MySQL 中 Varchar(50) 和 varchar(500) 区别是什么?
一. 问题描述
我们在设计表结构的时候,设计规范里面有一条如下规则:
-
对于可变长度的字段,在满足条件的前提下,尽可能使用较短的变长字段长度。
为什么这么规定?我在网上查了一下,主要基于两个方面
-
基于存储空间的考虑
-
基于性能的考虑
网上说Varchar(50)和varchar(500)存储空间上是一样的,真的是这样吗?
基于性能考虑,是因为过长的字段会影响到查询性能?
本文我将带着这两个问题探讨验证一下
二.验证存储空间区别
1.准备两张表
CREATE TABLE `category_info_varchar_50` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(50) NOT NULL COMMENT '分类名称',`is_show` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否展示:0 禁用,1启用',`sort` int(11) NOT NULL DEFAULT '0' COMMENT '序号',`deleted` tinyint(1) DEFAULT '0' COMMENT '是否删除',`create_time` datetime NOT NULL COMMENT '创建时间',`update_time` datetime NOT NULL COMMENT '更新时间',PRIMARY KEY (`id`) USING BTREE,KEY `idx_name` (`name`) USING BTREE COMMENT '名称索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='分类';CREATE TABLE `category_info_varchar_500` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(500) NOT NULL COMMENT '分类名称',`is_show` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否展示:0 禁用,1启用',`sort` int(11) NOT NULL DEFAULT '0' COMMENT '序号',`deleted` tinyint(1) DEFAULT '0' COMMENT '是否删除',`create_time` datetime NOT NULL COMMENT '创建时间',`update_time` datetime NOT NULL COMMENT '更新时间',PRIMARY KEY (`id`) USING BTREE,KEY `idx_name` (`name`) USING BTREE COMMENT '名称索引'
) ENGINE=InnoDB AUTO_INCREMENT=288135 DEFAULT CHARSET=utf8mb4 COMMENT='分类';
2.准备数据
给每张表插入相同的数据,为了凸显不同,插入100万条数据
DELIMITER $$
CREATE PROCEDURE batchInsertData(IN total INT)
BEGINDECLARE start_idx INT DEFAULT 1;DECLARE end_idx INT;DECLARE batch_size INT DEFAULT 500;DECLARE insert_values TEXT;SET end_idx = LEAST(total, start_idx + batch_size - 1);WHILE start_idx <= total DOSET insert_values = '';WHILE start_idx <= end_idx DOSET insert_values = CONCAT(insert_values, CONCAT('(\'name', start_idx, '\', 0, 0, 0, NOW(), NOW()),'));SET start_idx = start_idx + 1;END WHILE;SET insert_values = LEFT(insert_values, LENGTH(insert_values) - 1); -- Remove the trailing commaSET @sql = CONCAT('INSERT INTO category_info_varchar_50 (name, is_show, sort, deleted, create_time, update_time) VALUES ', insert_values, ';');PREPARE stmt FROM @sql;EXECUTE stmt;SET @sql = CONCAT('INSERT INTO category_info_varchar_500 (name, is_show, sort, deleted, create_time, update_time) VALUES ', insert_values, ';'); PREPARE stmt FROM @sql;EXECUTE stmt;SET end_idx = LEAST(total, start_idx + batch_size - 1);END WHILE;
END$$
DELIMITER ;CALL batchInsertData(1000000);
3.验证存储空间
查询第一张表SQL
SELECTtable_schema AS "数据库",table_name AS "表名",table_rows AS "记录数",TRUNCATE ( data_length / 1024 / 1024, 2 ) AS "数据容量(MB)",TRUNCATE ( index_length / 1024 / 1024, 2 ) AS "索引容量(MB)"
FROMinformation_schema.TABLES
WHEREtable_schema = 'test_mysql_field' and TABLE_NAME = 'category_info_varchar_50'
ORDER BYdata_length DESC,index_length DESC;
查询结果

查询第二张表SQL
SELECTtable_schema AS "数据库",table_name AS "表名",table_rows AS "记录数",TRUNCATE ( data_length / 1024 / 1024, 2 ) AS "数据容量(MB)",TRUNCATE ( index_length / 1024 / 1024, 2 ) AS "索引容量(MB)"
FROMinformation_schema.TABLES
WHEREtable_schema = 'test_mysql_field' and TABLE_NAME = 'category_info_varchar_500'
ORDER BYdata_length DESC,index_length DESC;
查询结果

