Django序列化器详解:普通序列化器与模型序列化器的选择与运用

系列文章目录
- Django入门全攻略:从零搭建你的第一个Web项目
- Django ORM入门指南:从概念到实践,掌握模型创建、迁移与视图操作
- Django ORM实战:模型字段与元选项配置,以及链式过滤与QF查询详解
- Django ORM深度游:探索多对一、一对一与多对多数据关系的奥秘与实践
- 跨域问题与Django解决方案:深入解析跨域原理、请求处理与CSRF防护
- Django视图层探索:GET/POST请求处理、参数传递与响应方式详解
- Django路由与会话深度探索:静态、动态路由分发,以及Cookie与Session的奥秘
- Django API开发实战:前后端分离、Restful风格与DRF序列化器详解
- Django序列化器详解:普通序列化器与模型序列化器的选择与运用
- 还在写0.0…
文章目录
- 系列文章目录
- 前言
- 一、普通序列化器-Serializer
- 1. 普通序列化器编写方式
- 2. 普通序列化器序列化
- 3. 普通序列化器反序列化创建
- 4. 普通序列化器反序列化更新
- 5. 普通序列化器完整代码
- 二、模型序列化器-ModelSerializer
- 1. 模型序列化器编写方式
- 2. 模型序列化器反序列化创建、更新
- 3. 模型序列化器与普通序列化器的对比
前言
在 Django REST framework 中,数据序列化至关重要。本文将探讨 普通序列化器 和 模型序列化器,了解它们的基本功能和差异,帮助您根据项目需求选择合适的序列化器。
Response是不能直接返回ORM数据的,所以需要我们进行序列化操作,可以通过手动将其转为字典或JSON,也可以使用DRF所提供的序列化器,一般建议使用序列化器。
如果你经常使用的是自己去将数据封装为JSON,那么常见的代码模型就像这样
data = models.objects.all()
json_data = {}
for d in data:json_data['age'] = d.agejson_data['name'] = d.name
return Response(json_data)
随字段越来越多,工作量会越来越大,而且有关于时间(DateTimeField、DateField)等字段类型的序列化直接通过JSON也是不行的,需要自己手动编写JSON的序列化器,非常麻烦,于是乎 DRF 就提供了更为便捷的两种序列化器,普通序列化器与模型序列化器
一、普通序列化器-Serializer
1. 普通序列化器编写方式
导包:
from rest_framework import serializers
普通序列化器,可以按照给定字段,将所匹配的ORM数据字段转换为JSON数据,不光可以对一条数据,也可以对一个QuerySet所对应的结果集
例如:
用户表 UserModel:
#models.py
from django.db import models# Create your models here.
class UserModel(models.Model):name = models.CharField(max_length=50)phone = models.CharField(max_length=11)password = models.CharField(max_length=30)info = models.CharField(max_length=100, null=True)def __str__(self):return self.nameclass Meta:db_table = 'user'
普通序列化器UserSerializer定义如下:
#userSerializer.py
class UserSerializer(serializers.Serializer):name = serializers.CharField(max_length=50)phone = serializers.CharField(validators=[validators_phone])password = serializers.CharField(max_length=30)info = serializers.CharField(max_length=100,default="默认值")
序列化器的使用分两个阶段:
1、在客户端请求时,使用序列化器可以完成对数据的反序列化(将字典格式的数据转化为模型对象)。
2、在服务器响应时,使用序列化器可以完成对数据的序列化(将模型对象转化为字典格式的数据)。
2. 普通序列化器序列化
序列化就是将ORM数据放入序列化器加工,诞生出JSON数据对象,序列化器对象的data属性即为处理好的 JSON 数据对象
1、单条数据的序列化:
- 单挑数据的序列化很简单,直接通过序列化器类对象的参数
instance传入查询得到的结果即可
#views.py
class UserIdView(APIView):def get(self, request, id):user = UserModel.objects.get(pk=id)usSer = UserSerializer(instance=user)return Response({"message": "get测试成功!", "data": usSer.data})2、多条数据的序列化:
- 如果使用像filter、all这样的一些ORM方法,获取到的是QuerySet结果集,不是单独数据对象,那么使用序列化器时,需要传入many=True参数,用来表示:传入的不止一条数据。
#views.py
class UserView(APIView):def get(self, request):users = UserModel.objects.all()usSer = UserSerializer(instance=users, many=True)return Response({"message":"get测试成功!","data":usSer.data})Serializer属性中选项参数
| 选项参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_length | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最大值 |
| min_value | 最小值 |
| 通用参数名称 | 作用 |
|---|---|
| read_only | 该字段仅用于序列化输出,需要序列化输出时设置:read_only=True;默认为False |
| write_only | 该字段仅用于反序列输入,需要序列化输入时设置:write_only=True;默认为False |
