深度学习之---迁移学习
目录
一、什么是迁移学习
二、为什么需要迁移学习?
1. 大数据与少标注的矛盾:
2. 大数据与弱计算的矛盾:
3. 普适化模型与个性化需求的矛盾:
4. 特定应用(如冷启动)的需求。
三、迁移学习的基本问题有哪些?
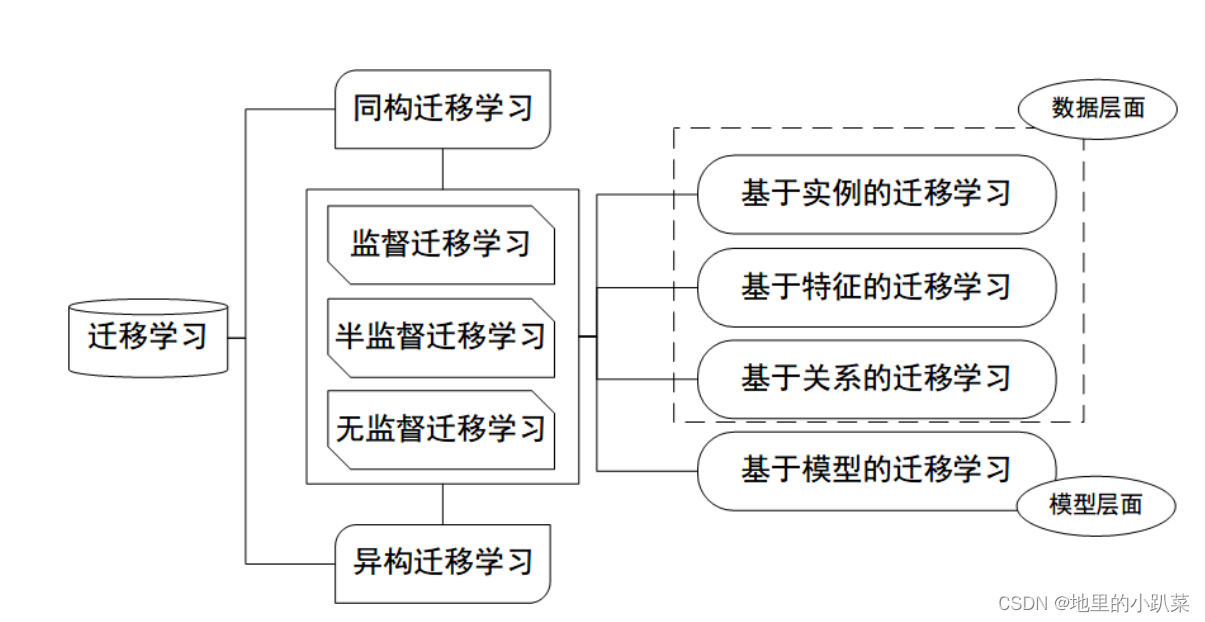
四、 迁移学习有哪些常用概念?
编辑 五、迁移学习与传统机器学习有什么区别?
六、迁移学习的核心及度量准则?
一、什么是迁移学习
迁移学习(Transfer Learning)是一种机器学习方法,就是把为任务 A 开发 的模型作为初始点,重新使用在为任务 B 开发模型的过程中。迁移学习是通过 从已学习的相关任务中转移知识来改进学习的新任务,虽然大多数机器学习算 法都是为了解决单个任务而设计的,但是促进迁移学习的算法的开发是机器学 习社区持续关注的话题。 迁移学习对人类来说很常见,例如,我们可能会发现 学习识别苹果可能有助于识别梨,或者学习弹奏电子琴可能有助于学习钢琴。
找到目标问题的相似性,迁移学习任务就是从相似性出发,将旧领域 (domain)学习过的模型应用在新领域上
二、为什么需要迁移学习?
1. 大数据与少标注的矛盾:
虽然有大量的数据,但往往都是没有标注的, 无法训练机器学习模型。人工进行数据标定太耗时。
2. 大数据与弱计算的矛盾:
普通人无法拥有庞大的数据量与计算资源。因 此需要借助于模型的迁移。
3. 普适化模型与个性化需求的矛盾:
即使是在同一个任务上,一个模型也 往往难以满足每个人的个性化需求,比如特定的隐私设置。这就需要在 不同人之间做模型的适配。
4. 特定应用(如冷启动)的需求。
三、迁移学习的基本问题有哪些?
基本问题主要有3个:
- How to transfer: 如何进行迁移学习?(设计迁移方法)
- What to transfer: 给定一个目标领域,如何找到相对应的源领域, 然后进行迁移?(源领域选择)
- When to transfer: 什么时候可以进行迁移,什么时候不可以?(避 免负迁移)
四、 迁移学习有哪些常用概念?
基本定义
域(Domain):数据特征和特征分布组成,是学习的主体
源域 (Source domain):已有知识的域
目标域 (Target domain):要进行学习的域
任务 (Task):由目标函数和学习结果组成,是学习的结果
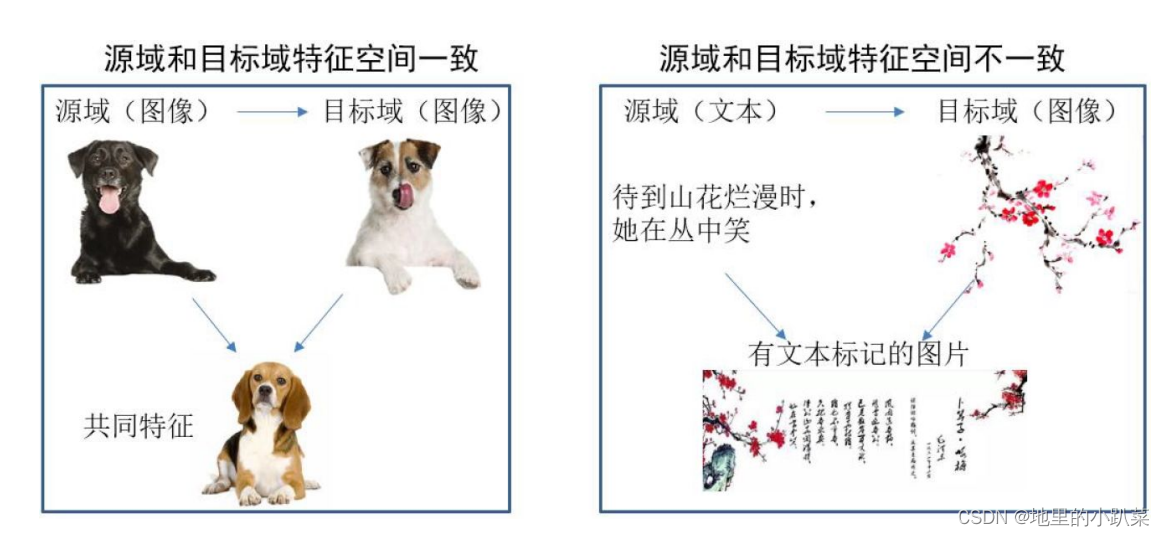
按特征空间分类

