关联查询的SQL有几种情况
1、内连接:inner join … on
结果:A表 ∩ B表
2、左连接:A left join B on
(2)A表全部
(3)A表- A∩B
3、右连接:A right join B on
(4)B表全部
(5)B表-A∩B
4、全外连接:full outer join … on,但是mysql不支持这个关键字,mysql使用union(合并)结果的方式代替
(6)A表∪B表: (2) A表结果 union (4)B表的结果
(7)A∪B - A∩B (3)A表- A∩B结果 union (5)B表-A∩B结果
1、内连接
// An highlighted block#演示内连接,结果是A∩B
/*
观察数据:
t_employee 看成A表
t_department 看成B表
此时t_employee (A表)中有 李红和周洲的did是NULL,没有对应部门,t_department(B表)中有 测试部,在员工表中找不到对应记录的。
*/#查询所有员工的姓名,部门编号,部门名称
#如果员工没有部门的,不要
#如果部门没有员工的,不要
/*
员工的姓名在t_employee (A表)中
部门的编号,在t_employee (A表)和t_department(B表)都有
部门名称在t_department(B表)中
所以需要联合两个表一起查询。
*/
SELECT ename,did,dname
FROM t_employee INNER JOIN t_department;
#错误Column 'did' in field list is ambiguous
#因为did在两个表中都有,名字相同,它不知道取哪个表中字段了
#有同学说,它俩都是部门编号,随便取一个不就可以吗?
#mysql不这么认为,有可能存在两个表都有did,但是did的意义不同的情况。
#为了避免这种情况,需要在编写sql的时候,明确指出是用哪个表的didSELECT ename,t_department.did,dname
FROM t_employee INNER JOIN t_department;
#语法对,结果不太对
#结果出现“笛卡尔积”现象, A表记录 * B表记录
/*
(1)凡是联合查询的两个表,必须有“关联字段”,
关联字段是逻辑意义一样,数据类型一样,名字可以一样也可以不一样的两个字段。
比如:t_employee (A表)中did和t_department(B表)中的did。发现关联字段其实就是可以建外键的字段。当然联合查询不要求一定建外键。(2)联合查询必须写关联条件,关联条件的个数 = n - 1.
n是联合查询的表的数量。
如果2个表一起联合查询,关联条件数量是1,
如果3个表一起联合查询,关联条件数量是2,
如果4个表一起联合查询,关联条件数量是3,
。。。。
否则就会出现笛卡尔积现象,这是应该避免的。(3)关联条件可以用on子句编写,也可以写到where中。
但是建议用on单独编写,这样呢,可读性更好。每一个join后面都要加on子句
A inner|left|right join B on 条件
A inner|left|right join B on 条件 inner|left|right jon C on 条件
*/SELECT ename,t_department.did,dname
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did;SELECT *
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did;#查询部门编号为1的女员工的姓名、部门编号、部门名称、薪资等情况
SELECT ename,gender,t_department.did,dname,salary
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did
WHERE t_department.did = 1 AND gender = '女';#查询部门编号为1的员工姓名、部门编号、部门名称、薪资、职位编号、职位名称等情况
SELECT ename,gender,t_department.did,dname,salary,job_id,jname
FROM t_employee INNER JOIN t_department ON t_employee.did = t_department.didINNER JOIN t_job ON t_employee.`job_id` = t_job.`jid`
WHERE t_department.did = 1;;
#演示内连接,结果是A∩B
/*
观察数据:
t_employee 看成A表
t_department 看成B表
此时t_employee (A表)中有 李红和周洲的did是NULL,没有对应部门,
t_department(B表)中有 测试部,在员工表中找不到对应记录的。
*/
#查询所有员工的姓名,部门编号,部门名称
#如果员工没有部门的,不要
#如果部门没有员工的,不要
/*
员工的姓名在t_employee (A表)中
部门的编号,在t_employee (A表)和t_department(B表)都有
部门名称在t_department(B表)中
所以需要联合两个表一起查询。
*/
SELECT ename,did,dname
FROM t_employee INNER JOIN t_department;
#错误Column ‘did’ in field list is ambiguous
#因为did在两个表中都有,名字相同,它不知道取哪个表中字段了
#有同学说,它俩都是部门编号,随便取一个不就可以吗?
#mysql不这么认为,有可能存在两个表都有did,但是did的意义不同的情况。
#为了避免这种情况,需要在编写sql的时候,明确指出是用哪个表的did
SELECT ename,t_department.did,dname
FROM t_employee INNER JOIN t_department;
#语法对,结果不太对
#结果出现“笛卡尔积”现象, A表记录 * B表记录
/*
(1)凡是联合查询的两个表,必须有“关联字段”,
关联字段是逻辑意义一样,数据类型一样,名字可以一样也可以不一样的两个字段。
比如:t_employee (A表)中did和t_department(B表)中的did。
发现关联字段其实就是可以建外键的字段。当然联合查询不要求一定建外键。
(2)联合查询必须写关联条件,关联条件的个数 = n - 1.
n是联合查询的表的数量。
如果2个表一起联合查询,关联条件数量是1,
如果3个表一起联合查询,关联条件数量是2,
如果4个表一起联合查询,关联条件数量是3,
。。。。
否则就会出现笛卡尔积现象,这是应该避免的。
(3)关联条件可以用on子句编写,也可以写到where中。
但是建议用on单独编写,这样呢,可读性更好。
每一个join后面都要加on子句
A inner|left|right join B on 条件
A inner|left|right join B on 条件 inner|left|right jon C on 条件
*/
SELECT ename,t_department.did,dname
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did;
SELECT *
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did;
#查询部门编号为1的女员工的姓名、部门编号、部门名称、薪资等情况
SELECT ename,gender,t_department.did,dname,salary
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did
WHERE t_department.did = 1 AND gender = ‘女’;
#查询部门编号为1的员工姓名、部门编号、部门名称、薪资、职位编号、职位名称等情况
SELECT ename,gender,t_department.did,dname,salary,job_id,jname
FROM t_employee INNER JOIN t_department ON t_employee.did = t_department.did
INNER JOIN t_job ON t_employee.job_id = t_job.jid
WHERE t_department.did = 1;
相关文章:

关联查询的SQL有几种情况
1、内连接:inner join … on 结果:A表 ∩ B表 2、左连接:A left join B on (2)A表全部 (3)A表- A∩B 3、右连接:A right join B on (4)B表全部 &#…...

查缺补漏三:事务隔离级别
什么是事务? 事务就是一组操作的集合,事务将整组操作作为一个整体,共同提交或者共同撤销 这些操作只能同时成功或者同时失败,成功即可提交事务,失败就执行事务回滚 MySQL的事务默认是自动提交的,一条语句执…...

没有她的通讯录(C语言实现)
🚀write in front🚀 📝个人主页:认真写博客的夏目浅石. 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 📣系列专栏:夏目的C语言宝藏 💬总结:希望你看完之…...

Spring Security 从入门到精通
前言 Spring Security 是 Spring 家族中的一个安全管理框架。相比与另外一个安全框架Shiro,它提供了更丰富的功能,社区资源也比Shiro丰富。 一般来说中大型的项目都是使用SpringSecurity 来做安全框架。小项目有Shiro的比较多,因为相比与Spr…...
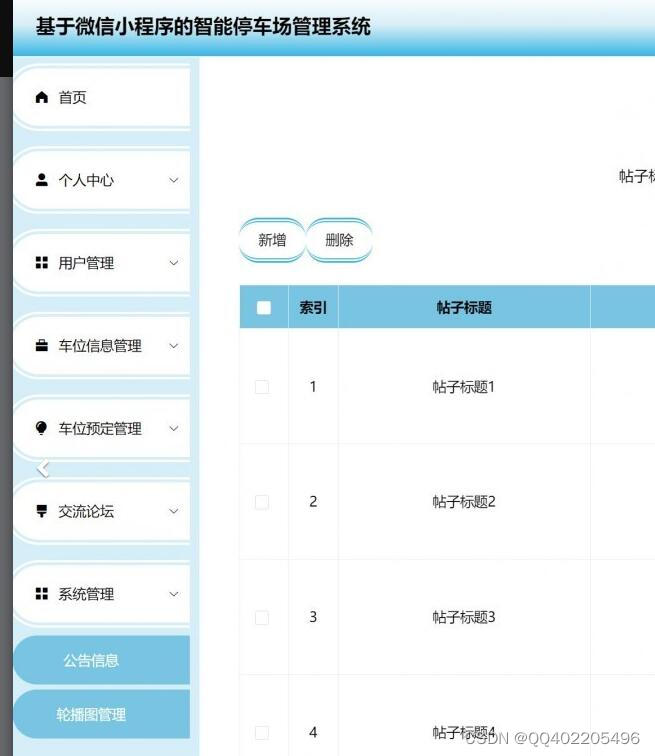
微信小程序Springboot vue停车场车位管理系统
系统分为用户和管理员两个角色 用户的主要功能有: 1.用户注册和登陆系统 2.用户查看系统的公告信息 3.用户查看车位信息,在线预约车位 4.用户交流论坛,发布交流信息,在线评论 5.用户查看地图信息,在线导航 6.用户查看个…...
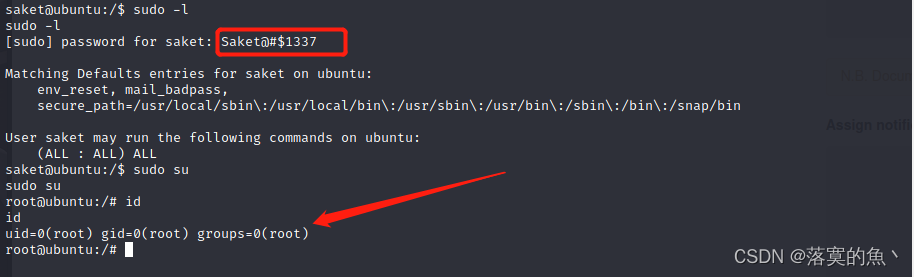
看完这篇 教你玩转渗透测试靶机vulnhub——Hack Me Please: 1
Vulnhub靶机Hack Me Please: 1渗透测试详解Vulnhub靶机介绍:Vulnhub靶机下载:Vulnhub靶机安装:Vulnhub靶机漏洞详解:①:信息收集:②:漏洞利用③:获取反弹shell:④&#x…...
