如何用R语言ggplot2画高水平期刊散点图
文章目录
- 前言
- 一、数据集
- 二、ggplot2画图
- 1、全部代码
- 2、细节拆分
- 1)导包
- 2)创建图形对象
- 3)主题设置
- 4)轴设置
- 5)图例设置
- 6)散点颜色
- 7)保存图片
前言
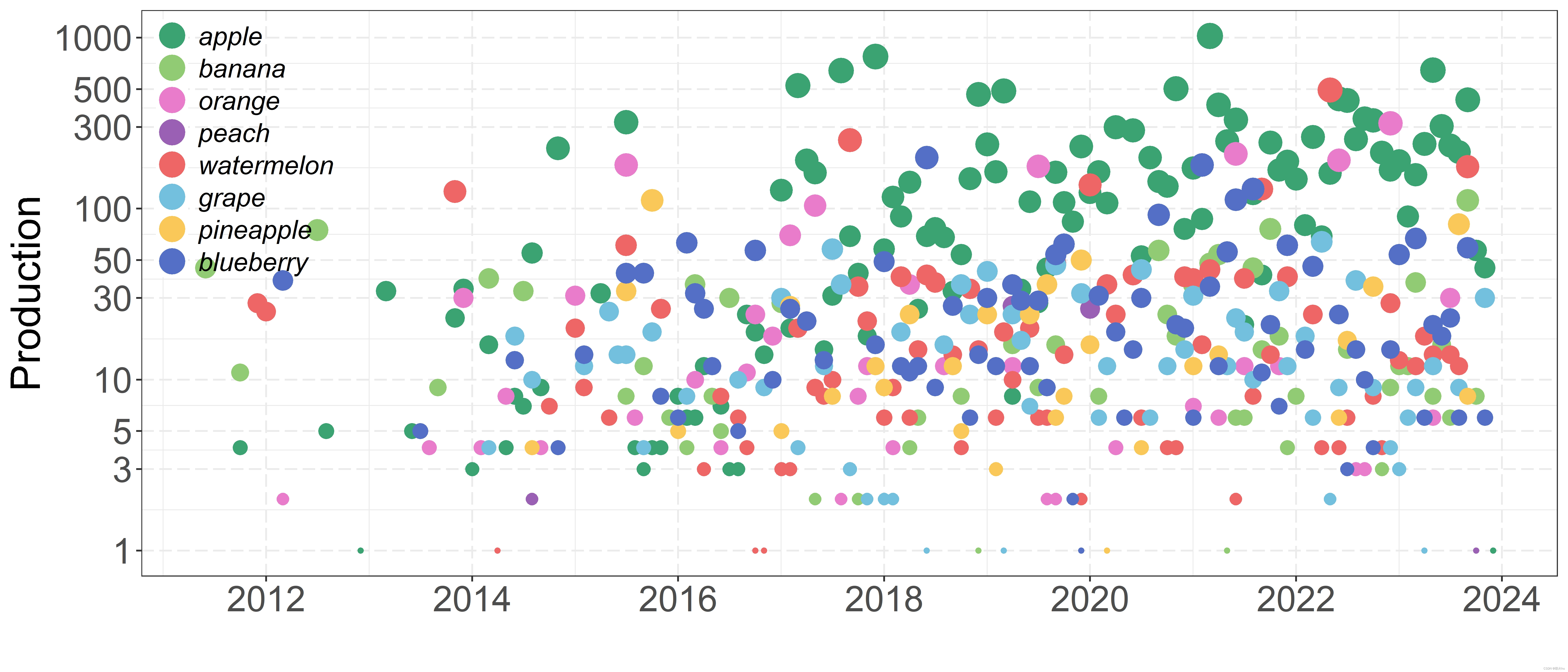
一、数据集
数据下载链接见文章顶部
处理前的数据:
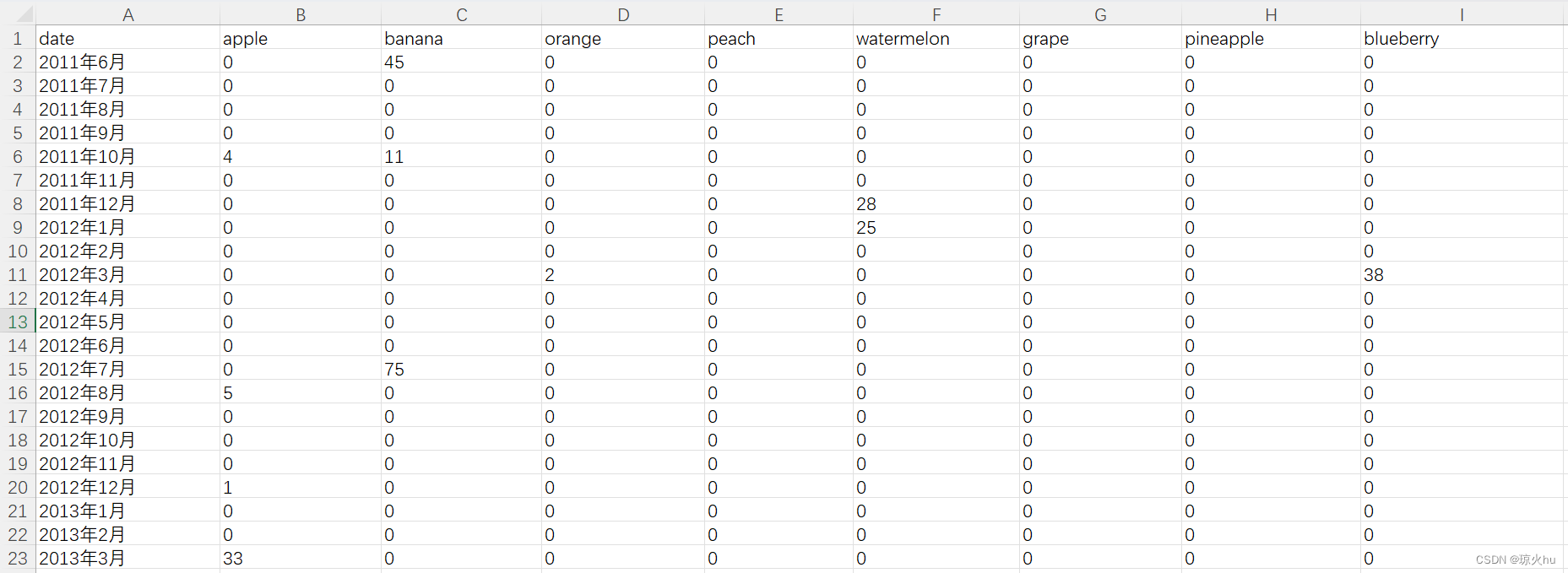
library(readxl)
library(reshape2) # reshape2 包是 R 语言中的一个数据处理包,主要用于数据重塑(reshaping),提供了代码所需的 melt 函数。data = read_excel("fig1_datasets.xlsx", sheet = "Sheet1")
data_melt = melt(data, id.vars = c("date"), variable.name = "fruit", value.name = "production")
data_melt = data_melt[data_melt$production != 0,]
data_melt$size = log(data_melt$production) # 构造 size 列用于表示散点大小,log 函数用于减少最大点和最小点的大小差异。
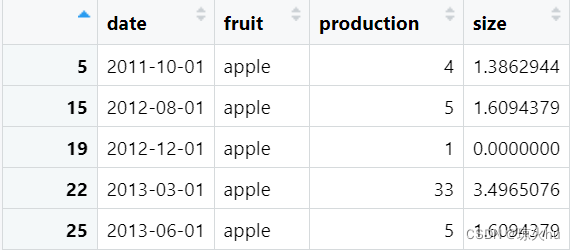
处理后的数据:
二、ggplot2画图
1、全部代码
library(ggplot2)
library(scales)pic =ggplot(data_melt, aes(x = date, y = production, color = fruit, size = size)) +geom_point() +# 主题设置theme_bw() + theme(panel.grid.major = element_line(linetype = 5)) +# 轴设置xlab("") +ylab("Production") +theme(axis.text = element_text(size = 19)) + theme(axis.title = element_text(size = 22)) +scale_x_datetime(breaks = breaks_pretty(n = 8))+scale_y_log10(breaks = breaks_log(n = 10)) +# 图例设置guides(size = 'none') +guides(color = guide_legend(override.aes = list(size = 6))) +theme(legend.title = element_blank()) +theme(legend.text = element_text(size = 14, face = "italic")) +theme(legend.position = c(0.073, 0.765)) +theme(legend.background = element_rect(fill = NA, colour = NA)) +# 散点颜色scale_color_manual(values = c('#3ba272', '#91cc75', '#ea7ccc', '#9a60b4', '#ee6666', '#73c0de', '#fac858', '#5470C6'))jpeg(filename = "test1.png", width = 7000, height = 3000, res = 600, quality = 100)
pic
dev.off()
2、细节拆分
1)导包
library(ggplot2)
library(scales)
ggplot2 中已经提供一些 scale 相关函数用于调整绘图中各种变量的比例尺。然而,还有一个独立的 R 包叫做 scales ,它提供了更多关于比例尺的函数和工具。本案例代码中的 breaks_pretty 函数由其提供。
2)创建图形对象
pic =ggplot(data_melt, aes(x = date, y = production, color = fruit, size = size)) +geom_point()
- 设置 x 轴为日期,y 轴为产量,按 fruit 列的水果类型着色,散点大小为 size 列。
- geom_point 指定画散点图。
3)主题设置
theme_bw() +
theme(panel.grid.major = element_line(linetype = 5))
- theme_bw 指定黑白主题。
- 设置主网格线(坐标轴上的刻度位置对应的网格线为主网格线)为5号线段类型。
4)轴设置
xlab("") +
ylab("Production") +
theme(axis.text = element_text(size = 19)) +
theme(axis.title = element_text(size = 22)) +
scale_x_datetime(breaks = breaks_pretty(n = 8))+
scale_y_log10(breaks = breaks_log(n = 10))
- xlab 设置 x 轴标题,ylab 设置 y 轴标题。
- 设置轴刻度字号19,轴标题字号22。
- scale_x_datetime()函数用于调整 x 轴上日期时间型变量的比例尺,其中breaks参数用于指定刻度的位置。
在这个特定的例子中,breaks_pretty(n = 8)是一个函数调用,它会生成相对于输入数据的合适的刻度位置。参数 n 指定了希望返回的刻度数量。
因此,scale_x_datetime(breaks = breaks_pretty(n = 8)) 的作用是设置 x 轴上日期时间型变量的刻度位置为相对于数据合适的 8 个刻度位置。这样做可以确保刻度位置不会过于拥挤或稀疏,使得图形更易读。 - scale_y_log10() 函数用于对 y 轴上的连续型变量进行对数变换,并且 breaks 参数用于指定刻度的位置。
