clickhouse学习笔记(四)库、表、分区相关DDL操作
目录
一、数据库操作
1、创建数据库
2、查询及选择数据库
3、删除数据库
二、数据表操作
1、创建表
2、删除表
3、基本操作
①追加新字段
②修改字段类型或默认值
③修改字段注释
④删除已有字段
⑤移动数据表(重命名)
⑥清空表
三、默认值
1、默认值三种定义方法之间的不同:
2、可以使用 ALTER 语句修改默认值,例如:
四、临时表
五、分区表
1、创建分区
2、删除指定分区
3、复制分区数据
4、重置分区数据
5、装载与卸载分区
六、视图
七、分布式DDL执行
一、数据库操作
1、创建数据库
创建数据库的语法如下
CREATE DATABASE IF NOT EXISTS db_name[ENGINE = engine]
数据库也支持设置引擎,[ENGINE = engine]表示数据库所使用的的引擎类型,当不加[ENGINE = engine]时会默认为使用默认引擎Ordinary
目前支持5种引擎如下
Ordinary:默认引擎,在绝大多数情况下我们都会使用默认引擎,使用时无须刻意声明,在此数据库下可以使用任意类型的表引擎Dictionary:字典引擎,此类数据库会自动为所有数据字典创建它们的数据表,关于数据字典的详细介绍会在后面展开Memory:内存引擎,用于存放临时数据。此类数据库下的数据表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会被清除Lazy:日志引擎,此类数据库下只能使用 Log 系列的表引擎,关于 Log 表引擎的详细介绍会后续章节展开MySQL:MySQL 引擎,此类数据库下会自动拉取远端 MySQL 中的数据,并为它们创建 MySQL 表引擎的数据表,关于MySQL表引擎的详细介绍也会在后续章节展开。
数据库的实质就是物理磁盘上的一个目录文件,在执行创建语句后安装路径下会创建对应名字的目录文件
2、查询及选择数据库
SHOW DATABASES;USE DATABASES;3、删除数据库
DROP DATABASE [IF EXISTS] db_name;
二、数据表操作
表也是在物理磁盘上的一个目录文件,会在数据库的目录下,而数据是在表的目录下的文本文件
1、创建表
clickhouse提供了三种建表方式:
第一种:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (column_name1 type [DEFAULT|MATERIALIZED|ALIAS expr],column_name2 type [DEFAULT|MATERIALIZED|ALIAS expr],......
) ENGINE = engine#使用 [db_name.] 参数可以为数据表指定数据库,如果不指定此参数,则默认会使用 default 数据库第二种:支持在不同的数据库之间复制表结构
CREATE TABLE [IF NOT EXISTS] [db_name1.]table_name1 AS [db_name2.]table_name2 [ENGINE = engine]
第三种:通过 SELECT 子句的形式创建,同时还会将 SELECT 子句查询的数据顺带写入
CREATE TABLE [IF NOT EXISTS] [db_name].table_name ENGINE = engine AS SELECT ...
#如下
CREATE TABLE IF NOT EXISTS db.not_exists_table ENGINE = Memory AS SELECT * FROM db.exists_table
2、删除表
DROP TABLE [IF EXISTS] [db_name.]table_name
3、基本操作
目前只有 MergeTree、Merge 和 Distributed 这三类表引擎支持 ALTER 查询
①追加新字段
ALTER TABLE table_name ADD COLUMN [IF NOT EXISTS] 字段名 [类型] [默认值] [插在哪个字段后面]
②修改字段类型或默认值
ALTER TABLE table_name MODIFY COLUMN [IF NOT EXISTS] 字段名 [类型] [默认值]
③修改字段注释
ALTER TABLE table_name COMMENT COLUMN [IF EXISTS] 字段名 'some comment'
④删除已有字段
ALTER TABLE table_name DROP COLUMN [IF EXISTS] name
⑤移动数据表(重命名)
在 Linux 系统中,mv 命令的本意是将一个文件从原始位置 A 移动到目标位置 B,但是如果位置 A 与位置 B 相同,则可以变相实现重命名的作用。ClickHouse 的 RENAME 查询就与之有着异曲同工之妙,RENAME 语句的完整语法如下所示:
RENAME TABLE [db_name1.]table_name1 TO [db_name2.]table_name2, [db_name1.]table_name3 TO [db_name2.]table_name3......
RENAME 可以修改数据表的名称,如果将原始数据库与目标数据库设为不同的名称,那么就可以实现数据表在两个数据库之间移动的效果,并且还可以同时移动多张 ,但是只能在单个节点范围内移动,即同一台服务器,而不是集群中的其他节点
⑥清空表
TRUNCATE TABLE [IF EXISTS] [db_name.]table_name
三、默认值
表字段支持三种默认值表达式的定义方法,分别是 DEFAULT、MATERIALIZED 和 ALIAS,有默认值且没有明确定义数据类型的以默认值为主,有明确数据类型的以定义的数据类型为主,如下:
CREATE TABLE table_name ( id String, col1 DEFAULT 100, col2 String DEFAULT col1
) ENGINE=Memory
其中 col1 字段根据默认值被推断为 UInt8;而 col2 字段由于同时定义了数据类型和默认值,所以它最终的数据类型来自明确定义的 String。
1、默认值三种定义方法之间的不同:
- 1)数据写入:在数据写入时,只有 DEFAULT 类型的字段可以出现在 INSERT 语句中,而 MATERIALIZED 和 ALIAS 都不能被显式赋值,它们只能依靠计算取值。例如试图为 MATERIALIZED 类型的字段写入数据,将会得到如下的错误。
DB::Exception: Cannot insert column URL,because it is MATERIALIZED column..
- 2)数据查询:在数据查询时,只有 DEFAULT 类型的字段可以通过 SELECT * 返回,而 MATERIALIZED 和 ALIAS 类型的字段不会出现在 SELECT * 查询的返回结果集中。
- 3)数据存储:在数据存储时,只有 DEFAULT 和 MATERIALIZED 类型的字段才支持持久化。如果使用的表引擎支持物理存储(例如 TinyLog 表引擎),那么这些列字段将会拥有物理存储。而 ALIAS 类型的字段不支持持久化,它的取值总是需要依靠计算产生,数据不会落到磁盘。
2、可以使用 ALTER 语句修改默认值,例如:
ALTER TABLE [db_name.]table_name MODIFY COLOMN col_name DEFAUET value
修改动作并不会影响数据表内先前已经存在的数据,但是默认值的修改有诸多限制,例如在 MergeTree 表引擎中,它的主键字段是无法被修改的;而某些表引擎则完全不支持修改(例如 TinyLog)。
四、临时表
创建临时表的方法是在普通表的基础之上添加 TEMPORARY 关键字
相比普通表而言,临时表有如下两点特殊之处:
它的生命周期是会话绑定的,所以它只支持 Memory 表引擎,如果会话结束,数据表就会被销毁;临时表不属于任何数据库,所以在它的建表语句中,既没有数据库参数也没有表引擎参数;- 临时表的优先级是大于普通表的。当临时表和普通表表名称相同的时候,会优先读取临时表的数据
五、分区表
不是所有的表引擎都支持分区,目前只有合并树(mergeTree)家族系列的表引擎才支持数据分区
1、创建分区
创建方式如下 案例:将日期转化成了年月分区
CREATE TABLE partition_v1 (ID String,URL String,EventDate Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY ID写入数据
INSERT INTO partition_v1 VALUES ('a1', 'www.a1.com', '2019-05-01'), ('a2', 'www.a2.com', '2019-06-02')
通过system.parts系统表查询数据表的分区状态
SELECT table, partition, path FROM system.parts WHERE table = 'partition_v1'
可以看到建立了两个分区,且每个分区对应一个独立的文件目录,所以当查询时过滤分区可以直接跳过不满足条件的分区
2、删除指定分区
ALTER TABLE table_name DROP PARTITION partition_expr
案例如下:
ALTER TABLE partition_v1 DROP PARTITION 201906
3、复制分区数据
ClickHouse 支持将 A 表的分区数据复制到 B 表,语法如下
ALTER TABLE B REPLACE PARTITION partition_expr FROM A
案例如下:
假设有一个数据表 partition_v2,并且与之前 partition_v1 的分区键和表结构完全相同,那么如果想将 partition_v1 中 5 月份的数据导入到 partition_v2中,就可以这么做
