德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第十一周) - 自然语言处理扩展研究
自然语言处理扩展研究
- 1. 多语言研究
- 2. 语言锚定
- 3. 伦理问题
1. 多语言研究
多语言(Multilinguality)是NLP的一个重要研究方向,旨在开发能够处理多种语言的模型和算法。由于不同语言在语法、词汇和语义结构上存在差异,这成为一个复杂且具有挑战性的研究领域。多语言性的研究促进了机器翻译、跨语言信息检索和多语言对话系统等应用的发展。
以下是多语言的几个主要研究方向和重要技术:
多语言模型的构建,开发能够同时处理多种语言并在这些语言之间共享知识的模型。
- 多语言预训练模型(Multilingual Pre-trained Models):如mBERT(multilingual BERT)、XLM(Cross-lingual Language Model)和mT5(multilingual T5)。
- 共享编码器(Shared Encoder):使用共享编码器处理不同语言的输入,减少特定语言的依赖。
语言间迁移学习,利用高资源语言中的知识和数据改善低资源语言的处理能力。
- 跨语言迁移学习(Cross-lingual Transfer Learning):在高资源语言上训练的模型迁移到低资源语言中使用。
- 适应模型(Adapter Modules):使用适配器模块在特定语言中进行微调,提高模型的灵活性和适应性。
机器翻译和跨语言任务,提高语言之间的自动翻译质量和跨语言任务的处理能力。
- 无监督机器翻译(Unsupervised Machine Translation):利用未对齐的单语语料进行翻译模型的训练。
- 多语言机器翻译(Multilingual Machine Translation):开发能够处理多种语言对的翻译模型。
- 跨语言信息检索(Cross-lingual Information Retrieval):允许用户使用一种语言查询以另一种语言撰写的文档。
多语言情感分析和情感计算,对多语言文本进行情感分析,检测情绪、情感和态度。
- 多语言情感资源的构建:开发多语言情感词典和注释数据集。
- 跨语言情感模型:在高资源语言上训练的情感模型泛化到低资源语言。
多语言知识库和知识图谱,构建和使用多语言知识库,进行跨语言的知识推理和问答。
- 多语言知识图谱:如Wikidata、DBpedia,多语言实体和关系数据的集成。
- 跨语言问答系统(Cross-lingual Question Answering):允许用户用一种语言提问并从另一种语言的文档中找到答案。
语言对齐和表示共享
- 跨语言词嵌入(Cross-lingual Word Embeddings):使不同语言的词语映射到同一向量空间,如MUSE、fastText。
- 对齐变换器(Aligned Transformers):通过对齐不同语言的语义表示,改进多语言处理,如LABSE(Language-agnostic BERT Sentence Embedding)。
挑战与未来方向
- 数据稀缺性:低资源语言缺乏大量标注数据,这仍然是一个主要挑战。
- 语言多样性:语言的复杂性和差异性使得开发通用的处理方法变得困难。
- 伦理和公平性:确保模型在各类语言和文化中表现公平,不带有偏见。
- 多语言相关研究
Unsupervised Part-of-Speech Tagging with Bilingual Graph-Based Projections
Multi-Source Transfer of Delexicalized Dependency Parsers
Massively Multilingual Word Embeddings
Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond
How Multilingual is Multilingual BERT?
2. 语言锚定
语言锚定(Language Grounding)在NLP领域尤为重要,因为它涉及将自然语言理解与真实世界的知识和感知信息相结合。这一研究领域探索了如何使得机器能够将语言输入与具体的实体或场景关联起来,从而实现更高水平的理解和交互。这个过程使得机器能够理解语言中的词汇、短语或句子所代表的具体含义,并将这些语言元素与实际的物体、事件或情境联系起来。这种连接有助于提高机器对语言的理解和处理能力,尤其是在涉及视觉、空间感知或情境理解的任务中。语言锚定强调的是将抽象的语言信息与具体、可感知的现实世界信息相结合,从而让机器能够更好地理解和生成语言。
语言锚定涉及将语言单元(如词汇、短语、句子)与外部世界的物理实体和感知数据(如图像、视频、声音等)进行关联,实现基于真实世界情境的语言理解。
目的:
- 增强语义理解:提高机器对语言的理解能力,使其能够关联语言描述和现实物体。
- 跨模态任务:为图像描述、视觉问答等任务提供基础支持。
- 自然交互:提升人机交互的自然性和准确性,使人类和机器之间的沟通更加直观。
语言锚定的主要研究方向
图像描述生成(Image Captioning)任务通过对图像进行分析,生成自然语言描述。核心技术包括编码器-解码器架构,使用卷积神经网络来编码图像特征,并用循环神经网络生成文本描述。以及注意力机制改进模型的性能,使其在描述生成时能够动态关注图像中的不同部分。著名模型有Show, Attend and Tell 结合了注意力机制,显著提升了描述生成的质量。Image Transformer使用Transformer架构提高了图像描述的效果。
视觉问答(Visual Question Answering, VQA)任务要求系统基于图像内容回答自然语言问题。核心技术包括联合嵌入(Joint Embedding)将图像特征和文本特征映射到相同的表示空间,提高理解和推理能力。以及多模态注意力(Multimodal Attention)同时关注文本和图像内容的关键部分,如BUTD(Bottom-Up and Top-Down Attention)。
跨模态检索(Cross-modal Retrieval)任务要求系统基于描述找到匹配的图像,或基于图像找到对应的描述。核心技术包括对比学习(Contrastive Learning)增加相似样本的相似度,减少非相似样本的相似度。双塔架构(Dual-Tower Architecture)分别使用CNN和RNN对图像和文本进行嵌入,然后进行相似性匹配。
多模态融合是将不同模态的信息进行有效融合是语言锚定的关键技术。融合方法包括前期融合(Early Fusion)在特征提取过程中早期结合不同模态的信息。后期融合(Late Fusion)独立处理视觉和语言信息后再进行融合。分层融合(Hierarchical Fusion)多层次的融合策略,可以在不同层次上结合模态信息,如使用多头注意力机制的Transformer。
