梯度提升树GBDT系列算法

Boosting方法的基本元素与基本流程💫

在Boosting集成算法当中,我们逐一建立多个弱评估器(基本是决策树),并且下一个弱评估器的建立方式依赖于上一个弱评估器的评估结果,最终综合多个弱评估器的结果进行输出。
这个过程相当于有意地加重“难以被分类正确的样本”的权重,同时降低“容易被分类正确的样本”的权重,而将后续要建立的弱评估器的注意力引导到难以被分类正确的样本上。
不同的Boosting算法之间的核心区别就在于上一个弱评估器的结果具体如何影响下一个弱评估器的建立过程。此外,Boosting算法在结果输出方面表现得十分多样。早期的Boosting算法的输出一般是最后一个弱评估器的输出,当代Boosting算法的输出都会考虑整个集成模型中全部的弱评估器。一般来说,每个Boosting算法会其以独特的规则自定义集成输出的具体形式。
💥由此,我们可以确立任意boosting算法的三大基本元素以及boosting算法自适应建模的基本流程:
- 损失函数L(x,y) :用以衡量模型预测结果与真实结果的差异
- 弱评估器f(x) :(一般为)决策树,不同的boosting算法使用不同的建树过程
- 综合集成结果H(x):即集成算法具体如何输出集成结果
几乎所有boosting算法的原理都围绕这三大元素构建。在此三大要素基础上,所有boosting算法都遵循以下流程进行建模:

💢正如之前所言,Boosting算法之间的不同之处就在于使用不同的方式来影响后续评估器的构建。无论boosting算法表现出复杂或简单的流程,其核心思想一定是围绕上面这个流程不变的。
梯度提升树GBDT的基本思想

梯度提升树(Gradient Boosting Decision Tree,GBDT)是提升法中的代表性算法,它即是当代强力的XGBoost、LGBM等算法的基石,也是工业界应用最多、在实际场景中表现最稳定的机器学习算法之一。在最初被提出来时,GBDT被写作梯度提升机器(Gradient Boosting Machine,GBM),它融合了Bagging与Boosting的思想、扬长避短,可以接受各类弱评估器作为输入,在后来弱评估器基本被定义为决策树后,才慢慢改名叫做梯度提升树。
作为一个Boosting算法,GBDT中自然也包含Boosting三要素,并且也遵循boosting算法的基本流程进行建模,不过需要注意的是,GBDT在整体建树过程中有几个关键点:
- 弱评估器💯
- GBDT的弱评估器输出类型不再与整体集成算法输出类型一致。对于基础的Bagging和Boosting算法来说,当集成算法执行的是回归任务时,弱评估器也是回归器,当集成算法执行分类任务时,弱评估器也是分类器。但对于GBDT而言,无论GBDT整体在执行回归/分类/排序任务,弱评估器一定是回归器。GBDT通过sigmoid或softmax函数输出具体的分类结果,但实际弱评估器一定是回归器。
- 损失函数💯
-
在GBDT算法中,可以选择的损失函数非常多(‘deviance’, ‘exponential’),是因为这个算法从数学原理上做了改进——损失函数的范围不在局限于固定或者单一的某个损失函数,而是推广到了任意可微的函数。
-
GBDT分类器损失函数:‘deviance’, ‘exponential’
GBDT回归器损失函数:‘squared_error’, ‘absolute_error’, ‘huber’, ‘quantile’ - 拟合残差💯
GBDT依然自适应调整弱评估器的构建,但不再通过调整数据分布来间接影响后续弱评估器,而是通过修改后续弱评估器的拟合目标来直接影响后续弱评估器的结构。
具体地来说,在GBDT当中,我们不修改样本权重,但每次用于建立弱评估器的是样本以及当下集成输出与真实标签的差异()。这个差异在数学上被称之为残差(Residual),因此GBDT不修改样本权重,而是通过拟合残差来影响后续弱评估器结构。
GBDT加入了随机森林中随机抽样的思想,在每次建树之前,允许对样本和特征进行抽样来增大弱评估器之间的独立性(也因此可以有袋外数据集)。虽然Boosting算法不会大规模地依赖于类似于Bagging的方式来降低方差,但由于Boosting算法的输出结果是弱评估器结果的加权求和,因此Boosting原则上也可以获得由“平均”带来的小方差红利。当弱评估器表现不太稳定时,采用与随机森林相似的方式可以进一步增加Boosting算法的稳定性
梯度提升树GBDT的快速实现