| required | 该字段表示在反序列化输入时必须输入 |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 对字段进行校验,定义在字段中 |
| error_message | 当字段校验不通过时,报error_message的value值 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
3. 普通序列化器反序列化创建
反序列化的概念很简单,就是把
JSON等数据变为ORM数据对象,甚至是入库或者是修改
DRF要求序列化器必须对数据进行校验,才能获取验证成功的数据或保存成模型类对象
- 在操作过程中,反序列化首先需要通过
data传参- 接着调用
is_valid进行校验,验证成功返回True,反之返回False
- 如果校验失败,还可以通过结果的
errors属性返回错误值is_valid调用后方法会进行字段属性(max_value=10)的校验、自定义的校验等等- 对校验过后的对象调用
save方法,这个save方法会触发序列化器中的create方法
- 普通序列化器中,
create方法默认是没有实现的,需要手动根据模型类进行编写
如果需要自定义校验规则,可以通过
validators实现:
#userSerializer.py
from rest_framework import serializers
from app.models import UserModel
import redef validators_phone(values):r_phone = r"^1[3-9]\d{9}$"if re.match(r_phone, values):print("手机号匹配成功!")else:print("手机号匹配失败,抛出异常!")raise serializers.ValidationError("手机号匹配失败!不满足规则!")class UserSerializer(serializers.Serializer):name = serializers.CharField(max_length=50)phone = serializers.CharField(validators=[validators_phone])password = serializers.CharField(max_length=30)info = serializers.CharField(max_length=100,default="默认值")
比如现在,需要提交数据用到创建User的接口,此时可以这么做
为了能够保证数据成功入库,默认的普通序列化器是不具备入库功能的,需要编写create方法
#userSerializer.py
class UserSerializer(serializers.Serializer):name = serializers.CharField(max_length=50)phone = serializers.CharField(validators=[validators_phone])password = serializers.CharField(max_length=30)info = serializers.CharField(max_length=100,default="默认值")def create(self, validated_data):object = UserModel.objects.create(**validated_data)return object#具体来说,**validated_data的作用是:解包字典。
#它将validated_data字典中的键值对解包为一系列的关键字参数。
成功之后,就可以通过像之前一样的数据提交,编写视图完成数据入库,序列化器可以直接处理request所提交的数据data,并且可以剔除在request.data中其他多余的字段,只会处理序列化器里的字段
# views.py
class UserView(APIView):def post(self, request):ser = UserSerializer(data=request.data) # 传参data,进行反序列化if ser.is_valid():print("校验成功!")ser.save()return Response({"message":"[POST]信息添加成功!"})else:print("校验失败!")return Response({"message": ser.errors})
4. 普通序列化器反序列化更新
反序列化经过校验的数据,不光可以用来创建数据,还可以用来更新数据
- 更新首先需要一个已经存在的数据,所以需要通过
instance参数传递已有的一个ORM对象- 还需要待更新的新值,那么就需要传
data参数- 之后同样需要
is_valid方法调用,检查即将更新进入的数据是否合法- 最终
save触发序列化器中的update方法
默认普通序列化器是没有自带对于数据的更新方法的,现在需要在序列化器里创建
update方法
# userSerializer.py
class UserSerializer(serializers.Serializer):name = serializers.CharField(max_length=50)phone = serializers.CharField(validators=[validators_phone])password = serializers.CharField(max_length=30)info = serializers.CharField(max_length=100,default="默认值")def update(self, instance, validated_data):# instance 要更新的数据,validated_data 是新数据instance.name = validated_data.get('name', instance.name)instance.phone = validated_data.get('phone', instance.phone)instance.password = validated_data.get('password', instance.password)instance.info = validated_data.get('info', instance.info)instance.save()return instance#获取字段值:
#validated_data.get('name') 尝试从 validated_data 字典中获取键为 'name' 的值。
#validated_data 是由序列化器在验证请求数据后生成的一个字典,它包含了经过验证的字段和它们的值。#默认值机制:
#get 方法有一个可选的第二个参数,即默认值。如果 'name' 这个键不存在于validated_data 中,get 方法将返回这个默认值。
#在这个例子中,如果请求数据中没有包含 'name' 字段,那么默认值就是 instance.name,即当前模型实例的 name 字段的值。
然后通过PUT传递要更新数据的ID,以及更新后的值,来为某条数据更新
class UserIdView(APIView):def put(self, request, id):user = UserModel.objects.get(pk=id)ser = UserSerializer(instance=user, data=request.data)if ser.is_valid():print("校验成功!")ser.save()return Response({"message": "[PUT]信息修改成功!"})else:print("校验失败!")return Response({"message": ser.errors})
5. 普通序列化器完整代码
models.py:
from django.db import models# Create your models here.
class UserModel(models.Model):name = models.CharField(max_length=50)phone = models.CharField(max_length=11)password = models.CharField(max_length=30)info = models.CharField(max_length=100, null=True)def __str__(self):return self.nameclass Meta:db_table = 'user'
userSerializer.py:
from rest_framework import serializers
from app.models import UserModel
import redef validators_phone(values):r_phone = r"^1[3-9]\d{9}$"if re.match(r_phone, values):print("手机号匹配成功!")else:print("手机号匹配失败,抛出异常!")raise serializers.ValidationError("手机号匹配失败!不满足规则!")class UserSerializer(serializers.Serializer):name = serializers.CharField(max_length=50)phone = serializers.CharField(validators=[validators_phone])password = serializers.CharField(max_length=30)info = serializers.CharField(max_length=100,default="默认值")def create(self, validated_data):object = UserModel.objects.create(**validated_data)return objectdef update(self, instance, validated_data):# instance 要更新的数据,validated_data 是新数据instance.name = validated_data.get('name', instance.name)instance.phone = validated_data.get('phone', instance.phone)instance.password = validated_data.get('password', instance.password)instance.info = validated_data.get('info', instance.info)instance.save()return instance
views.py:
from rest_framework.views import APIView
from rest_framework.response import Response
from app.models import UserModel
from app.serializer.userSerializer import UserSerializer
from django.shortcuts import render# Create your views here.class UserView(APIView):def get(self, request):users = UserModel.objects.all()usSer = UserSerializer(instance=users, many=True)return Response({"message":"get测试成功!","data":usSer.data})def post(self, request):ser = UserSerializer(data=request.data) # 传参data,进行反序列化if ser.is_valid():print("校验成功!")ser.save()return Response({"message":"[POST]信息添加成功!"})else:print("校验失败!")return Response({"message": ser.errors})class UserIdView(APIView):def get(self, request, id):user = UserModel.objects.get(pk=id)usSer = UserSerializer(instance=user)return Response({"message": "get测试成功!", "data": usSer.data})def put(self, request, id):user = UserModel.objects.get(pk=id)ser = UserSerializer(instance=user, data=request.data)if ser.is_valid():print("校验成功!")ser.save()return Response({"message": "[PUT]信息修改成功!"})else:print("校验失败!")return Response({"message": ser.errors})
urls.py:
from django.urls import path
from app.views import UserView,UserIdViewurlpatterns = [path('user/', UserView.as_view()),path('user/<int:id>/', UserIdView.as_view()),
]二、模型序列化器-ModelSerializer
1. 模型序列化器编写方式
之前的普通序列化器,很明显可以感觉到,如果模型类字段少了,还行,但是模型字段越来越多,那么开发者在序列化器里所要复刻的字段也要越来越多,很麻烦, 而且还得手动实现
update和create方法,而且光写了序列化器字段还不行,还得有字段属性
于是乎,有了现在的与模型类关联的序列化器,可以更加方便的进行字段映射以及内置方法的编写
模型类关联序列化器大概总结有如下三个特性,一个缺点:
- 特点:
- 基于模型类自动生成一系列字段
- 自动生成的系列字段,同时还包含
unique、max_length等属性校验- 包含默认的
create和update的实现- 缺点:
- 不会自动映射模型类字段的
default属性
模型类关联的序列化器用的是新的序列化器基类:
from rest_framework.serializers import ModelSerializer
用户模型类依旧使用上文中的UserModel.py文件
按照之前的普通序列化写法,你需要同步一个字段,并将字段属性也要记得同步,非常麻烦,但通过与模型类关联的序列化器就很简单了。
- 首先通过继承
ModelSerializer基类- 通过序列化器元类属性中的
model属性关联模型类- 通过序列化器元类属性中的
fields属性指明序列化器需要处理的字段
# userModelSerializer.py
from rest_framework import serializers
from app.models import UserModelclass UserModelSerializer(serializers.ModelSerializer):# 不需要再重写 create 和 update 方法了,可查看ModelSerializer源码class Meta:model = UserModelfields = '__all__' # 指明所有模型类字段# exclude = ('password',) # 排除掉的字段# read_only_fields = ('name','info') # 只用于序列化的字段# fields = ('name','phone','password','info')# extra_kwargs = {# 'info':{'min_length':5, 'required':True},# } #修改原有字段的选项参数
模型类关联的序列化器和普通的序列化器使用方法一样,使用序列化器返回当前所有的商品数据,还是像之前一样传入instance参数即可,还要记得由于是多个商品,不是单独数据,要记得加many=True参数
2. 模型序列化器反序列化创建、更新
模型序列化器的创建就更简单了,不需要手动实现create方法,大致流程如下:
- 为序列化器绑定数据,
ser=Serializer(data=request.data)- 校验数据,
ser.is_valid()- 存储入库,
ser.save()
创建用户接口:
from rest_framework.views import APIView
from rest_framework.response import Response
from app.models import UserModel
from app.serializer.userModelSerializer import UserModelSerializer# Create your views here.class UserView(APIView):def get(self, request):users = UserModel.objects.all()usSer = UserModelSerializer(instance=users, many=True)return Response({"message":"get测试成功!","data":usSer.data})def post(self, request):ser = UserModelSerializer(data=request.data) # 传参data,进行反序列化if ser.is_valid():print("校验成功!")ser.save()return Response({"message":"[POST]信息添加成功!"})else:print("校验失败!")return Response({"message": ser.errors})
注意: 反序列化自动生成的字段属性中,不会包含原始模型类字段中的default字段属性
更细用户信息接口:
更新某一个商品数据,模型序列化器也是自带了update方法
class UserIdView(APIView):def get(self, request, id):user = UserModel.objects.get(pk=id)usSer = UserModelSerializer(instance=user)return Response({"message": "get测试成功!", "data": usSer.data})def put(self, request, id):user = UserModel.objects.get(pk=id)ser = UserModelSerializer(instance=user, data=request.data)if ser.is_valid():print("校验成功!")ser.save()return Response({"message": "[PUT]信息修改成功!"})else:print("校验失败!")return Response({"message": ser.errors})
3. 模型序列化器与普通序列化器的对比
- 序列化时,将模型类对象传入
instance参数- 序列化结果使用序列化器对象的
data属性获取得到
- 序列化结果使用序列化器对象的
- 反序列化创建时,将要被反序列化的数据传入
data参数- 反序列化一定要记得先使用
is_valid校验
- 反序列化一定要记得先使用
- 反序列化更新时,将要更新的数据对象传入
instance参数,更新后的数据传入data参数 - 模型序列化器比普通序列化器更加方便,自动生成序列化映射字段,
create、update方法等 - 关联外键序列化,字段属性外键为多时要记得加
many=True