- 语言锚定相关研究
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data
Provable Limitations of Acquiring Meaning from Ungrounded Form: What Will Future Language Models Understand?
Entailment Semantics Can Be Extracted from an Ideal Language Model
Experience Grounds Language
VQA: Visual Question Answering
Learning Transferable Visual Models From Natural Language Supervision
3. 伦理问题
伦理问题(Ethical Issues)在NLP和更广泛的人工智能领域中越来越受到关注。随着这些技术的广泛应用,确保它们的开发和使用符合道德和法律规范变得至关重要。这包括隐私保护、数据安全、公平性、透明度和可解释性等方面。然而,伴随着NLP技术的快速发展,也出现了许多伦理问题。这些问题如果不能妥善处理,可能会导致严重的社会后果。
主要伦理问题
偏见和歧视(Bias and Discrimination),NLP模型可能会在种族、性别、宗教等方面表现出偏见,这通常源于训练数据中的不平衡和偏见。
- 种族偏见:NLP模型可能对某些种族群体表现出负面偏见。
- 性别偏见:模型可能对性别角色有不公平的刻板印象。
隐私问题(Privacy Issues),NLP应用(如聊天机器人、语音助手等)通常需要收集和处理大量用户数据,存在隐私泄露的风险。
- 数据收集:未经用户同意的数据收集可能侵害隐私。
- 数据泄露:数据存储和传输过程中存在泄露风险。
虚假信息生成(Misinformation and Fake News),NLP技术可以用来生成看似真实但实际上虚假的内容。
- 虚假新闻:自动生成的新闻报道可能被用来传播虚假信息。
- 生成式模型:如GPT-3等生成模型可以创建大规模高质量的虚假内容。
道德责任(Ethical Responsibility),开发和使用NLP技术的公司和研究人员需要对其技术的社会影响负责。
- 透明性和可解释性:模型决策过程需要透明和可解释,以便用户理解和信任。
- 责任归属:模型产生错误或带来负面影响时的责任归属问题。
相关研究方向
降低偏见(Bias Mitigation)研究如何识别和消除NLP模型中的偏见。
- 数据均衡和去偏处理:在数据收集和预处理阶段重视数据的多样性和公平性。
- 公平性算法:开发专门的算法,如公平性正则化、对抗训练等,来降低模型中的偏见。
隐私保护技术(Privacy-preserving Techniques),保证用户数据的隐私和安全。
- 差分隐私(Differential Privacy):通过添加噪声保护数据隐私,使得单个数据条目的贡献难以察觉。
- 联邦学习(Federated Learning):允许模型在不共享原始数据的情况下进行训练,确保数据留在本地设备。
虚假信息检测(Misinformation Detection),研究如何检测和防止虚假信息的传播。
- 信息溯源:追踪信息的来源和传播路径,以验证其可信度。
- 内容验证模型:训练专门的模型来检测虚假内容和生成内容的质量,比如使用对抗性训练来区分真实和虚假内容。
模型透明性和解释性(Model Transparency and Interpretability),提高模型的透明度和决策过程的可解释性。
- 可解释性方法:使用可解释性工具,如LIME(Local Interpretable Model-agnostic Explanations)、SHAP(SHapley Additive exPlanations)等,帮助用户理解模型决策。
- 透明度报告:发布模型透明度报告,包含数据来源、模型设计和评估方法等关键信息。
随着NLP技术的日益普及,伦理问题将越来越成为研究和应用中的一个重要关注点。只有通过多方合作和持续努力,才能在技术进步的同时确保社会的公平性、安全性和隐私保护。
- 伦理问题相关研究
The Social Impact of Natural Language Processing
Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints
GeoMLAMA: Geo-Diverse Commonsense Probing on Multilingual Pre-Trained Language Models
Visually Grounded Reasoning across Languages and Cultures
On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models
Datasheets for Datasets
Closing the AI Accountability Gap: Defining an End-to-End Framework for Internal Algorithmic
相关文章:
 - 自然语言处理扩展研究)
德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第十一周) - 自然语言处理扩展研究
自然语言处理扩展研究 1. 多语言研究2. 语言锚定3. 伦理问题 1. 多语言研究 多语言(Multilinguality)是NLP的一个重要研究方向,旨在开发能够处理多种语言的模型和算法。由于不同语言在语法、词汇和语义结构上存在差异,这成为一个复杂且具有挑战性的研究…...
中核函数的本质意义)
支持向量机(SVM)中核函数的本质意义
本质上在做什么? 内积是距离度量,核函数相当于将低维空间的距离映射到高维空间的距离,并非对特征直接映射。 为什么要求核函数是对称且Gram矩阵是半正定? 核函数对应某一特征空间的内积,要求①核函数对称;②…...
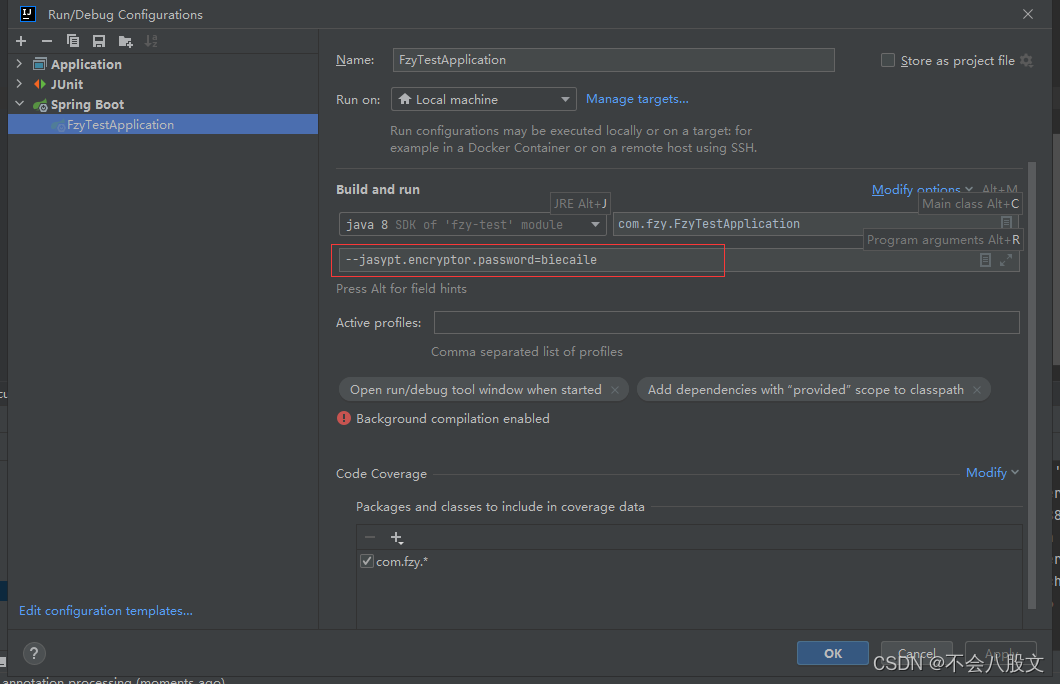
SpringBoot使用jasypt实现数据库信息的脱敏,以此来保护数据库的用户名username和密码password(容易上手,详细)
1.为什么要有这个需求? 一般当我们自己练习的时候,username和password直接是爆露出来的 假如别人路过你旁边时看到了你的数据库账号密码,他跑到他的电脑打开navicat直接就是一顿连接,直接疯狂删除你的数据库,那可就废…...