sklearn当中集成了GBDT分类与GBDT回归,我们使用如下两个类来调用它们:
- class
sklearn.ensemble.GradientBoostingClassifier - class
sklearn.ensemble.GradientBoostingRegressor -
GBDT算法的超参数看起来很多,但是仔细观察的话,你会发现GBDT回归器与GBDT分类器的超参数高度一致。并且所有超参数都给出了默认值,需要人为输入的参数为0。所以,就算是不了解参数的含义,我们依然可以直接使用sklearn库来调用GBDT算法。
使用GBDT完成分类任务
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfrom sklearn.datasets import load_wine
from sklearn.ensemble import GradientBoostingClassifier as GBC
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_scoreX,y = load_wine(return_X_y=True,as_frame=True)# 切分训练集和测试集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=0)# 使用GBDT完成对红酒数据集的预测
clf = GBC() #实例化GBDT分类器,并使用默认参数
clf = clf.fit(Xtrain,Ytrain)train_score = clf.score(Xtrain,Ytrain)
test_score = clf.score(Xtest,Ytest)
print(f"GBDT在训练集上的预测准确率为{train_score}")
print(f"GBDT在测试集上的预测准确率为{test_score}")- GBDT在训练集上的预测准确率为1.0
- GBDT在测试集上的预测准确率为0.9629629629629629
梯度提升分类与其他算法的对比
dtc = DTC(random_state=0) #实例化单棵决策树
dtc = dtc.fit(Xtrain,Ytrain)
score_dtc = dtc.score(Xtest,Ytest)rfc = RFC(random_state=0) #实例化随机森林
rfc = rfc.fit(Xtrain,Ytrain)
score_rfc = rfc.score(Xtest,Ytest)gbc = GBC(random_state=0) #实例化GBDT
gbc = gbc.fit(Xtrain,Ytrain)
score_gbc = gbc.score(Xtest,Ytest)
# 默认使用准确度(accuracy)作为评分方式,即预测正确的样本数占总样本数的比例print("决策树:{}".format(score_dtc))
print("随机森林:{}".format(score_rfc))
print("GBDT:{}".format(score_gbc))- 决策树:0.9444444444444444
- 随机森林:0.9814814814814815
- GBDT:0.9629629629629629
💥画出决策树、随机森林和GBDT在十组五折交叉验证下的效果对比
score_dtc = []
score_rfc = []
score_gbc = []for i in range(10):dtc = DTC()cv1 = cross_val_score(dtc,X,y,cv=5)score_dtc.append(cv1.mean())rfc = RFC()cv2 = cross_val_score(rfc,X,y,cv=5)score_rfc.append(cv2.mean())gbc = GBC()cv3 = cross_val_score(gbc,X,y,cv=5)score_gbc.append(cv3.mean())plt.plot(range(1,11),score_dtc,label = "DecisionTree")
plt.plot(range(1,11),score_rfc,label = "RandomForest")
plt.plot(range(1,11),score_gbc,label = "GBDT")
plt.legend(bbox_to_anchor=(1.4,1))
plt.show()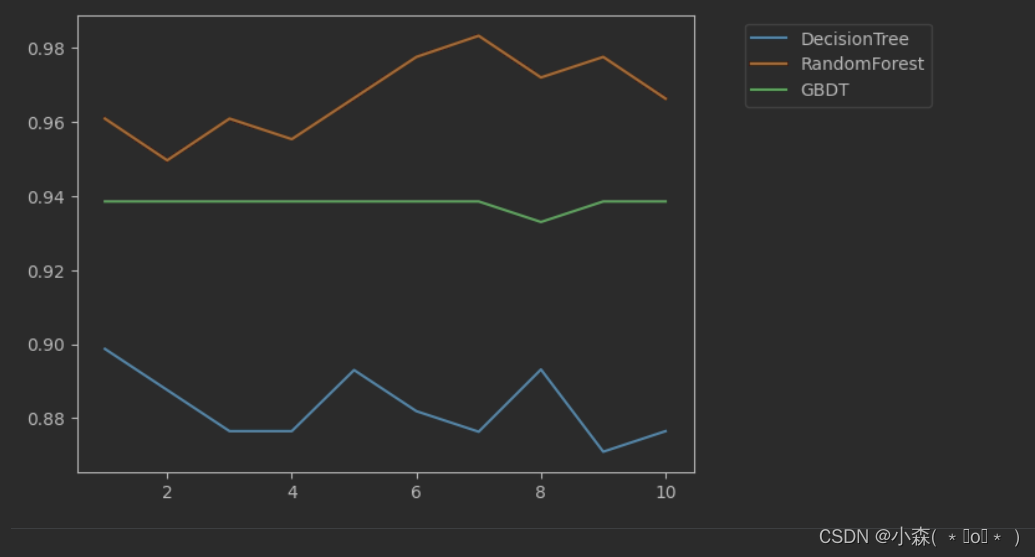
使用GBDT完成回归任务