按迁移情景分类
归纳式迁移学习(Inductive TL):源域和目标域的学习任务 不同
直推式迁移学习(Transductive TL):源域和目标域不同,学 习任务相同
无监督迁移学习(Unsupervised TL):源域和目标域均没有 标签 按迁移方法分类
基于样本的迁移 (Instance based TL):通过权重重用源域和 目标域的样例进行迁移
基于样本的迁移学习方法 (Instance based Transfer Learning) 根据一定的权重生成规则,对数据样本进行重用, 来进行迁移学习。下图形象地表示了基于样本迁移方法的思想 源域中存在不同种类的动物,如狗、鸟、猫等,目标域只有狗 这一种类别。在迁移时,为了最大限度地和目标域相似,我们 可以人为地提高源域中属于狗这个类别的样本权重。

基于特征的迁移 (Feature based TL):将源域和目标域的特 征变换到相同空间
基于特征的迁移方法 (Feature based Transfer Learning) 是 指将通过特征变换的方式互相迁移,来减少源域和目标域之间的 差距;或者将源域和目标域的数据特征变换到统一特征空间中, 然后利用传统的机器学习方法进行分类识别。根据特征的同构 和异构性,又可以分为同构和异构迁移学习。下图很形象地表示 了两种基于特 征的迁移学习方法。
基于模型的迁移 (Parameter based TL):利用源域和目标域的参数共享 模型
基于模型的迁移方法 (Parameter/Model based Transfer Learning) 是指 从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移 方式要求的假设条件是: 源域中的数据与目标域中的数据可以共享一些模型的 参数。下图形象地表示了基于模型的迁移学习方法的基本思想。

基于关系的迁移 (Relation based TL):利用源域中的逻辑网络关系进行迁移
基于关系的迁移学习方法 (Relation Based Transfer Learning) 与上述三种 方法具有截然不同的思路。这种方法比较关注源域和目标域的样本之间的关 系。下图形象地表示了不 同领域之间相似的关系。

 五、迁移学习与传统机器学习有什么区别?
五、迁移学习与传统机器学习有什么区别?