相关文章:
Django序列化器详解:普通序列化器与模型序列化器的选择与运用
系列文章目录 Django入门全攻略:从零搭建你的第一个Web项目Django ORM入门指南:从概念到实践,掌握模型创建、迁移与视图操作Django ORM实战:模型字段与元选项配置,以及链式过滤与QF查询详解Django ORM深度游ÿ…...
Commons-io工具包与Hutool工具包
Commons-io Commons-io是apache开源基金组织提供的一组有关IO操作的开源工具包 作用:提高I0流的开发效率。 FileUtils类(文件/文件夹相关) static void copyFile(File srcFile,File destFile) 复制文件 static void copyDirectory(File srcDir,File destDir) 复…...

ROS中Twist消息类型
Twist消息类型在Robot Operating System (ROS)中是一个常见的数据结构,主要用于描述物体的线性速度和角速度。这种消息类型在ROS的geometry_msgs包中定义,常用于机器人运动控制,尤其是当需要向机器人发布速度指令时。 Twist消息由两个Vector…...
Pixi.js学习 (四)鼠标跟随、元素组合与图片位控
目录 一、鼠标移动跟随 1.1 获取鼠标坐标 1.2 鼠标跟随 二、锚点、元素组合 2.1 锚点 2.2 元素组合 三、图片图层 四、实战 例题一:完成合金弹头人物交互 例题二:反恐重击瞄准和弹痕 例题一代码: 例题二代码: 总结 前言 为了提高作…...

