Apache Doris 基础 -- 数据表设计(分层存储)
1、应用场景
未来一个重要的用例是类似于ES日志存储,其中日志场景中的数据是根据日期分割的。许多数据都是查询不频繁的冷数据,因此需要降低此类数据的存储成本。考虑到节约成本:
- 来自不同厂商的常规云磁盘的定价比对象存储更昂贵。
- Doris 集群实际在线使用时,常规云盘利用率不能达到100%。
- 云磁盘不按需计费,对象存储按需计费。
- 使用普通云磁盘实现高可用性需要多个副本和副本迁移,以防止出现故障。相比之下,将数据存储在对象存储中可以消除这些问题,因为它是共享的。
2、解决方案
在分区级别设置冻结时间,表示多久这个 Partition 会被 Freeze,并定义冻结后数据的远程存储位置。在BE(后端)守护线程中,会定期检查表的冻结状态。如果满足冻结条件,则上传数据到兼容S3协议和HDFS的对象存储。
冷热分层支持所有Doris功能,并且只将一些数据移动到对象存储中,以节省成本而不牺牲功能。因此,它具有以下特点:
- 冷数据存储在对象存储上,用户无需担心数据的一致性和安全性。
- 灵活的冻结策略,其中冷远程存储属性可以应用于表和分区级别。
- 用户可以查询数据,而不用担心数据的分布。如果数据不是本地的,它将从对象存储中提取,并在BE(后端)本地缓存。
- 副本克隆优化。如果存储的数据在对象存储上,克隆副本时不需要在本地获取存储的数据。
- 远程对象空间回收。当表或分区被删除或冷热分级过程中出现特殊情况导致空间浪费时,回收线程会定期回收空间,从而节省存储资源。
- 缓存优化,在BE中本地缓存访问的冷数据,以实现类似于非冷-热分层的查询性能。
- BE线程池优化,区分来自本地和对象存储的数据源,以防止读取对象的延迟影响查询性能。
3、存储策略的使用
存储策略是使用冷热分层特性的入口点。用户只需要在表创建期间或使用Doris时将存储策略与表或分区关联起来。
在创建S3资源时,将执行远程S3连接验证,以确保资源的正确创建。
下面是创建S3资源的示例:
CREATE RESOURCE "remote_s3"
PROPERTIES
("type" = "s3","s3.endpoint" = "bj.s3.com","s3.region" = "bj","s3.bucket" = "test-bucket","s3.root.path" = "path/to/root","s3.access_key" = "bbb","s3.secret_key" = "aaaa","s3.connection.maximum" = "50","s3.connection.request.timeout" = "3000","s3.connection.timeout" = "1000"
);CREATE STORAGE POLICY test_policy
PROPERTIES("storage_resource" = "remote_s3","cooldown_ttl" = "1d"
);CREATE TABLE IF NOT EXISTS create_table_use_created_policy
(k1 BIGINT,k2 LARGEINT,v1 VARCHAR(2048)
)
UNIQUE KEY(k1)
DISTRIBUTED BY HASH (k1) BUCKETS 3
PROPERTIES("storage_policy" = "test_policy"
);
下面是一个创建HDFS资源的示例:
CREATE RESOURCE "remote_hdfs" PROPERTIES ("type"="hdfs","fs.defaultFS"="fs_host:default_fs_port","hadoop.username"="hive","hadoop.password"="hive","dfs.nameservices" = "my_ha","dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2","dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port","dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port","dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");CREATE STORAGE POLICY test_policy PROPERTIES ("storage_resource" = "remote_hdfs","cooldown_ttl" = "300"
)CREATE TABLE IF NOT EXISTS create_table_use_created_policy (k1 BIGINT,k2 LARGEINTv1 VARCHAR(2048)