在这个特定的例子中,breaks_log(n = 10) 是一个函数调用,参数 n 指定了希望返回的刻度数量。scale_y_log10(breaks = breaks_log(n = 10)) 的作用是将 y 轴原本的均匀刻度改为对数刻度,并且使其返回的刻度数量为 10。这样做可以确保对数刻度的刻度位置合适,并且数量适当,以便更好地展示数据。
5)图例设置
guides(size = 'none') +
guides(color = guide_legend(override.aes = list(size = 6))) +
theme(legend.title = element_blank()) +
theme(legend.text = element_text(size = 14, face = "italic")) +
theme(legend.position = c(0.073, 0.765)) +
theme(legend.background = element_rect(fill = NA, colour = NA))
- guides(size = ‘none’) 删除了 size 图例。这里的参数 size 指的是大小美学映射,而不是列名里的 “size”。
- guides(color = guide_legend(override.aes = list(size = 6))) 将图例中的散点大小设为6。
- 设置图例标题为空。
- 设置图例字体为14号斜体。
- 设置图例位置(x, y)为(0.073, 0.765)。
- 设置图例背景填充颜色、边框颜色为无,防止遮挡散点。
6)散点颜色
scale_color_manual(values = c('#3ba272', '#91cc75', '#ea7ccc', '#9a60b4', '#ee6666', '#73c0de', '#fac858', '#5470C6'))
7)保存图片
jpeg(filename = "test1.png", width = 7000, height = 3000, res = 600, quality = 100)
pic
dev.off()
- jpeg 函数打开了一个JPEG设备,设定了图片的保存路径为 “test1.png”,图片的宽度为7000像素,高度为3000像素,分辨率为600 dpi,图片质量为100%。
- pic是之前生成的图形对象。
- dev.off()关闭了之前打开的图形设备,保存了图片到指定路径。这是在完成图片保存后必须执行的步骤,以确保保存的图片被正确地输出。
相关文章:
如何用R语言ggplot2画高水平期刊散点图
文章目录 前言一、数据集二、ggplot2画图1、全部代码2、细节拆分1)导包2)创建图形对象3)主题设置4)轴设置5)图例设置6)散点颜色7)保存图片 前言 一、数据集 数据下载链接见文章顶部 处理前的数据…...