六、迁移学习的核心及度量准则?
迁移学习的总体思路可以概括为:开发算法来最大限度地利用有标注的领 域的知识,来辅助目标领域的知识获取和学习。
迁移学习的核心是:找到源领域和目标领域之间的相似性,并加以合理利 用。这种相似性非常普遍。比如,不同人的身体构造是相似的;自行车和摩托 车的骑行方式是相似的;国际象棋和中国象棋是相似的;羽毛球和网球的打球 方式是相似的。这种相似性也可以理解为不变量。以不变应万变,才能立于不 败之地。
有了这种相似性后,下一步工作就是, 如何度量和利用这种相似性。度量 工作的目标有两点:一是很好地度量两个领域的相似性,不仅定性地告诉我们 它们是否相似,更定量地给出相似程度。二是以度量为准则,通过我们所要采 用的学习手段,增大两个领域之间的相似性,从而完成迁移学习。
一句话总结: 相似性是核心,度量准则是重要手段。
七、迁移学习三步走
1加载预训练模型(inceptionnet-v3)(主干网络,backbone),提取所 有图片数据集的特征(特征向量2048维度)。(调用别人训练好的模型,因为 他们的模型泛化能力强,不用自己创建训练模型)
2用特征向量训练自己的后端网络模型,(后端用自己创建dense后端模 型,保存dense后端6个模型)
3调用最后一个模型来显示测试集16张图片预测结果