)
UNIQUE KEY(k1)
DISTRIBUTED BY HASH (k1) BUCKETS 3
PROPERTIES("storage_policy" = "test_policy"
);
使用以下命令将存储策略与现有表关联:
ALTER TABLE create_table_not_have_policy SET ("storage_policy" = "test_policy");
使用实例将存储策略与已有分区关联。
ALTER TABLE create_table_partition MODIFY PARTITION (*) SET ("storage_policy" = "test_policy");
如果在表创建过程中为整个表和某些分区指定了不同的存储策略,那么分区的存储策略集将被忽略,表的所有分区将使用表的存储策略。如果希望某个特定分区具有不同于其他分区的存储策略,可以使用上面提到的方法修改该特定分区的关联。
要了解更多细节,请参考Docs目录中的以下文档:RESOURCE, POLICY, CREATE TABLE, ALTER TABLE,其中提供了详细的解释。
3.1 限制
- 一个表或分区只能与一个存储策略相关联。一旦关联,如果不首先删除它们之间的关联,则不能删除存储策略。
- 存储策略关联的对象信息不支持修改数据存储路径,如
bucket、endpoint、root_path等信息。 - 存储策略支持创建、修改和删除。在删除存储策略之前,请确保没有表引用该存储策略。
- 存储策略支持创建、修改和删除。在删除存储策略之前,请确保没有表引用该存储策略。
- 当启用Merge-on-Write特性时,Unique模型不支持设置存储策略。
4、已占用的冷数据对象大小
方法1:可以使用show proc '/backends'命令查看每个后端上传对象的大小。查找RemoteUsedCapacity字段。请注意,这种方法可能会有一些延迟。
方法2:可以使用show tablet from tableName命令查看表中每个tablet的大小,由RemoteDataSize字段表示。
5、冷数据缓存
如前所述,对冷数据引入缓存是为了优化查询性能和节省对象存储资源。当冷数据在冷却后首次被访问时,Doris将冷却后的数据重新加载到后端(BE)的本地磁盘上。冷数据缓存具有以下特点:
- 缓存存储在BE的磁盘上,不占用内存空间。
- 缓存可以限制大小,并使用LRU (Least Recently Used)进行数据清除。
- 冷数据缓存的实现与联合查询catalog的缓存相同。请参考Filecache的文档了解更多细节。
6、冷数据的压缩
冷数据进入的时间是从数据行集文件写入本地磁盘的那一刻算起,再加上冷却持续时间。由于数据不是一次性写入和冷却的,因此Doris对冷数据执行压缩,以避免对象存储中的小文件问题。然而,冷数据压缩的频率和资源优先级不是很高。建议在冷却前对本地热数据进行压缩处理。您可以调整以下BE参数:
- BE参数
cold_data_compaction_thread_num设置冷数据压缩的并发性。默认值为2。 - BE参数
cold_data_compaction_interval_sec设置数据冷压缩的时间间隔。缺省值是1800秒(30分钟)。
7、冷数据的模式更改
冷数据支持以下模式更改类型:
- 添加或删除列
- 修改列类型
- 调整列序
- 添加或修改索引
8、冷数据的垃圾回收
冷数据的垃圾数据是指没有被任何副本使用的数据。以下情况可能会在对象存储上产生垃圾数据:
- 上传
rowset失败但是有部分segment上传成功。 - 在FE重新选择
CooldownReplica之后,旧的和新的CooldownReplica的行集版本不匹配。FollowerReplicas同步新CooldownReplica的CooldownMeta,旧CooldownReplica中版本不一致的rowset 成为垃圾数据。 - 在冷数据压缩之后,合并前的行集(rowsets)不能立即删除,因为它们可能仍被其他副本使用。但是,最终,所有FollowerReplicas都使用最新合并的行集,合并之前的行集成为垃圾数据。
此外,对象上的垃圾数据不会立即清理。BE参数remove_unused_remote_files_interval_sec设置冷数据垃圾收集的时间间隔。缺省值是21600秒(6小时)。
相关文章:
)
Apache Doris 基础 -- 数据表设计(分层存储)
1、应用场景 未来一个重要的用例是类似于ES日志存储,其中日志场景中的数据是根据日期分割的。许多数据都是查询不频繁的冷数据,因此需要降低此类数据的存储成本。考虑到节约成本: 来自不同厂商的常规云磁盘的定价比对象存储更昂贵。Doris 集群实际在线…...