Python基于 Jupyter Notebook 的图形可视化工具库之ipysigma使用详解
概要 在数据科学和网络分析中,图(Graph)结构是一种常用的数据结构,用于表示实体及其关系。为了方便图数据的可视化和交互操作,ipysigma 提供了一个基于 Jupyter Notebook 的图形可视化工具。通过 ipysigma,用户可以在 Jupyter Notebook 中创建、编辑和展示图结构,方便进…...

四叉树和KD树
1. 简介 四叉树和KD树都是用于空间数据索引和检索的树状数据结构。它们通过将空间递归地划分为更小的区域,并存储每个区域内的点,来实现快速搜索和范围查询。 2. 四叉树 2.1 定义 四叉树是一种树状数据结构,它将二维空间递归地划分为四个…...

C语言中结构体使用.与->访问成员变量的区别
文章目录 前言点运算符(.)箭头运算符(->)总结 前言 在C语言中,. 和 -> 都是用来访问结构体成员的运算符,但它们的使用场景和含义有所不同。 提示:以下是本篇文章正文内容,下面…...

计算机二级Access选择题考点
在Access中,若要使用一个字段保存多个图像、图表、文档等文件,应该设置的数据类型是附件。在“销售表"中有字段:单价、数量、折扣和金额。其中,金额单价x数量x折扣,在建表时应将字段"金额"的数据类型定义为计算。若…...

人工智能历史与现状
1 人工智能历史与现状 1.1 人工智能的概念和起源 1.1.1 人工智能的概念 人工智能 (Artificial Intelligence ,AI)是一门研究如何使计算机 能够模拟人类智能行为的科学和技术,目标在于开发能够感知、理解、 学习、推理、决策和解决问题的智能机器。人工智能的概念主要包含 以…...

【git使用一】windows下git下载、安装和卸载
目录 (1)下载安装包 (2)安装git (3)安装验证 (4)卸载git (1)下载安装包 官网下载地址:Git 国内镜像下载地址:CNPM Binaries Mir…...

JVM 类加载器的工作原理
JVM 类加载器的工作原理 类加载器(ClassLoader)是一个用于加载类文件的子系统,负责将字节码文件(.class 文件)加载到 JVM 中。Java 类加载器允许 Java 应用程序在运行时动态地加载、链接和初始化类。 2. 类加载器的工…...