X,y = fetch_california_housing(return_X_y=True,as_frame=True)Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=0)# 使用GBDT完成对加利福尼亚房屋数据集的预测gbr = GBR(random_state=0) #实例化GBDT
gbr = gbr.fit(Xtrain,Ytrain)
r2_gbdt = gbr.score(Xtest,Ytest) # 回归器默认评估指标为R2
r2_gbdt
# 0.7826346388949185# 计算GBDT回归器的评估指标:均方误差MSE
from sklearn.metrics import mean_squared_error
pred = gbr.predict(Xtest)
MSE = mean_squared_error(Ytest,pred)
MSE# 0.28979949770874125梯度提升回归与其他算法的对比
import time
modelname = ["DecisionTree","RandomForest","GBDT","RF-D"]
models = [DTR(random_state=0),RFR(random_state=0),GBR(random_state=0),RFR(random_state=0,max_depth=3)]for name,model in zip(modelname,models):start = time.time()result = cross_val_score(model,X,y,cv=5,scoring="neg_mean_squared_error").mean()end = time.time()-startprint(name)print("\t MSE:{:.3f}".format(abs(result)))print("\t time:{:.2f}s".format(end))print("\n")结果:
DecisionTreeMSE:0.818time:0.66sRandomForestMSE:0.425time:70.69sGBDTMSE:0.412time:16.84sRF-DMSE:0.639time:11.49s 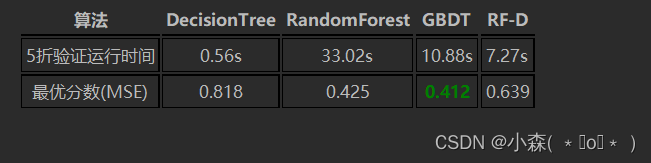
对比决策树和随机森林来说,GBDT默认参数状态下已经能够达到很好的效果。
梯度提升树GBDT的重要参数和属性