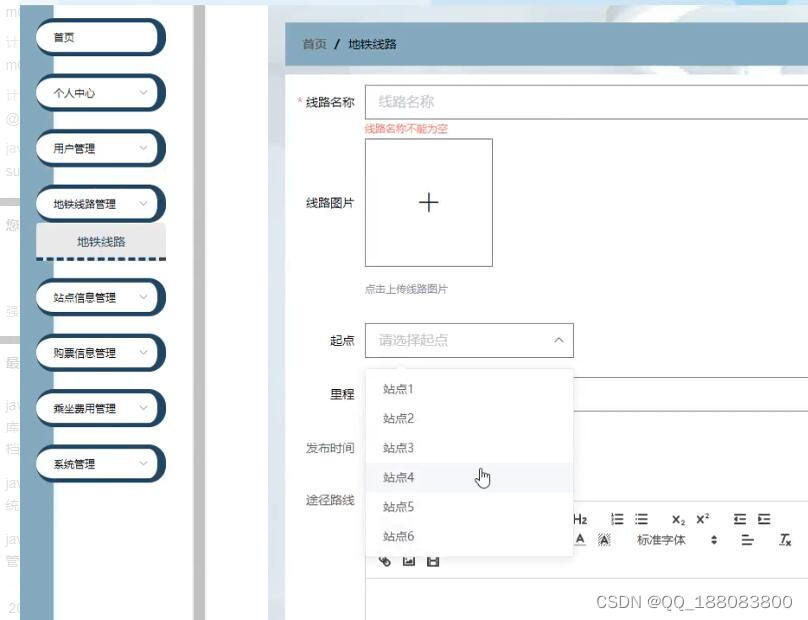
nodejs+vue地铁站自动售票系统-火车票售票系统vscode
地铁站自动售票系统主要包括个人中心、地铁线路管理、站点管理、购票信息管理、乘坐管理、用户信息管理等多个模块。它使用的是前端技术:nodejsvueelementui 前后端通讯一般都是采取标准的JSON格式来交互。前端技术:nodejsvueelementui,视图层其实质就是…...
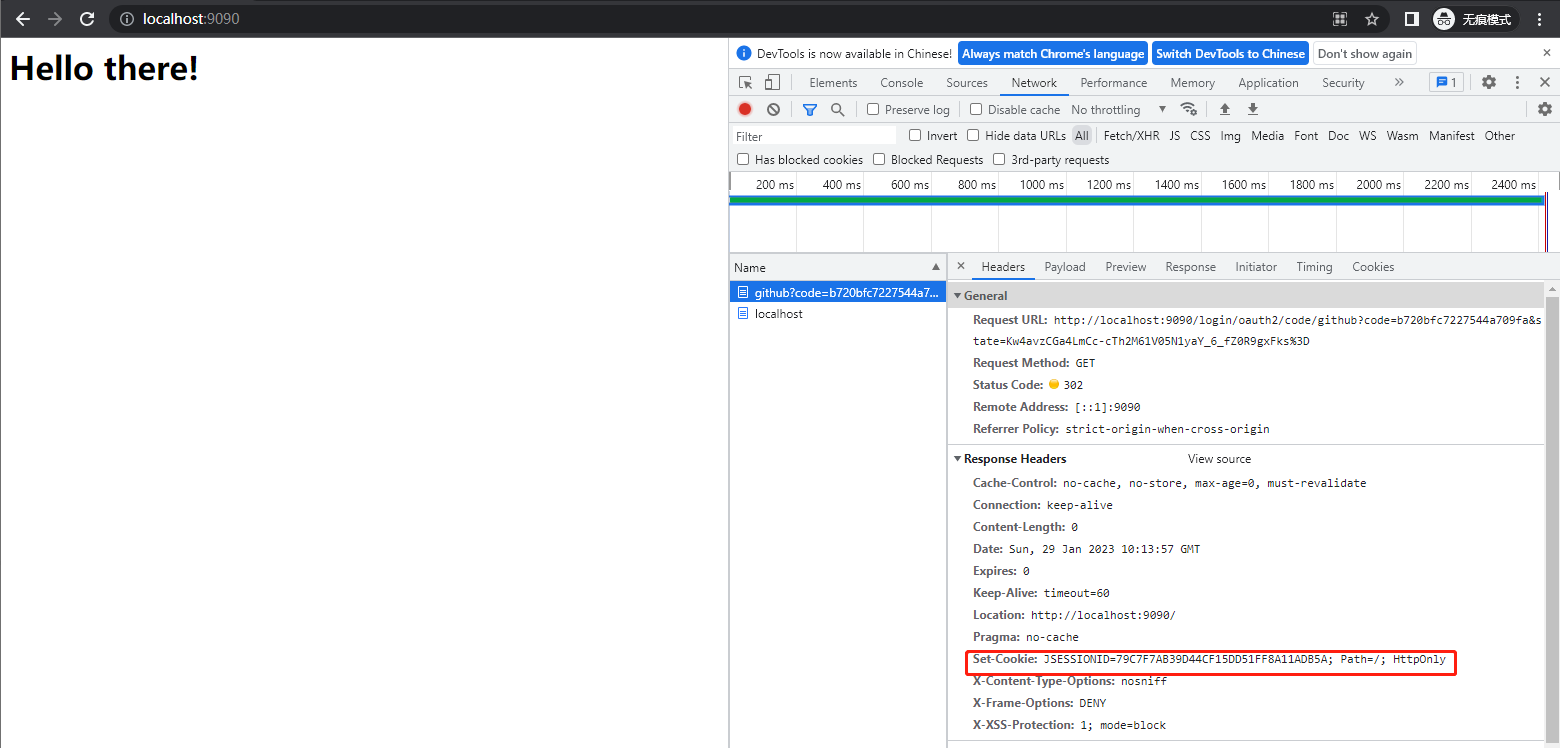
Spring Security in Action 第十二章 OAuth 2是如何工作的?
本专栏将从基础开始,循序渐进,以实战为线索,逐步深入SpringSecurity相关知识相关知识,打造完整的SpringSecurity学习步骤,提升工程化编码能力和思维能力,写出高质量代码。希望大家都能够从中有所收获&#…...
天工开物 #5 我的 Linux 开发机