ARM Cortex-M4 CPU指令大全:作用、原理与实例
引言 在计算机系统中,CPU(中央处理器)是执行各种指令的核心部件。ARM Cortex-M4是广泛应用于嵌入式系统中的一款处理器,其指令集架构(ISA)基于ARMv7-M。本文将介绍ARM Cortex-M4处理器中的常见指令&#x…...

Mysql学习(九)——存储引擎
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 七、存储引擎7.1 MySQL体系结构7.2 存储引擎简介7.3 存储引擎特点7.4 存储引擎选择7.5 总结 七、存储引擎 7.1 MySQL体系结构 连接层:最上层是一些客户…...
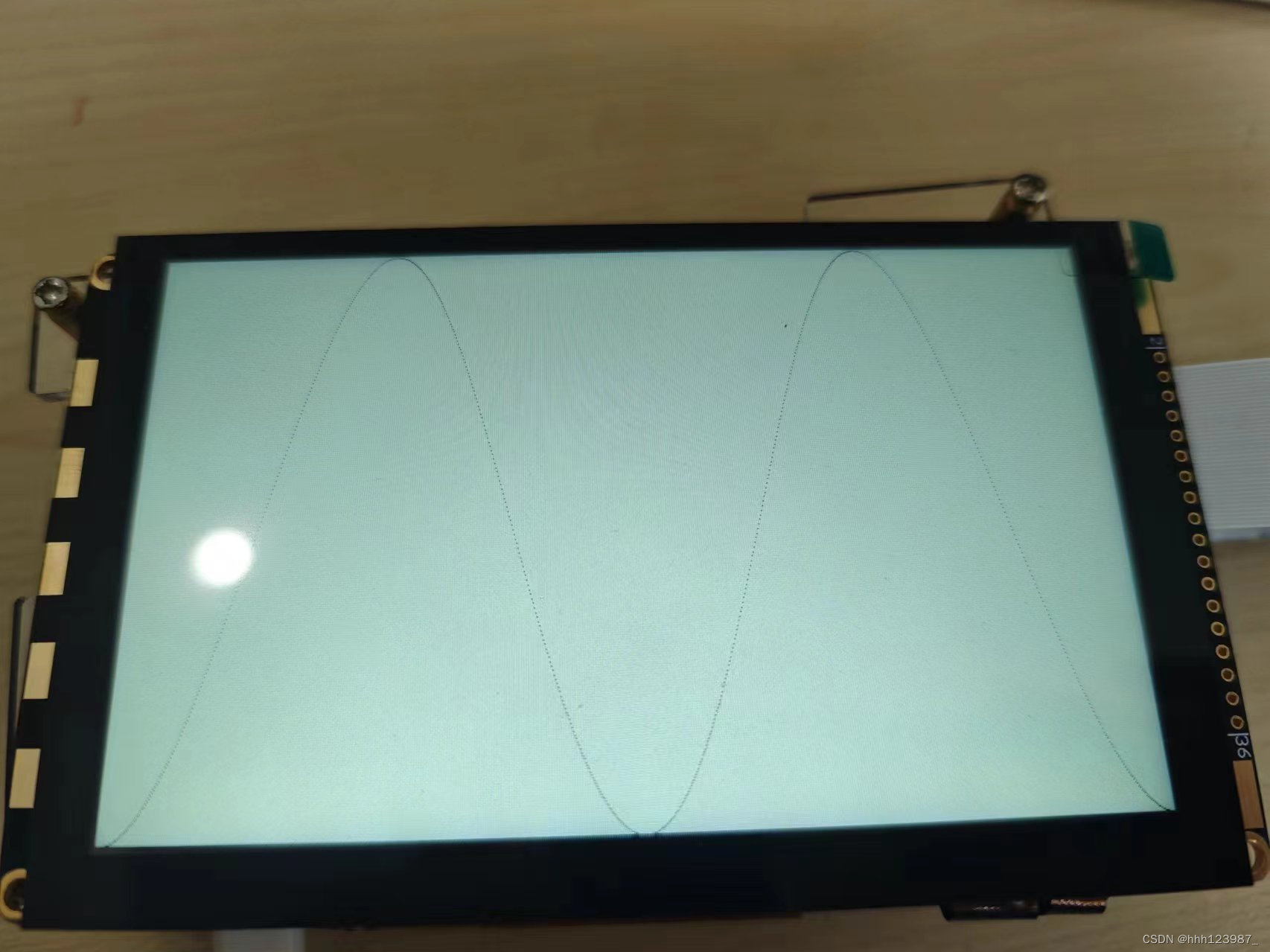
TFT屏幕波形显示
REVIEW 关于TFT显示屏,之前已经做过彩条显示: TFT显示屏驱动_tft驱动-CSDN博客 关于ROM IP核,以及coe文件生成: FPGA寄存器 Vivado IP核_fpga寄存器资源-CSDN博客 1. TFT屏幕ROM显示正弦波 ①生成coe文件 %% sin-cos wave dat…...
服务器无法远程桌面连接不上的问题排查与解决方案
一、问题概述 当尝试使用远程桌面协议(RDP)连接至服务器时,如果连接失败,这通常意味着存在一些配置问题、网络问题或服务器本身的问题。此类问题对于管理员而言,需要系统地进行排查和解决。 二、排查步骤 1. 检查网…...