使用Spring Boot设计一套BI系统
商业智能(Business Intelligence,简称BI)系统是一种将数据转化为可操作信息,帮助企业进行决策支持的技术与工具的集合。随着大数据时代的到来,BI系统在企业中的应用变得越来越广泛。本文旨在探讨如何使用Spring Boot框…...

2024.6.12总结
今天是排毕业照的日子,拍照的时候并没有太过兴奋。后来受到主管说明天就能签offer了,这才喜极而泣。 自从得知自己面试通过后,我是非常高兴,开始幻想着今后的生活。可是,后面在等offer的过程中,我是无比的…...

1027 - 求任意三位数各个数位上数字的和
问题描述 对于一个任意的三位自然数 x ,编程计算其各个数位上的数字之和 S 。 输入 输入一行,只有一个整数 x(100≤x≤999) 。 输出 输出只有一行,包括 1 个整数。 样例 输入 123 输出 6 以下是C实现的代码: 代码1 #…...

K8s 卷快照类
卷快照类 卷快照类 这个警告信息通常出现在使用 kubectl 删除 Kubernetes 集群资源时,如果尝试删除的是集群作用域(cluster-scoped)的资源,但指定了命名空间(namespace),就会出现这个警告。 集…...

从零手写实现 nginx-23-directive IF 条件判断指令
前言 大家好,我是老马。很高兴遇到你。 我们为 java 开发者实现了 java 版本的 nginx https://github.com/houbb/nginx4j 如果你想知道 servlet 如何处理的,可以参考我的另一个项目: 手写从零实现简易版 tomcat minicat 手写 nginx 系列 …...

08_基于GAN实现人脸图像超分辨率重建实战_超分辨基础理论
1. 超分辨的概念与应用 我们常说的图像分辨率指的是图像长边像素数与图像短边像素数的乘积,比如iPhoneX手机拍摄照片的分辨率为 4032px3024px,为1200万像素。 显然,越高的分辨率能获得更清晰的成像。与之同时,分辨率越高也意味着更大的存储空间,对于空间非常有限的移动设…...

React.ReactElement 与 React.ReactNode
React.ReactNode 在 JSX 中作为子元素传递的所有可能类型的并集,这是对子元素的一个非常宽泛的定义。 <RNode><p>One element</p></RNode><RNode><><p>Fragments for</p><p>More elements</p></&g…...

深度解析服务发布策略之蓝绿发布
目录 什么是蓝绿发布 蓝绿发布的优点 蓝绿发布的缺点 蓝绿发布的实现步骤 小结 在软件开发和运维中,发布新版本是一个风险较高的操作。为了降低风险,提高发布的稳定性和可靠性,通常会采取一系列的技术策略。其中蓝绿发布(Blu…...

【Mysql】 深入理解MySQL的执行计划
文章目录 前言一、字段解释二、代码实现三、总结 前言 在日常的数据库操作中,我们经常会遇到一些复杂的查询,这些查询可能会涉及到多个表的联合查询,或者是一些复杂的条件筛选。为了更好地理解和优化这些查询,了解MySQL的执行计划…...

说下你对Spring IOC 的理解
说下你对Spring IOC 的理解 1. Spring IOC是一个管理对象之间依赖关系的容器,它实现了依赖注入技术,可以解决传统的紧耦合问题,降低了项目维护难度。 2. Spring IOC将对象之间的依赖关系交由容器来管理对象,开发者只需要告诉容器…...

前缀和算法:算法秘籍下的数据预言家
✨✨✨学习的道路很枯燥,希望我们能并肩走下来! 文章目录 目录 文章目录 前言 一. 前缀和算法的介绍 二、前缀和例题 2.1 【模版】前缀和 2.2 【模板】二维前缀和 2.3 寻找数组的中间下标 2.4 除自身以外数组的乘积 2.5 和为k的子数组 2.6 和可被k整除的子数组 2.7 …...