Python日志配置策略
1 三种情况下都能实现日志打印: 被库 A 调用,使用库 A 的日志配置。被库 B 调用,使用库 B 的日志配置。独立运行,使用自己的日志配置。 需要实现一个灵活的日志配置策略,使得日志记录器可以根据调用者或运行环境自动…...
想学编程,什么语言最好上手?
Python是许多初学者的首选,因为它的语法简洁易懂,而且有丰富的资源和社区支持。我这里有一套编程入门教程,不仅包含了详细的视频 讲解,项目实战。如果你渴望学习编程,不妨点个关注,给个评论222,…...

binlog和redolog有什么区别
在数据库管理系统中,binlog(binary log)和 redolog(redo log)是两种重要的日志机制,它们在数据持久性和故障恢复方面扮演着关键角色。虽然它们都用于记录数据库的变化,但它们的目的和使用方式有…...
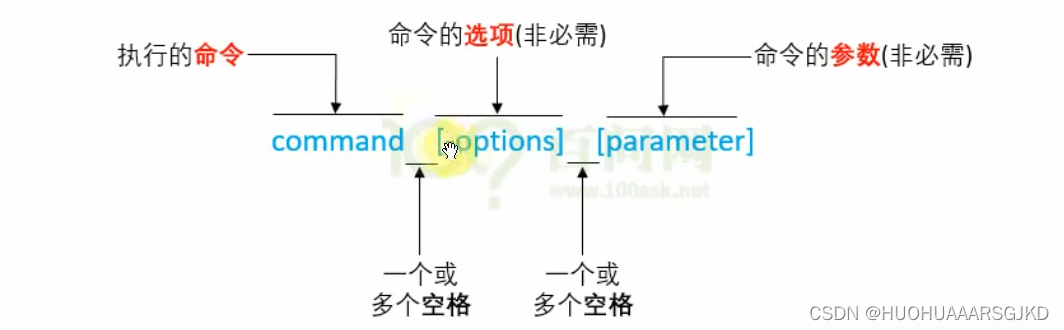
Linux笔记--ubuntu文件目录+命令行介绍
文件目录 命令行介绍 当我们在ubuntu中命令行处理位置输入ls后会显示出其所有目录,那么处理这些命令的程序就是shell,它负责接收用户的输入,并根据输入找到其他程序并运行 命令行格式 linux的命令一般由三部分组成:command命令、…...