JAVA面试题整理——内存溢出与内存泄露的区别与联系
内存溢出与内存泄露的区别与联系 在前面jvm学习整理的时候其实用过一个简单的例子了解过内存溢出,在jvm内存模型章节下,大家有兴趣的可以去看看:JVM初学 GC_knowwait的博客-CSDN博客 内存溢出 内存溢出(out of memory)…...

L50--- 104. 二叉树的最大深度(深搜)---Java版
1.题目描述 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 2.思路 这个二叉树的结构如下: 根节点 1 左子节点 2 右子节点 3 左子节点 4 计算过程 从根节点 1 开始计算: 计算左子树的最大深度: 根节点 2…...

Linux 中 “ 磁盘、进程和内存 ” 的管理
在linux虚拟机中也有磁盘、进程、内存的存在。第一步了解一下磁盘 一、磁盘管理 (1.1)磁盘了解 track( 磁道 ) :就是磁盘上的同心圆,从外向里,依次排序1号,2号磁盘........等等。…...

test_pipeline
test_pipeline 是一个测试管道(test pipeline)的定义。 在计算机视觉任务中,通常需要对输入图像进行一系列的预处理操作,以便将其适配到模型的输入要求或提高模型的性能。测试管道就是用于定义这些预处理操作的一系列步骤。 在给…...

使用甲骨文云arm服务器安装宝塔时nginx无法卸载
使用甲骨文云arm服务器安装宝塔 其他环境都能安装上 唯独nginx安装完不运行 卸载了几次以后还无法卸载了. 修复 重启都不行. 差点就重建主机了. 最后靠下面的命令 就卸载掉了 然后重装就把nginx安装好了 mv /www/server/nginx/sbin/nginx /tmp/nginx_back mv /etc/in…...

C++青少年简明教程:C++的指针入门
C青少年简明教程:C的指针入门 说到指针,就不可能脱离开内存。了解C的指针对于初学者来说可能有些复杂,我们可以试着以一种简单、形象且易于理解的方式来解释: 首先,我们可以将计算机内存想象成一个巨大的有许多格子的…...
)
Apache Doris 基础 -- 数据表设计(分层存储)
1、应用场景 未来一个重要的用例是类似于ES日志存储,其中日志场景中的数据是根据日期分割的。许多数据都是查询不频繁的冷数据,因此需要降低此类数据的存储成本。考虑到节约成本: 来自不同厂商的常规云磁盘的定价比对象存储更昂贵。Doris 集群实际在线…...