4.结论
两张表在占用空间上确实是一样的,并无差别
三.验证性能区别
1.验证索引覆盖查询
select name from category_info_varchar_50 where name = 'name100000'
-- 耗时0.012s
select name from category_info_varchar_500 where name = 'name100000'
-- 耗时0.012s
select name from category_info_varchar_50 order by name;
-- 耗时0.370s
select name from category_info_varchar_500 order by name;
-- 耗时0.379s
通过索引覆盖查询性能差别不大
1.验证索引查询
select * from category_info_varchar_50 where name = 'name100000'
--耗时 0.012s
select * from category_info_varchar_500 where name = 'name100000'
--耗时 0.012s
select * from category_info_varchar_50 where name in('name100','name1000','name100000','name10000','name1100000',
'name200','name2000','name200000','name20000','name2200000','name300','name3000','name300000','name30000','name3300000',
'name400','name4000','name400000','name40000','name4400000','name500','name5000','name500000','name50000','name5500000',
'name600','name6000','name600000','name60000','name6600000','name700','name7000','name700000','name70000','name7700000','name800',
'name8000','name800000','name80000','name6600000','name900','name9000','name900000','name90000','name9900000')
-- 耗时 0.011s -0.014s
-- 增加 order by name 耗时 0.012s - 0.015sselect * from category_info_varchar_50 where name in('name100','name1000','name100000','name10000','name1100000',
'name200','name2000','name200000','name20000','name2200000','name300','name3000','name300000','name30000','name3300000',
'name400','name4000','name400000','name40000','name4400000','name500','name5000','name500000','name50000','name5500000',
'name600','name6000','name600000','name60000','name6600000','name700','name7000','name700000','name70000','name7700000','name800',
'name8000','name800000','name80000','name6600000','name900','name9000','name900000','name90000','name9900000')
-- 耗时 0.012s -0.014s
-- 增加 order by name 耗时 0.014s - 0.017s
索引范围查询性能基本相同, 增加了order By后开始有一定性能差别;
3.验证全表查询和排序
全表无排序

![]()
全表有排序
select * from category_info_varchar_50 order by name ;
--耗时 1.498s
select * from category_info_varchar_500 order by name ;
--耗时 4.875s

![]()
结论:
全表扫描无排序情况下,两者性能无差异,在全表有排序的情况下, 两种性能差异巨大;
分析原因
varchar50 全表执行sql分析

我发现86%的时花在数据传输上,接下来我们看状态部分,关注Created_tmp_files和sort_merge_passes


Created_tmp_files为3
sort_merge_passes为95
varchar500 全表执行sql分析

增加了临时表排序


Created_tmp_files 为 4
sort_merge_passes为645
关于sort_merge_passes, Mysql给出了如下描述:
❝Number of merge passes that the sort algorithm has had to do. If this value is large, you may want to increase the value of the sort_buffer_size.
❞
其实sort_merge_passes对应的就是MySQL做归并排序的次数,也就是说,如果sort_merge_passes值比较大,说明sort_buffer和要排序的数据差距越大,我们可以通过增大sort_buffer_size或者让填入sort_buffer_size的键值对更小来缓解sort_merge_passes归并排序的次数。
四.最终结论
至此,我们不难发现,当我们最该字段进行排序操作的时候,Mysql会根据该字段的设计的长度进行内存预估, 如果设计过大的可变长度, 会导致内存预估的值超出sort_buffer_size的大小, 导致mysql采用磁盘临时文件排序,最终影响查询性能
相关文章:
MySQL 中 Varchar(50) 和 varchar(500) 区别是什么?
一. 问题描述 我们在设计表结构的时候,设计规范里面有一条如下规则: 对于可变长度的字段,在满足条件的前提下,尽可能使用较短的变长字段长度。 为什么这么规定?我在网上查了一下,主要基于两个方面 基于存储空间的考…...

强化RAG:微调Embedding还是LLM?
为什么我们需要微调? 微调有利于提高模型的效率和有效性。它可以减少训练时间和成本,因为它不需要从头开始。此外,微调可以通过利用预训练模型的功能和知识来提高性能和准确性。它还提供对原本无法访问的任务和领域的访问,因为它…...

提取 Excel单元格文本下的超链接
在Excel中,可以使用内置的函数来提取单元格中的超链接地址。如果你有一个包含超链接的单元格,例如B1,你可以使用以下步骤来提取这个超链接: 在一个新的单元格(例如C1)中,输入以下公式ÿ…...

