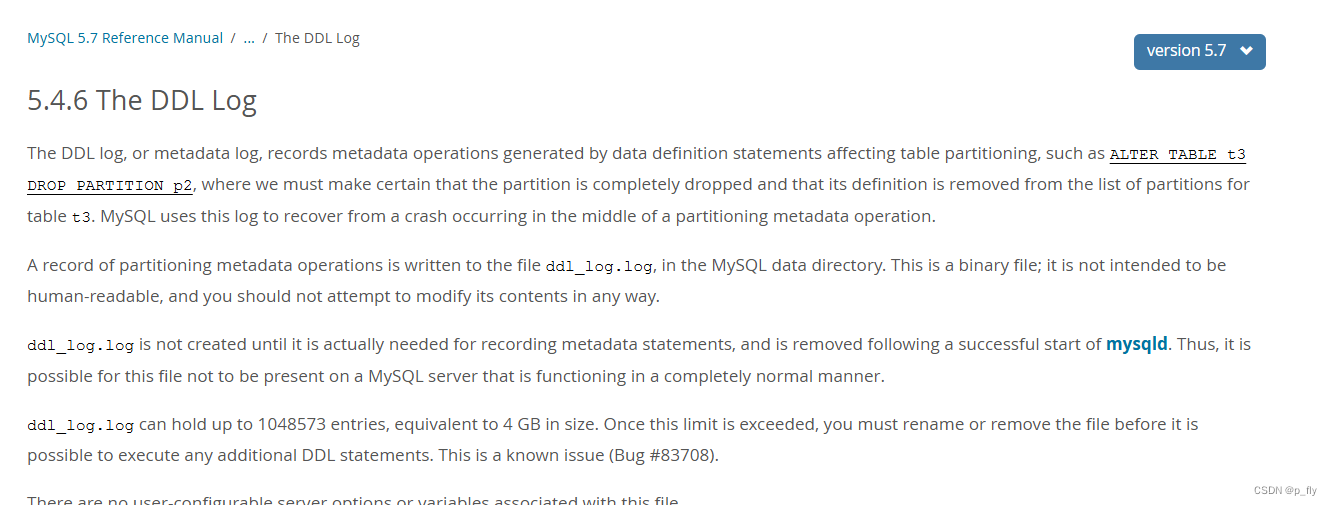
【MySQL】日志详解
本文使用的MySQL版本是8 日志概览 它们记录了数据库系统中的不同操作和事件,以便于故障排除、性能优化和数据恢复。本文将介绍MySQL中常见的几种日志,同时也会介绍一点常用的选项。 官方文档:MySQL :: MySQL 8.0 Reference Manual :: 7.4 M…...

MyBatis 延迟加载,一级缓存,二级缓存设置
MyBatis不仅提供了一级缓存和二级缓存机制,还支持延迟加载(Lazy Loading),以进一步优化性能。 1. 延迟加载(Lazy Loading) 延迟加载是在需要时才加载数据,而不是在查询时立即加载所有相关数据。…...

Linux 基本指令2
cp 指令 cp[选项]源文件 目标文件 将源文件的内容复制到目标文件中,源文件可以有多个,最后一个文件为目标文件,目标文件也可以是一段路径,若目的地不是一个目录的话会拷贝失败。若没有路径上的目录则会新建一个,若源是…...

从四皇后到N皇后:回溯算法的核心思想与实战演练
1. 从棋盘游戏到算法思维:四皇后问题入门 记得我第一次接触四皇后问题时,正坐在大学算法课的教室里。教授用粉笔在黑板上画出一个4x4的棋盘,然后突然转身问我们:"如果让你们来摆放这四个皇后,保证她们互不攻击&am…...
可行性验证)
亚洲美女-造相Z-Turbo可部署方案:适配信创环境(麒麟OS+昇腾910B)可行性验证
亚洲美女-造相Z-Turbo可部署方案:适配信创环境(麒麟OS昇腾910B)可行性验证 今天我们来聊聊一个挺有意思的话题:怎么把一个专门生成亚洲美女图片的AI模型,部署到咱们国产的信创环境里。这个模型叫“亚洲美女-造相Z-Tur…...

Univer全栈框架实战指南:3步构建企业级AI原生表格应用
Univer全栈框架实战指南:3步构建企业级AI原生表格应用 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is d…...

MiniCPM-V 4.5 本地部署全攻略:从环境配置到图片、视频、多图推理实战
MiniCPM-V 4.5 本地部署全攻略:从环境配置到图片、视频、多图推理实战 在人工智能技术飞速发展的今天,视觉-语言多模态模型正成为研究和应用的热点。MiniCPM-V 4.5作为这一领域的最新成果,凭借其卓越的性能和高效的推理能力,为开…...

2026年了,为什么很多企业做了智慧气象,结果还是没把风险降下来?
上个月,和一位新能源集团的运营负责人聊天,他抛出一个百思不得其解的问题:“我们花了300多万上了智慧气象系统,接了精细化预报,预警信息每天推送到手机、电脑、大屏,三个渠道同步。结果上个月一场雷暴&…...

别再只会用‘Let‘s think step by step’了:DeepSeek-R1原生CoT机制详解与实战调优
解锁DeepSeek-R1推理潜能:原生思维链技术深度解析与高阶应用指南 当我们在数学考试中遇到复杂题目时,老师总会强调"把解题过程写清楚"。这种分步思考的方式,正是人类解决复杂问题的核心方法。如今,大语言模型也掌握了这…...
)
Ollama搭配BGE-M3实战:手把手教你构建个人知识库问答系统(附完整代码)
Ollama与BGE-M3实战:从零构建智能知识库问答系统 你是否经常遇到这种情况——电脑里存了几百份技术文档、产品手册或会议纪要,急需查找某个具体问题的答案时,却不得不在成堆的文件中手动翻找?传统的关键词搜索往往返回大量无关结果…...

NVIDIA Profile Inspector 终极指南:免费解锁显卡隐藏性能的完整教程
NVIDIA Profile Inspector 终极指南:免费解锁显卡隐藏性能的完整教程 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 想要让游戏画面更流畅、画质更清晰吗?NVIDIA Profile Inspe…...

STM32CubeIDE工程复制粘贴保姆级教程:告别重复配置,5分钟搞定新项目
STM32CubeIDE工程复制粘贴保姆级教程:告别重复配置,5分钟搞定新项目 每次启动新项目时,你是否还在重复那些繁琐的初始化步骤?从零开始配置时钟树、外设参数、中断优先级,不仅耗时费力,还容易出错。对于经验…...

Unity渲染流水线中的NDC空间:从齐次裁剪到屏幕坐标的完整转换指南
Unity渲染流水线中的NDC空间:从齐次裁剪到屏幕坐标的完整转换指南 在Unity引擎的渲染流水线中,理解NDC(归一化设备坐标)空间的作用至关重要。这个看似抽象的概念,实际上决定了3D场景如何最终呈现在2D屏幕上。对于想要深…...