使用Spring Boot设计一套BI系统
商业智能(Business Intelligence,简称BI)系统是一种将数据转化为可操作信息,帮助企业进行决策支持的技术与工具的集合。随着大数据时代的到来,BI系统在企业中的应用变得越来越广泛。本文旨在探讨如何使用Spring Boot框…...

小红书数据采集实战:5个Python技巧让爬虫更智能
小红书数据采集实战:5个Python技巧让爬虫更智能 【免费下载链接】xhs 基于小红书 Web 端进行的请求封装。https://reajason.github.io/xhs/ 项目地址: https://gitcode.com/gh_mirrors/xh/xhs 在小红书这个拥有数亿用户的社交电商平台上,海量的用…...

OpenClaw日志分析:千问3.5-35B-A3B-FP8任务执行问题定位
OpenClaw日志分析:千问3.5-35B-A3B-FP8任务执行问题定位 1. 问题背景与日志分析的价值 上周我在尝试用OpenClaw自动化处理一批技术文档时,遇到了任务频繁中断的问题。当时对接的是千问3.5-35B-A3B-FP8模型,系统提示"模型响应异常"…...

从生活沟通到AI对话:写好提示词,用好AI的魔法钥匙
一个顿悟:从复杂技术到简单提示最近与一位从事软件开发的朋友交流,他提出了一个颇具启发性的构想:将软件的售后客服工作交给AI来处理。起初,他的思路充满了技术复杂性——计划向AI提供核心代码库、训练一个专属的客服模型、进行深…...

BAR和BA
BAR 是请求方发出的“问题”:“我刚才发的那批数据包,你收到了哪几个?”BA 是接收方回复的“答案”:“我收到了第1、3、4、5个包,第2个没收到。”BAR - Block Ack Request(块确认请求) 角色与发…...

精益生产线功能拆解:如何利用精益生产线解决多品种小批量生产难题
在当前的制造业环境中,订单碎片化已成为常态,精益生产线不再是一个可选的优化项,而是企业生存的必修课。面对多品种、小批量的市场需求,传统的大批量流水线往往显得笨重不堪,频繁换型导致的停机、在制品积压造成的资金…...

嵌入式C++轻量级生命体基类:面向OOP的零开销实体抽象
1. 项目概述life_entity是一个面向嵌入式系统与游戏逻辑建模场景设计的轻量级 C 基类,其核心定位并非通用游戏引擎组件,而是为资源受限环境(如 Cortex-M3/M4 微控制器运行 FreeRTOS 或裸机实时调度器)中实现可继承、可多态、可生命…...
)
C++笔记 继承关系中构造和析构顺序(面向对象)
在C面向对象编程中,继承是实现代码复用和类层次设计的核心特性。当存在基类与派生类的继承关系时,构造函数和析构函数的调用顺序有严格的规则——这不仅是面试高频考点,更是避免内存泄漏、保证对象正确初始化/清理的关键。核心结论先明确&…...

C语言基础:LiuJuan20260223Zimage嵌入式开发入门
C语言基础:LiuJuan20260223Zimage嵌入式开发入门 1. 学习目标与前置知识 如果你是刚开始接触嵌入式开发的C语言初学者,这篇文章就是为你准备的。我们将从最基础的C语言语法开始,一步步带你了解如何在嵌入式环境中使用C语言进行开发。不需要…...

新手福音:在快马平台开启你的云端代码编程第一课
作为一名刚接触编程的新手,我最近发现了一个特别适合入门的学习方式——云端代码编程。以前总觉得学编程要先装一堆软件、配置环境,光是这些准备工作就能劝退不少人。但在InsCode(快马)平台上,这些烦恼都不存在了。 零门槛的编程初体验 打开平…...
)
PX4固件二次开发入门:从源码结构到第一个自定义模块(基于v1.11版本)
PX4固件二次开发实战:从源码解析到自定义模块开发(v1.11版本) 当你第一次打开PX4的源码仓库,面对数十个文件夹和数千个文件时,那种扑面而来的压迫感我深有体会。作为过来人,我想分享一套系统性的二次开发方…...