一键安全体检!亚信安全携手鼎捷软件推出企业安全体检活动 正式上线
亚信安全联合鼎捷软件股份有限公司(以下简称“鼎捷软件”)正式推出“一键安全体检”服务。亚信安全网络安全专家将携手鼎捷软件数据安全专家,围绕企业的数智安全状况,进行问题探索与治愈、新问题预测与预警,在全面筛查…...
)
numpy - array(1)
一维数据:向量 二位数据:矩阵 维度超过三维的数据:张量 这些数据在numpy中统称array (1)使用穷举法创建多为数据,接受列表或者元组类型的数据 a numpy.array([1, 2, 3]) b numpy.array([[1, 2, 3], (4, 5, 6), [7, 8, 9]]) (2)创建所有元…...
师彼长技以助己(6)递归思维
师彼长技以助己(6)递归思维 递归思维-小游戏 思维小游戏 思维 小游戏:1 玩一个从1或2开始往上加的游戏,谁加到20就赢 如何保证一定赢呢?我们倒推,要先到20的话,谁先到17就赢,如此…...

Kali Linux 2024.2
Kali Linux 2024.2 版本(t64、GNOME 46 和社区包) 比平常晚了一点,但 Kali 2024.2 来了!延迟是由于实现这一目标的幕后变化所致,这也是人们关注的焦点。社区提供了大量帮助,这次他们不仅添加了新的软件包&…...
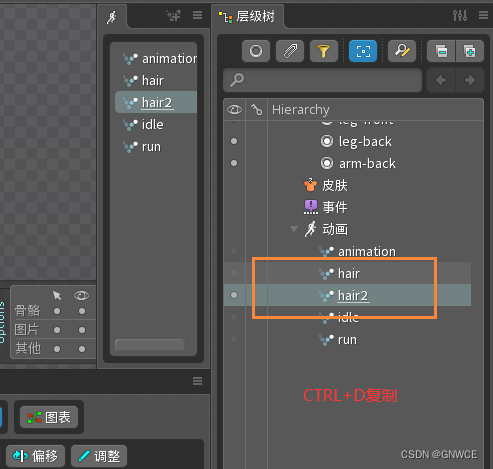
【Spine学习08】之短飘,人物头发动效制作思路
上一节说完了跑步的, 这节说头发发型。 基础过程总结: 1.创建骨骼(头发需要在上方加一个总骨骼) 2.创建网格(并绑定黄线) 3.绑定权重(发根位置的顶点赋予更多总骨骼的权重) 4.切换到…...

chatgpt的命令词
人不走空 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌赋:斯是陋室,惟吾德馨 目录 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌…...

用python把docx批量转为pdf
为保证转换质量,本文的方法是通过脚本和com技术调用office自带的程序进行转换的,因此需要电脑已经装有office。如果希望不装office也能用,则需要研究OpenXML技术,后面实在闲的慌(退休)再搞。 安装所需库 …...

项目采购管理
目录 1.概述 2.三个子过程 2.1.规划采购管理 2.2.实施采购 2.3.控制采购 2.4.归属过程组 3.应用场景 3.1.十个应用场景 3.2.软件开发项目 3.2.1. 需求识别和分析 3.2.2. 制定采购计划 3.2.3. 发布采购请求 3.2.4. 供应商评估与选择 3.2.5. 合同签订 3.2.6. 采购…...

Elasticsearch 认证模拟题 - 18
一、题目 为一个索引,按要求设置以下 dynamic Mapping 一切 text 类型的字段,类型全部映射成 keyword一切以 int_ 开头命名的字段,类型都设置成 integer 1.1 考点 字段的动态映射 1.2 答案 # 创建索引和索引模板 PUT my_index {"m…...

Python基础-速记笔记
Python的基础数据类型都有哪些? 1、字符串(string)2、布尔类型(bool)3、整数(int) 4、浮点数(float)5、列表(list)6、集合(set)7、元组(tuple)8、字典(dict) 其中不可变类型有: 字符串(string)、布尔类型(bool)、整数(int) 、浮点数(float)、元组(tup…...