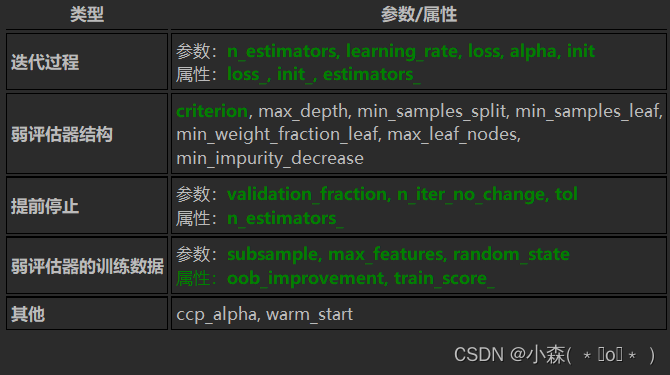
由于GBDT超参数数量较多,因此我们可以将GBDT的参数分为以下5大类别,其他属性我们下次再进行分析验证💨
相关文章:
梯度提升树GBDT系列算法
Boosting方法的基本元素与基本流程💫 在Boosting集成算法当中,我们逐一建立多个弱评估器(基本是决策树),并且下一个弱评估器的建立方式依赖于上一个弱评估器的评估结果,最终综合多个弱评估器的结果进行输出…...

探索智慧农业系统架构的设计与应用
随着科技的不断进步和农业现代化的推进,智慧农业正逐渐成为农业发展的重要趋势。智慧农业系统架构的设计与应用,将农业生产与信息技术相结合,为农业生产提供了新的思路和解决方案。本文将深入探讨智慧农业系统架构的设计与应用,从…...

【C语言】一篇文章带你深度理解函数
目录 1. 函数的概念 2. 库函数 2.1 标准库和头文件 2.2 库函数的使用方法 2.2.1 举例 sqrt 2.2.2 库函数文档的一般格式 3. 自定义函数 3.1 函数的语法形式 3.2 函数的举例 4. 形参和实参 4.1 实参 4.2 形参 4.3 实参和形参的关系 5. …...

荣耀手机删除系统APP
1、打开开发者模式 设置–系统–关于手机–快速多次点击手机的版本号,即可进入开发者模式。 然后进入开发人员选项,开启USB调试,如下图。 2、数据线连接电脑,检查设备连接情况 按键盘winR键,在弹窗中输入cmd&#…...

vue+elementui+springboot图片上传
1、前端代码 <template><div><el-uploadclass"avatar-uploader"action"http://localhost:8081/ch06/demo/uploadAvatar":show-file-list"false":on-success"handleAvatarSuccess":before-upload"beforeAvatarUpl…...

路由器怎么设置局域网?
局域网(Local Area Network,LAN)是指在一个相对较小的地理范围内,如家庭、办公室或学校等,通过路由器等设备连接起来的计算机网络。设置局域网可以方便地实现内部资源共享和信息交流。本文将介绍如何设置局域网以及一个…...

Linux2(文件类型分类 基本命令2 重定向)
目录 一、文件类型分类 二、基本命令2 1. find 帮助查询 2. stat 查看文件的信息 3. wc 统计文本 4. 查看文本内容 4.1 cat 4.2 more 4.3 less 4.4 head 4.5 tail 5. cal 显示日历 6. date 显示时间 7. du 文件大小 8. ln 链接 软链接 硬链接 区别 9. histo…...
c->c++(一):部分KeyWord
本文主要探讨c相关关键字的使用。 char char默认是unsigned/signed取决平台,wchar_t宽字符:用于Unicode编码(超过一个字节),用wcin和wcout输入输出,字符串为wstring char8_t(20),char16_t(11起),char32_t(11):指定占用字节数且是无符号,字符串类u8string,u16s…...

【iOS】YYModel源码阅读笔记
文章目录 前言一、JSON转换库对比二、YYModel性能优化三、YYModel的使用四、架构分析YYClassInfo 剖析 五、流程剖析转换前准备工作 – 将JSON统一成NSDictionary将NSDictionary 转换为Model对象提取Model信息使用NSDictionary的数据填充Model 总结 前言 先前写了JSONModel的源…...