首先说一下结论:最终我选择了基于 Arch Linux[1] 的 Garuda Linux[2] 发行版作为基础来搭建自己的 Linux 开发机。Neofetch 时刻发行版的选择在上周末的这次折腾里,我一共尝试了 Garuda Linux 发行版,原教旨的 Arch Linux 发行版,…...
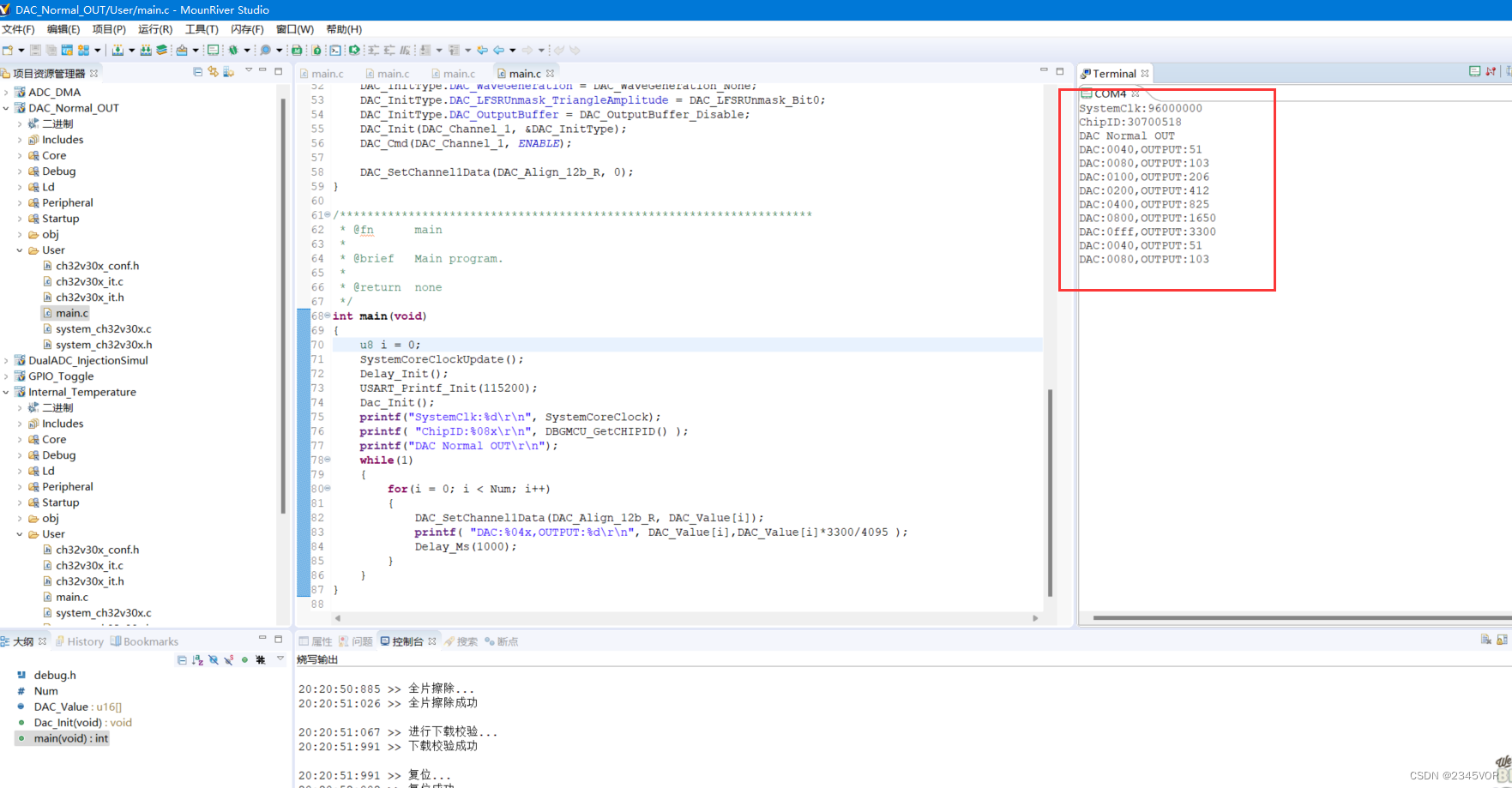
【沁恒WCH CH32V307V-R1开发板输出DAC实验】
【沁恒WCH CH32V307V-R1开发板输出DAC实验】1. 前言2. 软件配置2.1 安装MounRiver Studio3. DAC项目测试3.1 打开DAC工程3.2 编译项目4. 下载验证4.1 接线4.2 演示效果5. 小结1. 前言 数字/模拟转换模块(DAC),包含 2 个可配置 8/12 位数字输入…...
Linux进程控制详解
目录前言一、进程创建1.1 fork函数初识1.2 写时拷贝1.3 fork常规用法1.4 fork调用失败的原因二、进程终止2.1 进程终止时,操作系统做了什么??2.2 进程终止的常见方式有哪些??2.3 如何用代码终止一个进程三、进程等待3.…...