71、最长上升子序列II
最长上升子序列II 题目描述 给定一个长度为N的数列,求数值严格单调递增的子序列的长度最长是多少。 输入格式 第一行包含整数N。 第二行包含N个整数,表示完整序列。 输出格式 输出一个整数,表示最大长度。 数据范围 1 ≤ N ≤ 100000…...
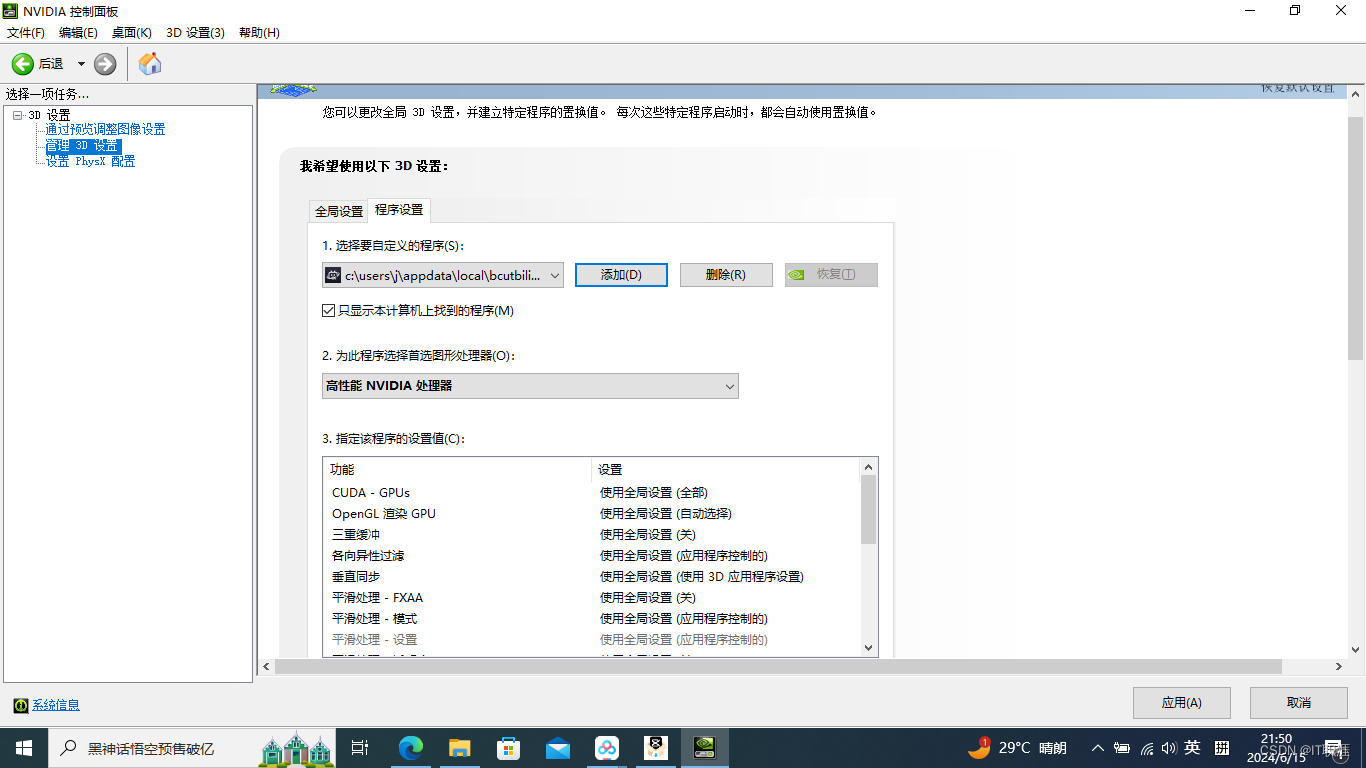
解决必剪电脑版导出视频缺斤少两的办法
背景 前几天将电脑重置了,今天想要剪辑一下视频,于是下载了必剪,将视频、音频都调整好,导出,结果15分钟的视频只能导出很短的时长,调整参数最多也只能导出10分钟,My God! 解决 首…...
)
新人学习笔记之(常量)
一、什么是常量 1.常量:在程序的执行过程中,其值不能发生改变的数据 二、常量的分类 常量类型说明举例整型常量整数、负数、0123 456实型常量所有带小数点的数字1.93 18.2字符常量单引号引起来的字母、数字、英文符号S B字符串常量双引号引起来的&…...