Golang | Leetcode Golang题解之第139题单词拆分
题目: 题解: func wordBreak(s string, wordDict []string) bool {wordDictSet : make(map[string]bool)for _, w : range wordDict {wordDictSet[w] true}dp : make([]bool, len(s) 1)dp[0] truefor i : 1; i < len(s); i {for j : 0; j < i;…...
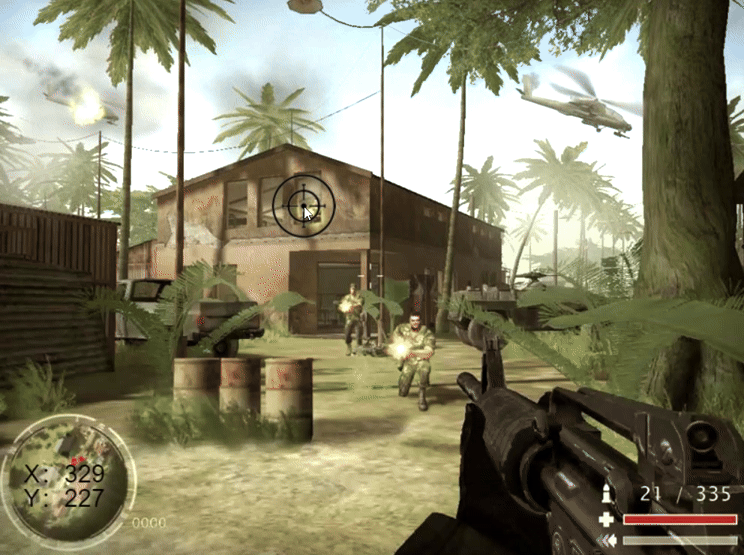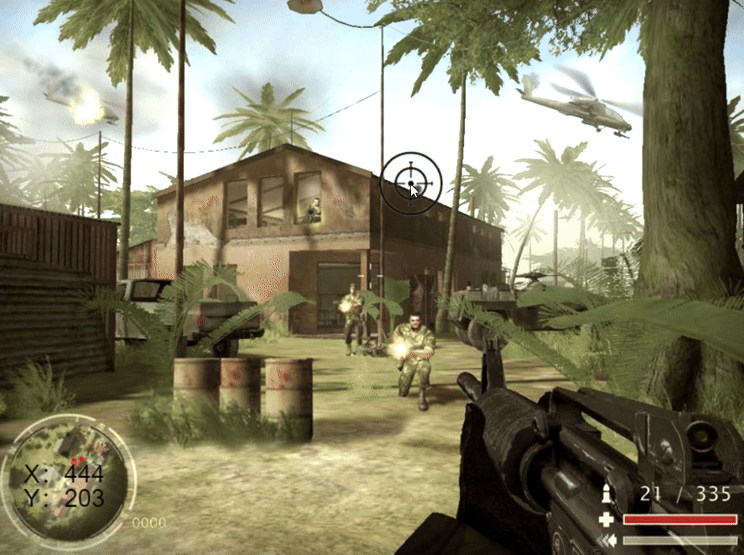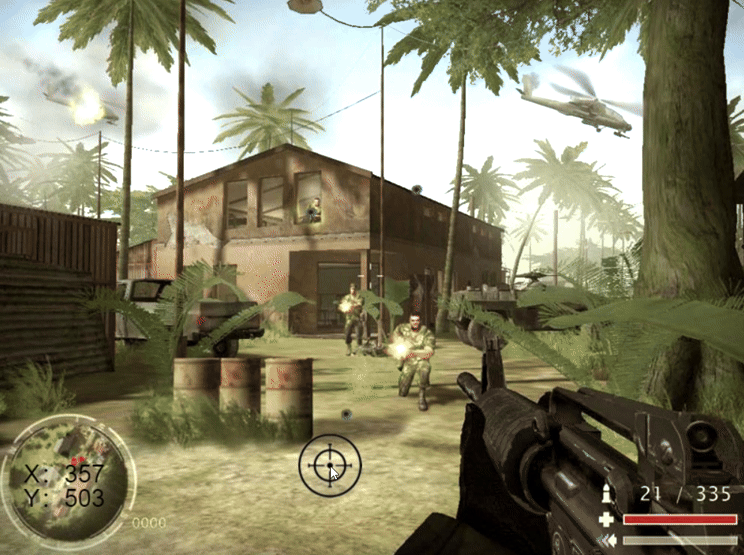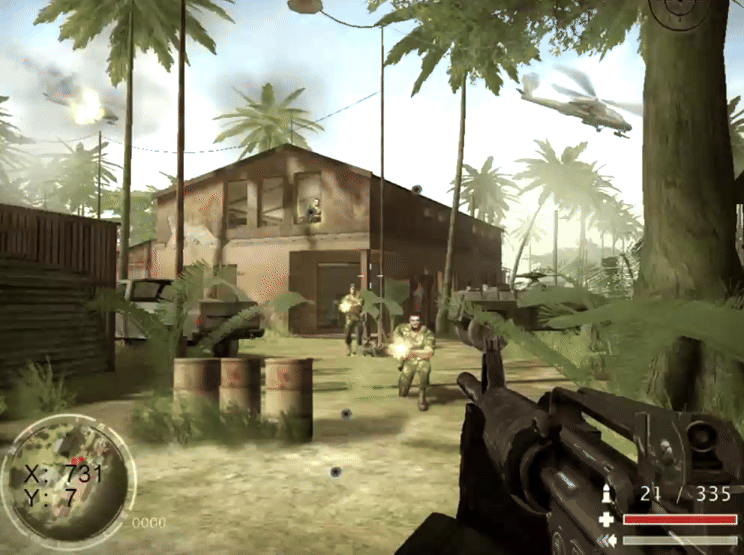
简单聊一下Oracle,MySQL,postgresql三种锁表的机制,行锁和表锁
MySQL: MySQL使用行级锁定和表级锁定。行级锁定允许多个会话同时写入表,适用于多用户、高并发和OLTP应用。表级锁定只允许一个会话一次更新表,适用于只读、主要读取或单用户应用。 比如mysql开启一个窗口执行 begin; update xc_county_a…...