C语言深度剖析之程序环境和预处理
1.程序的翻译环境和执行环境 第一种是翻译环境,在这个环境中源代码被转换为可执行的机器指令 第二种是执行环境,它用于实际执行代码 2.翻译环境 分为四个阶段 预编译阶段 ,编译,汇编,链接 程序编译过程:多个…...
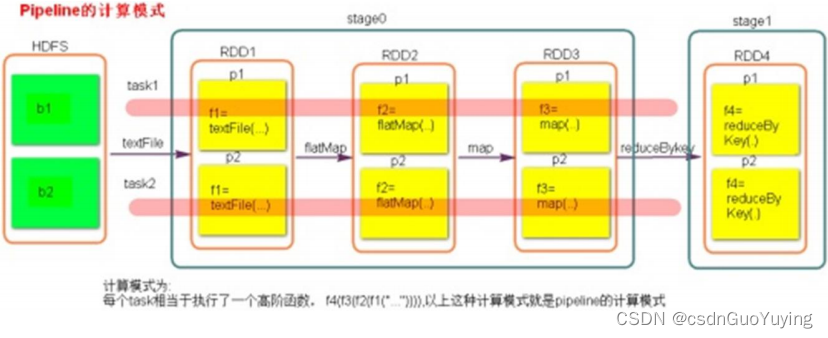
【Spark分布式内存计算框架——Spark Core】9. Spark 内核调度(上)
第八章 Spark 内核调度 Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stag…...
: Graphics pipeline之Render passes(渲染通道))
Vulkan教程(15): Graphics pipeline之Render passes(渲染通道)
Vulkan官方英文原文: https://vulkan-tutorial.com/Drawing_a_triangle/Graphics_pipeline_basics/Render_passes对应的Vulkan技术规格说明书版本: Vulkan 1.3.2Setup设置Before we can finish creating the pipeline, we need to tell Vulkan about the…...
乐观锁、雪花算法、MyBatis-Plus多数据源
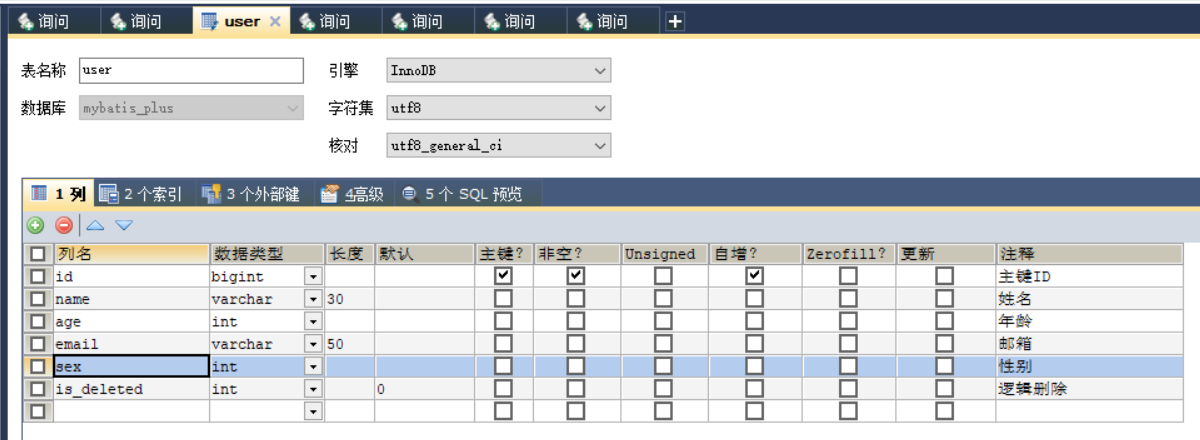
乐观锁、雪花算法、MyBatis-Plus多数据源e>雪花算法2、乐观锁a>场景b>乐观锁与悲观锁c>模拟修改冲突d>乐观锁实现流程e>Mybatis-Plus实现乐观锁七、通用枚举a>数据库表添加字段sexb>创建通用枚举类型c>配置扫描通用枚举d>测试九、多数据源1、创建…...
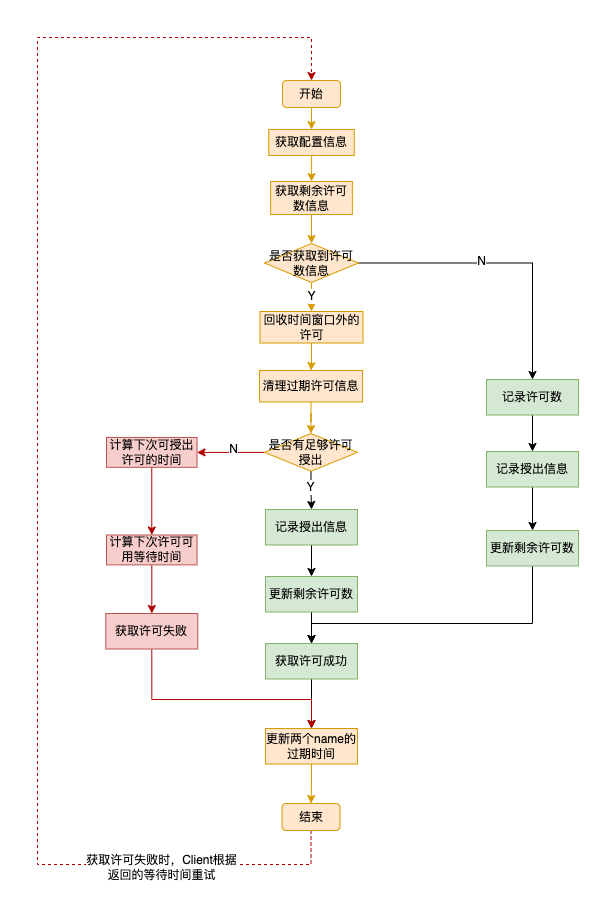
详解Redisson分布式限流的实现原理
我们目前在工作中遇到一个性能问题,我们有个定时任务需要处理大量的数据,为了提升吞吐量,所以部署了很多台机器,但这个任务在运行前需要从别的服务那拉取大量的数据,随着数据量的增大,如果同时多台机器并发…...