Lua解释器裁剪
本文目录 1、引言2、文件功能3、选择需要初始化的库4、结论 文章对应视频教程: 已更新。见下方 点击图片或链接访问我的B站主页~~~ Lua解释器裁剪,很简单~ 1、引言 在嵌入式中使用lua解释器,很多时候会面临资源紧张的情况。 同时,…...

web前端设计nav:深入探索导航栏设计的艺术与技术
web前端设计nav:深入探索导航栏设计的艺术与技术 在web前端设计中,导航栏(nav)扮演着至关重要的角色,它不仅是用户浏览网站的指引,更是网站整体设计的点睛之笔。本文将从四个方面、五个方面、六个方面和七…...

分析解读NCCL_SHM_Disable与NCCL_P2P_Disable
在NVIDIA的NCCL(NVIDIA Collective Communications Library)库中,NCCL_SHM_Disable 和 NCCL_P2P_Disable 是两个重要的环境变量,它们控制着NCCL在多GPU通信中的行为和使用的通信机制。下面是对这两个环境变量的详细解读࿱…...

使用 Python 进行测试(6)Fake it...
总结 如果我有: # my_life_work.py def transform(param):return param * 2def check(param):return "bad" not in paramdef calculate(param):return len(param)def main(param, option):if option:param transform(param)if not check(param):raise ValueError(…...