第一步
import os.path
import numpy as np
# # import tensorflow.compat.v1 as tf
# import tensorflow._api.v2.compat.v1 as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
from tensorflow.python.platform import gfile
MODEL_FILE = 'model/tensorflow_inception_graph.pb'
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'
INPUT_IMAGE = 'data/agriculture'
OUTPUT_VEC = 'data/bottleneck'
def load_google_model(path):with gfile.FastGFile(path, "rb") as f:graph_def = tf.GraphDef()graph_def.ParseFromString(f.read())jpeg_data_tensor, bottleneck_tensor = \tf.import_graph_def(graph_def, return_elements=
[JPEG_DATA_TENSOR_NAME, BOTTLENECK_TENSOR_NAME])return jpeg_data_tensor, bottleneck_tensor
def get_random_cached_bottlenecks(sess, path,
jpeg_data_tensor, bottleneck_tensor):for _, class_name in enumerate(os.listdir(path)):sub_path = os.path.join(path, class_name)for img in os.listdir(sub_path):img_path=os.path.join(sub_path,img)image_data = gfile.FastGFile(img_path,
'rb').read()bottleneck_values = sess.run(bottleneck_tensor,
feed_dict={jpeg_data_tensor: image_data})第二步骤:bottleneck_values = np.squeeze(bottleneck_values)sub_dir_path = os.path.join(OUTPUT_VEC,
class_name)if not os.path.exists(sub_dir_path):os.makedirs(sub_dir_path)new_image_path=os.path.join(sub_dir_path,
img)+".txt"if not os.path.exists(new_image_path):bottleneck_string = ','.join(str(x) for x in
bottleneck_values)with open(new_image_path, 'w') as
bottleneck_file:bottleneck_file.write(bottleneck_string)else:break
if __name__ == '__main__':jpeg_data_tensor, bottleneck_tensor =
load_google_model(MODEL_FILE)with tf.Session() as sess:tf.global_variables_initializer().run()get_random_cached_bottlenecks(sess, INPUT_IMAGE,
jpeg_data_tensor, bottleneck_tensor)第二步
import os
import numpy as np
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
# import tensorflow._api.v2.compat.v1 as tf
from sklearn.model_selection import train_test_split
IN_DIR = 'data/bottleneck'
OUT_DIR = 'runs'
checkpoint_every = 100 #every 每,
def get_data(path): x_vecs=[]y_labels=[]for i, j in enumerate(os.listdir(path)): #enumerate代表枚
举,把元素一个个列举出来。sub_path = os.path.join(path, j)for vec in os.listdir(sub_path):vec_path = os.path.join(sub_path, vec)with open(vec_path, 'r') as f:vec_str = f.read()vec_values = [float(x) for x in
vec_str.split(',')]x_vecs.append(vec_values)y_labels.append(np.eye(5)[i])return np.array(x_vecs), np.array(y_labels)
image_data,labels=get_data(IN_DIR)
train_data,test_data,train_label,test_label=train_test_split(
image_data,labels,train_size=0.8,shuffle=True)
test_data,val_data,test_label,val_label=train_test_split(test
_data,test_label,train_size=0.5)
if __name__ == '__main__':#入口X = tf.placeholder(tf.float32, [None, 2048])Y = tf.placeholder(tf.float32, [None, 5])with tf.name_scope('final_training_ops'):logits = tf.layers.dense(X, 5)with tf.name_scope('loss'):cross_entropy_mean =
tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits
=logits, labels=Y))with tf.name_scope('Optimizer'):train_step =
tf.train.GradientDescentOptimizer(0.001).minimize(cross_entro
py_mean)with tf.name_scope('evaluation'): correct_prediction = tf.equal(tf.argmax(logits, 1),
tf.argmax(Y, 1))evaluation_step =
tf.reduce_mean(tf.cast(correct_prediction, tf.float32))with tf.Session() as sess:sess.run(tf.global_variables_initializer())# 保存检查点checkpoint_dir =
os.path.abspath(os.path.join(OUT_DIR, 'checkpoints'))checkpoint_prefix = os.path.join(checkpoint_dir,
'model')if not os.path.exists(checkpoint_dir):os.makedirs(checkpoint_dir)saver = tf.train.Saver(tf.global_variables(),
max_to_keep=6)for epoch in range(1001):batch_size = 64start = 0num_step = len(train_data) // batch_sizefor i in range(num_step):xb = train_data[start : start + batch_size]yb = train_label[start : start + batch_size]start = start + batch_size_ = sess.run([train_step], feed_dict={X: xb,
Y: yb})if epoch % 100 == 0:validation_accuracy =
sess.run(evaluation_step, feed_dict={X: val_data, Y:
val_label})print("[epoch {}]验证集准确率
{:.3f}%".format(epoch, validation_accuracy * 100))path = saver.save(sess, checkpoint_prefix,
global_step=epoch)print('Saved model checkpoint to
{}\n'.format(path))test_accuracy = sess.run(evaluation_step, feed_dict=
{X: test_data, Y: test_label})第三步骤:print("测试集准确率{:.3f}%".format(test_accuracy *
100))第三步
import numpy as np
import cv2
import os
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
from tensorflow.python.platform import gfile
import matplotlib.pyplot as plt
MODEL_FILE = 'model/tensorflow_inception_graph.pb'
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'
CHECKPOINT_DIR = 'runs/checkpoints'
test_dir = 'data/test/agriculture'
def load_google_model(path):with gfile.FastGFile(path, "rb") as f:graph_def = tf.GraphDef()graph_def.ParseFromString(f.read())jpeg_data_tensor, bottleneck_tensor = \tf.import_graph_def(graph_def, return_elements=
[JPEG_DATA_TENSOR_NAME, BOTTLENECK_TENSOR_NAME])return jpeg_data_tensor, bottleneck_tensor
def create_test_featrue(sess, test_dir, jpeg_data_tensor,
bottleneck_tensor):test_data, test_feature, test_labels = [], [], []for i in os.listdir(test_dir):img = cv2.imread(os.path.join(test_dir, i))img = cv2.resize(img, (256, 256))img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)test_data.append(img)img_data = gfile.FastGFile(os.path.join(test_dir, i),
"rb").read() feature = sess.run(bottleneck_tensor, feed_dict=
{jpeg_data_tensor: img_data})test_feature.append(feature)test_labels.append(i.split("_")[0])return test_data, np.reshape(test_feature, (-1, 2048)),
np.array(test_labels)
def show_img(test_data, pre_labels, test_labels):_, axs = plt.subplots(4, 4)for i, axi in enumerate(axs.flat):axi.imshow(test_data[i])print(pre_labels[i], test_labels[i])axi.set_xlabel(xlabel=pre_labels[i], color="black" if
pre_labels[i] == test_labels[i] else "red")axi.set(xticks=[], yticks=[])plt.savefig(os.path.join("data/test/", 'agriculture' +
".jpg"))plt.show()
if __name__ == '__main__':jpeg_data_tensor, bottleneck_tensor =
load_google_model(MODEL_FILE)class_names = os.listdir("data/agriculture")num_class= len(class_names)x_transfer = tf.placeholder(tf.float32, [None, 2048])y_transfer = tf.placeholder(tf.int64, [None, num_class])
# [None,5]logits = tf.layers.dense(x_transfer, num_class)saver = tf.train.Saver()with tf.Session() as sess:sess.run(tf.global_variables_initializer())print(CHECKPOINT_DIR)last_point =
tf.train.latest_checkpoint(CHECKPOINT_DIR)print(last_point)saver.restore(sess, last_point)三个步骤代码组合起来实现迁移学习:test_data, test_feature, test_labels = \create_test_featrue(sess, test_dir,
jpeg_data_tensor, bottleneck_tensor)pred = sess.run(tf.argmax(logits, 1), {x_transfer:
test_feature})show_img(test_data, [class_names[i] for i in pred],
test_labels)
相关文章:
深度学习之---迁移学习
目录 一、什么是迁移学习 二、为什么需要迁移学习? 1. 大数据与少标注的矛盾: 2. 大数据与弱计算的矛盾: 3. 普适化模型与个性化需求的矛盾: 4. 特定应用(如冷启动)的需求。 三、迁移学习的基本问题有…...