[python入门㊹] - python测试类
目录 ❤ 断言方法 assertEqual 和 assertNotEqual assertTrue 和 assertFalse assertIsNone 和 assertIsNotNone ❤ 一个要测试的类 ❤ 测试AnonymousSurvey类 ❤ setUp() 和 teardown() 方法 ❤ 断言方法 常用的断言方法: 方法 用途 assertEqual(a, b) 核实a …...
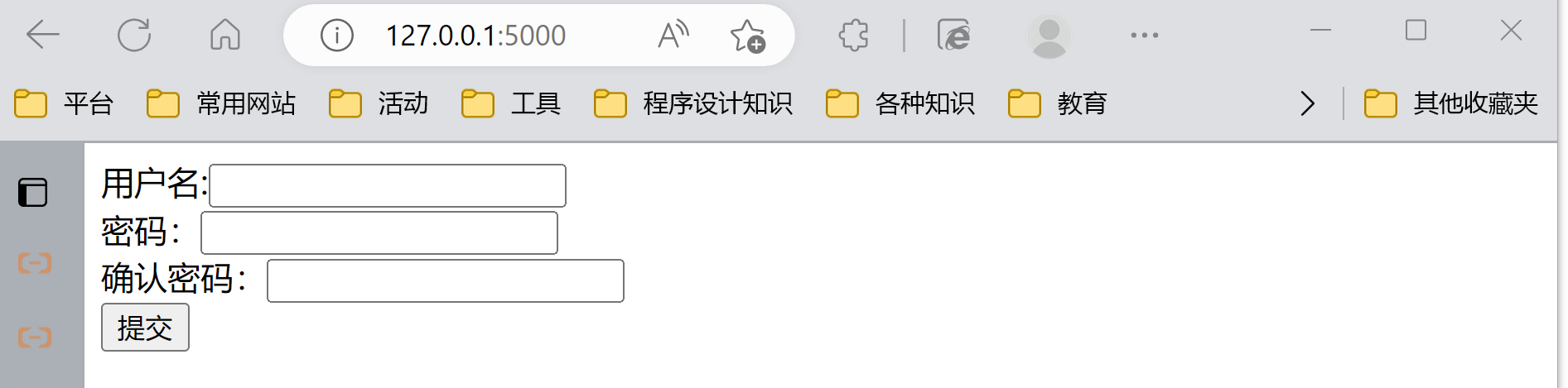
Web 框架 Flask 快速入门(二)表单
课程地址:Python Web 框架 Flask 快速入门 文章目录🌴 表单1、表单介绍2、表单的简单实现1. 代码2. 代码的执行逻辑3、使用wtf扩展实现4、bug记录:表单验证总是失败🌴 表单 1、表单介绍 当我们在网页上填写账号密码进行登录的时…...