Flink Watermark详解
Flink Watermark详解 一、概述 Flink Watermark是Apache Flink框架中为了处理乱序和延迟事件时间数据而引入的一种机制。在流处理中,由于数据可能不是按照事件产生的时间顺序到达的,Watermark被用来告知系统在该时间戳之前的数据已经全部到达ÿ…...

LeetCode538.把二叉搜索树转换为累加树
class Solution { public:int sum 0; TreeNode* convertBST(TreeNode* root) { if (root){convertBST(root->right);sum root->val;root->val sum;convertBST(root->left);}return root;}};...

关于编程思想
面向过程思想 面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候再一个一个的依次调用就可以了 JS就是典型的面向过程的编程语言 优点: 性能比面向对象编程高,适合跟硬件联系很紧密的东西…...
521. 最长特殊序列 Ⅰ(Rust单百解法-脑筋急转弯)
题目 给你两个字符串 a 和 b,请返回 这两个字符串中 最长的特殊序列 的长度。如果不存在,则返回 -1 。 「最长特殊序列」 定义如下:该序列为 某字符串独有的最长 子序列 (即不能是其他字符串的子序列) 。 字符串 s …...
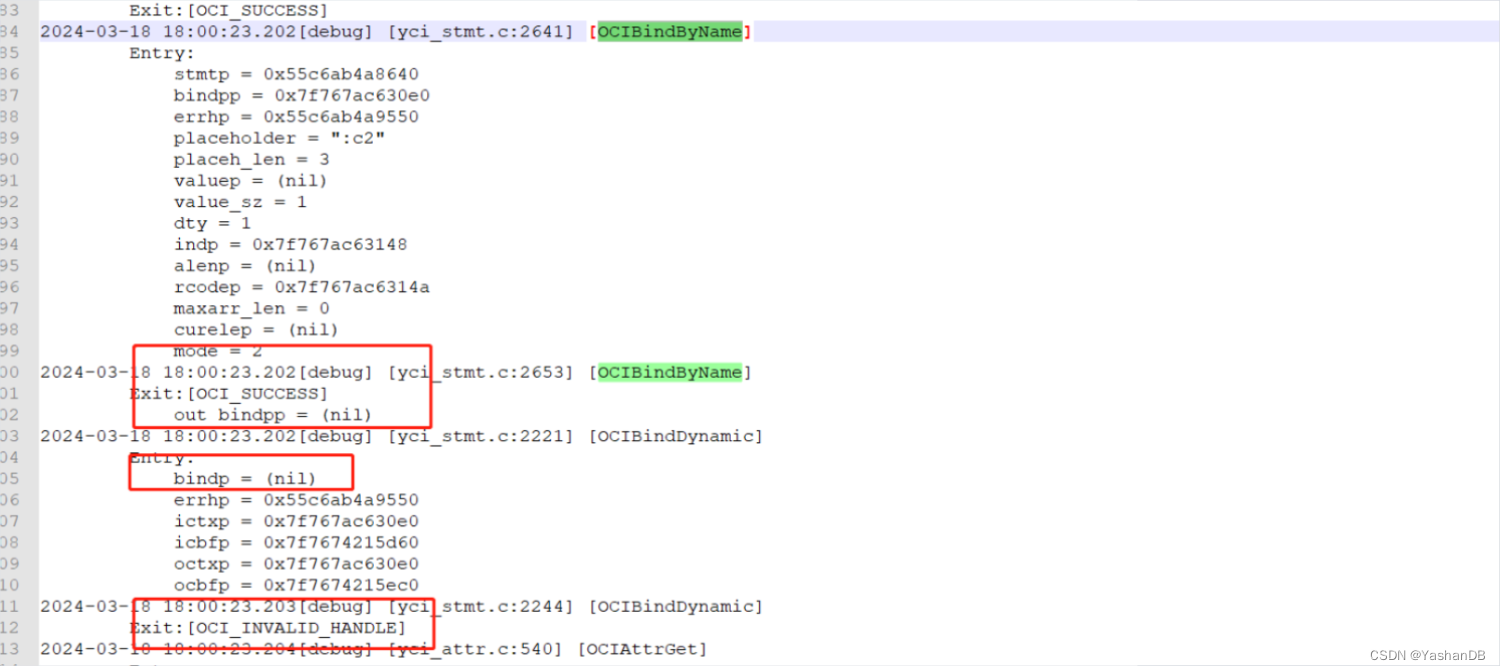
【YashanDB知识库】PHP使用OCI接口使用数据库绑定参数功能异常
【问题分类】驱动使用 【关键字】OCI、驱动使用、PHP 【问题描述】 PHP使用OCI8连接yashan数据库,使用绑定参数获取数据时,出现报错 如果使用PDO_OCI接口连接数据库,未弹出异常,但是无法正确获取数据 【问题原因分析】 开启O…...