百度网盘限速解决办法
文章目录 开启P2P下载30秒会员下载体验一次性高速下载服务导入“百度网盘青春版”后下载注册新号参与活动 获取下载直链后使用磁力链接下载不是办法的办法无效、已失效方法免限速客户端、老版本客户端、永久会员下载体验试用客户端,或类似脚本、工具获取下载直链后多…...
银河麒麟系统项目部署
使用服务器信息 软件:VMware Workstation Pro 虚拟机:ubtun 内存:20G 虚拟机连接工具: MobaXterm Redis连接工具: RedisDesktopManager 镜像:F:\Kylin-Server-10-8.2-Release-Build09-20211104-X86_64…...

Stable Diffusion【应用篇】【艺术写真】:粘土风之后陶瓷风登场,来看看如何整合AI艺术写真吧
在国外的APP Remini引爆了粘土滤镜后,接着Remini又推出了瓷娃娃滤镜。相当粘土滤镜,个人更喜欢瓷娃娃滤镜,因为陶瓷工艺更符合东方艺术审美。 下面我们就来看看陶瓷特效在AI写真方面的应用。话不多说,我们直接开整。 关于粘土整…...

手机IP地址距离多远会变:解析移动设备的网络定位奥秘
在移动互联网时代,手机IP地址扮演着至关重要的角色,它不仅是我们访问网络的基础,还常常与网络定位、地理位置服务等相关联。那么,手机IP地址在距离多远时会发生变化呢?手机IP地址距离多远会变?下面跟着虎观…...

ChatGPT中文镜像网站分享
ChatGPT 是什么? ChatGPT 是 OpenAI 开发的一款基于生成预训练变换器(GPT)架构的大型语言模型。主要通过机器学习生成文本,能够执行包括问答、文章撰写、翻译等多种文本生成任务。截至 2023 年初,ChatGPT 的月活跃用户…...