ALTER TABLE partition_v2 REPLACE PARTITION 201905 FROM partition_v1
不过需要注意的是,并不是任意数据表之间都能够相互复制,它们还需要满足两个前提条件:
两张表需要拥有相同的分区键;它们的表结构完全相同;
4、重置分区数据
如果数据表某一列的数据有误,需要将其重置为默认值,此时可以使用下面的语句实现:
ALTER TABLE table_name CLEAR COLUMN column_name IN PARTITION partition_expr
首先如果声明了默认值表达式,那么以表达式为准;否则以相应数据类型的默认值为准,比如 String 类型的默认值就是空字符串。
5、装载与卸载分区
表分区可以通过 DETACH 语句卸载,分区被卸载后,它的物理数据并没有删除,而是被转移到了当前数据表目录的 detached 子目录下。而装载分区则是反向操作,它能够将 detached 子目录下的某个分区重新装载回去。卸载与装载这一对伴生的操作,常用于分区数据的迁移和备份场景。卸载某个分区的语法如下所示:
ALTER TABLE table_name DETACH PARTITION partition_expr
假设有一个分区表 partition_v3,里面有很多月的数据,那么执行下面的语句就可以将该表中整个 8 月份的分区卸载。
ALTER TABLE partition_v3 DETACH PARTITION 201908
此时再次查询这张表,会发现其中 2019 年 8 月份的数据已经没有了。而进入 partition_v3 的磁盘目录,则可以看到被卸载的分区目录已经被移动到了 detached 目录中。
记住,一旦分区被移动到了 detached 子日录,就代表它已经脱离了 ClickHouse 的管理,ClickHouse 并不会主动清理这些文件。这此分区文件会一直存在,除非我们主动删除或者使用 ATTACH 语句重新装载它们。装载某个分区的完整语法如下所示:
ALTER TABLE table_name ATTACH PARTITION partition_expr
再次执行下面的语句,就可以将刚才已被卸载的 201908 分区重新装载回去:
ALTER TABLE partition_v3 ATTACH PARTITION 201908
六、视图
clickhouse有普通和物化视图两种,物化视图有独立的存储,普通的和关系型数据库的视图类似,只是一层简单的查询代理,创建普通视图的语法如下
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name AS SELECT...
物化视图需要指定表引擎,数据保存形式由表引擎决定,创建语法如下
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]view_name [TO [db.]name] ENGINE = engine [POPULATE] AS SELECT ...
案例如下
-- 物化视图本质上可以看成是一张特殊的数据表,在创建的时候也需要指定引擎
CREATE MATERIALIZED VIEW girls_view_1 ENGINE=TinyLog()
AS SELECT id, name, age FROM girls;
注意:
- 因为物化视图是可以存储数据的,所以当girls表被写入数据时,物化视图也会同步更新
- 物化视图只会同步创建后更新的数据,如果想在创建的时候就把数据同步过来需要POPULATE 使用案例如下
-- 只需要在 AS SELECT 的前面加上 POPULATE 即可
-- 此时表 girls 的数据,更准确的说是 SELECT 查询得到的结果集才会进入物化视图中
CREATE MATERIALIZED VIEW girls_view_1 ENGINE=TinyLog()
POPULATE AS SELECT id, name, age FROM girls;
视图可以用show table 和drop table命令来展示和删除,且视图名不能与表名重复
七、分布式DDL执行
将一条普通的 DDL 语句转换成分布式执行十分简单,只需加上 ON CLUSTER cluster_name 声明即可。例如,执行下面的语句后将会对 ch_cluster 集群内的所有节点广播这条 DDL 语句。
CREATE TABLE partition_v4 ON CLUSTER ch_cluster(ID String,URL String,EventDate Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY ID
相关文章:
clickhouse学习笔记(四)库、表、分区相关DDL操作
目录 一、数据库操作 1、创建数据库 2、查询及选择数据库 3、删除数据库 二、数据表操作 1、创建表 2、删除表 3、基本操作 ①追加新字段 ②修改字段类型或默认值 ③修改字段注释 ④删除已有字段 ⑤移动数据表(重命名) ⑥清空表 三、默认值…...