深入分析 Android BroadcastReceiver (三)
文章目录 深入分析 Android BroadcastReceiver (三)1. 广播消息的优缺点及使用场景1.1 优点1.2 缺点 2. 广播的使用场景及代码示例2.1. 系统广播示例:监听网络状态变化 2.2. 自定义广播示例:发送自定义广播 2.3. 有序广播示例:有序广播 2.4. …...

射频非线性建模:从S参数到X参数与NVNA的工程实践
1. 非线性星期三:一场射频工程师的“大信号”狂欢如果你是一名射频或微波电路设计工程师,对S参数、负载牵引、谐波失真这些词感到既熟悉又头疼,那么十多年前在巴尔的摩举行的国际微波研讨会(IMS 2011)上,有…...

交完Essay才发现Turnitin更新了AI检测?我是这么应对的
上学期我的一个朋友被约谈了。 教授发邮件说:"你的Essay和AI生成文本相似度过高,请来办公室解释。" 他确实用了AI——谁没用呢——但他也认真改写了好几遍。问题是,Turnitin在2025年更新了AI检测模型,现在它不只看词汇…...

从GPS周内秒到日常时间:原理、转换与编程实践
1. GPS时间系统的基本概念 第一次接触GPS时间数据时,我也被"周内秒"这个概念搞懵了。这和我们平时用的年月日时分秒完全不同,更像是一种程序员喜欢的计数方式。GPS时间系统(GPST)本质上是个超级精准的原子钟,…...
)
从文献检索到论文写作:Perplexity与Zotero构建AI-native科研流水线(实测单篇综述效率提升3.8倍)
更多请点击: https://intelliparadigm.com 第一章:从文献检索到论文写作:Perplexity与Zotero构建AI-native科研流水线(实测单篇综述效率提升3.8倍) 在AI-native科研范式下,传统文献管理与写作流程正被重构…...

SmartNIC如何优化AI流水线与网络计算卸载
1. SmartNIC与AI流水线的联姻:网络计算卸载的技术革命 在分布式AI推理场景中,我们常常遇到一个令人头疼的现象:当GPU计算单元满载运行时,CPU利用率也常常飙升至90%以上。这种资源争用并非来自模型推理本身,而是源于那些…...
:复制带随机指针的链表)
用100道题拿下你的算法面试(链表篇-7):复制带随机指针的链表
一、面试问题 给定一个链表的头节点,链表中每个节点都包含两个指针:一个指向下一个节点的 next 指针,以及一个指向链表中任意节点的 random 指针。请复制该链表,并返回新链表的头节点。 二、【朴素解法】使用哈希表 —— 时间复杂…...

基于MCP协议与FFmpeg构建AI视频处理服务器:原理、部署与实战
1. 项目概述:一个面向视频处理的MCP服务器 最近在折腾一些AI应用,发现很多工具在处理视频内容时,总感觉差了那么一口气。要么是功能太单一,只能做简单的剪辑或转码;要么就是流程太复杂,需要把视频下载、处…...

Notero终极指南:打通Zotero与Notion的学术工作流桥梁
Notero终极指南:打通Zotero与Notion的学术工作流桥梁 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 当你在Zotero中积累了数百篇文献,却发现整理和引用它…...

【Oracle数据库指南】第06篇:Oracle DML语句与事务控制——数据操作与ACID特性深度解析
上一篇【第05篇】Oracle子查询与集合操作——嵌套查询与结果合并全解析 下一篇【第07篇】SQL*Plus基础——登录、环境设置与缓冲区操作 摘要 本文全面讲解Oracle DML(数据操作语言)语句,包括INSERT、UPDATE、DELETE和MERGE的详细用法&#x…...

日本电子产业转型启示:从技术过剩到商业模式创新
1. 日本电子产业的十字路口:一场箱根闭门会背后的行业剧痛2013年的春天,当全球电子产业的聚光灯都打在硅谷和深圳时,日本箱根的一家温泉旅馆里,正进行着一场鲜为人知却意义深远的对话。索尼、瑞萨、NEC、日立、松下、富士通、Mega…...