C++Qt做一个鼠标在按钮上悬浮3s显示一个悬浮窗口
当你想要在 Qt 中创建一个自定义按钮并添加悬浮窗口的功能时,你可以通过继承 QPushButton 类来实现。下面是一个示例代码,演示了如何创建一个自定义按钮类 HoverButton,并在鼠标悬浮在按钮上 3 秒后显示一个悬浮窗口,窗口包含图片…...
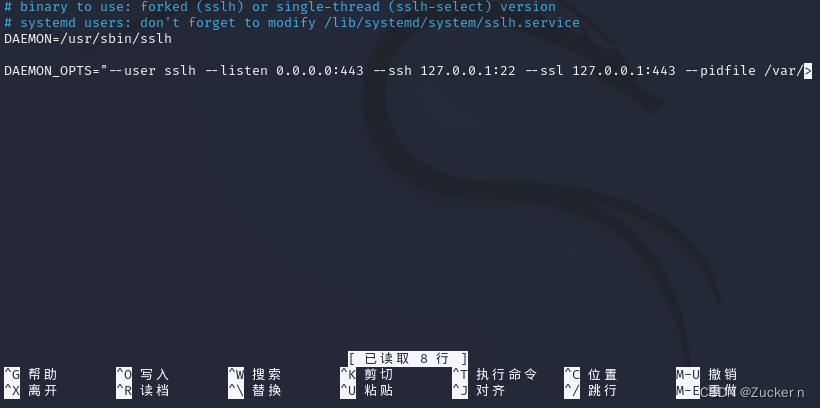
sslh一键在一个端口上运行多个服务(KALI工具系列二十三)
目录 1、KALI LINUX 简介 2、sslh工具简介 3、信息收集 3.1 目标主机IP(win) 3.2 KALI的IP 4、操作示例 4.1 监听特定端口 4.2 配置SSH 4.3 配置apache 4.4 配置sshl 4.5 验证配置 5、总结 1、KALI LINUX 简介 Kali Linux 是一个功能强大、…...

Vue27-内置指令04:v-once指令
一、需求 二、v-once指令 获取初始值: 三、小结...
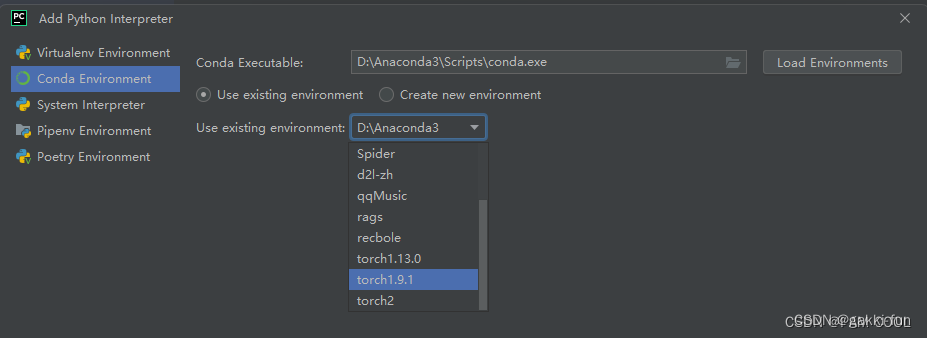
Pytorch环境配置的方法
Pytorch虚拟环境配置全流程 以安装pytorch1.9.1为例 1. 创建虚拟环境 安装Anaconda3,打开 PowerShell 创建虚拟环境并进入: conda create -n torch1.9.1 python3.8 conda activate torch1.9.1 conda create -n torch1.9.1 python3.8 conda activate to…...

数字化制造案例分享以及数字化制造能力评估(34页PPT)
资料介绍: 通过全面的数字化企业平台和智能制造技术的应用,制造型企业不仅提升了自身的竞争力,也为整个制造业的数字化转型提供了借鉴。同时,数字化制造能力的评估是企业实现数字化转型的关键环节,需要从技术变革、组…...