聚焦现代商贸物流愿景 构筑供应链金融服务体系|第二届京津冀现代商贸物流金融创新发展百人大会成功举办
6月16日,以“链产业筑高地赢未来——聚焦现代商贸物流愿景、构筑供应链金融服务体系”为主题的第二届京津冀现代商贸物流金融创新发展百人大会(以下简称“百人大会”),在2024中国廊坊国际经济贸易洽谈会(以下简称“廊坊经洽会”)开…...

解锁数据潜力:数据提取与治理的终极指南
解锁数据潜力:数据提取与治理的终极指南 在当今信息爆炸的时代,数据已成为企业决策的核心驱动力。然而,仅仅拥有海量数据并不足以确保竞争优势,关键在于如何有效地提取、治理和利用这些数据。本文将为您揭示数据提取技术的奥秘&a…...
报表中的时间是如何处理的?)
行列视(RCV)报表中的时间是如何处理的?
答:行列视(RCV)作为一套独立、且用于数据加工、处理和展示的系统,具有一套独立的时间处理机制。报表中的指标除了数据值外,最重要的属性就是时间。主要规则介绍如下: 实时数据,时间是指当前时间…...

成员变量和for循环里面的变量不冲突原因
今天写项目,发现一个类中有一个成员变量与for循环块中的局部变量重名了,但是也没有报错,功能也是正常的,然后了解了一下原因: 成员变量和 for 循环块中的变量不冲突的原因在于它们的作用域(Scopeÿ…...
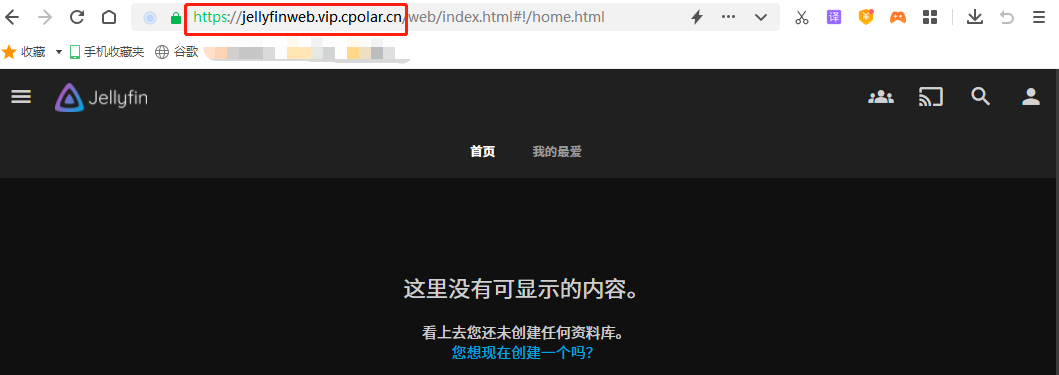
如何使用任意浏览器远程访问本地搭建的Jellyfin影音平台
文章目录 前言1. Jellyfin服务网站搭建1.1 Jellyfin下载和安装1.2 Jellyfin网页测试 2.本地网页发布2.1 cpolar的安装和注册2.2 Cpolar云端设置2.3 Cpolar本地设置 3.公网访问测试4. 结语 前言 本文主要分享如何使用Windows电脑本地部署Jellyfin影音服务并结合cpolar内网穿透工…...

CEM美国培安消解罐内管 CEM40位 55ML 微波消解罐
内罐采用高纯实验级进口增强改性处理TFM材料或PFA材料,我厂加工的微波罐能与原厂仪器匹配,而且是盖、体通配,无尺寸误差。精选材质,未添加回料,洁净的加工环境,优化了加工工艺,确保低本底&#…...

使用 Selenium 保持登录会话信息
使用 Selenium 保持登录会话信息 在进行 Web 自动化测试时,保持登录会话信息是一个常见的需求。这不仅能节省每次测试时重复登录的时间,还能模拟实际用户行为,使测试更加真实可靠。在这篇博客中,我们将深入探讨如何使用 Selenium 在每次启动时保持原有的登录会话信息。 什…...