碳化硅陶瓷膜良好的性能
碳化硅陶瓷膜是一种高性能的陶瓷材料,以其独特的物理和化学特性,在众多领域展现出了广泛的应用前景。以下是对碳化硅陶瓷膜的详细介绍: 一、基本特性 高强度与高温稳定性:碳化硅陶瓷膜是一种非晶态陶瓷材料,具有极高的…...
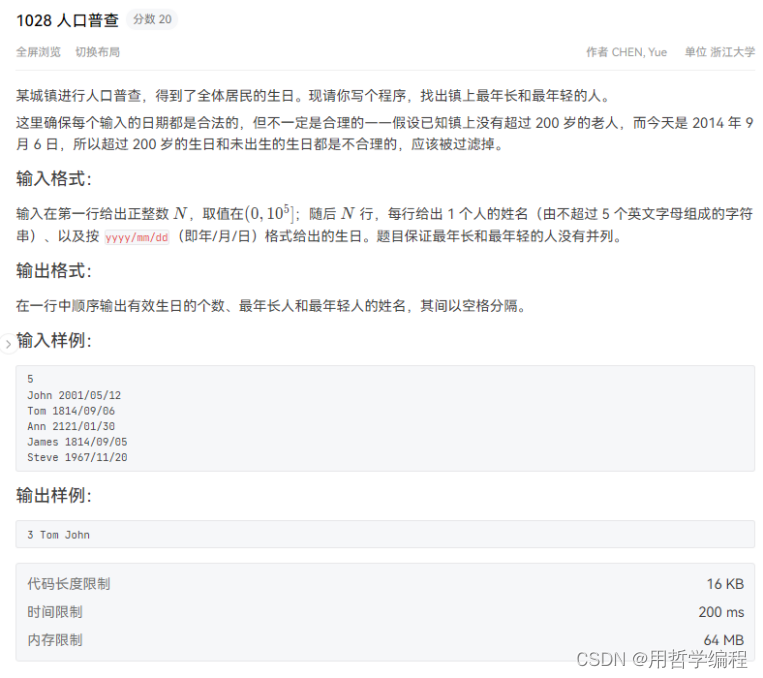
每日一题——Python实现PAT乙级1028 人口普查 Keyboard(举一反三+思想解读+逐步优化)六千字好文
一个认为一切根源都是“自己不够强”的INTJ 个人主页:用哲学编程-CSDN博客专栏:每日一题——举一反三Python编程学习Python内置函数 Python-3.12.0文档解读 目录 题目链接编辑我的写法 专业点评 时间复杂度分析 空间复杂度分析 总结 我要更强…...
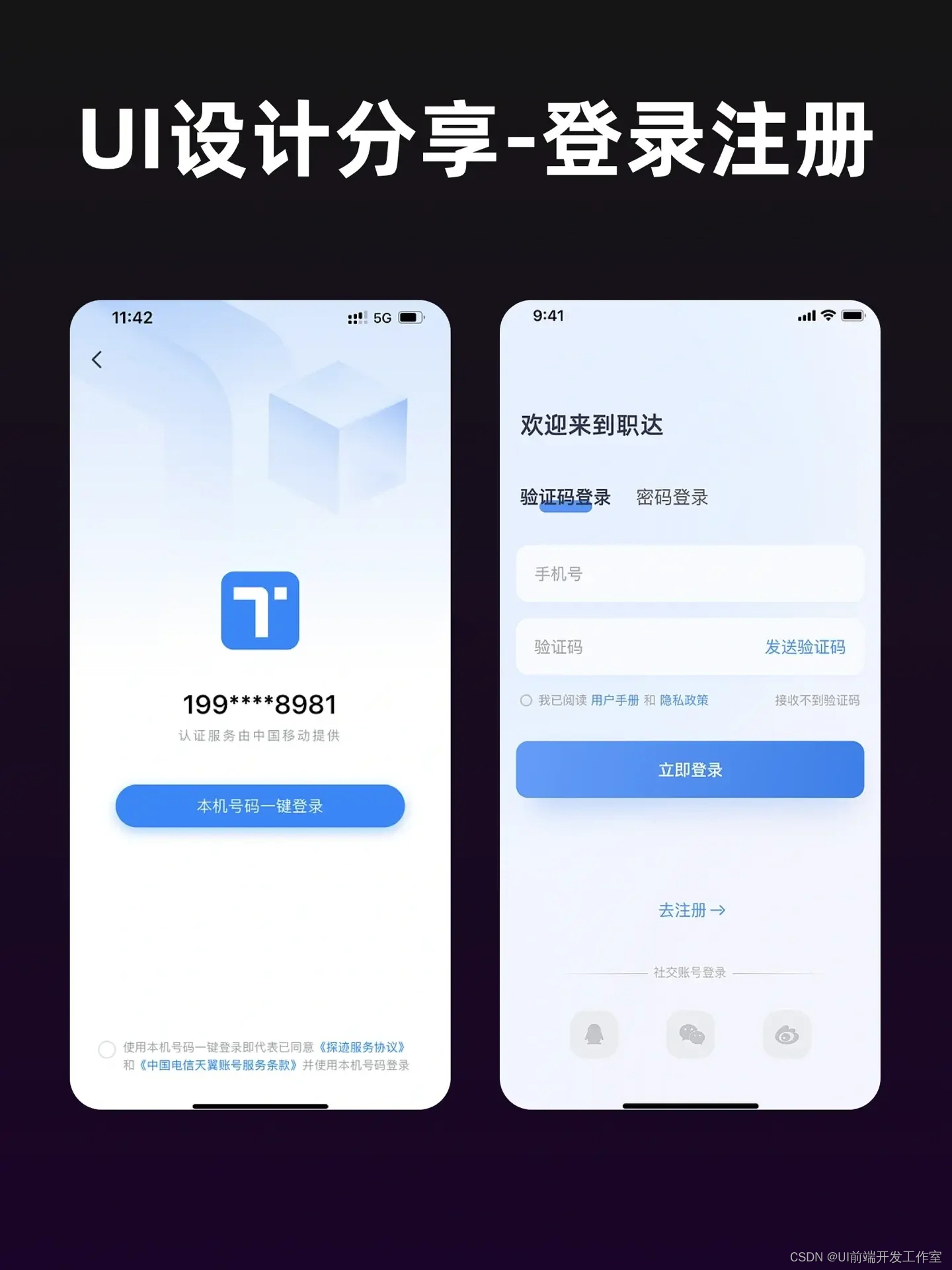
小程序 UI 风格,构建美妙视觉
小程序 UI 风格,构建美妙视觉...

使用Python在VMware虚拟机中模拟Ubuntu服务器搭建网站
在此之前可以先使用VS Code连接到虚拟机:Visual Studio Code连接VMware虚拟机-CSDN博客 安装Web服务器Apache sudo apt-get install apache2 在个别情况下需要对Apache服务器的配置文件进行调整: 打开etc路径下的apache2文件夹,根据端口…...