Python的网络请求
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 在上一节中多次提到了URL地址与下载网页,这两项是网络爬虫必备而又关键的功能,说到这两个功能必然会提到HTTP。本节将介绍在P…...

[Shell编程学习路线]——探讨Shell中变量的作用范围(export)
🏡作者主页:点击! 🛠️Shell编程专栏:点击! ⏰️创作时间:2024年6月14日10点14分 🀄️文章质量:95分 文章目录 ————前言———— 定义变量: 输出变…...
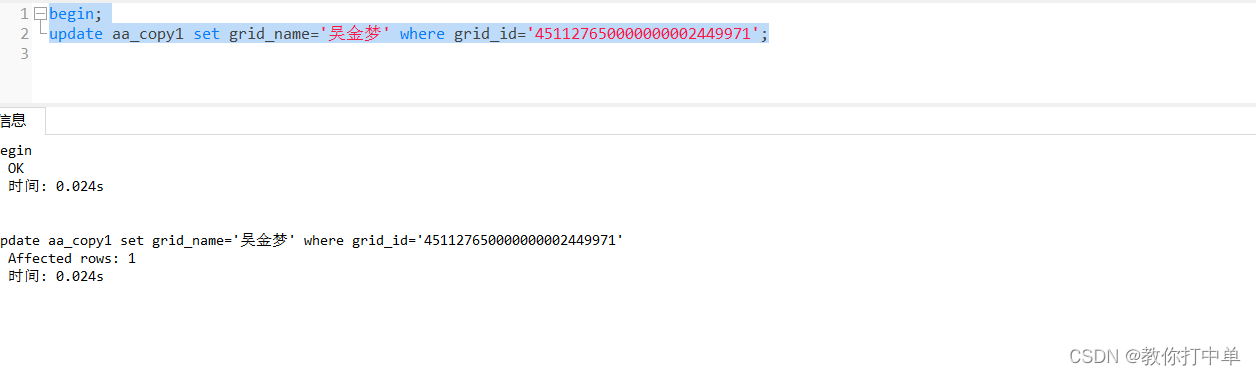
AlertManager解析:构建高效告警系统
一、AlertManager简介 AlertManager是一个开源的告警管理工具,主要用于处理来自于监控系统(如Prometheus)的告警。它的设计目标是提供一个统一的告警处理平台,能够集中管理告警的路由、去重、分组和通知等操作。在现代云服务架构中…...

打造专属 Switch 模拟游戏机
文章目录 2种方案Switch版RetroArchLakka系统 整体性能对比:Lakka更优核心是否兼容:并不兼容整合2种方案:共享游戏ROM和配置、资源等文件夹临时修改Samba共享整个Lakka系统根目录 存储空间优化添加模拟器核心Switch版RetroArchLakka 添加游戏…...
函数和isinstance()函数)
如何使用Python中的type()函数和isinstance()函数
在Python中,type()函数和isinstance()函数都用于确定一个对象的类型,但它们在用法和目的上有所不同。 1. type()函数 type()函数返回对象的数据类型(或类)。它接受一个参数(即要检查的对象),并…...

【LeetCode刷题】前缀和解决问题:560.和为k的子数组
【LeetCode刷题】Day 16 题目1:560.和为k的子数组思路分析:思路1:前缀和 哈希表 题目1:560.和为k的子数组 思路分析: 问题1:怎样找到数组所有子数组? 方式一:暴力枚举出来&#x…...
DTU在城市智慧供热上的应用:引领供热行业的智能化革新
随着城市化的快速推进和人们对舒适生活需求的日益增长,供热系统作为城市基础设施的重要组成部分,其智能化、高效化的发展已成为必然趋势。在这一进程中,DTU(Data Transfer Unit,数据传输单元)以其独特的优势…...
LeetCode | 58.最后一个单词的长度
这道题要求最后一个单词的长度,第一个想到的就是反向遍历字符串,寻找最后一个单词并计算其长度。由于尾部可能会有’ ,所以我们从后往前遍历字符串,找到第一个非空格的字符,然后记录下到下一个空格前依次有多少个字母即…...

202479读书笔记|《你是人间的四月天》——谁又能参透这幻化的轮回, 谁又大胆的爱过这伟大的变幻?
202479读书笔记|《你是人间的四月天》——谁又能参透这幻化的轮回, 谁又大胆的爱过这伟大的变幻? 散文诗歌书信 《你是人间的四月天(果麦经典)》作者林徽因,才女的散文,诗歌,书信集选。很值得一…...

近期docker镜像加速器被封杀,需要的请看此内容 点赞加关注
{ “registry-mirrors”: [“https://docker.m.daocloud.io”], “insecure-registries”: [“harbor.sunya.com”], “exec-opts”: [“native.cgroupdriversystemd”], “data-root”: “/data/docker”, “log-driver”: “json-file”, “log-opts”: {“max-size”:“500m…...

开源大模型的新星:ChatGPT-Next-Web 项目解析与推荐
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

【区块链】记账的千年演化:从泥板到区块链
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 记账的千年演化:从泥板到区块链引言一、古代记账:泥板与…...

MySQL的索引类型,以及各自的作用
MySQL的索引类型,以及各自的作用 常见的索引类型 主键索引(Primary Key Index): 唯一标识表中的记录,确保索引列的值在整个表中是唯一的主键索引通常是唯一索引的一种特例作用:加速查询,并自动…...