青少年编程与数学 01-001开始使用计算机 02课题、计算机操作系统3_3
青少年编程与数学 01-001开始使用计算机 02课题、计算机操作系统3_3 四、Linux操作系统安装(一) 准备工作(二)设置BIOS/UEFI(三) 安装Linux(四)磁盘分区(五)安…...
填表统计预约打卡表单系统(FastAdmin+ThinkPHP+UniApp)
填表统计预约打卡表单系统:一键搞定你的预约与打卡需求 填表统计预约打卡表单系统是一款基于FastAdminThinkPHPUniApp开发的一款集信息填表、预约报名,签到打卡、活动通知、报名投票、班级统计等功能的自定义表单统计小程序。 📝 一、引言…...
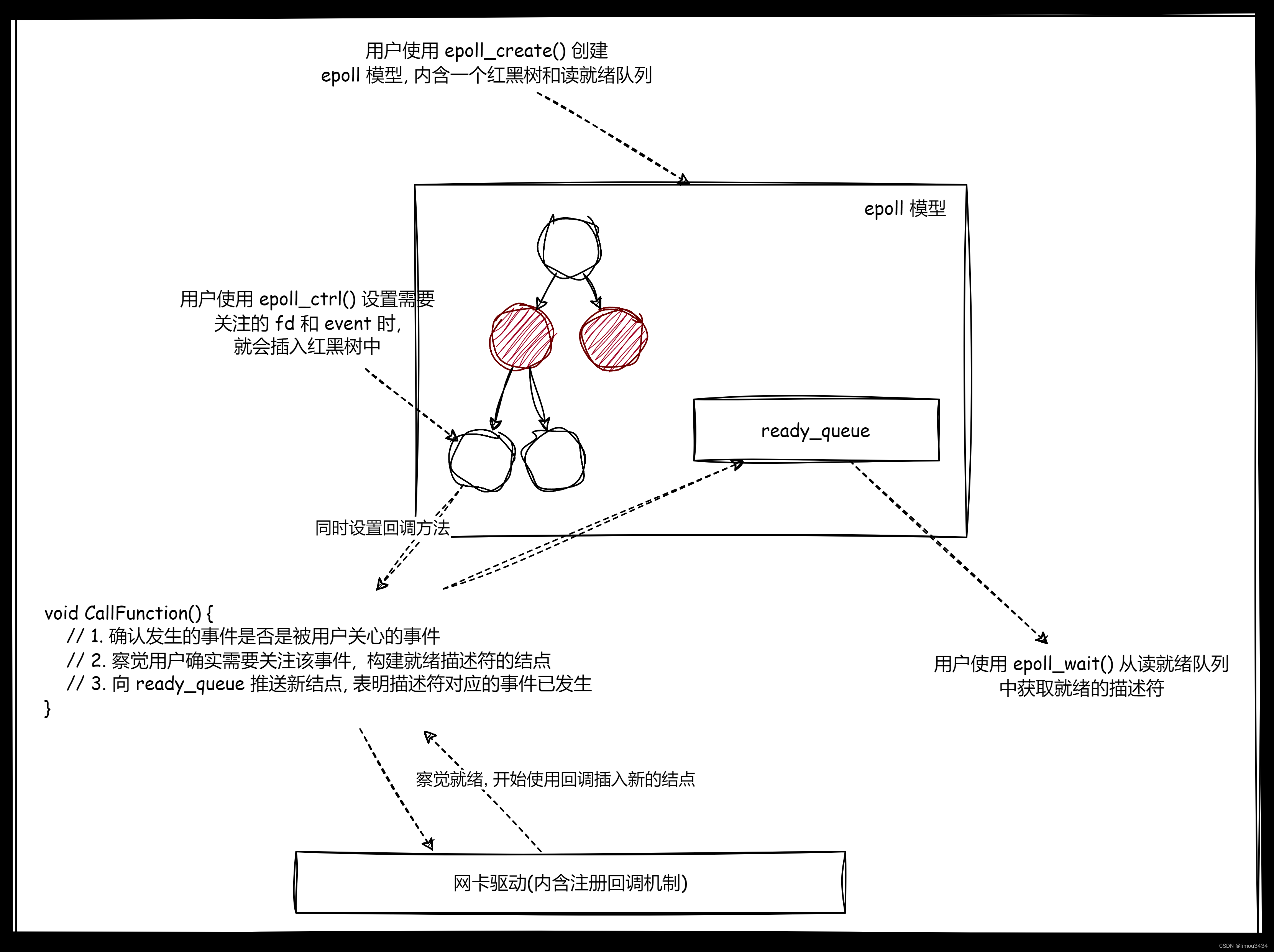
IO模型和多路转接
叠甲:以下文章主要是依靠我的实际编码学习中总结出来的经验之谈,求逻辑自洽,不能百分百保证正确,有错误、未定义、不合适的内容请尽情指出! 文章目录 1.IO 概要1.1.IO 低效原因1.2.IO 常见模型1.2.1.阻塞 IO1.2.2.非阻…...