程序员画图工具?那必然是你了!!【送源码】
作为一个程序员,画图是必不可少的技巧。当然此画图不是搞艺术,而是画各种架构图、流程图、泳道图以及各种示意图。 平时我不论是记笔记、写技术文章,还是工作中写文档,都需要配上各种各样的示意图。不管是帮助自己更好的掌握知识…...
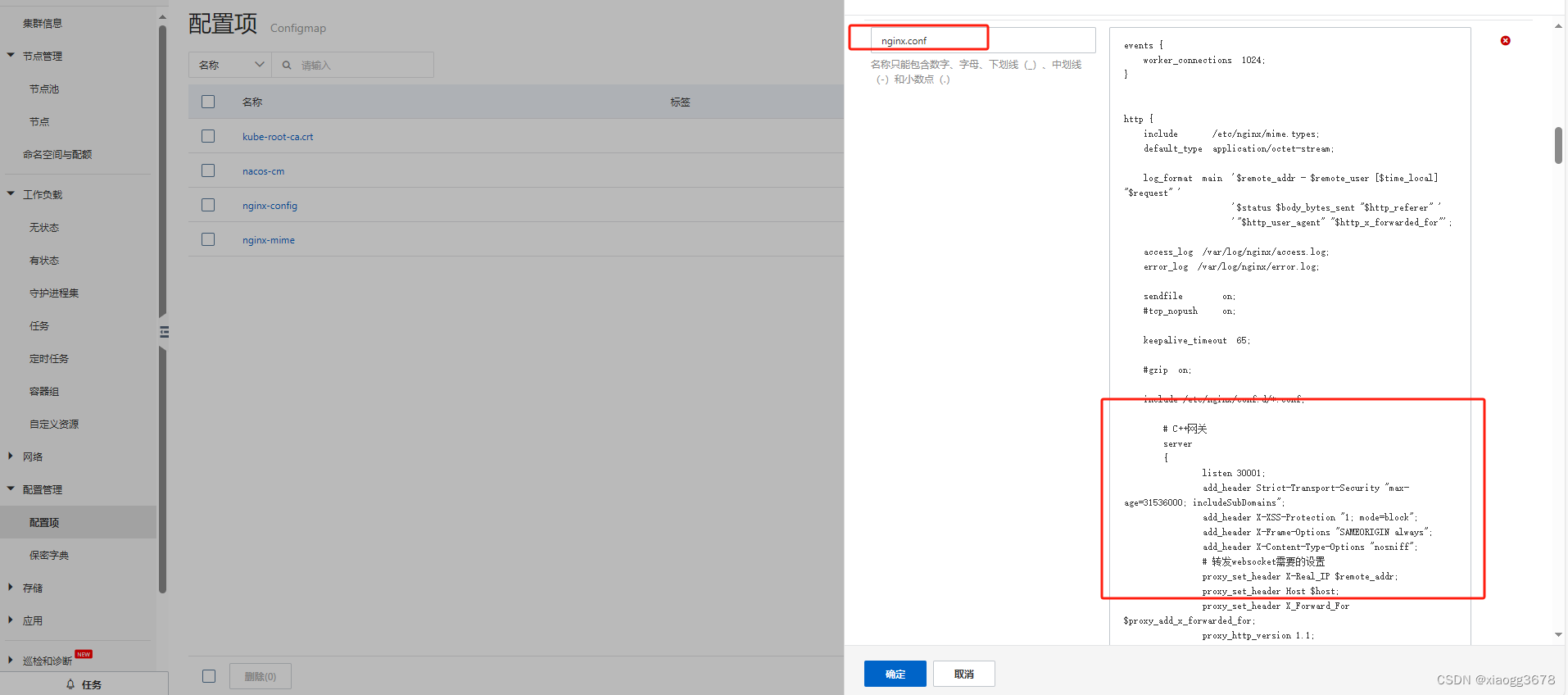
k8s nginx.conf配置文件配置
无状态nginx配置nginx.conf覆盖容器配置nginx.conf 代码:events {worker_connections 1024; }http {include /etc/nginx/mime.types;default_type application/octet-stream;log_format main $remote_addr - $remote_user [$time_local] "$request&q…...

XSKY 在金融行业:新一代分布式核心信创存储解决方案
近日,国家金融监督管理总局印发了《关于银行业保险业做好金融“五篇大文章”的指导意见》,在数字金融领域提出明确目标,要求银行业保险业数字化转型成效明显,数字化经营管理体系基本建成,数字化服务广泛普及࿰…...
第9章 类
第9章 类 9.1 创建和使用类9.1.1 创建 Dog 类9.1.2 根据类创建实例 9.2 使用类和实例9.2.1 Car 类9.2.2 给属性指定默认值9.2.3 修改属性的值 9.3 继承9.3.1 子类的方法__init__()9.3.2 给子类定义属性和方法9.3.3 重写父类的方法9.3.4 将实例用作属性9.3.5 模拟实物 9.4 导入类…...