数组中的map方法
JavaScript中的map()方法详解 map()方法经常拿来遍历数组,但是不改变原数组,但是会返回一个新的数组,并且这个新的数组不会改变原数组的长度 注意:有时候会出现这种现象,出现几个undefined const array [1, 4,9, 16…...

Qwen2.5-14B-Instruct深度微调实录:像素剧本圣殿开源剧本创作指南
Qwen2.5-14B-Instruct深度微调实录:像素剧本圣殿开源剧本创作指南 1. 项目概览 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct大模型深度微调的专业剧本创作工具。这个开源项目将前沿AI技术与复古像素美学相结合&#…...

ONLYOFFICE社区模块功能详解:博客、论坛、投票与Wiki的完整协作指南
ONLYOFFICE社区模块功能详解:博客、论坛、投票与Wiki的完整协作指南 【免费下载链接】CommunityServer Free open source office suite with business productivity tools: document and project management, CRM, mail aggregator. 项目地址: https://gitcode.co…...

AI绘画新玩法:图图的嗨丝造相-Z-Image-Turbo部署实战,轻松生成高质量渔网袜图片
AI绘画新玩法:图图的嗨丝造相-Z-Image-Turbo部署实战,轻松生成高质量渔网袜图片 1. 引言:解锁AI绘画的专属风格 你是否曾经遇到过这样的困扰?想要生成特定风格的图片,比如穿着精致渔网袜的人物形象,但使用…...

3分钟掌握英雄联盟身份定制:LeaguePrank终极使用指南
3分钟掌握英雄联盟身份定制:LeaguePrank终极使用指南 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 还在为千篇一律的游戏界面感到乏味吗?想在不违反游戏规则的前提下展示个性风格?LeagueP…...

OpenClaw健康监测:用Phi-3-mini-128k-instruct分析智能手表数据
OpenClaw健康监测:用Phi-3-mini-128k-instruct分析智能手表数据 1. 为什么选择OpenClaw处理健康数据? 去年体检报告上的几项异常指标让我开始关注日常健康监测。虽然手环和智能手表能记录睡眠、心率等数据,但原始数据报表就像一本天书——我…...

告别Edge收藏夹翻页烦恼!用这个免费插件实现多列平铺,效率翻倍
Edge浏览器收藏夹效率革命:多列平铺插件实战指南 每次打开Edge浏览器,面对那串长得仿佛没有尽头的单列收藏夹,你是不是也感到一阵无力?滚动、翻页、再滚动——找个书签比找停车位还费劲。作为一名每天要和上百个书签打交道的效率控…...

OpenClaw技能组合:Qwen2.5-VL-7B串联多个自动化任务流
OpenClaw技能组合:Qwen2.5-VL-7B串联多个自动化任务流 1. 为什么需要任务流串联 上周我需要完成一个市场竞品分析的周报,整个过程让我意识到手动操作的效率瓶颈。首先要在电商平台截图商品页面,然后用OCR工具提取价格信息,接着把…...

Phi-3-vision-128k-instruct Vue3前端集成实战:构建智能图像分析Web应用
Phi-3-vision-128k-instruct Vue3前端集成实战:构建智能图像分析Web应用 1. 引言:当Vue3遇见多模态AI 想象一下,你正在开发一个电商网站,需要让系统自动识别用户上传的商品图片并生成详细描述。传统方案要么依赖人工标注&#x…...

Tencent Hunyuan3D-1.0日志轮转配置:防止磁盘空间耗尽的日志管理方案
Tencent Hunyuan3D-1.0日志轮转配置:防止磁盘空间耗尽的日志管理方案 【免费下载链接】Hunyuan3D-1 腾讯开源的Hunyuan3D-1项目,创新提出两阶段3D生成方法,实现快速、高质量的文本到3D和图像到3D转换,融合Hunyuan-DiT模型…...

FireRed-OCR Studio企业应用:银行开户资料图像→KYC字段结构化提取
FireRed-OCR Studio企业应用:银行开户资料图像→KYC字段结构化提取 1. 金融文档数字化的挑战与机遇 在银行开户业务中,客户需要提交身份证、营业执照、税务登记证等多种纸质材料。传统人工录入方式存在三个核心痛点: 效率瓶颈:…...