搜维尔科技:特斯拉称工厂内有两台人形机器人开始自主工作
搜维尔科技消息,据外电报道,特斯拉声称,其目前拥有两台 Optimus 人形机器人在工厂内自主工作,这尚属首次。 如果目前这场薪酬方案混乱有什么好处的话,那就是特斯拉几乎看起来又有了一个公关部门。 当然,其…...
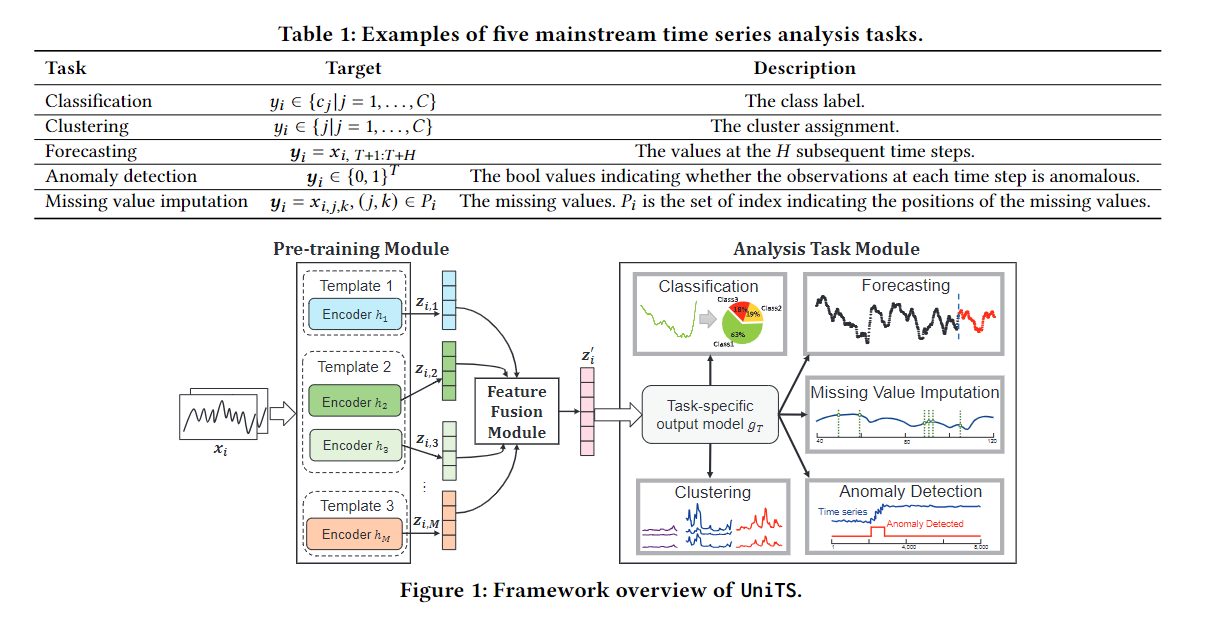
SIGMOD 2024 | 时空数据(Spatial-Temporal)和时间序列(Time Series)论文总结
SIGMOD2024于6月9号-6月14号正在智利圣地亚戈举行(Santiago Chile) 本文总结了SIGMOD 2024有关时间序列(time series),包括时序数据库,查询优化等内容。以及时空数据(spatial-temporal data)的…...

学习分享-分布式 NoSQL 数据库管理系统Cassandra以及它和redis的区别
前言 最近在学习的过程中遇到如何应对海量幂等 Key 所消耗的内存的问题,在网上查找资料了解到Cassandra或许是解决方式之一,所以查找了Cassandra的相关资料及其Cassandra和redis的区别。 什么是Cassandra Cassandra 是一个开源的分布式 NoSQL 数据库管…...
)
Android 汉字转拼音(两行就够了)
在Android中,我们可以使用Android自带的Transliterator类来实现汉字转拼音的功能。下面是使用Transliterator类的示例代码: 在你的Activity或者工具类中,使用以下代码来实现汉字转拼音的功能: import android.support.v7.app.Ap…...