Elasticsearch 第二期:倒排索引,分析,映射
前言 正像前面所说,ES真正强大之处在于可以从无规律的数据中找出有意义的信息——从“大数据”到“大信息”。这也是Elasticsearch一开始就将自己定位为搜索引擎,而不是数据存储的一个原因。因此用这一篇文字记录ES搜索的过程。 关于ES搜索计划分两篇或…...
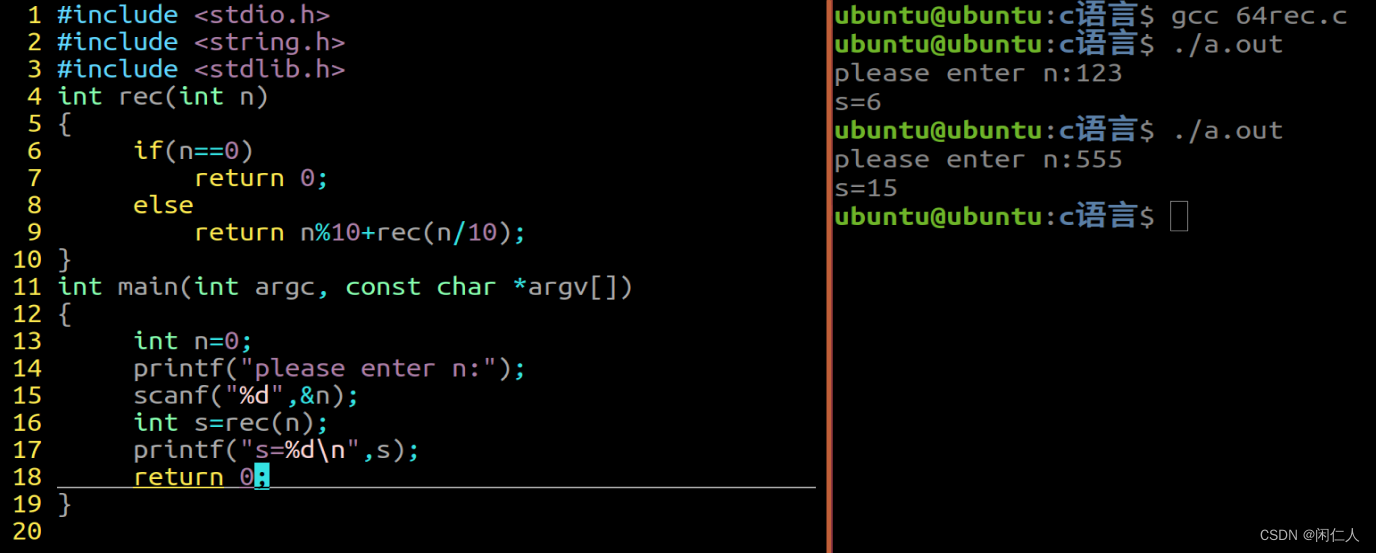
函数的一点点习题
1、利用递归计算0-n的和 #include <stdio.h> #include <string.h> #include <stdlib.h> int rec(int n) {if(n0)return 0;elsereturn nrec(n-1); } int main(int argc, const char *argv[]) {int n0;printf("please enter n:");scanf("%d&quo…...

使用Java计算Linux系统中sum命令得到的校验值
目录 ■相关知识 ・sum 命令 ・BSD校验算法是什么 ・BSD校验算法 和hash值 有区别吗 ・BSD校验算法,为什么是BSD,这个缩写代表什么 ■Java代码 ■效果 ====== ■相关知识 ・…...
】)
鸿蒙开发电话服务:【 @ohos.telephony.sms (短信服务)】
短信服务 说明: 本模块首批接口从API version 6开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 import sms from ohos.telephony.sms;sms.createMessage createMessage(pdu: Array, specification: string, callback: Asy…...
算法02 递归算法及其相关问题【C++实现】
递归 在编程中,我们把函数直接或者间接调用自身的过程叫做递归。 递归处理问题的过程是:通常把一个大型的复杂问题,转变成一个与原问题类似的,规模更小的问题来进行求解。 递归的三大要素 函数的参数。在用递归解决问题时&…...