基于PointNet / PointNet++深度学习模型的激光点云语义分割
一、场景要素语义分割部分的文献阅读笔记 1.1 PointNet PointNet网络模型开创性地实现了直接将点云数据作为输入的高效深度学习方法(端到端学习)。最大池化层、全局信息聚合结构以及联合对齐结构是该网络模型的三大关键模块,最大池化层解决了…...
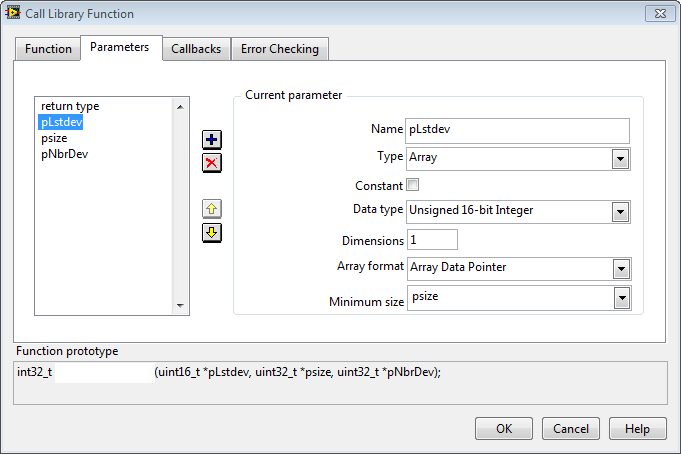
LabVIEW调用DLL时需注意的问题
在LabVIEW中调用DLL(动态链接库)是实现与外部代码集成的一种强大方式,但也存在一些常见的陷阱和复杂性。本文将从参数传递、数据类型匹配、内存管理、线程安全、调试和错误处理等多个角度详细介绍LabVIEW调用DLL时需要注意的问题,…...

时序预测 | MATLAB实现TCN-Attention自注意力机制结合时间卷积神经网络时间序列预测
时序预测 | MATLAB实现TCN-Attention自注意力机制结合时间卷积神经网络时间序列预测 目录 时序预测 | MATLAB实现TCN-Attention自注意力机制结合时间卷积神经网络时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.MATLAB实现TCN-Attention自注意力机制结合时…...

上位机图像处理和嵌入式模块部署(h750 mcu vs f407)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 在目前工业控制上面,f103和f407是用的最多的两种stm32 mcu。前者频率低一点,功能少一点,一般用在低端的嵌入式设…...
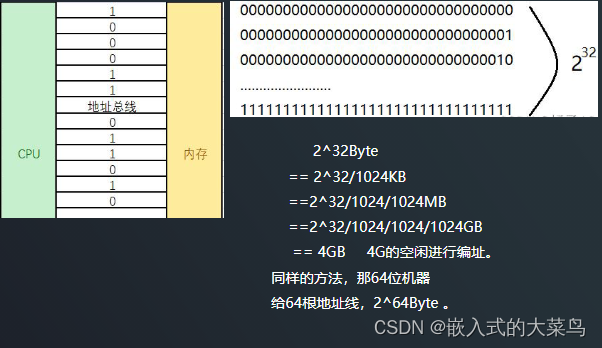
Linux C语言:指针和指针变量
一、指针的作用 使程序简洁、紧凑、高效有效地表示复杂的数据结构动态分配内存能直接访问硬件能够方便的处理字符串得到多于一个的函数返回值 二、内存、地址和变量 1、内存地址 2、变量和地址 1)变量用来在程序中保存数据 比如: int k 58; //声明一个int变…...

Llama模型家族之Stanford NLP ReFT源代码探索 (二)Intervention Layers层
LlaMA 3 系列博客 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (三) 基于 LlaMA…...

MATLAB神经网络---序列输入层sequenceInputLayer
序列输入层sequenceInputLayer 描述一: sequenceinputlayer是Matlab深度学习工具箱中的一个层,用于处理序列数据输入。它可以将输入数据转换为序列格式,并将其传递给下一层进行处理。该层通常用于处理文本、语音、时间序列等类型的数据。在使用该层时&…...