腾讯测试开发<ieg 实验室>
3.26 40min 自我介绍实习经历有无遇到什么难点,你是如何克服的在这个项目中你大概做了多少个测试用例,这么多测试用例你平时用什么工具进行管理的,每一次跑全部还是每次只跑一部分现在假设给你一个新的项目,需要你这边去做测试&a…...

windows命令帮助大全
有关某个命令的详细信息,请键入 HELP 命令名 ASSOC 显示或修改文件扩展名关联。 ATTRIB 显示或更改文件属性。 BREAK 设置或清除扩展式 CTRLC 检查。 BCDEDIT 设置启动数据库中的属性以控制启动加载。 CACLS 显示或修改文件的访问控制列表(ACL)。 CALL 从另一个批处…...
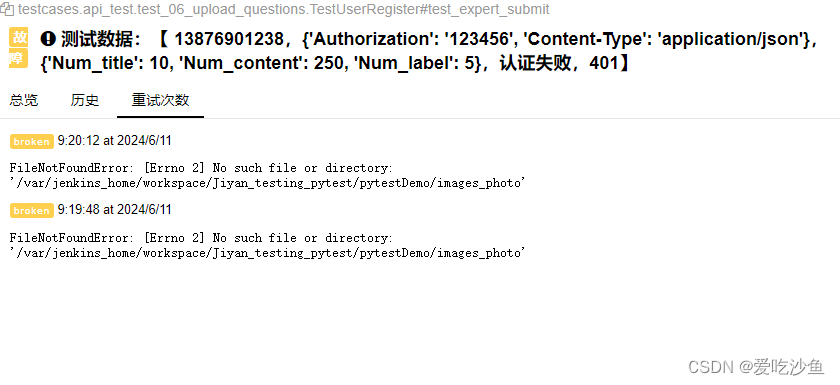
pytest中失败用例重跑
pip install pytest-rerunfailures 下载rerunfailures插件包 配置文件中加入命令 --reruns 次数 也可在命令行中pytest --rerun-failures2 可以在allure报告中看到重试效果...
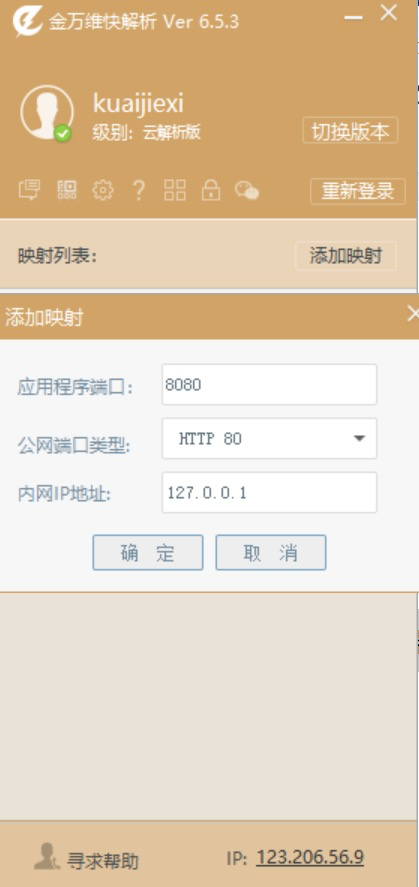
http穿透怎么做?
众所周知http协议的默认端口是80,由于国家工信部要求,域名必须备案才给开放80端口,而备案需要固定公网IP,这就使得开放http80端口的费用成本和时间成本变的很高。那么能不能利用内网穿透技术做http穿透呢?下面我就给大…...

前端技术回顾系列 11|TS 中一些实用概念
在微信中阅读,关注公众号:CodeFit。 创作不易,如果你觉得这篇文章对您有帮助,请不要忘了 点赞、分享 和 关注 我的公众号:CodeFit,为我的持续创作提供动力。 上文回顾:泛型在类和接口中的应用 上一篇文章我们回顾了 泛型 在 类 和 接口 中的应用。 通过使用泛型,我们…...

leetcode LRU 缓存
leetcode: LRU 缓存 LRU 全称为 Least Recently Used,最近最少使用,常常用于缓存机制,比如 cpu 的 cache 缓存,使用了 LRU 算法。LRU 用于缓存机制时,关键的是当缓存满的时候有新数据需要加载到缓存的,这个…...
)
LeetCode 2786.访问数组中的位置使分数最大:奇偶分开记录(逻辑还算清晰的题解)
【LetMeFly】2786.访问数组中的位置使分数最大:奇偶分开记录(逻辑还算清晰的题解) 力扣题目链接:https://leetcode.cn/problems/visit-array-positions-to-maximize-score/ 给你一个下标从 0 开始的整数数组 nums 和一个正整数 …...