如何完美解决升级 IntelliJ IDEA 最新版之后遇到 Git 记住密码功能失效的问题
🛠️ 如何完美解决升级 IntelliJ IDEA 最新版之后遇到 Git 记住密码功能失效的问题 摘要 在这篇文章中,我们将详细探讨如何解决在升级到 IntelliJ IDEA 最新版(2024.1.3 Ultimate Edition)后遇到的 Git 记住密码功能失效的问题。…...

SpringCloud微服务架构(eureka、nacos、ribbon、feign、gateway等组件的详细介绍和使用)
一、微服务演变 1、单体架构(Monolithic Architecture) 是一种传统的软件架构模式,应用程序的所有功能和组件都集中在一个单一的应用中。 在单体架构中,应用程序通常由一个大型的、单一的代码库组成,其中包含了所有…...

flinksql BUG : flink hologres-cdc source FINISHED
org.apache.flink.runtime.JobException: The failure is not recoverable or the failure does not allow to restart.at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler...
现代密码学-国密算法
商用密码算法种类 商用密码算法 密码学概念、协议与算法之间的依赖关系 数字签名、证书-公钥密码、散列类算法 消息验证码-对称密码 ,散列类 安全目标与算法之间的关系 机密性--对称密码、公钥密码 完整性--散列类算法 可用性--散列类、公钥密码 真实性--公…...

终极指南:三分钟掌握全网盘高速下载神器LinkSwift
终极指南:三分钟掌握全网盘高速下载神器LinkSwift 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

KMS_VL_ALL_AIO智能激活脚本:5分钟搞定Windows和Office永久激活的终极方案
KMS_VL_ALL_AIO智能激活脚本:5分钟搞定Windows和Office永久激活的终极方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活和Office办公软件授权而烦恼吗&…...

STM32F4用HAL库驱动MPU6050,从引脚重映射到数据读取的保姆级避坑指南
STM32F4 HAL库驱动MPU6050全流程实战:从引脚重映射到数据解析的深度避坑指南 第一次接触STM32F4和MPU6050的组合时,我花了整整三天时间才让传感器吐出第一个有效数据。不是I2C通信失败,就是数据全为零,最崩溃的是明明按照教程操作…...

冒险岛WZ文件解析:从数据迷宫到资源宝库的完整指南
冒险岛WZ文件解析:从数据迷宫到资源宝库的完整指南 【免费下载链接】WzComparerR2 Maplestory online Extractor 项目地址: https://gitcode.com/gh_mirrors/wz/WzComparerR2 你是否曾经好奇冒险岛游戏中那些精美的角色装备、华丽的地图场景和丰富的UI界面是…...

OpenClaw 用户迁移至 Taotoken 平台享受更优 Token 价格
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw 用户迁移至 Taotoken 平台享受更优 Token 价格 对于正在使用 OpenClaw 这类兼容 OpenAI 协议客户端的开发者或团队而言&a…...

专业级隐私保护工具:Boss-Key老板键完全使用指南
专业级隐私保护工具:Boss-Key老板键完全使用指南 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在现代办公环境中,…...

还在用高斯牛顿法?看看有全局最优保证的求解器!
点击下方卡片,关注「3D视觉工坊」公众号选择星标,干货第一时间送达3D视觉工坊很荣幸邀请到了西湖大学与浙江大学联合培养项目的博士生三年级研究生廖邦彦,为大家着重分享他们团队的工作。如果您有相关内容需要分享,欢迎文末联系我…...

别再重装系统了!Ubuntu 20.04 下 libsnark 零知识证明环境一次搭建成功的保姆级避坑指南
零知识证明开发实战:Ubuntu 20.04下libsnark环境高效搭建指南 在区块链和密码学领域,零知识证明技术正成为隐私保护的核心解决方案。作为最具代表性的开源库之一,libsnark因其高效的证明系统实现而被众多隐私项目采用。然而,许多开…...

SciPy 图结构
在 SciPy 中,图结构(Graph) 的处理主要依赖于 scipy.sparse.csgraph 模块。该模块专门用于处理稀疏矩阵表示的图(邻接矩阵或拉普拉斯矩阵),提供了一系列高效的图算法。 注意:SciPy 的图功能侧重…...

懒人必备!OpenClaw 汉化版一键配置上手教程
一、Windows 11 安装 OpenClaw 必看说明 OpenClaw(国内用户昵称"小龙虾")是一款广受欢迎的开源本地AI助手,GitHub星标数已超28万。它集成了多项实用功能:电脑自动操控、智能文件管理、浏览器自动化以及办公流程自动化等…...