C++基础(5) - 复合类型(上)
文章目录数组1、什么是数组2、数组的声明3、数组的初始化4、数组的访问5、二维数组6、memset —— 给数组中每一个元素赋同样的值字符串(字符数组)1、string.h 头文件1.1 strlen()1.2 strcmp()1.3 strcpy()1.4 strcat()string 类简介1、C11 字符串初始化…...
介绍及实例说明)
java重写(@Override)介绍及实例说明
1.概述方法的重写(override)是封装的特性之一。在子类中可以根据需要对基类中继承来的方法进行重写。重载和重写没有任何关系。作用:通过重写,子类既可以继承父类的东西,又可以灵活的扩充。1.override注解是告诉编译器…...

现代React Native开发:从Expo生态到Redux状态管理的工程实践
1. 项目概述:一个为现代React Native开发量身定制的生产力引擎 如果你和我一样,在过去几年里用React Native做过几个项目,那你一定对项目初始化时那种重复、繁琐的“体力活”深有体会。每次新建一个项目,都要重新安装一堆依赖库&…...

从找石油到防灾害:地震勘探技术如何跨界守护城市安全?
地震勘探技术的跨界革命:从油气勘探到城市安全守护者 上世纪20年代,当第一批地球物理学家尝试用炸药激发地震波来寻找石油时,他们或许不会想到,这项技术会在百年后成为保护现代城市安全的"透视眼"。传统的地震勘探技术…...

3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南
3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics LyricsX是一款专为macOS用户设计的开源桌面歌词显示…...

终极指南:5步安装Koikatu HF Patch解锁完整游戏体验
终极指南:5步安装Koikatu HF Patch解锁完整游戏体验 【免费下载链接】KK-HF_Patch Automatically translate, uncensor and update Koikatu! and Koikatsu Party! 项目地址: https://gitcode.com/gh_mirrors/kk/KK-HF_Patch KK-HF Patch是专为《恋活…...
)
R语言实战:用DescTools、ggiraphExtra、factoextra等包搞定多变量数据可视化(附完整代码)
R语言实战:多变量数据可视化的高效工具箱指南 在数据分析的日常工作中,我们常常需要处理包含数十甚至上百个变量的复杂数据集。传统的单变量或双变量可视化方法在这种场景下显得力不从心,而R语言生态系统中丰富的可视化包为我们提供了强大的工…...

基于RAG与MCP协议构建实时新闻AI助手:newsmcp项目实战解析
1. 项目概述:一个让AI“读新闻”的智能工具最近在折腾AI应用开发的朋友,可能都绕不开一个核心问题:如何让大语言模型(LLM)获取并理解最新的、模型训练数据之外的信息?比如,你想让ChatGPT帮你分析…...

告别手动下载!3步轻松批量获取网易云音乐FLAC无损音乐
告别手动下载!3步轻松批量获取网易云音乐FLAC无损音乐 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 你是不是也遇到过这样的烦恼&#x…...

告别ElementUI日历的默认样式!手把手教你用SCSS深度定制一个高颜值日历组件
从零打造高颜值日历组件:ElementUI Calendar深度定制指南 当你打开项目后台管理系统,那个灰扑扑的默认日历组件是否总让你皱眉?作为前端开发者,我们经常需要在不破坏原有功能的前提下,为ElementUI的Calendar组件换上符…...

Python3+bypy实战:给你的服务器加个百度网盘自动备份脚本
Python3bypy实战:构建服务器自动化备份系统 在数据为王的时代,服务器上的关键数据如同数字生命线。想象一下凌晨三点收到数据库崩溃的告警,却发现最后一次备份是两周前的手动快照——这种噩梦般的场景正是自动化备份要消灭的敌人。本文将带你…...

CDFControl工具详解,搞定云桌面黑屏、卡顿、随机掉线疑难故障
一 前言 在企业Citrix云桌面运维工作中,我们经常遇到一类无明确报错、间歇性复现的疑难故障。常规Windows事件查看器日志干净无报错,常规DDC控制台监控无异常,但终端用户会频繁出现登录黑屏、会话卡顿、虚拟机随机掉线、VDA注册超时等问题。 很多运维人员遇到此类问题只能…...