嵌入式仪器模块:音频综测仪和自动化测试软件
• 24 位分辨率 • 192 KHz 采样率 • 支持多种模拟/数字音频信号的输入/输出 应用场景 • 音频信号分析:幅值、频率、占空比、THD、THDN 等指标 • 模拟音频测试:耳机、麦克风、扬声器测试,串扰测试 • 数字音频测试:平板电…...

计算商场折扣 、 判断体重指数 题目
题目 JAVA5 计算商场折扣分析:代码: JAVA6 判断体重指数分析:代码:大佬代码: JAVA5 计算商场折扣 描述 牛牛商场促销活动: 满100全额打9折; 满500全额打8折; 满2000全额打7折&…...

input输入框禁止输入小数点方法
使用blur事件: <el-input v-model"number" type"number" placeholder"请输入" blur"numberBlur" /> 第一种: 使用parseInt转为整数: this.number parseInt(this.number);第二种ÿ…...

小盲区、大智慧:大禹电子双探头传感器助力垃圾精细化管理
在智慧城市建设的浪潮下,环卫作业的数字化与精细化已成为提升城市管理效率的关键一环。针对客户提出的垃圾桶顶部安装、测量桶内垃圾高度的需求,特别是面对桶内积水、沙尘等复杂工况,以及对小盲区、高精度的严苛要求,大禹电子凭借…...

别再只当扫码枪用了!用Python+GM861S模块,DIY一个智能物料盘点小工具
用PythonGM861S模块打造智能物料盘点系统 在仓库管理和生产制造场景中,物料盘点是项耗时又容易出错的工作。传统扫码枪往往只作为简单数据采集工具,而结合Python编程能力,我们可以将GM861S这类高性能扫码模块升级为智能终端。这个项目将展示如…...

【基于Xilinx ZYNQ7000与PYNQ的嵌入式AI实践】从零构建实时人脸识别系统
1. 项目背景与核心价值 最近在折腾嵌入式AI项目时,发现Xilinx ZYNQ7000系列开发板真是个宝藏硬件。它独特的PS(处理器系统)PL(可编程逻辑)双架构,配合PYNQ框架的Python生态,让算法部署变得异常灵…...

从系统光标到个性化指针:动漫主题鼠标指针的完整实现指南
1. 项目概述:从“二次元”到“生产力”的鼠标指针革命如果你和我一样,每天有超过8小时的时间与电脑为伴,那么鼠标指针就是你最亲密的“数字伙伴”。它可能是一个单调的白色箭头,也可能是一个乏味的沙漏。但你想过吗?这…...

TypeScript代码质量扫描利器tscanner:超越tsc的类型安全检查实践
1. 项目概述:一个被低估的TypeScript代码质量扫描利器最近在重构一个遗留的TypeScript项目,代码库已经膨胀到几十万行,各种any满天飞,类型定义混乱不堪,手动审查根本无从下手。就在我头疼的时候,同事推荐了…...
:痛点剖析与破局利器 EasyExcel)
【架构实战】百万级Excel数据导入的“坑”与“填坑”指南(上):痛点剖析与破局利器 EasyExcel
前言大家好,这里是程序员阿亮!今天来给大家讲解一下在传统企业中报表和数据处理业务非常常见的工具-Excel在后端的使用和场景!引言:从一个看似简单的需求说起在日常的 B2B 业务、ERP 系统或者后台管理系统中,“Excel 导…...

郎朗乐境音乐会定档7月5日深圳:以破界之姿,开启全维感官盛宴
2026年7月5日,郎朗乐境音乐会将在深圳市宝安体育中心体育馆启幕,作为“深圳国际形象大使”的郎朗,将在这座以创新著称的国际化都市,,进一步探索艺术表达形式的多重可能,呈现一场融合音乐、文化与多维感官体…...

Figma中文汉化插件完整指南:3分钟让Figma界面说中文的终极方案
Figma中文汉化插件完整指南:3分钟让Figma界面说中文的终极方案 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?对于中文设计师来…...

Rust构建的轻量级文件搜索工具fltr:高性能文本检索新选择
1. 项目概述:一个轻量级、高性能的本地文件搜索工具在开发或日常文件管理工作中,我们常常面临一个看似简单却极其恼人的问题:如何在成千上万的文件中,快速、精准地找到包含特定关键词或符合特定模式的那一个?无论是定位…...

基于Dify平台快速构建AI对话机器人:从部署到生产级实践
1. 项目概述与核心价值最近在折腾AI应用落地的过程中,我反复被一个问题困扰:如何把一个强大的大语言模型(LLM)能力,快速、低成本地封装成一个能实际解决业务问题的对话机器人?自己从零开始搭框架、写API、处…...