Sermant标签路由能力在同城双活场景的应用
作者:聂子雄 华为云高级软件工程师 摘要:目前应用上云已成为趋势,用户也对应用在云上的高可靠方案有更高追求,目前同城双活场景作为应用高可靠方案中的一种常见实践方案,对微服务流量提出了数据中心亲和性的要求&…...

javascript-obfuscator混淆
安装 npm install javascript-obfuscator -g 配置 重度混淆,性能低 性能下降50-100% { "compact": true, "controlFlowFlattening": true, "controlFlowFlatteningThreshold": 0.75, // 设置为0到1之间的值 "deadCodeI…...

GitHub项目里的api
在一个GitHub项目中提到的"api"通常指的是该项目提供的应用程序编程接口(Application Programming Interface)。这意味着该项目包含了一套规则和工具,允许其他开发者通过代码调用该接口来与项目功能互动、获取数据或执行特定任务。…...

2026 年 Docker 镜像加速终极方案:告别拉取卡顿,一键提速
大家好!相信很多开发者都遇到过这样的问题:在配置 Docker 环境时,docker pull 命令经常卡住不动,进度条仿佛静止了一般,严重影响开发效率。为了解决这个痛点,我深入研究并测试了多种方案,最终整…...

10分钟搞定:XUnity.AutoTranslator游戏翻译插件终极使用指南
10分钟搞定:XUnity.AutoTranslator游戏翻译插件终极使用指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏看不懂而烦恼吗?XUnity.AutoTranslator正是你需要的游戏…...

ChatSVA:多智能体框架革新硬件验证中的SVA生成
1. ChatSVA:硬件验证领域的SVA生成革命在集成电路设计领域,功能验证已成为制约开发效率的最大瓶颈。据统计,现代芯片开发周期中超过50%的时间消耗在功能验证环节,而SystemVerilog断言(SVA)作为形式化验证和…...

人文艺术体系清单——衣冠服饰体系
一、历朝服饰考据清单(主流汉地服饰)考据要求:完整复原形制、剪裁结构、面料制式、色彩规范、时代特征、人文气运、上古图腾溯源,对齐本体系地脉气运、人文文气、先天图腾大道逻辑。上古时期:玄鸟衣冠、上古祭服、原始…...
)
别再搞混了!Web地图开发必懂的EPSG:4326和EPSG:3857(附JavaScript转换代码)
Web地图开发中的坐标系解密:从原理到实战 第一次在Leaflet地图上叠加GPS轨迹数据时,我盯着那个偏离了三条街的路径百思不得其解——经纬度坐标明明正确,为什么显示位置完全不对?这个困扰无数Web开发者的经典问题,根源在…...

别再死记硬背截止、放大、饱和了!用Arduino+面包板,5分钟直观演示三极管三种工作状态
用Arduino实战破解三极管工作状态的秘密 记得第一次学三极管时,盯着课本上那些截止区、放大区、饱和区的曲线图,我完全无法理解这些抽象概念和实际电路有什么关系。直到有一天,我在实验室里用Arduino和几个简单元件搭建了一个测试电路&#x…...

WechatDecrypt技术实现:如何通过开源工具实现微信数据本地解密与隐私保护
WechatDecrypt技术实现:如何通过开源工具实现微信数据本地解密与隐私保护 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 在数字化时代,数据隐私保护已成为技术开发者和普通用户共…...

AI智能体记忆系统设计:分层架构与向量化检索实战
1. 项目概述:一个为AI智能体设计的记忆系统最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的痛点:如何让这些智能体拥有“记忆”?不是那种简单的对话历史记录,而是更接近人类工作记忆和…...

3步完成微信聊天记录永久备份:开源工具WeChatExporter终极指南
3步完成微信聊天记录永久备份:开源工具WeChatExporter终极指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter WeChatExporter是一款专为Mac用户设计的开源工…...

MimicFlow:可视化AI代码生成过程,弥合编程信任鸿沟
1. 项目概述:当AI写代码时,我们如何“看见”思考过程?如果你和我一样,深度使用过Cursor、GitHub Copilot或者任何基于大语言模型的AI编程助手,一定经历过这样的瞬间:你提出一个需求,AI助手瞬间生…...