使用CSS、JavaScript、jQuery三种方式实现手风琴效果
手风琴效果有不少,王者荣耀官网(源网址 https://pvp.qq.com/raiders/ )有一处周免英雄,使用的就是手风琴效果,如图所示。 我试着用css、js、jQuery三种方式实现了这种效果,最终效果差不多,美中不…...
:覆盖90%考点,小白也能直接背)
MySQL高频面试题(2026最新版):覆盖90%考点,小白也能直接背
很多开发者备考时,要么盲目刷题、记不住重点,要么只背答案、不懂原理,面试时被面试官追问一句就卡壳。其实MySQL面试没有那么复杂,核心考点就那么多,只要吃透高频题、理解底层逻辑,就能从容应对。本文整理了…...

OpenClaw多模态实践:Qwen3.5-9B-VL图文报告自动生成
OpenClaw多模态实践:Qwen3.5-9B-VL图文报告自动生成 1. 为什么需要多模态自动化 去年整理学术文献时,我每天要手动截取论文图表、复制关键数据、整理成Markdown笔记。这个过程不仅耗时,还经常漏掉重要细节。直到发现OpenClaw可以对接Qwen3.…...

intv_ai_mk11企业应用案例:如何将intv_ai_mk11集成进内部知识库与客服预处理流程
intv_ai_mk11企业应用案例:如何将intv_ai_mk11集成进内部知识库与客服预处理流程 1. 企业面临的挑战与AI解决方案 在当今企业运营中,知识管理和客户服务是两大核心痛点。许多企业面临以下问题: 知识库利用率低:员工难以快速找到…...

FinalBurn Neo技术指南:现代设备复刻街机厅沉浸体验全攻略
FinalBurn Neo技术指南:现代设备复刻街机厅沉浸体验全攻略 【免费下载链接】FBNeo FinalBurn Neo - We are Team FBNeo. 项目地址: https://gitcode.com/gh_mirrors/fb/FBNeo 如何在现代设备上复刻街机厅的沉浸体验?FinalBurn Neo(FBN…...

重磅发布!集装箱式SST直流移动智算中心
NEWS3月28日,台达、汉腾科技与龙芯中科联合宣布重磅发布集装箱式 SST(固态变压器)直流移动智算中心,发布活动于台达吴江制造基地举行。这款全新方案以台达 SST 固态变压器为核心能源支撑,深度集成CPU、AI 加速卡与服务…...

工业机器人嵌入式系统建模与自动化工具项目三基于RAPID指令的故障排查与项目实施
目录 一、 项目背景与研发目标 1.1 项目研发背景 1.2 项目核心目标 二、 项目全周期进展 2.1 需求分析与环境搭建阶段(完成度100%) 2.2 核心模块编码开发阶段(完成度100%) 2.3 功能调试阶段(核心故障爆发…...

零基础新手指南:借助快马AI无需代码构建你的第一篇论文官网
作为一个完全没有编程基础的研究生,我曾经为了搭建个人论文展示网站头疼不已。直到发现了InsCode(快马)平台,整个过程变得异常简单。下面分享我的完整实践过程,希望能帮助到同样需要展示学术成果的朋友们。 明确网站需求结构 在开始前&#x…...

Arduino嵌入式SD卡逐行读取库ReadLines详解
1. 项目概述ReadLines 是一个专为 Arduino 平台设计的轻量级文件行读取库,核心目标是解决嵌入式系统中对 SD 卡文本文件进行逐行解析这一高频但易出错的操作需求。在资源受限的 MCU 环境下(如 ESP8266、STM32F103C8T6、ATmega328P)࿰…...

三菱PLC与组态王四层电梯控制系统:详细图纸与IO分配解释
三菱PLC和组态王4层电梯四层电梯控制系统 我们主要的后发送的产品有,带解释的梯形图接线图原理图图纸,io分配,组态画面实验室四层电梯模型卡成狗的时候,真的恨自己当初梯形图只会写互锁单按钮那种幼儿园题。后来拆前辈的旧板子加…...

intv_ai_mk11镜像部署教程:3条命令完成服务启动、状态检查、日志监控
intv_ai_mk11镜像部署教程:3条命令完成服务启动、状态检查、日志监控 1. 快速了解intv_ai_mk11 intv_ai_mk11是一款基于7B参数Llama架构的AI对话机器人,它能帮助你完成各种任务: 回答各类问题(技术、生活、知识等)辅…...