JVM
栈 定义 每个线程运行时所需要的内存, 称为虚拟机栈每个栈由多个栈帧(包含参数, 局部变量, 放回值)组成, 对应着每次方法调用时所占用的内存每个线程只能有一个活动栈帧, 对应着当前正在执行的那个方法 堆 定义: 通过new关键字, 创建对象都会使用堆内存 特点:它是线程共享…...

MySQL锁机制和事务管理:如何处理并发和隔离性
引言 在数据库系统中,多个用户可能同时访问和修改数据,这就是并发操作。并发操作的主要优势在于,它显著提高了资源的利用率和事务的吞吐量。然而,如果不适当的管理并发操作,就会引发一些问题。以下几种并发操作中常见的问题: 丢失修改:这是某一事务的更新被另一事务的…...

别再瞎调了!FOC电机控制中,采样电阻选型和PCB布局的5个实战避坑点
FOC电机控制实战指南:采样电阻选型与PCB布局的5个关键避坑点 在无刷电机控制领域,FOC(磁场定向控制)算法凭借其优异的动态性能和效率表现,已成为工业驱动、消费电子和机器人关节的主流方案。然而,许多工程师…...

StructBERT文本相似度模型Java开发实战:SpringBoot集成与API调用
StructBERT文本相似度模型Java开发实战:SpringBoot集成与API调用 你是不是也遇到过这样的场景?用户搜索“苹果手机”,你希望系统不仅能返回iPhone,还能识别出“苹果公司手机”、“Apple iPhone”这些同义查询。或者,在…...

ARP 协议超详细讲解
前言网络设备有数据要发送给另一台网络设备时,必须要知道对方的网络层地址(即IP地址)。IP地址由网络层来提供,但是仅有IP地址是不够的,IP数据报文必须封装成帧才能通过数据链路进行发送。数据帧必须要包含目的MAC地址&…...

C++的std--ranges容错系统
C的std::ranges容错系统:现代编程的稳健之道 在C20标准中,std::ranges库的引入彻底改变了算法与容器的交互方式,其容错机制为开发者提供了更安全、更灵活的编程体验。传统迭代器容易因越界或无效操作导致未定义行为,而std::range…...

Keyv自定义序列化教程:超越JSON,支持更多数据类型
Keyv自定义序列化教程:超越JSON,支持更多数据类型 【免费下载链接】keyv jaredwray/keyv: 这是一个分布式键值存储库,用于在多个节点上存储数据。适合用于需要分布式存储和访问的场景。特点:易于使用,支持多种数据存储…...

Nunchaku FLUX.1 CustomV3部署案例:AI绘画培训课程实训环境标准化镜像交付方案
Nunchaku FLUX.1 CustomV3部署案例:AI绘画培训课程实训环境标准化镜像交付方案 1. 引言:当AI绘画遇上教育培训的规模化挑战 如果你正在运营一个AI绘画培训班,或者负责一个数字艺术学院的课程设计,你肯定遇到过这样的难题&#x…...

TextInput Effects部署与测试:确保跨平台兼容性的完整流程
TextInput Effects部署与测试:确保跨平台兼容性的完整流程 【免费下载链接】react-native-textinput-effects Text inputs with custom label and icon animations for iOS and android. Built with react native and inspired by Codrops. 项目地址: https://git…...

Notepad--:国产跨平台文本编辑器的终极指南与快速上手
Notepad--:国产跨平台文本编辑器的终极指南与快速上手 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- Note…...

G-Helper解决华硕笔记本续航衰减的智能调控方案:延长50%使用时间
G-Helper解决华硕笔记本续航衰减的智能调控方案:延长50%使用时间 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF,…...

iOSDeviceSupport:解决设备调试兼容性问题的高效管理工具
iOSDeviceSupport:解决设备调试兼容性问题的高效管理工具 【免费下载链接】iOSDeviceSupport All versions of iOS Device Support 项目地址: https://gitcode.com/gh_mirrors/ios/iOSDeviceSupport 问题场景:当新系统遇见旧Xcode "连接失败…...